kaurjasmmender/Fraud-Detection-Dashboard
GitHub: kaurjasmmender/Fraud-Detection-Dashboard
一个端到端信用卡欺诈检测系统,在严重不平衡数据集上结合XGBoost建模与业务成本阈值优化,并通过FastAPI和Power BI提供预测服务与可视化。
Stars: 0 | Forks: 0
# 信用卡欺诈检测
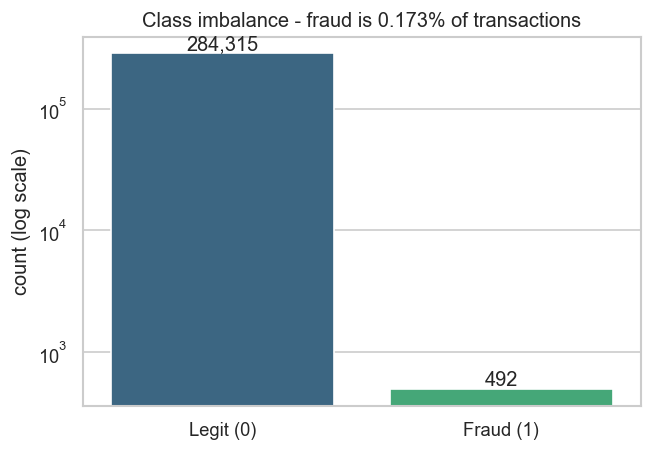
一个端到端机器学习系统,用于在严重不平衡的数据集(**0.17% 欺诈率**)上检测信用卡欺诈交易——从基于 SQL 的 EDA,到带有**业务驱动决策阈值**的 XGBoost 模型,并通过 FastAPI 端点提供服务,将数据输入至 Power BI 仪表板。
## 核心结果
| 指标 (留存测试集) | XGBoost | 逻辑回归基线 |
|---|---|---|
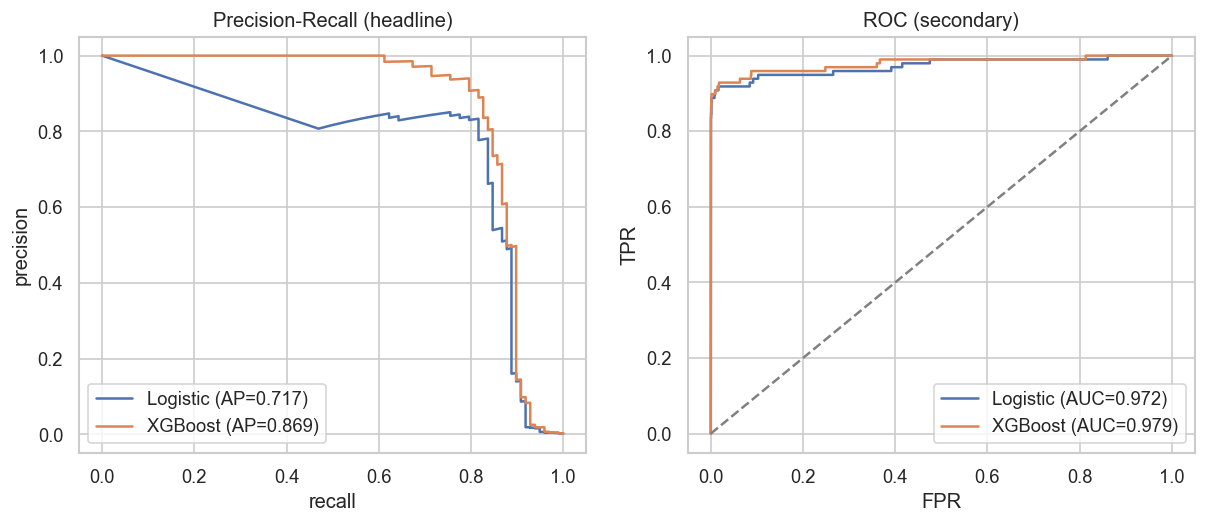
| **PR-AUC** (核心) | **0.869** | 0.718 |
| ROC-AUC (次要) | 0.979 | — |
| 5折交叉验证 PR-AUC | 0.852 ± 0.020 | — |
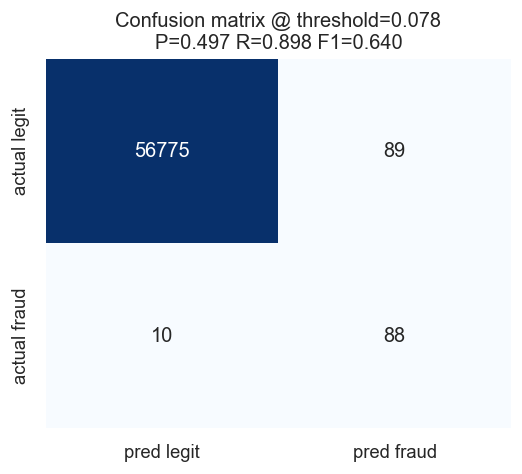
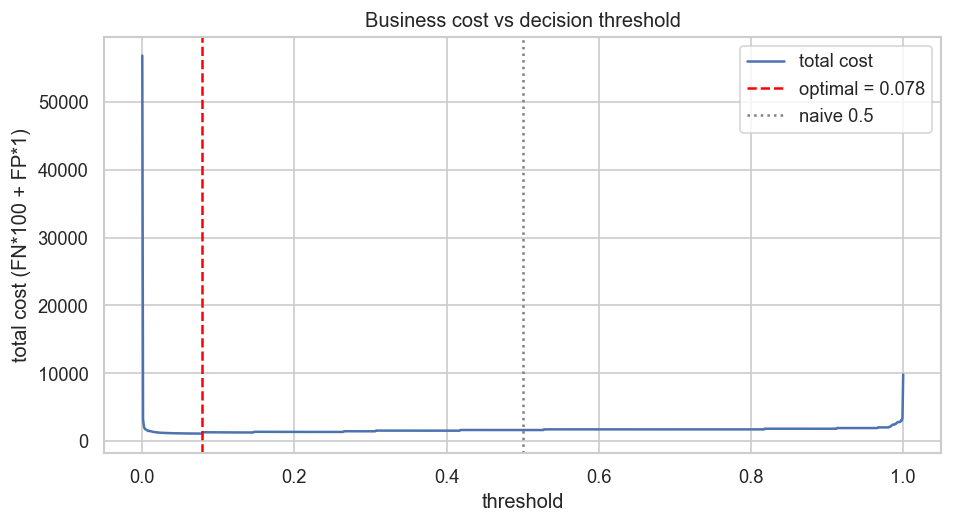
在**基于成本的阈值 (0.078)** 下,该模型捕获了**约 90% 的欺诈**
(recall 为 0.898),同时将测试集中 98 起欺诈案例中的漏报数量降至仅 10 起。
## 工作原理
```
creditcard.csv ──► SQLite ──► data_loader ──► features ──► train ──► evaluate
(raw data) (fraud.db) (load+split) (scale) (XGBoost) (metrics)
│
▼
score.py ──► outputs/scored_transactions.csv ──► Power BI
api/ ──► FastAPI /predict, /health
```
该流水线强制执行了实际会被评估的规则:
1. **无数据泄露** —— 分层的训练/测试拆分发生在缩放*之前*;
缩放器仅在训练拆分集上进行拟合。
2. **仅重采样训练数据** —— `scale_pos_weight` (≈577) 在 XGBoost 的损失函数中重新加权了欺诈类别;测试集保留了真实世界的不平衡状态。
3. **正确的指标** —— 核心指标为 PR-AUC;报告了 F1、指定精确率下的召回率 (recall-at-precision) 以及混淆矩阵;展示了 ROC-AUC 但未作为核心。
4. **业务驱动的阈值** —— 该截断值最小化了总成本,其中漏报的欺诈 (FN) 权重是被拦截的合法客户 (FP) 的 **100 倍**,而不是简单的 0.5。
5. **可复现性** —— 全局使用唯一的 `RANDOM_SEED`;锁定依赖项。
## 精选可视化
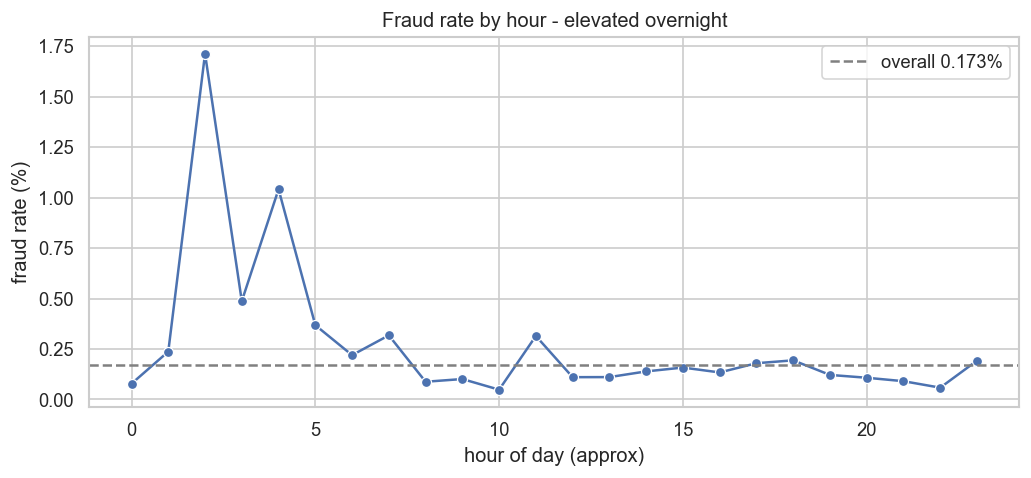
**类别不平衡与欺诈时间分布**
**模型性能 (PR 与 ROC,基线 vs XGBoost)**
**基于成本阈值的混淆矩阵**
**通过最小化业务成本来选择阈值**
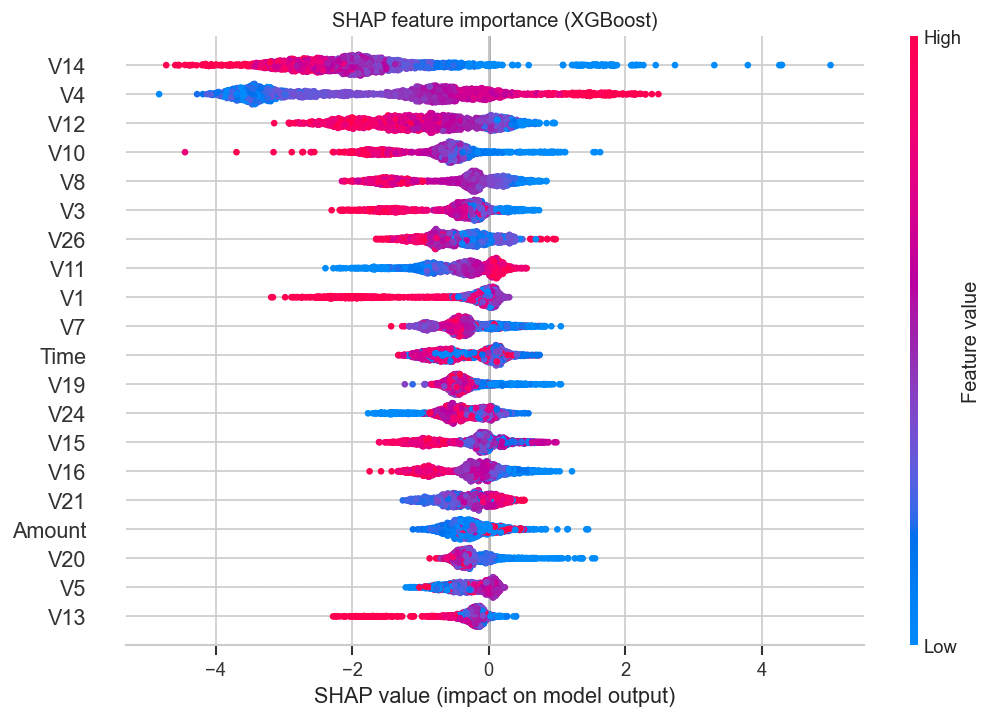
**驱动模型的因素 (SHAP)**
## 技术栈
- **数据 / 数据库:** Python, pandas, SQLite (通过 SQLAlchemy)
- **建模:** scikit-learn, XGBoost, imbalanced-learn
- **评估 / 可视化:** scikit-learn 指标, matplotlib, seaborn, SHAP
- **服务:** FastAPI, uvicorn, pydantic
- **仪表板:** Power BI (基于 `outputs/scored_transactions.csv` 构建)
## 项目结构
```
sql/ 01_schema.sql, 02_eda_queries.sql # load CSV into SQLite + EDA
src/ config, data_loader, features, # reusable pipeline
train, evaluate, score
api/ main.py, schema.py, test_api.py # FastAPI serving layer
notebooks/ 01_eda → 04_threshold_analysis # narrative, executed w/ outputs
reports/ model_card.md, figures/ # documentation + plots
models/ *.pkl (gitignored) # trained model + scaler
outputs/ scored_transactions.csv # dashboard input
```
有关完整的模型文档(预期用途、评估、局限性、伦理),请参阅 [reports/model_card.md](reports/model_card.md)
。
## 快速开始
### 1. 设置
```
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
```
### 2. 获取数据
从
[Kaggle](https://www.kaggle.com/mlg-ulb/creditcardfraud) 下载 `creditcard.csv`,并将其放置在
`data/raw/creditcard.csv`(已被 gitignore 忽略 — 切勿提交)。
### 3. 导入 SQLite
```
sqlite3 data/fraud.db < sql/01_schema.sql
sqlite3 data/fraud.db ".import --csv --skip 1 data/raw/creditcard.csv transactions"
```
### 4. 训练、评估、评分
```
python -m src.train # trains XGBoost, saves model + scaler, prints CV/PR-AUC
python -m src.evaluate # PR-AUC, ROC-AUC, recall@precision, cost-based threshold
python -m src.score # writes outputs/scored_transactions.csv for Power BI
```
### 5. 提供 API 服务
```
uvicorn api.main:app --reload
```
- `GET /health` → `{"status": "ok"}`
- `POST /predict` → `{ "probability": ..., "is_fraud": ..., "threshold": 0.078 }`
- 交互式文档位于
```
# /predict 需要全部 30 个 features (Time, V1..V28, Amount) — 查看一个现成的示例请见 /docs
curl -X POST http://127.0.0.1:8000/predict \
-H "Content-Type: application/json" \
-d '{"Time":0.0,"V1":-1.36,"V2":-0.07, ... ,"V28":-0.02,"Amount":149.62}'
```
运行 API 测试:
```
python -m api.test_api # or: pytest api/test_api.py
```
## Notebooks
已执行并嵌入了输出 — 可直接在 GitHub 上查看。
| Notebook | 内容 |
|---|---|
| [01_eda](notebooks/01_eda.ipynb) | 基于 SQL 的 EDA、不平衡情况、按小时统计的欺诈、对 Amount 进行 Mann–Whitney 检验 |
| [02_preprocessing](notebooks/02_preprocessing.ipynb) | 分层拆分、RobustScaler、`scale_pos_weight` vs SMOTE |
| [03_modeling](notebooks/03_modeling.ipynb) | 基线 → XGBoost、PR/ROC 曲线、交叉验证 (CV)、SHAP |
| [04_threshold_analysis](notebooks/04_threshold_analysis.ipynb) | 基于成本的阈值 + 对 FN:FP 比率的敏感性分析 |
## 局限性
特征 `V1`–`V28` 是匿名的 PCA 成分,因此模型无法为决策提供人类可读的理由。它是在 2013 年为期两天的交易数据上进行训练的(模式会发生漂移),并且在所选阈值下精确率约为 0.50 —— 假设在采取任何面向客户的行动之前,需要经过人工审核步骤。完整讨论请见
[model card](reports/model_card.md)。
标签:Apex, AV绕过, FastAPI, Power BI, SQL, XGBoost, 多线程, 数据科学, 机器学习, 欺诈检测, 系统审计, 资源验证, 逆向工具