bolkosz-uriel/Offline-Security-Analyst-Copilot
GitHub: bolkosz-uriel/Offline-Security-Analyst-Copilot
一款完全离线运行的 AI 日志分析与事件响应 Copilot,通过混合确定性引擎和本地 LLM,将异构原始日志自动转化为结构化的安全事件报告。
Stars: 0 | Forks: 0
# 离线安全分析师 Copilot
一个本地化、**离线优先的 AI 日志分析器和事件响应 copilot**。它能够提取多样的日志格式,将其标准化至统一的存储中,检测异常,将其分组为攻击模式,并将每种模式转化为一份**可操作的、结构化的事件报告** —— 所有这些都在你自己的机器上完成,数据绝不外传。
分析过程是**混合**的:确定性引擎负责计算硬性事实(妥协指标、攻击类型分类、MITRE ATT&CK 基线以及填充了具体值的修复方案),而**本地 LLM**(通过 [Ollama](https://ollama.com/))则负责叙述和划分优先级。由于确定性层为模型提供了事实基础并进行了回填,即使在笔记本电脑上使用小型、对 CPU 友好的模型,输出结果也能保持具体且实用 —— 并且当你将其指向 GPU 上的更大模型时,输出质量也会随之提升。
## 功能
给定一个包含原始日志的目录,该 copilot 会:
1. **提取与标准化** 异构日志(syslog、认证日志、JSON 应用日志),并将其存储到 [DuckDB](https://duckdb.org/) 的统一 schema 中。
2. **检测异常**,方法是将事件聚合到每个 `(host, hour)` 窗口中,并使用导出为 ONNX 的 Isolation Forest 对其进行评分,以实现硬件感知推理。
3. **聚类** 使用 HDBSCAN 将异常窗口聚合为*攻击模式*。
4. **分析** 每种模式并生成结构化的事件报告:包含执行摘要、严重程度与置信度、MITRE ATT&CK 技术、重构的攻击链、妥协指标 (IOC) 以及划分好优先级的修复方案。
5. **报告** 将丰富后的事件生成为专业的 PDF。
它内置了 **FastAPI** 后端、**Streamlit** 仪表板,以及 **Docker Compose** 技术栈(API + UI + Ollama)。
### 核心特性
- **完全离线。** DuckDB、ONNX Runtime 和本地 Ollama 模型意味着无需网络调用,杜绝数据外泄。
- **混合式、可操作的分析。** 确定性 IOC 提取 + 攻击类型分类 + MITRE 基线与 LLM 报告相融合。薄弱或缺失的模型输出会自动由确定性层进行回填,任何引用了集群真实证据中不存在的 IP 的 LLM 散文都会被视为无根据并被替换 —— 从而确保报告始终具体且可信。
- **对小型 LLM 友好。** 紧凑且基于事实的 prompt 使得分析成本极低,足以在仅用 CPU 的笔记本电脑上运行,同时保持 schema 约束。
- **自选模型。** 每次分析都可以从 UI 中(或通过配置)选择任何已在本地拉取的 Ollama 模型。
- **硬件感知。** 自动检测 GPU 执行提供者(CUDA / DirectML / ROCm / TensorRT / MIGraphX),并能在无 GPU 时平滑回退至 CPU。
- **稳健的 API。** 端点会返回有用的 `4xx`/`5xx` 响应(例如当模型未训练或 Ollama 宕机时),而不是直接崩溃。
- **丰富的 UI。** 一个可导航的仪表板,包含系统健康状况、提取日志、日志浏览以及完整的事件视图(严重程度、MITRE 标签、IOC 面板、可视化攻击路径、优先级修复方案、实时进度条以及 PDF 导出)。
## 截图
**概览** —— 系统健康状态、已解析的计算设备以及分析模型选择器。
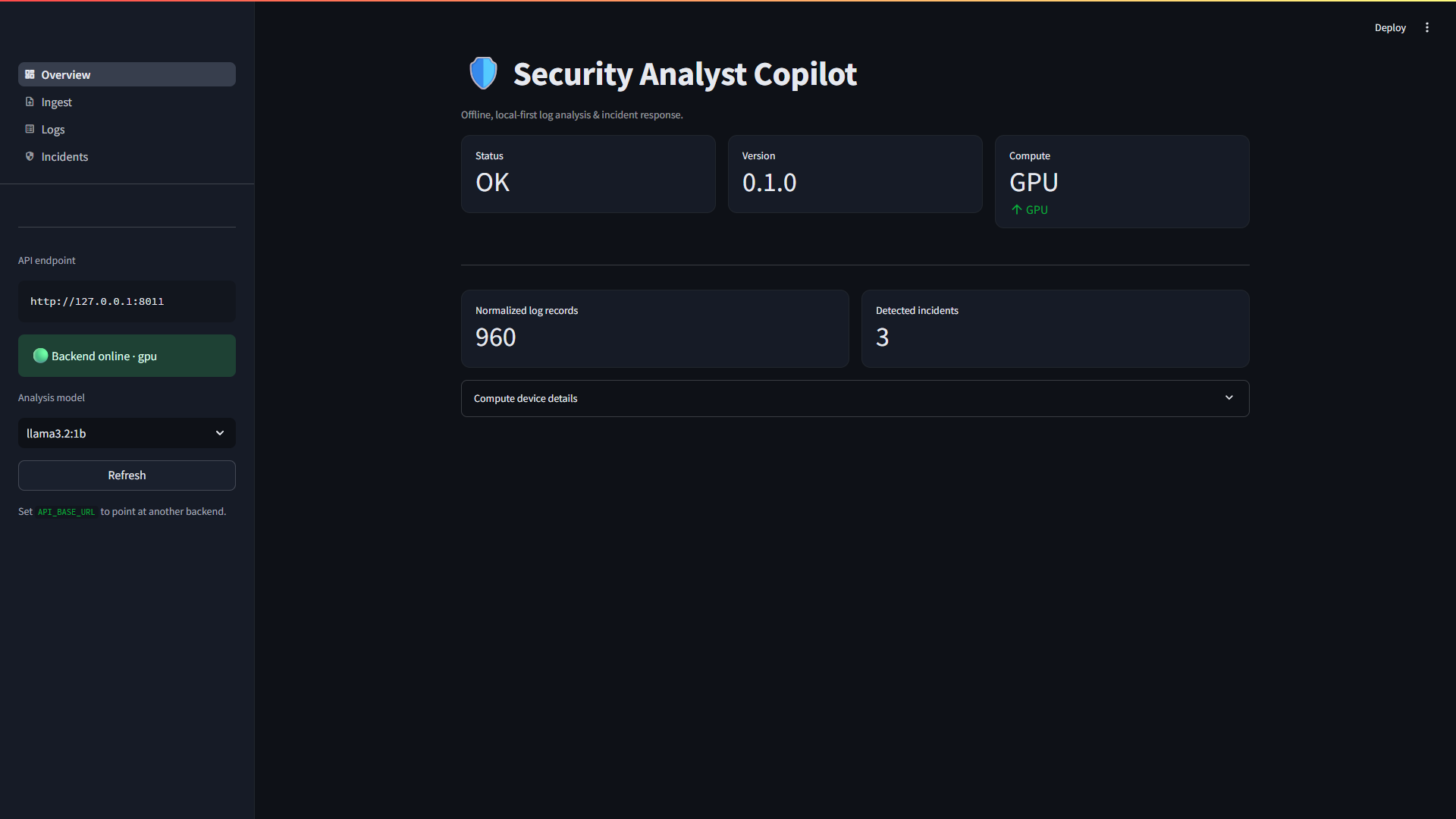
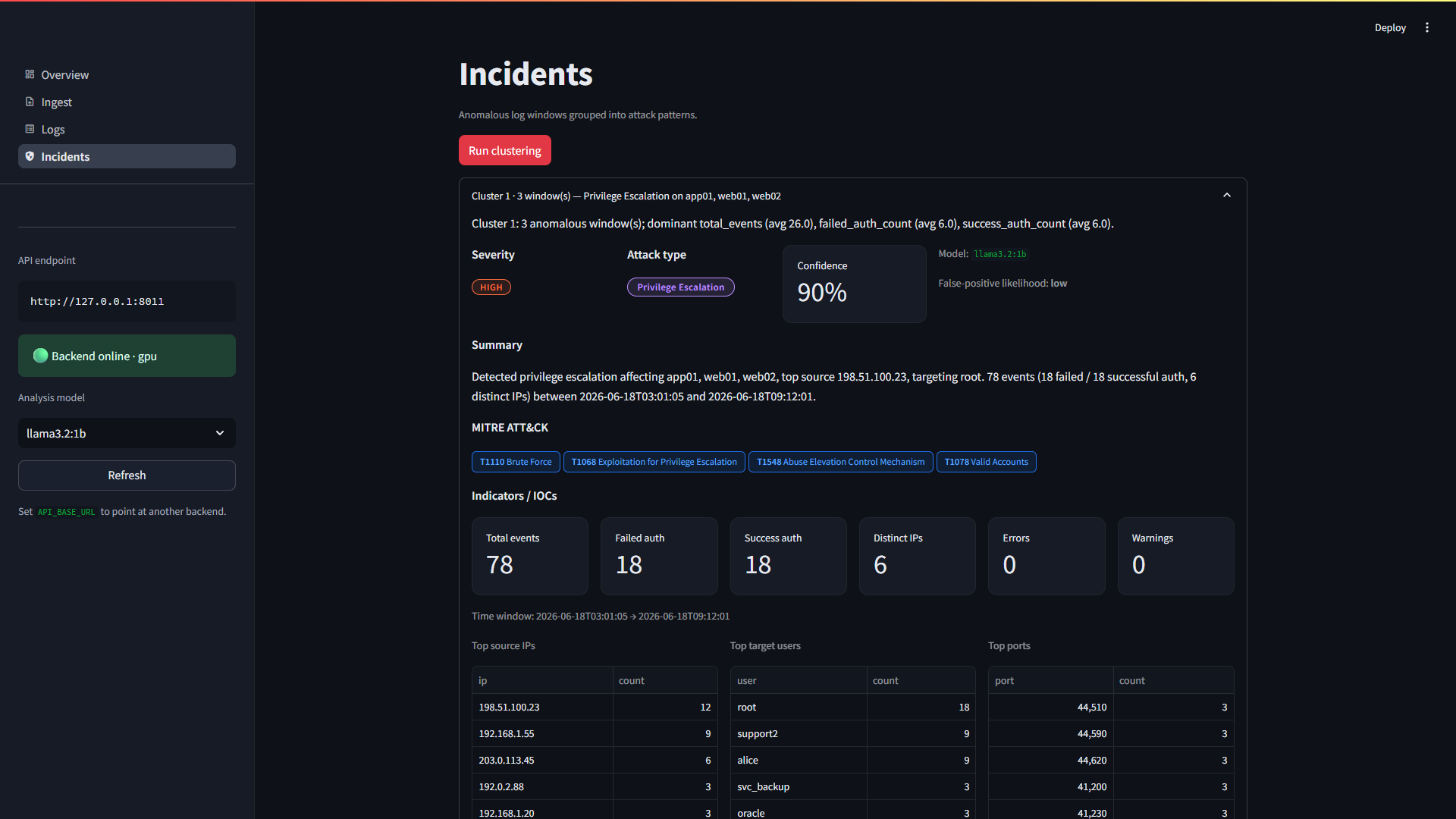
**事件分析** —— 严重程度与置信度、MITRE ATT&CK 技术以及确定性指标 (IOC) 面板。
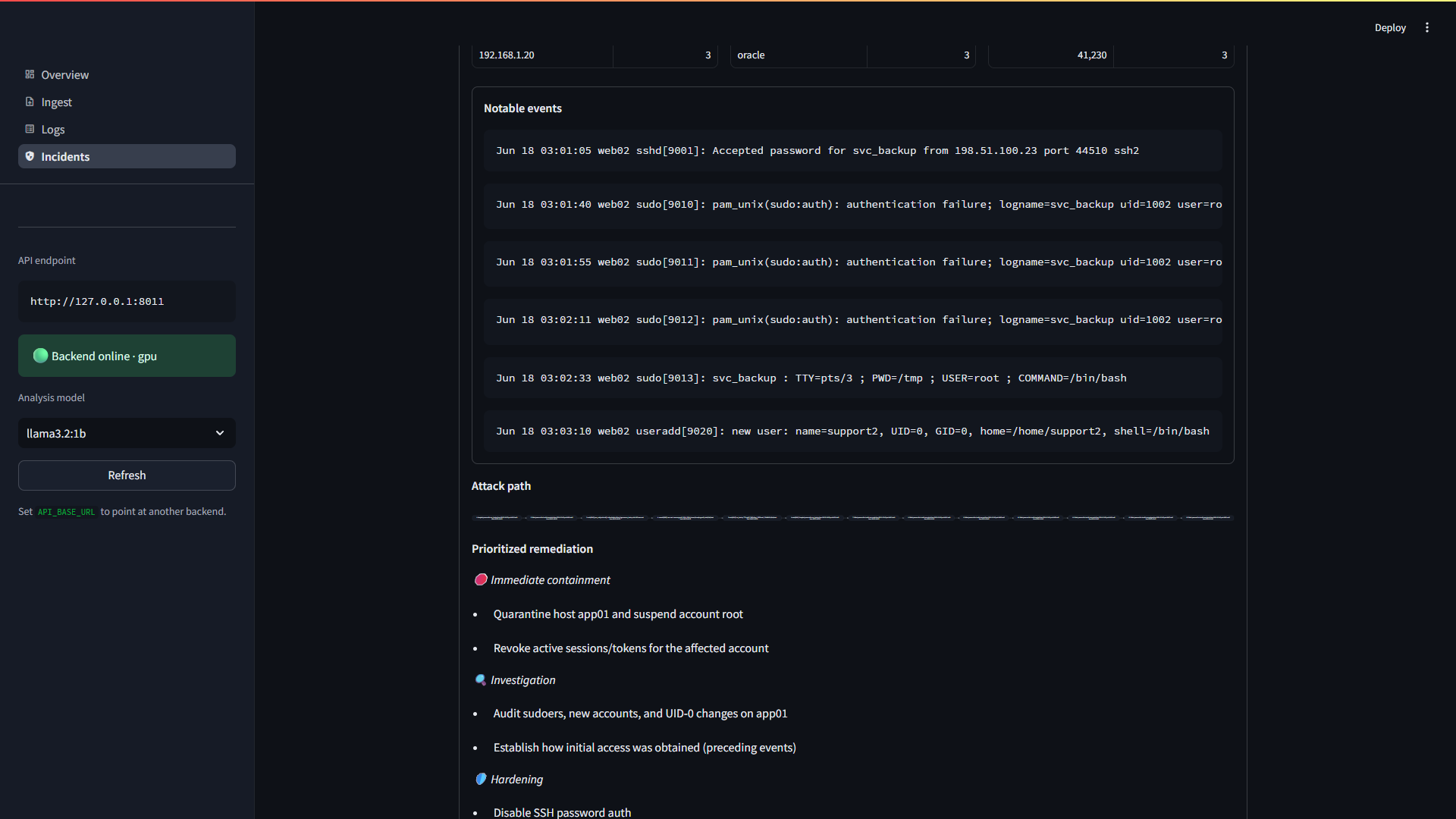
**优先级修复方案** —— 显著证据、重构的攻击路径以及立即执行 / 深入调查 / 加固步骤。
使用内置示例数据生成的 PDF 示例报告包含在
[`docs/sample_incident_report.pdf`](docs/sample_incident_report.pdf) 中。
## 工作原理(架构)
```
raw logs ─▶ ingestion ─▶ normalization ─▶ DuckDB ─▶ feature windows
│
▼
Isolation Forest (ONNX Runtime)
│ anomalies
▼
HDBSCAN
│ attack-pattern clusters
▼
┌───────────────────────────────────────────┐
│ Hybrid analysis │
│ deterministic IOCs / attack-type / MITRE │
│ + local LLM (Ollama) narration │
└───────────────────────────────────────────┘
│ structured incident
▼
PDF report + Streamlit UI
```
**混合分析详解**
- **确定性层** (`llm_integration/indicators.py`):查询集群确切的 `(host, hour)` 窗口并计算 IOC(顶级源 IP、目标用户、端口、时间窗口、事件计数、显著行),对攻击类型进行分类(暴力破解、凭证填充、端口扫描、权限提升、C2 beacon、Web 应用攻击、数据外泄或未知类型),推导出 MITRE ATT&CK 基线,并生成填充了具体值的修复方案种子。在遇到奇怪或缺失的数据时永远不会引发异常。
- **LLM 层** (`llm_integration/schemas.py` + `client.py`):确定性事实被注入到紧凑的 prompt 中,并且 `IncidentReportSchema` 的 JSON schema 作为 `format` 约束传递给 Ollama,从而在语法上强制模型输出符合规范的 JSON。验证器对于小型模型的怪异行为(大小写、百分比、杂乱的列表项)非常宽容,因此表面上的问题只会优雅地降级处理。
- **事实基础与回退** (`llm_integration/enrichment.py`):两层被合并。确定性基线会回填模型遗留的任何薄弱字段,而无根据的 LLM 文本将被丢弃,替换为基于事实生成的内容。合并后的结果会被持久化,因此在重新加载后依然存在。
## 项目结构
```
src/security_analyzer/
main.py FastAPI entry point (startup DB init, device detection)
config.py Settings (Pydantic; SA_-prefixed env vars / .env)
database.py DuckDB connection + schema
models/ Core domain models (RawLog, ParsedLog, Anomaly, Cluster, Incident)
schemas/ API request/response models
ingestion/ scanner (file discovery + type classification), parsers, pipeline
normalization/ parsed-record -> standardized schema
ml_pipeline/ feature engineering, Isolation Forest training + ONNX inference,
HDBSCAN clustering
llm_integration/ indicators (deterministic IOC/attack-type/MITRE), structured
LLM schema, Ollama client, enrichment (hybrid merge + grounding)
reporting/ PDF incident report rendering (ReportLab)
api/v1/routes/ ingest, logs, predict, incidents/cluster/analyze,
export-report, ollama (model listing) routers
utils/ logging + hardware detection
ui/ Streamlit dashboard (app.py, requirements.txt, Dockerfile,
.streamlit/ theme)
data/ sample logs (attack-representative)
models/ trained ML artifacts (generated)
reports/ generated PDF reports (generated)
tests/ unit + integration tests
Dockerfile API container image
docker-compose.yml API + Streamlit UI + Ollama stack
pyproject.toml package metadata, dependencies, build backend
```
## 环境要求
- **Python 3.11+**
- [Poetry](https://python-poetry.org/)(推荐)或普通 `pip`
- [Ollama](https://ollama.com/) 并且至少拉取了一个模型(用于 LLM 分析)
- 可选:NVIDIA/AMD/Intel GPU 以实现更快的推理(请参阅 [CPU / GPU 选择](#cpu--gpu-selection))
- 可选但最简单的方式:**Docker** + Docker Compose
## 安装
你可以使用 Docker 运行所有内容,或者设置一个本地开发环境。
### 选项 A — Docker(推荐)
该 compose 技术栈会同时运行 API、Streamlit UI 和 Ollama 服务:
```
docker compose up --build
# API -> http://localhost:8000 (交互式文档位于 /docs)
# UI -> http://localhost:8501
# Ollama -> http://localhost:11434
```
第一次运行时,需要将模型拉取到内置的 Ollama 服务中,以便分析功能正常运行:
```
docker compose exec ollama ollama pull llama3.2:1b
```
DuckDB 数据库和拉取的模型会持久化存储在命名卷中。将原始日志放入宿主机的 `./data` 目录(挂载到 API 容器中)即可提取它们。
### 选项 B — 本地开发
安装该包及其依赖项:
```
poetry install
# 或者,使用 pip:
pip install .
```
GPU 加速是可选的。默认安装 CPU ONNX Runtime,因此硬件检测开箱即用:
```
# NVIDIA / CUDA (Linux 或 Windows)
poetry install -E gpu # or: pip install .[gpu]
# Windows DirectML (大多数 DX12 GPU)
poetry install -E directml # or: pip install .[directml]
```
安装 [Ollama](https://ollama.com/download) 并拉取模型(仅需一次):
```
# winget install Ollama.Ollama # (Windows) — 或从网站下载
ollama pull llama3.2:1b # ~1.3 GB; small & CPU-friendly
# Ollama 默认在 http://127.0.0.1:11434 上提供服务。
```
运行后端:
```
poetry run security-analyzer
# 或者
poetry run uvicorn security_analyzer.main:app --reload
```
运行 Streamlit UI(其依赖项单独固定在 `ui/requirements.txt` 中):
```
pip install -r ui/requirements.txt
streamlit run ui/app.py
# UI 位于 http://127.0.0.1:8501,默认与位于 http://127.0.0.1:8000 的 API 通信。
# 通过 API_BASE_URL 环境变量将其指向其他位置。
```
## 使用指南
### 使用 Web UI
仪表板(侧边栏导航)是驱动整个流水线最简单的方法:
1. **概览** —— 确认后端在线以及它是否解析到了 CPU 或 GPU。从侧边栏选择器中挑选用于分析的 **Ollama 模型**。
2. **提取** —— 将包含日志的目录扫描到 DuckDB 中(将该字段留空则使用服务器配置的目录,默认为内置的 `data/`)。
3. **日志** —— 浏览标准化后的记录。
4. **事件** —— 点击 **运行聚类** 来检测异常并对它们进行分组。展开某个集群以查看其详细信息,接着点击 **使用本地 LLM 分析** 来生成报告(进度条会显示预计持续时间)。事件视图会呈现严重程度、MITRE 技术、IOC 面板、可视化攻击路径以及优先级的修复方案。使用 **生成 PDF 报告** 将其导出。
### 通过 API 实现端到端
通过 HTTP 执行相同的流程(离线;分析步骤需要 Ollama 正在运行):
```
# 1. 导入捆绑的示例(或传入 {"directory": "/path/to/logs"})。
curl -X POST http://127.0.0.1:8000/api/v1/ingest \
-H 'Content-Type: application/json' -d '{}'
# 2. 训练异常模型(基于已导入的数据进行训练;如果为空则进行引导)。
python -m security_analyzer.ml_pipeline.train
# 3. 将异常聚类为攻击模式。
curl -X POST http://127.0.0.1:8000/api/v1/cluster
# 4. 列出 incidents(每个包含确定性指标 + 任何已保存的分析)。
curl http://127.0.0.1:8000/api/v1/incidents
# 5. 通过其 label 分析一个 cluster(可选择一个模型)。
curl -X POST http://127.0.0.1:8000/api/v1/incidents/1/analyze \
-H 'Content-Type: application/json' -d '{"model": "llama3.2:1b"}'
# 6. 为已分析的 cluster 导出 PDF。
curl -L http://127.0.0.1:8000/api/v1/export-report/1 -o incident.pdf
```
### 精选 API 端点
| 方法与路径 | 用途 |
| --- | --- |
| `GET /health` | 存活检测 + 已解析的计算设备。 |
| `POST /api/v1/ingest` | 扫描并将日志目录标准化至 DuckDB。 |
| `GET /api/v1/logs` | 查询标准化日志(`limit`、`offset`)。 |
| `POST /api/v1/predict-anomaly` | 对单个特征向量进行评分。 |
| `GET /api/v1/predict-anomaly/features` | 列出模型的特征列。 |
| `POST /api/v1/cluster` | 运行异常检测 + HDBSCAN 聚类。 |
| `GET /api/v1/incidents` | 包含指标(及已持久化分析)的集群。 |
| `POST /api/v1/incidents/{label}/analyze` | 生成并持久化混合报告(可选 `{"model": ...}`)。 |
| `GET /api/v1/export-report/{label}` | 下载事件 PDF。 |
| `GET /api/v1/ollama/models` | 列出本地可用的 Ollama 模型。 |
交互式 API 文档可在 `http://127.0.0.1:8000/docs` 获取。
### 直接进行异常评分
`POST /api/v1/predict-anomaly` 接受有序列表(与特征列匹配),或者以特征名称为键的映射(缺失名称默认为 `0`):
```
# Ordered: [total_events, failed_auth_count, success_auth_count,
# distinct_source_ips, error_count, warning_count]
curl -X POST http://127.0.0.1:8000/api/v1/predict-anomaly \
-H 'Content-Type: application/json' \
-d '{"features": [500, 480, 1, 300, 200, 50]}'
# 或者以 name 为键
curl -X POST http://127.0.0.1:8000/api/v1/predict-anomaly \
-H 'Content-Type: application/json' \
-d '{"features": {"failed_auth_count": 480, "distinct_source_ips": 300}}'
```
`anomaly_score` 被标准化至 `[0, 1]` 区间(数值越高 = 越异常;`0.5` 是决策边界)。如果模型尚未训练,该端点会返回 `503` 及相关指导,而不是直接崩溃。
## 选择 LLM 模型
分析模型完全由你决定 —— 从 UI 侧边栏、`SA_OLLAMA_MODEL` 设置或 `analyze` 端点上的 `model` 字段中,挑选任何你已经拉取到 Ollama 的模型。建议:
| 环境 | 推荐模型 | 说明 |
| --- | --- | --- |
| **CPU / 笔记本电脑** | `llama3.2:1b`、`llama3.2:3b` | 快速且轻量;尽管模型较小,但确定性的事实基础能确保报告依然具体。 |
| **GPU 工作站** | `qwen3:14b`、`mistral-small3.1:24b` | 叙述和攻击链推理明显更加丰富。 |
因为确定性层始终提供 IOC、攻击类型、MITRE 基线和修复方案种子,即使是 1B 模型也能生成具体、可操作的报告 —— 更大的模型主要会改善文字叙述和攻击链重构。
### CPU / GPU 选择
`SA_DEVICE=auto`(默认值)会在 ONNX Runtime 报告存在 GPU 提供者(CUDA / DirectML / ROCm / TensorRT / MIGraphX)时解析为 GPU 执行路径,否则使用 CPU。使用 `SA_DEVICE=cpu` 或 `SA_DEVICE=gpu` 可强制指定设备。解析出的设备会通过 `/health` 报告,显示在 UI 中,并在启动时记录到日志。要启用 GPU,请安装匹配的 ONNX Runtime 扩展包(请参阅[安装](#option-b--local-development))。
## 配置
设置从环境变量(前缀为 `SA_`)或 `.env` 文件中读取:
| 设置项 | 环境变量 | 默认值 | 描述 |
| --- | --- | --- | --- |
| `database_path` | `SA_DATABASE_PATH` | `./security_analyzer.duckdb` | DuckDB 文件位置。 |
| `log_dir` | `SA_LOG_DIR` | `./data` | 默认提取日志的目录。 |
| `reports_dir` | `SA_REPORTS_DIR` | `./reports` | 生成的 PDF 报告保存位置。 |
| `models_dir` | `SA_MODELS_DIR` | `./models` | 存储已训练 ML 产物的位置。 |
| `device` | `SA_DEVICE` | `auto` | 计算设备:`auto`、`cpu`、`gpu`。 |
| `ollama_model` | `SA_OLLAMA_MODEL` | `llama3.2:1b` | 默认用于分析的 Ollama 模型。 |
| `ollama_host` | `SA_OLLAMA_HOST` | `http://127.0.0.1:11434` | Ollama 服务器 URL。 |
Streamlit UI 额外读取 `API_BASE_URL`(默认 `http://127.0.0.1:8000`)以定位后端。
## 推荐用例
- **隔离/气闸网络上的事件分流。** 因为数据绝对不会离开宿主机,它适用于机密、OT/ICS 或其他网络环境,这些环境通常不允许使用基于云的 SOC 工具。
- **家庭实验室 / 小型团队的安全监控。** 将其指向 SSH/认证日志、Web 服务器日志和应用日志,即可浮现出暴力破解、扫描、权限提升和 Web 攻击模式,而无需搭建完整的 SIEM。
- **事件后 / 取证日志审查。** 将导出的一批日志放入 `data/` 中,运行流水线,即可获得包含 IOC、MITRE 映射的集群攻击模式以及可分享的 PDF。
- **SIEM 前端的基础/富化层。** 使用确定性的 IOC 和攻击类型分类作为结构化信号,将 LLM 报告作为适合分析师阅读的叙述,同时让你的 SIEM 负责警报和基于规则的严重性划分。
- **保护隐私的演示与培训。** 这是一种自包含、可复现的方法,可在笔记本电脑上展示端到端的异常检测 -> 聚类 -> LLM 事件分析。内置的 `data/` 示例包含了具有代表性的攻击场景。
**适用范围与限制。** 这是一个分析 copilot,而不是实时的 IDS/SIEM:它作为批处理流水线处理提取的日志,而不是流处理。LLM 的输出是辅助性的,应由分析师进行审查。检测质量取决于提取日志的数量和多样性(异常模型需要足够的窗口来学习基线)。
## 测试
测试套件结合了单元测试和集成测试。`pytest` 会自动将 `src/` 添加到路径中(通过 `pyproject.toml`),因此无需额外设置:
```
poetry run pytest
# 或者,在已激活的环境中:
pytest
```
标签:AI风险缓解, DuckDB, Kubernetes, 安全运营, 库, 应急响应, 异常检测, 扫描框架, 本地大模型, 请求拦截, 逆向工具