iamyadavvikas/incident-response-lab
GitHub: iamyadavvikas/incident-response-lab
一个基于 Docker 的生产级微服务故障响应训练实验室,让工程师在完全可观测的本地环境中安全练习分布式系统的故障检测、根因分析与修复。
Stars: 0 | Forks: 0
# 故障响应与可靠性工程实验室
一个生产级的故障响应训练环境,旨在模拟微服务订单处理平台上的真实可靠性故障。专为 SRE、平台工程师和后端开发者设计,用于在本地机器上完全插桩的 11 个服务技术栈中练习检测、分流、根因分析和修复。
## 问题陈述
现代分布式系统会以可预见的方式发生故障——资源饱和、上游延迟、流量激增——但大多数工程师只能在生产环境中遇到这些故障,而生产环境往往风险极高且影响范围极广。
**痛点在于:** 目前缺乏一个安全、逼真且完全可观测的环境,让工程师能够:
- 触发真实的基础设施故障(CPU 飙升、延迟注入、流量洪峰)
- 通过生产级的监控(Prometheus 告警、Grafana 仪表盘、分布式追踪)观察其影响
- 遵循正式的 SRE 方法论(时间轴、严重性分类、RCA、事后总结)进行故障响应练习
- 在不危及面向客户系统的情况下,反复迭代并验证修复方案
**本项目的解决方案:** 提供一个便携的、基于 Docker 的微服务平台,内置故障模式、全面的可观测性以及详细的故障场景文档——让工程师能够在低风险环境中培养故障响应的肌肉记忆。
## 解决方案
**故障响应与可靠性工程实验室** 提供:
- **11 个服务的微服务平台** —— Order API (FastAPI)、后台 worker、Redis (缓存 + 队列)、PostgreSQL (订单数据库)、模拟的第三方 API、OpenTelemetry collector、Prometheus + Grafana、自定义 exporter 以及负载生成器
- **3 种精心设计的故障模式** —— Redis CPU 饱和、外部 API 延迟 SLO 违规、10 倍流量激增
- **生产级可观测性** —— Prometheus 告警规则、Grafana 仪表盘 (6 个面板)、OpenTelemetry 分布式追踪、每个服务上的 Prometheus 指标
- **混沌工程脚本** —— 4 个用于触发和监控故障的工具 (`redis-cpu-stress.py`、`latency-injector.sh`、`traffic-surge.py`、`redis-exporter.py`)
- **完整的故障文档** —— 包含时间轴、RCA、指标和行动项的 3 份故障报告,以及一份带有 30 天行动计划的综合事后总结
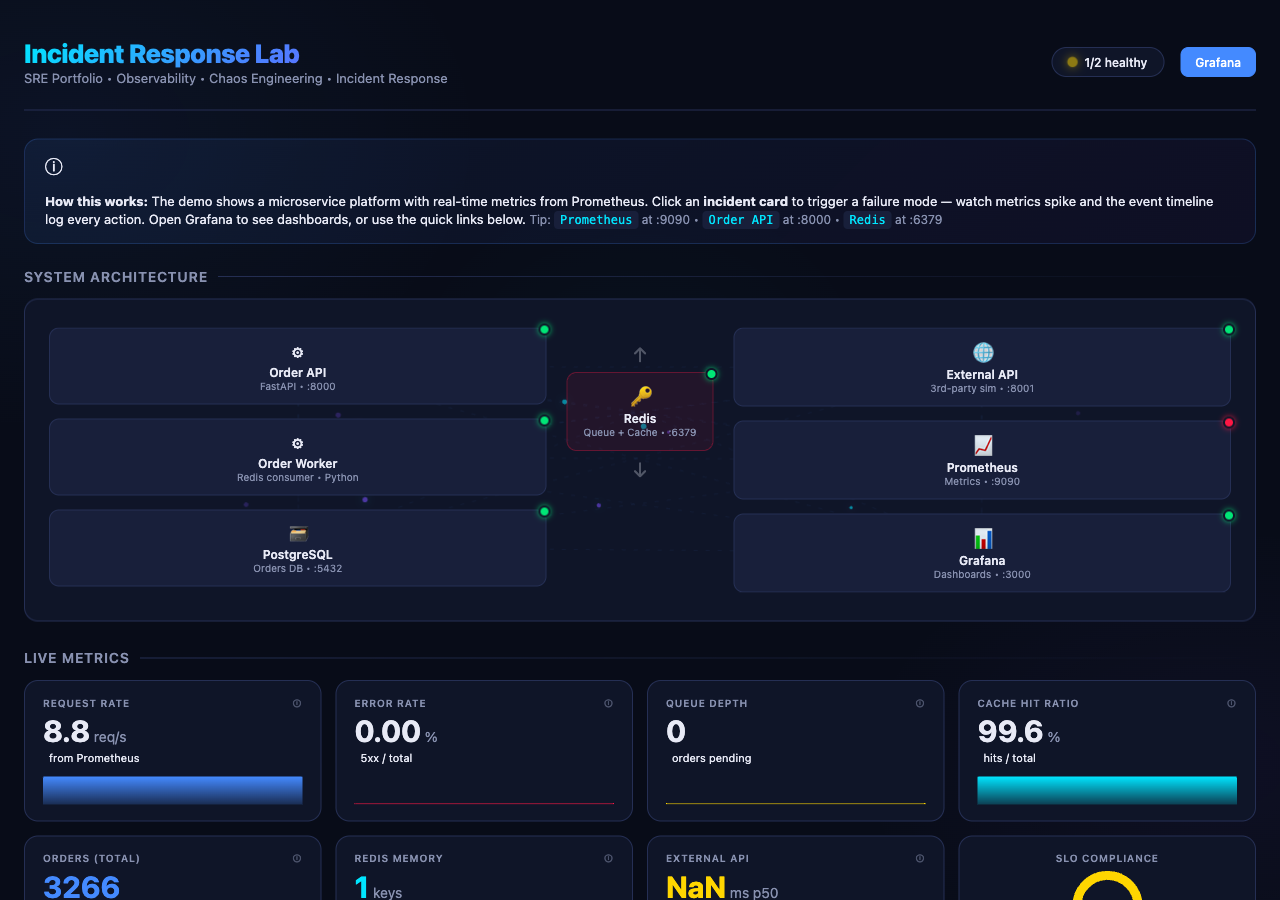
- **交互式演示页面** —— 实时 Prometheus 指标、架构状态、可点击的故障触发器、事件时间轴
## 架构
```
┌──────────────────────────────────────────────────────────────────────────┐
│ │
│ Browser/Demo Page (:8081) Client Traffic │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────┐ ┌───────────────────┐ ┌───────────────────┐ │
│ │ Demo Page │ │ Order API (:8000)◄─────┤ Load Generator │ │
│ │ index.html │ │ FastAPI + OTEL │ │ (curl/sleep) │ │
│ └────────────┘ └──────┬──────────┬──┘ └───────────────────┘ │
│ │ │ │
│ ┌────────▼──┐ ┌────▼────────┐ │
│ │ Redis │ │ PostgreSQL │ │
│ │ cache │ │ orders DB │ │
│ │ + queue │ │ │ │
│ └────┬─────┘ └──────┬───────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌────┴─────┐ ┌─────┴────────┐ │
│ │ Worker │ │ Order API │ │
│ │ (:none) │ │ (direct) │ │
│ │ bg proc │ │ │ │
│ └──────────┘ └──────────────┘ │
│ │
│ ┌──────────────────┐ ┌─────────────────────┐ │
│ │ Mock External │ │ OTEL Collector │ │
│ │ API (:8001) │ │ (:4317 gRPC) │ │
│ │ FastAPI + OTEL │ │ → Prometheus (:8889)│ │
│ └──────────────────┘ └─────────────────────┘ │
│ │
│ ┌────────────┐ ┌──────────────────┐ ┌────────────┐ │
│ │ Prometheus │ │ Redis Exporter │ │ Postgres │ │
│ │ (:9090) │ │ (:9121) │ │ Exporter │ │
│ │ + Alerts │ │ custom Python │ │ (:9187) │ │
│ └────────────┘ └──────────────────┘ └────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ │
│ │ Grafana │ │
│ │ (:3000) │ │
│ │ Dashboard│ │
│ └──────────┘ │
└──────────────────────────────────────────────────────────────────────────┘
```
### 数据流
1. **订单创建** —— 客户端 POST 请求至 Order API → 写入 PostgreSQL → 推送订单 ID 至 Redis 列表 `orders:pending`
2. **后台处理** —— Worker 阻塞于 `BRPOP orders:pending` → 模拟处理 → 更新订单状态为 `completed`
3. **商品目录** —— Order API 查询 Redis 缓存 → 若未命中,则调用 Mock External API → 缓存结果 (TTL 30-60s)
4. **可观测性** —— 每个服务均向 collector 发送 OpenTelemetry 追踪 (导出至 Prometheus),并在 `/metrics` 暴露 Prometheus 指标
5. **告警** —— Prometheus 每 5 秒评估一次告警规则;当 Redis CPU > 80%、p95 延迟 > 1s、错误率 > 5% 或队列深度 > 100 时触发告警
## 技术栈
| 组件 | 技术 | 用途 |
|-----------|-----------|---------|
| **Order API** | Python 3.12 + FastAPI + uvicorn | 核心微服务 (REST endpoint、Redis 缓存、Postgres 持久化) |
| **Mock External API** | Python 3.12 + FastAPI | 模拟第三方依赖,支持配置延迟/错误 |
| **Worker** | Python 3.12 (后台进程) | Redis 队列消费者,订单处理模拟 |
| **数据库** | PostgreSQL 16 (Alpine) | 订单持久化 |
| **缓存 / 队列** | Redis 7 (Alpine) | 商品缓存 (`SETEX`),任务队列 (`BRPOP`/`RPUSH`) |
| **追踪** | OpenTelemetry Collector 0.110.0 | 分布式追踪 (FastAPI、httpx、Redis 自动埋点) |
| **指标** | Prometheus 2.53 | 时间序列指标,告警评估 (5s 抓取) |
| **仪表盘** | Grafana 11.1 | 故障响应仪表盘 (6 个面板) |
| **自定义 Exporter** | Python (redis-exporter) | Redis 队列长度、总键数 gauge |
## 截图
### 演示页面
实时指标、架构状态、故障触发器和事件时间轴 —— 所有数据均由真实的 Prometheus 查询驱动。

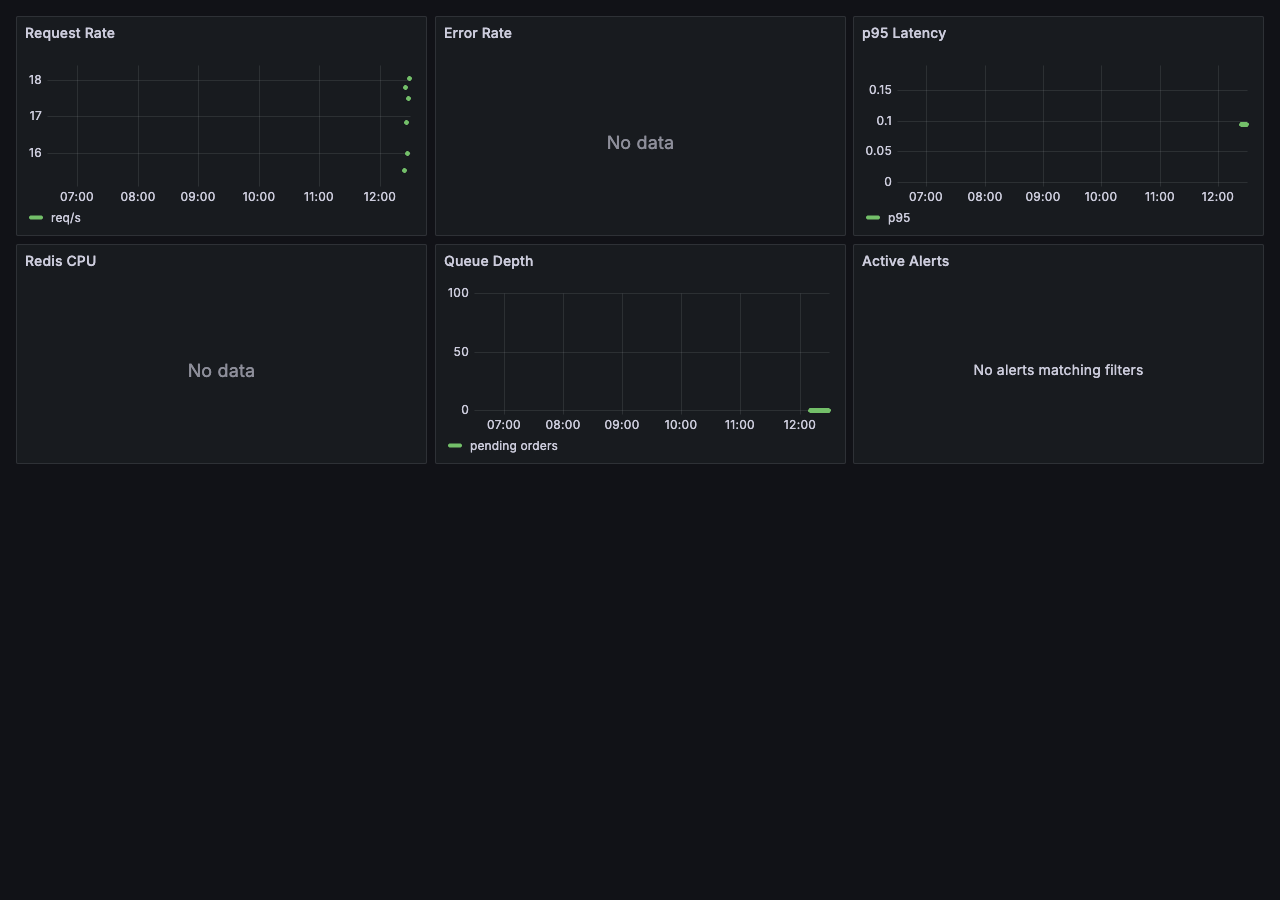
### Grafana 故障响应仪表盘
包含 6 个面板的仪表盘:请求率、错误率、p95 延迟、Redis CPU、队列深度、活跃告警。

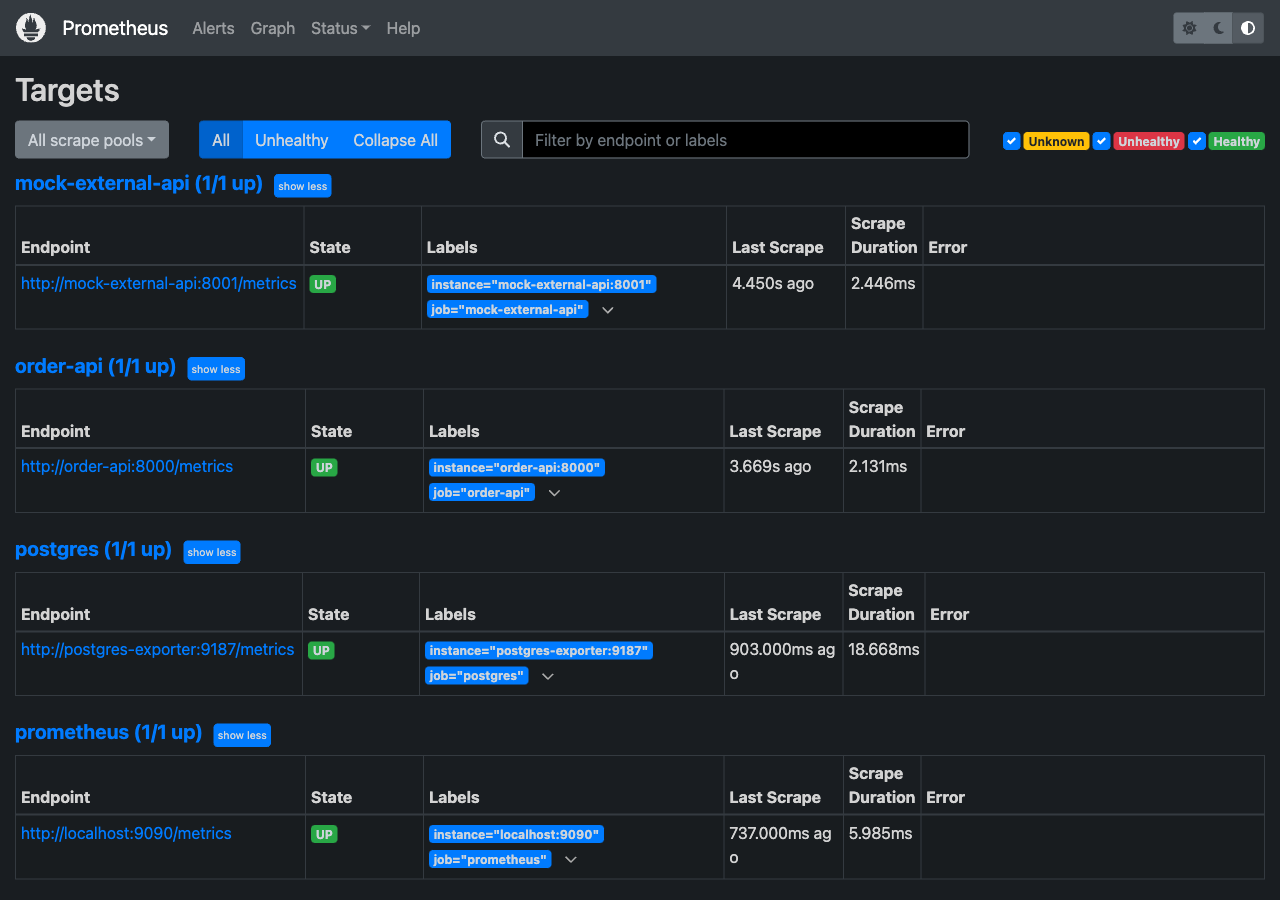
### Prometheus Targets
所有 5 个抓取目标均为 UP 状态 —— order-api、mock-external-api、prometheus、redis-exporter、postgres-exporter。
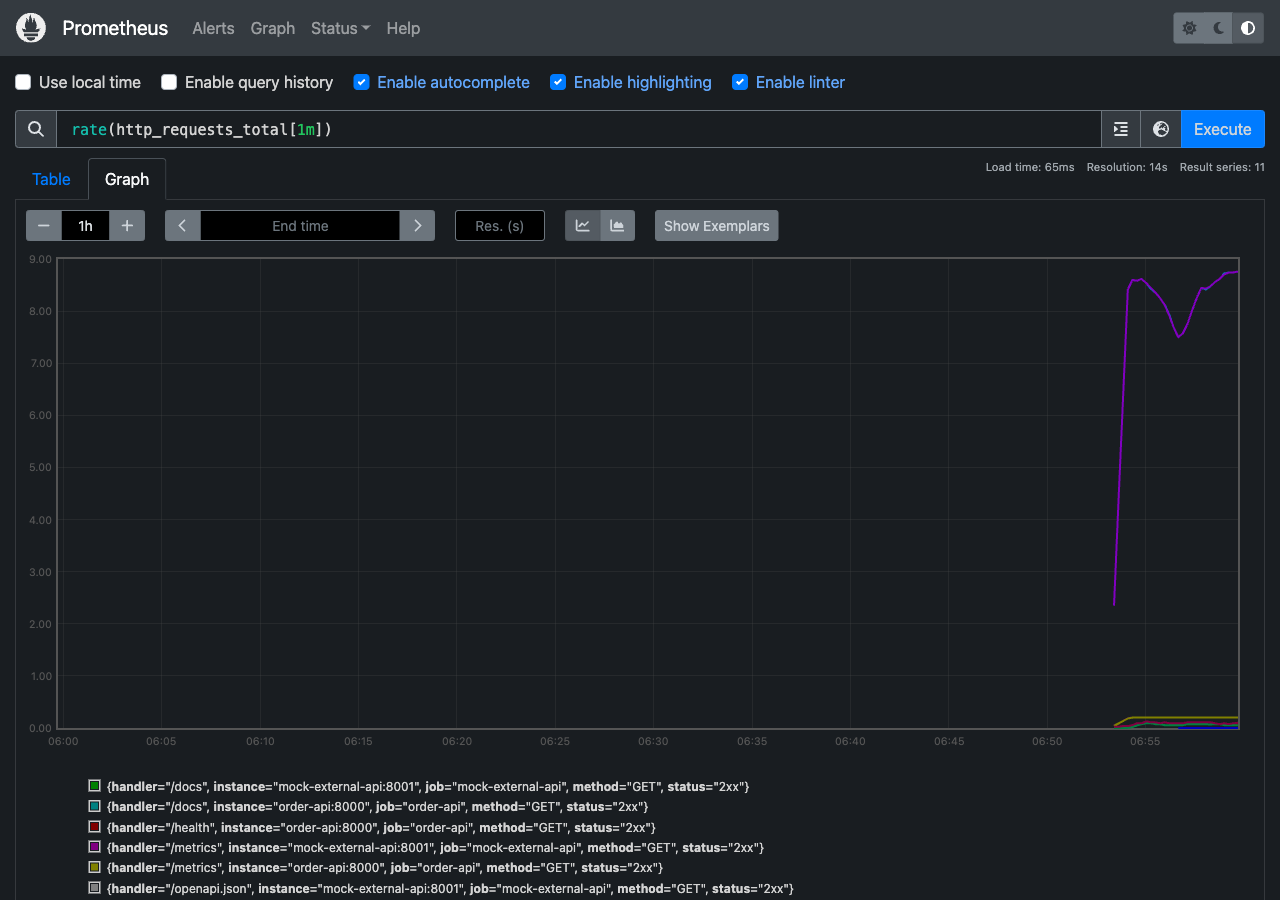
### Prometheus Graph
实时指标可视化 —— `rate(http_requests_total[1m])` 展示请求率。
### Order API 文档
从 FastAPI 自动生成的 Swagger UI —— 可直接试用 endpoint。
### 运行中的服务
所有 11 个服务均在 Docker 中运行:
```
NAMES STATUS PORTS
incident-response-lab-redis-exporter-1 Up 6 minutes 0.0.0.0:9121->9121/tcp
incident-response-lab-mock-external-api-1 Up 6 minutes 0.0.0.0:8001->8001/tcp
incident-response-lab-order-api-1 Up 6 minutes 0.0.0.0:8000->8000/tcp
incident-response-lab-order-worker-1 Up 19 minutes
incident-response-lab-redis-1 Up 19 minutes (healthy) 0.0.0.0:6379->6379/tcp
incident-response-lab-load-generator-1 Up 20 minutes
incident-response-lab-grafana-1 Up 20 minutes 0.0.0.0:3000->3000/tcp
incident-response-lab-postgres-exporter-1 Up 20 minutes 9187/tcp
incident-response-lab-postgres-1 Up 20 minutes (healthy) 0.0.0.0:5432->5432/tcp
incident-response-lab-prometheus-1 Up 20 minutes 0.0.0.0:9090->9090/tcp
incident-response-lab-otel-collector-1 Up 20 minutes 0.0.0.0:4317-4318->4317-4318/tcp
```
## 快速开始
### 前置条件
- Docker & Docker Compose v2
- Python 3.12+ (用于在 Docker 外运行混沌脚本)
- ~4 GB 可用内存
### 快速启动
```
# Clone the repository
git clone https://github.com/iamyadavvikas/incident-response-lab.git
cd incident-response-lab
# Start all services
docker compose up -d --build
# Verify everything is running
docker compose ps
# Open the services:
# - Demo Page: http://localhost:8081
# - Grafana: http://localhost:3000 (admin:admin)
# - Prometheus: http://localhost:9090
# - Order API: http://localhost:8000
# - Order API Docs: http://localhost:8000/docs
# - External API: http://localhost:8001
```
### 启动后的流程
1. PostgreSQL 和 Redis 初始化 (健康检查约 5s 后通过)
2. Order API 和 Mock External API 启动于端口 8000 和 8001
3. 后台 worker 开始轮询 Redis 队列
4. OTEL collector 开始在端口 4317 接收追踪数据
5. Prometheus 开始抓取所有 5 个目标 (5s 间隔)
6. Grafana 配置故障响应仪表盘
7. 负载生成器开始向 Order API 发送稳定的流量 (~20 req/s)
8. 端口 8081 上的演示页面开始从 Prometheus 获取实时指标
## 服务
### Order API (`:8000`)
订单处理平台的核心 REST API。
| Endpoint | Method | 描述 |
|----------|--------|-------------|
| `/health` | GET | 健康检查 |
| `/products` | GET | 商品列表 (Redis 缓存,失败时回退至外部 API) |
| `/products/{id}` | GET | 单个商品 (Redis 缓存,失败时回退至外部 API) |
| `/orders` | POST | 创建订单 (插入 Postgres,推入 Redis 队列) |
| `/orders` | GET | 列出最近的订单 (限制 100 条) |
| `/orders/{id}` | GET | 根据 ID 获取订单 |
| `/metrics` | GET | Prometheus 指标 endpoint |
### Mock External API (`:8001`)
模拟的第三方商品目录服务。
| Endpoint | Method | 描述 |
|----------|--------|-------------|
| `/products` | GET | 返回 5 个商品 (可通过环境变量配置延迟) |
| `/products/{id}` | GET | 单个商品 (未知 ID 返回 404) |
**用于故障注入的环境变量:**
- `EXTERNAL_API_LATENCY_MS` —— 为每个请求添加 `time.sleep()` (默认:`0`)
- `EXTERNAL_API_ERROR_RATE` —— 返回 HTTP 500 的请求比例 (默认:`0.0`)
### Worker (后台)
从 Redis 队列消费订单 (`BRPOP orders:pending`),模拟处理过程,并将 PostgreSQL 中的状态更新为 `completed`。
- `WORKER_PROCESSING_TIME` —— 模拟每个订单处理工作所需的秒数 (默认:`0.1`)
- 如果队列增长速度快于 worker 的处理速度,队列深度将会增加
## 监控与可观测性
### 可用指标
| 指标 | 类型 | 来源 | 描述 |
|--------|------|--------|-------------|
| `http_requests_total` | Counter | 所有服务 | HTTP 请求总数 |
| `http_request_duration_seconds_bucket` | Histogram | 所有服务 | 请求延迟分布 |
| `orders_created_total` | Counter | Order API | 创建的订单总数,按状态划分 |
| `order_processing_seconds` | Histogram | Order API | 订单创建延迟 |
| `order_queue_depth` | Gauge | Order API | 当前 Redis 队列深度 |
| `cache_hits_total` | Counter | Order API | Redis 缓存命中数 |
| `cache_misses_total` | Counter | Order API | Redis 缓存未命中数 |
| `external_api_calls_total` | Counter | Order API | 对外部 API 的调用,按状态划分 |
| `external_api_latency_seconds` | Histogram | Mock External API | 外部 API 延迟 |
| `external_api_errors_total` | Counter | Mock External API | 外部 API 错误计数 |
| `redis_queue_length` | Gauge | Redis Exporter | Redis 队列大小 |
| `redis_total_keys` | Gauge | Redis Exporter | Redis 总键数 |
### Prometheus 告警规则
| 告警 | 表达式 | 严重性 | 描述 |
|-------|-----------|----------|-------------|
| `HighRedisCPULoad` | `rate(redis_cpu_sys_seconds_total[1m]) + rate(redis_cpu_user_seconds_total[1m]) > 0.8` | critical | Redis CPU 饱和 (故障 001) |
| `ExternalAPIHighLatency` | `histogram_quantile(0.95, rate(external_api_latency_seconds_bucket[1m])) > 1` | critical | 外部 API SLO 违规 (故障 002) |
| `HighErrorRate` | `rate(http_requests_total{status=~"5.."}[1m]) / rate(http_requests_total[1m]) > 0.05` | warning | 错误率超过 5% |
| `QueueDepthGrowing` | `redis_queue_length > 100` | warning | 队列积压增长 (故障 003) |
### Grafana 仪表盘
故障响应仪表盘上的 6 个面板 (`http://localhost:3000/d/incident-response`):
1. **请求率** —— `rate(http_requests_total[1m])` —— 每秒请求数
2. **错误率** —— `rate(http_requests_total{status=~"5.."}[1m]) / rate(http_requests_total[1m])` —— 错误百分比
3. **p95 延迟** —— `histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[1m]))` —— 以秒为单位的 P95 延迟
4. **Redis CPU** —— `rate(redis_cpu_sys_seconds_total[1m]) + rate(redis_cpu_user_seconds_total[1m])` —— Redis CPU 核心数
5. **队列深度** —— `redis_queue_length` —— 队列中待处理的订单
6. **活跃告警** —— Prometheus 告警列表
### 分布式追踪 (OpenTelemetry)
每个服务都使用了 OpenTelemetry 进行埋点:
- `FastAPIInstrumentor` —— HTTP 请求追踪
- `HTTPXClientInstrumentor` —— 出站 HTTP 调用追踪
- `RedisInstrumentor` —— Redis 命令追踪
- `create_order`、`list_products`、`get_product` 的自定义 span
OTEL collector 通过 gRPC (`:4317`) 接收 span,并将指标导出到 Prometheus (`:8889`)。
## 故障场景
三个已记录的故障,每个都配有混沌脚本和完整的故障报告。
### 故障 001:Redis CPU 饱和
**严重性:** SEV-2 | **持续时间:** 2小时 15分钟
**触发方式:** `redis-cpu-stress.py` 跨 10 种命令类型 (SET, GET, INCR, LPUSH, LRANGE, HSET, HGETALL, SADD, SMEMBERS, ZADD) 向 Redis 发送每秒 1 万次操作。
**机制:** 缓存击穿 + `KEYS *` 健康检查阻塞了 Redis 事件循环。
**影响:** p99 延迟从 52ms 升至 2.4s,队列深度从 0 升至 5,234,错误率从 0.1% 升至 12.4%。
**解决方案:** 移除 `KEYS *` (替换为 `PING,杀掉空闲的 `MONITOR` 连接,并在缓存未命中路径上添加断路器。
```
# Trigger the incident
python3 chaos/redis-cpu-stress.py --target-rate 10000 --duration 120
```
[完整故障报告](incidents/incident-001.md)
### 故障 002:外部 API 延迟 SLO 违规
**严重性:** SEV-1 (SLO 违规) | **持续时间:** 47分钟
**触发方式:** `latency-injector.sh` 通过环境变量 + SIGHUP 重载,向 Mock External API 注入 2000ms 的延迟。
**机制:** 外部 API 调用没有设置客户端超时;Order API 与上游以 1:1 的比例发生降级。
**影响:** p95 延迟从 120ms 升至 2.1s,SLO 达标率从 99.92% 降至 97.2%,47 分钟内消耗了 34% 的月度错误预算。
**解决方案:** 添加 500ms 的 HTTP 超时,引入断路器模式,并增加过期缓存回退机制。
```
# Trigger the incident
bash chaos/latency-injector.sh 2000 0.0 http://localhost:8001
```
[完整故障报告](incidents/incident-002.md)
### 故障 003:10 倍流量激增
**严重性:** SEV-3 | **持续时间:** 12分钟
**触发方式:** `traffic-surge.py` 每秒向 Order API POST 1,100 个订单。
**机制:** 单个 worker 每秒处理 10 个订单,却接收到每秒 1,100 个订单;队列以每秒 1,090 个订单的速度增长。
**影响:** 队列深度从 0 升至 8,512,出现瞬时的 7.2% HTTP 500 错误率,端到端延迟从 150ms 升至 14m。
**解决方案:** (模拟) 自动扩容至 4 个 worker,后续通过批处理进行优化。
```
# Trigger the incident
python3 chaos/traffic-surge.py --target-rate 1100 --duration 120
```
[完整故障报告](incidents/incident-003.md)
## 事后总结
一份综合事后总结在单一时间轴上分析了所有三起故障:
| 指标 | 目标 | 实际 | 评估 |
|--------|--------|--------|------------|
| 服务正常运行时间 | 99.99% | 100% | 通过 |
| SLO (p95 < 1s) | 99.9% | 97.2% | 失败 |
| 错误预算 | 100% | 消耗了 66% | 警告 |
| MTTR | < 30分钟 | 平均 30分钟 | 勉强及格 |
| MTTD | < 5分钟 | 平均 2分钟 | 通过 |
**发现的系统性问题:**
1. 外部调用缺少客户端超时设置
2. 没有断路器模式
3. 单个 worker 成为瓶颈
4. 缺少慢查询监控 (Redis SLOWLOG)
5. 缓存未命中路径上没有限流
**30天行动计划:** P0 项 (HTTP 超时、替换为 SCAN、HPA 指标) 已完成;P1 项 (断路器、过期缓存回退、慢查询告警) 正在进行中;P2 项 (请求对冲、Redis Cluster、Runbook、负载测试) 已计划安排。
[完整事后总结](incidents/postmortem.md)
## 混沌工程工具包
| 脚本 | 语言 | 用途 | 目标 |
|--------|----------|---------|---------|
| `chaos/redis-cpu-stress.py` | Python | 通过多线程操作使 Redis CPU 饱和 | Redis (:6379) |
| `chaos/latency-injector.sh` | Bash | 通过 `docker exec` 向 Mock External API 注入延迟/错误 | Mock External API (:8001) |
| `chaos/traffic-surge.py` | Python | 通过大量订单 POST 请求淹没 Order API | Order API (:8000) |
| `chaos/redis-exporter.py` | Python | 自定义 Prometheus exporter (队列长度、总键数) | Redis (:6379) → Prometheus |
## 项目结构
```
incident-response-lab/
├── docker-compose.yml # 11-service orchestration
├── services/
│ ├── api/ # Order API (FastAPI)
│ │ ├── main.py # Endpoints, Redis cache, Postgres, OTEL, Prometheus metrics
│ │ ├── Dockerfile
│ │ └── requirements.txt
│ ├── mock-external-api/ # Simulated 3rd-party API
│ │ ├── main.py # 5 products, configurable latency/error injection
│ │ ├── Dockerfile
│ │ └── requirements.txt
│ └── worker/ # Background order processor
│ ├── main.py # Redis BRPOP consumer, Postgres status updates
│ ├── Dockerfile
│ └── requirements.txt
├── config/
│ ├── prometheus/
│ │ ├── prometheus.yml # Scrape config (5 targets, 5s interval)
│ │ └── alerts.yml # 4 alert rules
│ ├── grafana/
│ │ ├── datasources.yaml # Prometheus datasource
│ │ └── dashboards/
│ │ ├── dashboards.yaml # Dashboard provisioning
│ │ └── incident-response.json # 6-panel dashboard
│ └── otel-collector/
│ └── otel-config.yml # OTLP receiver, Prometheus exporter
├── chaos/
│ ├── redis-cpu-stress.py # Incident 001: Redis CPU saturation
│ ├── latency-injector.sh # Incident 002: Latency injection
│ ├── traffic-surge.py # Incident 003: Traffic surge
│ ├── redis-exporter.py # Custom Prometheus exporter
│ └── Dockerfile
├── incidents/
│ ├── incident-001.md # Redis CPU Saturation (SEV-2)
│ ├── incident-002.md # External API Latency (SEV-1)
│ ├── incident-003.md # Traffic Surge (SEV-3)
│ └── postmortem.md # Cross-incident RCA + 30-day action plan
├── demo/
│ └── index.html # Interactive demo page with live metrics
└── screenshots/ # Visual documentation
```
## 演示页面
位于 **http://localhost:8081** 的交互式演示页面提供:
- **实时架构图** —— 服务健康状态 (绿色/黄色/红色徽章),自动刷新
- **实时指标** —— 请求率、错误率、队列深度、缓存命中率、Redis 键数/内存、外部 API 延迟、SLO 达标率环
- **迷你火花线图表** —— 每个指标的 40 个数据点滚动历史记录
- **故障模拟器** —— 点击即可触发所有 3 种类型的故障,并在 90 秒后自动恢复,同时跟踪 MTTR 并显示进度条
- **事件时间轴** —— 带有类型标签 (info、warning、error、ok、action) 的所有操作颜色编码日志
- **快捷链接** —— 一键访问 Grafana、Prometheus、Order API Swagger、External API Swagger
## 面试沟通要点
### SRE 岗位
- **故障响应方法论:** 正式的严重性分类、时间轴重建、无指责事后总结、错误预算分析
- **监控理念:** 四大黄金信号 (延迟、流量、错误、饱和度)、基于 SLO 的告警、消耗率感知
- **混沌工程:** 在受控环境中进行安全的故障注入、基于可观测性的调试
- **弹性模式:** 断路器、过期缓存回退、基于队列的负载平滑、限流
### 平台工程岗位
- **可观测性技术栈:** 从零开始构建 Prometheus + Grafana + OpenTelemetry 集成
- **自定义埋点:** Prometheus histogram/counter/gauge 模式、FastAPI instrumentator、Redis 自动埋点
- **多语言埋点:** Python (FastAPI、worker)、支持 Go 的 collector (OTEL)
- **基础设施即代码:** 使用 Docker Compose 搭建完整技术栈、Grafana 配置、基于文件的 Prometheus 服务发现
### 后端工程岗位
- **架构模式:** 基于队列的异步处理、Cache-aside 模式、外部服务抽象
- **故障模式:** 缓存击穿、上游降级传播、worker 池耗尽
- **性能优化:** 连接池、查询优化、批处理、连接管理
- **追踪:** 分布式上下文传播、span 属性、trace 到 metrics 的关联
## License
MIT
标签:API集成, Docker, SRE, 偏差过滤, 可观测性, 安全防御评估, 应急响应演练, 搜索引擎查询, 测试用例, 混沌工程, 版权保护, 用户代理, 自定义请求头, 请求拦截, 逆向工具