TsingZ0/PFLlib
GitHub: TsingZ0/PFLlib
这是一个帮助用户在个人电脑上快速掌握和测试个性化联邦学习算法的开源库和基准平台。
Stars: 2141 | Forks: 411
#  PFLlib:个性化联邦学习库与基准测试平台
👏 **[官方网站](http://www.pfllib.com)** 和 **[排行榜](http://www.pfllib.com/benchmark.html)** 已上线!我们的方法——[FedCP](https://github.com/TsingZ0/FedCP)、[GPFL](https://github.com/TsingZ0/GPFL) 和 [FedDBE](https://github.com/TsingZ0/DBE)——处于领先地位。值得注意的是,**FedDBE** 在不同数据异质性水平下都展现出稳健的性能。
[](https://www.jmlr.org/papers/v26/23-1634.html)
[](https://arxiv.org/abs/2312.04992)

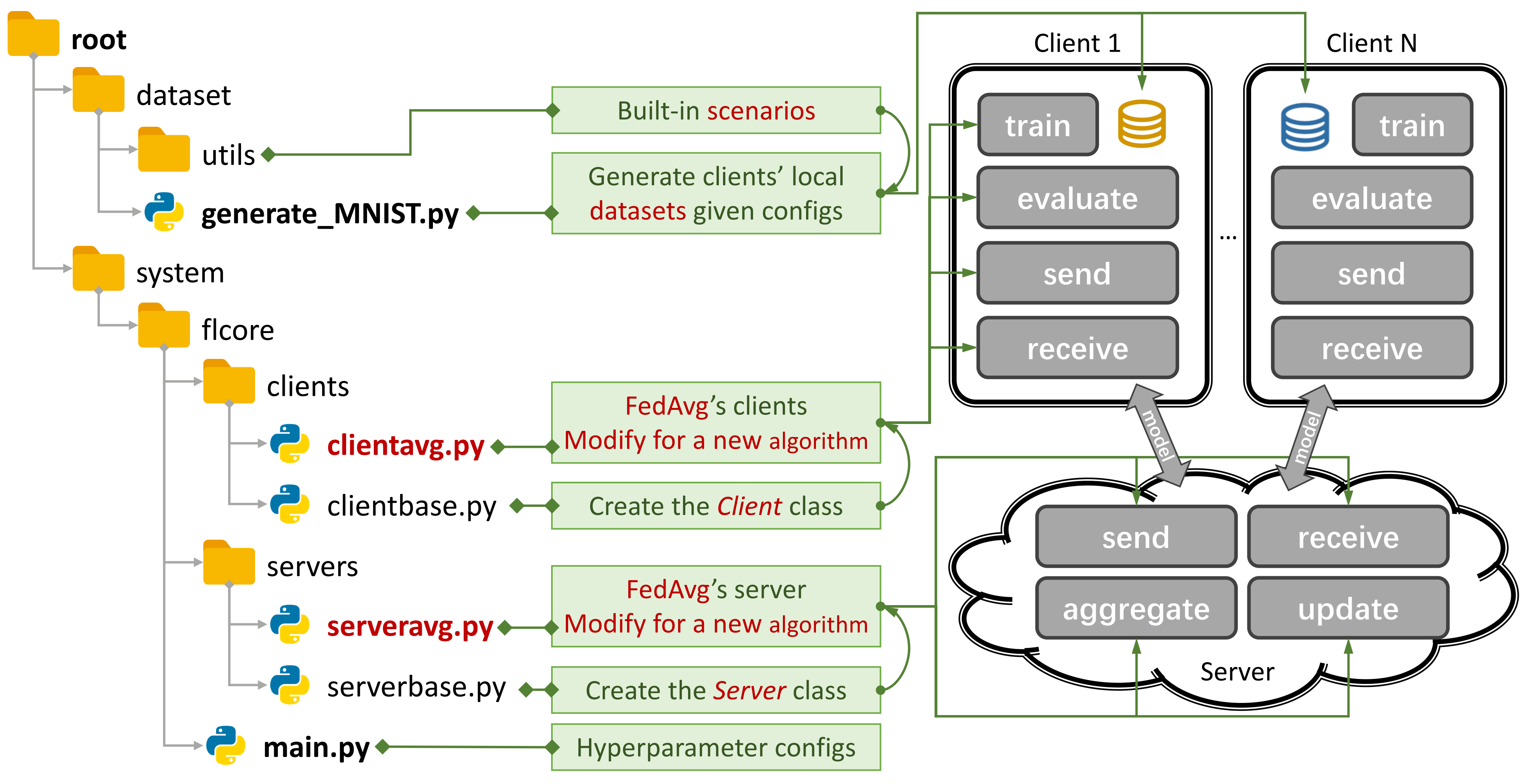
图 1:FedAvg 示例。您可以使用 `generate_DATA.py` 创建一个场景,并使用 `main.py`、`clientNAME.py` 和 `serverNAME.py` 运行一个算法。对于新算法,您只需在 `clientNAME.py` 和 `serverNAME.py` 中添加新功能。
🎯 **如果您觉得我们的仓库有用,请引用相关论文:**
```
@article{zhang2025pfllib,
title={PFLlib: A Beginner-Friendly and Comprehensive Personalized Federated Learning Library and Benchmark},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={Journal of Machine Learning Research},
volume={26},
number={50},
pages={1--10},
year={2025}
}
@inproceedings{Zhang2025htfllib,
author={Zhang, Jianqing and Wu, Xinghao and Zhou, Yanbing and Sun, Xiaoting and Cai, Qiqi and Liu, Yang and Hua, Yang and Zheng, Zhenzhe and Cao, Jian and Yang, Qiang},
title = {HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark},
year = {2025},
booktitle = {Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
```
### 主要特性
- **39 种传统联邦学习([tFL](#traditional-fl-tfl))和个性化联邦学习([pFL](#personalized-fl-pfl))算法,3 种场景,24 个数据集。**
- 实际设备部署:[HtFL-OnDevice](https://github.com/TsingZ0//HtFL-OnDevice)。
- 部分 **实验结果** 可在其[论文](https://arxiv.org/abs/2312.04992)和[此处](#experimental-results)获取。
- 参考[示例](#how-to-start-simulating-examples-for-fedavg)学习如何使用。
- 参考[易于扩展](#easy-to-extend)学习如何添加新数据或算法。
- 该基准测试平台可以在 **单张 NVIDIA GeForce RTX 3090 GPU 卡** 上,仅使用 **5.08GB GPU 内存**,模拟 **500 个客户端** 使用 4 层 CNN 在 Cifar100 上的场景。
- 我们提供[隐私评估](#privacy-evaluation)和[系统化研究支持](#systematical-research-support)。
- 您现在可以通过在 `./system/main.py` 中设置 `args.num_new_clients` 来在部分客户端上训练并在新客户端上评估性能。请注意,并非所有 tFL/pFL 算法都支持此特性。
- PFLlib 主要关注数据(统计)异质性。如需解决**数据和模型双重异质性**问题的算法和基准测试平台,请参考我们的扩展项目 **[异构联邦学习 (HtFLlib)](https://github.com/TsingZ0/HtFLlib)**。
- 为满足多样化的用户需求,项目可能会频繁更新默认设置和场景创建代码,从而影响实验结果。
- 当出现错误时,[已关闭的问题](https://github.com/TsingZ0/PFLlib/issues?q=is%3Aissue+is%3Aclosed)可能对您大有帮助。
- 提交拉取请求时,请在评论框中提供充分的 *说明* 和 *示例*。
**数据异质性**现象的根源是用户的特性,这些用户生成非独立同分布(non-IID)和不平衡的数据。在联邦学习场景中存在数据异质性的情况下,已提出了大量方法来解决这一难题。相比之下,个性化联邦学习(pFL)可以利用统计上异质的数据为每个用户学习个性化模型。
## 包含代码的算法(持续更新)
***基本 tFL***
- **FedAvg** — [Communication-Efficient Learning of Deep Networks from Decentralized Data](http://proceedings.mlr.press/v54/mcmahan17a.html) *AISTATS 2017*
***基于更新校正的 tFL***
- **SCAFFOLD** - [SCAFFOLD: Stochastic Controlled Averaging for Federated Learning](http://proceedings.mlr.press/v119/karimireddy20a.html) *ICML 2020*
***基于正则化的 tFL***
- **FedProx** — [Federated Optimization in Heterogeneous Networks](https://arxiv.org/abs/1812.06127) *MLsys 2020*
- **FedDyn** — [Federated Learning Based on Dynamic Regularization](https://openreview.net/forum?id=B7v4QMR6Z9w) *ICLR 2021*
***基于模型拆分的 tFL***
- **MOON** — [Model-Contrastive Federated Learning](https://openaccess.thecvf.com/content/CVPR2021/html/Li_Model-Contrastive_Federated_Learning_CVPR_2021_paper.html) *CVPR 2021*
- **FedLC** — [Federated Learning With Label Distribution Skew via Logits Calibration](https://proceedings.mlr.press/v162/zhang22p.html) *ICML 2022*
***基于知识蒸馏的 tFL***
- **FedGen** — [Data-Free Knowledge Distillation for Heterogeneous Federated Learning](http://proceedings.mlr.press/v139/zhu21b.html) *ICML 2021*
- **FedNTD** — [Preservation of the Global Knowledge by Not-True Distillation in Federated Learning](https://proceedings.neurips.cc/paper_files/paper/2022/hash/fadec8f2e65f181d777507d1df69b92f-Abstract-Conference.html) *NeurIPS 2022*
***基于启发式搜索的 tFL***
- **FedCross** - [FedCross: Towards Accurate Federated Learning via Multi-Model Cross-Aggregation](https://www.computer.org/csdl/proceedings-article/icde/2024/171500c137/1YOuaPcHF3q) *ICDE 2024*
***基于元学习的 pFL***
- **Per-FedAvg** — [Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach](https://proceedings.neurips.cc/paper/2020/hash/24389bfe4fe2eba8bf9aa9203a44cdad-Abstract.html) *NeurIPS 2020*
***基于正则化的 pFL***
- **pFedMe** — [Personalized Federated Learning with Moreau Envelopes](https://papers.nips.cc/paper/2020/hash/f4f1f13c8289ac1b1ee0ff176b56fc60-Abstract.html) *NeurIPS 2020*
- **Ditto** — [Ditto: Fair and robust federated learning through personalization](https://proceedings.mlr.press/v139/li21h.html) *ICML 2021*
***基于个性化聚合的 pFL***
- **APFL** — [Adaptive Personalized Federated Learning](https://arxiv.org/abs/2003.13461) *2020*
- **FedFomo** — [Personalized Federated Learning with First Order Model Optimization](https://openreview.net/forum?id=ehJqJQk9cw) *ICLR 2021*
- **FedAMP** — [Personalized Cross-Silo Federated Learning on non-IID Data](https://ojs.aaai.org/index.php/AAAI/article/view/16960) *AAAI 2021*
- **FedPHP** — [FedPHP: Federated Personalization with Inherited Private Models](https://link.springer.com/chapter/10.1007/978-3-030-86486-6_36) *ECML PKDD 2021*
- **APPLE** — [Adapt to Adaptation: Learning Personalization for Cross-Silo Federated Learning](https://www.ijcai.org/proceedings/2022/301) *IJCAI 2022*
- **FedALA** — [FedALA: Adaptive Local Aggregation for Personalized Federated Learning](https://ojs.aaai.org/index.php/AAAI/article/view/26330) *AAAI 2023*
***基于模型拆分的 pFL***
- **FedPer** — [Federated Learning with Personalization Layers](https://arxiv.org/abs/1912.00818) *2019*
- **LG-FedAvg** — [Think Locally, Act Globally: Federated Learning with Local and Global Representations](https://arxiv.org/abs/2001.01523) *2020*
- **FedRep** — [Exploiting Shared Representations for Personalized Federated Learning](http://proceedings.mlr.press/v139/collins21a.html) *ICML 2021*
- **FedRoD** — [On Bridging Generic and Personalized Federated Learning for Image Classification](https://openreview.net/forum?id=I1hQbx10Kxn) *ICLR 2022*
- **FedBABU** — [Fedbabu: Towards enhanced representation for federated image classification](https://openreview.net/forum?id=HuaYQfggn5u) *ICLR 2022*
- **FedGC** — [Federated Learning for Face Recognition with Gradient Correction](https://ojs.aaai.org/index.php/AAAI/article/view/20095/19854) *AAAI 2022*
- **FedCP** — [FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy](https://arxiv.org/pdf/2307.01217v2.pdf) *KDD 2023*
- **GPFL** — [GPFL: Simultaneously Learning Generic and Personalized Feature Information for Personalized Federated Learning](https://arxiv.org/pdf/2308.10279v3.pdf) *ICCV 2023*
- **FedGH** — [FedGH: Heterogeneous Federated Learning with Generalized Global Header](https://dl.acm.org/doi/10.1145/3581783.3611781) *ACM MM 2023*
- **FedDBE** — [Eliminating Domain Bias for Federated Learning in Representation Space](https://openreview.net/forum?id=nO5i1XdUS0) *NeurIPS 2023*
- **FedCAC** — [Bold but Cautious: Unlocking the Potential of Personalized Federated Learning through Cautiously Aggressive Collaboration](https://arxiv.org/abs/2309.11103) *ICCV 2023*
- **PFL-DA** — [Personalized Federated Learning via Domain Adaptation with an Application to Distributed 3D Printing](https://www.tandfonline.com/doi/full/10.1080/00401706.2022.2157882) *Technometrics 2023*
- **FedAS** — [FedAS: Bridging Inconsistency in Personalized Federated Learning](https://openaccess.thecvf.com/content/CVPR2024/papers/Yang_FedAS_Bridging_Inconsistency_in_Personalized_Federated_Learning_CVPR_2024_paper.pdf) *CVPR 2024*
***基于知识蒸馏的 pFL(更多算法在 [HtFLlib](https://github.com/TsingZ0/HtFLlib) 中)***
- **FD (FedDistill)** — [Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data](https://arxiv.org/pdf/1811.11479.pdf) *2018*
- **FML** — [Federated Mutual Learning](https://arxiv.org/abs/2006.16765) *2020*
- **FedKD** — [Communication-efficient federated learning via knowledge distillation](https://www.nature.com/articles/s41467-022-29763-x) *Nature Communications 2022*
- **FedProto** — [FedProto: Federated Prototype Learning across Heterogeneous Clients](https://ojs.aaai.org/index.php/AAAI/article/view/20819) *AAAI 2022*
- **FedPCL (w/o pre-trained models)** — [Federated learning from pre-trained models: A contrastive learning approach](https://proceedings.neurips.cc/paper_files/paper/2022/file/7aa320d2b4b8f6400b18f6f77b6c1535-Paper-Conference.pdf) *NeurIPS 2022*
- **FedPAC** — [Personalized Federated Learning with Feature Alignment and Classifier Collaboration](https://openreview.net/pdf?id=SXZr8aDKia) *ICLR 2023*
***其他 pFL***
- **FedMTL (not MOCHA)** — [Federated multi-task learning](https://papers.nips.cc/paper/2017/hash/6211080fa89981f66b1a0c9d55c61d0f-Abstract.html) *NeurIPS 2017*
- **FedBN** — [FedBN: Federated Learning on non-IID Features via Local Batch Normalization](https://openreview.net/forum?id=6YEQUn0QICG) *ICLR 2021*
## 数据集与场景(持续更新)
### ***标签倾斜*** 场景
对于***标签倾斜***场景,我们引入了 **16** 个著名数据集:
- **MNIST**
- **EMNIST**
- **FEMNIST**
- **Fashion-MNIST**
- **Cifar10**
- **Cifar100**
- **AG News**
- **Sogou News**
- **Tiny-ImageNet**
- **Country211**
- **Flowers102**
- **GTSRB**
- **Shakespeare**
- **Stanford Cars**
- **COVIDx**
- **kvasir**
这些数据集可以轻松地划分为 **IID** 和 **non-IID** 版本。在 **non-IID** 场景中,我们区分两种类型的分布:
此外,我们提供一个 `balance` 选项,其中数据量在所有客户端间均匀分布。
### ***特征偏移*** 场景
对于***特征偏移***场景,我们使用 **3** 个在领域自适应中广泛使用的数据集:
- **Amazon Review**(原始数据可从[此链接](https://drive.google.com/file/d/1QbXFENNyqor1IlCpRRFtOluI2_hMEd1W/view?usp=sharing)获取)
- **Digit5**(原始数据[此处](https://drive.google.com/file/d/1sO2PisChNPVT0CnOvIgGJkxdEosCwMUb/view)可得)
- **DomainNet**
### ***真实世界*** 场景
对于***真实世界***场景,我们引入了 **5** 个自然分离的数据集:
- **Camelyon17**(5 家医院,2 个标签)
- **iWildCam**(194 个相机陷阱,158 个标签)
- **Omniglot**(20 个客户端,50 个标签)
- **HAR (Human Activity Recognition)**(30 个客户端,6 个标签)
- **PAMAP2**(9 个客户端,12 个标签)
有关 **IoT** 中数据集和联邦学习算法的更多详情,请参考 [FL-IoT](https://github.com/TsingZ0/FL-IoT)。
### **MNIST** 在***标签倾斜***场景中的示例
```
cd ./dataset
# 请在 dataset\utils\dataset_utils.py 中修改 train_ratio 和 alpha
python generate_MNIST.py iid - - # for iid and unbalanced scenario
python generate_MNIST.py iid balance - # for iid and balanced scenario
python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy
```
运行 `python generate_MNIST.py noniid - dir` 的命令行输出
```
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
--------------------------------------------------
```
## 模型
- 适用于 MNIST 和 Fashion-MNIST
1. Mclr_Logistic(1\*28\*28) # 凸函数
2. LeNet()
3. DNN(1\*28\*28, 100)
- 适用于 Cifar10、Cifar100 和 Tiny-ImageNet
1. Mclr_Logistic(3\*32\*32) # 凸函数
2. FedAvgCNN()
3. DNN(3\*32\*32, 100)
4. ResNet18, AlexNet, MobileNet, GoogleNet 等。
- 适用于 AG_News 和 Sogou_News
- LSTM()
- [Bag of Tricks for Efficient Text Classification](https://aclanthology.org/E17-2068/) 中的 fastText()
- [Convolutional Neural Networks for Sentence Classification](https://aclanthology.org/D14-1181/) 中的 TextCNN()
- [Attention is all you need](https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html) 中的 TransformerModel()
- 适用于 AmazonReview
- [Curriculum manager for source selection in multi-source domain adaptation](https://link.springer.com/chapter/10.1007/978-3-030-58568-6_36) 中的 AmazonMLP()
- 适用于 Omniglot
- FedAvgCNN()
- 适用于 HAR 和 PAMAP
- [Convolutional neural networks for human activity recognition using mobile sensors](https://eudl.eu/pdf/10.4108/icst.mobicase.2014.257786) 中的 HARCNN()
## 环境
安装 [CUDA](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html)。
安装 [conda 最新版](https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh) 并激活 conda。
其他配置请参考 `prepare.sh` 脚本。
```
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version
```
## 如何开始模拟(以 FedAvg 为例)
- 使用 [git](https://git-scm.com/) 将[此项目](https://github.com/TsingZ0/PFLlib)下载到合适的位置。
git clone https://github.com/TsingZ0/PFLlib.git
- 创建合适的环境(参见[环境](#environments))。
- 构建评估场景(参见[数据集与场景(持续更新)](#datasets-and-scenarios-updating))。
- 运行评估:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # 使用 MNIST 数据集、FedAvg 算法和 4 层 CNN 模型
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0,1,2,3 # 在多个 GPU 上运行
**注意**:在将任何算法用于新机器之前,最好先调整算法相关的超参数。
## 易于扩展
该库设计为易于扩展新算法和数据集。以下是添加方法:
- **新数据集**:要添加新数据集,只需在 `./dataset` 中创建一个 `generate_DATA.py` 文件,然后编写下载代码并使用 [utils](https://github.com/TsingZ0/PFLlib/tree/master/dataset/utils),如 `./dataset/generate_MNIST.py` 所示(可将其视为模板):
# `generate_DATA.py`
导入必要的包
从 utils 导入必要的处理函数
def generate_dataset(...):
# 像平常一样下载数据集
# 像平常一样预处理数据集
X, y, statistic = separate_data((dataset_content, dataset_label), ...)
train_data, test_data = split_data(X, y)
save_file(config_path, train_path, test_path, train_data, test_data, statistic, ...)
# 调用 generate_dataset 函数
- **新算法**:要添加新算法,请扩展基类 **Server** 和 **Client**,它们分别定义在 `./system/flcore/servers/serverbase.py` 和 `./system/flcore/clients/clientbase.py` 中。
- Server
# serverNAME.py
导入必要的包
从 flcore.clients.clientNAME 导入 clientNAME
从 flcore.servers.serverbase 导入 Server
class NAME(Server):
def __init__(self, args, times):
super().__init__(args, times)
# 选择慢速客户端
self.set_slow_clients()
self.set_clients(clientAVG)
def train(self):
# 您的算法的服务器调度代码
- Client
# clientNAME.py
导入必要的包
从 flcore.clients.clientbase 导入 Client
class clientNAME(Client):
def __init__(self, args, id, train_samples, test_samples, **kwargs):
super().__init__(args, id, train_samples, test_samples, **kwargs)
# 添加特定的初始化
def train(self):
# 您的算法的客户端训练代码
- **新模型**:要添加新模型,只需将其包含在 `./system/flcore/trainmodel/models.py` 中。
- **新优化器**:如果您需要新的训练优化器,请将其添加到 `./system/flcore/optimizers/fedoptimizer.py`。
- **新基准测试平台或库**:我们的框架是灵活的,允许用户为特定应用构建自定义平台或库,例如 [FL-IoT](https://github.com/TsingZ0/FL-IoT) 和 [HtFLlib](https://github.com/TsingZ0/HtFLlib)。
## 隐私评估
您可以使用以下隐私评估方法来评估 PFLlib 中 tFL/pFL 算法的隐私保护能力。请参考 `./system/flcore/servers/serveravg.py` 中的示例。请注意,这些评估中的大多数在原始论文中通常并未被考虑。_我们鼓励您添加更多的攻击和指标用于隐私评估。_
### 当前支持的攻击:
- [DLG (Deep Leakage from Gradients)](https://www.ijcai.org/proceedings/2022/0324.pdf) 攻击
### 当前支持的指标:
- **PSNR (Peak Signal-to-Noise Ratio)**:用于图像评估的客观指标,定义为 RGB 图像波动最大值的平方与两幅图像之间均方误差(MSE)之比的对数。PSNR 分数越低,表示隐私保护能力越好。
## 实验结果
如果您对上述算法的**实验结果(例如准确率)**感兴趣,可以在我们已发表的联邦学习论文中找到结果,这些论文也使用了此库。这些论文包括:
- [FedALA](https://github.com/TsingZ0/FedALA)
- [FedCP](https://github.com/TsingZ0/FedCP)
- [GPFL](https://github.com/TsingZ0/GPFL)
- [DBE](https://github.com/TsingZ0/DBE)
以下是相关论文供您参考:
```
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}
```
PFLlib:个性化联邦学习库与基准测试平台
👏 **[官方网站](http://www.pfllib.com)** 和 **[排行榜](http://www.pfllib.com/benchmark.html)** 已上线!我们的方法——[FedCP](https://github.com/TsingZ0/FedCP)、[GPFL](https://github.com/TsingZ0/GPFL) 和 [FedDBE](https://github.com/TsingZ0/DBE)——处于领先地位。值得注意的是,**FedDBE** 在不同数据异质性水平下都展现出稳健的性能。
[](https://www.jmlr.org/papers/v26/23-1634.html)
[](https://arxiv.org/abs/2312.04992)


图 1:FedAvg 示例。您可以使用 `generate_DATA.py` 创建一个场景,并使用 `main.py`、`clientNAME.py` 和 `serverNAME.py` 运行一个算法。对于新算法,您只需在 `clientNAME.py` 和 `serverNAME.py` 中添加新功能。
🎯 **如果您觉得我们的仓库有用,请引用相关论文:**
```
@article{zhang2025pfllib,
title={PFLlib: A Beginner-Friendly and Comprehensive Personalized Federated Learning Library and Benchmark},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={Journal of Machine Learning Research},
volume={26},
number={50},
pages={1--10},
year={2025}
}
@inproceedings{Zhang2025htfllib,
author={Zhang, Jianqing and Wu, Xinghao and Zhou, Yanbing and Sun, Xiaoting and Cai, Qiqi and Liu, Yang and Hua, Yang and Zheng, Zhenzhe and Cao, Jian and Yang, Qiang},
title = {HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark},
year = {2025},
booktitle = {Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
```
### 主要特性
- **39 种传统联邦学习([tFL](#traditional-fl-tfl))和个性化联邦学习([pFL](#personalized-fl-pfl))算法,3 种场景,24 个数据集。**
- 实际设备部署:[HtFL-OnDevice](https://github.com/TsingZ0//HtFL-OnDevice)。
- 部分 **实验结果** 可在其[论文](https://arxiv.org/abs/2312.04992)和[此处](#experimental-results)获取。
- 参考[示例](#how-to-start-simulating-examples-for-fedavg)学习如何使用。
- 参考[易于扩展](#easy-to-extend)学习如何添加新数据或算法。
- 该基准测试平台可以在 **单张 NVIDIA GeForce RTX 3090 GPU 卡** 上,仅使用 **5.08GB GPU 内存**,模拟 **500 个客户端** 使用 4 层 CNN 在 Cifar100 上的场景。
- 我们提供[隐私评估](#privacy-evaluation)和[系统化研究支持](#systematical-research-support)。
- 您现在可以通过在 `./system/main.py` 中设置 `args.num_new_clients` 来在部分客户端上训练并在新客户端上评估性能。请注意,并非所有 tFL/pFL 算法都支持此特性。
- PFLlib 主要关注数据(统计)异质性。如需解决**数据和模型双重异质性**问题的算法和基准测试平台,请参考我们的扩展项目 **[异构联邦学习 (HtFLlib)](https://github.com/TsingZ0/HtFLlib)**。
- 为满足多样化的用户需求,项目可能会频繁更新默认设置和场景创建代码,从而影响实验结果。
- 当出现错误时,[已关闭的问题](https://github.com/TsingZ0/PFLlib/issues?q=is%3Aissue+is%3Aclosed)可能对您大有帮助。
- 提交拉取请求时,请在评论框中提供充分的 *说明* 和 *示例*。
**数据异质性**现象的根源是用户的特性,这些用户生成非独立同分布(non-IID)和不平衡的数据。在联邦学习场景中存在数据异质性的情况下,已提出了大量方法来解决这一难题。相比之下,个性化联邦学习(pFL)可以利用统计上异质的数据为每个用户学习个性化模型。
## 包含代码的算法(持续更新)
***基本 tFL***
- **FedAvg** — [Communication-Efficient Learning of Deep Networks from Decentralized Data](http://proceedings.mlr.press/v54/mcmahan17a.html) *AISTATS 2017*
***基于更新校正的 tFL***
- **SCAFFOLD** - [SCAFFOLD: Stochastic Controlled Averaging for Federated Learning](http://proceedings.mlr.press/v119/karimireddy20a.html) *ICML 2020*
***基于正则化的 tFL***
- **FedProx** — [Federated Optimization in Heterogeneous Networks](https://arxiv.org/abs/1812.06127) *MLsys 2020*
- **FedDyn** — [Federated Learning Based on Dynamic Regularization](https://openreview.net/forum?id=B7v4QMR6Z9w) *ICLR 2021*
***基于模型拆分的 tFL***
- **MOON** — [Model-Contrastive Federated Learning](https://openaccess.thecvf.com/content/CVPR2021/html/Li_Model-Contrastive_Federated_Learning_CVPR_2021_paper.html) *CVPR 2021*
- **FedLC** — [Federated Learning With Label Distribution Skew via Logits Calibration](https://proceedings.mlr.press/v162/zhang22p.html) *ICML 2022*
***基于知识蒸馏的 tFL***
- **FedGen** — [Data-Free Knowledge Distillation for Heterogeneous Federated Learning](http://proceedings.mlr.press/v139/zhu21b.html) *ICML 2021*
- **FedNTD** — [Preservation of the Global Knowledge by Not-True Distillation in Federated Learning](https://proceedings.neurips.cc/paper_files/paper/2022/hash/fadec8f2e65f181d777507d1df69b92f-Abstract-Conference.html) *NeurIPS 2022*
***基于启发式搜索的 tFL***
- **FedCross** - [FedCross: Towards Accurate Federated Learning via Multi-Model Cross-Aggregation](https://www.computer.org/csdl/proceedings-article/icde/2024/171500c137/1YOuaPcHF3q) *ICDE 2024*
***基于元学习的 pFL***
- **Per-FedAvg** — [Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach](https://proceedings.neurips.cc/paper/2020/hash/24389bfe4fe2eba8bf9aa9203a44cdad-Abstract.html) *NeurIPS 2020*
***基于正则化的 pFL***
- **pFedMe** — [Personalized Federated Learning with Moreau Envelopes](https://papers.nips.cc/paper/2020/hash/f4f1f13c8289ac1b1ee0ff176b56fc60-Abstract.html) *NeurIPS 2020*
- **Ditto** — [Ditto: Fair and robust federated learning through personalization](https://proceedings.mlr.press/v139/li21h.html) *ICML 2021*
***基于个性化聚合的 pFL***
- **APFL** — [Adaptive Personalized Federated Learning](https://arxiv.org/abs/2003.13461) *2020*
- **FedFomo** — [Personalized Federated Learning with First Order Model Optimization](https://openreview.net/forum?id=ehJqJQk9cw) *ICLR 2021*
- **FedAMP** — [Personalized Cross-Silo Federated Learning on non-IID Data](https://ojs.aaai.org/index.php/AAAI/article/view/16960) *AAAI 2021*
- **FedPHP** — [FedPHP: Federated Personalization with Inherited Private Models](https://link.springer.com/chapter/10.1007/978-3-030-86486-6_36) *ECML PKDD 2021*
- **APPLE** — [Adapt to Adaptation: Learning Personalization for Cross-Silo Federated Learning](https://www.ijcai.org/proceedings/2022/301) *IJCAI 2022*
- **FedALA** — [FedALA: Adaptive Local Aggregation for Personalized Federated Learning](https://ojs.aaai.org/index.php/AAAI/article/view/26330) *AAAI 2023*
***基于模型拆分的 pFL***
- **FedPer** — [Federated Learning with Personalization Layers](https://arxiv.org/abs/1912.00818) *2019*
- **LG-FedAvg** — [Think Locally, Act Globally: Federated Learning with Local and Global Representations](https://arxiv.org/abs/2001.01523) *2020*
- **FedRep** — [Exploiting Shared Representations for Personalized Federated Learning](http://proceedings.mlr.press/v139/collins21a.html) *ICML 2021*
- **FedRoD** — [On Bridging Generic and Personalized Federated Learning for Image Classification](https://openreview.net/forum?id=I1hQbx10Kxn) *ICLR 2022*
- **FedBABU** — [Fedbabu: Towards enhanced representation for federated image classification](https://openreview.net/forum?id=HuaYQfggn5u) *ICLR 2022*
- **FedGC** — [Federated Learning for Face Recognition with Gradient Correction](https://ojs.aaai.org/index.php/AAAI/article/view/20095/19854) *AAAI 2022*
- **FedCP** — [FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy](https://arxiv.org/pdf/2307.01217v2.pdf) *KDD 2023*
- **GPFL** — [GPFL: Simultaneously Learning Generic and Personalized Feature Information for Personalized Federated Learning](https://arxiv.org/pdf/2308.10279v3.pdf) *ICCV 2023*
- **FedGH** — [FedGH: Heterogeneous Federated Learning with Generalized Global Header](https://dl.acm.org/doi/10.1145/3581783.3611781) *ACM MM 2023*
- **FedDBE** — [Eliminating Domain Bias for Federated Learning in Representation Space](https://openreview.net/forum?id=nO5i1XdUS0) *NeurIPS 2023*
- **FedCAC** — [Bold but Cautious: Unlocking the Potential of Personalized Federated Learning through Cautiously Aggressive Collaboration](https://arxiv.org/abs/2309.11103) *ICCV 2023*
- **PFL-DA** — [Personalized Federated Learning via Domain Adaptation with an Application to Distributed 3D Printing](https://www.tandfonline.com/doi/full/10.1080/00401706.2022.2157882) *Technometrics 2023*
- **FedAS** — [FedAS: Bridging Inconsistency in Personalized Federated Learning](https://openaccess.thecvf.com/content/CVPR2024/papers/Yang_FedAS_Bridging_Inconsistency_in_Personalized_Federated_Learning_CVPR_2024_paper.pdf) *CVPR 2024*
***基于知识蒸馏的 pFL(更多算法在 [HtFLlib](https://github.com/TsingZ0/HtFLlib) 中)***
- **FD (FedDistill)** — [Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data](https://arxiv.org/pdf/1811.11479.pdf) *2018*
- **FML** — [Federated Mutual Learning](https://arxiv.org/abs/2006.16765) *2020*
- **FedKD** — [Communication-efficient federated learning via knowledge distillation](https://www.nature.com/articles/s41467-022-29763-x) *Nature Communications 2022*
- **FedProto** — [FedProto: Federated Prototype Learning across Heterogeneous Clients](https://ojs.aaai.org/index.php/AAAI/article/view/20819) *AAAI 2022*
- **FedPCL (w/o pre-trained models)** — [Federated learning from pre-trained models: A contrastive learning approach](https://proceedings.neurips.cc/paper_files/paper/2022/file/7aa320d2b4b8f6400b18f6f77b6c1535-Paper-Conference.pdf) *NeurIPS 2022*
- **FedPAC** — [Personalized Federated Learning with Feature Alignment and Classifier Collaboration](https://openreview.net/pdf?id=SXZr8aDKia) *ICLR 2023*
***其他 pFL***
- **FedMTL (not MOCHA)** — [Federated multi-task learning](https://papers.nips.cc/paper/2017/hash/6211080fa89981f66b1a0c9d55c61d0f-Abstract.html) *NeurIPS 2017*
- **FedBN** — [FedBN: Federated Learning on non-IID Features via Local Batch Normalization](https://openreview.net/forum?id=6YEQUn0QICG) *ICLR 2021*
## 数据集与场景(持续更新)
### ***标签倾斜*** 场景
对于***标签倾斜***场景,我们引入了 **16** 个著名数据集:
- **MNIST**
- **EMNIST**
- **FEMNIST**
- **Fashion-MNIST**
- **Cifar10**
- **Cifar100**
- **AG News**
- **Sogou News**
- **Tiny-ImageNet**
- **Country211**
- **Flowers102**
- **GTSRB**
- **Shakespeare**
- **Stanford Cars**
- **COVIDx**
- **kvasir**
这些数据集可以轻松地划分为 **IID** 和 **non-IID** 版本。在 **non-IID** 场景中,我们区分两种类型的分布:
此外,我们提供一个 `balance` 选项,其中数据量在所有客户端间均匀分布。
### ***特征偏移*** 场景
对于***特征偏移***场景,我们使用 **3** 个在领域自适应中广泛使用的数据集:
- **Amazon Review**(原始数据可从[此链接](https://drive.google.com/file/d/1QbXFENNyqor1IlCpRRFtOluI2_hMEd1W/view?usp=sharing)获取)
- **Digit5**(原始数据[此处](https://drive.google.com/file/d/1sO2PisChNPVT0CnOvIgGJkxdEosCwMUb/view)可得)
- **DomainNet**
### ***真实世界*** 场景
对于***真实世界***场景,我们引入了 **5** 个自然分离的数据集:
- **Camelyon17**(5 家医院,2 个标签)
- **iWildCam**(194 个相机陷阱,158 个标签)
- **Omniglot**(20 个客户端,50 个标签)
- **HAR (Human Activity Recognition)**(30 个客户端,6 个标签)
- **PAMAP2**(9 个客户端,12 个标签)
有关 **IoT** 中数据集和联邦学习算法的更多详情,请参考 [FL-IoT](https://github.com/TsingZ0/FL-IoT)。
### **MNIST** 在***标签倾斜***场景中的示例
```
cd ./dataset
# 请在 dataset\utils\dataset_utils.py 中修改 train_ratio 和 alpha
python generate_MNIST.py iid - - # for iid and unbalanced scenario
python generate_MNIST.py iid balance - # for iid and balanced scenario
python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy
```
运行 `python generate_MNIST.py noniid - dir` 的命令行输出
```
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
--------------------------------------------------
```
## 模型
- 适用于 MNIST 和 Fashion-MNIST
1. Mclr_Logistic(1\*28\*28) # 凸函数
2. LeNet()
3. DNN(1\*28\*28, 100)
- 适用于 Cifar10、Cifar100 和 Tiny-ImageNet
1. Mclr_Logistic(3\*32\*32) # 凸函数
2. FedAvgCNN()
3. DNN(3\*32\*32, 100)
4. ResNet18, AlexNet, MobileNet, GoogleNet 等。
- 适用于 AG_News 和 Sogou_News
- LSTM()
- [Bag of Tricks for Efficient Text Classification](https://aclanthology.org/E17-2068/) 中的 fastText()
- [Convolutional Neural Networks for Sentence Classification](https://aclanthology.org/D14-1181/) 中的 TextCNN()
- [Attention is all you need](https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html) 中的 TransformerModel()
- 适用于 AmazonReview
- [Curriculum manager for source selection in multi-source domain adaptation](https://link.springer.com/chapter/10.1007/978-3-030-58568-6_36) 中的 AmazonMLP()
- 适用于 Omniglot
- FedAvgCNN()
- 适用于 HAR 和 PAMAP
- [Convolutional neural networks for human activity recognition using mobile sensors](https://eudl.eu/pdf/10.4108/icst.mobicase.2014.257786) 中的 HARCNN()
## 环境
安装 [CUDA](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html)。
安装 [conda 最新版](https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh) 并激活 conda。
其他配置请参考 `prepare.sh` 脚本。
```
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version
```
## 如何开始模拟(以 FedAvg 为例)
- 使用 [git](https://git-scm.com/) 将[此项目](https://github.com/TsingZ0/PFLlib)下载到合适的位置。
git clone https://github.com/TsingZ0/PFLlib.git
- 创建合适的环境(参见[环境](#environments))。
- 构建评估场景(参见[数据集与场景(持续更新)](#datasets-and-scenarios-updating))。
- 运行评估:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # 使用 MNIST 数据集、FedAvg 算法和 4 层 CNN 模型
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0,1,2,3 # 在多个 GPU 上运行
**注意**:在将任何算法用于新机器之前,最好先调整算法相关的超参数。
## 易于扩展
该库设计为易于扩展新算法和数据集。以下是添加方法:
- **新数据集**:要添加新数据集,只需在 `./dataset` 中创建一个 `generate_DATA.py` 文件,然后编写下载代码并使用 [utils](https://github.com/TsingZ0/PFLlib/tree/master/dataset/utils),如 `./dataset/generate_MNIST.py` 所示(可将其视为模板):
# `generate_DATA.py`
导入必要的包
从 utils 导入必要的处理函数
def generate_dataset(...):
# 像平常一样下载数据集
# 像平常一样预处理数据集
X, y, statistic = separate_data((dataset_content, dataset_label), ...)
train_data, test_data = split_data(X, y)
save_file(config_path, train_path, test_path, train_data, test_data, statistic, ...)
# 调用 generate_dataset 函数
- **新算法**:要添加新算法,请扩展基类 **Server** 和 **Client**,它们分别定义在 `./system/flcore/servers/serverbase.py` 和 `./system/flcore/clients/clientbase.py` 中。
- Server
# serverNAME.py
导入必要的包
从 flcore.clients.clientNAME 导入 clientNAME
从 flcore.servers.serverbase 导入 Server
class NAME(Server):
def __init__(self, args, times):
super().__init__(args, times)
# 选择慢速客户端
self.set_slow_clients()
self.set_clients(clientAVG)
def train(self):
# 您的算法的服务器调度代码
- Client
# clientNAME.py
导入必要的包
从 flcore.clients.clientbase 导入 Client
class clientNAME(Client):
def __init__(self, args, id, train_samples, test_samples, **kwargs):
super().__init__(args, id, train_samples, test_samples, **kwargs)
# 添加特定的初始化
def train(self):
# 您的算法的客户端训练代码
- **新模型**:要添加新模型,只需将其包含在 `./system/flcore/trainmodel/models.py` 中。
- **新优化器**:如果您需要新的训练优化器,请将其添加到 `./system/flcore/optimizers/fedoptimizer.py`。
- **新基准测试平台或库**:我们的框架是灵活的,允许用户为特定应用构建自定义平台或库,例如 [FL-IoT](https://github.com/TsingZ0/FL-IoT) 和 [HtFLlib](https://github.com/TsingZ0/HtFLlib)。
## 隐私评估
您可以使用以下隐私评估方法来评估 PFLlib 中 tFL/pFL 算法的隐私保护能力。请参考 `./system/flcore/servers/serveravg.py` 中的示例。请注意,这些评估中的大多数在原始论文中通常并未被考虑。_我们鼓励您添加更多的攻击和指标用于隐私评估。_
### 当前支持的攻击:
- [DLG (Deep Leakage from Gradients)](https://www.ijcai.org/proceedings/2022/0324.pdf) 攻击
### 当前支持的指标:
- **PSNR (Peak Signal-to-Noise Ratio)**:用于图像评估的客观指标,定义为 RGB 图像波动最大值的平方与两幅图像之间均方误差(MSE)之比的对数。PSNR 分数越低,表示隐私保护能力越好。
## 实验结果
如果您对上述算法的**实验结果(例如准确率)**感兴趣,可以在我们已发表的联邦学习论文中找到结果,这些论文也使用了此库。这些论文包括:
- [FedALA](https://github.com/TsingZ0/FedALA)
- [FedCP](https://github.com/TsingZ0/FedCP)
- [GPFL](https://github.com/TsingZ0/GPFL)
- [DBE](https://github.com/TsingZ0/DBE)
以下是相关论文供您参考:
```
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}
```
显示更多
``` Client 3 Size of data: 2541 Labels: [0 4 7 8] Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)] -------------------------------------------------- Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9] Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)] -------------------------------------------------- Client 5 Size of data: 6189 Labels: [1 3 4 8 9] Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)] -------------------------------------------------- Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9] Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)] -------------------------------------------------- Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8] Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)] -------------------------------------------------- Client 8 Size of data: 3600 Labels: [0 1] Samples of labels: [(0, 1), (1, 3599)] -------------------------------------------------- Client 9 Size of data: 4006 Labels: [0 1 2 4 6] Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)] -------------------------------------------------- Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5] Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)] -------------------------------------------------- Client 11 Size of data: 3772 Labels: [2 3 5] Samples of labels: [(2, 159), (3, 3055), (5, 558)] -------------------------------------------------- Client 12 Size of data: 3613 Labels: [0 1 2 5] Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)] -------------------------------------------------- Client 13 Size of data: 2134 Labels: [1 2 4 5 7] Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)] -------------------------------------------------- Client 14 Size of data: 5730 Labels: [5 7] Samples of labels: [(5, 2719), (7, 3011)] -------------------------------------------------- Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8] Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)] -------------------------------------------------- Client 16 Size of data: 3628 Labels: [0] Samples of labels: [(0, 3628)] -------------------------------------------------- Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8] Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)] -------------------------------------------------- Client 18 Size of data: 5266 Labels: [0 5 6] Samples of labels: [(0, 998), (5, 8), (6, 4260)] -------------------------------------------------- Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9] Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)] -------------------------------------------------- Total number of samples: 70000 The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577] The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526] Saving to disk. Finish generating dataset. ```标签:Apex, Python, 个性化联邦学习, 凭据扫描, 分布式计算, 开源库, 异常处理, 搜索引擎爬虫, 教育工具, 数据异质性, 无后门, 机器学习, 深度学习, 算法实现, 网络安全, 联邦学习, 逆向工具, 隐私保护