builtbyraman/babel_elastic_ai
GitHub: builtbyraman/babel_elastic_ai
Babel 是一款 Kibana 原生的 SIGMA 检测工程平台,集成 AI 助手实现检测规则的编写、多格式转换、测试部署与 MITRE ATT&CK 覆盖分析。
Stars: 0 | Forks: 0
# Babel + AI
网络安全领域简直就是一个现实版的 Babel —— 每个平台都说着不同的“方言”,而为某个平台编写的检测规则很少能在另一个平台上运行。Babel 扭转了这一挑战:它建立在更新的 [SIGMA](https://sigmahq.io/) 开放标准之上,并在现代化后的 Elastic 和 Kibana 中原生运行,允许安全团队通过与事件响应生命周期以及战术、技术和程序相一致的单一界面,跨平台和工具编写、转换、测试、部署和跟踪检测规则。
## 解决方案视图
### 规则编辑器
在 YAML 编辑器(左侧)编写 SIGMA 规则,在可视化编辑器(中间)查看自动填充的字段,并在 Elasticsearch 输出面板(右侧)获得即时的格式转换。输出面板上方提供了一键 **在 Discover 中打开**、**回测** 和 **部署** 操作。
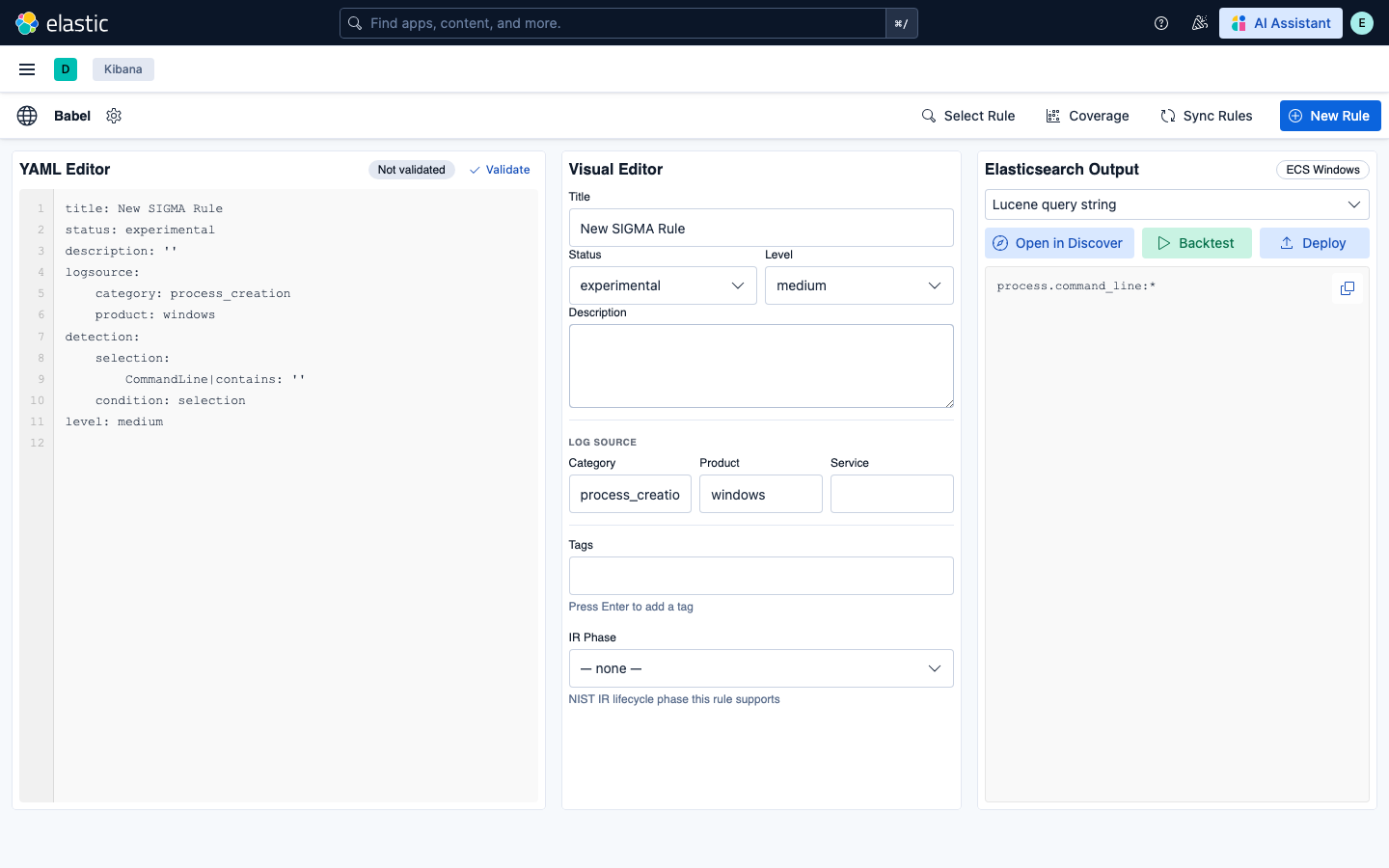
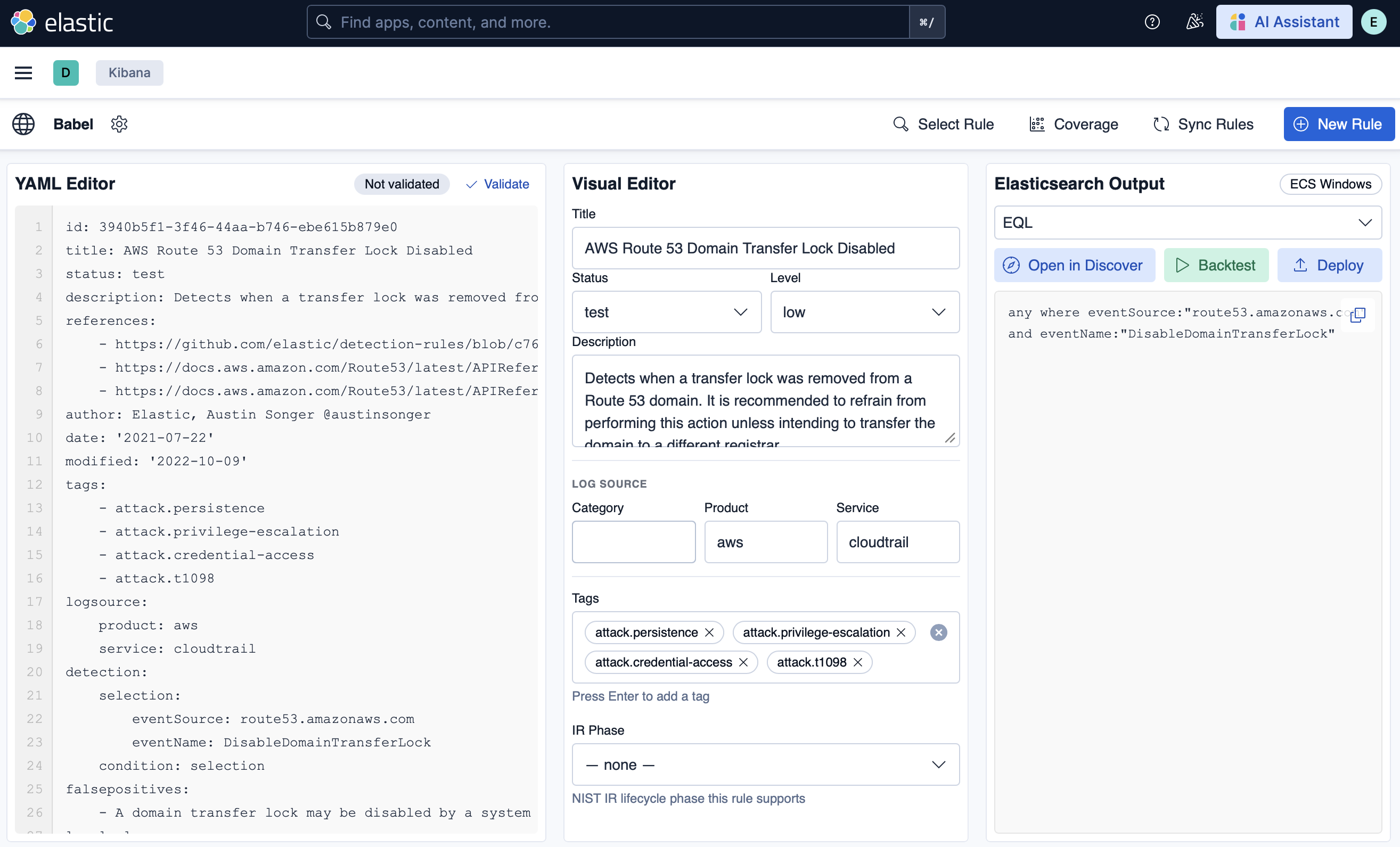
### 真实规则 — 完整元数据与 EQL 转换
从规则库中加载任意规则以查看其完整的 SIGMA YAML、自动填充的可视化编辑器字段(标题、状态、级别、描述、logsource、MITRE 标签、IR 阶段)以及实时转换的输出。在这里,一个 AWS CloudTrail 规则只需单击即可转换为 EQL。
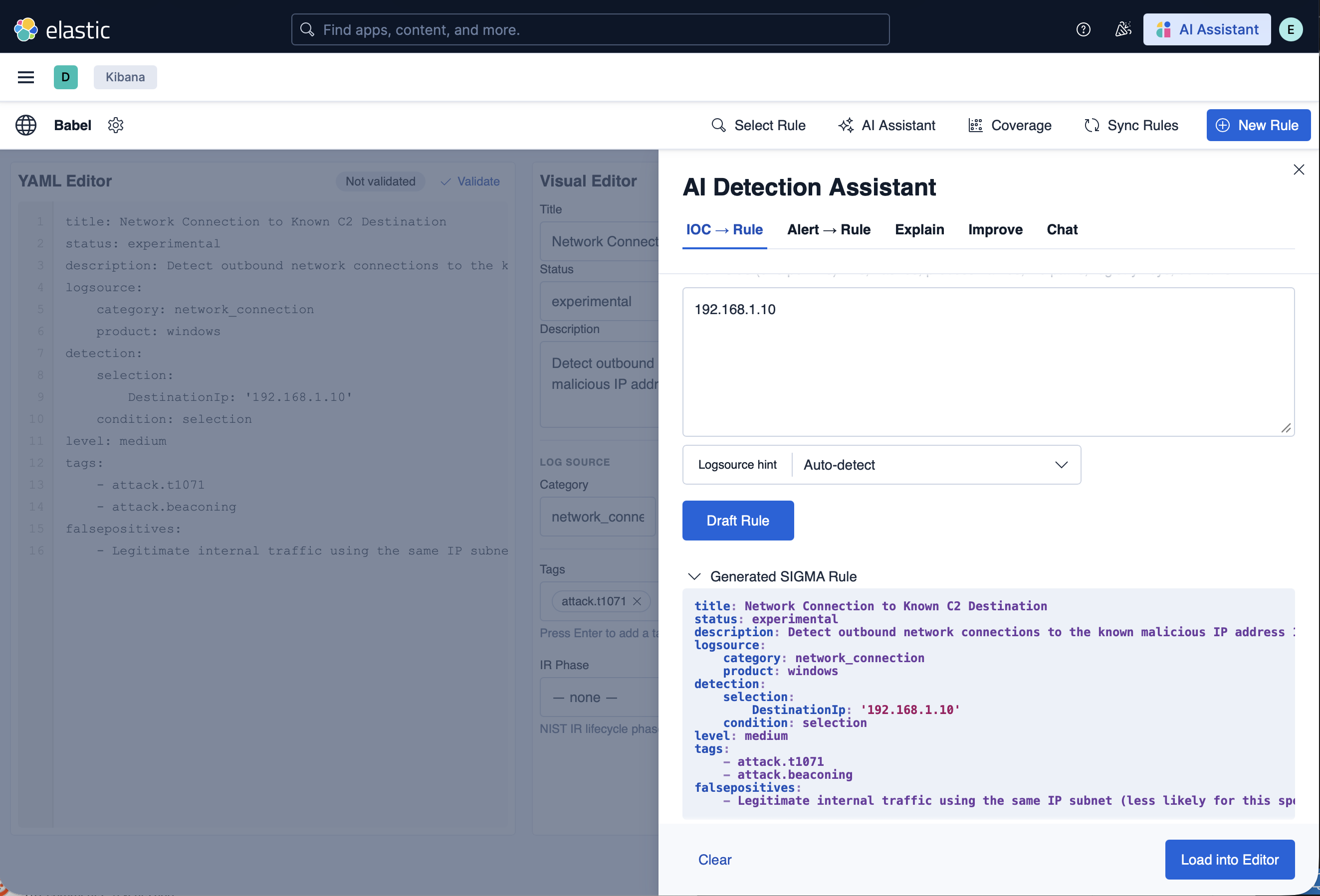
### AI 助手 — 从 IOC 起草
使用您选择的模型起草、解释和改进 SIGMA 规则 —— 默认使用本地 Ollama 模型,因此不会有任何数据离开您的主机。**IOC → Rule** 标签页可将一个指示器(此处为 IP)转化为完整的规则 —— logsource、detection、level、MITRE 标签、误报 —— 随时可以 **加载到编辑器**。相邻的标签页包括 **Alert → Rule**、**Explain** 和 **Improve**。
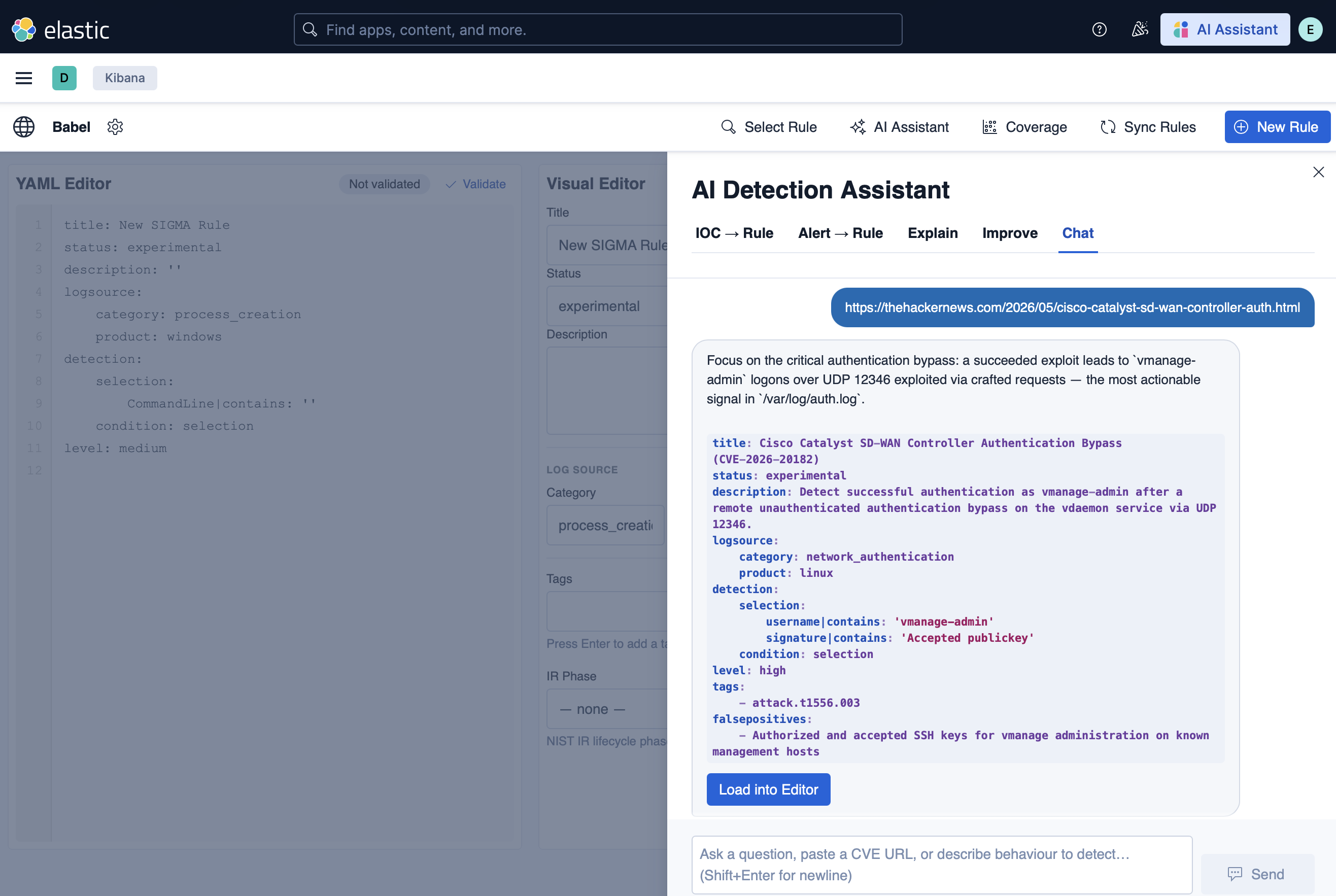
### AI 助手 — 基于 CVE 或威胁报告的聊天
**Chat** 标签页是一个对话式的检测工程助手。粘贴一段 CVE 报告或威胁情报 URL —— 或者仅仅描述一种行为 —— 它就会阅读安全公告并起草匹配的规则;在这里,一个链接即可生成针对 Cisco SD-WAN 身份验证绕过 (CVE-2026-20182) 的检测。您编辑器中打开的规则将作为每条消息的附加上下文。
### 多格式转换
从下拉菜单中切换输出格式 —— Lucene、EQL、ES|QL、Query DSL、Kibana NDJSON、SIEM Rule 或 ElastAlert —— 转换后的查询会即时更新。
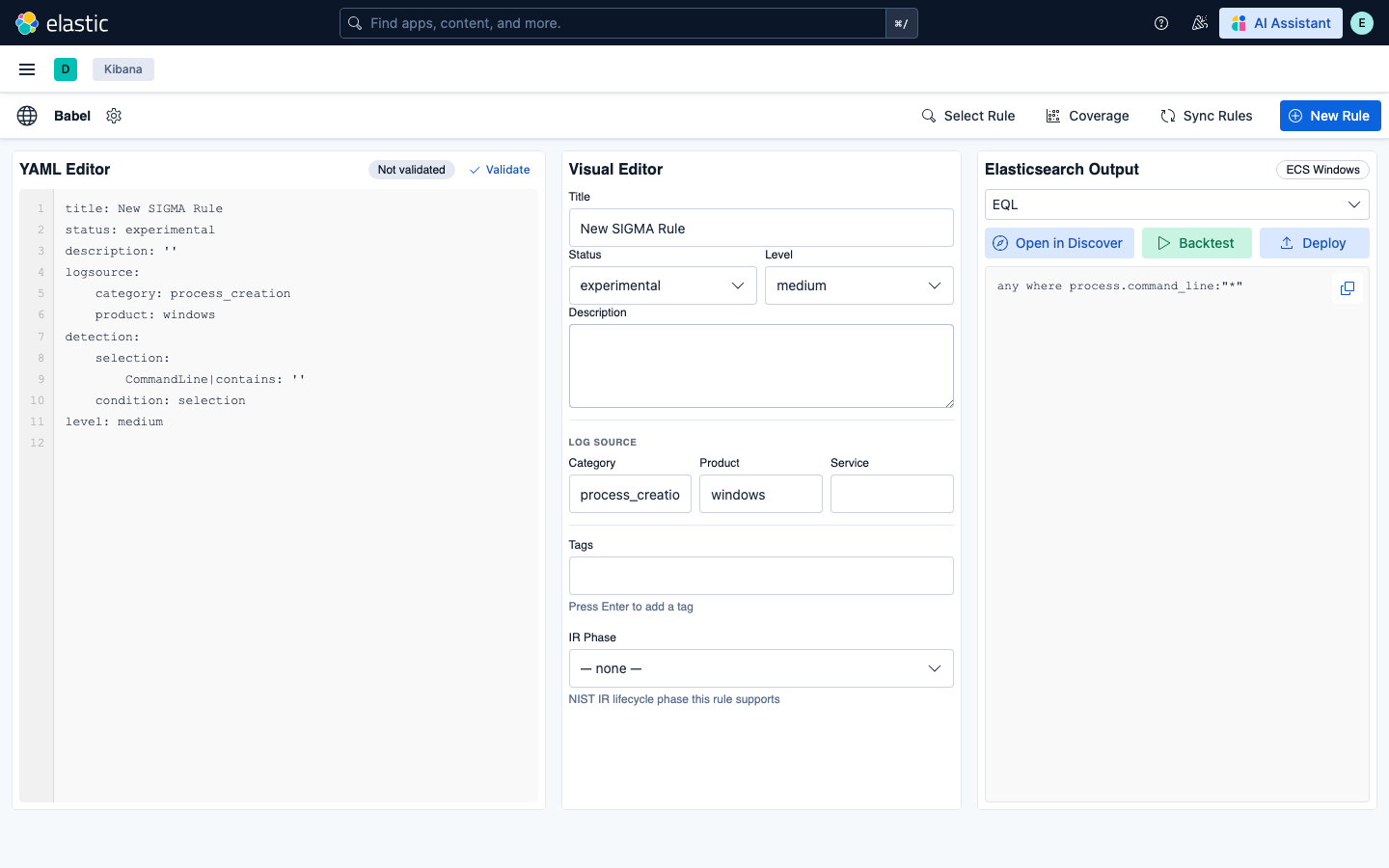
### MITRE ATT&CK 覆盖热力图
Coverage 视图将您的规则库映射到所有 14 项 ATT&CK 战术上。每个单元格显示六层颜色级别的技术覆盖情况:无覆盖 → 1 条规则 → 2-5 条 → 6-10 条 → 11-20 条 → 20+ 条规则。摘要统计信息显示了规则总数、命中的技术数和覆盖的战术数。
### IR 准备就绪报告
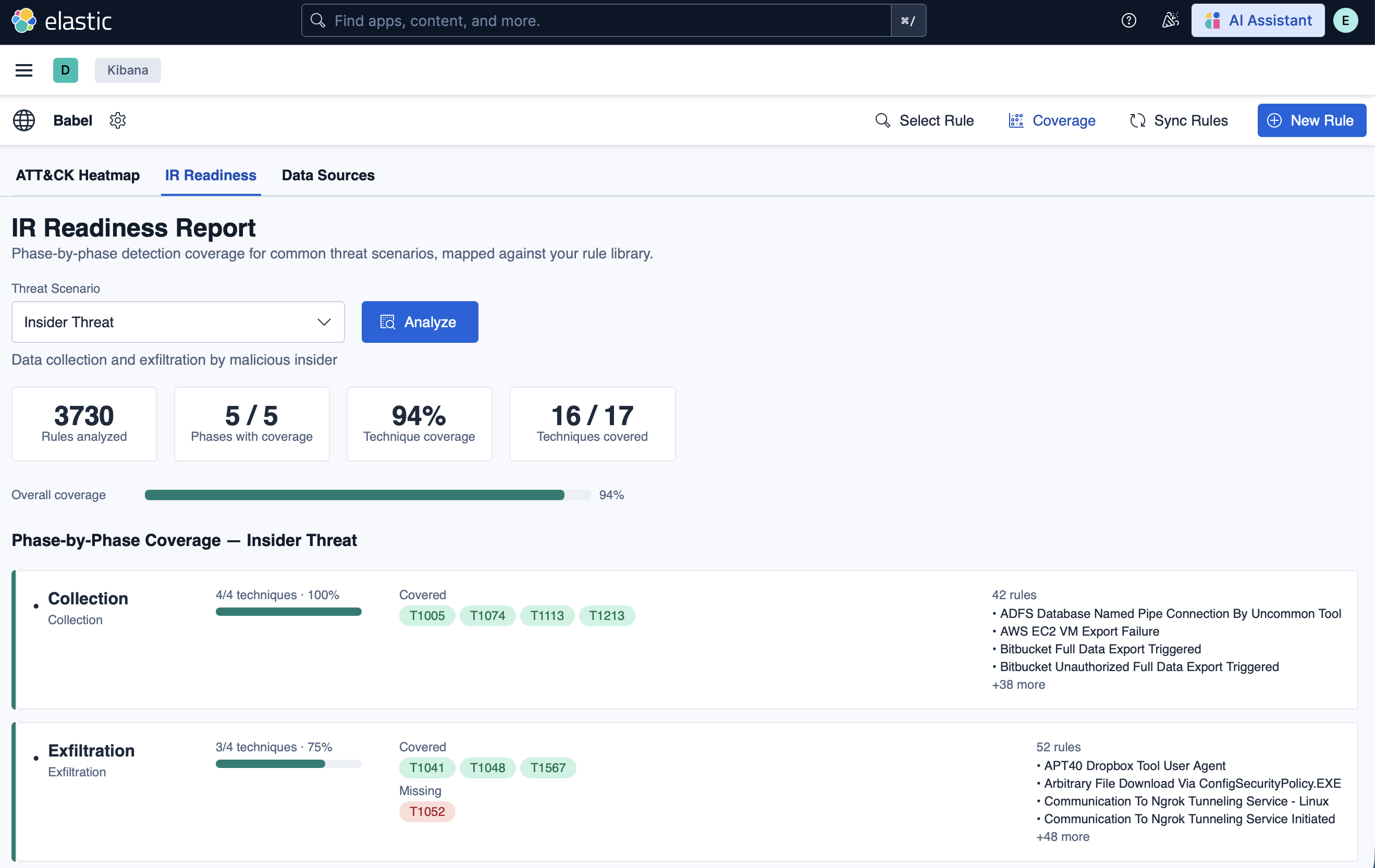
IR Readiness 标签页根据五种威胁场景评估检测覆盖率 —— 勒索软件、APT、内部威胁、数据泄露和供应链。选择一个场景并点击 Analyze,以获取逐阶段的详细分析。
运行 Insider Threat 场景显示在 5/5 个阶段中实现了 94% 的技术覆盖,并在列出覆盖和缺失技术的同时,显示了提供覆盖的具体规则。
### 数据源感知
Data Sources 标签页将您的 Elasticsearch 索引映射到 SIGMA logsource 类别。没有匹配索引数据的源会被标记 —— 在数据被摄取之前,针对这些源的规则不会产生警报。
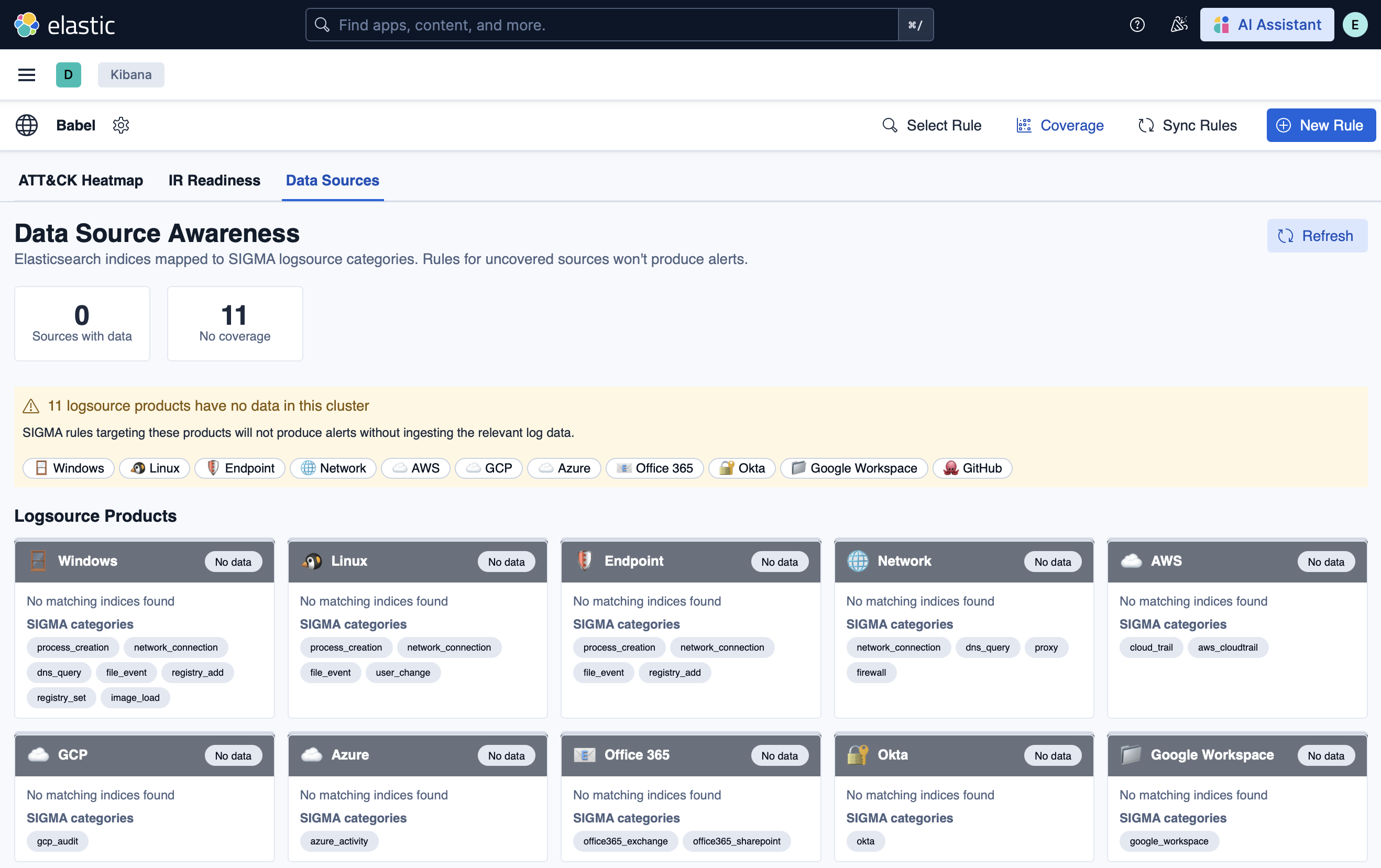
### 规则库
Select Rule 覆盖层可以通过标题、描述或技术 ID 搜索所有 3,730 条同步的规则。按战术或 IR 阶段进行筛选;点击任意行可将规则直接加载到编辑器中。
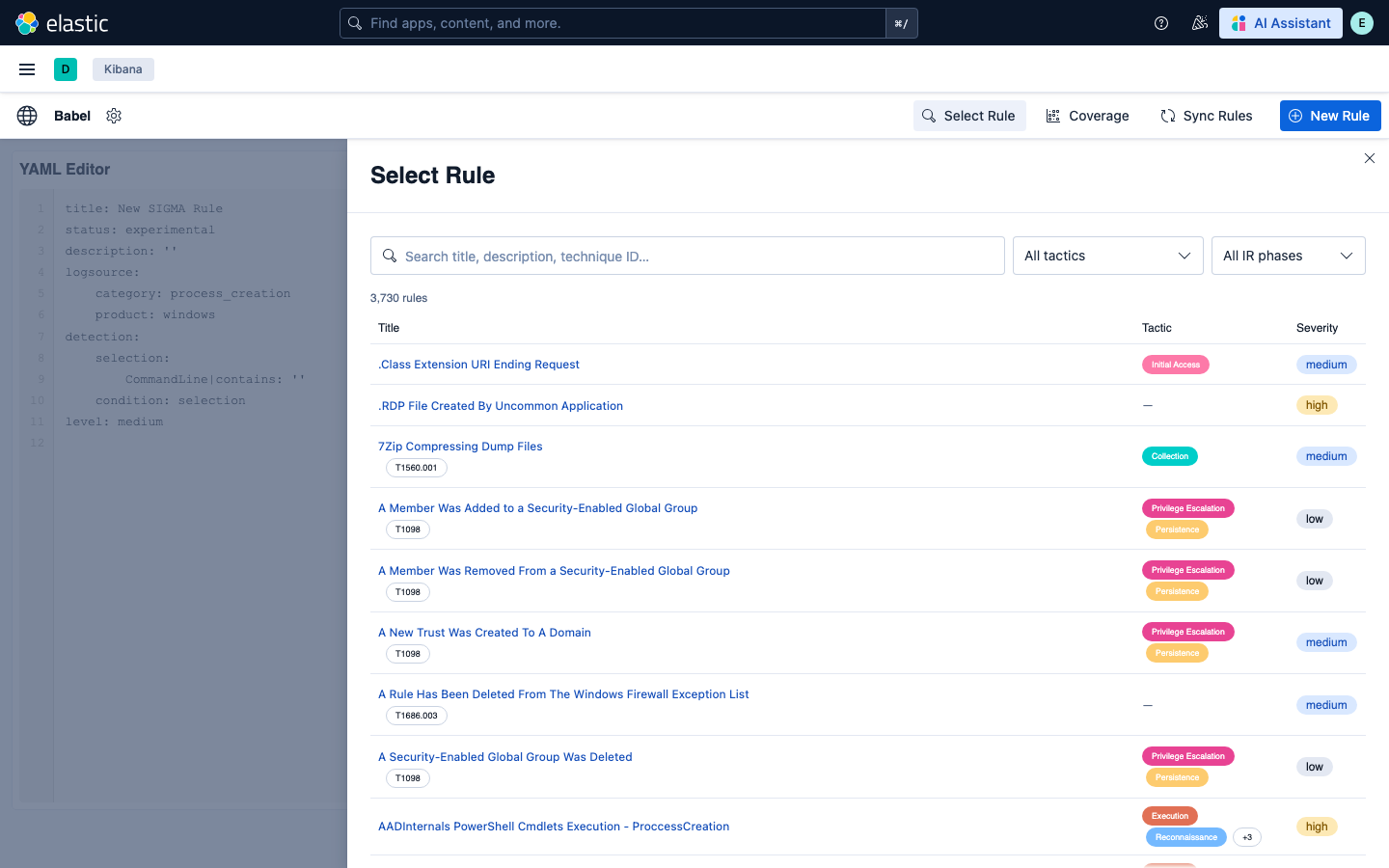
### GitHub 仓库设置
将多个 GitHub 仓库配置为规则源 —— 包括同一仓库内的不同路径。规则按仓库进行同步,并保持完全隔离。
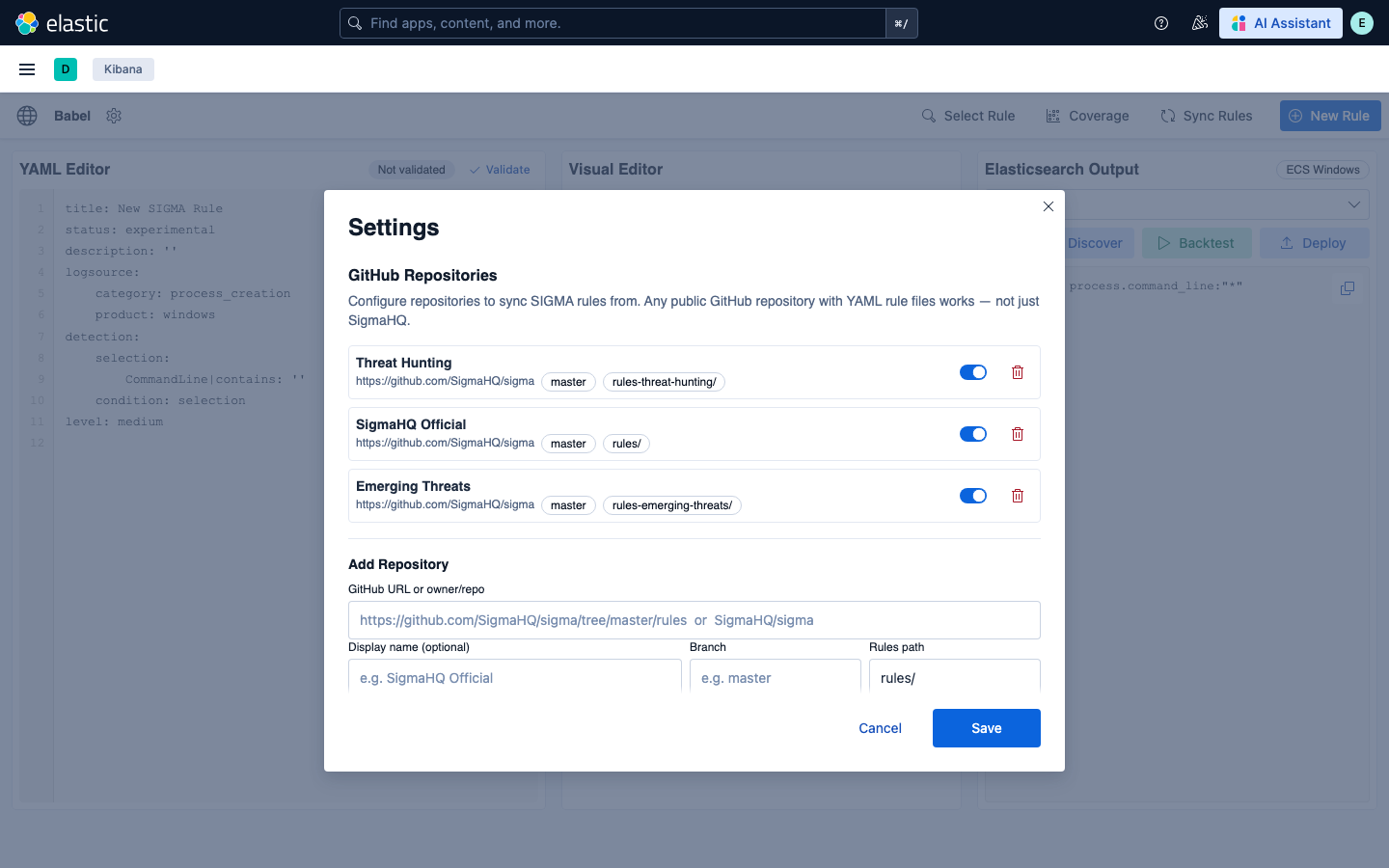
### 集成状态
Settings 面板显示与 Babel API 和 Elasticsearch 的实时连接状态、可用的数据源类别以及所有已配置的仓库及其启用状态。
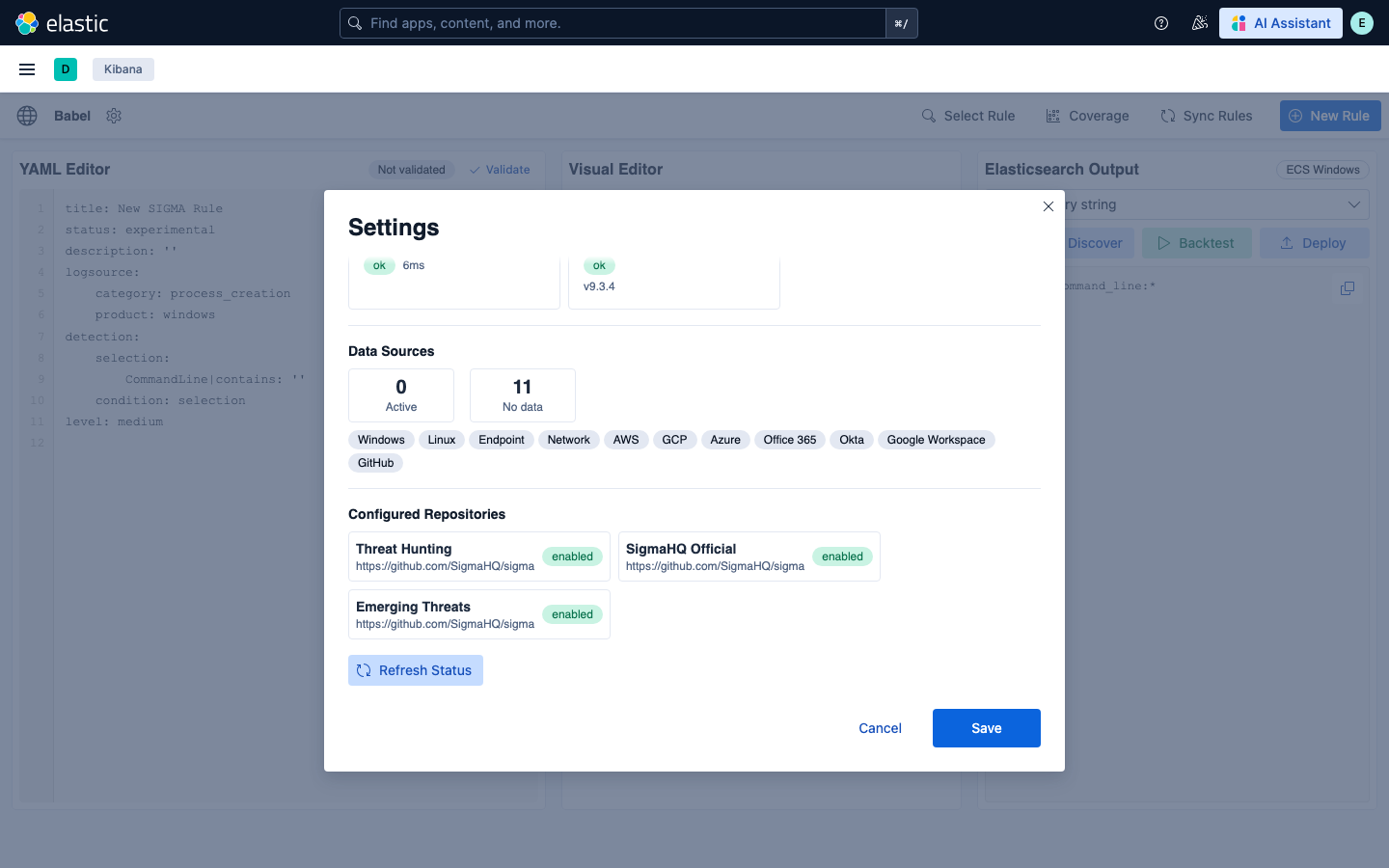
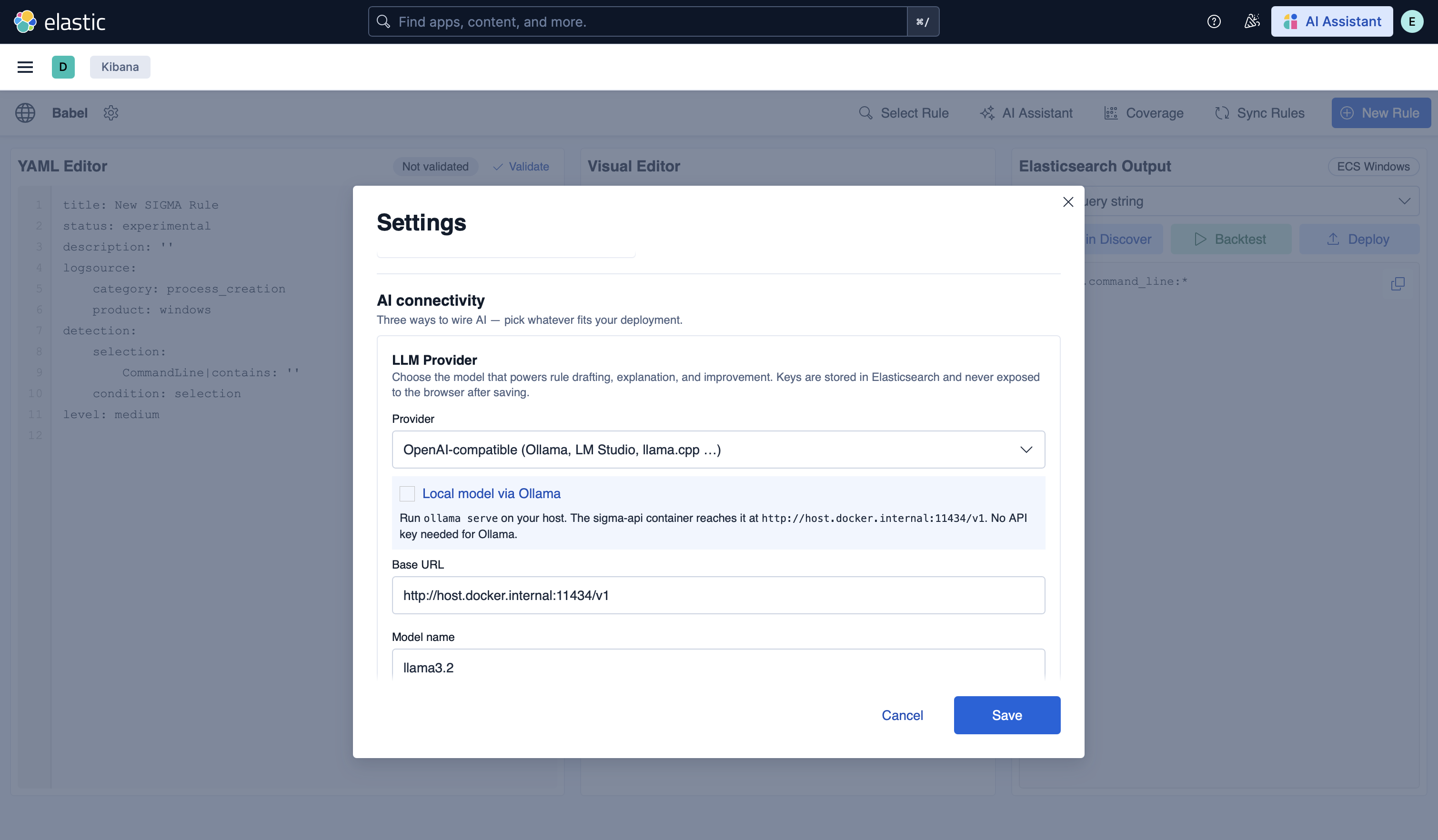
### AI 连接 — 选择您的模型/提供商
Settings 的 **AI connectivity** 区域提供了三种接入 AI 的方式 —— 选择最适合您部署的方式。**LLM Provider** 面板可选择驱动 Babel AI 面板的模型:通过 Ollama 的本地模型(默认)、托管提供商(Anthropic、OpenAI)、OpenAI 兼容的 endpoint 或 Kibana connector。为您选择的项目设置 **Base URL** 和 **Model name**;密钥存储在 Elasticsearch 中,绝不会暴露给浏览器。
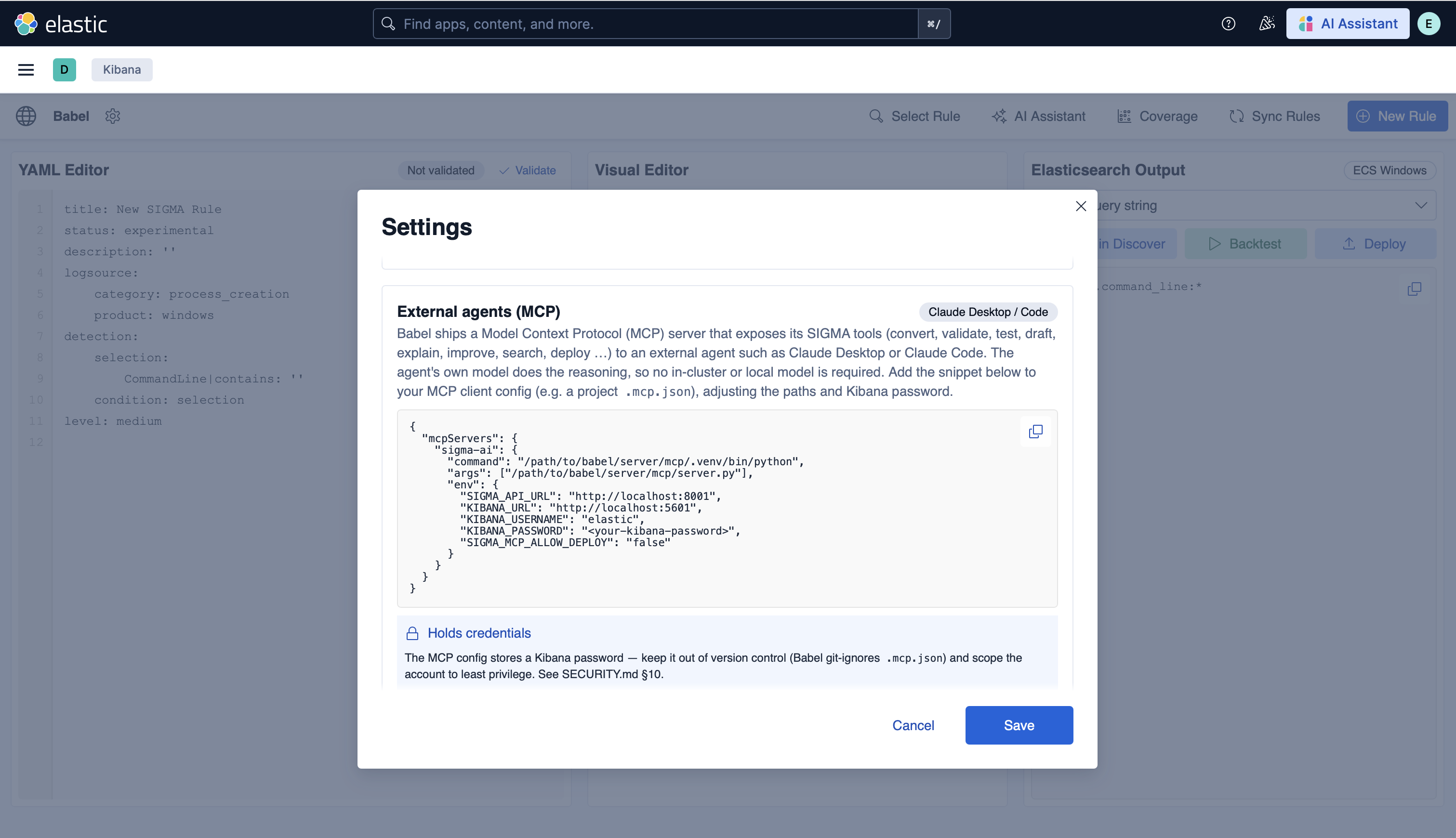
### AI 连接 — 外部代理 (MCP)
**External agents (MCP)** 面板提供了一个可直接复制的 `.mcp.json` 代码片段,用于将 Claude Desktop 或 Claude Code 指向 Babel 的 MCP server —— 将 SIGMA 工具(convert、validate、draft、explain 等)暴露给外部代理,且无需集群内或本地模型。该面板提醒您配置中包含 Kibana 凭据,并提供了指向安全说明的链接。
## 功能
- **YAML 编辑器** — 编写和验证 SIGMA 规则,并提供实时语法反馈
- **可视化规则构建器** — 无需编写原始 YAML 即可构建规则
- **AI 助手** — 由 LLM 驱动的检测工程助手,使用您选择的模型 —— 默认通过 Ollama 使用本地模型(无数据离开您的主机),或使用 Anthropic Claude、OpenAI / 兼容 OpenAI 的 endpoint,或 Elastic GenAI connector:
- 从 IOC 列表起草 SIGMA 规则
- 从 Kibana 或 Security Onion 警报复起草 SIGMA 规则
- 用通俗易懂的英语解释规则 —— 检测逻辑、日志源、MITRE ATT&CK 映射、误报以及调优建议
- 根据您的实时 ECS 字段映射改进规则,并附带更改内容及原因的摘要
- 用于交互式规则编写和检测工程问题的聊天助手
- 与提供商无关,可在 Settings 中配置;参见 [AI 助手 — 模型与密钥设置](#ai-assistant--model--key-setup)
- **多 SIEM 转换** — 将规则转换为 8 种输出格式:
- Lucene query string
- Query DSL
- Kibana NDJSON
- SIEM Rule (JSON / NDJSON)
- EQL
- ES|QL
- ElastAlert
- **实时规则测试** — 针对带有命中聚类的 Elasticsearch 索引进行回测
- **规则部署** — 将规则直接推送到 Kibana Detection Engine
- **MITRE ATT&CK 覆盖热力图** — 可视化您的规则集涵盖的技术
- **IR 准备就绪评估** — 将规则映射到事件响应阶段
- **字段建议** — 自动将 SIGMA 字段映射到 ECS 字段
- **Schema 漂移检测** — 随时间跟踪 Elasticsearch 映射的更改
- **规则质量评分** — 评估规则的有效性和陈旧度
- **数据源可用性映射** — 检查可用的索引、文档计数和字段映射
- **GitHub 同步** — 从多个可配置的 GitHub 仓库(SigmaHQ 和自定义仓库)拉取规则;同步的规则数量没有上限
## 要求
### 运行时
| 依赖 | 版本 | 说明 |
|---|---|---|
| Kibana / Elasticsearch | 9.3.4 | 已锁定版本 — 见下文说明 |
| Python | 3.11+ | Babel API 必需 |
### 构建工具
| 依赖 | 版本 | 说明 |
|---|---|---|
| Node.js | 20+ | 仅用于构建 |
| `zip` CLI | 任意 | 仅用于构建 |
### npm 包 (运行时)
| 包 | 版本 |
|---|---|
| `@elastic/eui` | ^114.3.0 |
| `js-yaml` | ^4.2.0 |
| `react` | ^18.3.1 |
| `react-dom` | ^18.3.1 |
### npm 包 (开发 / 构建)
| 包 | 版本 |
|---|---|
| `typescript` | ^5.9.3 |
| `webpack` | ^5.107.2 |
| `webpack-cli` | ^6.0.1 |
| `ts-loader` | ^9.6.0 |
| `html-webpack-plugin` | ^5.6.7 |
| `jest` | ^30.4.2 |
| `jest-environment-jsdom` | ^30.4.1 |
| `ts-jest` | ^29.4.11 |
| `@testing-library/react` | ^16.3.2 |
| `@types/node` | ^20.19.42 |
| `@types/react` | ^18.3.31 |
| `@types/react-dom` | ^18.3.7 |
| `@types/jest` | ^30.0.0 |
| `@types/js-yaml` | ^4.0.9 |
### Python 包 (Sigma 转换引擎)
这些是 `server/translation_script/sigma/` 所必需的。在构建或运行转换脚本之前,请设置虚拟环境:
| 包 | 版本 |
|---|---|
| `pySigma` | >=0.11.0, <1.0.0 |
| `pySigma-backend-elasticsearch` | >=1.0.0, <2.0.0 |
## 快速开始 (Docker Compose)
完整的堆栈 —— Elasticsearch、Kibana(包含 Babel)和 Babel API —— 只需一条命令即可启动。
### 1. 配置凭据
```
cp .env.example .env
```
编辑 `.env` 并至少设置:
| 变量 | 用途 |
|---|---|
| `ELASTIC_PASSWORD` | `elastic` 超级用户的密码 |
| `KIBANA_SYSTEM_PASSWORD` | 内部 Kibana 服务账号密码 |
| `KIBANA_ENCRYPTION_KEY` | 用于加密已保存对象的 32 字符密钥 |
### 2. 构建 Kibana 插件(一次性)
```
npm install
KIBANA_VERSION=9.3.4 npm run build
```
只有在修改插件源码时才需要重复此操作。正常的重启(`docker-compose up -d`)不需要重新构建。
### 3. 启动技术栈
```
docker-compose up --build -d
```
这会按依赖顺序启动四个服务:
| 服务 | 容器 | 端口 | 用途 |
|---|---|---|---|
| Elasticsearch | `babel-es` | 9200 | 规则存储和实时规则测试 |
| kibana-setup | *(初始化后退出)* | — | 仅设置一次 `kibana_system` 账号密码 |
| Sigma API | `babel-api` | 8001 | 规则转换、验证、覆盖率分析、IR 准备就绪和 AI 生成 (FastAPI, `server/api/`) |
| Kibana + Babel | `babel-kibana` | 560 | UI |
首次启动会拉取镜像并安装 Python 依赖项(约 2-3 分钟)。随后的启动速度很快。
### 4. 验证技术栈是否已启动
```
# Sigma API
curl http://localhost:8001/health
# → {"status": "healthy", "service": "sigma-ui-api"}
# Kibana
curl -u elastic: http://localhost:5601/api/babel/status
# → services: [{name: "Sigma Conversion API", status: "ok"}, {name: "Elasticsearch", status: "ok"}]
```
Kibana 可在 **http://localhost:5601** 访问 —— 使用 `.env` 中的密码以 `elastic` 身份登录。
在左侧导航栏中导航至 **Babel**。要检查服务连通性,请点击 Babel 导航栏中的 **齿轮图标 (⚙)** 以打开 Settings —— 面板底部显示了 Babel API 和 Elasticsearch 的实时状态。
### 5. (仅限首次启动)从 GitHub 同步规则
规则库(`babel_sigma_doc` 索引)在首次启动时为空。在 Babel UI 中:
1. 转到 **Settings** → 添加 GitHub 仓库(例如 `https://github.com/SigmaHQ/sigma`,分支 `master`,路径 `rules/`)
2. 点击 **Sync** —— 这将从仓库中获取所有 SIGMA YAML 文件
3. 返回 **Rule Library** 标签页;规则将在同步完成时出现
### 停止并重启
```
docker-compose down # stop (data volumes preserved)
docker-compose down -v # stop and wipe all data (fresh start)
docker-compose up -d # restart without rebuilding images
docker-compose up --build -d # rebuild images (after source changes)
```
## AI 助手 — 模型与密钥设置
Babel 的 AI 功能(从 IOC 或警报复起草规则、解释规则、改进规则以及聊天助手)会通过**您**选择的提供商调用大型语言模型 (LLM)。**开箱即用,Babel 被配置为使用由 Ollama 提供的本地模型 —— 无需 API 密钥,且不会有检测数据离开您的主机。** 您可以随时切换提供商。
Babel 提供了**三种连接 AI 的方式** —— 选择最适合您部署的方式。这三种方式均在 **Babel → ⚙ 齿轮图标 → Integration & Status → AI connectivity** 下进行管理:
| 方式 | 支持的功能 | 需要本地模型? | 适用场景 |
|---|---|---|---|
| **1. 应用内模型** | Babel 自带的 AI 面板 | 否 —— 除非您选择 Ollama | 大多数设置:本地 Ollama、托管的 Anthropic/OpenAI 或 Kibana connector |
| **2. Elastic AI Assistant** (Agent Builder) | 在 Kibana 原生 Assistant 中的 Babel SIGMA 代理 | 否 | Elastic Cloud / 托管的 Kibana;在 Elastic UI 中工作的团队 |
| **3. 外部代理 (MCP)** | 驱动 Babel 工具的 Claude Desktop / Code | 否 | 在工作站上使用 Claude 的分析师 |
**方式 1 — 应用内模型** 有四个提供商选项,在 *AI connectivity → AI Provider* 下配置。请在下方选择一个。
### 选项 A — 通过 Ollama 使用本地模型(默认;最适合敏感数据)
1. 在 **Docker 宿主机** 上安装 [Ollama](https://ollama.com) 并确保其正在运行(`ollama serve` —— 它监听 `:11434`)。
2. 拉取模型。Babel 自带的默认模型是:
ollama pull hf.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M
任何 Ollama 模型均可工作(`llama3.2`、`mistral`、`codestral` 等)。
3. 在 **AI Provider** 中,选择 **OpenAI-compatible (Ollama, LM Studio, llama.cpp …)** 并设置:
- **Base URL** — `http://host.docker.internal:11434/v1`(Docker 堆栈)或 `http://localhost:11434/v1`(直接在宿主机上运行 Sigma API)
- **Model name** — 您拉取的确切名称
- **API Key** — 留空
4. **保存。** 如果您保留自带的默认设置,则只需执行第 1–2 步即可。
其他兼容 OpenAI 的服务器(LM Studio、`llama.cpp --server`)的工作方式完全相同 —— 只需将 **Base URL** 指向它们的 `/v1` endpoint 即可。
### 选项 B — Anthropic Claude(托管)
1. 从 Anthropic Console 获取密钥。
2. **AI Provider → Anthropic Claude** → 粘贴密钥 (`sk-ant-…`) 并设置模型(默认为 `claude-sonnet-4-6`) → **保存。**
除了使用 UI,您还可以在 Sigma API 容器上将密钥作为环境变量提供:
```
# docker-compose.yml → sigma-api → environment:
- ANTHROPIC_API_KEY=sk-ant-…
```
### 选项 C — OpenAI / Azure OpenAI(托管)
**AI Provider → OpenAI** → 粘贴 `sk-…`,设置模型(`gpt-4o`)和 **Base URL**(默认为 `https://api.openai.com/v1`;如果是 Azure OpenAI,请使用您的 Azure endpoint) → **保存。** 环境变量备用方案:在 Sigma API 容器上设置 `OPENAI_API_KEY`。
### 选项 D — Elastic Connector(密钥保留在 Kibana 中 —— 最安全)
Babel 中不会存储任何 API 密钥 —— 凭据存在于 Kibana 的加密 connector 中。
1. 在 Kibana 中:**Stack Management → Connectors** → 创建一个 Generative AI connector —— OpenAI (`.gen-ai`)、AWS Bedrock (`.bedrock`)、Google Gemini (`.gemini`) 或 Elastic Inference (`.inference`)。
2. **AI Provider → Elastic Connector (Stack Management)** → 从列表中选择您的 connector → **保存。**
随后,推理将通过 Kibana 的 Actions 框架运行,因此模型凭据永远不会经过 Babel 或离开 Kibana。
### 设置模型名称
**Model** 字段因提供商而异 —— 设置错误是导致“找不到模型”错误或 AI 输出为空的最常见原因。在 **connector** 模式下,该字段会被忽略(模型在 Kibana connector 中设置)。
| 提供商 | **Model** 中应填写的内容 | 如何找到它 |
|---|---|---|
| **Ollama (本地)** | `ollama list` 中的确切名称,**包括 `:tag`** | 运行 `ollama list` 并逐字复制 NAME 列 —— 例如 `llama3.2`、`mistral:7b`,或自带的默认模型 `hf.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M`。标签很重要。 |
| **LM Studio / llama.cpp** (兼容 OpenAI) | 服务器报告的模型 ID | LM Studio:加载的模型的 API 标识符。llama-server:通常是文件名,或 `GET {base_url}/models` 返回的任何内容。 |
| **Anthropic** | Claude 模型 ID | 例如 `claude-sonnet-4-6`(默认)。请参阅 Anthropic 的模型列表。 |
| **OpenAI** | OpenAI 模型 ID | 例如 `gpt-4o`、`gpt-4o-mini`。 |
| **Azure OpenAI** | 您的**部署名称**(非基础模型) | Azure OpenAI 资源 → 部署。同时将 **Base URL** 设置为您的 Azure endpoint。 |
| **Elastic Connector** | *(留空)* | 模型**在 Kibana connector 中**进行配置 —— 在 connector 模式下,Babel 的 Model 字段会被忽略。 |
### 密钥存储位置
| 提供商 | 凭据位置 |
|---|---|
| Ollama / 本地 | 不需要 |
| Anthropic / OpenAI / 兼容 OpenAI 的提供商 | `sui_config` Elasticsearch 索引(读取时已脱敏) —— 或 `sigma-api` 容器上的环境变量 |
| Elastic Connector | Kibana 加密保存对象(从不存储在 Babel 中) |
对于敏感的检测内容,推荐使用 **Ollama(本地)** 或 **Elastic Connector**。当选择托管提供商时,规则/警报文本将发送给该供应商 —— 请参阅 [SECURITY.md](SECURITY.md) §9(AI 数据外发),并将 `sui_config` 索引的访问权限限制为管理员。
### 方式 2 — Elastic AI Assistant (Agent Builder)
如果您的 Kibana 启用了 **Agent Builder**,Babel 可以将三个 SIGMA 代理(IOC 起草器、警报转换器、规则顾问)注册到 Elastic 的**原生 AI Assistant** 中。然后,它们将在 Kibana 的 Assistant 内部运行,使用 Elastic 配置的任何 LLM connector(例如 Bedrock-Claude)以及 Elastic 自己的工具 —— 这样,即使没有 Babel 的面板或本地模型,也能获得检测帮助。
在 **Integration & Status → AI connectivity → Elastic AI Assistant (Agent Builder)** 中,点击 **Register agents**(或点击 **Remove** 取消注册)。如果面板显示 *“在此 Kibana 上不可用”*,则表示您的版本/许可证不支持或未启用 Agent Builder —— 请改用方式 1 或 3。
### 方式 3 — 外部代理 (MCP / Claude Desktop)
Babel 附带了一个 Model Context Protocol server (`server/mcp/server.py`),它将其 SIGMA 工具暴露给外部代理,例如 **Claude Desktop 或 Claude Code**。代理自身的模型负责进行推理,因此不需要本地或集群内模型。
在 **Integration & Status → AI connectivity → External agents (MCP)** 中,复制 `.mcp.json` 模板,填入路径和您的 Kibana 密码,并将其添加到您的 MCP 客户端中。此配置包含凭据 —— 请将其排除在版本控制之外(Babel 会在 git 中忽略 `.mcp.json`),并将账号权限限制为最小权限。请参阅 [SECURITY.md](SECURITY.md) §10。
## 架构
Babel 是一个 **Kibana 插件**,将繁重的处理任务推送到单独的 **Sigma API**。插件本身刻意保持轻量化 —— 浏览器中的 React UI 和一个负责代理请求、读写 Elasticsearch 以及部署检测规则的 Kibana 服务端插件。SIGMA 到查询的转换、验证、覆盖率分析和 AI 生成都在进程外的 Python 服务中运行,因此 Kibana 保持纯 TypeScript,内部没有任何 Python 运行时。AI 功能与**提供商无关**,默认使用 **由 Ollama 提供的本地模型**,并且一个可选的 **MCP server** 将相同的功能暴露给 Claude Code / Desktop。
### 组件与数据流
```
┌──────────────────────────────────────────────┐
Browser │ React + Elastic UI (public/) │
(analyst) │ YAML & visual editors · conversion output · │
│ coverage · IR readiness · AI Assistant │
└───────────────────────┬──────────────────────┘
│ HTTP /api/babel/*
▼
┌──────────────────────────────────────────────┐
Kibana process │ Babel server plugin (server/routes/) │
│ proxy · auth · Elasticsearch I/O · deploy │
└───────┬──────────────────────────┬───────────┘
/v1/* convert·validate·AI │ │ rule library · settings ·
▼ │ AI config · Detection Engine
┌─────────────────────────────────────┐ ▼
│ Sigma API — FastAPI (sigma-api) │ ┌─────────────────────────────┐
│ server/api/ :8001 │ │ Elasticsearch (:9200) │
│ /v1/conversions /v1/rules/validate │◄─►│ babel_sigma_doc (library) │
│ /v1/coverage /v1/test-runs │ │ babel_config (settings)│
│ /v1/ir-readiness /v1/ai/* │ │ sui_config (AI cfg) │
│ pySigma + ECS pipelines │ │ + your log indices │
└──────────────────┬───────────────────┘ └─────────────────────────────┘
AI generation │ x-llm-* headers
▼
┌─────────────────────────────────────┐
│ LLM provider (chosen in Settings) │
│ Ollama → Gemma GGUF (default) │
│ · Anthropic · OpenAI-compatible │
│ · Kibana GenAI connector │
└─────────────────────────────────────┘
Optional — agent / IDE access (Claude Code · Claude Desktop):
┌─────────────────────────────────────────┐ stdio ┌────────────────────────────┐
│ MCP server server/mcp/server.py │ ───────► │ 10 SIGMA tools → Sigma API │
│ convert·validate·test·draft·explain· │ │ /v1/* (+ same LLM model) │
│ improve·search·field-maps·esql·deploy │ └────────────────────────────┘
└─────────────────────────────────────────┘
```
### 组件
| 层级 | 位置 | 职责 |
|---|---|---|
| **浏览器 UI** | `public/` (React + Elastic UI) | YAML/可视化编辑器、转换输出、覆盖热力图、IR 准备就绪、AI 助手、设置。仅与 `/api/babel/*` 通信。 |
| **Babel 服务端插件** | `server/routes/`, `server/plugin.ts` | 轻量级代理和身份验证边界。负责读写 Elasticsearch(规则库、设置、AI 配置),将转换/AI 调用转发给 Sigma API,并在部署时在 Kibana Detection Engine 中创建规则。 |
| **Sigma API** | `server/api/` — 运行在 `:8001` 的 FastAPI | pySigma 转换 + ECS pipelines、规则验证、覆盖率/IR 准备就绪、字段建议、质量/有效性/schema 漂移、实时测试运行,以及 `/v1/ai/*` 生成端点。 |
| **Elasticsearch** | `:9200` | 规则库 (`babel_sigma_doc`)、插件设置 (`babel_config`)、AI 提供商配置 (`sui_config`),以及您自己的用于测试的日志索引。 |
| **LLM 提供商** | 本地 / 外部 | 在 Settings 中选择 → 存储在 `sui_config` 中。默认为 **Ollama → Gemma GGUF**;也支持 Anthropic、OpenAI / 兼容 OpenAI 的提供商或 Kibana GenAI connector。 |
| **MCP server** *(可选)* | `server/mcp/server.py` | 通过 stdio 暴露 10 个 SIGMA 工具给 Claude Code/Desktop 的 MCP server;代理给同一个 Sigma API 和 LLM 提供商。 |
### 请求如何流转
- **转换 / 验证** — UI → `POST /api/babel/...` → 插件 → 在 Sigma API 上调用 `POST /v1/conversions`(或 `/v1/rules/validate`) → pySigma → 结果沿链路返回。
- **AI 助手 (Explain / Improve / Draft)** — UI → `/api/babel/ai/*` → 插件从 `sui_config` 读取已保存的提供商配置,附加 `x-llm-provider` / `x-llm-model` / `x-llm-base-url` 头部,并在 Sigma API 上 `/v1/ai/*`,由其调用选定的模型。在 **connector 模式** 下,该调用改为通过 Kibana Actions 框架执行,因此模型凭据永远不会离开 Kibana。
- **部署** — UI → `/api/babel/deploy` → 插件通过 Sigma API 转换规则,然后在 Kibana Detection Engine 中创建一个 *禁用的* 规则,供分析师启用。
- **规则库 / 同步** — 完全由插件针对 Elasticsearch 处理;GitHub 同步将 SIGMA YAML 拉取到 `babel_sigma_doc` 中(不涉及 Sigma API)。
### 为什么要这样拆分
将转换和 AI 保持在 Kibana 进程之外,意味着插件可以作为纯 JS/TS 发布,无需捆绑 Python 解释器;pySigma 和 LLM 依赖项保持隔离并可独立升级;而且 Sigma API 可以进行扩展或重新部署(在另一台主机上运行并通过 `babel.sigmaApiUrl` 让 Kibana 指向它)。
### 如果没有 Sigma API,哪些功能会降级
插件将转换/分析/AI 代理给 Sigma API;如果无法访问该 API,这些功能将返回错误。编辑器和规则库功能在没有它的情况下仍然可以工作:
| 功能 | 需要 Sigma API |
|---|---|
| 规则编辑器(YAML 编辑、保存) | 否 |
| 规则库(浏览、搜索、从 GitHub 同步) | 否 |
| 规则转换 / 翻译 | **是** |
| 规则验证 | **是** |
| 将规则部署到 Detection Engine | **是**(转换步骤) |
| MITRE ATT&CK 覆盖热力图 | **是** |
| IR 准备就绪评估 | **是** |
| 字段映射建议 | **是** |
| 规则质量评分 | **是** |
| 实时规则测试(回测) | **是** |
| AI 助手(解释 / 起草 / 改进) | **是**(+ 可访问的 LLM 提供商) |
### 身份验证
插件自身的 `/api/babel/*` 路由继承了 **Kibana 身份验证** —— 任何已登录的 Kibana 用户都可以调用它们(没有基于路由的 RBAC;如果需要,请在 Space 或网络层面进行限制)。对于后端,在 `.env` 中设置 `SIGMA_API_KEY` 以要求在所有 Sigma API 请求上使用 bearer token;将其留空(默认值)则允许在 Docker 网络内进行未经身份验证的访问。
## 安装
Babel 是一个 **Kibana 插件**。它不是 Elastic 集成,无法从 Kibana 集成页面(Fleet → Integrations)安装。该页面用于 Elastic Agent 数据集成,它们使用的格式完全不同。尝试在那里安装 Babel 将失败并出现 `manifest.yml not found` 错误。
支持的安装方法是 Docker Compose —— Elasticsearch、Kibana 和 Babel API 全部一起启动:
```
cp .env.example .env # configure credentials
npm install && KIBANA_VERSION=9.3.4 npm run build # one-time plugin build
docker-compose up --build -d # start the stack
```
有关完整的操作步骤,请参见 [快速开始 (Docker Compose)](#quick-start-docker-compose)。
## 在 Security Onion 上安装
Security Onion 在 Docker 容器 (`so-kibana`) 中运行 Kibana,并将 **宿主机文件系统** 中 `/nsm/kibana/plugins` 的插件目录作为只读卷挂载到容器中。这意味着在重启 Kibana 之前,必须将插件文件放置在 SO 宿主机上 —— 而不是复制到容器中。
### 前置条件
- 具有 Security Onion 管理节点的 SSH 访问权限
- **构建机器** 上安装了 Node.js 20+(SO 节点本身不需要)
- 在构建之前了解您的 SO Kibana 版本 —— 插件的 `kibanaVersion` 必须完全匹配
**查找您的 SO Kibana 版本:**
```
sudo docker exec so-kibana cat /usr/share/kibana/package.json | python3 -c "import sys,json; print(json.load(sys.stdin)['version'])"
```
### 步骤 1 — 为您的 SO Kibana 版本构建插件
在您的构建机器上,克隆仓库并使用 SO 正在运行的确切 Kibana 版本进行构建:
```
npm install
KIBANA_VERSION= npm run build
```
这将生成 `target/babel--kbn.zip`(例如 `babel-2.0.0-kbn9.3.4.zip`),其中同时包含 Kibana 插件 (`babel/`) 和 Babel API (`api/`)。
### 步骤 2 — 将 zip 文件复制到 SO 宿主机
```
scp target/babel-2.0.0-kbn.zip @:/tmp/
```
### 步骤 3 — 将插件解压到 SO 插件目录
在 SO 宿主机上,仅将 `babel/` 插件目录解压到 `/nsm/kibana/plugins/`:
```
# 如果不存在,则创建 plugins 目录
sudo mkdir -p /nsm/kibana/plugins
# 解压(SO 上没有 unzip,请使用 Python)
cd /tmp
python3 -m zipfile -e babel-2.0.0-kbn.zip .
# 将插件移动到相应位置
sudo cp -r babel/ /nsm/kibana/plugins/babel
```
验证结构:
```
ls /nsm/kibana/plugins/babel/
# 预期: kibana.json package.json server/ target/
```
### 步骤 4 — 重启 Kibana
使用 SO 管理命令(不要使用 `docker restart`):
```
sudo so-kibana-restart
```
Kibana 大约需要 60–90 秒才能启动。查看日志:
```
sudo tail -f /opt/so/log/kibana/kibana.log
# 或者
sudo docker logs -f so-kibana 2>&1 | grep -i "babel\|plugin\|error"
```
成功加载将显示如下行:
```
Plugin "babel" is enabled
```
### 步骤 5 — 部署 Babel API
Kibana 插件需要 Babel API(Python Flask 服务)来进行规则转换、覆盖率分析和 IR 准备就绪评估。从解压后的 zip 文件中复制 `api/` 目录,并在 SO 宿主机或可访问的宿主机上运行它:
```
cd /tmp/api
# 选项 A — 使用 Docker 运行(推荐)
docker build -t babel-api .
docker run -d --name babel-api -p 8001:8001 babel-api
# 选项 B — 直接使用 Python 运行
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python3 app.py
```
API 默认监听 `8001` 端口。
### 步骤 6 — 在 Kibana 中配置 Babel API URL
Babel 需要知道 Babel API 运行的位置。将以下内容添加到您的 SO Kibana 配置中:
```
sudo vi /opt/so/conf/kibana/kibana.yml
```
```
babel.sigmaApiUrl: "http://:8001/v1"
```
然后再次重启 Kibana:
```
sudo so-kibana-restart
```
### 验证
```
# 检查 Kibana 是否加载了该插件
sudo docker logs so-kibana 2>&1 | grep -i babel
# 检查 Babel API 是否可访问
curl http://:8001/health
# → {"status": "ok"}
# 检查 Babel 自身的状态端点
curl -u elastic: http://localhost:5601/api/babel/status
```
然后在浏览器中打开 Kibana,并在左侧导航栏中查找 **Babel**。
### 卸载
```
sudo rm -rf /nsm/kibana/plugins/babel
sudo so-kibana-restart
```
## 从源码构建
### 1. 安装 Node 依赖
```
npm install
```
### 2. 构建
构建脚本会从本地安装或名为 `kibana-local-dev` 的正在运行的 Docker 容器中自动检测您的 Kibana 版本。如果两者都不存在,请显式设置版本:
```
KIBANA_VERSION=9.3.4 npm run build
```
成功后,脚本将生成:
- `target/babel/` — 组装好的插件目录
- `target/babel--kbn.zip` — 可随时用于 `kibana-plugin install` 的可分发 zip 文件(例如 `babel-2.0.0-kbn9.3.4.zip`)
如果 Docker 容器 `kibana-local-dev` 正在运行,脚本还会将插件复制到容器中并自动重启 Kibana。
## 配置
将以下内容添加到 `kibana.yml` 中:
```
# Babel API 的 URL — 必需,在 Docker 外部没有默认值可用
babel.sigmaApiUrl: "http://:/v1"
# Kibana 在部署 detection rules 时用于调用自身的 URL
# 默认为 http://localhost:5601 用于本地测试 — 如果 Kibana 位于 proxy 之后或在不同主机上,请进行更改。示例如下:
babel.kibanaUrl: "http://localhost:5601"
```
### 环境变量(可选)
| 变量 | 用途 |
|---|---|
| `SIGMA_API_KEY` | 如果 Babel API 需要身份验证,则转发给它的 Bearer token |
## Elasticsearch 前置条件
该插件会在您的 Elasticsearch 集群中创建并使用两个索引:
| 索引 | 用途 |
|---|---|
| `babel_sigma_doc` | 从 GitHub 仓库同步的规则库 |
| `babel_config` | 插件设置(GitHub token、已配置的仓库) |
这两个索引都会在 **当 Kibana 以具有索引创建权限的用户身份连接时**,在首次运行时自动进行引导创建。有两种情况需要手动创建:
- 集群上设置了 `action.auto_create_index: false`
- Kibana 配置为使用内置的 `kibana_system` 用户(在使用 `elastic-start-local` 时很常见),该用户没有 `indices:admin/create` 权限
在上述任一情况下,请在启动 Kibana 之前使用 `elastic` 超级用户创建索引:
```
curl -X PUT "http://localhost:9200/babel_config"
curl -X PUT "http://localhost:9200/babel_sigma_doc"
```
### GitHub 速率限制
规则同步功能会从 GitHub 单独获取每个 YAML 文件。如果没有 token,GitHub 每小时只允许 60 次未经身份验证的请求 —— 这不足以同步像 SigmaHQ 这样的大型仓库(约 3,000 条规则)。**强烈建议使用 GitHub 个人访问令牌。** 请使用仅在目标仓库上具有 `Contents: Read` 权限的细粒度 PAT。将其存储在插件的 Settings → GitHub Token 中。
### 授权
所有插件 API 路由均可供任何经过身份验证的 Kibana 用户访问。没有基于路由的 RBAC —— 只读分析师可以像管理员一样部署规则。如果需要,请在 Kibana Space 或网络层面限制访问。
## 开发
```
# 不执行 build 进行类型检查
npm run typecheck
# 运行测试(涵盖 server + public 的 79 个测试)
npm test
# 完整 build
KIBANA_VERSION=9.3.4 npm run build
```
### 项目结构
```
public/
components/ React UI components
hooks/ Custom hooks (editor sync, auto pipeline selection)
services/ API client
context/ Kibana service provider
server/
routes/ Kibana server-side API routes (/api/babel/*)
api/ Sigma API — FastAPI backend (conversion, validation, AI)
mcp/ MCP server exposing SIGMA tools to Claude Code/Desktop
translation_script/sigma/ Python SIGMA conversion engine (pySigma)
plugin.ts Kibana plugin lifecycle
config.ts Plugin configuration schema
api/ Conversion-only Flask API (bundled in the distribution zip)
scripts/
build.js Build orchestrator (typecheck → compile → webpack → zip)
.github/
workflows/ci.yml CI — plugin typecheck/test/build (+ zip artifact) and Sigma API pytest
```
## 许可证
Babel 自身的源代码采用 [Apache License 2.0](LICENSE) 授权 —— 可免费使用、修改和分发,包括在商业和企业环境中使用,且没有开源您修改内容的义务。
Babel 还捆绑或依赖于遵循各自许可证的第三方组件(例如遵循 Elastic License 2.0 / SSPL 的 Elastic UI,遵循 LGPL 的 pySigma),并且在运行时会获取您选择的内容 —— 来自 GitHub 的 SIGMA 规则和来自您选择的提供商的 LLM —— 每一项都受其自身条款的约束。有关完整列表和您的义务,请参见 [NOTICE](NOTICE) 文件。
标签:AI助手, AI风险缓解, AMSI绕过, Elasticsearch, Kibana插件, MITM代理, PB级数据处理, SIGMA规则, 响应拦截, 威胁检测, 安全运维, 本地大模型, 自动化攻击, 请求拦截, 逆向工具