bastion-soft/pi-detector-bench
GitHub: bastion-soft/pi-detector-bench
一个开放的、模型无关的 Prompt Injection 检测器基准测试框架,通过双维度评估(攻击捕获率与真实流量误报率)和阈值无关的排名方法,帮助客观比较各类 LLM 注入防御方案的实际效果。
Stars: 0 | Forks: 0
# Prompt Injection 检测器基准测试
[](https://github.com/bastion-soft/pi-detector-bench/actions/workflows/ci.yml)
[](LICENSE)
[](https://colab.research.google.com/github/bastion-soft/pi-detector-bench/blob/main/notebooks/benchmark_colab.ipynb)
**一个开放、与模型无关的 prompt injection *检测器* 基准测试 —— 在两个维度上进行衡量(对真实流量的攻击捕获率 **和** 误报率),与阈值无关,且可从原始分数完全复现。**
大多数 prompt injection 基准测试只衡量一件事:检测器能否识别出攻击?这只是故事的一半。一个会将四分之一*正常*用户消息标记为异常的检测器是一场故障,而不是护栏 —— 而一个在一个阈值下调校得看似出色的检测器,在另一个阈值下可能会彻底崩溃。该基准测试同时衡量**这两个维度**,并在**相同的捕获率**下对检测器进行比较,因此排名不会依赖于任何模型的 0.5 阈值恰好落在何处。
## 检测器性能
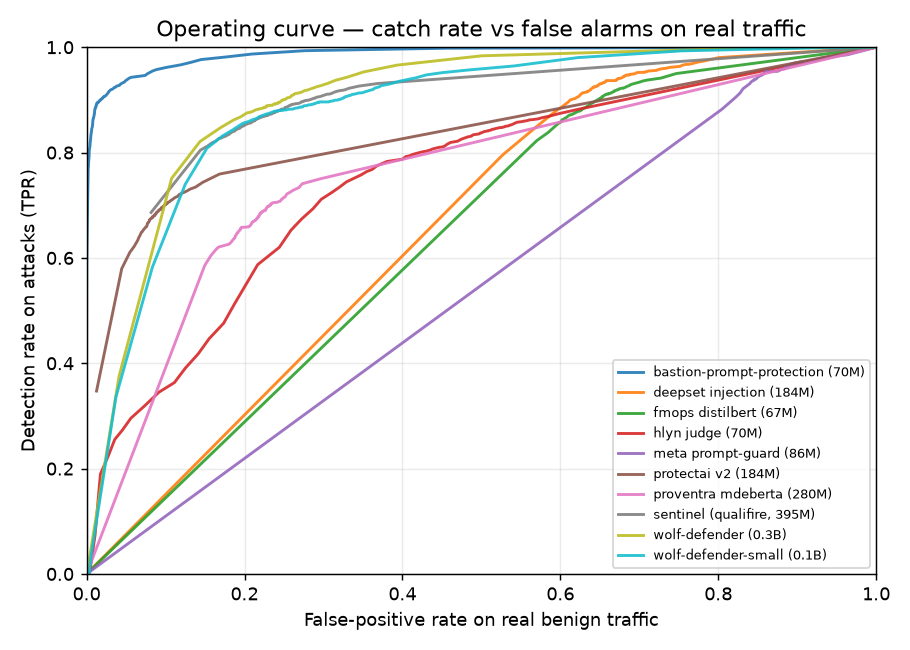
不同检测器的误报率(X 轴)与检测率(Y 轴)对比。您需要针对符合您业务领域的攻击数据集以及您真实的历史流量进行基准测试。
## 讨论
一篇 [Medium 文章](https://medium.com/@mantas.urbonas/measuring-prompt-injection-defences-e79b79471846) 提供了关于 2026 年对 LLM prompt injection 检测器需求的更多背景信息,以及此类基准测试背后的动机。
## 排行榜(初始结果)
十个开源检测器,四个预留的对抗性基准测试。完整的表格和延迟见 [`results/leaderboard.md`](results/leaderboard.md);这些是**初始结果** —— [添加你的模型](CONTRIBUTING.md)。
| Detector | Params | Detection (avg AUC) | False positives (real traffic, @0.5) | FPR @ 95% catch |
|---|---:|---:|---:|---:|
| bastion-prompt-protection | 70M | 0.991 | 1.24% | 7.71% |
| sentinel (qualifire) | 395M | 0.955 | 23.60% | 46.30% |
| wolf-defender | 0.3B | 0.954 | 24.03% | 34.63% |
| hlyn judge | 70M | 0.950 | 21.67% | 77.12% |
| wolf-defender-small | 0.1B | 0.941 | 28.79% | 43.79% |
| proventra mdeberta | 280M | 0.843 | 21.83% | 82.22% |
| protectai v2 | 184M | 0.820 | 8.82% | 100.00% |
| deepset injection | 184M | 0.766 | 65.89% | 69.44% |
| fmops distilbert | 67M | 0.700 | 64.98% | 74.64% |
| meta prompt-guard† | 86M | 0.314 | 88.30% | 85.77% |
这张表的*用途*:请注意,AUC 接近的检测器在误报率上却相差甚远,而且一些在 0.5 阈值下较低的低误报率(FPR)数据是通过漏报换来的(在“@95% catch”列中可见)。**请阅读 [`results/FINDINGS.md`](results/FINDINGS.md) 以获取客观真实的解读** —— 包括每个检测器的弱点。† `meta prompt-guard` 是一个已弃用、容易过度触发的模型,保留在此仅作上下文参考(详见 FINDINGS)。
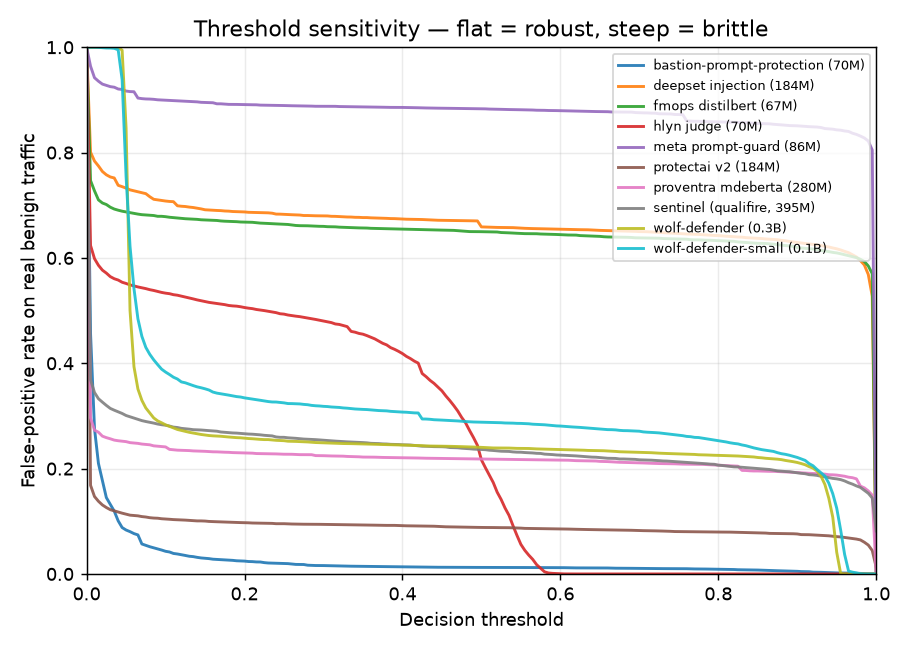
*随着决策阈值变化,真实流量上的误报情况 —— 一条平缓的线代表对阈值具有鲁棒性,而陡峭的线则代表脆弱。这就是为什么单一的固定阈值数据可能会产生误导,也是为什么我们还要在固定的捕获率下进行比较的原因。完整解读和操作曲线:[`results/FINDINGS.md`](results/FINDINGS.md)。*
## 为什么会有这个基准测试
它不仅仅是另一个攻击数据集 —— 它是一套**方法论**(见 [`METHODOLOGY.md`](METHODOLOGY.md)):
- **两个维度。** 检测(它能捕获攻击吗?)**以及**在**真实聊天流量**(WildChat + LMSYS)上的误报,而不是合成的正常流量。仅凭单一维度上的数据几乎毫无意义。
- **与阈值无关。** 除了固定的 0.5 视图外,我们还报告了**在固定检测率下的 FPR**(将每个检测器调整为捕获 95% 的攻击,并比较误报成本)、**EER** 以及完整的**操作曲线** —— 这样就不会有任何检测器因其 0.5 阈值的落点不同而受益或受损。
- **间接/结构化注入。** 一个单独的维度,专门用于隐藏在数据(文档、JSON、工具输出)内部的注入,并附带结构化数据的误报衡量指标。
- **从原始分数可复现。** 每个检测器的每个 prompt 得分均已提交 (`results/scores/`),因此所有表格、曲线和操作点都可以在离线状态下重新计算,无需 GPU。确切发布的数字不依赖于对某次 GPU 运行的信任。
## 自行运行
```
git clone https://github.com/bastion-soft/pi-detector-bench.git
cd pi-detector-bench
pip install -e .
huggingface-cli login # optional — only for gated entries/datasets
python -m scripts.run_leaderboard --dump-scores results/scores # detection
python -m scripts.measure_false_positives --dump-scores results/scores # false positives
python -m scripts.eval_indirect --dump-scores results/scores_indirect # indirect/structured
# 后处理 — 无 GPU,从转储的 scores 重新计算每个 table:
python -m scripts.rebuild_results_from_scores
python -m scripts.analyze_operating_points
python -m scripts.analyze_operating_points --scores-dir results/scores_indirect --within-set --label indirect
python -m scripts.plot_operating_points # optional curves (pip install -e ".[plot]")
```
没有 GPU?在免费的 Colab T4 上运行全套测试 —— 打开 [`notebooks/benchmark_colab.ipynb`](notebooks/benchmark_colab.ipynb)。
## 添加你的检测器
只需一个文件的 PR 即可。将你的模型追加到 [`models.yaml`](models.yaml):
```
- name: "my-detector (220M)"
hf_id: "my-org/my-prompt-injection-detector"
attack_label: 1 # softmax index meaning "attack" (or a list to sum)
params: "220M"
```
……然后运行测试套件并包含新的结果行和分数。完整指南 —— 包括如何提出**方法论变更**或添加**数据集** —— 详见 [`CONTRIBUTING.md`](CONTRIBUTING.md)。
## 文档
- **[`METHODOLOGY.md`](METHODOLOGY.md)** —— 检测器是如何评分的,以及为什么这样设计(双轴 / 与阈值无关的设计)。
- **[`results/FINDINGS.md`](results/FINDINGS.md)** —— 对初始结果的客观真实解读,包含图表和每个检测器的弱点。
- **[`CONTRIBUTING.md`](CONTRIBUTING.md)** —— 添加检测器、数据集或方法论变更。
## 许可证
代码:**MIT**(见 [`LICENSE`](LICENSE))。评估数据集保留其原始许可证 —— 部分数据集是受限的,需要先在 HuggingFace Hub 上接受条款。提交的结果仅包含每个 prompt 的得分和标签,绝对不包含数据集的 prompt 文本。
标签:AI安全, Chat Copilot, DLL 劫持, 大语言模型, 模型评估, 评估指标, 逆向工具