NVIDIA/gpu-operator
GitHub: NVIDIA/gpu-operator
NVIDIA GPU Operator 利用 Kubernetes Operator 框架,自动化部署、配置和管理集群中 NVIDIA GPU 所需的驱动、设备插件及监控等所有软件组件。
Stars: 2795 | Forks: 524
[](https://raw.githubusercontent.com/NVIDIA/gpu-operator/master/LICENSE)
[](https://gitlab.com/nvidia/kubernetes/gpu-operator/-/pipelines)
[](https://gitlab.com/nvidia/kubernetes/gpu-operator/-/pipelines)
# NVIDIA GPU Operator
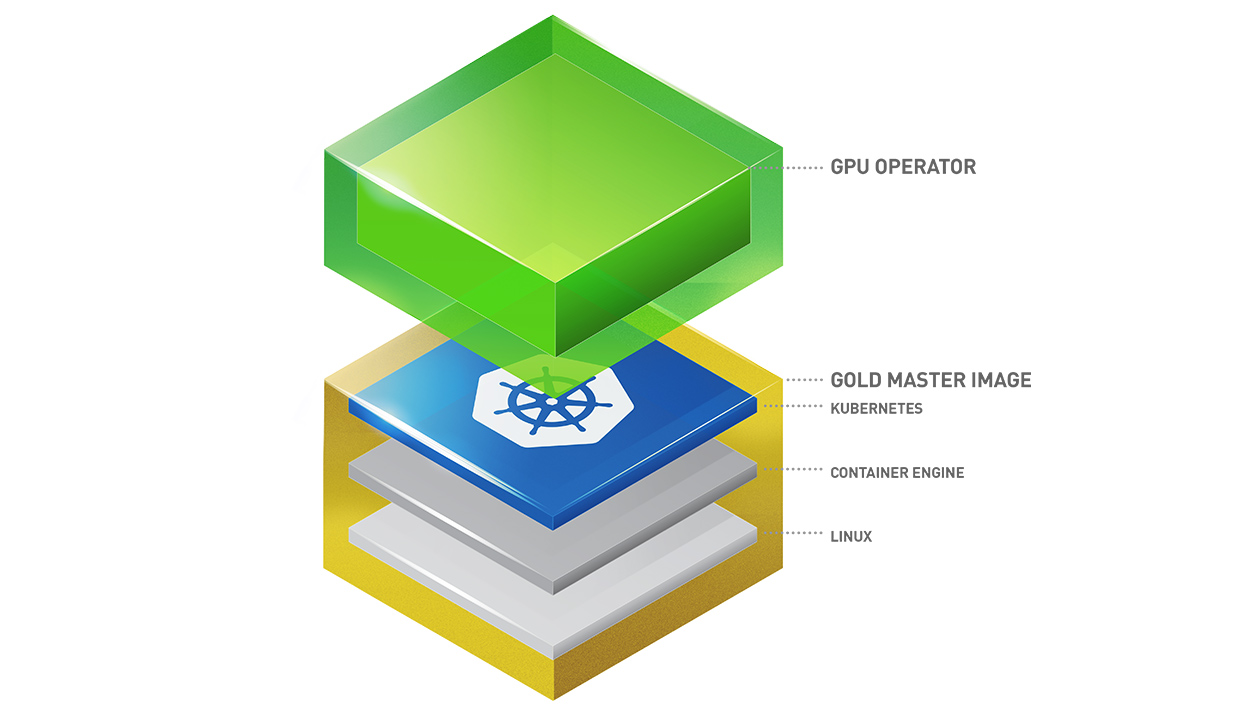
Kubernetes 通过 [device plugin framework](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/) 对特殊硬件资源(如 NVIDIA GPU、NIC、Infiniband 适配器和其他设备)提供访问支持。然而,配置和管理具有这些硬件资源的节点需要配置多个软件组件(例如驱动程序、容器运行时或其他库),这既复杂又容易出错。
NVIDIA GPU Operator 利用 Kubernetes 内部的 [operator framework](https://cloud.redhat.com/blog/introducing-the-operator-framework),自动化管理配置 GPU 所需的所有 NVIDIA 软件组件。这些组件包括 NVIDIA 驱动程序(用于启用 CUDA)、用于 GPU 的 Kubernetes 设备插件、NVIDIA Container Runtime、自动节点标记、基于 [DCGM](https://developer.nvidia.com/dcgm) 的监控以及其他组件。
## 目标用户和用例
GPU Operator 允许 Kubernetes 集群管理员像管理集群中的 CPU 节点一样管理 GPU 节点。管理员无需为 GPU 节点准备特殊的操作系统镜像,而是可以对 CPU 和 GPU 节点使用标准的操作系统镜像,然后依靠 GPU Operator 来为 GPU 配置所需的软件组件。
请注意,GPU Operator 特别适用于需要快速扩展 Kubernetes 集群的场景——例如在云端或本地配置额外的 GPU 节点,并管理底层软件组件的生命周期。由于 GPU Operator 将所有组件(包括 NVIDIA 驱动程序)作为容器运行,管理员可以通过启动或停止容器轻松更换各种组件。
## 快速开始
本部分提供了使用数据中心驱动程序部署 GPU Operator 的快速指南。
请确保您的 Kubernetes 集群满足[前提条件](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/getting-started.html#prerequisites),并且列在[平台支持页面](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/platform-support.html#supported-operating-systems-and-kubernetes-platforms)上。
**步骤 1:添加 NVIDIA Helm 仓库**
```
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update
```
**步骤 2:部署 GPU Operator**
```
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator
```
安装完成后,GPU Operator 及其操作数(operands)应该已经启动并正在运行。
注意:
要在 OpenShift 上部署 GPU Operator,请遵循[官方文档](https://docs.nvidia.com/datacenter/cloud-native/openshift/latest/steps-overview.html)中的说明。
## 产品文档
有关平台支持和入门信息,请访问官方文档[仓库](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/overview.html)。
## 路线图
- 支持最新的 NVIDIA 数据中心 GPU、系统和驱动程序。
- 支持 RHEL 10。
- 支持带有 Ubuntu 24.04 的 KubeVirt。
- 将 [NVIDIADriver](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/gpu-driver-configuration.html) CRD 推进至正式发布(GA)阶段。
- 将 [NVIDIA’s DRA Driver for GPUs](https://github.com/NVIDIA/k8s-dra-driver-gpu) 作为 GPU Operator 的受管组件集成进来。
## 网络研讨会
[How to easily use GPUs on Kubernetes](https://info.nvidia.com/how-to-use-gpus-on-kubernetes-webinar.html)
## 贡献
[阅读贡献相关文档](https://github.com/NVIDIA/gpu-operator/blob/master/CONTRIBUTING.md)。您可以通过提交 [pull request](https://help.github.com/en/articles/about-pull-requests) 做出贡献。
## 支持与获取帮助
如有任何问题,请在 [GitHub 项目上提交 issue](https://github.com/NVIDIA/gpu-operator/issues/new)。我们感谢您的反馈。
标签:AI基础设施, Apex, CUDA, DCGM, EVTX分析, GPU, GPU驱动, HPC, Operator, 云计算, 基础设施, 子域名突变, 容器编排, 容器运行时, 提示注入, 数据中心, 日志审计, 机器学习, 深度学习, 特权提升, 监控, 硬件加速, 系统运维, 自动化部署, 节点管理, 规则引擎, 设备插件, 请求拦截, 资源调度, 集群管理, 高性能计算