huggingface/tokenizers
GitHub: huggingface/tokenizers
提供基于 Rust 的高性能分词器实现,支持 BPE、WordPiece、Unigram 等主流算法,兼顾研究灵活性与生产级速度。
Stars: 10901 | Forks: 1153




提供了当今最常用分词器(tokenizer)的实现,侧重于性能与通用性。
## 主要特性:
- 使用当今最常用的分词器来训练新词表并进行分词。
- 得益于 Rust 的实现,速度极快(包括训练和分词)。在服务器 CPU 上对 1GB 文本进行分词只需不到 20 秒。
- 易于使用,且功能极其丰富。
- 专为研究与生产环境设计。
- 规范化(Normalization)过程带有对齐(alignment)跟踪。始终可以获取与给定 token 相对应的原始句子部分。
- 完成所有预处理:截断(Truncate)、填充(Pad),并添加您的模型所需的特殊 token。
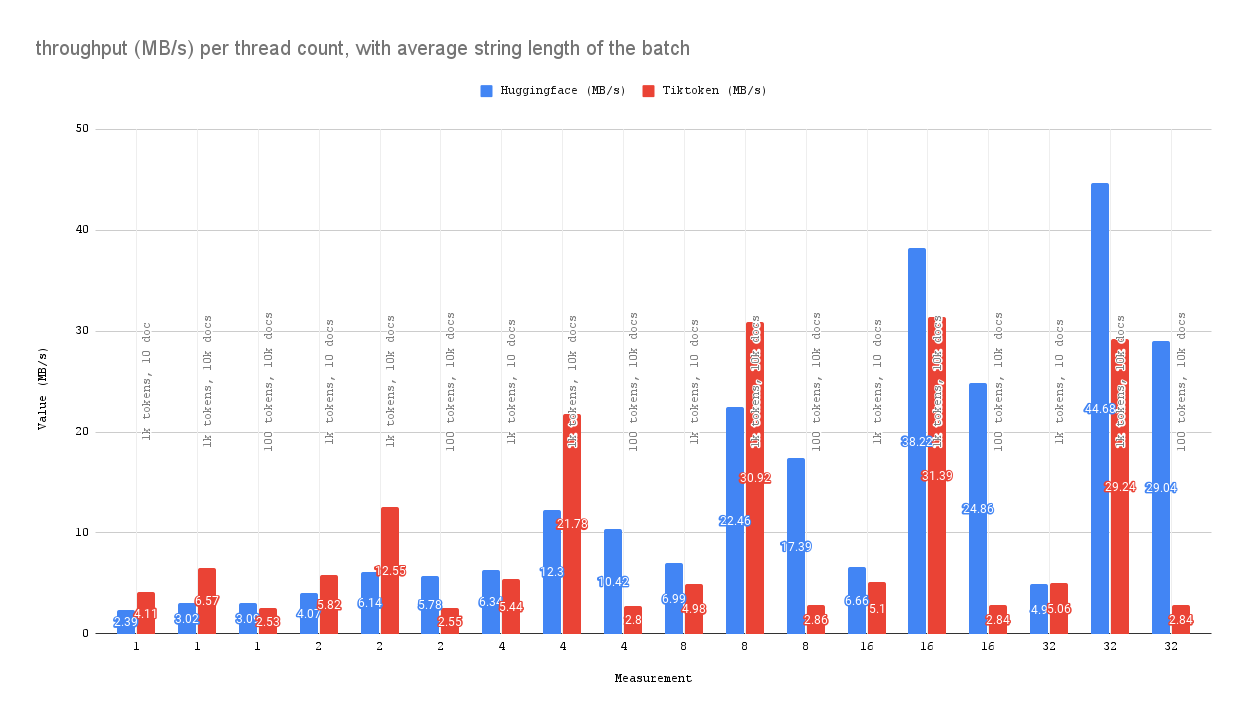
## 性能
性能可能因硬件而异,但运行 [~/bindings/python/benches/test_tiktoken.py](bindings/python/benches/test_tiktoken.py) 在 AWS g6 实例上应该会产生以下结果:
## 绑定
我们提供以下语言的绑定(更多语言支持即将推出!):
- [Rust](https://github.com/huggingface/tokenizers/tree/main/tokenizers)(原始实现)
- [Python](https://github.com/huggingface/tokenizers/tree/main/bindings/python)
- [Node.js](https://github.com/huggingface/tokenizers/tree/main/bindings/node)
- [Ruby](https://github.com/ankane/tokenizers-ruby)(由 @ankane 贡献,外部仓库)
## 安装
您可以使用以下命令从源码安装:
```
pip install git+https://github.com/huggingface/tokenizers.git#subdirectory=bindings/python
```
或者使用以下命令安装已发布的版本
```
pip install tokenizers
```
## Python 快速示例:
在 Byte-Pair Encoding、WordPiece 或 Unigram 中选择您的模型,并实例化一个 tokenizer:
```
from tokenizers import Tokenizer
from tokenizers.models import BPE
tokenizer = Tokenizer(BPE())
```
您可以自定义预分词(例如,拆分为单词)的方式:
```
from tokenizers.pre_tokenizers import Whitespace
tokenizer.pre_tokenizer = Whitespace()
```
然后,在一组文件上训练您的 tokenizer 只需要两行代码:
```
from tokenizers.trainers import BpeTrainer
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tokenizer.train(files=["wiki.train.raw", "wiki.valid.raw", "wiki.test.raw"], trainer=trainer)
```
一旦您的 tokenizer 训练完成,只需一行代码即可编码任何文本:
```
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
print(output.tokens)
# ["你好", ",", "大", "'", "家", "!", "你们", "好吗", "[UNK]", "?"]
```
查看 [文档](https://huggingface.co/docs/tokenizers/index) 或 [快速入门](https://huggingface.co/docs/tokenizers/quicktour) 以了解更多!
标签:AI, Apex, DLL 劫持, GNU通用公共许可证, Hugging Face, LLM, MITM代理, NLP, Node.js, Python, Rust, Tokenizer, Unmanaged PE, 人工智能, 分词器, 可视化界面, 大语言模型, 对齐追踪, 开源库, 搜索引擎爬虫, 文本预处理, 无后门, 机器学习, 极速计算, 深度学习, 生产环境, 用户模式Hook绕过, 研究工具, 网络流量审计, 自动化代码审查, 词表训练, 跨语言绑定, 逆向工具, 通知系统