## 📋 目录
点击展开
- [🧠 关于本项目](#-about-the-project)
- [✨ 核心特性](#-key-features)
- [⚙️ 工作原理](#️-how-it-works)
- [🧮 30 项特征](#-the-30-features)
- [📊 模型基准测试](#-model-benchmarks)
- [🛠️ 技术栈](#️-tech-stack)
- [📁 项目结构](#-project-structure)
- [🚀 快速开始](#-getting-started)
- [💻 用法](#-usage)
- [📂 数据集](#-dataset)
- [🏆 结果与分析](#-results-and-analysis)
- [🛣️ 路线图](#️-roadmap)
- [🤝 贡献](#-contributing)
- [📄 许可证](#-license)
- [👤 作者](#-author)
## 🧠 关于本项目
网络钓鱼攻击占全球**数据泄露的 90% 以上**。攻击者通过创建极具欺骗性的虚假网站来窃取凭证、财务详情和个人信息——而传统的基于规则的过滤器越来越难以应对。
本项目通过**机器学习**解决了这一问题。该模型不再依赖会过期的黑名单,而是学习让 URL 显得可疑的结构模式——域名年龄、重定向链、锚文本比率、HTTPS 使用情况以及其他 26 种信号——并能泛化到从未见过的 URL。
### 为什么选择机器学习?
| 方法 | 局限性 |
|----------|-----------|
| 黑名单过滤 | 只能捕获已知的钓鱼网站 |
| 基于规则的启发式算法 | 脆弱且极易被绕过 |
| ✅ 机器学习 | 学习模式,能泛化到新的威胁 |
### 本项目的亮点
- **30 个手工提取的特征**,涵盖 URL 结构、域名情报、HTML 内容和网络信誉
- **在同一数据集上对 10 个模型进行了正面对比测试**
- **97.4% 的准确率**和 99.4% 的召回率——几乎可以捕获所有钓鱼 URL
- **生产级 Flask 应用**——提供实时 Web 界面,支持 Heroku 部署
## ✨ 核心特性
```
🔍 Real-time URL analysis — Results in seconds
🤖 Gradient Boosting Classifier — Best-in-class accuracy
📊 Probability score display — Not just yes/no, but a confidence %
🌐 30-feature extraction engine — Deep structural URL analysis
🛡️ 99.4% phishing recall — Misses almost nothing
⚡ Lightweight Flask app — Fast, clean, deployable anywhere
📓 Full EDA Jupyter Notebook — Transparent, reproducible research
```
## ⚙️ 工作原理
```
┌─────────────────────────────────────────────────────────────┐
│ USER INPUT │
│ Paste any URL into the web form │
└──────────────────────────┬──────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ FEATURE EXTRACTION │
│ FeatureExtraction class analyses the URL across 4 layers │
│ │
│ ① URL Structure ② Domain Intelligence │
│ ③ HTML Content ④ Web Reputation │
│ │
│ Outputs: 30 numerical features │
└──────────────────────────┬──────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ GRADIENT BOOSTING CLASSIFIER │
│ Pre-trained on 11,055 labelled URLs │
│ Outputs: class prediction + probability score │
└──────────────────────────┬──────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ RESULT │
│ ✅ "85.3% safe to visit" │
│ ⚠️ "12.1% safe — likely phishing" │
└─────────────────────────────────────────────────────────────┘
```
## 🧮 30 项特征
特征引擎通过四个分析层级提取信号:
### 🔗 第一层 — URL 结构(7 项特征)
| 序号 | 特征 | 信号 |
|---|---------|--------|
| 1 | URL 中包含 IP 地址 | 钓鱼者使用 IP 来绕过域名信誉检查 |
| 2 | URL 长度 | 合法 URL 平均约 54 个字符;钓鱼 URL 通常更长 |
| 3 | URL 缩短服务 | 使用 bit.ly 等服务来隐藏恶意目的地 |
| 4 | `@` 符号 | 强制浏览器忽略 `@` 之前的所有内容 |
| 5 | 重定向 `//` | 位置 7 之后的双斜杠表示重定向 |
| 6 | 域名中的前缀/后缀 `-` | 带连字符的域名会模仿合法品牌(例如 `pay-pal.com`) |
| 7 | 子域名数量 | 深度嵌套的子域名是常见的钓鱼模式 |
### 🌐 第二层 — 域名情报(5 项特征)
| 序号 | 特征 | 信号 |
|---|---------|--------|
| 8 | HTTPS 协议 | 缺少 HTTPS 是一个危险信号 |
| 9 | 域名注册时长 | 较短的注册时间表明是一次性域名 |
| 10 | Favicon 来源 | 从外部域名加载的 Favicon 暴露了欺骗行为 |
| 11 | 非标准端口 | 使用异常端口来绕过标准流量过滤器 |
| 12 | 域名中的 HTTPS Token | 域名本身包含“https”是一种欺骗手段 |
### 🖥️ 第三层 — HTML 和 JavaScript(11 项特征)
| 序号 | 特征 | 信号 |
|---|---------|--------|
| 13 | 请求 URL 比率 | 高比例的外部资源(图片、音频)表明是克隆网站 |
| 14 | 锚点 URL 比率 | 指向与宿主不同域名的链接 |
| 15 | Script/Link 标签比率 | 比例失调的外部脚本 |
| 16 | 服务器表单处理程序 | 表单提交到 `about:blank` 或域外 |
| 17 | 信息邮件 (`mailto:`) | 在表单中使用 `mailto:` 而不是服务器端处理程序 |
| 18 | 异常 URL | 主机名与 WHOIS 注册数据不匹配 |
| 19 | 网站转发 | 超过 2 次重定向属于可疑;4 次及以上属于高度可疑 |
| 20 | 状态栏定制 | 使用 `onmouseover` 来伪装真实的链接目的地 |
| 21 | 禁用右键 | 通过 JavaScript 阻止右键点击以防止检查 |
| 22 | 弹出窗口 | 激进的 `alert()` 用法以窃取凭证 |
| 23 | Iframe 重定向 | 加载恶意 payload 的隐藏 iframe |
### 📈 第四层 — 网络信誉(7 项特征)
| 序号 | 特征 | 信号 |
|---|---------|--------|
| 24 | 域名年龄 | 钓鱼域名通常存在不到 6 个月 |
| 25 | DNS 记录 | 没有 DNS 记录是虚假域名的强烈指标 |
| 26 | 网站流量 | 较低的 Alexa 排名暗示这是一个不知名或新创建的网站 |
| 27 | PageRank | 较低的 PageRank 与钓鱼相关 |
| 28 | Google 索引 | 未被索引的页面通常是恶意的 |
| 29 | 指向页面的链接 | 极少的外部链接表明这是一个全新的虚假网站 |
| 30 | 统计报告 | 匹配已知钓鱼黑名单的 URL/IP |
## 📊 模型基准测试
十个分类器在相同的训练/测试集划分下进行了训练和评估:
| 排名 | 模型 | 准确率 | F1 分数 | 召回率 | 精确率 |
|:----:|-------|:--------:|:--------:|:------:|:---------:|
| 🥇 | **Gradient Boosting Classifier** | **0.974** | **0.977** | **0.994** | **0.986** |
| 🥈 | CatBoost Classifier | 0.972 | 0.975 | 0.994 | 0.989 |
| 🥉 | XGBoost Classifier | 0.969 | 0.973 | 0.993 | 0.984 |
| 4 | Multi-layer Perceptron | 0.969 | 0.973 | 0.995 | 0.981 |
| 5 | Random Forest | 0.967 | 0.971 | 0.993 | 0.990 |
| 6 | Support Vector Machine | 0.964 | 0.968 | 0.980 | 0.965 |
| 7 | Decision Tree | 0.960 | 0.964 | 0.991 | 0.993 |
| 8 | K-Nearest Neighbors | 0.956 | 0.961 | 0.991 | 0.989 |
| 9 | Logistic Regression | 0.934 | 0.941 | 0.943 | 0.927 |
| 10 | Naive Bayes Classifier | 0.605 | 0.454 | 0.292 | 0.997 |
### 特征重要性

**最重要的 3 个特征:**
1. 🔒 **HTTPS** — 是否存在有效的证书
2. ⚓ **AnchorURL** — 指向域外的链接比例
3. 📡 **WebsiteTraffic** — Alexa 流量排名
## 🛠️ 技术栈
| 分类 | 技术 | 用途 |
|----------|-----------|---------|
| **语言** | Python 3.6+ | 核心开发 |
| **Web 框架** | Flask 2.0.2 | Web 应用程序和 API |
| **机器学习** | scikit-learn 1.0.1 | 模型训练和推理 |
| **数据** | NumPy · Pandas | 数值处理 |
| **抓取** | BeautifulSoup4 · Requests | HTML 特征提取 |
| **域名情报** | python-whois · googlesearch | WHOIS 和搜索分析 |
| **部署** | Gunicorn · Procfile | 生产服务器和 Heroku |
| **Notebook** | Jupyter | EDA 和模型实验 |
## 📁 项目结构
```
Huzaifa/
│
├── 📂 pickle/
│ └── model.pkl # Trained GBC model (download separately)
│
├── 📂 static/
│ └── styles.css # Web app stylesheet
│
├── 📂 templates/
│ └── index.html # Main web interface
│
├── 📓 Phishing URL Detection.ipynb # EDA, training and evaluation notebook
├── 🐍 app.py # Flask entry point
├── 🔧 feature.py # 30-feature extraction engine
├── 📊 phishing.csv # Training dataset (11,055 URLs)
├── 🚀 Procfile # Heroku deployment config
├── 📋 requirements.txt # Python dependencies
└── 📖 README.md
```
## 🚀 快速开始
### 前置要求
- Python **3.6+**
- pip
- Git
### 安装说明
**第 1 步 — 克隆代码库**
```
git clone https://github.com/huziifa/Huzaifa.git
cd Huzaifa
```
**第 2 步 — 创建并激活虚拟环境**
```
# 创建
python -m venv venv
# 在 Windows 上激活
venv\Scripts\activate
# 在 Mac / Linux 上激活
source venv/bin/activate
```
**第 3 步 — 安装依赖**
```
pip install -r requirements.txt
```
**第 4 步 — 下载训练好的模型**
由于 GitHub 的文件大小限制,`model.pkl` 文件单独托管。
下载并将其放在 `pickle/` 文件夹中:
```
📥 Download model.pkl — [Link Here]
```
将文件放置于:
```
Huzaifa/pickle/model.pkl
```
**第 5 步 — 启动应用**
```
python app.py
```
**第 6 步 — 在浏览器中打开**
```
http://127.0.0.1:5000
```
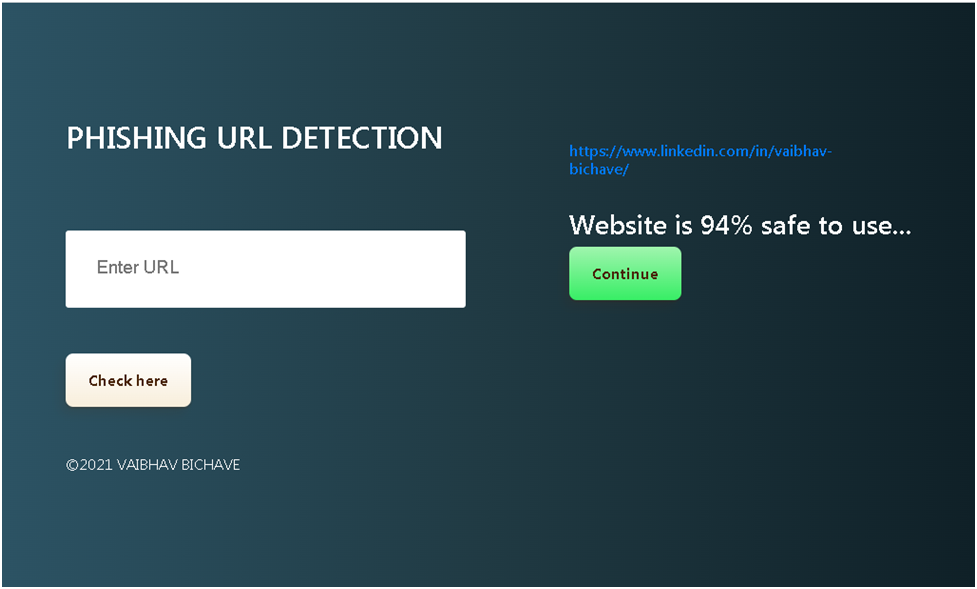
## 💻 用法
1. 在浏览器中打开 Web 应用
2. 将任意 URL 粘贴到输入框中
3. 点击 **Check URL**
4. 接收即时结果:
```
✅ https://github.com → 96.2% safe
✅ https://google.com → 94.8% safe
⚠️ http://paypa1-verify.tk → 3.1% safe ← phishing detected
⚠️ http://secure-login.free.fr → 7.4% safe ← phishing detected
```
## 📂 数据集
| 属性 | 值 |
|----------|-------|
| **来源** | [UCI 机器学习仓库](https://archive.ics.uci.edu/ml/datasets/phishing+websites) |
| **URL 总数** | 11,055 |
| **特征数** | 30 |
| **钓鱼网站** | 4,898 个样本 (-1) |
| **可疑网站** | 702 个样本 (0) |
| **合法网站** | 6,157 个样本 (1) |
| **训练/测试集划分** | 80% / 20% |
## 🏆 结果与分析
### 最终模型表现
```
┌─────────────────────────────────────────┐
│ Gradient Boosting Classifier │
│ │
│ Accuracy ████████████████░ 97.4% │
│ F1 Score ████████████████░ 97.7% │
│ Recall █████████████████ 99.4% │
│ Precision ████████████████░ 98.6% │
└─────────────────────────────────────────┘
```
### 主要结论
- **99.4% 召回率** — 模型几乎可以捕获所有钓鱼 URL。在安全领域,漏报一个钓鱼网站比误报危险得多,因此召回率是这里最关键的指标。
- **98.6% 精确率** — 只有极少数合法 URL 被错误标记,确保了可用、低阻力的体验。
- **关键信号** — HTTPS、AnchorURL 和 WebsiteTraffic 单独构成了大部分的预测能力,这证实了钓鱼者在这些维度上总是存在缺陷。
- **Naive Bayes 的失败** — 其 29.2% 的低召回率证明 URL 特征并不是条件独立的,这违背了 Naive Bayes 的核心假设。
## 🛣️ 路线图
- [x] 特征提取引擎(30 项特征)
- [x] 模型训练与基准测试(10 种算法)
- [x] Flask Web 应用程序
- [x] Heroku 部署配置(Procfile)
- [ ] REST API endpoint(`POST /api/check`)
- [ ] 浏览器扩展集成
- [ ] 实时重新训练 pipeline
- [ ] Docker 容器化
- [ ] 使用 GitHub Actions 实现 CI/CD
## 📄 许可证
基于 **MIT License** 分发。查看 [`LICENSE`](LICENSE) 了解完整条款。
## 👤 作者

### Huzaifa
*机器学习工程师与开发者*
[](https://github.com/huziifa)
[](https://linkedin.com/in/huziifa)

**如果这个项目对你有帮助,请考虑给它点个 Star ⭐**
*使用 Python、Flask 和 scikit-learn 构建*
[](https://www.python.org/)
[](https://flask.palletsprojects.com/)
[](https://scikit-learn.org/)
[](LICENSE)