ldbc/ldbc_snb_datagen_spark
GitHub: ldbc/ldbc_snb_datagen_spark
基于 Spark 的 LDBC 社交网络基准合成图数据生成器,用于生成模拟真实社交网络特征的有向标签图数据集,支持图数据库和图处理系统的性能评测与学术研究。
Stars: 182 | Forks: 61

# LDBC SNB Datagen (基于 Spark)
[](https://circleci.com/gh/ldbc/ldbc_snb_datagen_spark)
LDBC SNB 数据生成器 (Datagen) 用于为 [LDBC Social Network Benchmark 的工作负载](https://ldbcouncil.org/benchmarks/snb/)生成数据集。该生成器旨在生成有向标签图,以模拟真实数据图的特征。有关 Datagen 生成的 schema 以及输出文件格式的详细说明,可以在最新版本的官方 [LDBC SNB 规范文档](https://github.com/ldbc/ldbc_snb_docs)中找到。
:scroll: 如果您希望引用 LDBC SNB,请参阅[文档仓库](https://github.com/ldbc/ldbc_snb_docs#how-to-cite-ldbc-benchmarks)。
:warning: Datagen 有两个不同的版本:
* [基于 Hadoop 的 Datagen](https://github.com/ldbc/ldbc_snb_datagen_hadoop/) 用于生成 Interactive 工作负载的 SF1-1000 数据集。
* 对于 BI 工作负载,请使用基于 Spark 的 Datagen(即本仓库)。
对于 `main` 分支上的每次提交,CI 都会部署[新生成的小型数据集](https://ldbcouncil.org/ldbc_snb_datagen_spark/)。
## 快速入门
### 构建 JAR
要使用 SBT 组装 JAR 文件,请运行:
```
sbt assembly
```
### 安装 Python 工具
部分构建实用程序是用 Python 编写的。要使用它们,您需要创建一个 Python 虚拟环境
并安装依赖项。
例如,使用 [pyenv](https://github.com/pyenv/pyenv) 和 [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv):
```
pyenv install 3.7.13
pyenv virtualenv 3.7.13 ldbc_datagen_tools
pyenv local ldbc_datagen_tools
pip install -U pip
pip install ./tools
```
如果环境已经存在,请使用以下命令激活它:
```
pyenv activate
```
### 本地运行
`./tools/run.py` 脚本用于**本地运行**。要使用它,请按以下步骤下载并解压 Spark。
#### Spark 3.2.x
Spark 3.2.x 是推荐的运行时版本。后续说明均假定使用 Spark 3.2.x。
要将 Spark 放在 `/opt/` 目录下:
```
scripts/get-spark-to-opt.sh
export SPARK_HOME="/opt/spark-3.2.2-bin-hadoop3.2"
export PATH="${SPARK_HOME}/bin":"${PATH}"
```
要将其放在 `${HOME}/` 目录下:
```
scripts/get-spark-to-home.sh
export SPARK_HOME="${HOME}/spark-3.2.2-bin-hadoop3.2"
export PATH="${SPARK_HOME}/bin":"${PATH}"
```
支持 Java 8 和 Java 11,但不支持 Java 17(Spark 3.2.2 会失败,因为它使用了 Java 内部 API 且未适当设置权限)。
#### 构建项目
运行:
```
scripts/build.sh
```
#### 运行生成器
当您准备好 Spark 并构建好 JAR 文件后,请按以下步骤运行生成器:
```
export PLATFORM_VERSION=$(sbt -batch -error 'print platformVersion')
export DATAGEN_VERSION=$(sbt -batch -error 'print version')
export LDBC_SNB_DATAGEN_JAR=$(sbt -batch -error 'print assembly / assemblyOutputPath')
./tools/run.py --
```
#### 运行时配置参数
运行时配置参数决定了内存大小、线程数和并行度。有关参数列表,请参见:
```
./tools/run.py --help
```
要生成单个 `part-*` 文件,请将并行度(Spark 分区数)设置为 1。
```
./tools/run.py --parallelism 1 -- --format csv --scale-factor 0.003 --mode bi
```
#### 生成器配置参数
生成器配置参数允许配置输出目录、输出格式、布局等。
要获取完整的参数列表,请向 JAR 文件传递 `--help`:
```
./tools/run.py -- --help
```
* 在 **BI 模式**下生成 `csv-composite-merged-fk` 文件,产生压缩的 `.csv.gz` 文件:
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --format-options compression=gzip
* 在 **BI 模式**下生成 `csv-composite-merged-fk` 文件并生成因子:
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --generate-factors
* 在 **raw 模式**下生成 CSV 文件:
./tools/run.py -- --format csv --scale-factor 0.003 --mode raw --output-dir sf0.003-raw
* 在 **BI 模式**下生成 Parquet 文件:
./tools/run.py -- --format parquet --scale-factor 0.003 --mode bi
* 在 **BI 模式**下,使用编码为 long 类型的 epoch 毫秒来序列化日期和日期时间值(这相当于在 [Hadoop Datagen 中使用 `LongDateFormatter`](https://github.com/ldbc/ldbc_snb_datagen_hadoop/blob/v0.3.8/src/main/java/ldbc/snb/datagen/util/formatter/LongDateFormatter.java)):
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --epoch-millis
* 对于 **BI 模式**,`--format-options` 参数允许传递格式选项,例如时间戳/日期格式、是否包含表头(详情请参见 [Spark 格式化选项](https://spark.apache.org/docs/2.4.8/api/scala/index.html#org.apache.spark.sql.DataFrameWriter)),以及 CSV 中的字段是否需要加引号:
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --format-options timestampFormat=MM/dd/y\ HH:mm:ss,dateFormat=MM/dd/y,header=false,quoteAll=true
* `--explode-attrs` 参数意味着使用 `csv-singular-{projected-fk,merged-fk}` 格式之一,该格式具有单独的文件来存储多值属性(`email`、`speaks`)。
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --explode-attrs
* `--explode-edges` 参数意味着使用 `csv-{composite,singular}-projected-fk` 格式之一,该格式具有单独的文件来存储多对一边缘(例如 `Person_isLocatedIn_City`、`Tag_hasType_TagClass` 等)。
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --explode-edges
* `--explode-attrs` 和 `--explode-edges` 参数组合使用意味着采用 `csv-singular-projected-fk` 格式:
./tools/run.py -- --format csv --scale-factor 0.003 --mode bi --explode-attrs --explode-edges
要更改 Spark 配置目录,请调整 `SPARK_CONF_DIR` 环境变量。
一个复杂的示例:
```
export SPARK_CONF_DIR=./conf
./tools/run.py --parallelism 4 --memory 8G -- --format csv --format-options timestampFormat=MM/dd/y\ HH:mm:ss,dateFormat=MM/dd/y --explode-edges --explode-attrs --mode bi --scale-factor 0.003
```
也可以传递一个参数文件:
```
./tools/run.py -- --format csv --param-file params.ini
```
### Docker 镜像
SNB Datagen 镜像可在 [Docker Hub](https://hub.docker.com/orgs/ldbc/repositories) 上获取。
镜像标签遵循 `${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION}` 的模式,例如 `ldbc/datagen-standalone:0.5.0-2.12_spark3.2`。
在构建镜像时,请确保[使用 BuildKit](https://docs.docker.com/develop/develop-images/build_enhancements/#to-enable-buildkit-builds)。
#### 独立 Docker 镜像
独立镜像将 Spark 与 JAR 和 Python 辅助程序捆绑在一起,因此您可以像本地运行一样在容器中运行工作负载,正如您在这个示例中所见:
```
export SF=0.003
mkdir -p out_sf${SF}_bi # create output directory
docker run \
--mount type=bind,source="$(pwd)"/out_sf${SF}_bi,target=/out \
--mount type=bind,source="$(pwd)"/conf,target=/conf,readonly \
-e SPARK_CONF_DIR=/conf \
ldbc/datagen-standalone:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION} \
--parallelism 1 \
-- \
--format csv \
--scale-factor ${SF} \
--mode bi \
--generate-factors
```
可以使用提供的 Dockerfile 构建独立 Docker 镜像。要构建,请从仓库目录执行以下命令:
```
export PLATFORM_VERSION=$(sbt -batch -error 'print platformVersion')
export DATAGEN_VERSION=$(sbt -batch -error 'print version')
export DOCKER_BUILDKIT=1
docker build . --target=standalone -t ldbc/datagen-standalone:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION}
```
#### 仅 JAR 镜像
`ldbc/datagen-jar` 镜像包含 assembly JAR,因此可以将其打包到您的自定义容器中:
```
FROM my-spark-image
ARG VERSION
COPY --from=ldbc/datagen-jar:${VERSION} /jar /lib/ldbc-datagen.jar
```
可以使用提供的 Dockerfile 构建仅 JAR 的 Docker 镜像。要构建,请从仓库目录执行以下命令:
```
docker build . --target=jar -t ldbc/datagen-jar:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION}
```
#### 推送到 Docker Hub
要在 Docker Hub 上发布新的快照版本,请运行:
```
docker tag ldbc/datagen-jar:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION} ldbc/datagen-jar:latest
docker push ldbc/datagen-jar:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION}
docker push ldbc/datagen-jar:latest
docker tag ldbc/datagen-standalone:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION} ldbc/datagen-standalone:latest
docker push ldbc/datagen-standalone:${DATAGEN_VERSION/+/-}-${PLATFORM_VERSION}
docker push ldbc/datagen-standalone:latest
```
要发布新的稳定版本,请创建一个新的 Git 标签(例如通过在 GitHub 上创建新的 Release),然后构建 Docker 镜像并推送。
### Elastic MapReduce
我们提供了在 AWS EMR 上运行 Datagen 的脚本。详情请参阅 [`./tools/emr`](tools/emr) 目录中的 README。
## 图 schema
图 schema 如下所示:
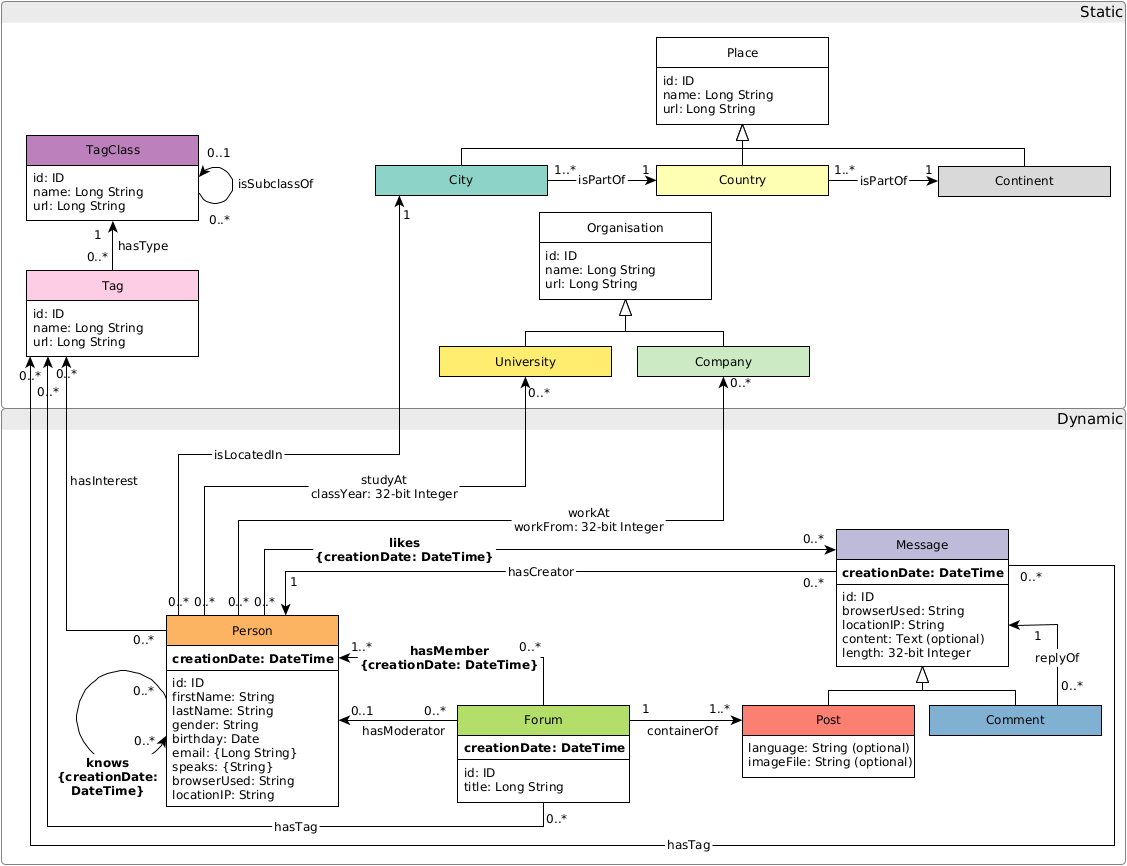
## 故障排除
* 运行测试时,可能会抛出 `java.net.UnknownHostException: your_hostname: your_hostname: Name or service not known` 错误,该错误源自 `org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal`。解决方法是在 `/etc/hosts` 文件中添加一条机器主机名的记录:`127.0.1.1 your_hostname`。
* 如果您正在使用 Docker 且 Spark 空间不足,请确保 Docker 有足够的空间来存储其容器。要将 Docker 容器的位置移动到具有更大空间的磁盘,请停止 Docker,编辑(或创建)`/etc/docker/daemon.json` 文件并添加 `{ "data-root": "/path/to/new/docker/data/dir" }`,然后在需要时同步旧文件夹,最后重启 Docker。(参见[更详细的说明](https://www.guguweb.com/2019/02/07/how-to-move-docker-data-directory-to-another-location-on-ubuntu/))。
* 如果您使用的是本地 Spark 安装并且在 `/tmp` 中空间不足(`java.io.IOException: No space left on device`),请设置 `SPARK_LOCAL_DIRS` 以指向一个具有足够可用空间的目录。
* 在生成因子时,Docker 镜像可能会抛出以下错误 `java.io.FileNotFoundException: /tmp/blockmgr-.../.../temp_shuffle_... (No file descriptors available)`。此错误发生在 Fedora 36 主机机器上。改用 Ubuntu 22.04 主机机器可以解决此问题。相关问题:[#420](https://github.com/ldbc/ldbc_snb_datagen_spark/issues/420)。
标签:Apache Spark, BI工作负载, DNS解析, Hadoop生态系统, LDBC SNB, LDBC基准测试, Python, SBT, Spark, 商业智能, 图分析, 图挖掘, 图数据生成器, 图数据集, 图模型, 图模式, 图计算, 域名枚举, 基准测试工具, 大数据, 大数据处理, 开源项目, 性能测试, 数据工程, 数据生成, 无后门, 有向标记图, 目录扫描, 社交网络图, 社交网络基准, 虚拟环境, 请求拦截, 逆向工具, 配置错误检测