flyteorg/flyte
GitHub: flyteorg/flyte
Flyte 是基于 Kubernetes 的可扩展数据和 ML 工作流编排平台,提供强类型、可复现的管道构建能力。
Stars: 7089 | Forks: 832

Flyte
:building_construction: :rocket: :chart_with_upwards_trend:
![]()
![]()
![]()
构建
使用 Python 或任何其他语言编写代码,并利用强大的类型引擎。
Deploy & Scale
Either locally or on a remote cluster, execute your models with ease.
快速开始 · 文档 · 资源
## 目录 * [快速开始](#quick-start) * [教程](#tutorials) * [功能特性](#features) * [谁在使用 Flyte](#whos-using-flyte) * [如何保持参与](#how-to-stay-involved) * [如何贡献](#how-to-contribute) ## 快速开始 1. 安装 Flyte 的 Python SDK ``` pip install flytekit ``` 2. 创建一个工作流(参见[示例](https://github.com/flyteorg/flytesnacks/blob/master/examples/basics/basics/hello_world.py)) 3. 使用以下命令在本地运行: ``` pyflyte run hello_world.py hello_world_wf ``` **准备好尝试 Flyte 集群了吗?** 1. 创建一个新的沙箱集群,作为 Docker 容器运行: ``` flytectl demo start ``` 2. 现在在集群上执行您的工作流: ``` pyflyte run --remote hello_world.py hello_world_wf ``` **想看更多内容但不想安装任何东西?**
[试用 Union 平台](https://signup.union.ai),它构建于 Flyte 之上,并可免费使用 GPU、数据血缘等功能!
**准备好投入生产了吗?**
前往[部署指南](https://docs.flyte.org/en/latest/deployment/deployment/index.html)获取在不同环境中安装 Flyte 的说明
## 教程
- [在 Flyte 代码库上微调 Code Llama](https://github.com/unionai-oss/llm-fine-tuning/tree/main/flyte_llama#readme)
- [使用 Horovod 和 Spark 预测销售](https://docs.flyte.org/en/latest/flytesnacks/examples/forecasting_sales/index.html)
- [使用 BLASTX 进行核苷酸序列查询](https://docs.flyte.org/en/latest/flytesnacks/examples/blast/index.html)
## 功能特性
🚀 **强类型接口**:通过使用 Flyte 类型定义数据护栏,在工作流的每一步验证您的数据。
**想看更多内容但不想安装任何东西?**
[试用 Union 平台](https://signup.union.ai),它构建于 Flyte 之上,并可免费使用 GPU、数据血缘等功能!
**准备好投入生产了吗?**
前往[部署指南](https://docs.flyte.org/en/latest/deployment/deployment/index.html)获取在不同环境中安装 Flyte 的说明
## 教程
- [在 Flyte 代码库上微调 Code Llama](https://github.com/unionai-oss/llm-fine-tuning/tree/main/flyte_llama#readme)
- [使用 Horovod 和 Spark 预测销售](https://docs.flyte.org/en/latest/flytesnacks/examples/forecasting_sales/index.html)
- [使用 BLASTX 进行核苷酸序列查询](https://docs.flyte.org/en/latest/flytesnacks/examples/blast/index.html)
## 功能特性
🚀 **强类型接口**:通过使用 Flyte 类型定义数据护栏,在工作流的每一步验证您的数据。🌐 **任何语言**:使用原始容器用任何语言编写代码,或选择 [Python](https://github.com/flyteorg/flytekit)、[Java](https://github.com/flyteorg/flytekit-java)、[Scala](https://github.com/flyteorg/flytekit-java) 或 [JavaScript](https://github.com/NotMatthewGriffin/pterodactyl) SDK 来开发您的 Flyte 工作流。
🔒 **不可变性**:不可变的执行通过防止对执行状态的任何更改来帮助确保可复现性。
🧬 **数据血缘**:在您的数据和 ML 工作流的整个生命周期中跟踪数据的流动和转换。
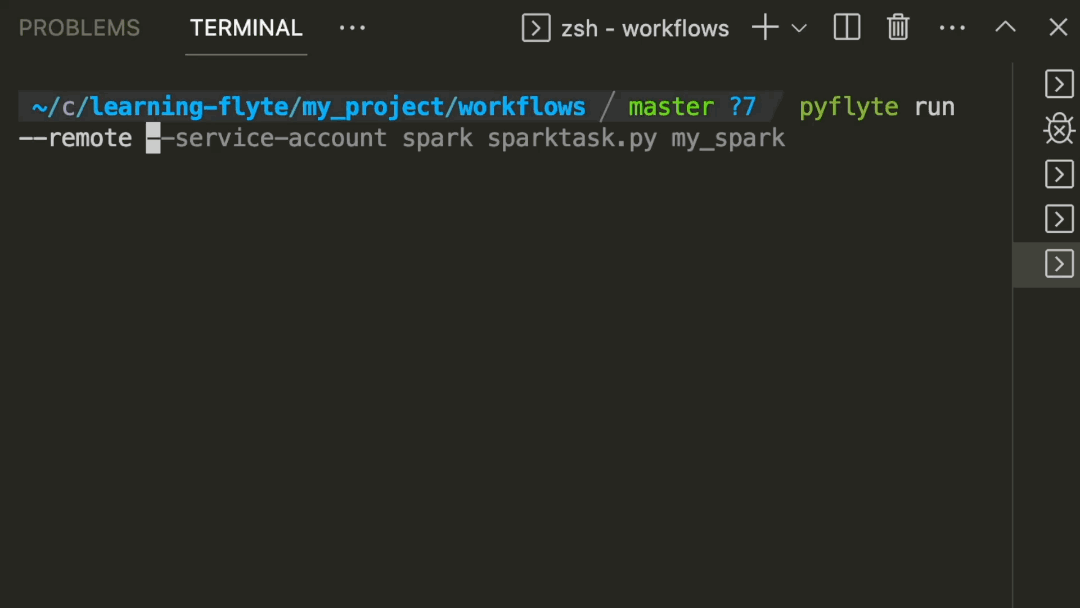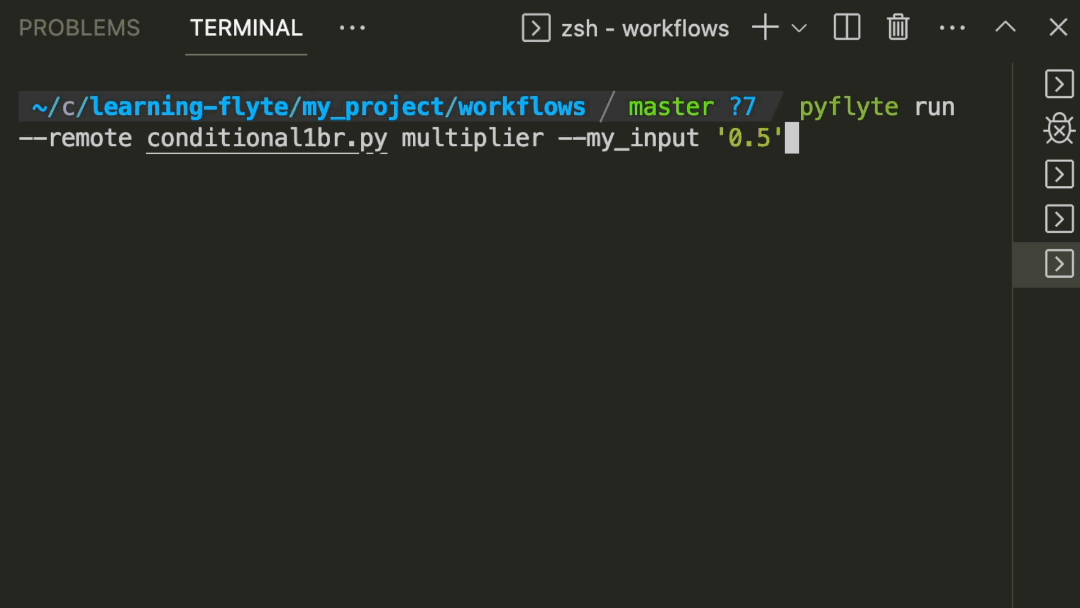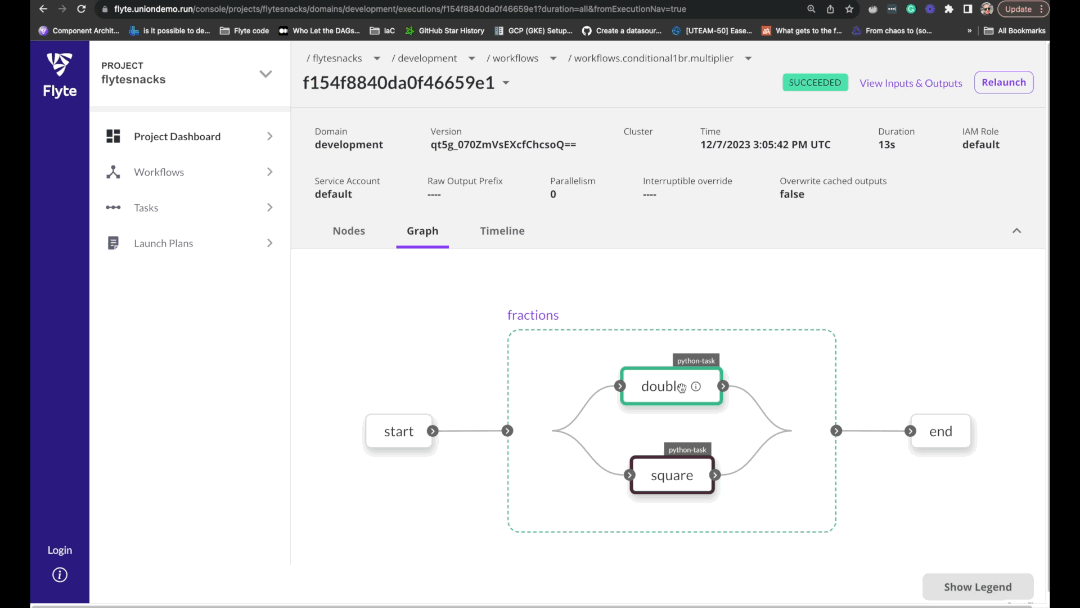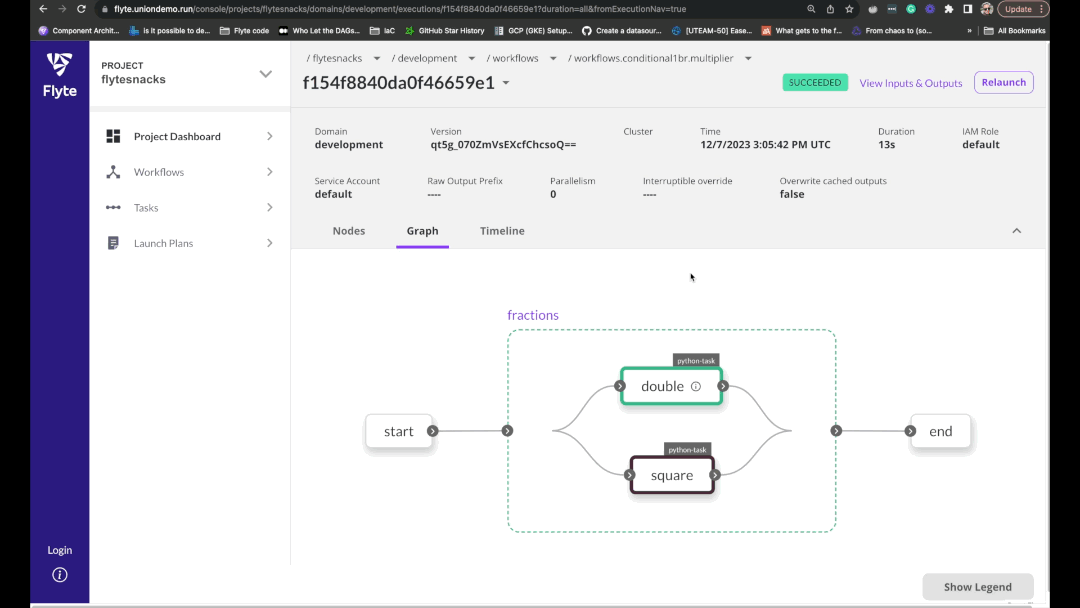
📊 **Map 任务**:使用 [map tasks](https://docs.flyte.org/en/latest/user_guide/advanced_composition/map_tasks.html) 以最少的配置实现并行代码执行。
🌎 **多租户**:多个用户可以共享同一个平台,同时维护各自独立的数据和配置。
🌟 **动态工作流**:[构建灵活且适应性强的 工作流](https://docs.flyte.org/en/latest/user_guide/advanced_composition/dynamic_workflows.html),这些工作流可以根据需要进行更改和发展,从而更容易响应不断变化的需求。
⏯️ 在继续执行之前[等待](https://docs.flyte.org/en/latest/user_guide/advanced_composition/waiting_for_external_inputs.html)**外部输入**。
🌳 **分支**:根据其他任务生成的静态或动态数据或输入数据,[有选择地执行](https://docs.flyte.org/en/latest/user_guide/advanced_composition/conditionals.html)工作流的分支。
📈 **数据可视化**:通过图表可视化数据、监控模型和查看训练历史。
📂 **FlyteFile 和 FlyteDirectory**:在本地和云存储之间传输[文件](https://docs.flyte.org/en/latest/user_guide/data_types_and_io/flytefile.html)和[目录](https://docs.flyte.org/en/latest/user_guide/data_types_and_io/flytedirectory.html)。
🗃️ **结构化数据集**:使用 [Structured Dataset](https://docs.flyte.org/en/latest/user_guide/data_types_and_io/structureddataset.html) 提供的抽象 2D 表示在类型之间转换数据帧,并强制执行列级类型检查。
🛡️ **从故障中恢复**:仅恢复失败的任务。
🔁 **重新运行单个任务**:在最细粒度级别重新运行工作流,而无需修改数据/ML 工作流的先前状态。
🔍 **缓存输出**:通过将 `cache=True` 传递给任务装饰器来缓存任务输出。
🚩 **任务内检查点**:在任务执行过程中[检查点进度](https://docs.flyte.org/en/latest/user_guide/advanced_composition/intratask_checkpoints.html)。
⏰ **超时**:定义一个超时时间,之后任务将被标记为失败。
🏭 **从开发到生产**:就像将您的[域](https://docs.flyte.org/en/latest/concepts/domains.html)从开发或暂存更改为生产一样简单。
💸 **Spot 或可抢占实例**:通过在任务装饰器中将 `interruptible` 设置为 `True`,在 Spot 实例上调度您的工作流。
☁️ **云原生部署**:在 AWS、GCP、Azure 和其他云服务上部署 Flyte。
📅 **调度**:[调度](https://docs.flyte.org/en/latest/user_guide/productionizing/schedules.html)您的数据和 ML 工作流在特定时间运行。
📢 **通知**:通过 Slack、PagerDuty 或电子邮件配置[通知](https://docs.flyte.org/en/latest/user_guide/productionizing/notifications.html),随时了解工作流状态的变化。
⌛️ **时间轴视图**:评估您每个 Flyte 任务的持续时间并识别潜在的瓶颈。
💨 **GPU 加速**:通过在任务装饰器中请求资源来启用和控制任务的 GPU 需求。
🐳 **通过容器进行依赖隔离**:为您的任务维护独立的依赖集,这样就不会出现依赖冲突。
🔀 **并行性**:Flyte 任务天生具有并行性,以优化资源消耗并提高性能。
💾 **动态分配资源**在任务级别。
## 谁在使用 Flyte 加入 LinkedIn、Spotify、Freenome、Pachama、Warner Bros. 等众多公司的行列,采用 Flyte 用于关键任务用例。有关采用者的完整列表以及如何添加您的组织或项目的信息,请访问我们的 [ADOPTERS](https://github.com/flyteorg/community/blob/main/ADOPTERS.md) 页面。 ## 如何保持参与 👥 [每月社区同步会议](https://www.addevent.com/event/EA7823958):在每个月的第一个星期二举行,Flyte 团队会在会上提供项目更新,社区成员可以分享他们的进展并提出问题。
💬 [Slack](https://slack.flyte.org/):加入 Slack 上的 Flyte 社区,与其他用户聊天、提问并获得帮助。
⚠️ [简报](https://lists.lfaidata.foundation/g/flyte-announce/join):加入此群组以接收 Flyte 每月简报。
📹 [Youtube](https://www.youtube.com/channel/UCNduEoLOToNo3nFVly-vUTQ):收看小组讨论、客户成功案例、社区更新和功能深入探讨。
📄 [博客](https://flyte.org/blog):在这里,您可以找到教程和功能深入探讨,帮助您了解有关 Flyte 的更多信息。
💡 [RFCs](rfc/.):RFCs 用于提出改进 Flyte 的新想法和功能。您可以参考它们以随时了解最新的发展,并为平台的增长做出贡献。 ## 许可证 Flyte 基于 Apache License 2.0 发布。请明智地使用它。

标签:Apache 2.0 许可证, Apex, DNS解析, ETL, EVTX分析, Flyte, JavaCC, JS文件枚举, LF AI & Data, MLOps, NIDS, Python, Python工具, Python 库, 代码示例, 任务调度, 分布式计算, 可扩展架构, 大数据, 子域名突变, 容器化, 工作流编排, 工作流自动化, 开源项目, 异常处理, 数据分析, 数据工程, 数据科学, 无后门, 日志审计, 机器学习, 模型训练, 流水线管理, 测试用例, 漏洞利用检测, 目录扫描, 请求拦截, 资源验证, 逆向工具