QwenLM/Qwen-AgentWorld
GitHub: QwenLM/Qwen-AgentWorld
Qwen-AgentWorld 是一个覆盖七个智能体交互领域的原生语言世界模型,通过长思维链推理模拟智能体环境状态,并附带 AgentWorldBench 评估基准。
Stars: 217 | Forks: 15
# Qwen-AgentWorld
 欢迎使用 Qwen-AgentWorld 的 GitHub 仓库。在这里,您可以找到关于 Qwen-AgentWorld 的官方信息,提出您的问题([Issues](https://github.com/QwenLM/Qwen-AgentWorld/issues)),并与社区分享您的想法([Discussions](https://github.com/QwenLM/Qwen-AgentWorld/discussions))。
## 新闻
- **2026-06-24**:我们发布了 **Qwen-AgentWorld-35B-A3B** 和 **AgentWorldBench**。请在我们的[博客](https://qwen.ai/blog?id=qwen-agentworld)和[技术报告](http://arxiv.org/abs/2606.24597)中阅读更多内容。
## 开源发布
我们将 Qwen-AgentWorld-35B-A3B(模型权重)和 AgentWorldBench(评估基准)进行了开源:
| 发布内容 | 描述 |
|---------|-------------|
| [Qwen-AgentWorld-35B-A3B](https://huggingface.co/Qwen/Qwen-AgentWorld-35B-A3B) | 语言世界模型(MoE,总参数量 35B / 激活参数量 3B,256K 上下文) |
| [AgentWorldBench](https://huggingface.co/datasets/Qwen/AgentWorldBench) | 涵盖 7 个领域的评估基准 |
官方权重和数据发布在以下平台:
- [🤗 HuggingFace](https://huggingface.co/Qwen):通过模型 ID 自动下载,例如 `Qwen/Qwen-AgentWorld-35B-A3B`。您也可以使用 `huggingface download` 或 `git clone` 手动下载模型文件。请遵循模型页面上的说明。
- [🤖 ModelScope](https://modelscope.cn/organization/qwen):适用于无法访问 Hugging Face Hub 的用户。对于支持的框架,您可以通过设置环境变量从 ModelScope 下载,例如 `SGLANG_USE_MODELSCOPE=true` 或 `VLLM_USE_MODELSCOPE=true`。
## 简介
欢迎使用 Qwen-AgentWorld 的 GitHub 仓库。在这里,您可以找到关于 Qwen-AgentWorld 的官方信息,提出您的问题([Issues](https://github.com/QwenLM/Qwen-AgentWorld/issues)),并与社区分享您的想法([Discussions](https://github.com/QwenLM/Qwen-AgentWorld/discussions))。
## 新闻
- **2026-06-24**:我们发布了 **Qwen-AgentWorld-35B-A3B** 和 **AgentWorldBench**。请在我们的[博客](https://qwen.ai/blog?id=qwen-agentworld)和[技术报告](http://arxiv.org/abs/2606.24597)中阅读更多内容。
## 开源发布
我们将 Qwen-AgentWorld-35B-A3B(模型权重)和 AgentWorldBench(评估基准)进行了开源:
| 发布内容 | 描述 |
|---------|-------------|
| [Qwen-AgentWorld-35B-A3B](https://huggingface.co/Qwen/Qwen-AgentWorld-35B-A3B) | 语言世界模型(MoE,总参数量 35B / 激活参数量 3B,256K 上下文) |
| [AgentWorldBench](https://huggingface.co/datasets/Qwen/AgentWorldBench) | 涵盖 7 个领域的评估基准 |
官方权重和数据发布在以下平台:
- [🤗 HuggingFace](https://huggingface.co/Qwen):通过模型 ID 自动下载,例如 `Qwen/Qwen-AgentWorld-35B-A3B`。您也可以使用 `huggingface download` 或 `git clone` 手动下载模型文件。请遵循模型页面上的说明。
- [🤖 ModelScope](https://modelscope.cn/organization/qwen):适用于无法访问 Hugging Face Hub 的用户。对于支持的框架,您可以通过设置环境变量从 ModelScope 下载,例如 `SGLANG_USE_MODELSCOPE=true` 或 `VLLM_USE_MODELSCOPE=true`。
## 简介
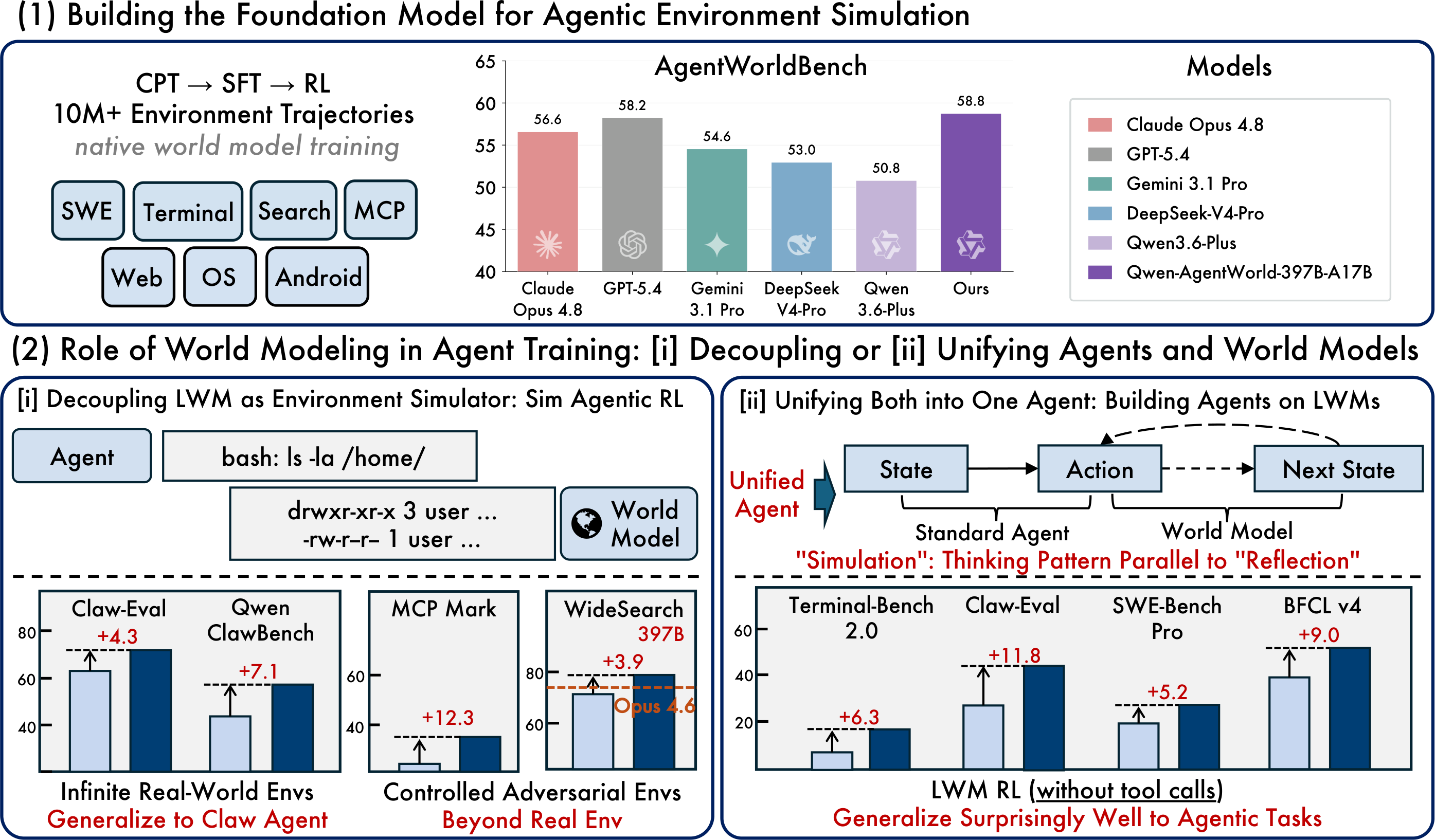
**Qwen-AgentWorld** 是一个原生语言世界模型,它通过在**七个统一领域**(MCP、Search、Terminal、SWE、Android、Web 和 OS)中进行长思维链推理来模拟智能体环境。它通过三阶段的 pipeline 进行训练——CPT 注入环境知识,SFT 激活下一状态预测推理,RL 增强模拟保真度——训练数据包含超过 1000 万条真实世界的交互轨迹。与以往将世界建模视为事后附加方法的做法不同,Qwen-AgentWorld 是一个**原生世界模型**:从 CPT 阶段开始,环境建模就是其训练目标。 主要特征: - **七个统一领域。** 第一个在单个模型中涵盖七个智能体交互领域的语言世界模型。 - **原生世界模型。** 从 CPT 阶段开始进行环境建模,而非事后适应。 - **可泛化、可扩展且可控的模拟器。** 对 OOD 环境实现零样本泛化(例如 Claw Agent);可控扰动和虚构世界构建超越了真实环境训练。 - **智能体基础模型。** 在单轮、非智能体轨迹上进行 LWM RL 预热,可迁移到跨七个基准测试的多轮、工具调用智能体任务中,其中包括三个完全超出领域的任务。 ## 性能表现
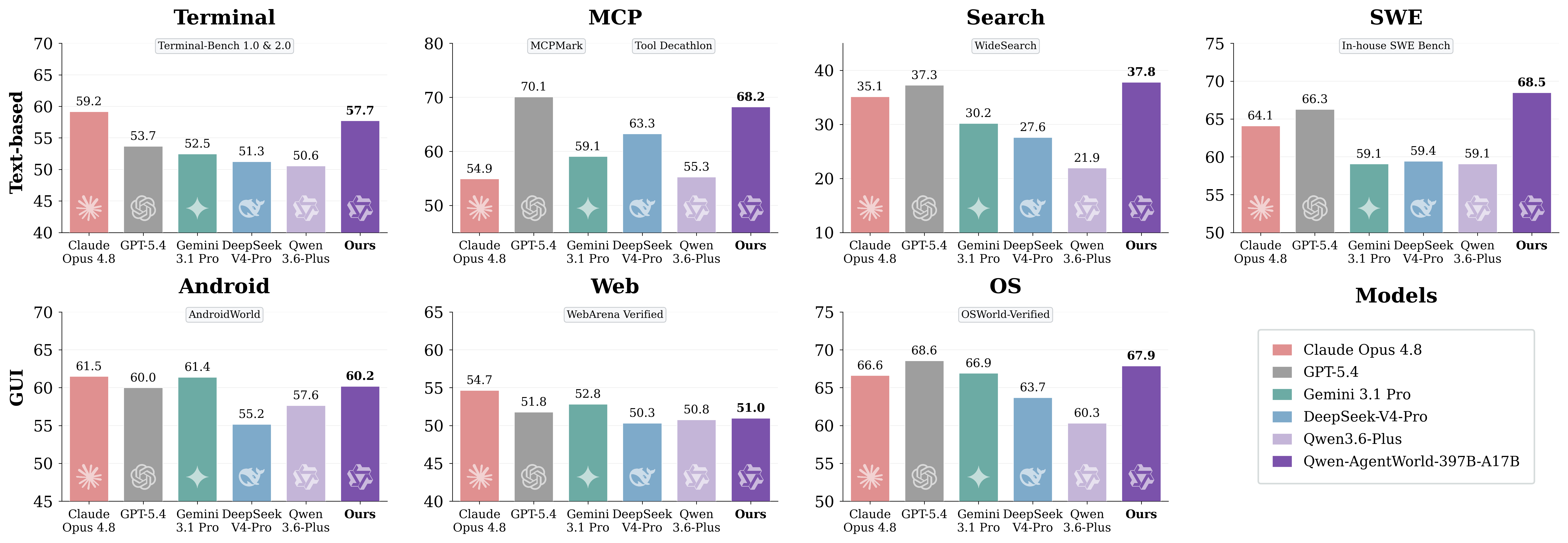 每个领域的五维度评分标准均值(↑),归一化到 0--100 分制。
| 模型 | MCP | Search | Term. | SWE | Android | Web | OS | **总体** |
|:------|:---:|:------:|:-----:|:---:|:-------:|:---:|:--:|:-----------:|
| GPT-5.4 | **70.10** | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
| Claude Opus 4.8 | 54.93 | 35.14 | **59.18** | 64.10 | 61.50 | **54.66** | 66.62 | 56.59 |
| Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | **61.74** | 51.42 | **70.20** | 57.80 |
| Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
| Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
| DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
| GLM-5.1 | 67.60 | 22.46 | 47.32 | 52.07 | 59.10 | 51.50 | 59.13 | 51.31 |
| Kimi K2.6 | 65.23 | 27.48 | 52.54 | 58.77 | 58.93 | 50.20 | 60.80 | 53.42 |
| MiniMax-M2.7 | 55.82 | 27.30 | 41.62 | 37.44 | 52.40 | 50.52 | 57.73 | 46.12 |
| Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
| Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 60.85 | 54.74 |
| Qwen3.6-Plus | 55.28 | 21.94 | 50.58 | 59.08 | 57.65 | 50.78 | 60.33 | 50.81 |
| **Qwen-AgentWorld-35B-A3B** | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
| **Qwen-AgentWorld-397B-A17B** | 68.24 | **37.82** | 57.73 | **68.49** | 60.20 | 50.98 | 67.89 | **58.71** |
Qwen-AgentWorld-397B-A17B 取得了最高的总体得分(58.71),超越了包括 GPT-5.4(58.25)在内的所有前沿专有模型。与没有进行 LWM 训练的 Qwen3.5-35B-A3B 相比,Qwen-AgentWorld-35B-A3B 展现出了 +8.66 的提升。
## 应用
**可泛化的环境扩展。** 在 4k 个分布外的 OpenClaw 环境上,使用 Qwen-AgentWorld-397B-A17B 进行 Sim RL:
| 模型 | Claw-Eval | QwenClawBench |
|:------|:---------:|:-------------:|
| Qwen3.5-35B-A3B | 65.4 | 47.9 |
| + Sim RL(使用 Qwen3.6-Plus) | 66.7 | 47.8 |
| + Sim RL(使用 Qwen-AgentWorld-397B-A17B) | **69.7** | **55.0** |
| Δ | +4.3 | +7.1 |
**可控模拟:MCP。** 环境适应 —— 控制指令注入有针对性的扰动,以暴露智能体的弱点:
| 模型 | Tool Decathlon | MCPMark |
|:------|:--------------:|:-------:|
| Qwen3.5-35B-A3B-SFT | 32.4 | 21.5 |
| + Sim RL(不受控) | 31.5 | 24.6 |
| + Sim RL(受控) | **36.1** | **33.8** |
| Δ | +3.7 | +12.3 |
**可控模拟:Search。** 虚构世界构建 —— 在完全虚构、自洽的世界中训练的智能体,能够泛化到真实的搜索任务:
| 模型 | WideSearch F1 Item | WideSearch F1 Row |
|:------|:------------------:|:-----------------:|
| Qwen3.5-35B-A3B-SFT | 34.02 | 13.72 |
| + Sim RL(受控) | **50.31** | **24.21** |
| Δ | +16.29 | +10.49 |
| | | |
| Qwen3.5-397B-A17B-SFT | 70.11 | 45.69 |
| + Sim RL(受控) | **73.98** | **51.74** |
| Δ | +3.87 | +6.05 |
**智能体基础模型。** 在单轮、非智能体轨迹上进行 LWM RL 预热,可迁移到多轮、工具调用的智能体任务中:
| | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 Item | Claw-Eval | QwenClawBench | BFCL v4 |
|:---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| | *领域内* | | | | *领域外* | | |
| Qwen3.5-35B-A3B-SFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 39.76 | 62.29 |
| 使用 LWM RL | **39.55** | **67.86** | **47.42** | **46.17** | **64.88** | **49.43** | **71.25** |
| Δ | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +9.67 | +8.96 |
有关详细结果,请查看[博客](https://qwen.ai/blog?id=qwen-agentworld)和[技术报告](http://arxiv.org/abs/2606.24597)。
## 快速开始
### 部署
Qwen-AgentWorld-35B-A3B 受多个推理框架支持。在此我们演示 SGLang 和 vLLM 的使用方法。
#### SGLang
[SGLang](https://github.com/sgl-project/sglang) 是一个用于大型语言模型的快速推理服务框架。
```
python -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--context-length 262144 \
--reasoning-parser qwen3
```
OpenAI 兼容的 API 将在 `http://localhost:8000/v1` 上可用。
#### vLLM
[vLLM](https://github.com/vllm-project/vllm) 是一个用于 LLM 的高吞吐量和内存高效的推理引擎。
```
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-code
```
OpenAI 兼容的 API 将在 `http://localhost:8000/v1` 上可用。
### 使用 Transformers 进行推理
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
```
## 在 AgentWorldBench 上进行评估
AgentWorldBench 通过在五个维度:**格式 (Format)**、**事实性 (Factuality)**、**一致性 (Consistency)**、**真实性 (Realism)** 和 **质量 (Quality)** 上对每个预测的环境观察结果进行评分,来评估语言世界模型。
每个领域的五维度评分标准均值(↑),归一化到 0--100 分制。
| 模型 | MCP | Search | Term. | SWE | Android | Web | OS | **总体** |
|:------|:---:|:------:|:-----:|:---:|:-------:|:---:|:--:|:-----------:|
| GPT-5.4 | **70.10** | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
| Claude Opus 4.8 | 54.93 | 35.14 | **59.18** | 64.10 | 61.50 | **54.66** | 66.62 | 56.59 |
| Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | **61.74** | 51.42 | **70.20** | 57.80 |
| Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
| Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
| DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
| GLM-5.1 | 67.60 | 22.46 | 47.32 | 52.07 | 59.10 | 51.50 | 59.13 | 51.31 |
| Kimi K2.6 | 65.23 | 27.48 | 52.54 | 58.77 | 58.93 | 50.20 | 60.80 | 53.42 |
| MiniMax-M2.7 | 55.82 | 27.30 | 41.62 | 37.44 | 52.40 | 50.52 | 57.73 | 46.12 |
| Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
| Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 60.85 | 54.74 |
| Qwen3.6-Plus | 55.28 | 21.94 | 50.58 | 59.08 | 57.65 | 50.78 | 60.33 | 50.81 |
| **Qwen-AgentWorld-35B-A3B** | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
| **Qwen-AgentWorld-397B-A17B** | 68.24 | **37.82** | 57.73 | **68.49** | 60.20 | 50.98 | 67.89 | **58.71** |
Qwen-AgentWorld-397B-A17B 取得了最高的总体得分(58.71),超越了包括 GPT-5.4(58.25)在内的所有前沿专有模型。与没有进行 LWM 训练的 Qwen3.5-35B-A3B 相比,Qwen-AgentWorld-35B-A3B 展现出了 +8.66 的提升。
## 应用
**可泛化的环境扩展。** 在 4k 个分布外的 OpenClaw 环境上,使用 Qwen-AgentWorld-397B-A17B 进行 Sim RL:
| 模型 | Claw-Eval | QwenClawBench |
|:------|:---------:|:-------------:|
| Qwen3.5-35B-A3B | 65.4 | 47.9 |
| + Sim RL(使用 Qwen3.6-Plus) | 66.7 | 47.8 |
| + Sim RL(使用 Qwen-AgentWorld-397B-A17B) | **69.7** | **55.0** |
| Δ | +4.3 | +7.1 |
**可控模拟:MCP。** 环境适应 —— 控制指令注入有针对性的扰动,以暴露智能体的弱点:
| 模型 | Tool Decathlon | MCPMark |
|:------|:--------------:|:-------:|
| Qwen3.5-35B-A3B-SFT | 32.4 | 21.5 |
| + Sim RL(不受控) | 31.5 | 24.6 |
| + Sim RL(受控) | **36.1** | **33.8** |
| Δ | +3.7 | +12.3 |
**可控模拟:Search。** 虚构世界构建 —— 在完全虚构、自洽的世界中训练的智能体,能够泛化到真实的搜索任务:
| 模型 | WideSearch F1 Item | WideSearch F1 Row |
|:------|:------------------:|:-----------------:|
| Qwen3.5-35B-A3B-SFT | 34.02 | 13.72 |
| + Sim RL(受控) | **50.31** | **24.21** |
| Δ | +16.29 | +10.49 |
| | | |
| Qwen3.5-397B-A17B-SFT | 70.11 | 45.69 |
| + Sim RL(受控) | **73.98** | **51.74** |
| Δ | +3.87 | +6.05 |
**智能体基础模型。** 在单轮、非智能体轨迹上进行 LWM RL 预热,可迁移到多轮、工具调用的智能体任务中:
| | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 Item | Claw-Eval | QwenClawBench | BFCL v4 |
|:---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| | *领域内* | | | | *领域外* | | |
| Qwen3.5-35B-A3B-SFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 39.76 | 62.29 |
| 使用 LWM RL | **39.55** | **67.86** | **47.42** | **46.17** | **64.88** | **49.43** | **71.25** |
| Δ | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +9.67 | +8.96 |
有关详细结果,请查看[博客](https://qwen.ai/blog?id=qwen-agentworld)和[技术报告](http://arxiv.org/abs/2606.24597)。
## 快速开始
### 部署
Qwen-AgentWorld-35B-A3B 受多个推理框架支持。在此我们演示 SGLang 和 vLLM 的使用方法。
#### SGLang
[SGLang](https://github.com/sgl-project/sglang) 是一个用于大型语言模型的快速推理服务框架。
```
python -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--context-length 262144 \
--reasoning-parser qwen3
```
OpenAI 兼容的 API 将在 `http://localhost:8000/v1` 上可用。
#### vLLM
[vLLM](https://github.com/vllm-project/vllm) 是一个用于 LLM 的高吞吐量和内存高效的推理引擎。
```
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-code
```
OpenAI 兼容的 API 将在 `http://localhost:8000/v1` 上可用。
### 使用 Transformers 进行推理
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
```
## 在 AgentWorldBench 上进行评估
AgentWorldBench 通过在五个维度:**格式 (Format)**、**事实性 (Factuality)**、**一致性 (Consistency)**、**真实性 (Realism)** 和 **质量 (Quality)** 上对每个预测的环境观察结果进行评分,来评估语言世界模型。
 ### 设置
```
# 下载 benchmark
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 安装依赖
pip install openai
```
### 数据格式
AgentWorldBench 由各个领域的 JSONL 文件组成(`mcp_test.jsonl`、`search_test.jsonl`、`terminal_test.jsonl`、`swe_test.jsonl`、`android_test.jsonl`、`web_test.jsonl`、`os_test.jsonl`)。
```
{
"task": "mcp",
"id": 145256090131919,
"prompt": ["### Turn 1\n**Action:**\n```json\n{...}\n```\n..."],
"response": ["**Environment Observation:**\n{...}"],
"current_prompt": "### Turn 1\n**Action:**\n...",
"system_str": "# Role and Objective\n\nYou are a **Tool World Model** ...",
"turn_idx": 1,
"total_turns": 5
}
```
关键字段:
- **`system_str`**:特定样本的世界模型系统提示词。每个样本都带有自己的系统提示词,因此本仓库 `prompts/` 目录中提供的提示词**仅供参考的模板**。
- **`prompt`** / **`response`**:轨迹中所有轮次的列表(动作提示词和真实的基准环境观察结果)。
- **`current_prompt`**:正在评估的当前轮次的动作提示词。
- **`turn_idx`**:当前轮次从 1 开始索引的位置。
### 运行评估
我们提供了一个独立的评估脚本(`eval/eval.py`),它使用兼容 OpenAI 的 API 来进行世界模型推理和 LLM 评判打分。评估遵循三阶段的 pipeline:
```
cd eval
# 步骤 1:运行 world model 推理
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# 步骤 2:运行 LLM judge 评分
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# 步骤 3:汇总并展示分数
python eval.py score --predictions ./results/judged.jsonl
```
用于打分的评判提示词位于 `prompts/{domain}/judge_system_prompt.txt`。`prompts/{domain}/system_prompt.txt` 中的世界模型系统提示词作为**参考模板**提供;在评估期间,将使用每个样本 `system_str` 字段中的系统提示词。
### 评估输出
`score` 命令输出各个领域和总体的结果:
```
======================================================================
AgentWorldBench Evaluation Results (example output)
======================================================================
--- MCP (286/286 valid, 0 failed) ---
format: 81.46
factuality: 68.75
consistency: 72.92
realism: 71.88
quality: 67.08
total_score: 72.42
...
======================================================================
Overall: 56.39
======================================================================
```
##调
我们建议您使用包括 [Swift](https://github.com/modelscope/swift)、[Llama-Factory](https://github.com/hiyouga/LLaMA-Factory)、[UnSloth](https://github.com/unslothai/unsloth) 等在内的训练框架,在特定领域的环境数据上对模型进行微调。
## 许可协议
所有开放权重的模型和 AgentWorldBench 均根据 Apache 2.0 许可协议授权。
您可以在相应的 Hugging Face 仓库中找到许可文件。
## 引用
如果您觉得我们的工作对您有帮助,欢迎引用我们。
```
@article{zuo2026qwen,
title={Qwen-agentworld: language world models for general agents},
author={Zuo, Yuxin and Xiao, Zikai and Sheng, Li and Huang, Fei and Tu, Jianhong and Liu, Yuxuan and Tang, Tianyi and Hu, Xiaomeng and Su, Yang and Lan, Qingfeng and others},
journal={arXiv preprint arXiv:2606.24597},
year={2026}
}
```
## 联系我们
如果您有兴趣给我们的研究团队或产品团队留言,请加入我们的 [Discord](https://discord.gg/CV4E9rpNSD) 或 [微信交流群](https://github.com/QwenLM/Qwen/blob/main/assets/wechat.png)!
### 设置
```
# 下载 benchmark
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 安装依赖
pip install openai
```
### 数据格式
AgentWorldBench 由各个领域的 JSONL 文件组成(`mcp_test.jsonl`、`search_test.jsonl`、`terminal_test.jsonl`、`swe_test.jsonl`、`android_test.jsonl`、`web_test.jsonl`、`os_test.jsonl`)。
```
{
"task": "mcp",
"id": 145256090131919,
"prompt": ["### Turn 1\n**Action:**\n```json\n{...}\n```\n..."],
"response": ["**Environment Observation:**\n{...}"],
"current_prompt": "### Turn 1\n**Action:**\n...",
"system_str": "# Role and Objective\n\nYou are a **Tool World Model** ...",
"turn_idx": 1,
"total_turns": 5
}
```
关键字段:
- **`system_str`**:特定样本的世界模型系统提示词。每个样本都带有自己的系统提示词,因此本仓库 `prompts/` 目录中提供的提示词**仅供参考的模板**。
- **`prompt`** / **`response`**:轨迹中所有轮次的列表(动作提示词和真实的基准环境观察结果)。
- **`current_prompt`**:正在评估的当前轮次的动作提示词。
- **`turn_idx`**:当前轮次从 1 开始索引的位置。
### 运行评估
我们提供了一个独立的评估脚本(`eval/eval.py`),它使用兼容 OpenAI 的 API 来进行世界模型推理和 LLM 评判打分。评估遵循三阶段的 pipeline:
```
cd eval
# 步骤 1:运行 world model 推理
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# 步骤 2:运行 LLM judge 评分
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# 步骤 3:汇总并展示分数
python eval.py score --predictions ./results/judged.jsonl
```
用于打分的评判提示词位于 `prompts/{domain}/judge_system_prompt.txt`。`prompts/{domain}/system_prompt.txt` 中的世界模型系统提示词作为**参考模板**提供;在评估期间,将使用每个样本 `system_str` 字段中的系统提示词。
### 评估输出
`score` 命令输出各个领域和总体的结果:
```
======================================================================
AgentWorldBench Evaluation Results (example output)
======================================================================
--- MCP (286/286 valid, 0 failed) ---
format: 81.46
factuality: 68.75
consistency: 72.92
realism: 71.88
quality: 67.08
total_score: 72.42
...
======================================================================
Overall: 56.39
======================================================================
```
##调
我们建议您使用包括 [Swift](https://github.com/modelscope/swift)、[Llama-Factory](https://github.com/hiyouga/LLaMA-Factory)、[UnSloth](https://github.com/unslothai/unsloth) 等在内的训练框架,在特定领域的环境数据上对模型进行微调。
## 许可协议
所有开放权重的模型和 AgentWorldBench 均根据 Apache 2.0 许可协议授权。
您可以在相应的 Hugging Face 仓库中找到许可文件。
## 引用
如果您觉得我们的工作对您有帮助,欢迎引用我们。
```
@article{zuo2026qwen,
title={Qwen-agentworld: language world models for general agents},
author={Zuo, Yuxin and Xiao, Zikai and Sheng, Li and Huang, Fei and Tu, Jianhong and Liu, Yuxuan and Tang, Tianyi and Hu, Xiaomeng and Su, Yang and Lan, Qingfeng and others},
journal={arXiv preprint arXiv:2606.24597},
year={2026}
}
```
## 联系我们
如果您有兴趣给我们的研究团队或产品团队留言,请加入我们的 [Discord](https://discord.gg/CV4E9rpNSD) 或 [微信交流群](https://github.com/QwenLM/Qwen/blob/main/assets/wechat.png)!
**Qwen-AgentWorld** 是一个原生语言世界模型,它通过在**七个统一领域**(MCP、Search、Terminal、SWE、Android、Web 和 OS)中进行长思维链推理来模拟智能体环境。它通过三阶段的 pipeline 进行训练——CPT 注入环境知识,SFT 激活下一状态预测推理,RL 增强模拟保真度——训练数据包含超过 1000 万条真实世界的交互轨迹。与以往将世界建模视为事后附加方法的做法不同,Qwen-AgentWorld 是一个**原生世界模型**:从 CPT 阶段开始,环境建模就是其训练目标。 主要特征: - **七个统一领域。** 第一个在单个模型中涵盖七个智能体交互领域的语言世界模型。 - **原生世界模型。** 从 CPT 阶段开始进行环境建模,而非事后适应。 - **可泛化、可扩展且可控的模拟器。** 对 OOD 环境实现零样本泛化(例如 Claw Agent);可控扰动和虚构世界构建超越了真实环境训练。 - **智能体基础模型。** 在单轮、非智能体轨迹上进行 LWM RL 预热,可迁移到跨七个基准测试的多轮、工具调用智能体任务中,其中包括三个完全超出领域的任务。 ## 性能表现
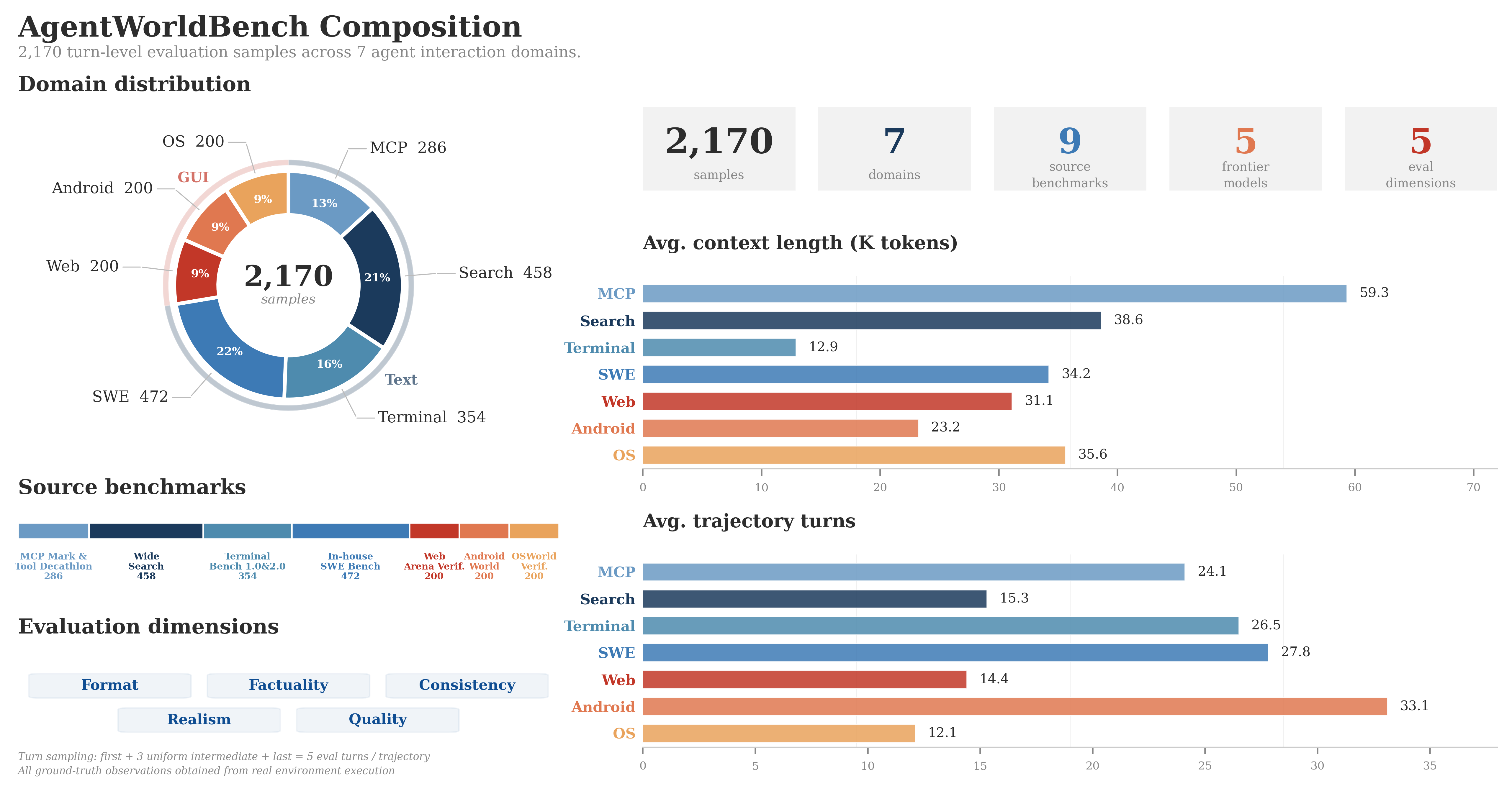
Overview of AgentWorldBench: domain distribution, source benchmarks, evaluation dimensions, and per-domain trajectory statistics.
标签:DLL 劫持, MoE模型, 人工智能, 凭据扫描, 大语言模型, 用户模式Hook绕过, 系统调用监控, 评测基准, 语言世界模型, 逆向工具, 通用智能体