notyorch/TUP-detection
GitHub: notyorch/TUP-detection
一个混合提示注入检测引擎,通过正则规则、神经分类器和 LLM 评判器三层流水线实现对 LLM 输入输出中越狱和指令覆盖攻击的高准确率检测。
Stars: 1 | Forks: 1
Hybrid Prompt-Injection Guard — TUP AIGSMP 的检测引擎
[](LICENSE) []() []() []() [](https://apartresearch.com/project/tup-detection-hybrid-promptinjection-guard-for-ai-generative-security-monitoring-r4w6)
![]()
关于 • 架构 • 结果 • 评估 • 局限性 • 路线图 • 快速开始 • 贡献 • 结构 • 配置
![]()
text_normalize · prompt_segments"] M1 --> M2 M2["M2 Build variant set V(x)
raw · normalized · per-segment"] M2 --> M3 M3["M3 L1 Regex policy
policies/rules/"] M3 -- hit --> ALERT["ALERT
rule_id, OWASP-mapped"] M3 -- no hit --> M4 M4["M4 Sentinel v2 — max s(v) over V(x)
injection_classifier (HF endpoint)"] M4 -- gray zone --> L3 L3["L3 LLM judge (optional)
nvidia_judge_engine"] L3 -.-> M4 M4 --> M5 M5["M5 Threshold τ → verdict → structured alert → TUP-fullstack"] ``` | 层级 | 组件 | 特性 | |-------|-----------|-----------------| | **L1** | 映射到 OWASP 的 regex (`policies/rules/`) | 确定性,零延迟,可追溯的 `rule_id` | | **L2** | Sentinel v2 (HF Inference Endpoint) | 神经分类器,抗改写鲁棒,无需 fine-tuning | | **L3** *(可选)* | LLM 评判器 (NVIDIA NIM — Llama 3.1) | 针对 `s ∈ [0.15, 0.85]` 的灰带仲裁 | 引擎同时监控 **输入和输出** —— 双向打分可以捕获只有在模型被引导之后才能观察到的攻击。 ### 检测模式 | 模式 | τ | 良性防护 | 用途 | |------|---|--------------|-----| | `benchmark` | 0.15 | 关闭 | Tier-B 评估 / 最大召回率 | | `production` | 0.50 | 开启 | 实时流量 / 抑制 FP | ## 结果 主要基准测试:**[deepset/prompt-injections](https://huggingface.co/datasets/deepset/prompt-injections)** (n = 662, Tier B)。 指标:**PINT 平衡准确率** = ½ (攻击召回率 + 良性特异度)。 | 系统 | PINT 平衡准确率 | |--------|:----------------------:| | TUP + DeBERTa *(旧基线)* | 72.4% | | Sentinel v2 *(模型卡片,间接)* | ~88% | | **TUP + Sentinel v2 (本仓库)** | **95.1%** | 在 deepset 上的堆栈消融实验 (τ = 0.15): | 堆栈 | PINT | 攻击召回率 | 良性通过率 | TP | FN | FP | |-------|:----:|:-------------:|:-----------:|:--:|:--:|:--:| | 仅 L1 | 58.4% | 17.9% | 99.0% | 47 | 216 | 4 | | 仅 Sentinel | 95.1% | 93.2% | 97.0% | 245 | 18 | 12 | | **混合模型** | **95.1%** | **94.3%** | **96.0%** | **248** | **15** | 16 | 在 **[Crescendo](https://arxiv.org/abs/2404.01833)** 多轮对抗性对话 (n = 10) 上,完整对话记录打分实现了 **100% 的攻击召回率**。 ## 评估 ### 测试 1 — 单轮注入检测 (deepset, n = 662) 跨四个指标的堆栈消融实验。仅第一层即可保护良性流量(99% 通过率),但只能捕获 18% 的攻击。单独使用 Sentinel v2 可提供强大的召回率。混合模型在保持 Tier-B PINT 准确率的同时,还额外捕获了 3 个 Sentinel 漏掉且易于解释的攻击,每一个都带有可追溯的 `rule_id` 属性。 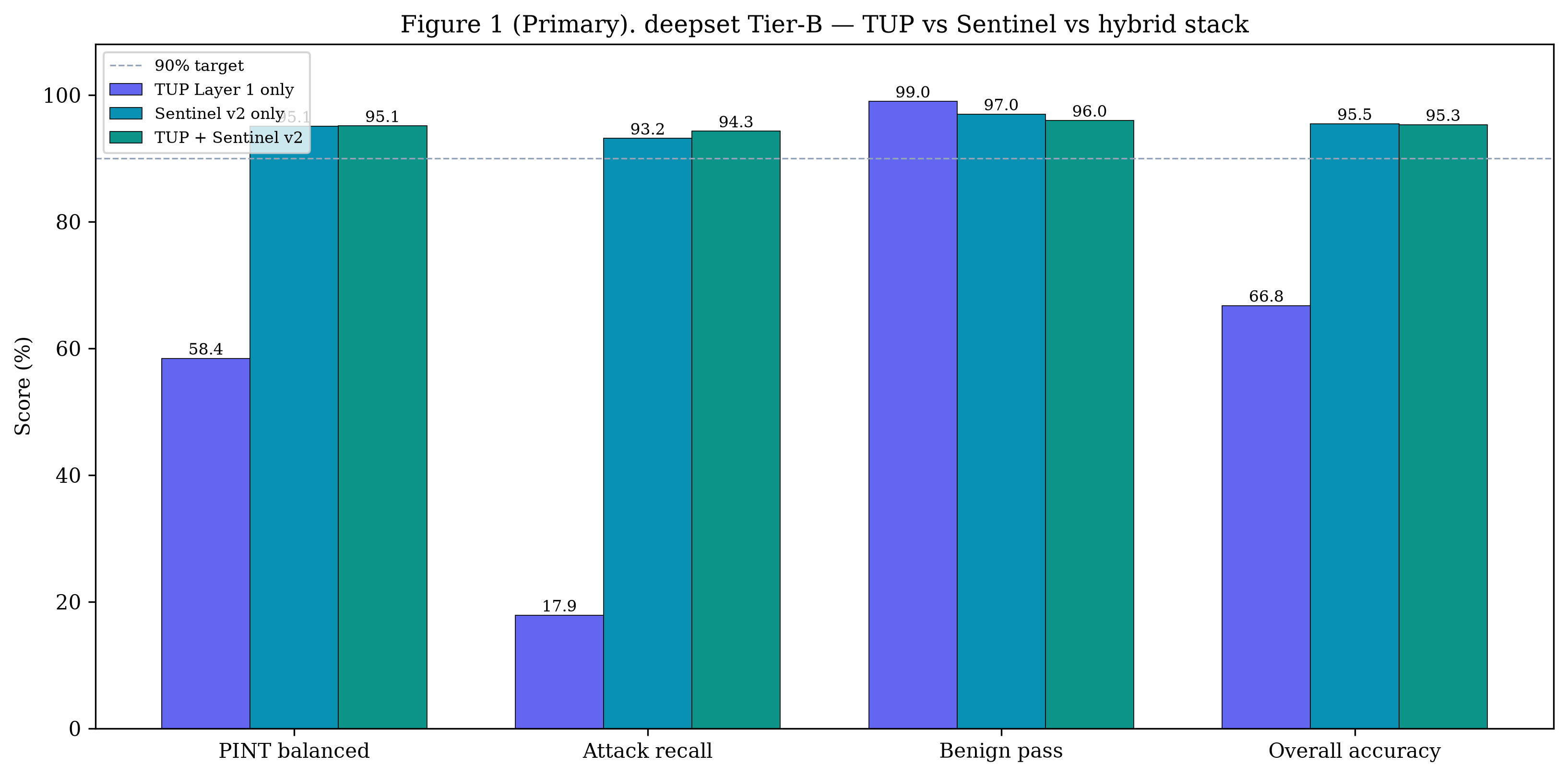 ### 测试 2 — 与公开基线对比 在同一 deepset 数据划分上测试了 TUP + Sentinel v2,并与我们的旧版 TUP + DeBERTa 堆栈及公开报告的基线进行了对比。这两个**已测量**的堆栈(TUP + Sentinel v2 和 TUP + DeBERTa)是在我们完全相同的 YAML 数据划分上评估的;而**文献**中的数值(Sentinel v2 模型卡片,ProtectAI DeBERTa)是在不同条件下报告的 —— 详见[局限性](#limitations)。 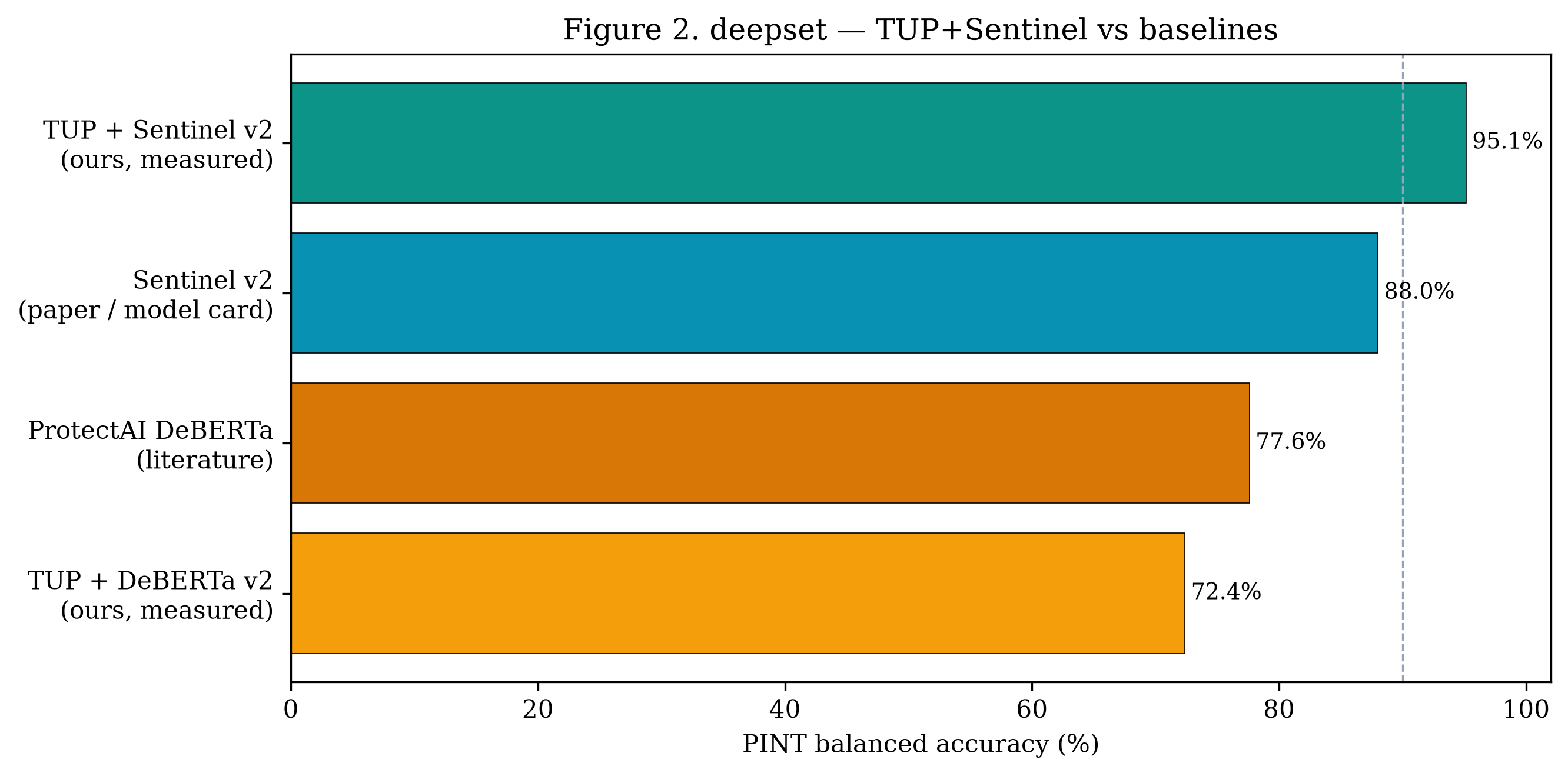 ### 测试 3 — 层级互补性(每层捕获的内容) 在 263 个攻击样本中,这两层表现出互补性:201 个仅由 Sentinel 检测到,44 个被两者同时检测到,还有 **3 个完全由第一层独占检测** —— 这 3 个样本携带的 `rule_id` 属性可以追溯到 `policies/rules/` 中映射到 OWASP 的模式,这是任何分类器都无法提供的。添加第一层重新捕获了它们,代价是比仅使用 Sentinel 增加了 4 个 FP。 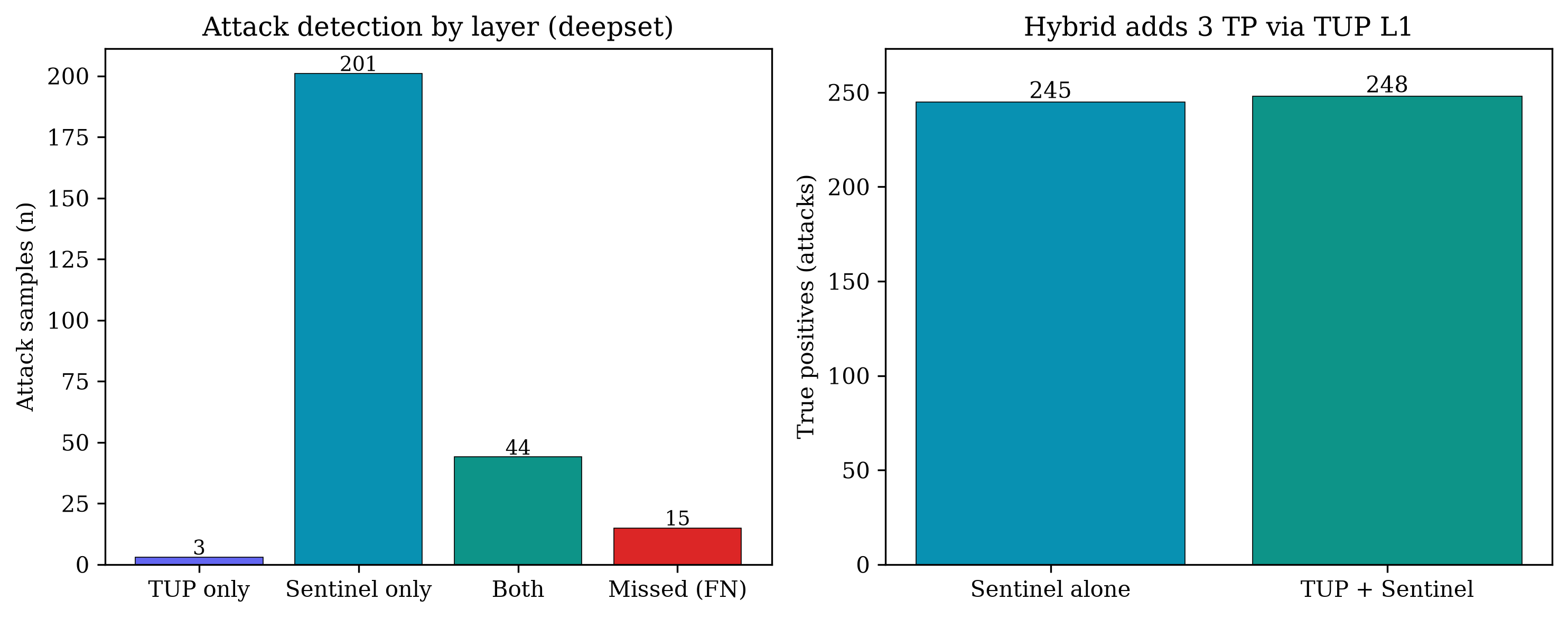 ### 测试 4 — 多轮攻击检测 (Crescendo, n = 10 组对话) Crescendo 攻击在对话轮次中逐渐升级 —— 早期的轮次看起来是良性的。无状态的单轮防护会漏掉 25% 的攻击。完整对话记录打分将完整的对话提供给分类器,并在所有 10 组对话中实现了 **100% 的攻击召回率**。 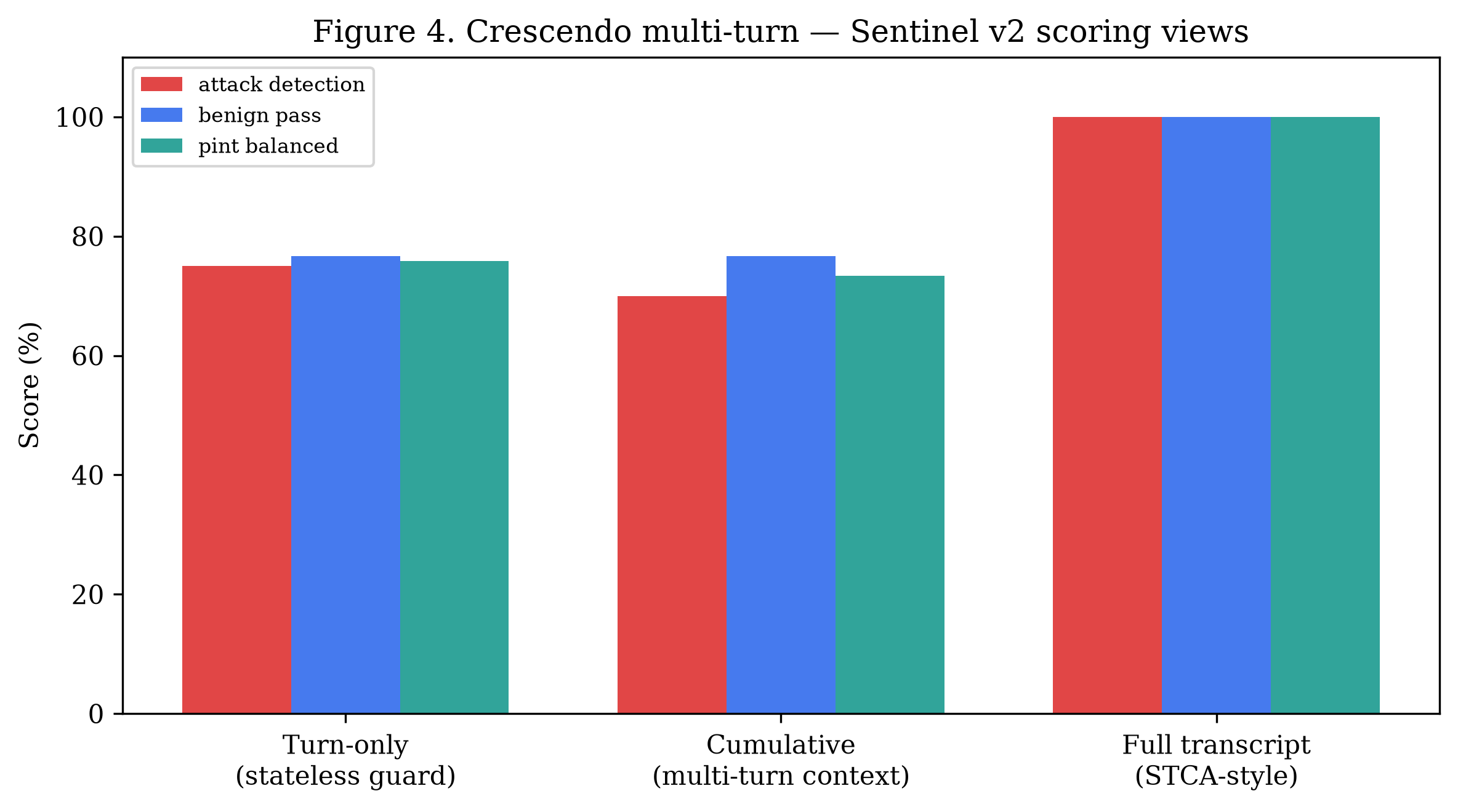 首次检测平均发生在第 2.7 轮;所有对话都在第 6 轮之前被标记。 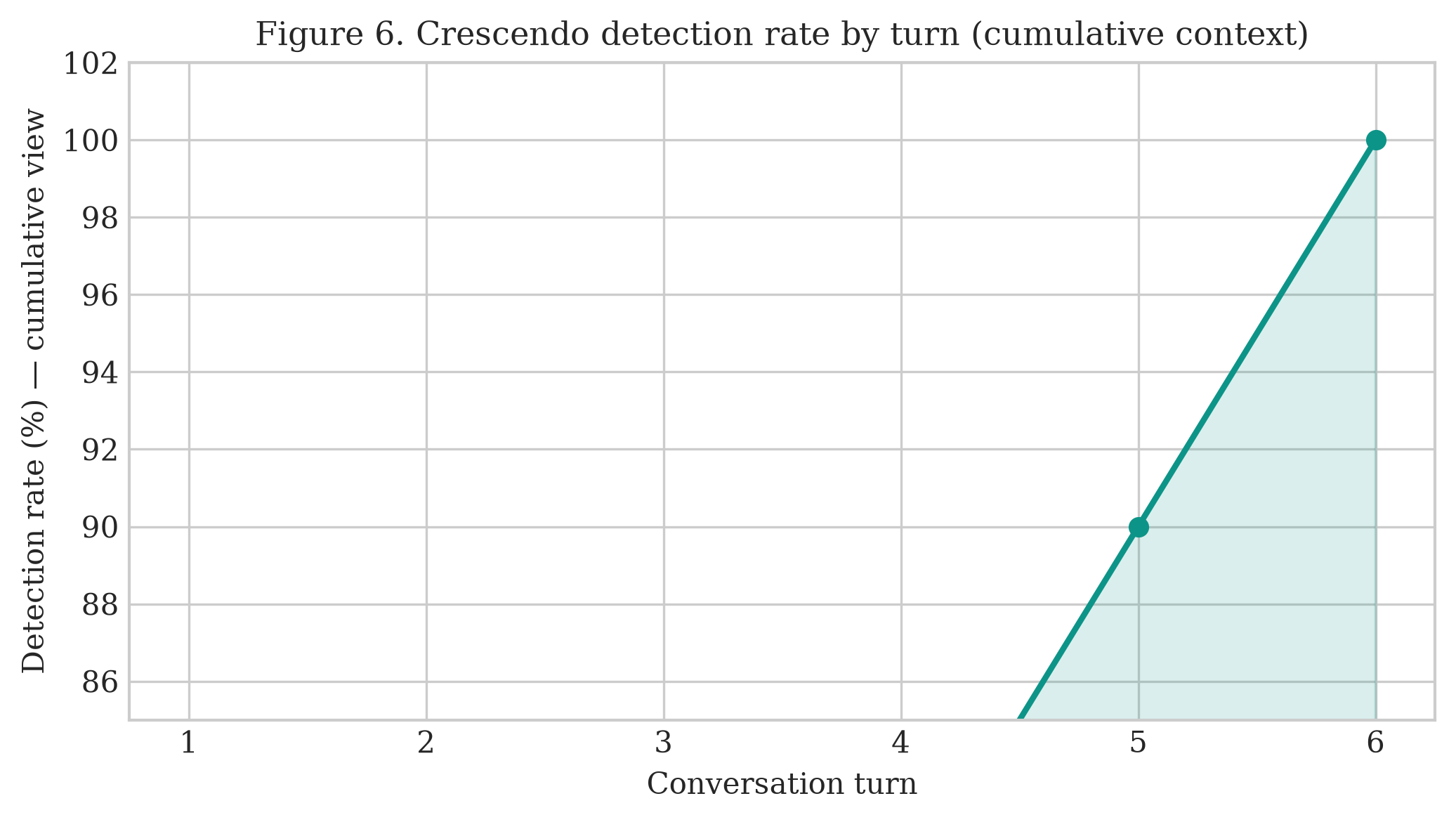 ## 局限性 我们公开报告这些情况,以便在上下文中解读结果: - **基线对比是近似的。** 只有两个 TUP 堆栈(TUP + Sentinel v2 和 TUP + DeBERTa)是在我们完全相同的 deepset YAML 数据划分上测量的。Sentinel v2 模型卡片 (~88%) 和 ProtectAI DeBERTa (77.6%) 的数值是在不同的数据集、数据划分和决策阈值下生成的**报告**值,且**未**在我们的基础设施下重新运行。请将跨系统的差距视为指示性参考,而非直接对比。 - **单一的主要数据集。** 头条的 Tier-B 结论依赖于一个公开的基准测试 (deepset/prompt-injections, n = 662)。更广泛的分布验证(例如 Antijection, OWASP v2)正在进行中,尚未完成。 - **多轮样本量小。** Crescendo 评估涵盖了 n = 10 组对话 —— 这为多轮覆盖提供了有力的方向性证据,但并非大规模的鲁棒性研究。 - **完整对话记录偏向性。** Crescendo 100% 的召回率是在完整对话记录打分下获得的,该过程将完整的对话输入给分类器。无状态的单轮打分(一种更严格、在运营上更真实的设置)难度更大,检测到的内容也更少。 - **Endpoint 依赖。** 实时打分需要受控的 Sentinel v2 HF Inference Endpoint。冻结的缓存分数可以离线重现所有报告的指标,但新输入需要部署好的模型。 ## 路线图 这些内容直接对应于上述的[局限性](#limitations),并作为 GitHub issues 进行追踪 —— 欢迎贡献(参见[贡献](#contributing)): - **扩展 Crescendo 多轮基准测试**,从 n = 10 扩大到 n ≥ 50 组对话,以获得更强的鲁棒性声明。 - **完成更广泛的分布验证**,在主要的 deepset 基准之外,对 Antijection 和 OWASP v2 数据划分进行测试。 - **添加对抗性规避测试套件**(改写、编码和 token 级扰动),以探测第二层 (Layer 2) 的鲁棒性。 - **在我们的基础设施下重跑文献基线**,用直接对比的数值取代近似的跨系统比较。 - **扩充第一层 (Layer 1) 规则包**,增加更多映射到 OWASP 的模式以及针对每个规则的 false-positive 回归测试。 ## 快速开始 ### 前置条件 * Python 3.10+ * 一个 Hugging Face 账号(Read token + 已接受 Sentinel v2 许可协议) * *(可选,L3 评判器)* 一个 NVIDIA NIM API key ### 快速冒烟测试(无需凭证) 想在 30 秒内看到引擎运行,且不需要任何 token 或 endpoint?第一层( 确定性的、映射到 OWASP 的 regex 引擎)不需要任何凭证和网络: ``` python3 -m venv .venv-pint && source .venv-pint/bin/activate pip install -r scripts/requirements-pint.txt && pip install -r tup-manager/requirements.txt python scripts/smoke_l1.py ``` 预期输出 —— 良性 prompt 通过,攻击触发并带有可追溯的 `rule_id`: ``` [PASS] benign | alert=False (rule: —) [PASS] attack | alert=True (rule: tup-rule-0001, tup-rule-0009, tup-rule-0011) ... RESULT: all 5 cases matched — Layer 1 engine is working ``` 完整的 pipeline(第二层 Sentinel v2 + 可选的 L3 评判器)需要以下步骤。 ### 1. 安装 ``` python3 -m venv .venv-pint && source .venv-pint/bin/activate pip install -r scripts/requirements-pint.txt pip install -r tup-manager/requirements.txt ``` ### 2. 配置 ``` cp notebooks/.env.pint.example .env ``` 然后使用你的密钥编辑 `.env`(参见[配置参考](#configuration-reference)): ``` SENTINEL_API_KEY=hf_... # HF token (Read scope, license accepted) HF_INFERENCE_ENDPOINT=https://xxxxx.aws.endpoints.huggingface.cloud NVIDIA_JUDGE_API_KEY=nvapi-... # optional — only for the L3 judge DETECTION_MODE=benchmark # or: production BENIGN_GUARD_ENABLED=false # true for production ``` ### 3. 部署 Sentinel v2 Inference Endpoint Sentinel v2 是一个受限模型 —— 请先接受许可协议。 1. 在 **[rogue-security/prompt-injection-jailbreak-sentinel-v2](https://huggingface.co/rogue-security/prompt-injection-jailbreak-sentinel-v2)** 接受许可 2. 在 **[ui.endpoints.huggingface.co/new](https://ui.endpoints.huggingface.co/new)** 创建一个 endpoint - 模型: `rogue-security/prompt-injection-jailbreak-sentinel-v2` - 任务: **Text Classification** · 实例: **CPU** · Scale-to-zero: **ON** 3. 将 endpoint URL 粘贴到 `.env` 中 (`HF_INFERENCE_ENDPOINT`) ### 4. 验证 ``` python scripts/verify_hf_endpoint.py ``` ### 5. 运行基准测试 ``` # 自动化 (导入 deepset + benchmark) ./scripts/run_sentinel_tier_b.sh # 手动 python scripts/import_external_dataset.py --preset deepset \ --out notebooks/data/external/deepset.yaml python scripts/run_pint_benchmark.py \ --dataset notebooks/data/external/deepset.yaml \ --detection-mode benchmark \ --results-out notebooks/data/external/results/deepset-sentinel.json ``` ### 运行测试套件 ``` pytest tup-manager/tests/ -v ``` ## 仓库结构 ``` TUP-detection/ ├── tup-manager/ # Detection engine (TUP Manager core) │ ├── tup_manager/ │ │ ├── detection_engine.py # Pipeline orchestration (M1–M5) │ │ ├── injection_classifier.py # Sentinel v2 backend (hf / local) │ │ ├── prompt_segments.py # Context/user segment parser │ │ ├── text_normalize.py # Input normalization (M1) │ │ ├── rules_engine.py # L1 regex dispatch │ │ ├── benign_guard.py # FP suppression for production │ │ ├── ensemble_classifier.py # Optional Llama Prompt Guard 2 │ │ └── nvidia_judge_engine.py # Optional L3 LLM judge (NVIDIA NIM) │ └── tests/ # Unit tests (pytest) │ ├── policies/ │ └── rules/ # OWASP-mapped regex rules (YAML) │ ├── scripts/ │ ├── run_pint_benchmark.py # Main benchmark + detection modes │ ├── run_stack_ablation_benchmark.py │ ├── run_crescendo_benchmark.py │ ├── import_external_dataset.py # deepset / OWASP v2 / Antijection │ ├── verify_hf_endpoint.py # Endpoint smoke test │ └── requirements-pint.txt │ └── notebooks/ ├── benchmark.ipynb ├── tup_detection_guard_benchmark_report.ipynb ├── tier_b_guard_comparison.ipynb ├── data/external/results/ # Frozen benchmark JSON results └── .env.pint.example ``` ## 配置参考 | 变量 | 默认值 | 描述 | |----------|---------|-------------| | `SENTINEL_API_KEY` | — | HF token (也可使用 `HF_TOKEN`) | | `HF_INFERENCE_ENDPOINT` | — | 已部署的 Sentinel v2 endpoint URL | | `DETECTION_MODE` | `production` | `benchmark` 或 `production` | | `INJECTION_THRESHOLD` | `0.5` | 生产环境阈值 τ | | `INJECTION_THRESHOLD_STRICT` | `0.15` | 基准测试阈值 τ | | `BENIGN_GUARD_ENABLED` | `true` |针对类似文档输入的 FP 抑制 | | `INJECTION_FAIL_OPEN` | `true` | 推理失败时: `true` → benign (0.0), `false` → malicious (1.0) | | `HF_INFERENCE_TIMEOUT` | `180` | 重试前的每请求超时秒数 | | `HF_INFERENCE_RETRIES` | `5` | 最大重试次数 (针对 scale-to-zero 冷启动) | | `DETECTION_JUDGE_ENABLED` | `auto` | 启用 L3 LLM 评判器 | | `NVIDIA_JUDGE_API_KEY` | — | 用于 L3 评判器的 NVIDIA NIM key | | `NVIDIA_JUDGE_MODEL` | `meta/llama-3.1-8b-instruct` | 评判器模型 | | `JUDGE_THRESHOLD` | `0.65` | 评判器决策阈值 | ### 故障排除 | 症状 | 修复方法 | |---------|-----| | `401` / `403` | Token 权限范围问题或未接受模型许可协议 | | `503` / 模型不受支持 | 使用专用的 **Inference Endpoint**,而不是 Serverless 免费层 | | 分数始终为 `0` | Endpoint 未运行或 URL 错误 | | 首次请求缓慢 | Scale-to-zero 冷启动 —— 会自动发送预热请求 | ## 引用 如果您在研究中使用 TUP Detection 或基于其基准进行开发,请引用它。仓库根目录包含一个机器可读的 [`CITATION.cff`](CITATION.cff)(GitHub 的 "Cite this repository" 按钮会使用它)。 **研究提交** — [Apart Research · Global South 2026](https://apartresearch.com/project/tup-detection-hybrid-promptinjection-guard-for-ai-generative-security-monitoring-r4w6): ``` @misc{tup_detection_apart_2026, title = {(HckPrj) TUP Detection: Hybrid Prompt-Injection Guard for AI Generative Security Monitoring}, author = {Jorge Enrique Vargas Pech and Jose Luis Rej{\'o}n Quintal and William Emmanuel Fern{\'a}ndez Castillo and Sa{\'u}l Ruiz Pe{\~n}a}, date = {2026-06-22}, organization = {Apart Research}, note = {Research submission to the research sprint hosted by Apart.}, howpublished = {\url{https://apartresearch.com/project/tup-detection-hybrid-promptinjection-guard-for-ai-generative-security-monitoring-r4w6}} } ``` **软件**: ``` @software{tup_detection_2026, author = {Vargas Pech, Jorge Enrique and Fern{\'a}ndez Castillo, William Emmanuel and Ruiz Pe{\~n}a, Sa{\'u}l and Rej{\'o}n Quintal, Jose Luis}, title = {TUP Detection: A Hybrid Tier-B Prompt-Injection Engine for the TUP AIGSMP Platform}, year = {2026}, url = {https://github.com/notyorch/TUP-detection}, note = {Detection engine of the TUP AI Governance \& Security Monitoring Platform (AIGSMP)} } ``` ## 作者与致谢 由 **Jorge Vargas Pech, William Fernández Castillo, Saúl Ruiz Peña, 和 Jose Luis Rejón Quintal** 构建,作为 **[TUP-fullstack](https://github.com/notyorch/TUP-fullstack)** 的检测模块。 技术支持由 [Sentinel v2](https://huggingface.co/rogue-security/prompt-injection-jailbreak-sentinel-v2) 提供, 评估基于 [deepset/prompt-injections](https://huggingface.co/datasets/deepset/prompt-injections) 以及 [Crescendo](https://arxiv.org/abs/2404.01833) 多轮攻击。 ## 许可证 本项目基于 MIT 许可证授权 —— 详见 [LICENSE](LICENSE) 文件。
标签:AI内容过滤, Web报告查看器, 人工智能, 大语言模型安全, 提示词注入检测, 机密管理, 混合检测引擎, 用户模式Hook绕过, 逆向工具, 零日漏洞检测