HUANGCHIHHUNGLeo/claude-real-video
GitHub: HUANGCHIHHUNGLeo/claude-real-video
让任意 LLM 真正「看」视频的本地工具,通过场景感知的关键帧提取与去重,将视频转化为文本和图片供模型理解。
Stars: 779 | Forks: 40
# claude-real-video
[](https://pypi.org/project/claude-real-video/) [](https://pypi.org/project/claude-real-video/) [](LICENSE) [](https://news.ycombinator.com/item?id=48766005)
**让 Claude —— 或任何 LLM —— 真正地“看”视频。**
大多数 AI 工具并不能真正地*看*视频。把 YouTube 链接粘贴到 ChatGPT 里,它读的是**字幕**,而不是画面。Claude 根本不接受视频文件。即使是原生支持读取视频的 Gemini,也必须将其发送给 Google,并按**固定间隔**(默认为 1 fps)进行采样,因此快速的镜头切换往往会被漏掉。
`claude-real-video` 采用了一种不同的方式,而且是**在本地**进行的:只需指向一个 URL 或文件,它就会提取出*真正重要*的画面(每一次场景转换,而不是固定的配额),丢弃近乎重复的帧,转录音频,最后交给你一个整洁的文件夹,任何 LLM 都能读取。所有的处理都在你自己的机器上完成 —— 发送到任何地方的内容,仅仅是你在之后选择粘贴到 LLM 的画面/文本。
```
crv "https://www.youtube.com/watch?v=..."
# → crv-out/frames/*.jpg + crv-out/transcript.txt + crv-out/MANIFEST.txt
```
然后将画面和 `MANIFEST.txt` 放入 Claude / ChatGPT / Gemini 中并开始提问。
不需要进行 LLM 相关的工作?它也可以作为一个**通用的视频关键帧提取器** —— 具备场景转换检测和去重功能,无需下载任何 ML 模型。
**使用 Claude Code?** 将其安装为技能,让 Claude 自己观看视频:
```
pip install claude-real-video
mkdir -p ~/.claude/skills && cp -r skills/claude-real-video ~/.claude/skills/
```
然后只需将视频链接粘贴到 Claude Code 中即可提问。
**0.3.0 版本新特性** —— 告诉它你*为什么*观看,并保存它的发现:
```
crv "https://youtu.be/..." --why "find the pricing strategy" --kb ~/notes
```
`--why` 让分析聚焦于你关心的内容,而不是通用的摘要;`--kb` 将结果保存为你自己笔记文件夹中带有日期的笔记,这样它就不会被埋没在 `crv-out` 里了。
## 为什么不直接采样帧?
大多数“让 LLM 看视频”的脚本(以及 Gemini 自己的 pipeline)都是按**固定间隔**抓取帧——例如每秒一帧。这会对静态的录屏过度采样,而对快速剪辑的视频采样不足。`claude-real-video` 则更聪明:
| | 固定间隔采样 | **claude-real-video** |
|---|---|---|
| 帧选择 | 每隔 N 秒 | **场景转换检测** + 密度下限 |
| 重复镜头(A-B-A 切换) | 每次都会再次发送 | **滑动窗口去重**,每个镜头只发送一次 |
| 静态幻灯片(10 分钟) | 约 600 个几乎完全相同的帧 | **缩减至 1**(去重) |
| 快速剪辑视频 | 错过采样点之间的帧 | 捕捉每一次视觉变化 |
| 音频 | 经常被忽略 | 带有语言检测的 Whisper 转录 |
| 处理发生的位置 | 通常在别人的云端 | **在你的机器上**(你可以自行决定之后与 LLM 分享哪些内容) |
| 输入 | 通常仅限本地文件 | **URL (yt-dlp) 或本地文件** |
你向模型输入的帧*更少、但更有意义* —— 更节省 context,理解更深刻。
## 安装
```
pip install claude-real-video # core (frames + dedup)
pip install "claude-real-video[whisper]" # + audio transcription
```
### 系统要求:ffmpeg
`ffmpeg` / `ffprobe` 用于提取帧和音频,并且无法通过 pip 安装。只需安装一次:
| 操作系统 | 命令 |
|---|---|
| **macOS** | `brew install ffmpeg` |
| **Linux** | `sudo apt install ffmpeg`(或你所用发行版的包管理器) |
| **Windows** | `winget install Gyan.FFmpeg` — 或 `choco install ffmpeg` — 或[下载一个构建版本](https://www.gyan.dev/ffmpeg/builds/)并将其 `bin\` 文件夹添加到你的 `PATH` 中 |
验证它是否在你的 `PATH` 中:
```
ffmpeg -version
```
转录功能使用 `whisper` CLI(通过 `[whisper]` 额外组件安装,或执行 `pip install openai-whisper`)。Whisper 也依赖 ffmpeg。
支持在 **macOS、Windows 和 Linux** 上运行 —— 要求 Python 3.10+。
## 用法
```
# YouTube / Instagram / TikTok / ... 链接
crv "https://www.instagram.com/reel/XXXX/"
# 本地文件,English transcript,输出到 ./out
crv lecture.mp4 -o out --lang en
# 仅提取 Frames,无 transcription
crv clip.mp4 --no-transcribe
# Login-gated video(你自己 / 已授权使用):传入 Netscape cookie 文件
crv "https://..." --cookies cookies.txt
```
`python -m claude_real_video ...` 也可以作为 `crv` 的别名。
### 选项
| 参数 | 默认值 | 含义 |
|---|---|---|
| `-o, --out` | `crv-out` | 输出目录 |
| `--scene` | `0.30` | 场景转换敏感度(值越小 = 帧数越多) |
| `--fps-floor` | `1.0` | 每隔 N 秒至少一帧 |
| `--max-frames` | `150` | 总帧数的硬性上限 |
| `--lang` | `auto` | Whisper 语言(`en`, `zh`, `auto` 等) |
| `--dedup-threshold` | `8` | 必须改变的像素百分比,该帧才算作新帧;值越高 = 帧数越少 |
| `--dedup-window` | `4` | 与保留的最后 N 个帧进行比较 —— 模型已经看过的镜头不会在镜头切走后又再次出现(`1` = 仅与相邻帧比较) |
| `--report` | 关闭 | 将丢弃的帧保留在 `./dropped` 中 + 生成 `report.html` 可视化每一次保留/丢弃的决定 |
| `--no-transcribe` | 关闭 | 跳过音频 |
| `--keep-audio` | 关闭 | 同时保存**完整原声带**(`audio.m4a`),以便音频模型可以真正*听到*它 |
| `--why` | – | 观看的原因,例如 `--why "find the pricing strategy"` —— 会被写入 `MANIFEST.txt`,以便模型以此为视角进行分析,而不是生成通用的摘要 |
| `--kb` | – | 同时将分析结果作为带有日期的 markdown 笔记保存到此文件夹中(你的 Obsidian 库、笔记目录等)—— 这样它就能融入你的知识库,而不是在 `crv-out` 中被遗忘 |
| `--cookies` | – | 用于受登录限制源的 Netscape cookie 文件 |
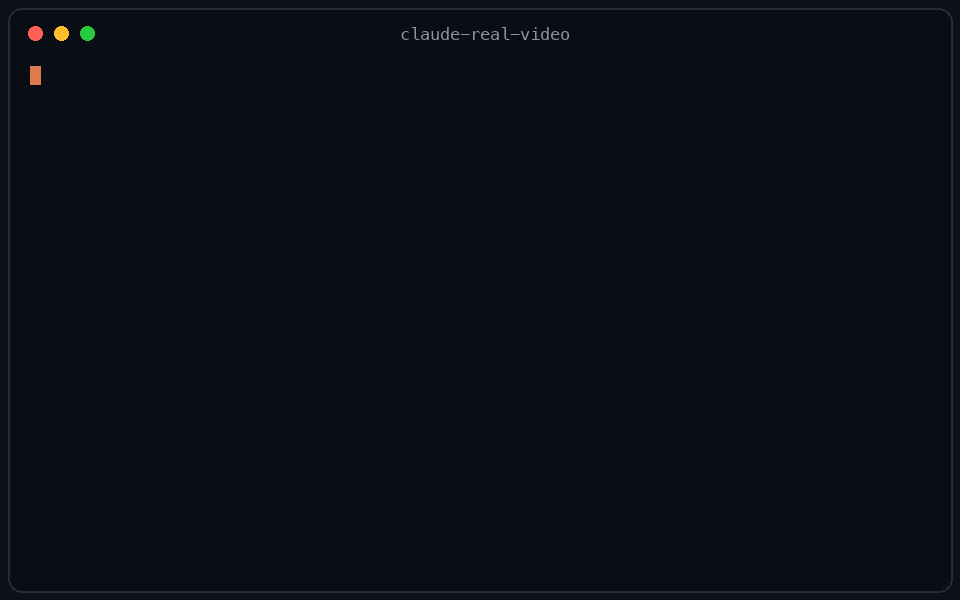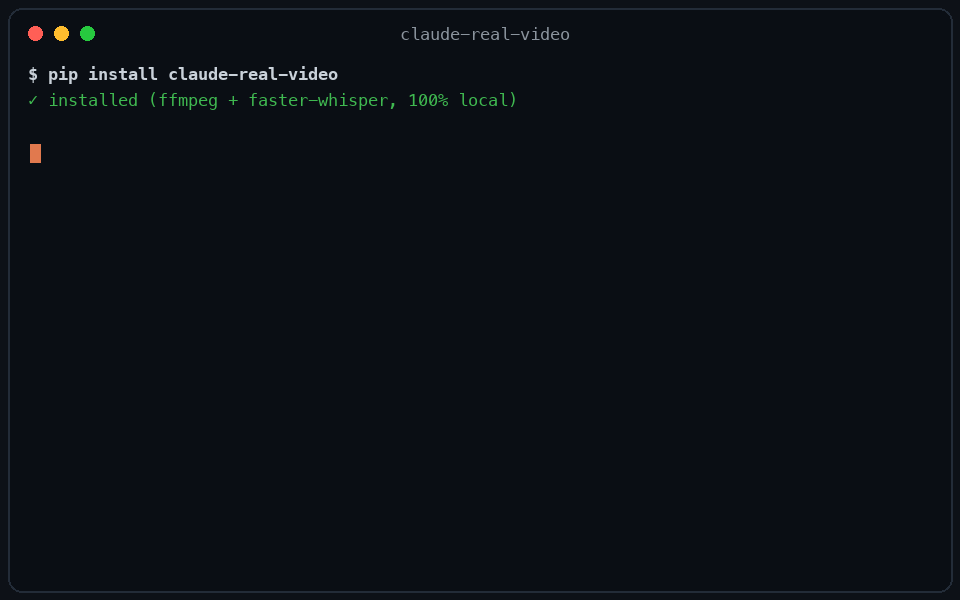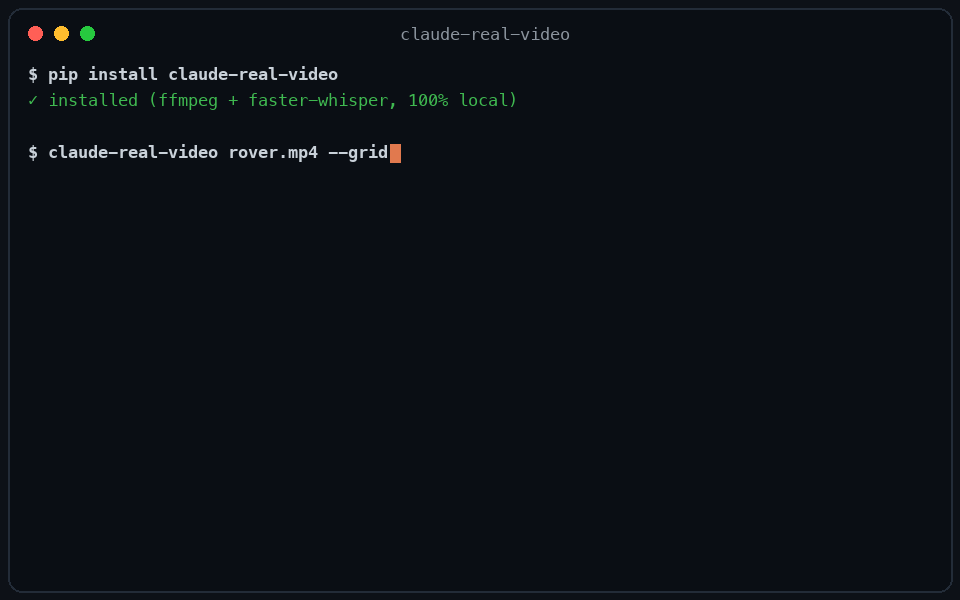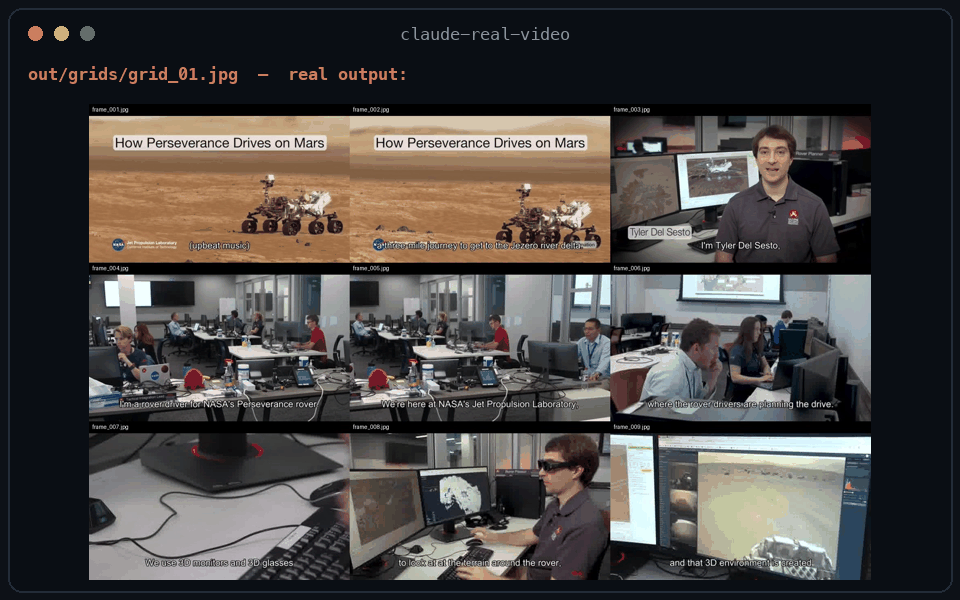
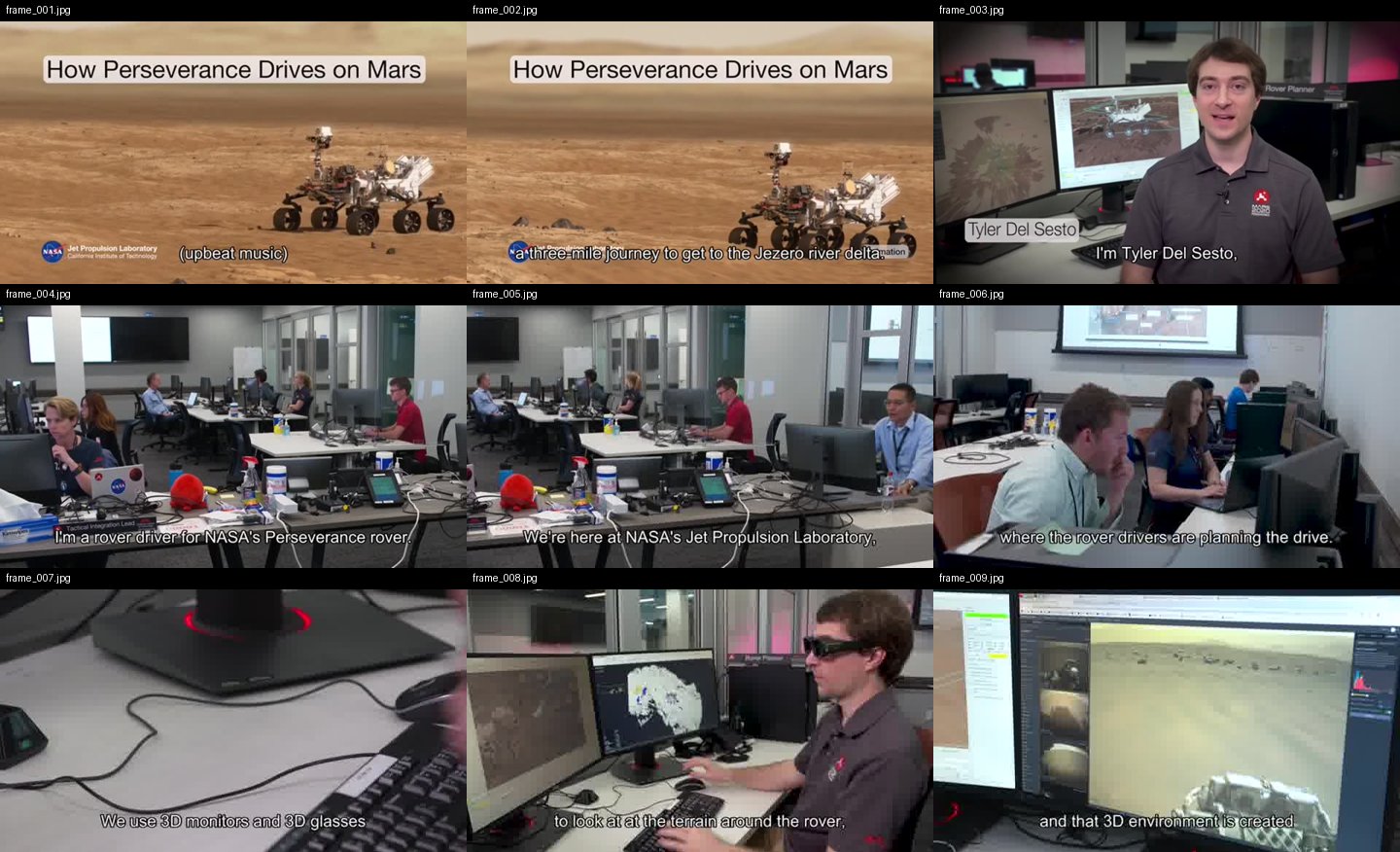
### `--grid` 输出的效果
一张联系表 = 按顺序排列的九个连续关键帧,每个单元格上都有文件名 —— 模型读取的是连贯的序列,而不是散落的静止画面:
## 从 Python 中使用
```
from claude_real_video import process
r = process("https://youtu.be/...", "out", lang="en")
print(r.frame_count, r.transcript_path)
```
## 工作原理
1. **获取** —— 对 URL 使用 `yt-dlp`(可选 cookies),或复制本地文件。
2. **提取** —— 一次按时间顺序的 `ffmpeg select` 过程会抓取每一次场景转换,*外加*一个密度下限(每隔 `--fps-floor` 秒至少一帧),因此快速切换和缓慢的屏幕录像都能被兼顾。
3. **去重** —— 真实的像素差异(下采样 RGB,而不是感知哈希 —— 哈希在面对纯色和等亮度的色调变化时会失效)与保留的最后 `--dedup-window` 帧的**滑动窗口**进行对比,因此 A-B-A 切换不会重复发送模型已经看过的镜头。`--report` 会生成 `report.html`,展示每一次保留/丢弃的决定及其差异百分比,方便进行调优。
4. **文本** —— 如果视频**已经有字幕**(本地文件旁挂载的 `.srt`/`.vtt` 文件,或内嵌的字幕轨道),它们将被直接用作转录文本 —— 比重新转录更快、更准确。只有在没有任何字幕的情况下,它才会回退到对音频使用 **Whisper**(如果没有音频则会干净地跳过)。
5. **音频** *(可选,`--keep-audio`)* —— 保存**完整的原始音轨**(`audio.m4a`:包含音乐 + 语音 + 音效,尽可能进行无损复制)。转录文本只包含*文字*;而音频文件允许具备听辨能力的模型(Gemini、GPT-4o 等)真正*听到*其中的音乐和语调。
6. **清单** —— `MANIFEST.txt` 会为模型总结所有内容。
因此,模型可以**看到**(关键帧)、**阅读**(转录文本),并且 —— 通过 `--keep-audio` —— **听到**(完整原声带)视频。转录文本是任何模型都能读取的纯文本;该工具**不会将字幕烧录到视频中** —— 烧录是一种呈现选择,并不是让视频具备 AI 可读性所必需的。
## 注意事项
- 仅下载你有权下载的内容。`--cookies` 选项适用于你自己的授权访问 —— 请勿在代码仓库中携带凭据。
- 重新运行会覆盖输出目录。
## crv Pro —— 理解视频是*如何*拍摄的
**免费版本会告诉你的 AI 屏幕上有什么。crv Pro 则会告诉它视频是如何拍摄的 —— 以及为什么有效。** 摄像机运动、剪辑节奏、动作爆发,外加带有一个 `--breakdown` 标志的报告:钩子分析、节奏曲线、镜头语言、Reels 算法视角,以及一套你的 LLM 可以用来完成完整视频拆解的标准。
这款免费工具会告诉 LLM 屏幕上有**什么**。一堆关键帧无法告诉它视频是如何运动的 —— 即镜头的运用和节奏。
**crv Pro** 在此处所有功能的基础上,增加了 `--motion` 通道:
- **镜头运动分类** —— 将每一个镜头标记为静止 / 平移 / 倾斜 / 缩放 / 手持(已通过真实基准视频验证)
- **剪辑节奏** —— 镜头列表、每分钟切换次数,以及节奏在整个视频中是如何变化的
- **动作爆发** —— 对高动态的镜头提取间隔 0.2 秒的帧序列,让模型读取运动轨迹,而不是靠猜
所有这些都作为纯文本保存在同一个清单文件中,依然是 100% 本地处理。一次性支付 $19 → **https://leoaido.com/crv-pro/**
## 许可证
MIT
标签:AI辅助, DLL 劫持, Python, 关键帧提取, 大语言模型, 无后门, 本地工具, 视频处理, 逆向工具