jamesob/local-llm
GitHub: jamesob/local-llm
一份详尽的本地大模型硬件搭建与运行指南,涵盖从入门到顶配的设备清单、系统调优及Docker化模型推理配置。
Stars: 762 | Forks: 35
# jamesob 的本地运行 SOTA LLM 指南
*注意:除了表格,本 README 中的所有内容均非 AI 编写。*
口袋里有 $2k 闲钱,想体验一下本地、最先进的机器智能?
$40k 怎么样?
如果 Dario 和 Altman 让你感到胃灼热(他们应该会),请继续阅读,了解如何在本地运行这种新型计算。
在这个 repo 中,你会发现
- 我用于本地运行 SOTA 的硬件,
- 我购买它们的原因以及配置它们的鲜为人知的*秘密*,
- 我如何在本地运行语音转文本 (STT),
- 可直接运行的配置,用于在 Docker 容器中运行我认为不错的模型。
## 目录
| 章节 | 概要 |
|---|---|
| [你打算花多少钱?](#how-much-are-you-willing-to-spend) | $2k 能让你用上 Qwen 和不错的 STT(相当不错了!);$40k 能让你得到几乎媲美 Opus 的体验 |
| [基础系统](#base-system) | 上一代 EPYC + eBay DDR4,花费 $5.6k |
| [GPUs](#gpus) | 4× RTX PRO 6000,384GB VRAM(钱都花在这了) |
| [c-payne switch 子 BOM](#c-payne-pcie-gen4-switch-sub-bom-c-paynecom) | 来自 [c-payne.com](https://c-payne.com) 的独立 PCIe 交换机,让 GPUs 实现点对点通信 |
| [GPU 支架](#gpu-mount) | 一天的木工活 |
| [让交换机正常工作](#getting-the-pci-switches-to-work-properly) | BIOS 通道拆分、链路速率、ASPM |
| [Kernel / GRUB 参数](#kernel--grub-parameters) | `iommu=off` 否则 NCCL 会挂起 |
| [ACS 禁用](#acs-disable-critical-for-switch-p2p) | 将 P2P 流量保留在交换机架构内 |
| [GPU 功耗限制](#gpu-power-limiting) | 在 110V 电路上运行价值 $46k 的硅片 |
| [结果](#result) | Gen4 线路速率:27.5/50.4 GB/s,亚微秒级延迟 |
| [`runners/`](./runners) | 开箱即用的服务配置:[GLM-5.2-594B](./runners/GLM-5.2-594B):vLLM docker-compose,DCP4+MTP5,~80 t/s @ 460k ctx |
| [`runners/stt`](./runners/stt) | 使用 `whisper-large-v3` 的开箱即用语音转文本配置 |
| [`tools/`](./tools) | [`measure-gpu-speed.sh`](./tools/measure-gpu-speed.sh):P2P 带宽/延迟基准测试 |
| [资源](#resources) | rtx6kpro repo, c-payne |
## 我的配置
我很幸运/愚蠢地在它们更便宜的时候买了 4 块 RTX Pro 6000。由于现在 RAM 太贵了,我选择组装一台上一代 DDR4 系统来承载这些显卡,零件是从 eBay 上淘来的。这让我能够保持基础系统成本合理,同时依然获得大量的 VRAM。

我做的另一件有点不同寻常的事是使用了 PCIe4 交换机(来自 [c-payne.com](c-payne.com)。这让 GPUs 在张量并行的 allreduce 步骤中能够以线路速度“直接”相互通信,而不必通过 PCI 根复合体发送所有数据。这样做的好处是减少了显卡之间的延迟,同时降低了对昂贵 PCIe5 硬件的需求。

因此,我把钱花在了 VRAM 上(这才是关键),而不是 PCIe5/DDR5 基础系统上,因为截至 2026 年 7 月,后者的价格极其昂贵。
我的具体 BOM 详细如下。
### 你打算花多少钱?
#### ~$2k
一个绝佳的方案是使用 2 块 RTX 3090,总计拥有 **48GB VRAM**。然后你就可以运行 [Qwen3.6-27B](https://huggingface.co/Qwen/Qwen3.6-27B),这是一个非常棒的模型。
你还可以运行 SOTA 语音转文本 (STT) 模型 [`whisper-large-v3`](https://huggingface.co/openai/whisper-large-v3),我发现它非常有用。那只是一个模型——然后你可以通过我跨平台的 [`stt` 控制器](https://github.com/jamesob/stt)来访问它。
我发现本地 STT 出奇地有用——而且用起来很安心,不像托管的同类产品。你可以在 [`./runners/stt`](./runners/stt) 中找到一个开箱即用的配置,它只需要 Nvidia GPU 上有约 11GB 的 VRAM。
#### ~$40k
在这个价位上,你将获得模型智能上的进一步提升。非常接近 Claude Opus。
你需要购买 4 块 RTX 6000 Pro,总计拥有 **384GB VRAM**。
##### 适用于 4x RTX6kPRO 的当前最佳模型
| 日期 | 最佳模型 | 我的配置 |
|---|---|---|
| 2026-07 | [`GLM-5.2-Int8Mix-NVFP4-REAP-594B`](https://huggingface.co/madeby561/GLM-5.2-Int8Mix-NVFP4-REAP-594B) | [Runner 配置](./runners/GLM-5.2-594B) |
##### 其他方案
注意:这些是我的建议,但花你的钱还有很多完全可行的方式。例如,可能还有一种路线,与其购买 4 块 rtx6kpros,不如将大部分预算用于构建一个[互连的 4x DGX Spark 集群](https://youtu.be/QJqKqxQR36Y?si=MiKNYtIzut_5pnXy),总共有 512GB VRAM,并将其作为缓慢的超级大脑,驱动 Qwen3.7-27b 来快速完成死板重复的任务。
## 硬件
以下是我为这台 4x RTX 6000 pro 机器最终购买的硬件。

### 基础系统
一套适中的上一代 EPYC 系统,几乎全部零件都是在 eBay 上分批购买的。
| 组件 | 规格 | 价格 |
|---|---|---|
| 主板 | ASRock Rack ROMED8-2T (SP3, 7× PCIe 4.0 x16, 双 10GbE) | $715 |
| CPU | AMD EPYC Milan 7313P (16核 3.0GHz) | $504 |
| 内存 | 8× 16GB Crucial CT16G4RFD4213 DDR4 ECC RDIMM (共 128GB, eBay) | $642 |
| CPU 散热器 | Dynatron T17 SP3 塔式,280W TDP | $40 |
| 机箱 | AAAWave Sluice V2 开放式机架 | $100 |
| PSUs | 2× Super Flower 1700W | $750 |
| PCIe Switch | c-payne Microchip Switchtec PM40100 Gen4 (见下方子 BOM) | ~$1,330 |
| 引导 NVMe | 4TB M.2 | $291 |
| 存储 NVMe | (2块) 8TB M.2 (模型权重) | $1,200 |
| 风扇 | 3× 120mm PWM | $15 |
| **总计** | | **$5,587** |
### GPUs
| 组件 | 规格 | 价格 |
|---|---|---|
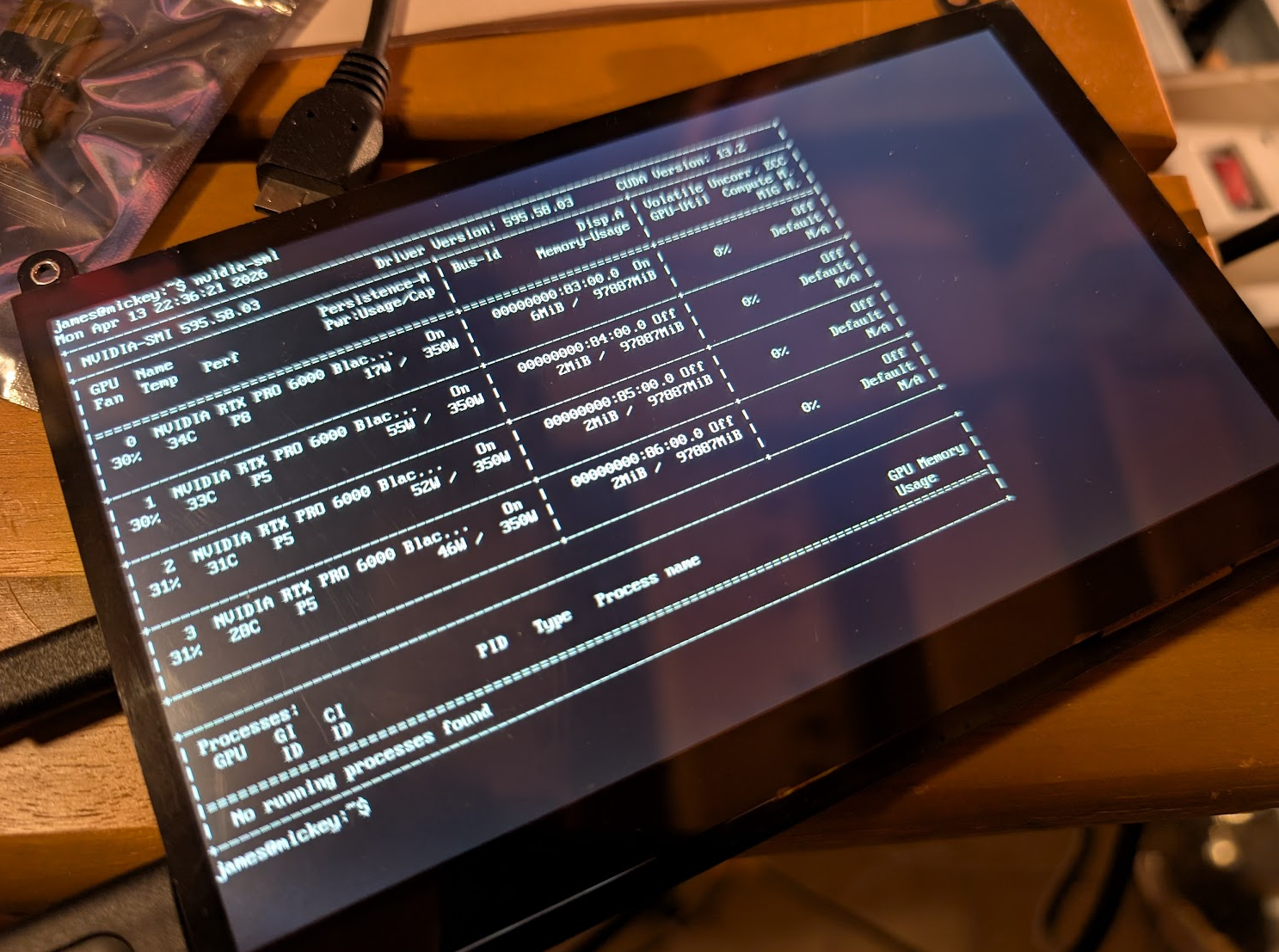
| GPUs | 4× NVIDIA RTX PRO 6000 Blackwell Workstation (每块 96GB, **共 384GB VRAM**) | **~$46,000** |
### c-payne PCIe Gen4 Switch 子 BOM (c-payne.com)
| 部件 | 数量 | 单价 (€) | 备注 |
|---|---|---|---|
| PCIe gen4 Switch 5× x16 — Microchip Switchtec PM40100 | 1 | 1.050 | 2× SlimSAS 8i 上行,5× x16 四宽距下行,aux x4 SlimSAS,3× 8-pin EPS 供电 |
| SlimSAS PCIe gen4 Host Adapter x16 — REDRIVER AIC (DS160PR810) | 1 | 140 | 插入 ROMED8-2T x16 插槽,为交换机上行供电 |
| SlimSAS SFF-8654 8i 线缆 — PCIe gen4 | 2 | ~30 | 每根承载 x8;成对 = x16 上行 |
| **总计** | | | **~€1,220 (~$1,330 USD)** |
### GPU 支架
我不得不为 PCI 交换机和 GPUs 定制了一个木质外壳,这花了大约一天的时间。

我发现 PCI 交换机自带的风扇非常吵而且似乎没什么用,所以我直接把它从板子上拔掉了。
### 囤积模型权重
我将所有模型权重保存在本地的 ZFS 文件系统中,该系统在这两块 8TB 硬盘上进行了复制,并挂载在 `~/storage`。
对于任何我想运行的模型,我都会先使用以下命令下载模型
```
hf download --local-dir ~/storage/
```
### 运行模型
一旦模型权重在本地缓存完毕,我就会为每个模型创建一个特定的目录,其中包含一个 `docker-compose.yml` 文件,将每个模型的运行隔离在其专属的 Docker 容器中。
你可以在 [`./runners/`](./runners) 中找到这些配置。
每个容器都以只读模式挂载 `~/storage/models`,以获取我在本地缓存的权重。
然后,我使用托管在另一台机器上的 VM 中的 `opencode` 来访问这些模型,它们的服务地址是 `http://clank.j.co:5000`。
我使用网络内部 DNS 服务器将 `clank.j.co` 指向 LLM 机器,但你也可以直接使用 `http://:5000`。
### 测试框架本身
我创建了一个 VM,并在上面运行了一个应用程序,它基本上只是为该 VM `~/src` 目录树中的每个文件夹创建一个 tmux 会话,然后运行一个 `opencode` 实例,该实例连接到推理机器的 HTTP API (`http://clank.j.co:5000`)。
让开源模型变得好用的一个关键是为它们配置合适的工具;我的 `skills/` 概括如下:
- camofox、kagi.com API key 和 searXNG 用于网页浏览和搜索,
- Telegram bot 用于通信和警报,
- 一个本地私有的 Gitea 实例用于源代码协作。
这台机器要么在会话中与我进行交互式协作,要么可以将其派生出去处理 Gitea issue 并在那里提交 PR。
所有这些都发生在一个沙箱化的 VM 中,它与宿主系统之间唯一的通信是通过共享的文件系统挂载完成的,因此它可以尽情折腾,安装任何它想安装的东西。
### 让 PCI 交换机正常工作
为了让主板不对 PCI 交换机的速度进行降级,需要大量折腾 BIOS。
#### BIOS 配置 (ROMED8-2T)
| 设置项 | 值 | 原因 |
|---|---|---|
| `Chipset Configuration → AMD PCIE Link Width` (交换机插槽) | **x16** (原为 x8/x8) | Bifurcation 拆分了插槽;上行链路在 Gen4 x8 下训练成功。需要连接两根 SlimSAS 8i 线缆(每根承载 x8)。 |
| PCIe Link Speed (交换机插槽) | **Gen4** (非 Auto) | Blackwell Gen5 设备在通过 Gen4 交换机自动向下协商时可能会训练失败并降至 Gen1。强制 Gen4 可以稳定运行。 |
| ASPM | **Disabled** | ASPM L1 会将空闲链路的速率降至 2.5GT/s。这就是 lspci 读数显示 "Gen1 downgraded" 的原因——链路在负载下实际上是以 Gen4 运行的(通过 p2pBandwidthLatencyTest 验证),但禁用 ASPM 可以消除这种表面上的警报以及任何重新训练的延迟。 |
| Re-Size BAR | **Enabled** | 完整暴露 96GB VRAM BAR 和 GPU P2P 所需。 |
| SR-IOV | **Disabled** | 裸金属推理;避免 IOMMU 开销和 P2P 干扰。 |
| Preferred IO | **Auto** | 可选择手动设置 → 总线 `81`(c-payne 交换机)以获得微小的延迟改善,但保持 Auto——这是一种压榨性能的优化,而不是修复,并且总线编号在 BIOS 更改后会发生偏移。 |
#### 降低 redriver 的增益
根据 c-payne 的建议,我确实使用[他的工具](https://c-payne.com/c-payne-tool)将增益降低到了 "lvl 3",这大概是整个过程中最繁琐的部分。
增益水平将取决于你的 SAS 连接线缆的长度。
#### 选择合适的 SAS 线缆
我搞砸了,直接从 c-payne 那里订购的线太少了,所以我在 Amazon 上购买了我认为是同款的 SAS 线缆。实际上存在微小的差异并导致了问题,我不得不重新订购线缆——所以请务必仔细检查你买到的是否是正确的配件!
## Kernel / GRUB 参数
```
# /etc/default/grub
GRUB_CMDLINE_LINUX="iommu=off amd_iommu=off nomodeset"
sudo update-grub
# nvidia_uvm P2P fix
echo 'options nvidia_uvm uvm_disable_hmm=1' | sudo tee /etc/modprobe.d/uvm.conf
sudo update-initramfs -u
```
如果没有 `iommu=off`,NCCL 在多 GPU P2P 通讯时会挂起。
## ACS 禁用(对交换机 P2P 至关重要)
如果启用 ACS(默认),P2P 流量会被迫通过 CPU 根端口反弹,而不是保留在交换机架构内,这完全失去了使用交换机的意义。
`pcie_acs_override` 需要打过补丁的 kernel,因此我们在运行时通过 setpci 将其禁用。
```
# /usr/local/bin/disable-acs.sh
#!/bin/bash
if [ "$EUID" -ne 0 ]; then
echo "ERROR: must be run as root"
exit 1
fi
for BDF in $(lspci -d "*:*:*" | awk '{print $1}'); do
setpci -v -s ${BDF} ECAP_ACS+0x6.w > /dev/null 2>&1
if [ $? -ne 0 ]; then
continue
fi
echo "Disabling ACS on $(lspci -s ${BDF})"
setpci -v -s ${BDF} ECAP_ACS+0x6.w=0000
done
```
在每次启动时通过 systemd oneshot 运行:
```
# /etc/systemd/system/disable-acs.service
[Unit]
Description=Disable PCIe ACS for GPU P2P
After=multi-user.target
[Service]
Type=oneshot
ExecStart=/usr/local/bin/disable-acs.sh
[Install]
WantedBy=multi-user.target
```
验证:`lspci -vvv | grep ACSCtl` 应该全部显示减号,并且 `nvidia-smi topo -m` 应该在所有四个 GPU 之间显示 **PIX**(而不是 PHB/NODE)。
使用 [`./tools/measure-gpu-speed.sh`](./tools) 即可轻松测量。
## GPU 功耗限制
为了避免安装 220V 电路,我(可能不太明智地)在一根 110V 电路上运行这台机器,但我对显卡进行了功率限制。
在启动时通过 systemd 应用持久化模式 + 功耗上限 (install-gpu-power-limit.sh):
```
sudo nvidia-smi -pm 1
sudo nvidia-smi -pl 350 # 350W per GPU (default 600W)
```
350W/GPU = 1,400W GPU 负载,专为 PSU 预算设计。在过渡性的单 1700W PSU 阶段(在 240V 电路之前),显卡以 ~260W 运行 (4×260 = 1,040W GPUs + ~280W 系统 ≈ 1,320W 总计)。
验证:`nvidia-smi --query-gpu=index,power.limit,power.draw --format=csv`
## 结果
上行:Gen4 x16(到 CPU 约 30 GB/s)。通过交换机的 P2P:**27.5 GB/s 单向 / 50.4 GB/s 双向,0.37–0.45 µs 延迟**,即 Gen4 线路速率。注意:如果在任何地方启用了 ASPM,在空闲时 lspci 可能仍会将下游 GPU 链路显示为 "2.5GT/s (downgraded)";这只是表面现象。链路在负载下会重新训练为 Gen4。
## 资源
- 一个经常更新的 repo,教你如何最大程度利用 4、6 或 8 块 RTX 6000 Pro 显卡:https://github.com/local-inference-lab/rtx6kpro
- 我使用的独立 PCI 交换机:https://c-payne.com
- RTX6kPRO discord 服务器;很多老哥在上面对新模型进行基准测试:https://discord.gg/QMNvFkuDN
标签:AI基础设施, DLL 劫持, Docker, 大语言模型, 安全防御评估, 本地部署, 版权保护, 硬件配置, 语音转文本, 请求拦截, 运维指南