cpt-ferna02/ticluster
GitHub: cpt-ferna02/ticluster
TICluster 利用 TF-IDF 与 DBSCAN 机器学习算法,将多个公开威胁情报源中的 IOC 聚类为威胁行为者活动,并自动生成 Sigma 检测规则和置信度评分。
Stars: 0 | Forks: 0
# ⬡ TICluster
**由 ML 驱动的威胁行为者归因引擎。**
TICluster 每隔几个小时自动从公开的威胁情报源中提取真实的失陷标识符 (IOC),然后利用机器学习将它们归类为可能的威胁行为者活动——无需依赖厂商标签。
## 截图
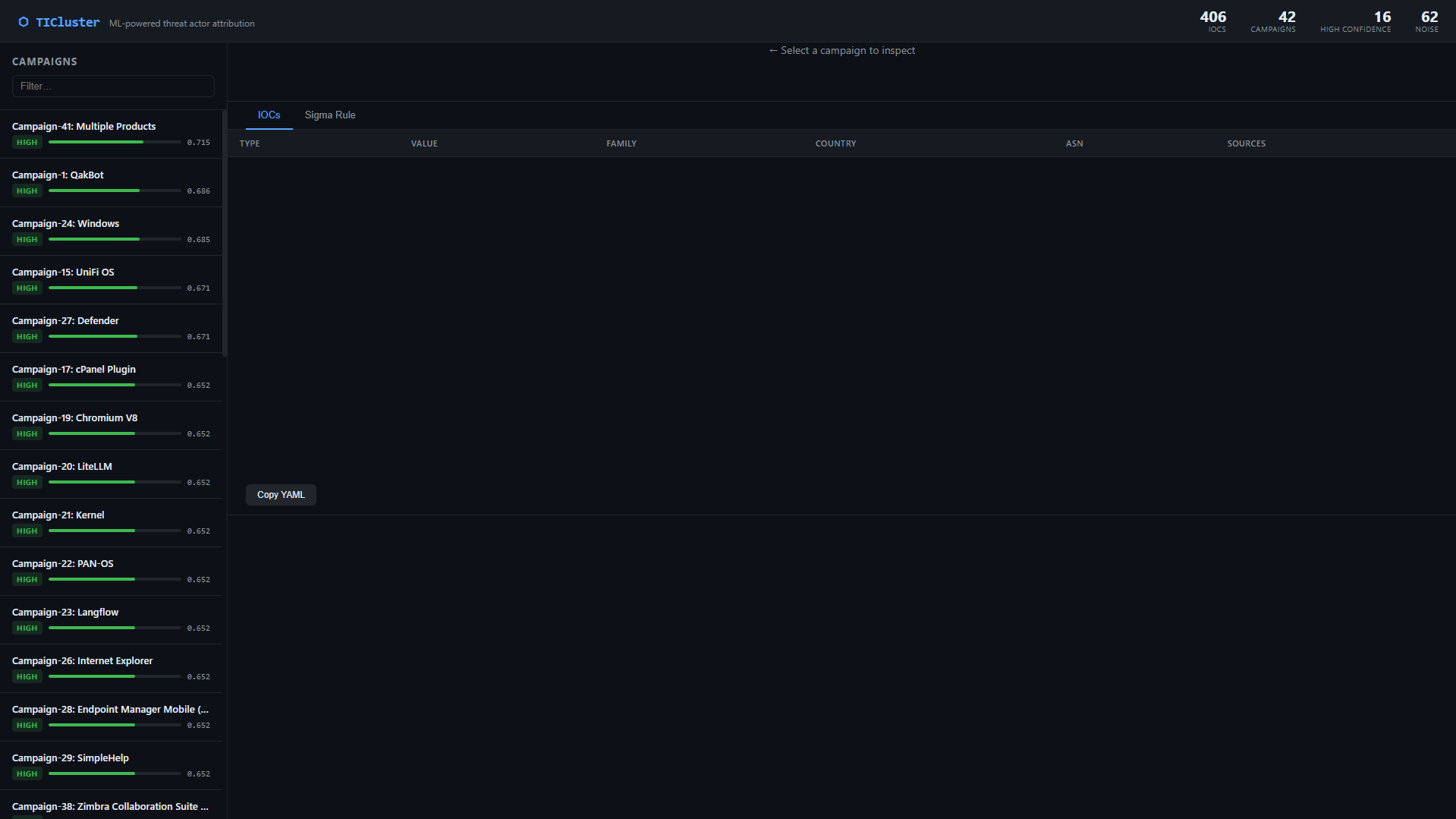
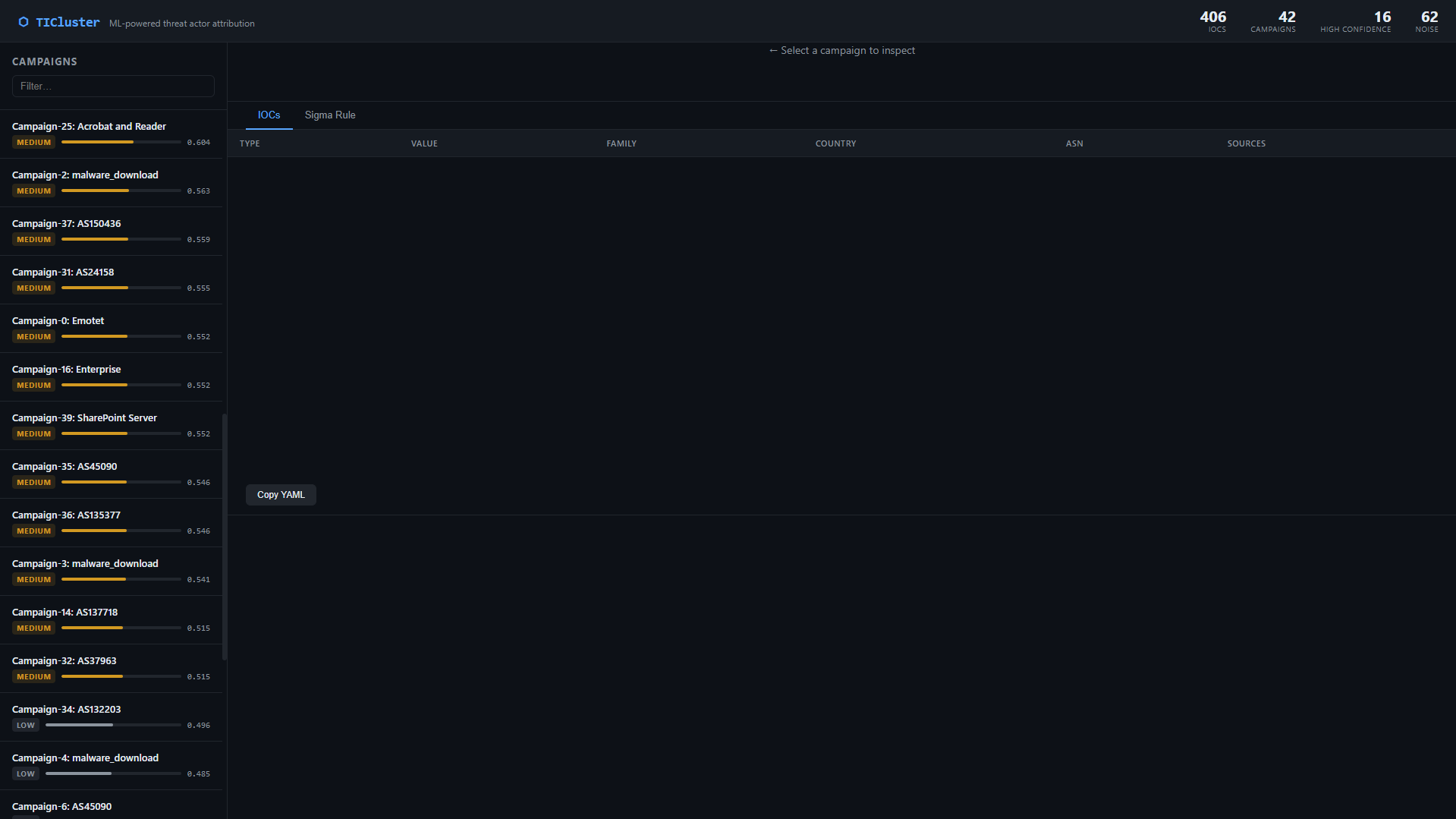
### 仪表盘 — 带有置信度分数的活动列表
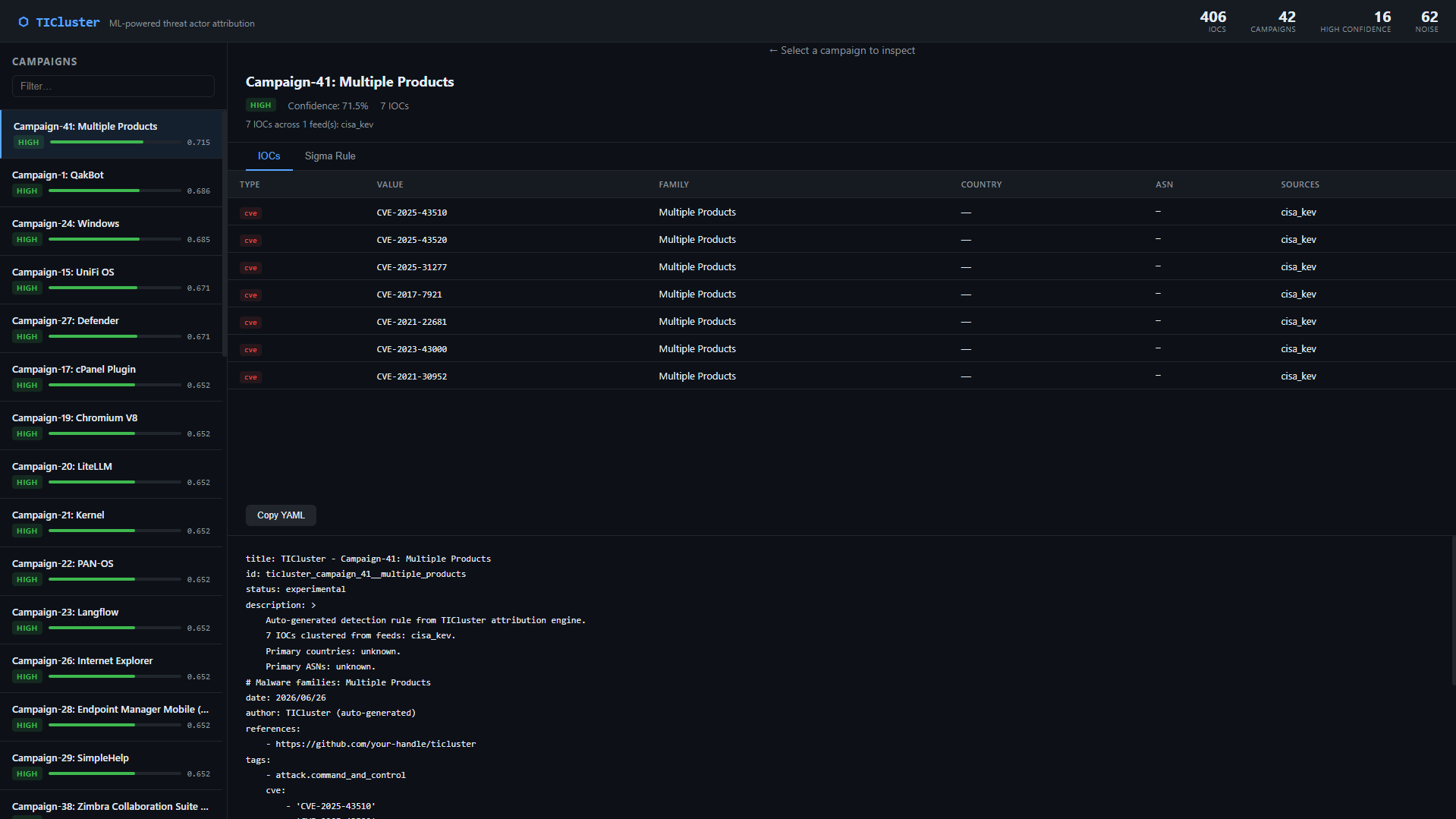
### 活动详情 — CVE 集群(IOCs 标签页)
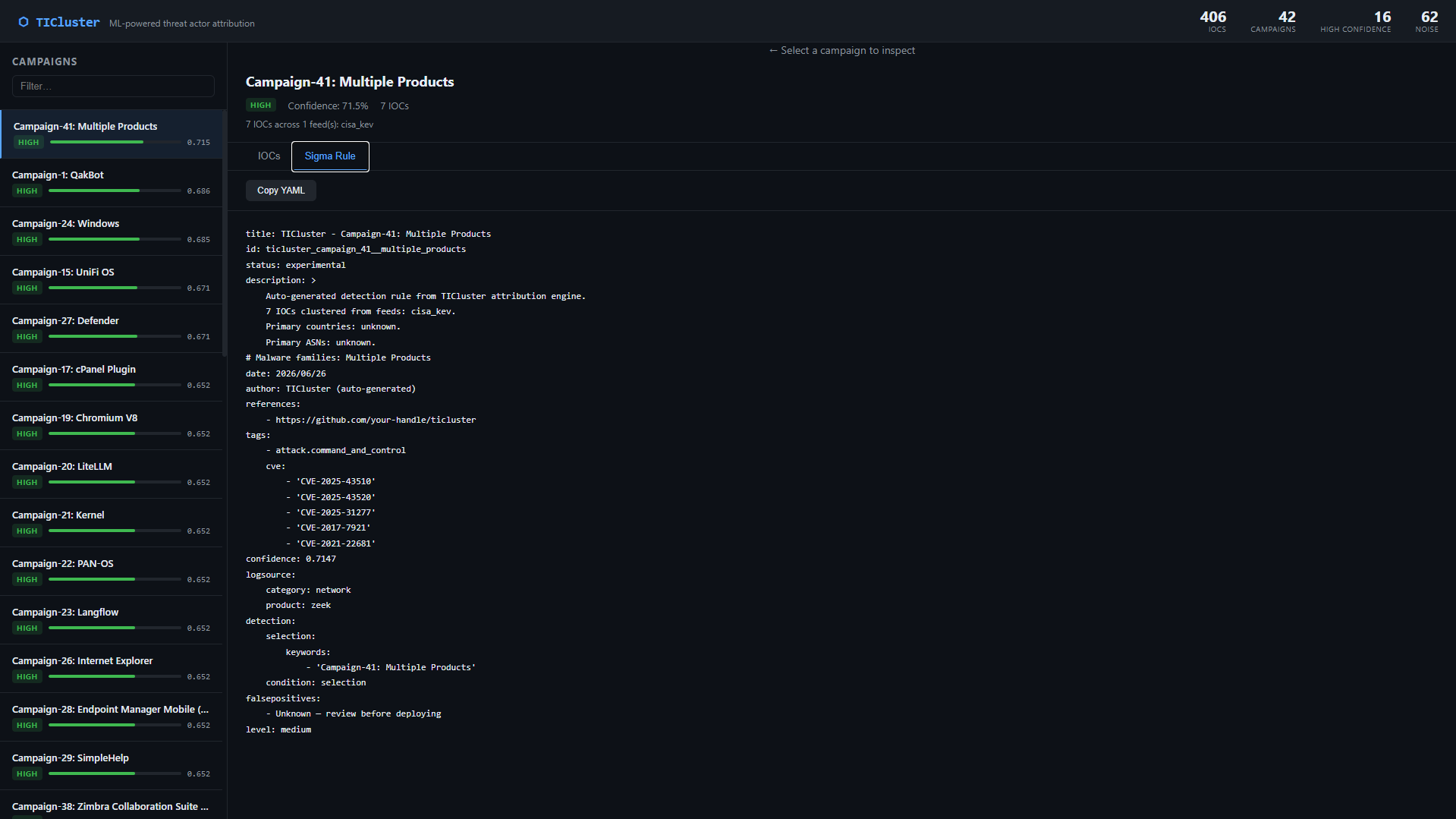
### 自动生成的 Sigma 规则 (YAML)
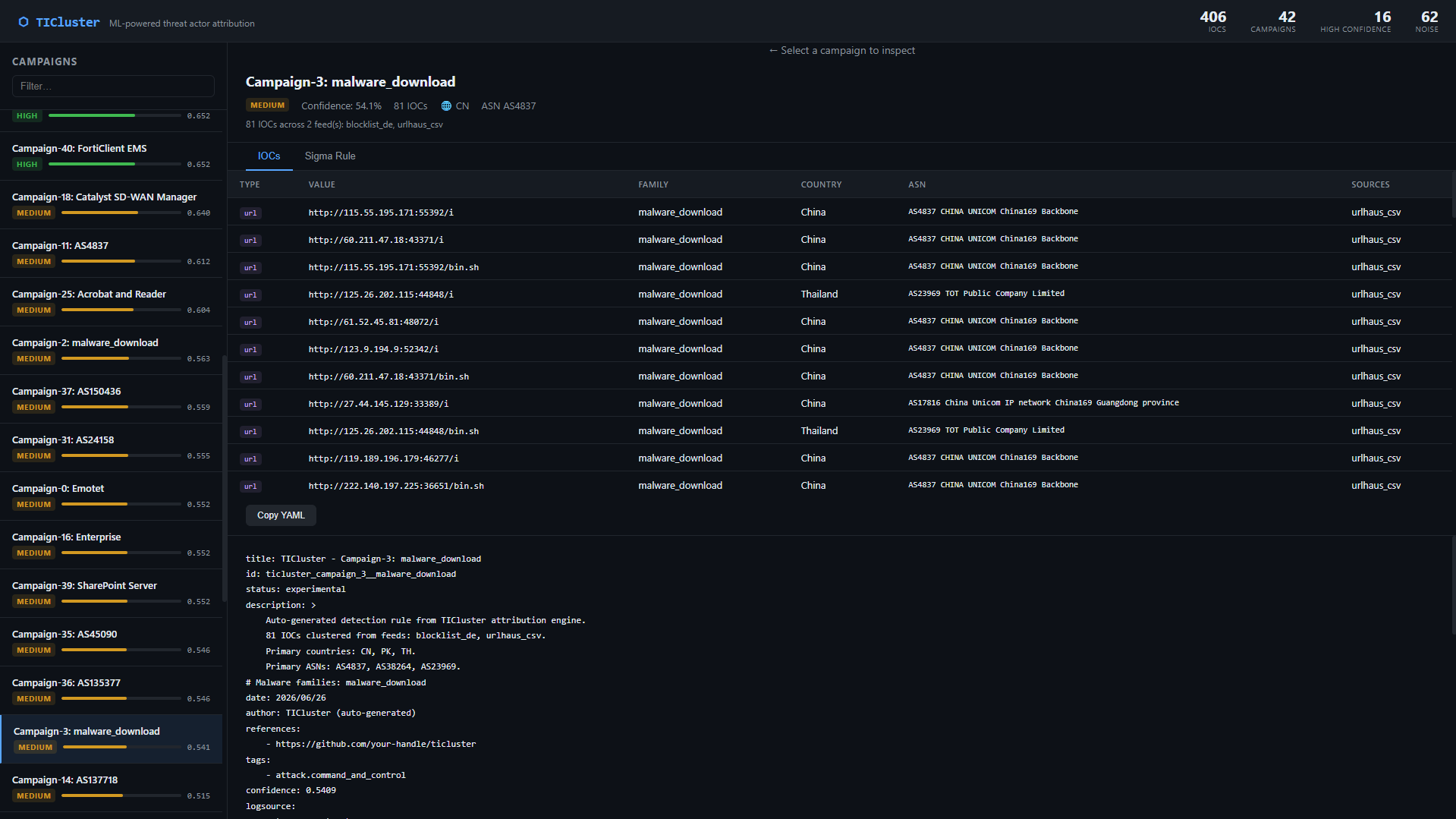
### 中国联通僵尸网络集群 — 81 个 IOC,跨情报源归因
### 中国联通集群 — Sigma 规则输出
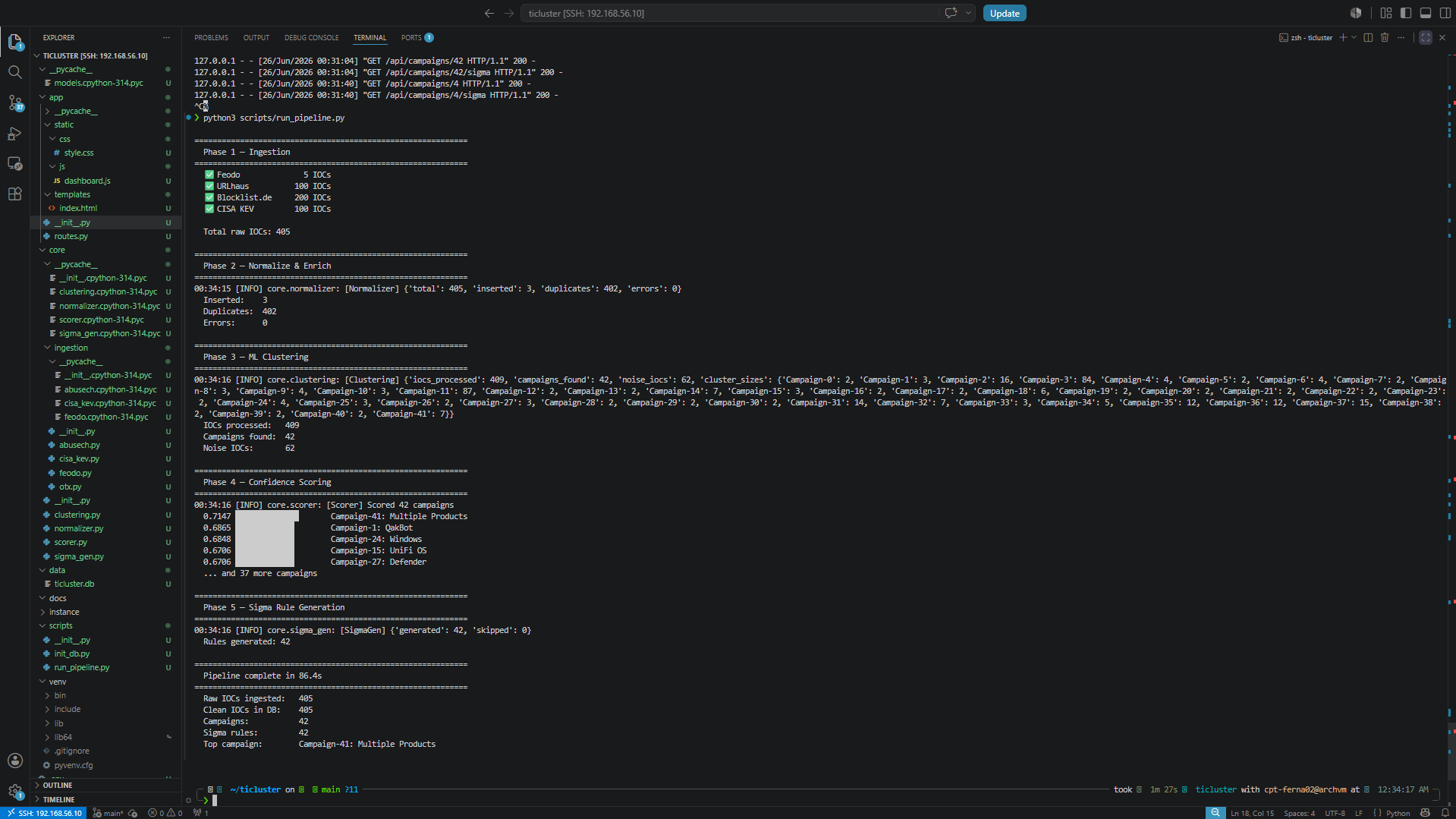
### 完整 Pipeline 运行 — 全部 5 个阶段,86 秒
## 与众不同之处
其他的所有威胁情报项目都在对单个 IOC 进行评分或提取。TICluster 提出了一个更难的问题:来自多个情报源的一组互不相关的 IOC,其行为是否像同一个威胁行为者?
这种聚类逻辑——通过 ASN、托管服务提供商、恶意软件家族和 URL 结构来跨情报源关联基础设施——正是区分初级分析师工具与高级分析师工具的关键。
## 技术栈
| 层级 | 技术 |
|---|---|
| 语言 | Python 3.14 |
| Web | Flask + Jinja2 |
| 数据库 | SQLite |
| ML | scikit-learn (TF-IDF + DBSCAN) |
| 富化 | ip-api.com(免费,无需密钥) |
| 前端 | Vanilla JS + CSS custom properties |
| 部署 | Railway.app |
无需任何付费 API。完全在本地虚拟机上运行。
## 架构
```
Threat Feeds (4 sources)
│
▼
core/ingestion/ ← pull raw IOCs from each feed
├── feodo.py ← Emotet/QakBot C2 IPs
├── abusech.py ← URLhaus malicious URLs + Blocklist.de IPs
├── cisa_kev.py ← CISA Known Exploited Vulnerabilities
└── otx.py ← AlienVault OTX (requires free API key)
│
▼
core/normalizer.py ← deduplicate, enrich with ASN/geo, write to DB
│
▼
core/clustering.py ← TF-IDF vectorization → cosine similarity → DBSCAN
│
▼
core/scorer.py ← weighted confidence score per campaign
│
▼
core/sigma_gen.py ← auto-generate Sigma YAML detection rules
│
▼
Flask dashboard ← campaign list, IOC table, Sigma rule viewer
```
## ML 方法
### 特征工程
原始 IOC 在向量化之前会被转换为行为特征字符串。模型永远不会看到原始的 IP 或 URL 值——它看到的是行为信号:
```
asn_as14061_digitalocean_llc org_digital_ocean country_us
type_ip family_qakbot source_feodo source_blocklist_de
```
如果来自完全不同情报源的两个 IP 共享相同的托管基础设施和恶意软件家族,它们就会被聚类在一起——这正是威胁分析师在进行手动归因时会使用的信号。
### 聚类
- **TF-IDF 向量化**将特征字符串转换为加权向量
- **余弦相似度**测量 IOC 之间的行为距离
- **DBSCAN** 在不要求固定集群数量的情况下对密集区域进行分组,并正确地将异常值标记为噪音,而不是强行将它们塞入集群中
### 评分
每个活动都会根据四个加权信号获得一个置信度浮点数 (0.0–1.0):
| 信号 | 权重 | 理由 |
|---|---|---|
| IOC 数量 | 25% | 越多 IOC = 模式越强 |
| 来源多样性 | 25% | 跨情报源印证 |
| ASN 集中度 | 30% | 紧密的基础设施 = 强信号 |
| 恶意软件家族一致性 | 20% | 命名家族 = 最强归因 |
## 挑战与解决方案
### 1. URLhaus CSV 没有表头行
**问题:** URLhaus 的批量下载是一个无表头的 CSV。Python 的 `csv.DictReader` 将第一行数据作为列名消耗掉了,导致每个 `url` 字段返回的都是空值——摄取器返回了 100 条带有空白值的记录。
**发现:** 对 endpoint 运行 `curl` 并打印原始的前两行,发现该文件直接以带引号的数据行开始,而以 `#` 为前缀的注释行被单独剥离了。
**修复:** 手动剥离了注释行,然后将硬编码的 `fieldnames` 列表传递给 `DictReader`,这样列映射就是按位置的,而不是依赖于根本不存在的表头行。
### 2. 模型与核心模块之间的 SQLite schema 不匹配
**问题:** SQLAlchemy 模型定义了如 `last_updated` 的列,而后来编写的 normalizer 却使用了 `updated_at`。聚类引擎再次使用了不同的名称。这导致了静默失败——没有崩溃,只是丢失了数据。
**发现:** 运行 `sqlite3 data/ticluster.db ".schema iocs"` 显示了磁盘上的实际列名,这与代码期望的名称不匹配。
**修复:** 使用 `ALTER TABLE` 将缺失的列(`fingerprint`、`sources`、`country_code`、`org`)添加到运行中的数据库,而不是重新创建它并丢失已摄取的数据。将所有模块中的列引用统一为规范的 schema。
### 3. 数据库路径不一致(项目根目录 vs data/)
**问题:** `scripts/init_db.py` 在 `data/ticluster.db` 创建了数据库,但 `core/normalizer.py` 硬编码了项目根目录下的 `ticluster.db`。每次写入都写到了与每次读取不同的文件中——normalizer 看起来在工作,但没有东西被持久化到真正的数据库中。
**发现:** 检查 `sqlite3 data/ticluster.db ".schema"` 显示 schema 为空,而那个幽灵般的根目录数据库却有数据。
**修复:** 在所有核心模块中统一使用 `DB_PATH = "data/ticluster.db"`。使得 schema 检查成为每当模块静默返回零结果时的第一个调试步骤。
### 4. Python 3.14 上的 SQLAlchemy datetime 解析崩溃
**问题:** SQLite 将 datetime 存储为纯字符串。一些 IOC 行在 datetime 列中有空字符串 `''`(来自不提供 `first_seen` 的摄取器)。Python 3.14 上的 SQLAlchemy 使用 C 扩展 (`processors.pyx`) 自动将这些字符串转换为 `datetime` 对象——结果遭遇严重崩溃,抛出 `ValueError: Invalid isoformat string: ''`。
**发现:** Werkzeug 调试器的回溯信息将 `sqlalchemy.cyextension.processors.str_to_datetime` 定位为崩溃点,该崩溃是在 `/api/campaigns` 路由加载 IOC 关系时触发的。
**修复:** 双重解决方案:
1. 原地清理错误数据:
`UPDATE iocs SET first_seen = NULL WHERE first_seen = ''`
2. 在引擎选项中通过 `"connect_args": {"detect_types": 0}` 禁用 SQLAlchemy 的自动 datetime 解析,然后在 `models.py` 中使用 `_dt()` 辅助函数安全地处理转换,该函数会在调用 `isoformat` 之前检查 `hasattr(val, "isoformat")`。
### 5. 括号粘贴模式损坏终端命令
**问题:** 将多行命令从编辑器复制到 Zsh 时,会在它们前面加上 `[200~` 并在后面加上 `~`,从而破坏了参数。`flask --port 5000` 变成了 `flask --port '5000V;'`,导致出现 `zsh: bad pattern` 错误。对于用作快速修复的多行 Python 单行命令来说,这尤为痛苦。
**修复:** 使用 `python3 -c "..."` heredoc 和 shell 脚本 (`run.sh`),避免将多行命令直接粘贴到终端中。对于文件的原地修复,使用了可以输入或作为脚本运行的 `python3 -c "open(...).write(...)"` 模式。
### 6. 并非所有 Python 版本都支持 `datetime.UTC` 常量
**问题:** 使用了 `datetime.now(datetime.UTC)` 来替换已废弃的 `datetime.utcnow()`,但 `datetime.UTC` 仅在 Python 3.11 中添加。尽管项目运行在 Python 3.14 上,但在运行时却导致了 `AttributeError: type object 'datetime.datetime' has no attribute 'UTC'`——函数内部的 import 作用域阻止了其解析。
**修复:** 改用 `from datetime import timezone` 以及 `datetime.now(timezone.utc)`,这适用于 Python 3.6+。
### 7. 用于生成有意义集群的 DBSCAN epsilon 调优
**问题:** 使用 `eps=0.5` 的初始运行产生了一个包含 80% IOC 的巨型集群——这对归因毫无用处。在模型看来,DigitalOcean 上的每个 IP 都是一样的。
**修复:** 将 `eps` 降低到 `0.4` 并设置 `min_samples=2`。这从 406 个 IOC 中生成了 42 个不同的活动,其中 62 个被正确作为噪音拒绝。这些噪音 IOC 是真正的一次性产物——强行将它们塞入集群会降低归因质量,而不是提高它。
## 结果(示例运行)
```
Pipeline runtime: 86.4s
Raw IOCs ingested: 405
Clean IOCs in DB: 405 (402 cross-source duplicates merged on re-run)
Campaigns found: 42
Noise IOCs: 62
Sigma rules: 42
Top campaigns by confidence:
0.7147 Campaign-41: Multiple Products (7 CVEs, CISA KEV, high consistency)
0.6865 Campaign-1: QakBot (3 IPs, AWS AS14618, cross-feed)
0.6848 Campaign-24: Windows (CVE cluster)
0.6706 Campaign-15: UniFi OS (CVE cluster)
0.6706 Campaign-27: Defender (CVE cluster)
```
**值得注意的集群 — Campaign-3(81 个 IOC):** 中国联通骨干网 IP (`AS4837`) 全部在高临时端口上提供 `/i` 和 `/bin.sh` endpoint,并得到了 URLhaus 和 Blocklist.de 的印证。典型的 Mirai/僵尸网络加载器基础设施。完全通过 URL 路径模式和 ASN 集中度识别出来——无需任何厂商标签。
## 在本地运行
```
git clone https://github.com/your-handle/ticluster
cd ticluster
python3 -m venv venv && source venv/bin/activate
pip install -r requirements.txt
python3 scripts/init_db.py
python3 scripts/run_pipeline.py # ~90s, enriches IPs via ip-api.com
./run.sh # Flask on http://localhost:5000
```
可选 — 将 AlienVault OTX API 密钥添加到 `.env`:
```
OTX_API_KEY=your_key_here
```
## 定时任务
```
0 */6 * * * cd /path/to/ticluster && ./venv/bin/python scripts/run_pipeline.py
```
每 6 小时运行一次。获取新鲜的 IOC,重新聚类,自动生成新的 Sigma 规则。
## 许可证
MIT
标签:Apex, Flask, Python, 威胁情报, 安全运营, 开发者工具, 扫描框架, 无后门, 机器学习, 逆向工具