 IPyflow
IPyflow
[](https://github.com/ipyflow/ipyflow/actions)
[](http://mypy-lang.org/)
[](https://github.com/psf/black)
[](https://opensource.org/licenses/BSD-3-Clause)
[](https://pypi.org/project/ipyflow)

## 太长不看
为 Jupyter[Lab] 提供精确的响应式 Python notebook:
1. `pip install ipyflow`
2. 从启动器或 kernel 选择器中选择 `Python 3 (ipyflow)`。
3. 对于每次 cell 执行,(最小范围的)未同步的上游和
下游 cell 也会重新执行,使得已执行的 cell 呈现出
从上到下运行 notebook 时的样子。
## 关于
IPyflow 是一个用于 JupyterLab 和 Notebook 7 的下一代 Python kernel,它会在给定的交互式会话期间跟踪符号与 cell 之间的数据流关系,从而更容易理解 notebook 的状态。这里有一个介绍它的 JupyterCon 演讲[视频](https://www.youtube.com/watch?v=mZZnDlyKk7g&t=8s)(以及对应的[幻灯片](https://docs.google.com/presentation/d/1D9MSiIkwv7gjRr7jfNYZXki9TfkoUr4Yr-a06i0w_QU))。
如果你想跳过这段简短介绍,直接查看安装 / 激活说明,请跳转到下方的[快速开始](#quick-start);否则,请继续阅读以了解 IPyflow 的理念和功能集。
## 目标
IPyflow 为 Jupyter 默认的 Python kernel(ipykernel)提供了可直接附加的响应式功能。它的设计初衷基于以下目标:
- **与 ipykernel 完全向后兼容:** IPyflow 的目标是成为 ipykernel 的*直接替代品*,提供其功能的严格超集。
- **精确的依赖推断:** IPyflow 不仅理解简单变量之间的依赖关系,还能理解 cell 之间更深层次的依赖。例如,IPyflow 知道当 cell `B` 因为下标引用 `x[0]` 而依赖于 cell `A` 时,它足够智能,不会在 `x` 的其他部分(例如 `x[1]`)发生变化时,去反应式地执行 cell `B`。因此,它将不必要的重复执行限制在了最低限度。
- **无畏执行:** IPyflow 试图强制执行以下不变式:每当你执行一个 cell 时,生成的输出看起来就像你执行了“重启 + 运行所有”操作一样。这意味着你基本上可以执行 notebook 中的任何 cell,并相信它*就是*能正常工作
TM。
## 快速开始
若要安装,请运行:
```
pip install ipyflow
```
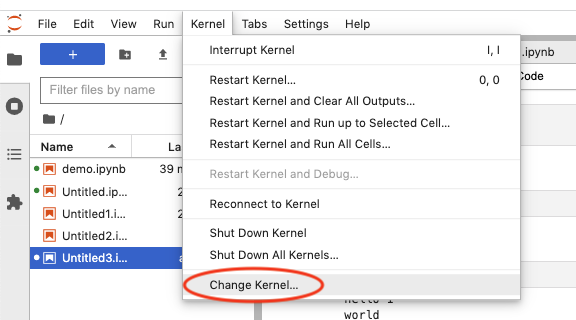
要运行 IPyflow kernel,请从启动器选项卡的可用 kernel 列表中选择“Python 3 (ipyflow)”。同样,你可以通过导航到“Change kernel”文件菜单项,在现有的 notebook 中切换到 / 切换出 IPyflow:
入口点 | Kernel 切换器
:-------------------------------:|:-------------------------------:
 | 
## 功能
### 响应式执行模型
IPyflow 附带了扩展,为 JupyterLab 和 Notebook 7 带来了可选的响应性,类似于其他 notebook(如 [Observable](https://observablehq.com/)、[Pluto.jl](https://github.com/fonsp/Pluto.jl) 和 [Marimo](https://github.com/marimo-team/marimo))中提供的执行行为。
不过,IPyflow 的响应式行为与上述工具略有不同,因为它是专门为了满足 Jupyter 用户的需求而设计的。一旦启用了响应式执行(见下文 —— 响应性是选择性启用的),使用 IPyflow 执行 cell `C` 会导致 `C` 的输出、`C` 依赖的 cell 的输出,以及依赖于 `C` 的 cell 的输出,全部呈现出如同 notebook 从上到下执行(例如通过“重启并运行所有”)时的样子。
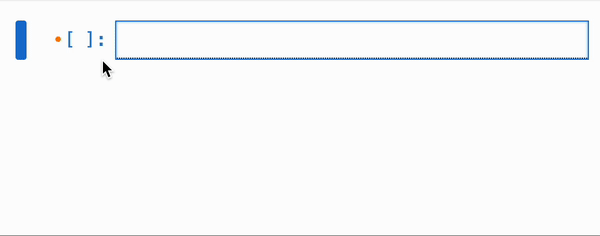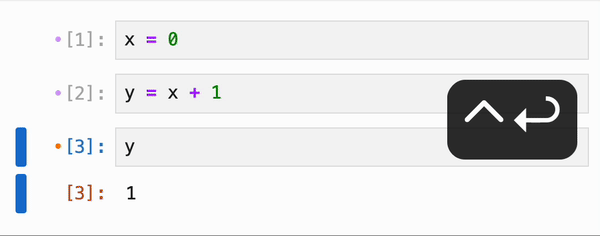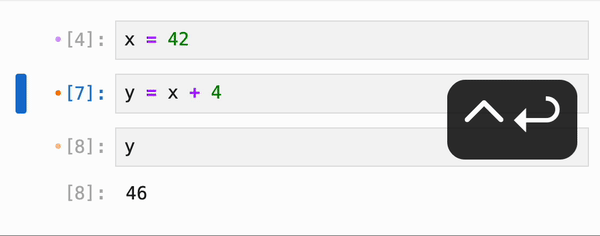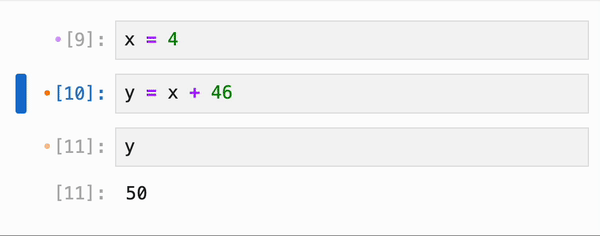
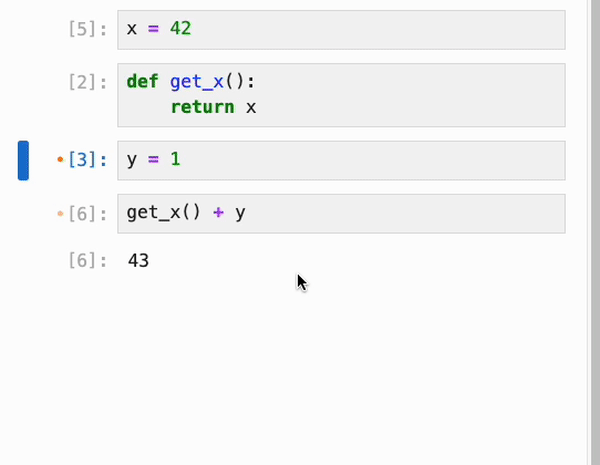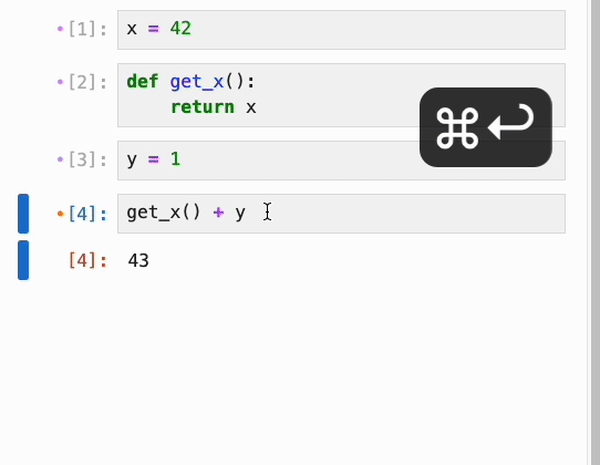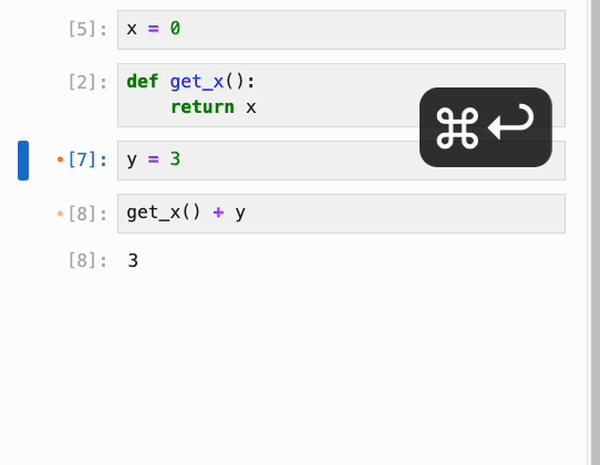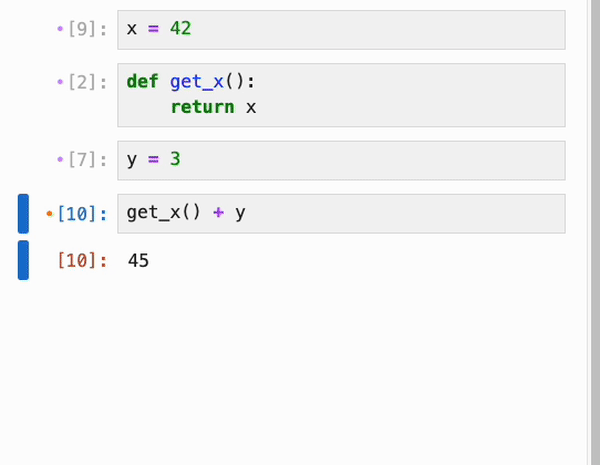
无论是否启用了响应式执行,IPyflow 的 JupyterLab 扩展都会对 cell 的依赖关系进行颜色编码:当你选择某个 cell `C` 时,所有在执行 `C` 时会重新执行的 cell 旁边都会有一个橙点,而 `C` 依赖的、但已是最新且不会重新执行的 cell 则会有紫点:
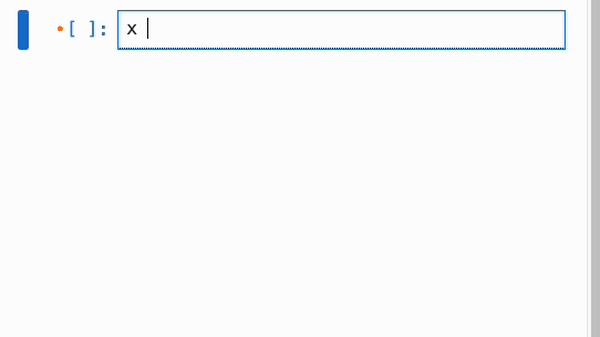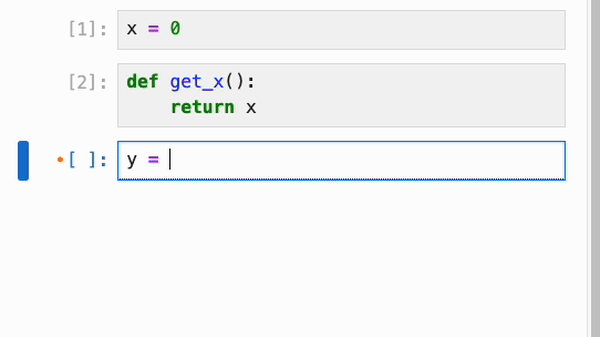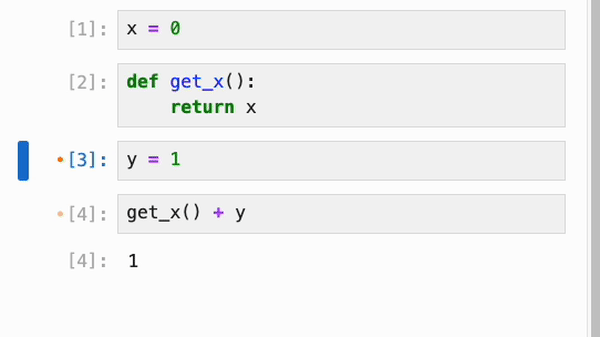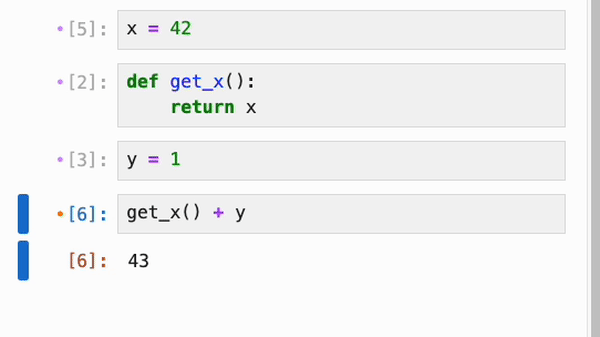
cell 的依赖信息会被持久化到 notebook 的元数据中,因此你可以在启动全新的 kernel 会话后跳转到任意 cell,运行它,并确信输出正是 notebook 作者所期望的:
### 自动保存与恢复先前的执行
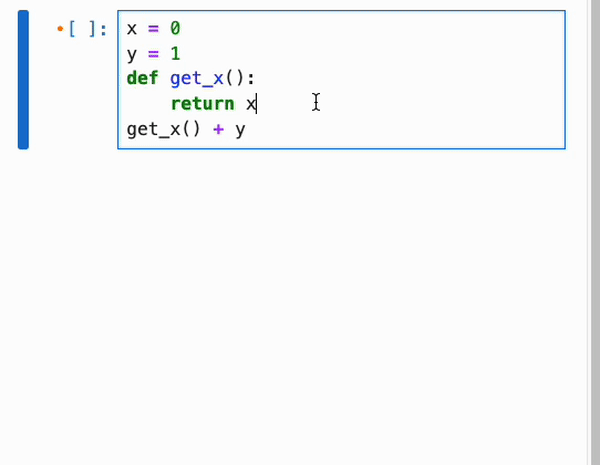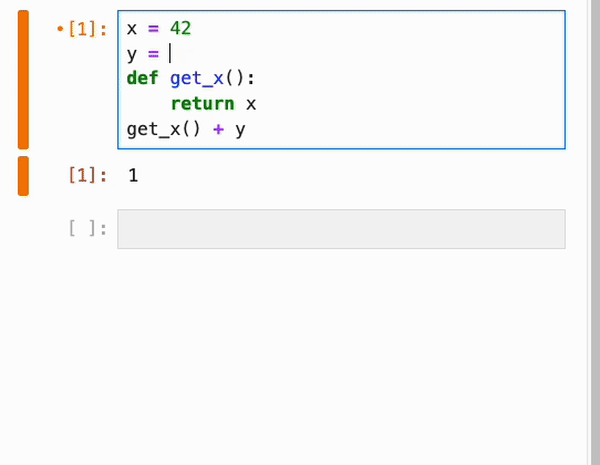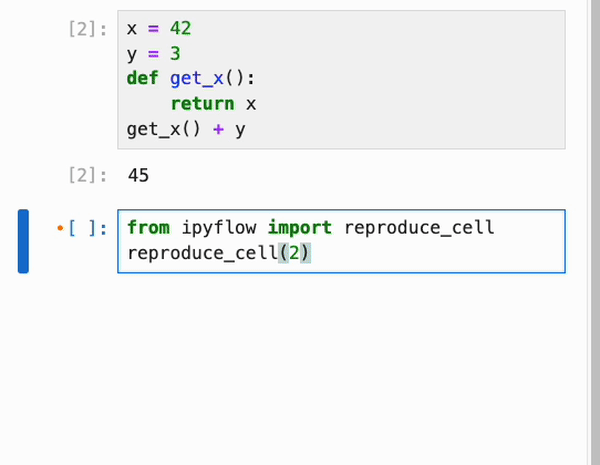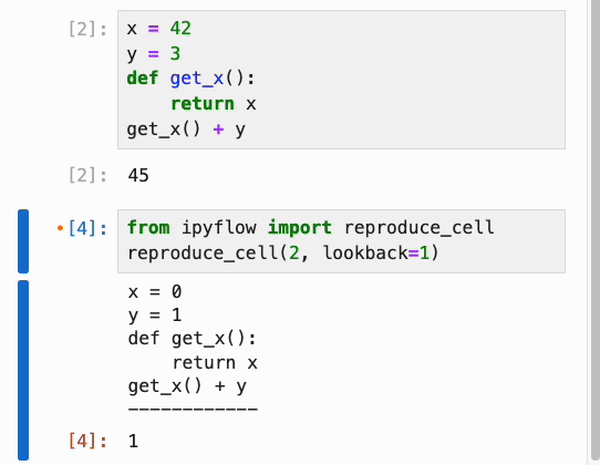
由于 IPyflow 会窥探运行时状态以推断依赖关系,因此它需要让 notebook 的内容与 kernel 的内存状态保持同步,即使在浏览器刷新时也是如此。因此,IPyflow 默认启用了更改时自动保存功能,使得 kernel 状态、notebook UI 的内存状态以及磁盘上的 notebook 文件全部保持同步。如果你不小心覆盖了想要保留的 cell 输出(例如在响应式执行期间),并且自动保存覆盖了磁盘上的先前结果,请不要担心!IPyflow 提供了一个名为 `reproduce_cell` 的库实用程序,用于恢复先前 cell 执行的输入和输出(在给定的 kernel 会话内):
```
from ipyflow import reproduce_cell
reproduce_cell(4, lookback=1) # to reproduce the previous execution of cell 4
```
示例:
### 选择启用响应性
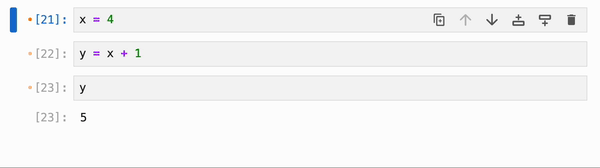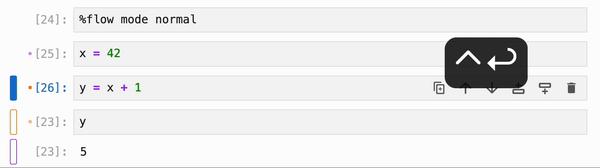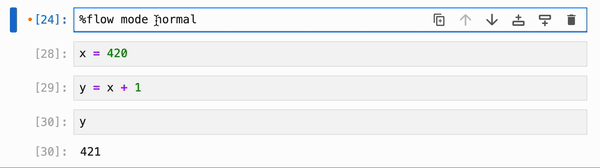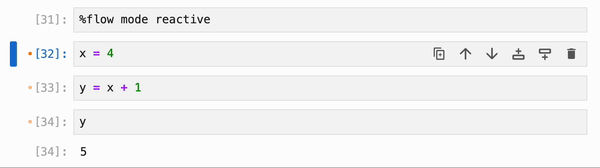
默认情况下,IPyflow 使用普通的(非响应式)执行,并且仅运行你执行的 cell。如果你想在不改变默认模式的情况下,响应式地执行单个 cell 及其依赖项,你可以使用 ctrl+shift+enter(在 Mac 上,cmd+shift+enter 也可以):
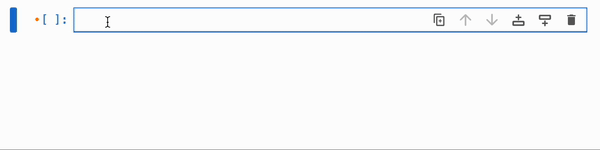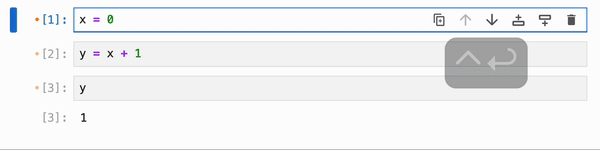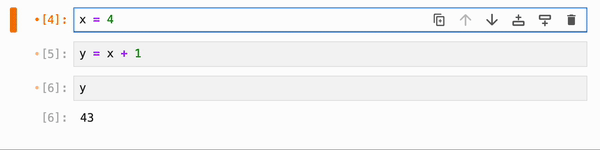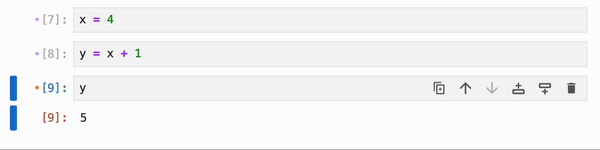
你还可以运行 magic 命令 `%flow mode reactive` 来将响应式执行设为默认(在这种情况下,ctrl+shift+enter / cmd+shift+enter 将从响应式切换为非响应式)。要切换回默认的非响应式行为,你可以运行 `%flow mode lazy`:
如果你希望将响应式执行设为每个新 kernel 会话的默认行为,你可以将其添加到你的 IPython profile 中(默认位置通常在 `~/.ipython/profile_default/ipython_config.py`):
```
c = get_config()
c.ipyflow.exec_mode = "reactive" # defaults to "lazy"
```
### 顺序执行与任意顺序语义
IPyflow 默认采用*顺序*(in-order)语义,这意味着,如果 cell `B` 依赖于 cell `A`,那么在 notebook 的空间顺序中,`A` 必须出现在 `B` 之前。IPyflow 并不阻止先前的 cell 引用由后续 cell 创建或更新的数据,但它在执行响应式执行时会忽略这些边。顺序语义虽然灵活性较低,但与任意顺序语义相比具有一些令人满意的特性,因为它们鼓励编写更清晰、更具重现性的 notebook,这些 notebook 以后可以更轻松地转换为 Python 脚本。既然我可能已经(也可能没有)向你推销了顺序语义,你可以通过运行 magic 命令 `%flow direction any_order` 在 IPyflow 中启用任意顺序语义,并使用 `%flow direction in_order` 重新启用默认的顺序语义:
如果你希望将任意顺序语义设为新 kernel 会话的默认行为,你也可以更新你的 IPython profile:
```
c = get_config()
c.ipyflow.flow_direction = "any_order" # defaults to "in_order"
```
### 解决不一致性的执行建议与快捷方式
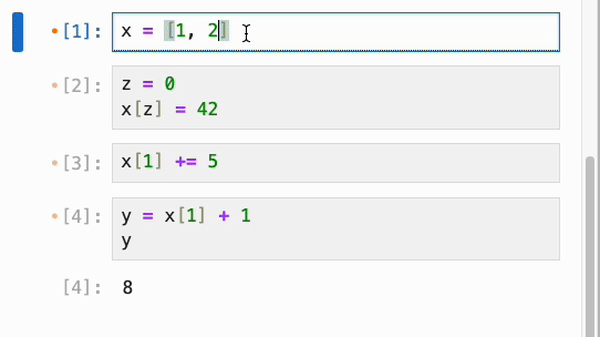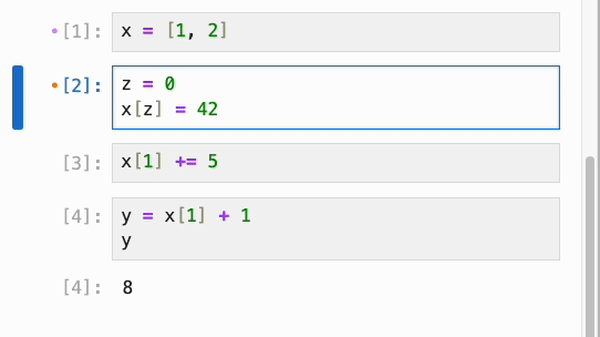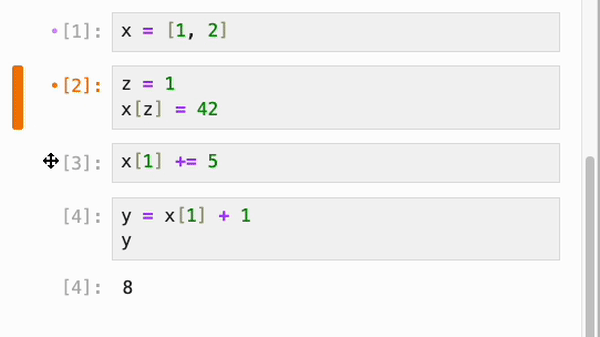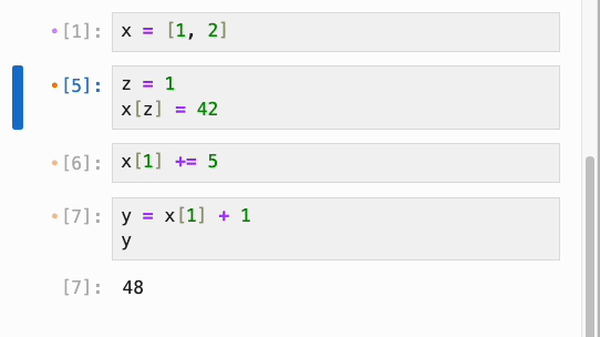
每当一个 cell 引用了更新后的数据时,它旁边的折叠图标就会变成橙色(类似于脏 cell 的颜色),而(递归地)依赖于它的 cell 的折叠图标会变成紫色。(橙色输入配紫色输出仅仅意味着输出可能不同步。)在使用响应式执行时,你通常不会看到这些,因为不同步的依赖 cell 会自动重新运行,但如果你使用 ctrl+shift+enter 临时退出响应性,或者如果你更改了 cell 更新的数据(从而覆盖了 cell 之间先前的边),你可能会看到它们。
如果你想让 IPyflow 为你修复这些问题,你可以在命令模式下按“Space”键自动解决所有过期或脏 cell。此操作可能会引入更多的过期 cell,在这种情况下,如果需要,你可以继续按“Space”键,直到所有的不一致性都被解决:
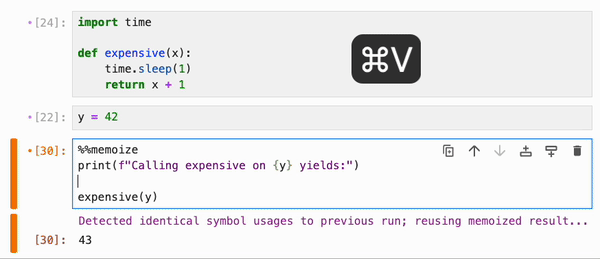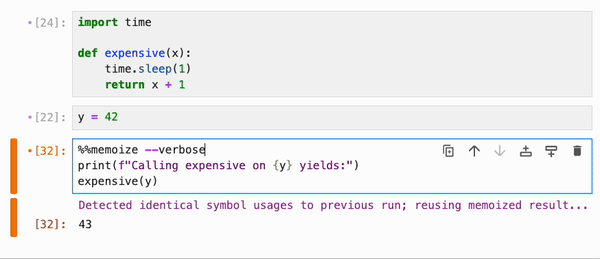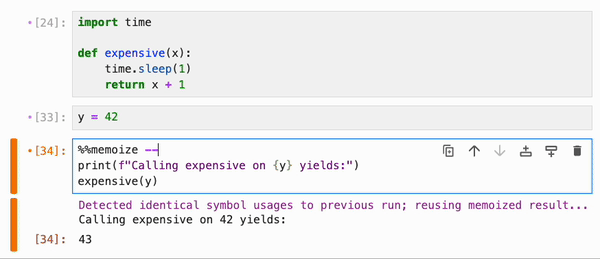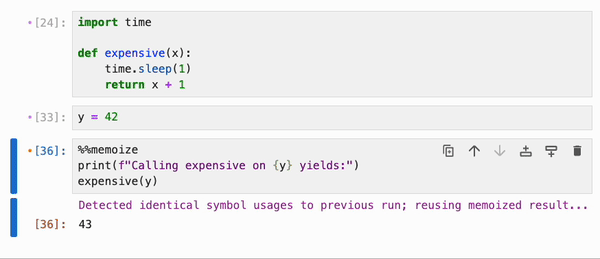
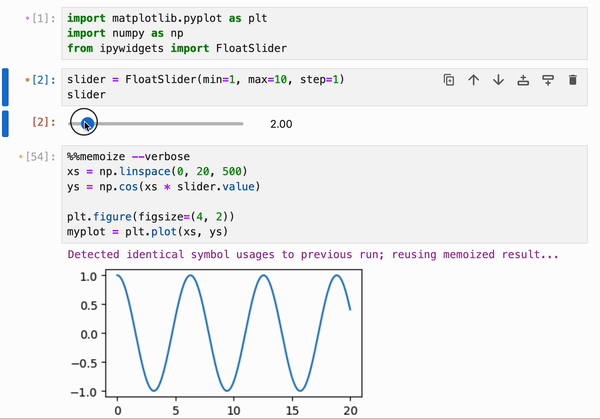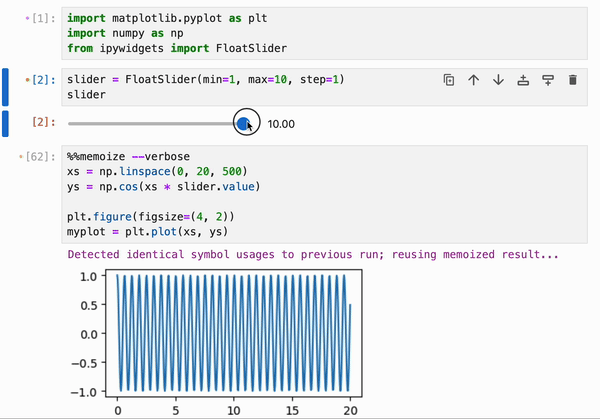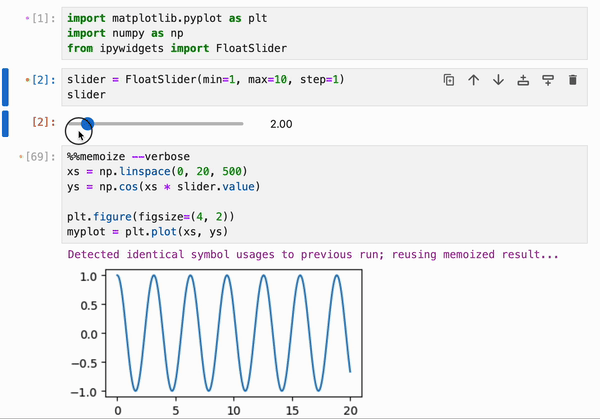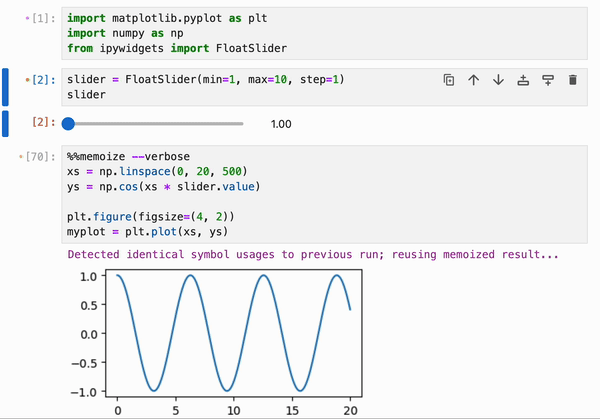
### 缓存
引用了 Python 函数和类、整数、浮点数、字符串等基本类型,以及 numpy 数组、pandas dataframe 及其容器(列表、字典、集合、元组等)的 cell,可以使用特殊的 `%%memoize` 伪 magic 命令被 IPyflow 缓存。无需指定 cell 的“输入”,因为 IPyflow 会自动推断这些。被缓存的 cell 会将其结果存储在内存中(尽管未来计划支持基于磁盘的缓存),并且每当 IPyflow 检测到输入和 cell 内容与先前运行完全相同时,它就会检索这些缓存的结果(而不是重新运行 cell):
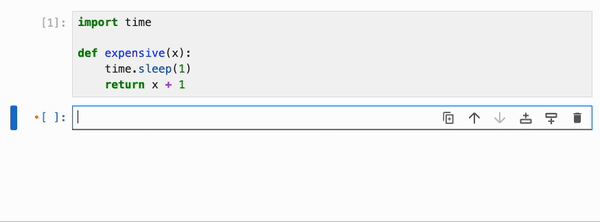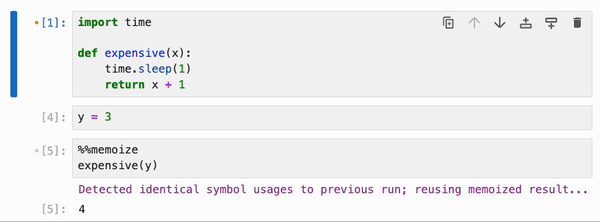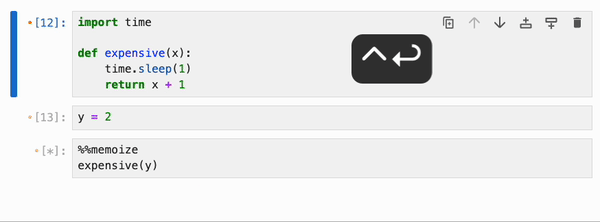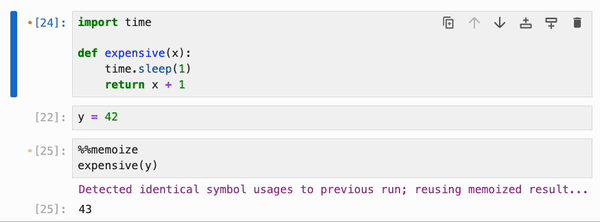
默认情况下,`%%memoize` 会跳过除 cell 中最后一个表达式(如果适用)可能产生的 displayhook 输出之外的所有输出。要同时跳过这个输出,请传递 `--quiet`;要包含 stdout、stderr 和其他富文本输出,请传递 `--verbose`:
### IPyWidgets 集成
IPyflow 的响应式执行引擎内置了对 `ipywidgets` 的支持,允许将 widget 的更改跨越 cell 边界进行传播:
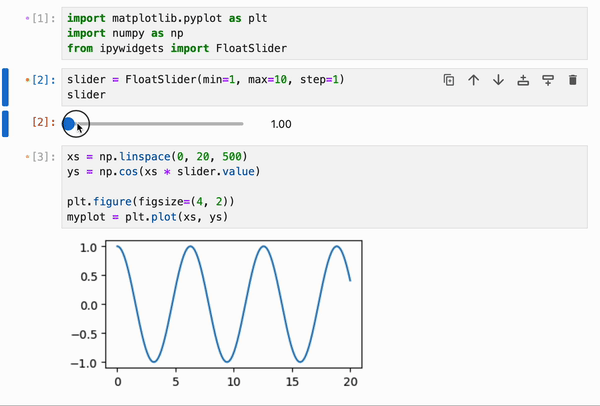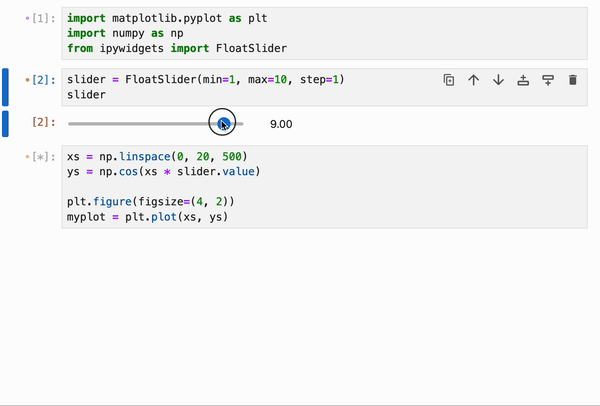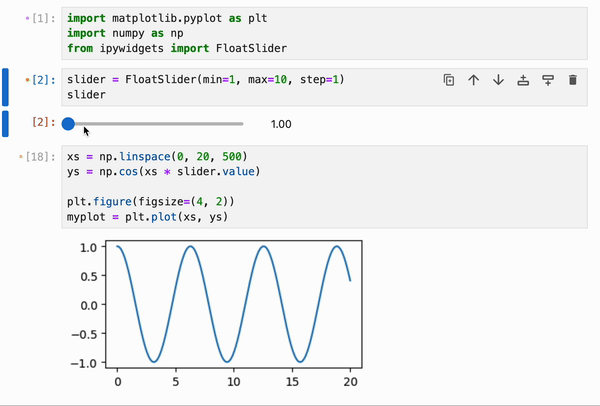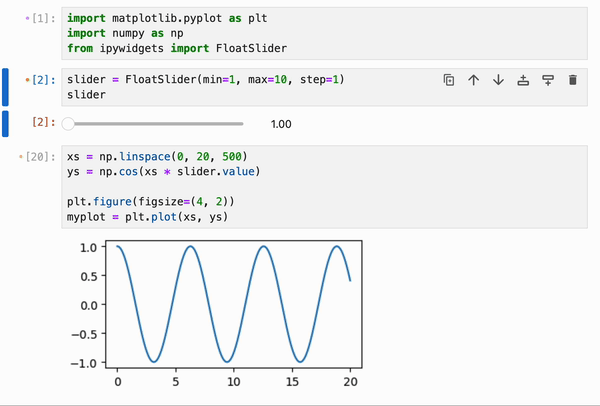
此功能可以与 `%%memoize` magic 结合使用,以提供跨 cell 的交互式绘图的近实时渲染:
此功能可以与其他扩展(如 [stickyland](https://github.com/xiaohk/stickyland))配对使用,在 JupyterLab + IPyflow 之上构建完全响应式的仪表板。
最后,IPyflow 还集成了 [mercury](https://github.com/mljar/mercury) widgets:
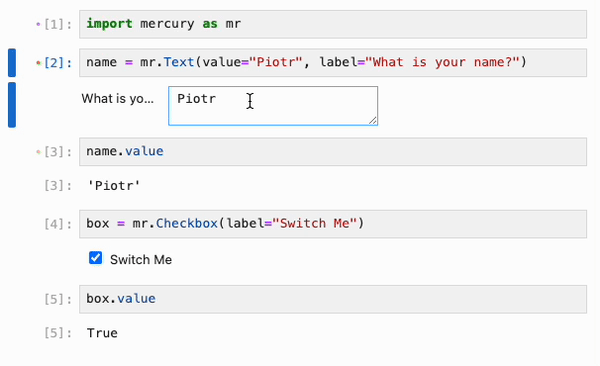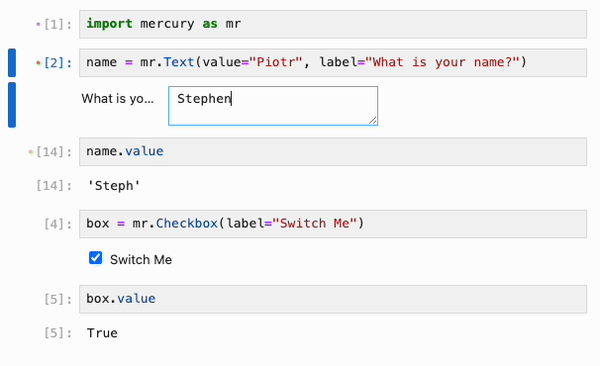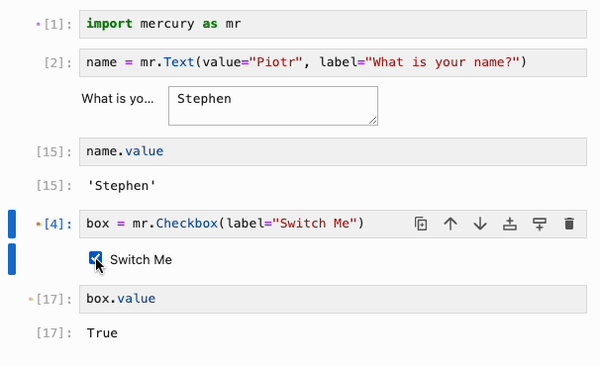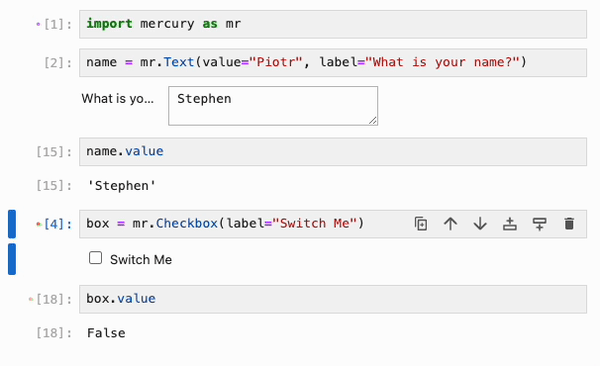
## State API
IPyflow 必须在深层次上理解底层的执行状态,才能提供其功能。它公开了一个用于与此类状态进行交互的 API,包括一个 `code` 函数,用于获取重建某个符号所需的代码:
```
# Cell 1
from ipyflow import code
# Cell 2
x = 0
# Cell 3
y = x + 1
# Cell 4
print(code(y))
# 输出:
"""
# Cell 2
x = 0
# Cell 3
y = x + 1
"""
```
你也可以使用 `slice()` 方法在 cell 级别执行此操作:
```
from ipyflow import cells
print(cells(4).slice())
# 输出:
"""
# Cell 2
x = 0
# Cell 3
y = x + 1
# Cell 4
print(code(y))
"""
```
你还可以使用 `timestamp` 函数查看符号最后一次更新时的 cell(从 1 开始索引)和语句(从 0 开始索引):
```
from ipyflow import timestamp
timestamp(y)
# Timestamp(cell_num=3, stmt_num=0)
```
要查看特定符号的依赖项和被依赖项,请分别使用 `deps` 和 `users` 函数:
```
from ipyflow import deps, users
deps(y)
# [
]
users(x)
# []
```
如果你想把某个符号提升为 IPyflow 内部使用的表示形式,请使用 `lift` 函数(当然,风险自负):
```
from ipyflow import lift
y_sym = lift(y)
y_sym.timestamp
# Timestamp(cell_num=3, stmt_num=0)
```
## Colab、VSCode 及其他接口
响应性和其他前端功能目前尚无法在 Colab 或 VSCode 等接口中运行,但你仍然可以通过使用以下代码初始化你的 notebook 会话,在这些平台上使用 IPyflow 的数据流 API:
```
%pip install ipyflow
%load_ext ipyflow
```
## 引用
IPyflow 最初以 nbsafety 的名义出现,它提供了最初的执行建议和切片功能。
对于[执行建议](http://www.vldb.org/pvldb/vol14/p1093-macke.pdf):
```
@article{macke2021fine,
title={Fine-grained lineage for safer notebook interactions},
author={Macke, Stephen and Gong, Hongpu and Lee, Doris Jung-Lin and Head, Andrew and Xin, Doris and Parameswaran, Aditya},
journal={Proceedings of the VLDB Endowment},
volume={14},
number={6},
pages={1093--1101},
year={2021},
publisher={VLDB Endowment}
}
```
对于[动态切片器](https://smacke.net/papers/nbslicer.pdf)(用于响应性和 `code` 函数等):
```
@article{shankar2022bolt,
title={Bolt-on, Compact, and Rapid Program Slicing for Notebooks},
author={Shankar, Shreya and Macke, Stephen and Chasins, Andrew and Head, Andrew and Parameswaran, Aditya},
journal={Proceedings of the VLDB Endowment},
volume={15},
number={13},
pages={4038--4047},
year={2022},
publisher={VLDB Endowment}
}
```
对于上述论文未涵盖的任何内容,你可以引用 IPyflow 仓库:
```
@misc{ipyflow,
title = {{IPyflow: A Next-Generation, Dataflow-Aware IPython Kernel}},
howpublished = {\url{https://github.com/ipyflow/ipyflow}},
year = {2022},
}
```
## 致谢
如果没有上述论文中列出的那些出色的学术合作者,IPyflow 就不可能实现。它的响应式执行功能受到了其他优秀工具的启发,例如 [Hex](https://hex.tech/) notebook、[Pluto.jl](https://github.com/fonsp/Pluto.jl) 和 [Observable](https://observablehq.com/)。IPyflow 也与其他响应式 Python notebook 相互借鉴了思想,如 [Marimo](https://github.com/marimo-team/marimo)、[Jolin.io](https://cloud.jolin.io/) 和 [Datalore](https://blog.jetbrains.com/datalore/2021/10/11/revamped-reactive-mode-and-how-it-makes-your-notebooks-reproducible/) —— 如果你喜欢 IPyflow,绝对也值得去看看它们。
IPyflow 的工作得益于许多公司人员的支持——既有直接的资金捐助([Databricks](https://www.databricks.com/)、[Hex](https://hex.tech/)),也有间接的精神支持和鼓励([Ponder](https://ponder.io/)、[Meta](https://www.meta.com/))。当然,IPyflow 还建立在令人惊叹的 Jupyter 社区所构建的基础之上。
## 许可证
本项目中的代码采用 [BSD-3-Clause 许可证](https://opensource.org/licenses/BSD-3-Clause)授权。