prowork101/Enterprise-observability
GitHub: prowork101/Enterprise-observability
基于 Terraform 在 AWS 上构建的集中式监控与告警平台,整合 Prometheus、Grafana、CloudWatch 和 SNS 实现基础设施指标的可视化与自动化告警。
Stars: 0 | Forks: 0
# 企业级可观测性与监控平台
## 概述
本项目使用 Terraform、Prometheus、Grafana、CloudWatch 和 SNS 在 AWS 上实现了一个集中式监控与报警平台。该解决方案提供了对基础设施健康状况、性能指标和运行状态的实时可视化能力,同时支持自动化的告警和事件响应。
## 项目结构
```
enterprise-observability-platform/
├── dashboards/
├── docs/
├── screenshots/
├── terraform/
│ ├── modules/
│ │ ├── cloudwatch/
│ │ ├── ec2-monitoring/
│ │ ├── security-groups/
│ │ └── sns/
│ ├── main.tf
│ ├── provider.tf
│ ├── variables.tf
│ ├── outputs.tf
│ └── terraform.tfvars
├── user-data.sh
├── README.md
└── .gitignore
```
## 使用的技术
* AWS
* Terraform
* Prometheus
* Grafana
* CloudWatch
* SNS
* EC2
* Node Exporter
## 架构
```
Terraform
│
▼
AWS EC2 Monitoring Server
│
├── Prometheus
│
├── Grafana
│
└── Node Exporter
│
▼
CloudWatch Alarms
│
▼
SNS Notifications
│
▼
Email Alerts
```
## 项目成果
* 使用 Terraform 部署基础设施。
* 使用 Prometheus 实现集中式监控。
* 构建 Grafana 仪表板以实现基础设施可视化。
* 配置 CloudWatch 告警以进行主动监控。
* 启用 SNS 邮件通知以发送告警。
## Terraform 命令
```
terraform init
terraform validate
terraform plan
terraform apply
terraform state list
terraform destroy
```
## 实施步骤
### 步骤 1:项目初始化
创建了项目结构和 Terraform 配置文件。
### 步骤 2:SNS 告警配置
预配置了 SNS 主题和邮件订阅,用于发送告警通知。
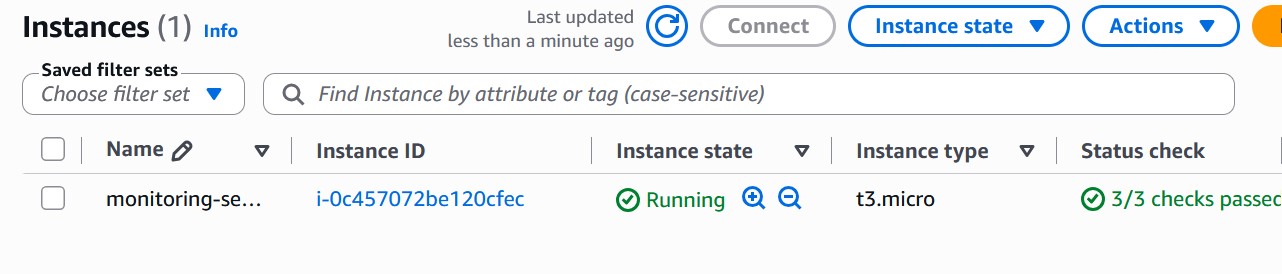
### 步骤 3:EC2 监控服务器部署
部署了一台 EC2 实例用于承载监控服务。
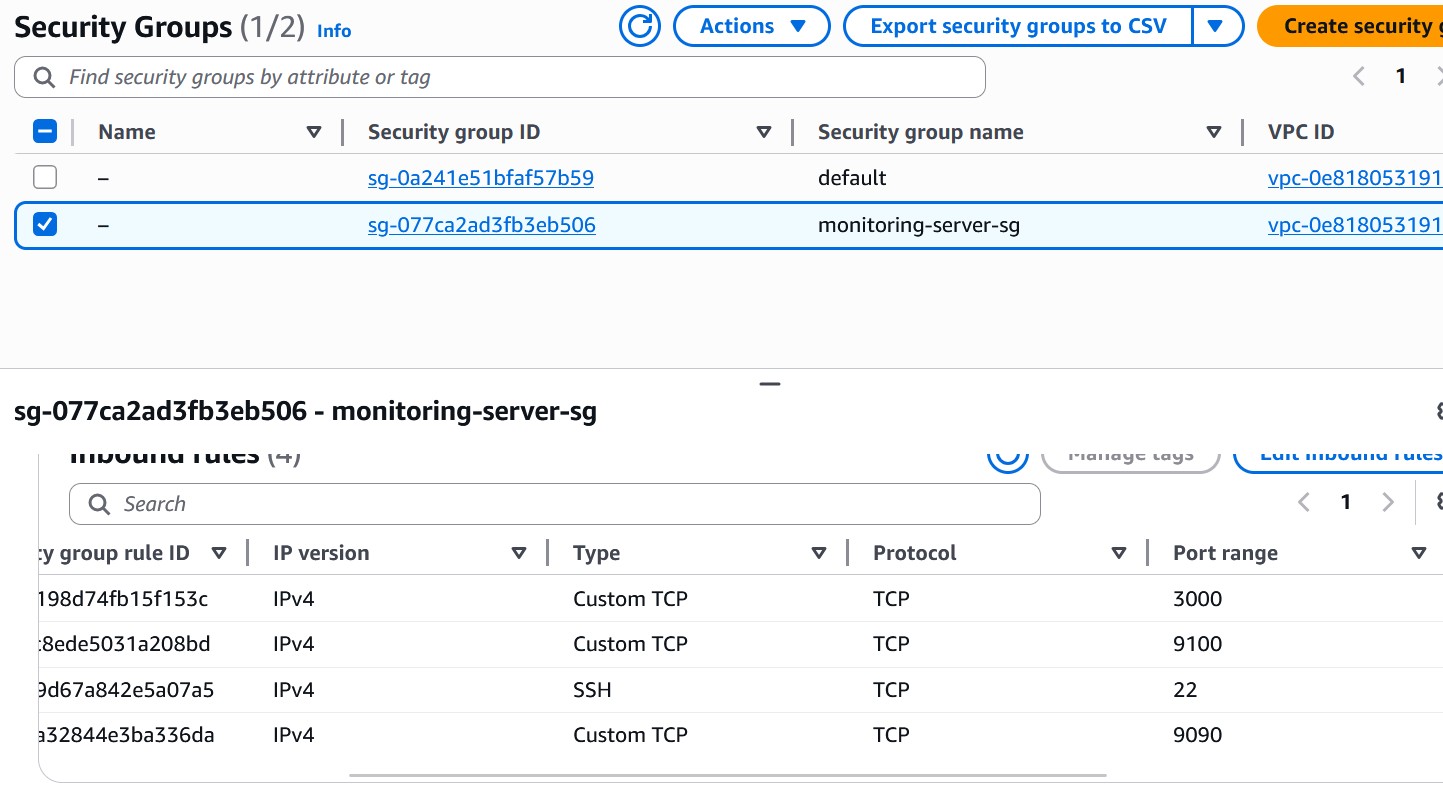
### 步骤 4:安全组配置
为 SSH、Grafana、Prometheus 和 Node Exporter 配置了网络访问权限。
### 步骤 5:安装 Prometheus
安装并配置了 Prometheus 用于收集指标。
### 步骤 6:安装 Grafana
安装了 Grafana 并配置了仪表板访问权限。
### 步骤 7:部署 Node Exporter
安装了 Node Exporter 以收集系统指标。
### 步骤 8:创建仪表板
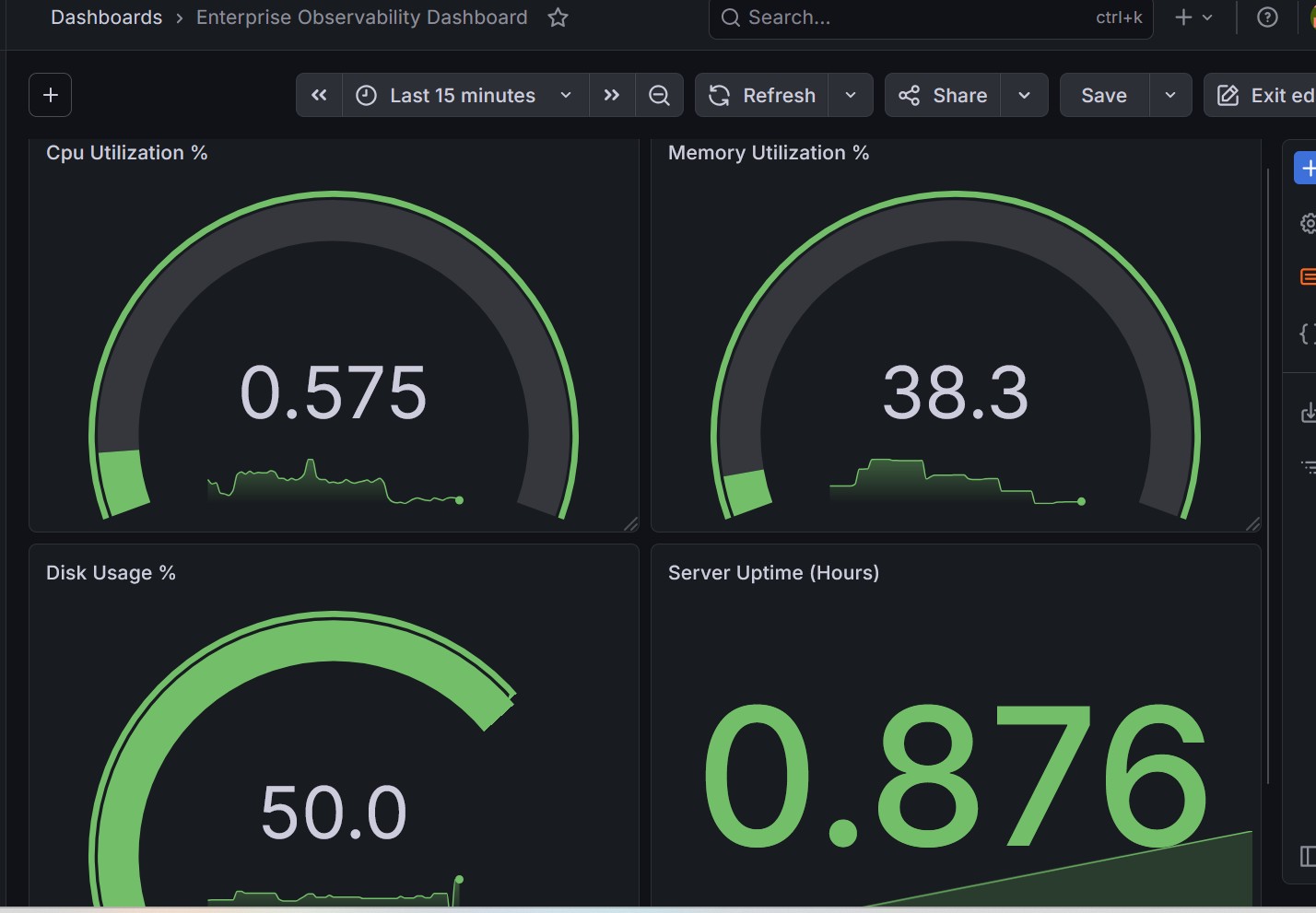
构建了用于监控 CPU、内存、磁盘和运行时间的仪表板。
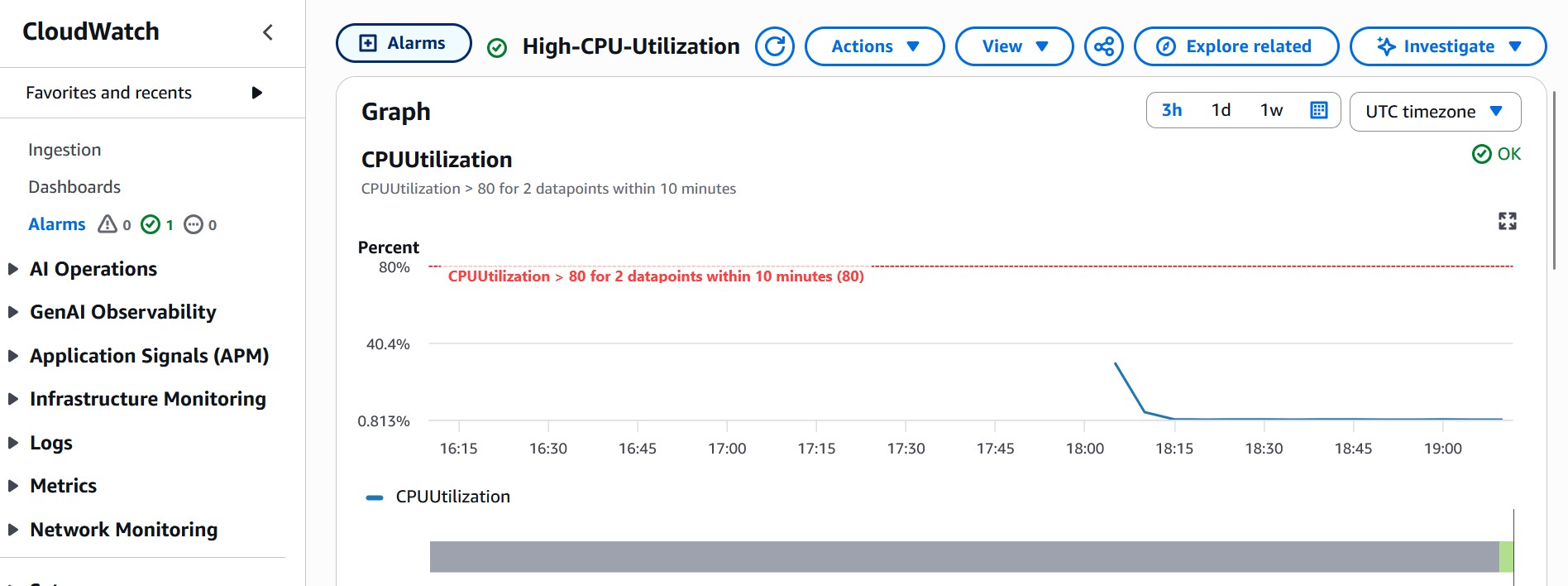
### 步骤 9:配置 CloudWatch 告警
配置了 CloudWatch 告警以进行基础设施监控。
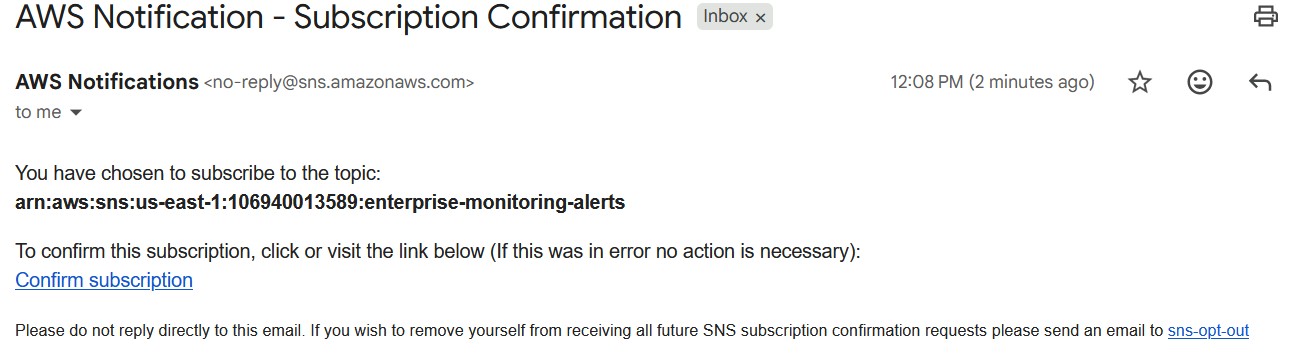
### 步骤 10:验证 SNS 告警
验证了邮件通知和告警发送工作流。
## 业务影响
设计并部署了一套集中式监控与告警解决方案。提供了对 CPU、内存、磁盘和运行时间指标的实时可视化能力。通过自动化的监控和通知机制,提升了运维感知能力与事件响应速度。
## 截图
### Terraform 部署

### EC2 实例
### 安全组
### Grafana
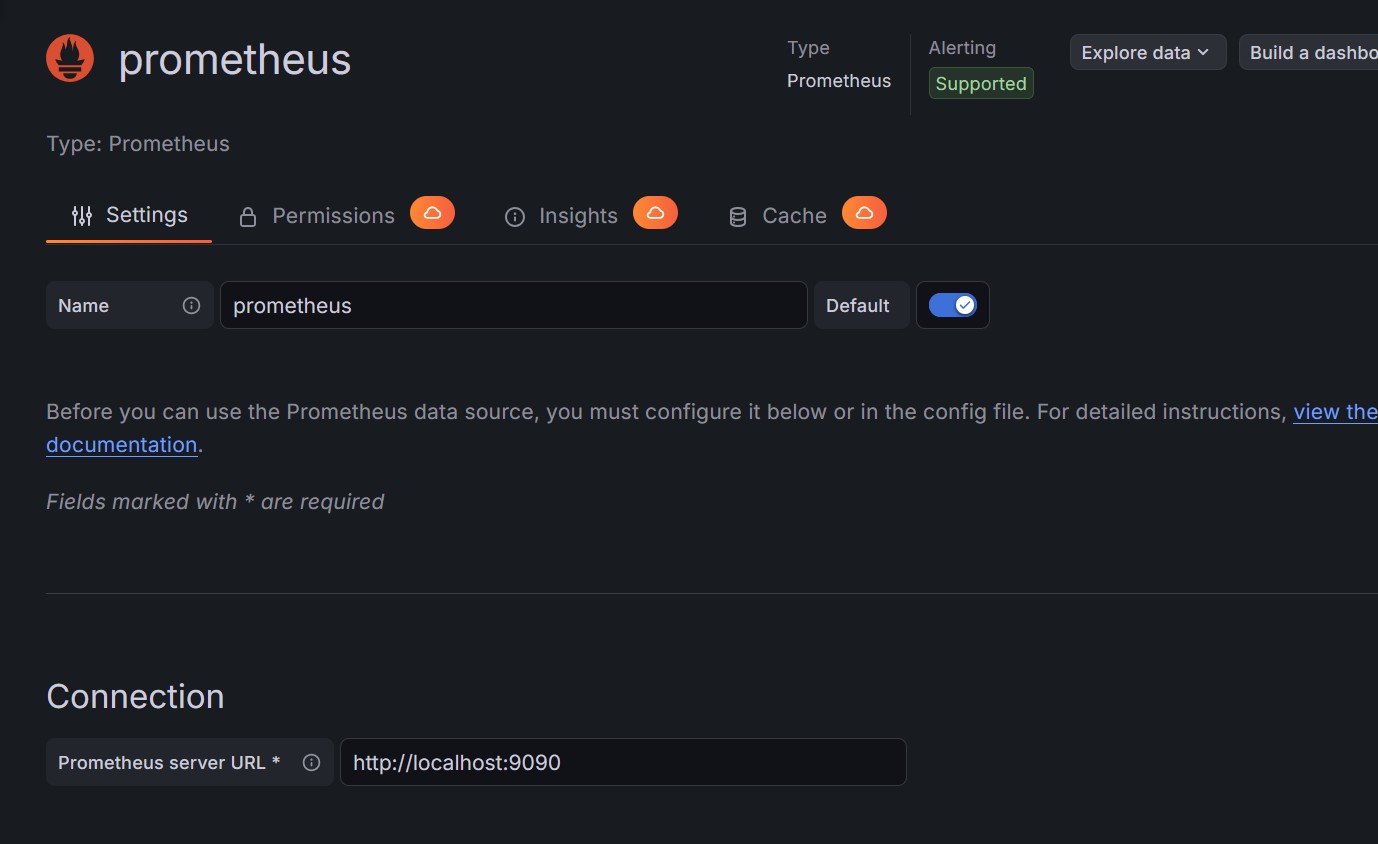
### Grafana 仪表板
### Prometheus
### CloudWatch 告警
### SNS 通知
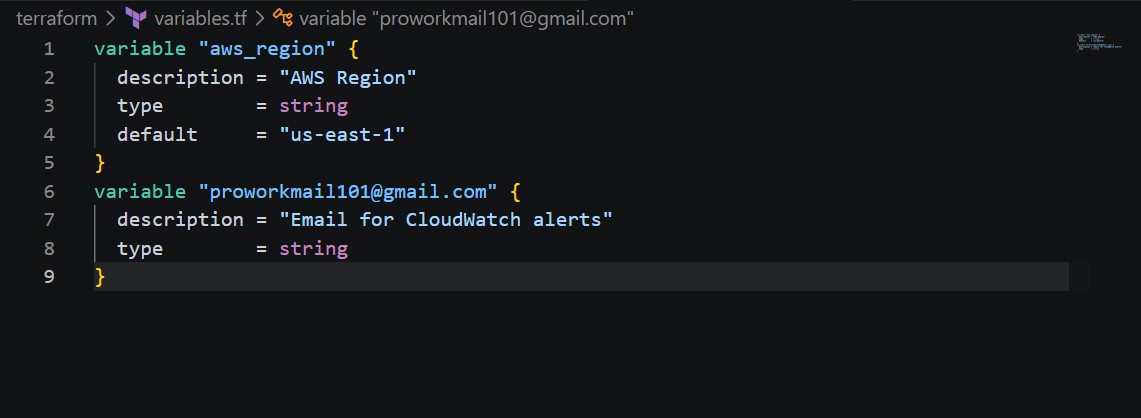
### 告警邮件
标签:API集成, AWS, DPI, ECS, Terraform, 可观测性, 漏洞利用检测, 监控告警, 自定义请求头, 运维