microsoft/CodeXGLUE
GitHub: microsoft/CodeXGLUE
微软发布的代码智能基准数据集与评测平台,涵盖代码理解与生成等多种任务。
Stars: 1826 | Forks: 392
# 简介
根据 [Evans Data Corporation](https://evansdata.com/press/viewRelease.php?pressID=278) 的数据,2019 年全球有 2390 万专业开发者,预计到 2024 年这一数字将达到 2870 万。随着开发者群体的不断增长,代码智能——旨在利用 AI 帮助软件开发者提高开发流程的生产力——在软件工程和人工智能社区中变得越来越重要。
当开发者想要寻找由他人编写的具有相同意图的代码时,[代码搜索](https://arxiv.org/abs/1909.09436) 系统可以在给定自然语言查询的情况下,帮助自动检索语义相关的代码。当开发者不确定接下来该写什么时,[代码补全](https://arxiv.org/abs/1912.00742) 系统可以根据当前的编辑上下文,自动补全后续的 token。当开发者想要用 Java 代码实现某些现有 Python 代码的相同功能时,[代码到代码翻译](https://arxiv.org/abs/2006.03511) 系统可以帮助将一种编程语言翻译成另一种编程语言。
因此,代码智能在微软“予力开发者”的使命中扮演着至关重要的角色。正如微软首席执行官萨提亚·纳德拉在微软 [Build 2020](https://mybuild.microsoft.com/sessions/23912de2-1531-4684-b85a-d57ac30af09e) 大会上所强调的那样,开发者的角色比以往任何时候都更加重要。GitHub 正日益成为源代码的默认归宿,而 Visual Studio Code 是最受欢迎的代码编辑器。微软为开发者提供了最完整的工具链,集 GitHub、Visual Studio 和 Microsoft Azure 之大成,帮助开发者从创意到代码,再从代码到云端。
近年来,包括神经网络在内的统计模型在代码智能任务中的应用激增。最近,受 [BERT](https://arxiv.org/abs/1810.04805) 和 [GPT](https://arxiv.org/abs/1908.09203) 等大型预训练模型在自然语言处理 (NLP) 领域取得巨大成功的启发,从大型编程语言数据中学习到的预训练模型应运而生。这些模型,包括 [IntelliCode](https://arxiv.org/pdf/2005.08025.pdf) 和 [CodeBERT](https://arxiv.org/pdf/2002.08155.pdf),在代码理解和生成问题上获得了进一步的提升。然而,代码智能领域缺乏一个涵盖广泛任务的基准测试套件。我们已经看到,多样化的基准数据集对于应用 AI 研究领域的增长具有重要意义,就像计算机视觉领域的 [ImageNet](http://image-net.org/) 和 NLP 领域的 [GLUE](https://gluebenchmark.com/) 一样。
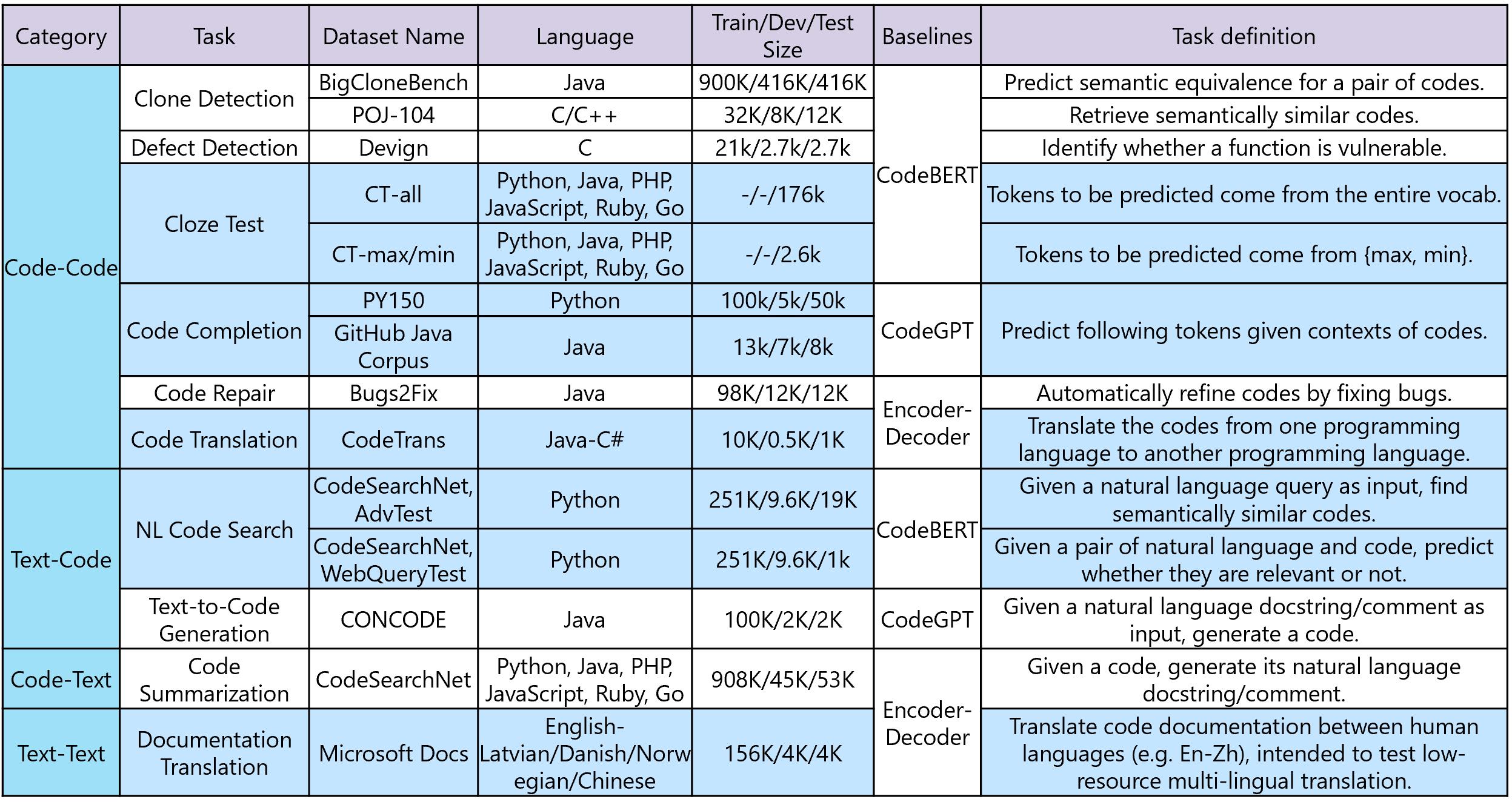
为了解决这个问题,来自微软亚洲研究院、开发者部门和 Bing 的研究人员推出了 CodeXGLUE,这是一个用于代码智能的基准数据集和公开挑战。它包含一系列代码智能任务以及一个用于模型评估和比较的平台。CodeXGLUE 代表 CODE 的通用语言理解评估基准 (General Language Understanding Evaluation benchmark for CODE)。它包含 14 个数据集,涵盖 10 个多样化的代码智能任务,涉及以下场景:
* **[code-code](https://github.com/microsoft/CodeXGLUE/tree/main/Code-Code)** (克隆检测、缺陷检测、完形填空测试、代码补全、代码修复和代码到代码翻译)
* **[text-code](https://github.com/microsoft/CodeXGLUE/tree/main/Text-Code)** (自然语言代码搜索、文本到代码生成)
* **[code-text](https://github.com/microsoft/CodeXGLUE/tree/main/Code-Text/)** (代码摘要)
* **[text-text](https://github.com/microsoft/CodeXGLUE/tree/main/Text-Text)** (文档翻译)
下表给出了 CodeXGLUE 的简要总结,包括任务、数据集、语言、各种状态下的规模、基线系统、提供商以及每个任务的简短定义。蓝色高亮的数据集为全新引入的。
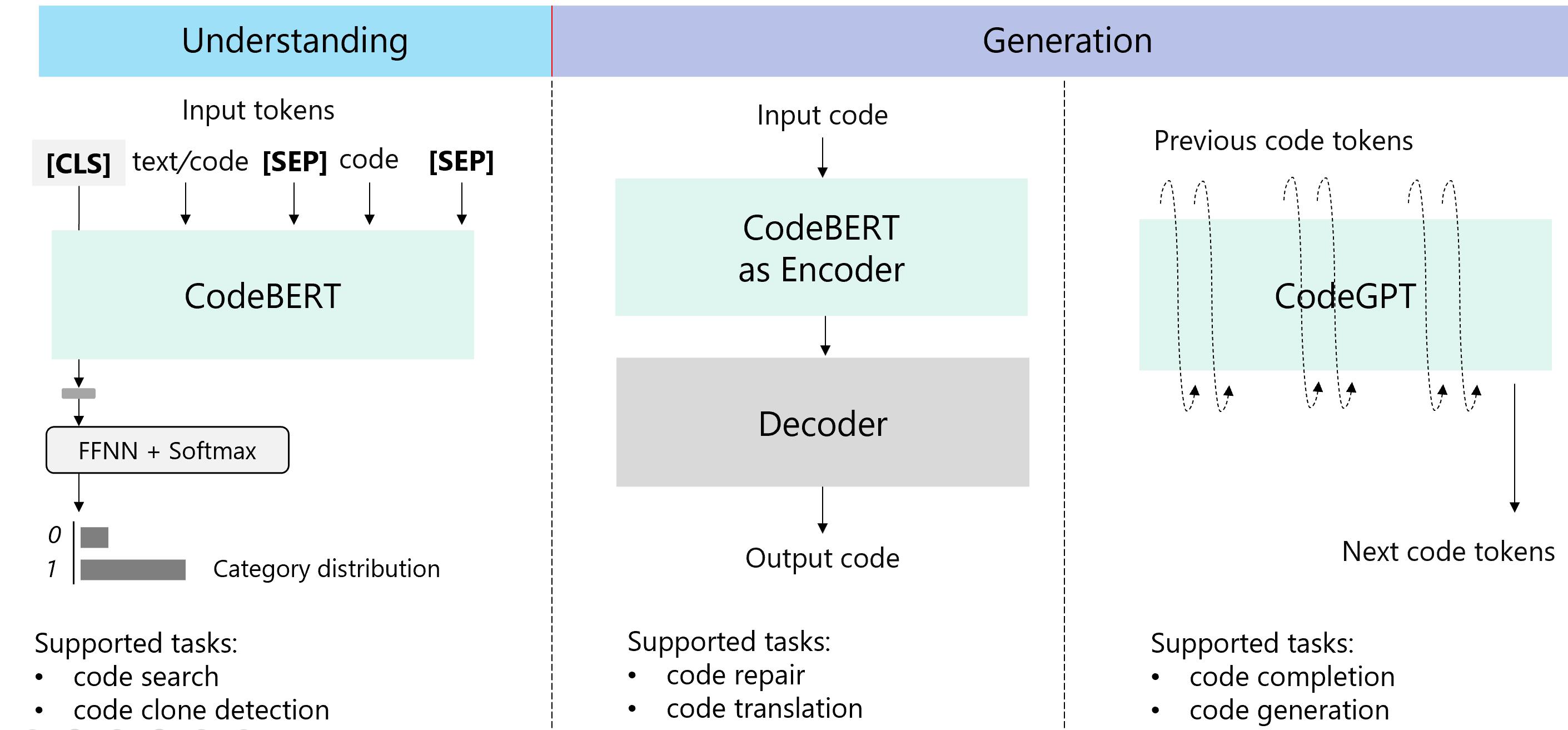
为了方便参与者,我们提供了三个基线模型来支持这些任务,包括一个擅长理解问题的 BERT 风格预训练模型(在本例中为 CodeBERT)。我们还包含了一个 GPT 风格的预训练模型,我们称之为 CodeGPT,以支持补全和生成问题。最后,我们包含了一个支持序列到序列生成问题的 Encoder-Decoder 框架。
我们提供了包含 [CodeBERT](https://github.com/microsoft/CodeBERT)、[CodeGPT](https://huggingface.co/microsoft/CodeGPT-small-java-adaptedGPT2
) 和 Encoder-Decoder 的三条流水线,以方便参与者。
通过 CodeXGLUE,我们致力于支持可应用于各种代码智能问题的模型开发,目标是提高软件开发者的生产力。我们鼓励研究人员参与公开挑战,以推动代码智能的持续进步。展望未来,我们将把 CodeXGLUE 扩展到更多的编程语言和下游任务,同时通过探索新的模型结构、引入新的预训练任务、使用不同类型的数据等方式,继续推进预训练模型的发展。
# 相关链接
[排行榜](https://microsoft.github.io/CodeXGLUE/) | [CodeXGLUE 论文](https://arxiv.org/pdf/2102.04664.pdf) | [从 HuggingFace datasets 访问](https://huggingface.co/datasets?search=code_x_glue)  # 任务与数据集
下面,我们将详细说明每个任务的任务定义以及上表中高亮显示的全新引入的数据集。
1. 克隆检测 (BigCloneBench, POJ-104)。模型的任务是衡量代码之间的语义相似度。包含两个现有数据集。一个用于代码间的二分类,另一个用于在给定代码作为查询的情况下检索语义相似的代码。
2. 缺陷检测。模型的任务是识别一段源代码是否包含可能被用于攻击软件系统的缺陷,例如资源泄漏、释放后使用漏洞和 DoS 攻击。包含一个现有数据集。
3. 完形填空测试。模型的任务是从代码中预测被遮蔽的 token,表述为一个多选分类问题。这两个数据集是新创建的,一个的候选词来自(过滤后的)词表,另一个的候选词为“max”和“min”。
4. 代码补全 (PY150, GitHub Java Corpus)。模型的任务是在给定代码上下文的情况下预测后续的 token。涵盖 token 级别和行级别的补全。token 级别的任务类似于语言建模,我们在此包含了两个有影响力的数据集。行级别数据集是新创建的,用于测试模型自动补全一行代码的能力。
5. 代码翻译。模型的任务是将一种编程语言的代码翻译成另一种编程语言的代码。新创建了一个 Java 和 C# 之间的数据集。
6. 代码搜索 (CodeSearchNet, AdvTest; CodeSearchNet, WebQueryTest)。模型的任务是衡量文本和代码之间的语义相似度。在检索场景中,新创建了一个测试集,其中测试集中的函数名和变量被替换,以测试模型的泛化能力。在文本-代码分类场景中,创建了一个自然语言查询来自 Bing 查询日志的测试集,以便在真实用户查询上进行测试。
7. 代码修复 (Bugs2Fix)。模型的任务是尝试自动改进代码,这些代码可能有错误或很复杂。包含一个现有数据集。
8. 文本到代码生成 (CONCODE)。模型的任务是在给定自然语言描述的情况下生成代码。包含一个现有数据集。
9. 代码摘要。模型的任务是为代码生成自然语言注释。包含现有数据集。
10. 文档翻译。模型的任务是在人类语言之间翻译代码文档。新创建了一个专注于低资源多语言翻译的数据集。
# 提交说明
一旦您构建的模型在开发集上的评估效果符合您的预期,您就可以提交测试结果以获得测试集上的官方评估。为了确保官方测试结果的完整性,我们不会向公众发布测试集的正确答案。要提交您的模型以在测试集上进行官方评估,请执行以下步骤:
1. 生成您在开发集上的预测输出。
2. 运行任务特定 git 仓库中的官方评估方法,并验证您的系统是否按预期运行。
3. 生成您在测试集上的预测输出。
4. 通过发送电子邮件至 `codexglue@microsoft.com` 提交以下信息。
您的电子邮件应包括:
1. 测试集上的预测结果。**[必填]**
2. 开发集上的预测结果。**[推荐]**
3. 个人/团队名称:出现在排行榜上的个人或团队名称。**[必填]**
4. 个人/团队机构:出现在排行榜上的个人或团队所属机构名称。**[可选]**
5. 模型代码:模型的训练代码。**[推荐]**
6. 模型信息:出现在排行榜上的模型/技术名称。**[必填]**
7. 论文信息:如果模型来自已发表的工作,请提供出现在排行榜上的论文名称、引用和 URL。**[可选]**
为了避免“P-hacking”,我们不建议同一小组在短时间内提交过多。
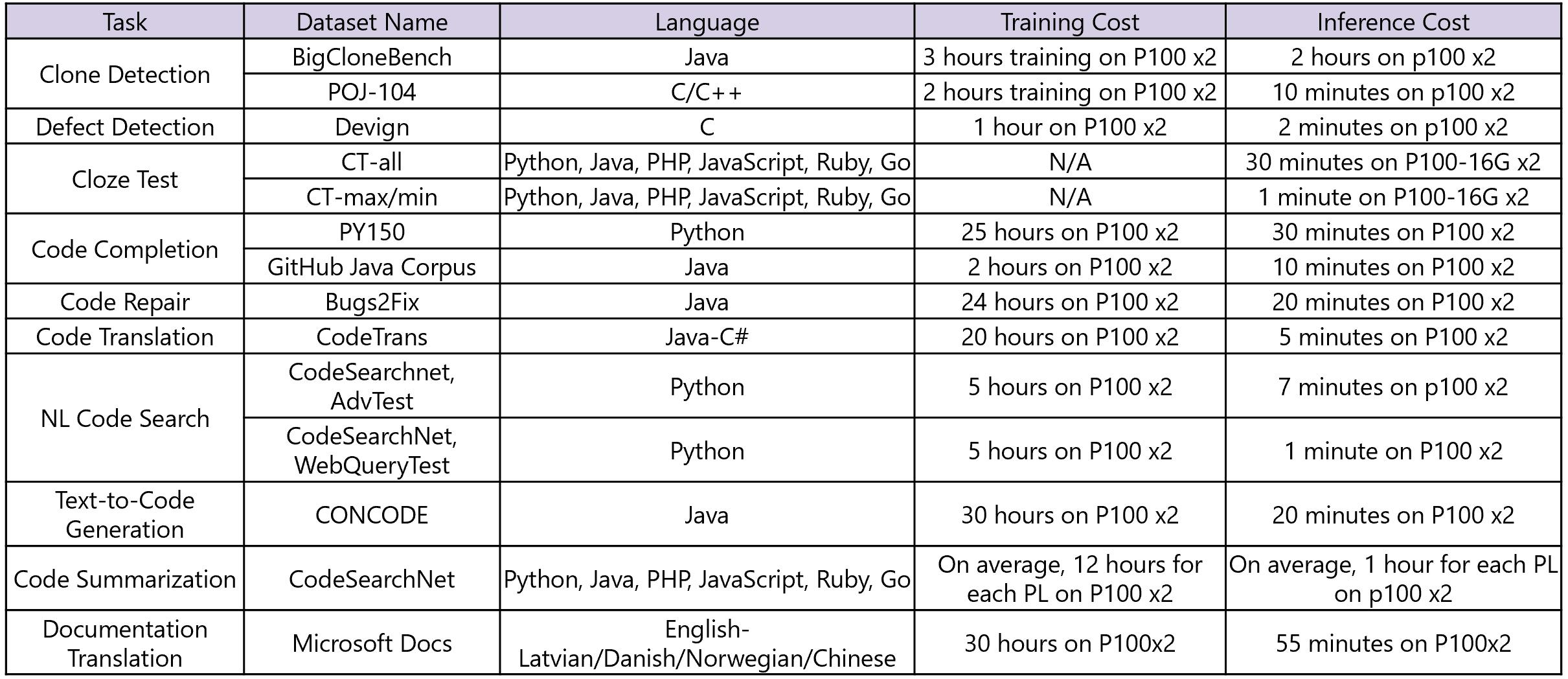
# 训练和推理时间成本
我们使用 2 块 P100 GPU 计算了每个数据集的训练和推理时间成本。结果分享在下表中。
# 许可证
我们的代码遵循 MIT 许可证。
我们的数据集遵循数据协议计算使用许可。
# 引用
如果您使用此代码或 CodeXGLUE,请考虑引用我们。
# 任务与数据集
下面,我们将详细说明每个任务的任务定义以及上表中高亮显示的全新引入的数据集。
1. 克隆检测 (BigCloneBench, POJ-104)。模型的任务是衡量代码之间的语义相似度。包含两个现有数据集。一个用于代码间的二分类,另一个用于在给定代码作为查询的情况下检索语义相似的代码。
2. 缺陷检测。模型的任务是识别一段源代码是否包含可能被用于攻击软件系统的缺陷,例如资源泄漏、释放后使用漏洞和 DoS 攻击。包含一个现有数据集。
3. 完形填空测试。模型的任务是从代码中预测被遮蔽的 token,表述为一个多选分类问题。这两个数据集是新创建的,一个的候选词来自(过滤后的)词表,另一个的候选词为“max”和“min”。
4. 代码补全 (PY150, GitHub Java Corpus)。模型的任务是在给定代码上下文的情况下预测后续的 token。涵盖 token 级别和行级别的补全。token 级别的任务类似于语言建模,我们在此包含了两个有影响力的数据集。行级别数据集是新创建的,用于测试模型自动补全一行代码的能力。
5. 代码翻译。模型的任务是将一种编程语言的代码翻译成另一种编程语言的代码。新创建了一个 Java 和 C# 之间的数据集。
6. 代码搜索 (CodeSearchNet, AdvTest; CodeSearchNet, WebQueryTest)。模型的任务是衡量文本和代码之间的语义相似度。在检索场景中,新创建了一个测试集,其中测试集中的函数名和变量被替换,以测试模型的泛化能力。在文本-代码分类场景中,创建了一个自然语言查询来自 Bing 查询日志的测试集,以便在真实用户查询上进行测试。
7. 代码修复 (Bugs2Fix)。模型的任务是尝试自动改进代码,这些代码可能有错误或很复杂。包含一个现有数据集。
8. 文本到代码生成 (CONCODE)。模型的任务是在给定自然语言描述的情况下生成代码。包含一个现有数据集。
9. 代码摘要。模型的任务是为代码生成自然语言注释。包含现有数据集。
10. 文档翻译。模型的任务是在人类语言之间翻译代码文档。新创建了一个专注于低资源多语言翻译的数据集。
# 提交说明
一旦您构建的模型在开发集上的评估效果符合您的预期,您就可以提交测试结果以获得测试集上的官方评估。为了确保官方测试结果的完整性,我们不会向公众发布测试集的正确答案。要提交您的模型以在测试集上进行官方评估,请执行以下步骤:
1. 生成您在开发集上的预测输出。
2. 运行任务特定 git 仓库中的官方评估方法,并验证您的系统是否按预期运行。
3. 生成您在测试集上的预测输出。
4. 通过发送电子邮件至 `codexglue@microsoft.com` 提交以下信息。
您的电子邮件应包括:
1. 测试集上的预测结果。**[必填]**
2. 开发集上的预测结果。**[推荐]**
3. 个人/团队名称:出现在排行榜上的个人或团队名称。**[必填]**
4. 个人/团队机构:出现在排行榜上的个人或团队所属机构名称。**[可选]**
5. 模型代码:模型的训练代码。**[推荐]**
6. 模型信息:出现在排行榜上的模型/技术名称。**[必填]**
7. 论文信息:如果模型来自已发表的工作,请提供出现在排行榜上的论文名称、引用和 URL。**[可选]**
为了避免“P-hacking”,我们不建议同一小组在短时间内提交过多。
# 训练和推理时间成本
我们使用 2 块 P100 GPU 计算了每个数据集的训练和推理时间成本。结果分享在下表中。

# 许可证
我们的代码遵循 MIT 许可证。
我们的数据集遵循数据协议计算使用许可。
# 引用
如果您使用此代码或 CodeXGLUE,请考虑引用我们。
@article{DBLP:journals/corr/abs-2102-04664,
author = {Shuai Lu and
Daya Guo and
Shuo Ren and
Junjie Huang and
Alexey Svyatkovskiy and
Ambrosio Blanco and
Colin B. Clement and
Dawn Drain and
Daxin Jiang and
Duyu Tang and
Ge Li and
Lidong Zhou and
Linjun Shou and
Long Zhou and
Michele Tufano and
Ming Gong and
Ming Zhou and
Nan Duan and
Neel Sundaresan and
Shao Kun Deng and
Shengyu Fu and
Shujie Liu},
title = {CodeXGLUE: {A} Machine Learning Benchmark Dataset for Code Understanding
and Generation},
journal = {CoRR},
volume = {abs/2102.04664},
year = {2021}
这项研究由 Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Daya Guo, Duyu Tang, Junjie Huang, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, Shuai Lu, Shujie Liu, 和 Shuo Ren 完成。标签:Apex, Azure, DLL 劫持, LLM, Microsoft, NLP, Python, Unmanaged PE, Visual Studio Code, 人工智能, 代码搜索, 代码智能, 代码翻译, 代码补全, 大语言模型, 威胁情报, 开发者工具, 数据管道, 无后门, 机器学习, 深度学习, 源代码分析, 生产效率, 用户模式Hook绕过, 编程, 软件工程, 逆向工具, 预训练模型