notnotparas/pushcv-cli
GitHub: notnotparas/pushcv-cli
一个本地优先、注重隐私的终端 CLI 工具,帮助求职者在终端中追踪职位申请、抓取招聘信息、估算薪资并使用本地 AI 定制简历。
Stars: 22 | Forks: 3
# pushcv
**求职专属的 Git** — 一个本地优先、注重隐私的 CLI 工具,用于追踪你的求职申请,抓取招聘信息,使用*本地* AI 模型量身定制简历,并估算薪酬 — 一切皆在终端完成。无需账户,无需云服务,数据绝不离开你的设备。
基于 [Typer](https://typer.tiangolo.com/) · [Rich](https://rich.readthedocs.io/) · [SQLModel](https://sqlmodel.tiangolo.com/) 以及本地 SQLite 数据库构建。
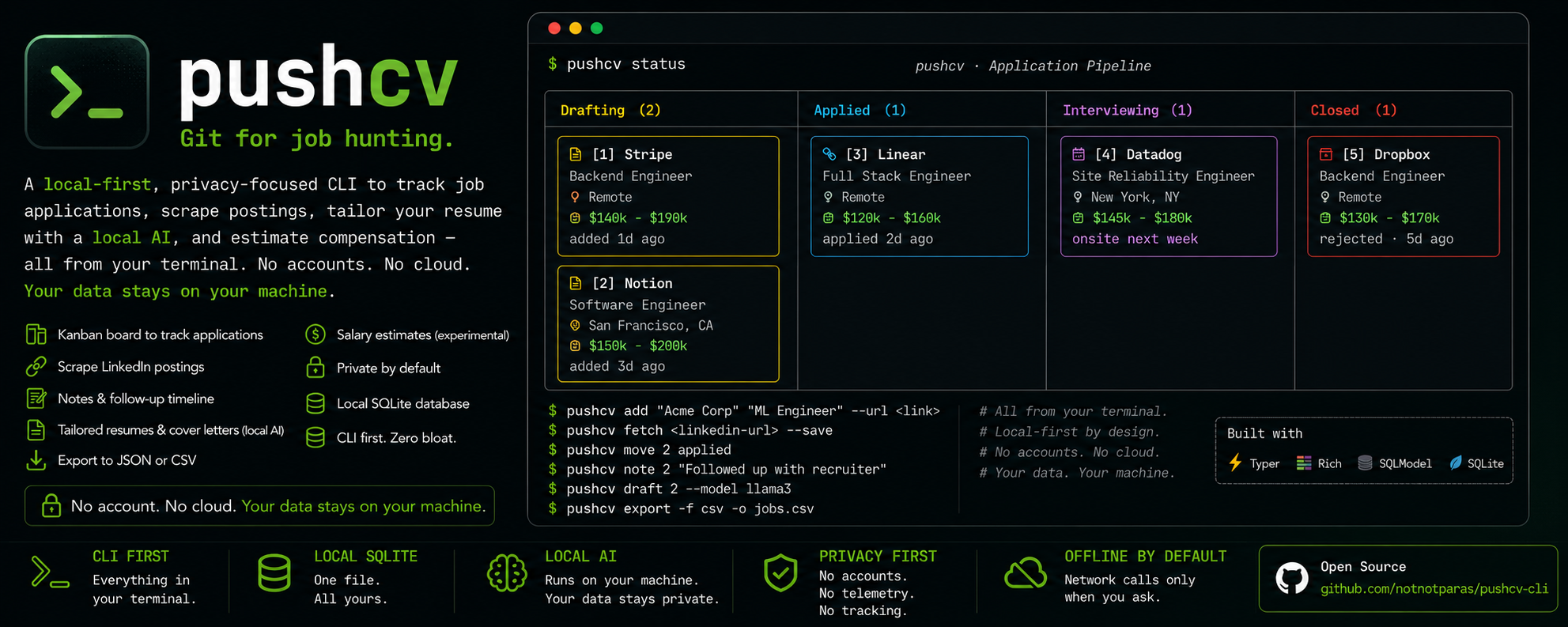
## 功能
- 📋 在终端的 Rich **看板**上**追踪申请** (草拟 → 已申请 → 面试中 → 已关闭)。
- ⏱ **跟进提醒** — pushcv 会记录你的投递时间,并直接在看板上标出停滞的申请(“15天前已申请 — 需要跟进吗?”)。使用 `pushcv note` 为每个职位保留带有日期的记录时间线。
- 🔎 一条命令**抓取 LinkedIn 招聘信息** — TLS/浏览器模拟(通过 `curl_cffi`)即使在网站进行抵抗时,也能访问公开的访客视图。
- 💰 基于实时网络数据 (DuckDuckGo) 的**薪资估算** *(实验性)*,可选择通过本地 AI 综合分析,以提供更紧凑、更锚定具体职位的范围。
- ✍️ **量身定制你的简历 — 以及求职信** — 使用**本地** LLM(通过 [LiteLLM](https://github.com/BerriAI/litellm) → 兼容 OpenAI 的服务器,例如 [Lemonade](https://github.com/lemonade-sdk/lemonade))针对任何已追踪的职位进行定制。无需 API 密钥,零成本,数据不作任何发送。
- 🔒 **默认隐私至上** — 仅使用一个本地 SQLite 数据库,无遥测,无账户。
- 📦 **你的数据归你所有** — 随时可以使用 `pushcv export` 将所有内容导出为 JSON 或 CSV 格式。
## 环境要求
- **Python ≥ 3.10**
- *(可选,用于 AI 功能)* 本地兼容 OpenAI 的推理服务器 — 例如 [Lemonade](https://github.com/lemonade-sdk/lemonade) — 用于提供对话模型。核心的追踪功能无需这些配置即可运行。
## 安装
推荐的方式是使用 [pipx](https://pipx.pypa.io/) — 它会在隔离的环境中安装 CLI,并将 `pushcv` 添加到你的 PATH 中。直接从仓库安装:
```
pipx install git+https://github.com/notnotparas/pushcv-cli.git
```
或者使用 pip:
```
pip install git+https://github.com/notnotparas/pushcv-cli.git
```
## 快速开始
```
pushcv init # create ./pushcv.db + ./profile.md
# → 在起草之前填写 profile.md(你的姓名、经验、技能)
pushcv add "Acme Corp" "Senior Engineer" # track a job manually
pushcv fetch "https://www.linkedin.com/jobs/view//" # …or scrape one
pushcv status # see your pipeline (Kanban board)
pushcv draft 1 # tailor a resume for job #1
pushcv move 1 applied # advance it on the board
pushcv note 1 "recruiter call Friday 3pm" # keep a dated timeline
pushcv show 1 # full details for one job
```
所有内容都会写入当前工作目录,因此请保留一个专用文件夹(例如 `~/job-hunt/`),并在其中运行 `pushcv`。
## 命令
| 命令 | 功能 |
|---------|--------------|
| `pushcv init` | 创建本地 `pushcv.db` 和 `profile.md` 模板。 |
| `pushcv add [--url]` | 手动添加职位(初始状态为*草拟*)。 |
| `pushcv fetch <url> [--save] [--debug]` | 抓取 LinkedIn 招聘信息;预览后确认保存。`--save` 跳过确认提示;`--debug` 转储原始 HTML 以便进行故障排除。 |
| `pushcv status` | 渲染看板。回填任何缺失的薪资估算。 |
| `pushcv move <n> <status>` | 将位置为 `n` 的职位移动到新状态 — 可以是某一列 (`drafting`, `applied`, `interviewing`, `closed`) 或同义词 (`offer`, `rejected`, `onsite`, `ghosted`, …)。 |
| `pushcv show <n>` | 显示位置为 `n` 的职位存储的所有信息 — 状态、日期、笔记以及完整的抓取描述。 |
| `pushcv note <n> "text"` | 在职位的时间线上添加带日期的笔记(在 `show` 中显示)。 |
| `pushcv export [-f json\|csv] [-o file]` | 导出所有已追踪的职位。默认输出到 stdout(支持管道);`-o` 写入文件。 |
| `pushcv draft <n> [--model] [--cover-letter]` | 为看板位置 `n` 的职位生成量身定制的、针对 ATS 优化的 Markdown 简历,并保存到 `drafts/`。状态将设置为*准备好申请*。使用 `--cover-letter`/`-c` 时,将改为起草一封简短的定制求职信(状态保持不变)。 |
| `pushcv delete <n> [--yes]` | 移除位置为 `n` 的职位(及其草稿)。首先会进行确认;`--yes` 可跳过确认。 |
## 简历与求职信定制(AI 设置)
`pushcv draft`(简历或 `--cover-letter`)以及可选的薪资综合分析,会通过 LiteLLM 使用**本地**语言模型,并指向一个兼容 OpenAI 的 endpoint:
- **Endpoint:** `http://localhost:13305/v1` (Lemonade 的默认端口)
- **默认模型:** `Qwen3-8B-GGUF` — 可以使用 `--model` 为每个命令单独覆盖,或者在 `main.py` 中修改 `DEFAULT_AI_MODEL`。
启动你的本地服务器(例如 Lemonade),加载一个对话模型,然后执行:
```
pushcv draft 1 --model Qwen3-8B-GGUF # tailored, ATS-optimized resume
pushcv draft 1 --cover-letter # short tailored cover letter
```
两者都严格基于你的 `profile.md` 生成 — 提示词禁止捏造雇主、日期或技能。如果服务器未运行,`draft` 会优雅地失败并显示清晰的错误信息,且**不会**损坏你的数据。任何信息都不会被发送到远程提供商。
## 薪资估算(实验性)
当你添加或抓取职位时,pushcv 会询问**一次**是否启用 AI 薪资估算(此选择会记录在 `.pushcv.json` 中):
- **网络提取(默认):** 从知名薪资网站(levels.fyi, Glassdoor, AmbitionBox, Payscale, …)解析数据并标明来源,例如 `💰 ₹27L - ₹35L · per ambitionbox.com`。无需模型。
- **AI 综合(主动开启):** 本地模型会将网络数据清理并整合为一个更紧凑、更锚定具体职位的范围(利用招聘信息中的资历要求以及来自 `profile.md` 的工作年限)。
估算值是一个** ballpark**(大概范围),而不是确切的报价 — 它们会随着实时的搜索结果而变化。引用的区间是参考信号,而不是确切的数字。货币单位会根据职位所在的位置进行推断(INR, USD, GBP, EUR, …)。
## 数据模型
单张 `job_application` 表(本地 SQLite,`pushcv.db`):
| 字段 | 类型 | 说明 |
|-------|------|-------|
| `id` | INTEGER | 主键,自增(内部使用)。 |
| `company` | VARCHAR | 必填。 |
| `title` | VARCHAR | 必填。 |
| `url` | TEXT | 招聘链接(可选)。 |
| `location` | TEXT | 来自 `fetch`(可选)。 |
| `description` | TEXT | 抓取的职位描述(可选)。 |
| `salary_estimate` | VARCHAR | 网络/AI 薪酬估算(可选)。 |
| `status` | VARCHAR | 流水线状态;默认为 `drafting`。 |
| `created_at` | TIMESTAMP | UTC 创建时间。 |
| `applied_at` | TIMESTAMP | 职位首次移动到*已申请*的时间(用于触发跟进提醒)。 |
| `notes` | TEXT | 来自 `pushcv note` 的带日期的时间线记录(可选)。 |
新增的列会在启动时自动迁移,因此升级 pushcv 绝不会破坏现有的数据库。
## 配置与文件
pushcv 写入的所有内容都存放在你的工作目录中:
| 路径 | 内容 |
|------|----------|
| `pushcv.db` | 你的申请记录 (SQLite)。 |
| `profile.md` | 你的主档案 — 简历定制的事实来源。 |
| `.pushcv.json` | 工作区级别的偏好设置(例如 AI 薪资估算开关)。 |
| `drafts/` | 生成的简历与求职信 Markdown 文件。 |
默认情况下,所有这些文件都会被 git 忽略 — 它们属于个人数据,不应被提交到版本库。仓库中包含了一个已填写的参考资料 [`profile.example.md`](profile.example.md),用于展示一份完整的档案是什么样的。
## 隐私与负责任的使用
- **无遥测,无账户,无云服务。** 你的数据始终保留在你的机器上。
- 该抓取工具仅供你针对正在申请的职位进行**个人使用**。请遵守目标网站的服务条款和速率限制;不要恶意请求 endpoint。
- 薪资数字是基于公开网络数据汇总的估算值 — 在依赖这些数据之前,请对照引用的来源进行核实。
## 开发
```
python3 -m venv .venv && source .venv/bin/activate
pip install -e ".[dev]" # editable install + test tooling
pushcv --help
pytest # run the helper test suite
```
项目布局(src/ 布局):
```
pushcv-cli/
├── pyproject.toml # PEP 621 metadata, pinned deps, `pushcv` entry point
├── README.md · LICENSE · CONTRIBUTING.md · .gitignore
├── profile.example.md # filled-in reference profile
├── tests/ # unit tests for the pure helpers
└── src/pushcv/
├── __init__.py # version
├── main.py # Typer app, DB engine, all commands, Kanban UI
├── models.py # SQLModel table (JobApplication)
├── scraper.py # LinkedIn fetch/parse (curl_cffi + BeautifulSoup)
├── search.py # DuckDuckGo salary search + extraction
├── ai_engine.py # LiteLLM → local model (resume + salary synthesis)
└── config.py # per-workspace preferences (.pushcv.json)
```
## 路线图 — 欢迎贡献!
这些任务的范围被界定为适合新手参与的 PR;请开启一个 issue 来认领:
- **为 `fetch` 接入更多招聘网站** — 首选 Greenhouse 和 Lever:两者都公开了干净的 JSON API (`boards-api.greenhouse.io`, `api.lever.co`),比 LinkedIn 友好得多,而且它们本来就是大多数外部申请链接的最终落地点。抓取器只需返回与 [scraper.py](src/pushcv/scraper.py) 中 `fetch_linkedin_job` 相同的字典结构即可。
- **扩展测试套件** — 目前 `tests/` 仅覆盖了纯粹的辅助函数;抓取器、薪资提取和命令流程仍需补充测试覆盖。
- **可选的依赖扩展** (`pushcv[ai]`),这样最小化安装就不会强行拉取 LLM 技术栈。
- **PDF 导出**,用于导出起草的简历/求职信(例如通过 pandoc 或 typst)。
## 许可证
[MIT](./LICENSE) © pushcv 贡献者</div><div><strong>标签:</strong>BeEF, DFIR, Python, Splunk, SQLite, 无后门, 本地大模型, 求职辅助工具, 爬虫, 简历优化, 逆向工具</div></article></div>
<!-- 人机验证 -->
<script>
(function () {
var base = (document.querySelector('base') && document.querySelector('base').getAttribute('href')) || '';
var path = base.replace(/\/?$/, '') + '/cap-wasm/cap_wasm.min.js';
window.CAP_CUSTOM_WASM_URL = new URL(path, window.location.href).href;
})();
</script>
</body>
</html>