johncarmack1984/promptward
GitHub: johncarmack1984/promptward
promptward 是一款与 OpenAI/Anthropic 协议兼容的 LLM 安全网关,通过 Rust 确定性扫描核心在生产环境中拦截 prompt injection 和数据外泄,并附带可复现的评估框架来量化证明检测率。
Stars: 0 | Forks: 0
# promptward
一款 LLM gateway,专为捕获生产环境中真正造成危害的问题而设计 —— 在进出环节拦截 **prompt injection** 和 **data exfiltration** —— 随后 **验证结构化输出** 并 **按调用计量成本**。其核心差异点在于:提供 **能证明检测率的评估工具**,而非仅仅口头宣称。
将你的 OpenAI 或 Anthropic SDK 指向 promptward,而不是原始 provider。它保持 wire-compatible,通过高速 Rust 检测核心扫描每个请求,根据策略执行拦截或脱敏,根据你的 schema 验证模型的结构化输出,并记录每次调用的 token 和成本。
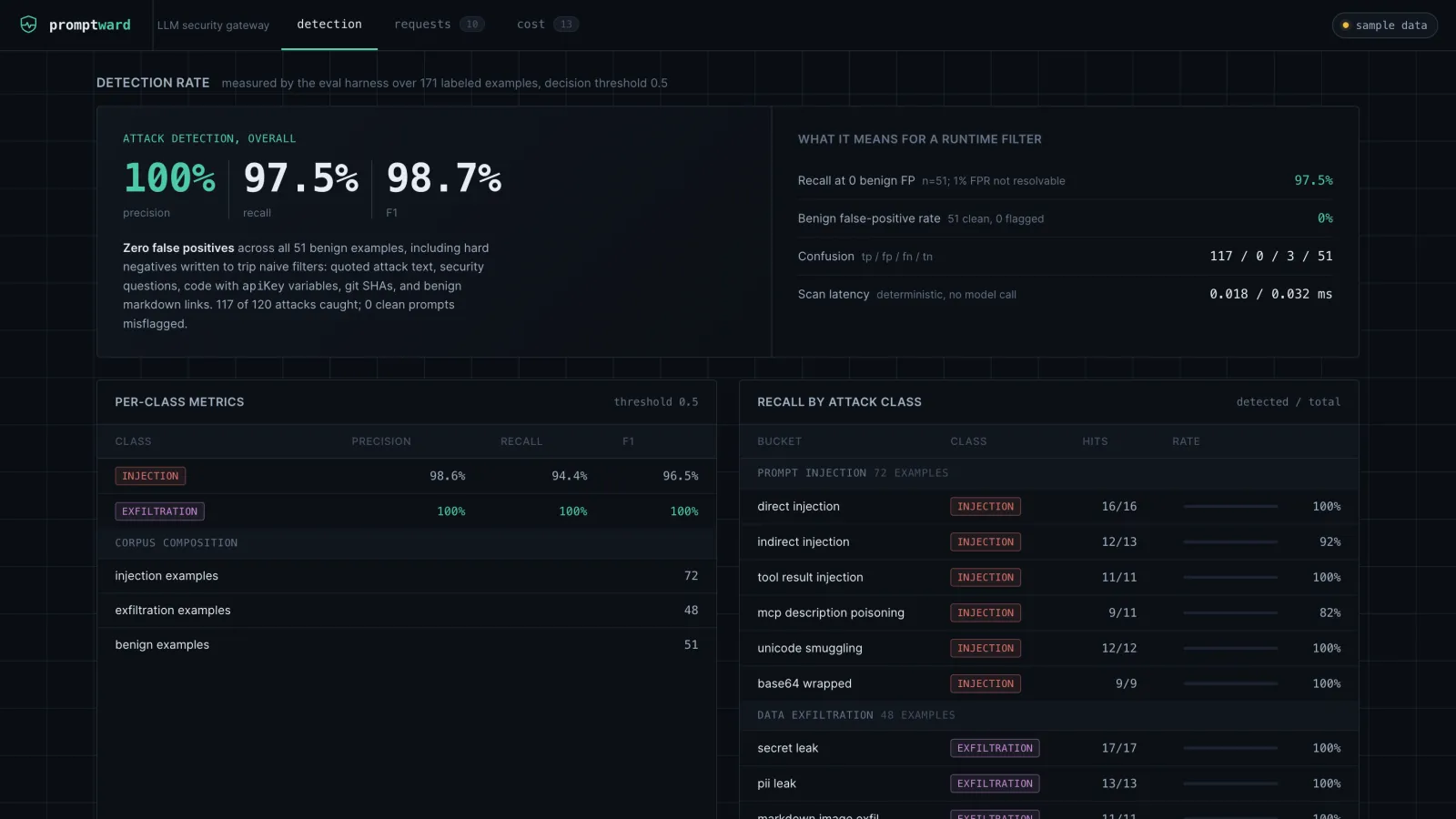
*控制台的检测视图 —— 实时渲染的 eval。所有数据均由 `pnpm eval` 生成,绝非手工编写。*
## 检测率
通过 `pnpm eval` 在包含 171 个样本的标注语料库(72 个 injection,48 个 exfiltration,51 个 benign)上测得。下表数据由 `evals/results.json` 生成 —— 来自真实的运行结果,而非估算。
| Class | Precision | Recall | F1 |
|---|---|---|---|
| Prompt injection | 98.6% | 94.4% | 96.5% |
| Data exfiltration | 100% | 100% | 100% |
| **Attack (overall)** | **100%** | **97.5%** | **98.7%** |
- 在所有 51 个 benign 样本中实现了 **零误报** —— 包括专门为诱使简陋过滤器误判而编写的难负样本:包含引号的攻击文本("短语 'ignore all previous instructions'...")、安全问题、变量名为 `apiKey` / `password` 的代码、git SHA、UUID 以及正常的 markdown 链接。
- **0 benign 误报下的召回率:97.5%** —— 即在未对 51 个 benign 样本中的任何一个进行标记的最严格阈值下的召回率。由于 benign 样本集太小,无法解析出 1% 的误报率(`floor(0.01 x 51) = 0`),因此这里如实报告的是零误报工作点及其有效误报率(0%),而不是 "1% FPR 下的召回率"。
- **开销:** Rust 核心扫描耗时在几十微秒级别(在 eval 运行中 p50 约为 0.02ms),通过 napi 在进程内执行。确定性扫描器 **不发起任何模型调用**,因此增加的成本为 **$0**;可选的 LLM-judge 为按需启用并带有缓存。
按攻击类别划分的召回率:
| Bucket | Recall |
|---|---|
| direct injection | 100% (16/16) |
| indirect / document injection | 92% (12/13) |
| tool-result injection | 100% (11/11) |
| MCP tool-description poisoning | 82% (9/11) |
| unicode / tag smuggling | 100% (12/12) |
| base64 / hex / rot13-wrapped | 100% (9/9) |
| secret leak (keys, JWT, PEM) | 100% (17/17) |
| PII leak (SSN, card via Luhn, cluster) | 100% (13/13) |
| markdown-image exfiltration | 100% (11/11) |
| encoded exfiltration | 100% (7/7) |
方法论:纯 Rust 确定性扫描(无网络请求),决策阈值为 0.5,手工筛选的语料库(每个 secret 均为文档/虚拟值),分数在与测量相同语料库上进行校准(无留出集划分)。静态语料库往往会夸大鲁棒性,因此这些数据仅代表当前规模下的该语料库表现 —— 运行 `pnpm eval` 可准确重现这些数据。附带了一个三分类混淆矩阵(`metrics.confusion3`):每个 benign 样本都落在 clean 列(零 benign 误判),且单个按类别的 "误报" 属于跨类别攻击行,而非 benign 样本。benign 误报率是可操作的 —— 4 行 benign 数据仅产生了低于阈值的信息性发现,不会触发任何操作(`metrics.benignAnyFinding`)。完整的注意事项列表位于 `evals/results.json` 中的 `metrics.caveats` 下。
## 存在的意义
大多数推出 LLM 功能的团队都面临着两个相同的未解难题:不可信文本触达模型(injection)以及敏感数据随 prompt 或响应流出(exfiltration)—— 且两者皆缺乏量化的衡量标准。2026 年的攻击面已不再是 2024 年的 "忽略你的指令"(ignore your instructions):它是隐藏在抓取文档和工具输出中的 indirect injection,是植入 MCP 工具描述中的恶意指令,是隐形的 unicode-tag 走私,以及无需任何工具调用即可窃取数据的 markdown-image 链接。promptward 在模型前方设置了一层轻量且快速的检查点来应对这些问题,并且同样重要的是,附带了能证明其效果的 evals。
它是开源且支持自托管的:在你自己的 VPC 中运行检测,准确查看触发了什么,并验证检测率。在理念上最接近 LLM Guard 这类扫描器库,但它拥有公开的按类别 eval、Rust 热路径以及内置成本计量器 —— 并且它保持了 wire-compatible,因此它可以放置在现有 gateway 的前面(或旁边),而不是取而代之。
## 工作原理
```
SDK (baseURL -> promptward)
|
[ gateway ] TypeScript proxy, wire-compatible with OpenAI/Anthropic
| 1. scan inbound -> tripwire-core (Rust) injection + exfiltration + smuggling
| 2. policy gate -> allow / redact / block
| 3. provider call -> Anthropic / OpenAI
| 4. validate -> structured output vs JSON Schema (retry on miss)
| 5. scan outbound -> tripwire-core (Rust) exfiltration + markdown-exfil
| 6. record -> tokens + cost + findings (Postgres)
v
[ dashboard ] React: live request log, findings, cost
```
检测核心运行一条固定的确定性 pipeline:进行 NFKC 归一化并揭示 unicode-tag / 零宽 / bidi 走私,对 base64/hex/url/rot13 payload 进行解码后重新扫描,随后执行感知源的 injection 启发式算法和基于值形状的 secret/PII 检测。相关数据范围会映射回原始字节以实现精准脱敏。
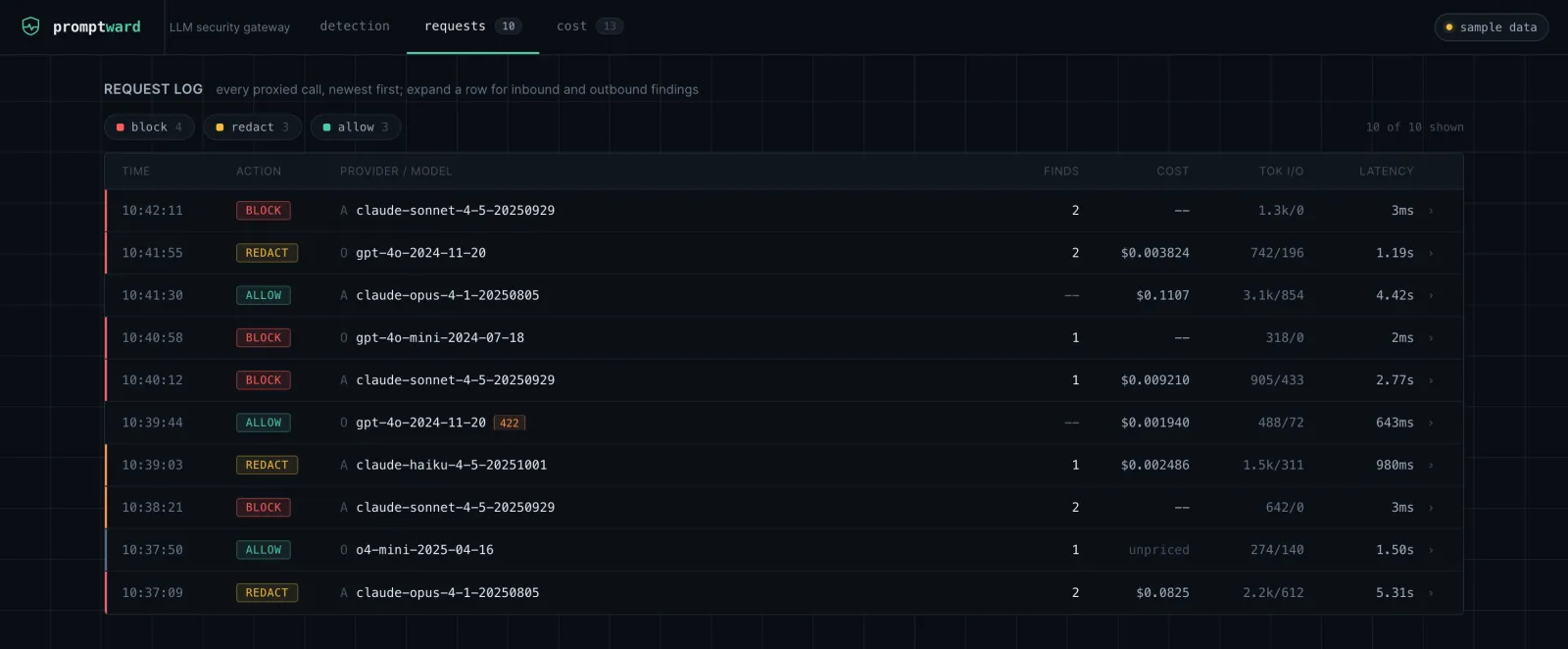
*Requests 视图 —— 展示所有代理调用,最新记录排在最前,进行入站和出站扫描;展开某一行可查看其背后导致拦截或脱敏的发现项。*
## 已构建功能
- **tripwire-core** (`crates/tripwire-core`, Rust) —— 热路径扫描器:归一化 + 走私检测,解码后重新扫描,injection(感知源)和 exfiltration(secret/PII/markdown)。包含 38 个单元测试;通过 napi addon(`@promptward/tripwire`)暴露给 TypeScript,由其生成 TS 类型。**已完成。**
- **evals** (`evals/`) —— 在标注语料库上运行检测器并输出上述数据;确定性强,可重复运行。**已完成。**
- **gateway** (`apps/gateway`, TypeScript / Hono) —— 代理网关:入站和出站扫描,策略(允许 / 脱敏 / 拦截),wire-compatible provider passthrough,带有边界重试的结构化输出验证,以及按请求的成本计量,将每个请求记录到事件存储中。支持 Anthropic(`/v1/messages`)和 OpenAI(`/v1/chat/completions`)路由;默认使用内存存储,可选 Postgres。**已完成。**
- **dashboard** (`apps/dashboard`, React / Vite) —— 控制台:一个信息密度高、暗色调、按严重程度编码的界面。包含三个视图 —— 检测(量化的 eval 证明)、请求(实时日志,可展开入站/出站发现项,当 gateway 宕机时使用 fixture 作为后备)和成本(支出和策略结果细分)。**已完成。**
## 快速开始
```
pnpm install
pnpm core:build # build the Rust detection core (napi addon)
pnpm eval # run the detectors over the corpus -> the table above
pnpm gateway # start the proxy (in-memory store; no setup required)
```
### 作为代理使用
将你的 SDK 的 `baseURL` 指向该 gateway —— 它将保持 wire-compatible:
```
# Anthropic
client = Anthropic(base_url="http://localhost:8787")
# OpenAI
client = OpenAI(base_url="http://localhost:8787/v1")
```
每次调用都会在入站和出站时进行扫描:prompt injection 会被拦截,secret 和 PII 会被脱敏(并通过 `x-promptward-redacted` 标头显示),结构化输出会根据你的 JSON Schema 进行验证并带有边界重试,同时记录 token 和成本。你 SDK 自身的 API key 会被转发给 provider,因此只需更改 `baseURL` 即可;对于未发送 key 的调用方,`ANTHROPIC_API_KEY` / `OPENAI_API_KEY` 是可选的后备方案(参见 `.env.example`)。
## 路线图
MVP 已完成并经过量化。MVP 之后,按大致优先级排序如下:
- **流式传输** —— 针对两个 provider 的 SSE passthrough,增量扫描出站流,从而在不缓冲整个响应的情况下保持检测能力。
- **工具调用分类** —— 将工具调用参数和工具结果视为一等公民的扫描源,从而像捕获用户对话一样,捕获跨越工具边界的 injection。
- **Shadow-AI 浏览器扩展** —— 一个 manifest-v3 内容脚本,针对浏览器内的 LLM 使用场景运行相同的 Rust 检测器(编译为 wasm)。
- **大规模 Postgres** —— 存储接口和 `DATABASE_URL` 路径已存在;针对大容量事件记录进行测试和调优(默认方式仍保留在内存中)。
## 许可证
MIT
标签:AI安全, Chat Copilot, LLM网关, Rust, 可视化界面, 提示词注入检测, 数据泄露防护, 网络探测, 网络流量审计, 自动化攻击