BelWue/flowpipeline
GitHub: BelWue/flowpipeline
一个基于 Go 的网络流数据处理工具包,通过可配置的模块化管道实现 Netflow/sFlow 的采集、处理与分析。
Stars: 27 | Forks: 9
该项目已迁移至 https://codeberg.org/BelWue/flowpipeline \
请查看新仓库以获取最新版本。
# Flowpipeline
一个兼容 [goflow2](https://github.com/netsampler/goflow2) 的 flow 消息处理工具包
[godoc](https://pkg.go.dev/github.com/BelWue/flowpipeline)

## 关于本项目
[bwNET](https://bwnet.belwue.de/) 是德国巴登-符腾堡州的一个研究项目,旨在为该州的科研教育网络 [BelWü](https://www.belwue.de) 提供创新服务。该 GitHub 组织包含了与该项目监控方面相关的代码。
本仓库包含我们的 flow 处理工具包,它使我们及用户能够为兼容 [goflow2](https://github.com/netsampler/goflow2) 的 flow 消息定义 pipeline。flowpipeline 项目将我们 flow 处理技术栈中的大部分其他部分集成到一个软件中,该软件可配置以实现任何功能:
* 接收原始 Netflow(使用 [goflow2](https://github.com/netsampler/goflow2))
* 丰富生成的 flow 消息([examples/configurations/enricher](https://github.com/BelWue/flowpipeline/tree/master/examples/configurations/enricher))
* 写入和读取 Kafka([examples/localkafka](https://github.com/BelWue/flowpipeline/tree/master/examples/configuration/localkafka))
* 将 flow 转储到 cli(例如 [flowdump](https://github.com/BelWue/flowpipeline/tree/master/examples/configuration/flowdump))
* 提供指标和洞察([examples/prometheus](https://github.com/BelWue/flowpipeline/tree/master/examples/configuration/prometheus))
* 以及更多...
## 入门指南
要开始使用,请选择以下部署方式之一。
### 从源码编译
克隆本仓库并使用 `go build .` 自行构建二进制文件。
默认情况下,二进制文件会在其本地目录中查找 `config.yml`,因此你需要创建一个,或者从任意示例目录调用它(并可能遵循那里的说明)。
### 二进制发布版
下载我们的[最新发布版](https://github.com/BelWue/flowpipeline/releases)并运行它,就像你自己编译的一样。
flowpipeline 发布版包含 MacOS(`flowpipeline-darwin`)和 linux(`flowpipeline-linux`)的可执行文件。
默认的动态链接版本需要相对较新的系统(glibc 2.32+, linux 5.11+ 用于 `bpf`, `mongodb` 等)并附带所有功能。
作为备选方案,静态二进制文件可在较旧的环境中运行(Rocky Linux 8, Debian 11, ...),但不包含需要 CGO/动态链接代码的 segments(`bpf`, `sqlite`, `mongodb` 和插件支持,请查看 [CONFIGURATION.md](https://github.com/BelWue/flowpipeline/blob/master/CONFIGURATION.md))。
### 容器发布版
#### Flowpipeline 独立容器
提供了一个即用型容器 `belwue/flowpipeline`,你可以在 [GitHub 容器注册表](https://github.com/BelWue/flowpipeline/pkgs/container/flowpipeline)上查看它。
引用其他文件(例如地理位置数据库)的配置在容器中无需额外修改即可工作。这是因为如果二进制文件是使用 `container` 构建标志构建的,则在所有接受配置以打开文件的 segments 中,都会在文件路径前加上卷挂载点 `/config`。
```
podman run -v ./examples/configuration/xy:/config flowpipeline
# 或
docker run -v ./examples/configuration/xy:/config flowpipeline
```
#### Flowpipeline 演示容器
我们还提供了一个容器,通过 prometheus+grafana 仪表板展示示例可视化(ghcr.io/belwue/flowpipeline-grafana)。
示例容器启动时包含:
- 运行在端口 3000 的 grafana
- 使用默认的 grafana 管理员凭据启动(`user:admin, password:admin`)
- 运行在端口 2055 的 netflow 接收器
- 运行在端口 6343 的 sflow 接收器
- 运行在端口 9090 的 prometheus
```
docker run -p 3000:3000 -p 2055:2055/udp -p 6343:6343 -p 9090:9090 /udp ghcr.io/belwue/flowpipeline-grafana
```
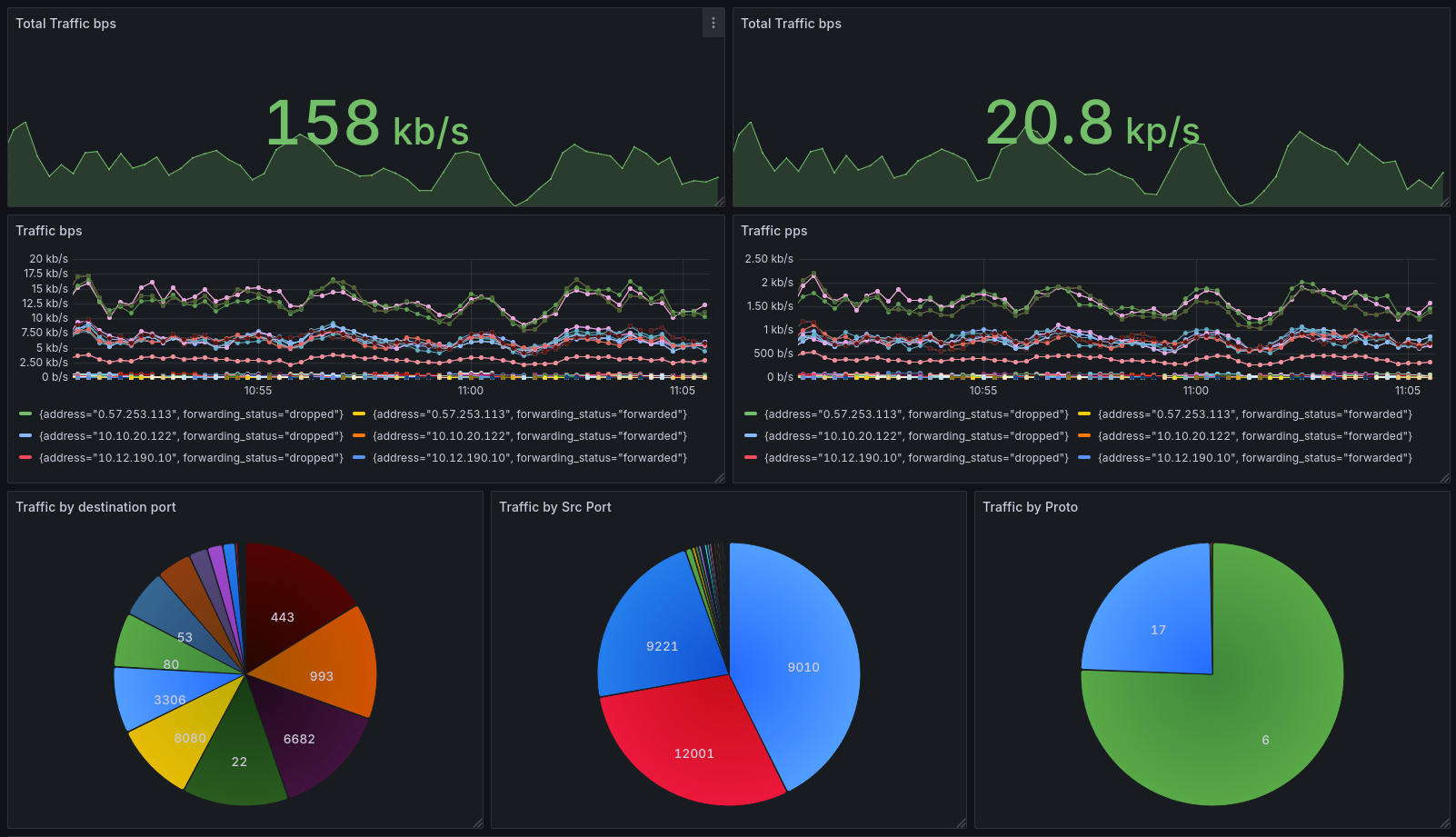 相应的配置文件位于 `/examples/visualization`
## 配置
有关完整指南,请参阅 [CONFIGURATION.md](https://github.com/BelWue/flowpipeline/blob/master/CONFIGURATION.md)。除此之外,查看示例应该能让你详细了解配置的样子以及可能的应用场景。
flowpipeline 使用的默认配置文件是 `config.yml`。
要使用另一个配置文件,必须使用 `-c path/to/file.yml` 指定其位置。
配置文件应以 `input` 组中的一个 segment 开始。随后可以跟一个或多个 segments。后续 segments 处理前一个 segment 输出的所有 flows。
大多数 segments 会输出它们从前一个 segment 消费的所有 flows。
例外是 `filter` 组的 segments。
为了完整起见,这是另一个最小示例,它在端口 2055 上监听 Netflow v9,应用作为第一个参数给出的过滤器,然后以 `tcpdump` 风格的格式将其打印到 `stdout`。
```
- segment: goflow
- segment: flowfilter
config:
filter: $0
- segment: printflowdump
```
例如,你可以使用 `./flowpipeline "proto tcp and (port 80 or port 443)"` 来调用它。
### 生产环境部署
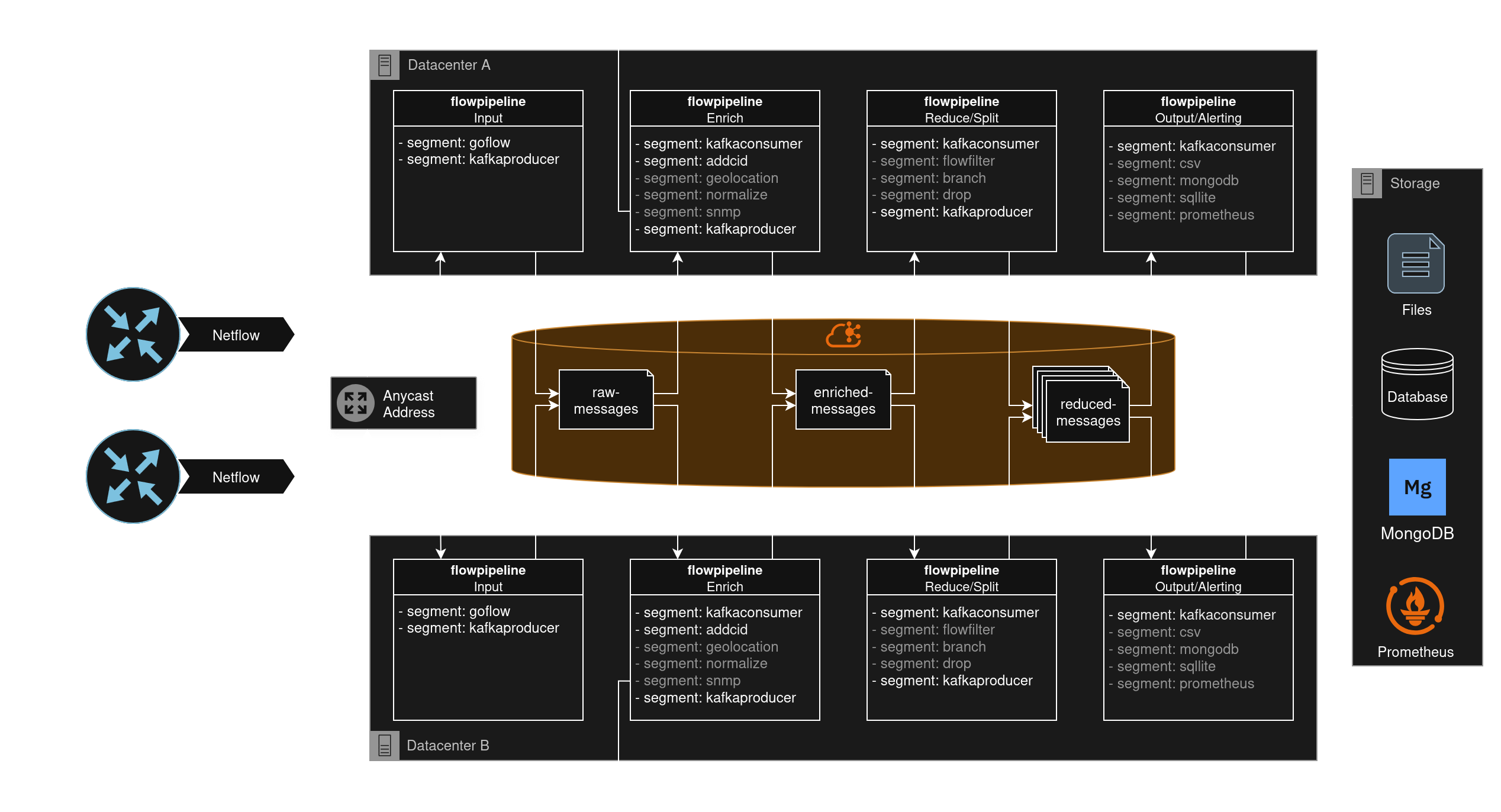
对于生产环境中的部署,强烈建议使用中心 Kafka 集群。
这允许在多个地理位置冗余的位置分布多个冗余的 flowpipeline 实例。
不同的 workers 可以使用 `kafkaconsumer` segment 从集群读取,并使用 `kafkaproducer` segment 写入集群。
冗余 workers 需要为所有实例配置相同的 kafka group,以避免重复 flows。
相应的配置文件位于 `/examples/visualization`
## 配置
有关完整指南,请参阅 [CONFIGURATION.md](https://github.com/BelWue/flowpipeline/blob/master/CONFIGURATION.md)。除此之外,查看示例应该能让你详细了解配置的样子以及可能的应用场景。
flowpipeline 使用的默认配置文件是 `config.yml`。
要使用另一个配置文件,必须使用 `-c path/to/file.yml` 指定其位置。
配置文件应以 `input` 组中的一个 segment 开始。随后可以跟一个或多个 segments。后续 segments 处理前一个 segment 输出的所有 flows。
大多数 segments 会输出它们从前一个 segment 消费的所有 flows。
例外是 `filter` 组的 segments。
为了完整起见,这是另一个最小示例,它在端口 2055 上监听 Netflow v9,应用作为第一个参数给出的过滤器,然后以 `tcpdump` 风格的格式将其打印到 `stdout`。
```
- segment: goflow
- segment: flowfilter
config:
filter: $0
- segment: printflowdump
```
例如,你可以使用 `./flowpipeline "proto tcp and (port 80 or port 443)"` 来调用它。
### 生产环境部署
对于生产环境中的部署,强烈建议使用中心 Kafka 集群。
这允许在多个地理位置冗余的位置分布多个冗余的 flowpipeline 实例。
不同的 workers 可以使用 `kafkaconsumer` segment 从集群读取,并使用 `kafkaproducer` segment 写入集群。
冗余 workers 需要为所有实例配置相同的 kafka group,以避免重复 flows。
 ### 自定义 Segments
如果你发现现有的 segments 缺少某些功能,或者你需要某些非常具体的行为,可以将 segments 作为插件包含进来。
这是通过 `-p yourplugin.so` 命令行选项和你自己的自定义模块完成的。有关基本示例和编译插件的说明,请参阅 [examples/plugin](https://github.com/BelWue/flowpipeline/tree/master/examples/configuration/plugin)。
请注意,这需要 CGO,因此无法在使用静态二进制发布版或在容器中运行。
## 贡献
非常欢迎任何形式的贡献(代码、问题、功能请求)。
### 自定义 Segments
如果你发现现有的 segments 缺少某些功能,或者你需要某些非常具体的行为,可以将 segments 作为插件包含进来。
这是通过 `-p yourplugin.so` 命令行选项和你自己的自定义模块完成的。有关基本示例和编译插件的说明,请参阅 [examples/plugin](https://github.com/BelWue/flowpipeline/tree/master/examples/configuration/plugin)。
请注意,这需要 CGO,因此无法在使用静态二进制发布版或在容器中运行。
## 贡献
非常欢迎任何形式的贡献(代码、问题、功能请求)。
相应的配置文件位于 `/examples/visualization`
## 配置
有关完整指南,请参阅 [CONFIGURATION.md](https://github.com/BelWue/flowpipeline/blob/master/CONFIGURATION.md)。除此之外,查看示例应该能让你详细了解配置的样子以及可能的应用场景。
flowpipeline 使用的默认配置文件是 `config.yml`。
要使用另一个配置文件,必须使用 `-c path/to/file.yml` 指定其位置。
配置文件应以 `input` 组中的一个 segment 开始。随后可以跟一个或多个 segments。后续 segments 处理前一个 segment 输出的所有 flows。
大多数 segments 会输出它们从前一个 segment 消费的所有 flows。
例外是 `filter` 组的 segments。
为了完整起见,这是另一个最小示例,它在端口 2055 上监听 Netflow v9,应用作为第一个参数给出的过滤器,然后以 `tcpdump` 风格的格式将其打印到 `stdout`。
```
- segment: goflow
- segment: flowfilter
config:
filter: $0
- segment: printflowdump
```
例如,你可以使用 `./flowpipeline "proto tcp and (port 80 or port 443)"` 来调用它。
### 生产环境部署
对于生产环境中的部署,强烈建议使用中心 Kafka 集群。
这允许在多个地理位置冗余的位置分布多个冗余的 flowpipeline 实例。
不同的 workers 可以使用 `kafkaconsumer` segment 从集群读取,并使用 `kafkaproducer` segment 写入集群。
冗余 workers 需要为所有实例配置相同的 kafka group,以避免重复 flows。
### 自定义 Segments
如果你发现现有的 segments 缺少某些功能,或者你需要某些非常具体的行为,可以将 segments 作为插件包含进来。
这是通过 `-p yourplugin.so` 命令行选项和你自己的自定义模块完成的。有关基本示例和编译插件的说明,请参阅 [examples/plugin](https://github.com/BelWue/flowpipeline/tree/master/examples/configuration/plugin)。
请注意,这需要 CGO,因此无法在使用静态二进制发布版或在容器中运行。
## 贡献
非常欢迎任何形式的贡献(代码、问题、功能请求)。标签:API集成, BelWü, EVTX分析, EVTX分析, goflow2, Go语言, IPFIX, Kafka, Linux运维, NetFlow, pipx 安装, pip 包, sFlow, SonarQube插件, WSL, 二进制发布, 可观测性, 安全研究社区, 开源安全, 开源工具, 数据 enrichment, 数据处理管道, 日志审计, 流处理, 流量采集, 目录遍历, 程序破解, 网络安全, 网络流量分析, 自定义请求头, 请求拦截, 调试插件, 防御绕过, 隐私保护