NVIDIA-Merlin/Transformers4Rec
GitHub: NVIDIA-Merlin/Transformers4Rec
Transformers4Rec是一个将NLP领域的Transformer架构应用于序列和会话推荐的PyTorch库,支持多特征输入和GPU加速的端到端推荐pipeline。
Stars: 1271 | Forks: 160
# [Transformers4Rec](https://github.com/NVIDIA-Merlin/Transformers4Rec/)
[](https://pypi.python.org/pypi/Transformers4Rec)
[](https://github.com/NVIDIA-Merlin/Transformers4Rec/blob/stable/LICENSE)
[](https://nvidia-merlin.github.io/Transformers4Rec/stable/README.html)
Transformers4Rec 是一个灵活高效的库,用于序列推荐和基于会话的推荐,并且可以与 PyTorch 配合使用。
该库通过集成最流行的 NLP 框架之一 [Hugging Face Transformers](https://github.com/huggingface/transformers) (HF),充当了自然语言处理 (NLP) 和推荐系统 (RecSys) 之间的桥梁。
Transformers4Rec 使 RecSys 研究人员和行业从业者能够使用最先进的 transformer 架构。
下图展示了该库在推荐系统中的使用。
输入数据通常是交互序列,例如在 Web 会话中浏览的商品或放入购物车的商品。
该库帮助您处理和建模这些交互,以便您可以为下一个商品输出更好的推荐。
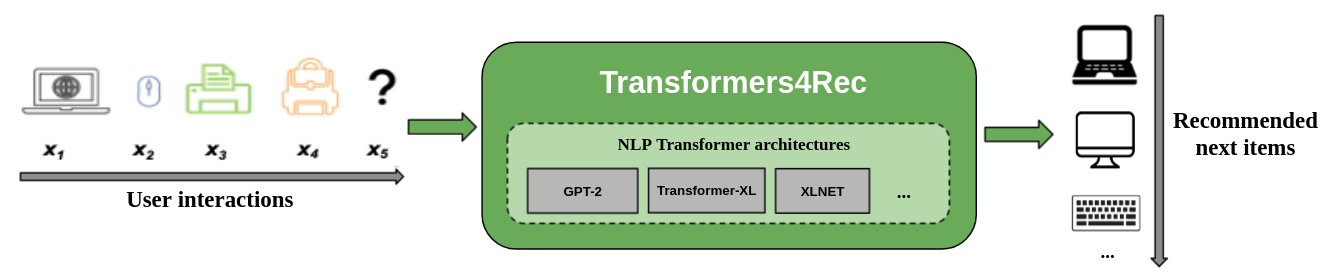
使用 Transformers4Rec 进行序列推荐和基于会话的推荐
传统的推荐算法在尝试建模用户行为时,通常会忽略时间动态和交互序列。
通常,用户的下一次交互与用户之前的选择序列有关。
在某些情况下,它可能是重复购买或播放歌曲。
用户兴趣也可能遭受兴趣漂移的影响,因为偏好会随时间变化。
**序列推荐** 任务解决了这些挑战。
序列推荐的一个特殊用例是 **基于会话的推荐** 任务,在该任务中,您只能访问当前会话内的短交互序列。
这在电子商务、新闻和媒体门户等在线服务中非常常见,在这些服务中,用户可能由于 GDPR 合规性限制了 Cookie 的收集,或者因为用户是新用户,而选择匿名浏览。
此任务也适用于用户的兴趣随时间变化很大,取决于用户上下文或意图的场景。
在这种情况下,利用当前会话的交互比旧的交互更有希望提供相关的推荐。
为了处理序列推荐和基于会话的推荐,先前在机器学习和 NLP 研究中应用的许多序列学习算法已被探索用于 RecSys,这些算法基于 k-Nearest Neighbors、频繁模式挖掘、隐马尔可夫模型、循环神经网络,以及最近使用自注意力机制 和 transformer 架构的神经架构。
与 Transformers4Rec 不同,这些框架只接受 item ID 序列作为输入,并没有为生产用途提供模块化、可扩展的实现。
## Transformers4Rec 的优势
Transformers4Rec 提供以下优势:
- **灵活性**:Transformers4Rec 提供可配置且与标准 PyTorch 模块兼容的模块化构建块。
这种构建块设计使您能够创建具有多个塔、多个头/任务和损失的自定义架构。
- **访问 HF Transformers**:由于集成了 [Hugging Face Transformers](https://github.com/huggingface/transformers),可以使用 64 种以上不同的 Transformer 架构来评估您的序列和基于会话的推荐任务。
- **支持多种输入特征**:HF Transformers 仅支持 token ID 序列作为输入,因为它最初是为 NLP 设计的。
Transformers4Rec 使您能够将其他类型的序列表格数据作为输入与 HF transformers 一起使用,这得益于 RecSys 数据集中丰富的特征。
Transformers4Rec 使用 schema 来配置输入特征,并根据目标自动创建必要的层,例如 embedding 表、投影层和输出层,而无需更改代码以包含新特征。
您可以以可配置的方式标准化和组合交互级和序列级输入特征。
- **无缝预处理和特征工程**:作为 Merlin 生态系统的一部分,Transformers4Rec 与 [NVTabular](https://github.com/NVIDIA-Merlin/NVTabular) 和 [Triton Inference Server](https://github.com/triton-inference-server/server) 集成。
这些组件使您能够构建用于序列和基于会话推荐的完全 GPU 加速的 pipeline。
NVTabular 具有用于基于会话推荐的常见预处理操作,并导出数据集 schema。
该 schema 与 Transformers4Rec 兼容,因此可以自动配置输入特征。
您可以将训练好的模型导出到 Triton Inference Server 进行服务,在一个包含在线特征预处理和模型推理的单个 pipeline 中。
有关更多信息,请参阅 [End-to-end pipeline with NVIDIA Merlin](https://nvidia-merlin.github.io/Transformers4Rec/stable/pipeline.html)。
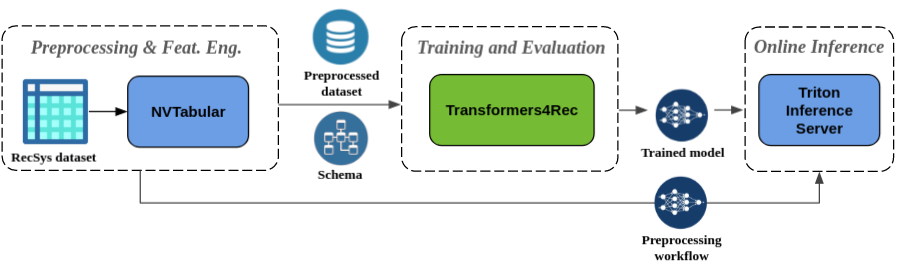
使用 NVIDIA Merlin 组件的 GPU 加速 pipeline,用于序列和基于会话的推荐
## Transformers4Rec 成就
Transformers4Rec 最近赢得了两项基于会话的推荐竞赛:[WSDM WebTour Workshop Challenge 2021 (由 Booking.com 组织)](https://developer.nvidia.com/blog/how-to-build-a-winning-deep-learning-powered-recommender-system-part-3/) 和 [SIGIR eCommerce Workshop Data Challenge 2021 (由 Coveo 组织)](https://medium.com/nvidia-merlin/winning-the-sigir-ecommerce-challenge-on-session-based-recommendation-with-transformers-v2-793f6fac2994)。
该库为基于会话的推荐提供了比基线算法更高的准确性,并且我们对准确性进行了广泛的实证分析。
这些观察结果发表在我们的 [ACM RecSys'21 论文](https://dl.acm.org/doi/10.1145/3460231.3474255) 中。
## 示例代码:定义和训练模型
使用 Transformers4Rec 训练模型通常需要执行以下高级步骤:
1. 提供 [schema](https://nvidia-merlin.github.io/Transformers4Rec/stable/api/merlin_standard_lib.schema.html#merlin_standard_lib.schema.schema.Schema) 并构建输入模块。
如果您遇到基于会话的推荐问题,通常需要使用
[TabularSequenceFeatures](https://nvidia-merlin.github.io/Transformers4Rec/stable/api/transformers4rec.torch.features.html#transformers4rec.torch.features.sequence.TabularSequenceFeatures)
类,因为它将上下文特征与序列特征合并。
2. 提供 prediction-tasks。
现成的任务可在我们的 [API 文档](https://nvidia-merlin.github.io/Transformers4Rec/stable/api/transformers4rec.torch.model.html#module-transformers4rec.torch.model.prediction_task) 中找到。
3. 构建 transformer-body 并将其转换为模型。
以下代码示例展示了如何使用 PyTorch 定义和训练 XLNet 模型以进行下一项预测任务:
```
from transformers4rec import torch as tr
from transformers4rec.torch.ranking_metric import NDCGAt, RecallAt
# 创建 Schema 或从磁盘读取:tr.Schema().from_json(SCHEMA_PATH)。
schema: tr.Schema = tr.data.tabular_sequence_testing_data.schema
max_sequence_length, d_model = 20, 64
# 定义用于处理表格输入特征的 Input Module。
input_module = tr.TabularSequenceFeatures.from_schema(
schema,
max_sequence_length=max_sequence_length,
continuous_projection=d_model,
aggregation="concat",
masking="causal",
)
# 定义 Transformer-config,如 XLNet 架构。
transformer_config = tr.XLNetConfig.build(
d_model=d_model, n_head=4, n_layer=2, total_seq_length=max_sequence_length
)
# 定义 Model Block,包括:inputs、masking、projection 和 transformer block。
body = tr.SequentialBlock(
input_module,
tr.MLPBlock([d_model]),
tr.TransformerBlock(transformer_config, masking=input_module.masking)
)
# 定义评估 top-N metrics 和 cut-offs。
metrics = [NDCGAt(top_ks=[20, 40], labels_onehot=True),
RecallAt(top_ks=[20, 40], labels_onehot=True)]
# 定义带有 NextItemPredictionTask 的 Head。
head = tr.Head(
body,
tr.NextItemPredictionTask(weight_tying=True, metrics=metrics),
inputs=input_module,
)
# 获取端到端 Model 类。
model = tr.Model(head)
```
## 安装
您可以使用 Pip、Conda 安装 Transformers4Rec,或运行 Docker 容器。
### 使用 Pip 安装 Transformers4Rec
您可以安装 Transformers4Rec,并具备使用 GPU 加速的 Merlin dataloader 的功能。
强烈建议安装 dataloader 以获得更好的性能。
这些组件可以作为 `pip install` 命令的可选参数进行安装。
要使用 Pip 安装 Transformers4Rec,请运行以下命令:
```
pip install transformers4rec[nvtabular]
```
-> 请注意,使用 `pip` 安装 Transformers4Rec 不会自动安装 RAPIDS cuDF。
-> GPU 加速版本的 NVTabular transforms 和 Merlin Dataloader 需要 cuDF。
此处提供了使用 pip 安装 cuDF 的说明:https://docs.rapids.ai/install#pip-install
```
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com
```
### 使用 Conda 安装 Transformers4Rec
要使用 Conda 安装 Transformers4Rec,请使用 `conda` 或 `mamba` 运行以下命令以创建一个新环境。
```
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge \
transformers4rec=23.04 `# NVIDIA Merlin` \
nvtabular=23.04 `# NVIDIA Merlin - Used in example notebooks` \
python=3.10 `# Compatible Python environment` \
cudf=23.02 `# RAPIDS cuDF - GPU accelerated DataFrame` \
cudatoolkit=11.8 pytorch-cuda=11.8 `# NVIDIA CUDA version`
```
### 使用 Docker 安装 Transformers4Rec
Transformers4Rec 预安装在 `merlin-pytorch` 容器中,该容器可从 NVIDIA GPU Cloud (NGC) 目录中获得。
有关 Merlin 容器名称、目录中容器镜像的 URL 以及关键 Merlin 组件的信息,请参阅 [Merlin Containers](https://nvidia-merlin.github.io/Merlin/stable/containers.html) 文档页面。
## Notebook 示例和教程
[End-to-end pipeline with NVIDIA Merlin](https://nvidia-merlin.github.io/Transformers4Rec/stable/pipeline.html) 页面
展示了如何使用 Transformers4Rec 和其他 Merlin 库(如 NVTabular)来构建完整的推荐系统。
我们有几个 [示例](./examples) notebook 来帮助您构建推荐系统或将 Transformers4Rec 集成到您的系统中:
- 一个入门示例,包括使用 XLNET transformer 架构训练基于会话的模型。
- 一个端到端示例,训练模型并采取下一步措施使用 Triton Inference Server 服务推理。
- 另一个端到端示例,在 RNN 上训练和评估基于会话的模型,并使用 Triton Inference Server 服务推理。
- 重现 RecSys 2021 论文中所述实验的 notebook 和脚本。
## 反馈与支持
如果您想直接为 Transformers4Rec 做出贡献,请参阅 [Contributing to Transformers4Rec](CONTRIBUTING.md)。我们对功能工程和预处理操作的贡献或功能请求特别感兴趣。为了进一步推进我们的 Merlin 路线图,我们鼓励您通过访问 https://developer.nvidia.com/merlin-devzone-survey 分享有关您推荐系统 pipeline 的所有详细信息。
如果您有兴趣了解更多关于 Transformers4Rec 的工作原理,请参阅我们的
[Transformers4Rec 文档](https://nvidia-merlin.github.io/Transformers4Rec/stable/getting_started.html)。我们还有 [API 文档](https://nvidia-merlin.github.io/Transformers4Rec/stable/api/modules.html),其中概述了 Transformers4Rec 中可用的模块和类的具体细节。
标签:Apex, Hugging Face, NLP, NVIDIA Merlin, PyTorch, RecSys, Transformer, Vectored Exception Handling, 人工智能, 代码示例, 会话推荐, 凭据扫描, 序列推荐, 开源库, 推荐系统, 搜索引擎爬虫, 数据分析, 时序模型, 机器学习, 深度学习, 用户模式Hook绕过, 用户行为建模, 请求拦截, 逆向工具