codedByBurhan/Atlas-SRE
GitHub: codedByBurhan/Atlas-SRE
一款零后端、隐私优先的纯客户端 RAG 问答助手,帮助 SRE 团队在事故响应中安全高效地检索和推理本地基础设施文档。
Stars: 0 | Forks: 0
# 🌐 ATLAS SRE
**AI 驱动的工程事件智能系统**
[]()
[]()
[]()
[]()
*通过一个零后端、隐私优先的 Copilot,缩短平均解决时间 (MTTR),助力事件响应、根因分析和架构探索。*
## 📑 目录
- [🛑 问题背景](#-the-problem)
- [💡 解决方案](#-the-solution)
- [✨ 核心模块与功能](#-core-modules--features)
- [🏗️ 技术架构](#-technical-architecture)
- [🚀 快速开始](#-getting-started)
- [🗺️ 路线图](#-blueprint-roadmap)
- [🤝 贡献指南](#-contributing)
- [📄 许可证](#-license)
## 🛑 问题背景
在严重的 Sev-1 级别事件中,**平均解决时间 (MTTR)** 决定了一切。站点可靠性工程师 (SRE) 和 DevOps 团队往往将宝贵的数分钟浪费在慌乱地翻阅零散的 PDF、历史复盘报告和过时的操作手册上。
虽然现有的 AI 解决方案试图解决这一问题,但它们却引入了巨大的风险:强制要求将高度敏感的基础设施文档、安全策略和专有架构图上传到第三方的中心化向量云中。这造成了严重的安全与合规瓶颈,使得它们实际上无法用于安全要求严格的企业级环境中。
## 💡 解决方案
**Atlas SRE** 引入了一种截然不同的事件智能处理方法。我们打造了一个完全自包含的 Web 应用程序,可以直接在您的浏览器中完整运行 **检索增强生成 (RAG)** 流水线。
Atlas SRE 在客户端本地解析和处理 PDF。我们仅利用 **Google Gemini 3.5 Flash/Pro API** 进行上下文感知生成,从根本上消除了对后端向量数据库的依赖。将文档保留在本地,即时解析查询,并在无需部署任何后端服务器的情况下安全地探索您的基础设施文档。
## ✨ 核心模块与功能
| 功能 | 描述 |
| :--- | :--- |
| 🛡️ **零后端本地 RAG** | 完全在浏览器中执行文档分块、**TF-IDF 词汇索引**和本地关键词重合度评分。彻底摆脱后端向量云,确保您的敏感数据严格保留在本地。 |
| 🤖 **AI 调查员 (事件 Copilot)** | 与由 **Gemini 3.5 Flash/Pro** 驱动的助手进行上下文感知综合对话。触发即时操作宏(例如 *“起草 RCA”*),并通过 **RAG 透明度日志**审计系统,该日志会公开检索评分、使用的文本块以及置信度估算。 |
| 📄 **交互式 PDF 引用引擎** | 渲染高保真 Canvas 元素并使用 `PDF.js` 提取局部文本。点击动态生成的引用标记,可直接锚定回原始文档中的特定页面。 |
| 📚 **知识库管理** | 安全地拖放敏感 PDF 以进行即时吸收。查看文本块和文档的实时指标,或加载预置的 18 份文档的 **演示知识库**(涵盖 SLO、服务中断等),以便立即进行测试和评估。 |
| 🗺️ **服务资源管理器** | 自动映射运维依赖关系。该资源管理器会解析已上传的架构文档,并使用 ASCII 风格的树状拓扑结构可视化服务(例如 Redis、PostgreSQL、Kafka)之间的关系。 |
| ⚙️ **系统设置配置** | 对实时的 LLM 参数进行细粒度控制。选择您首选的模型(**Gemini 3.5 Flash/Pro**),并根据需要调整 Retrieval Top-K 和 LLM Temperature。 |
## 🏗️ 技术架构
Atlas SRE 证明了您可以使用现代原生 Web 技术构建功能强大且安全的 AI 工具,同时将极致的运行速度、绝对的隐私性和部署的简便性放在首位。
### 🛠️ 技术栈
- **UI 与样式:** 使用 **Tailwind CSS** 和 **FontAwesome** 构建响应式、现代的毛玻璃拟态界面。
- **文档引擎:** 原生集成 **PDF.js**,处理二进制解析、文本层提取和高保真 Canvas 渲染。
- **检索逻辑:** 使用 **Vanilla JavaScript** 完全在内存中执行客户端 **TF-IDF 索引**、分块和词汇搜索。
- **LLM 集成:** 集成 **Google Gemini API**,严格基于检索到的本地上下文窗口提供高级推理、摘要提取和格式化。
- **格式化与安全:** 使用 `marked.js`、`DOMPurify` 和 `highlight.js` 安全地渲染 AI 生成的 Markdown,并提供语法高亮。
### 🔄 数据流
1. **吸收:** 通过 `PDF.js` Web Workers 在本地提取文本层。
2. **索引:** 对文本进行分块,并使用 **TF-IDF** 启发式算法在浏览器内存中对其进行数学索引。
3. **检索:** 评估本地关键词重合度,根据用户查询获取相关度最高的文档块。
4. **生成:** 将精确的文本块发送给 **Gemini 3.5 Flash/Pro**,以合成带有精确引用锚定的响应。
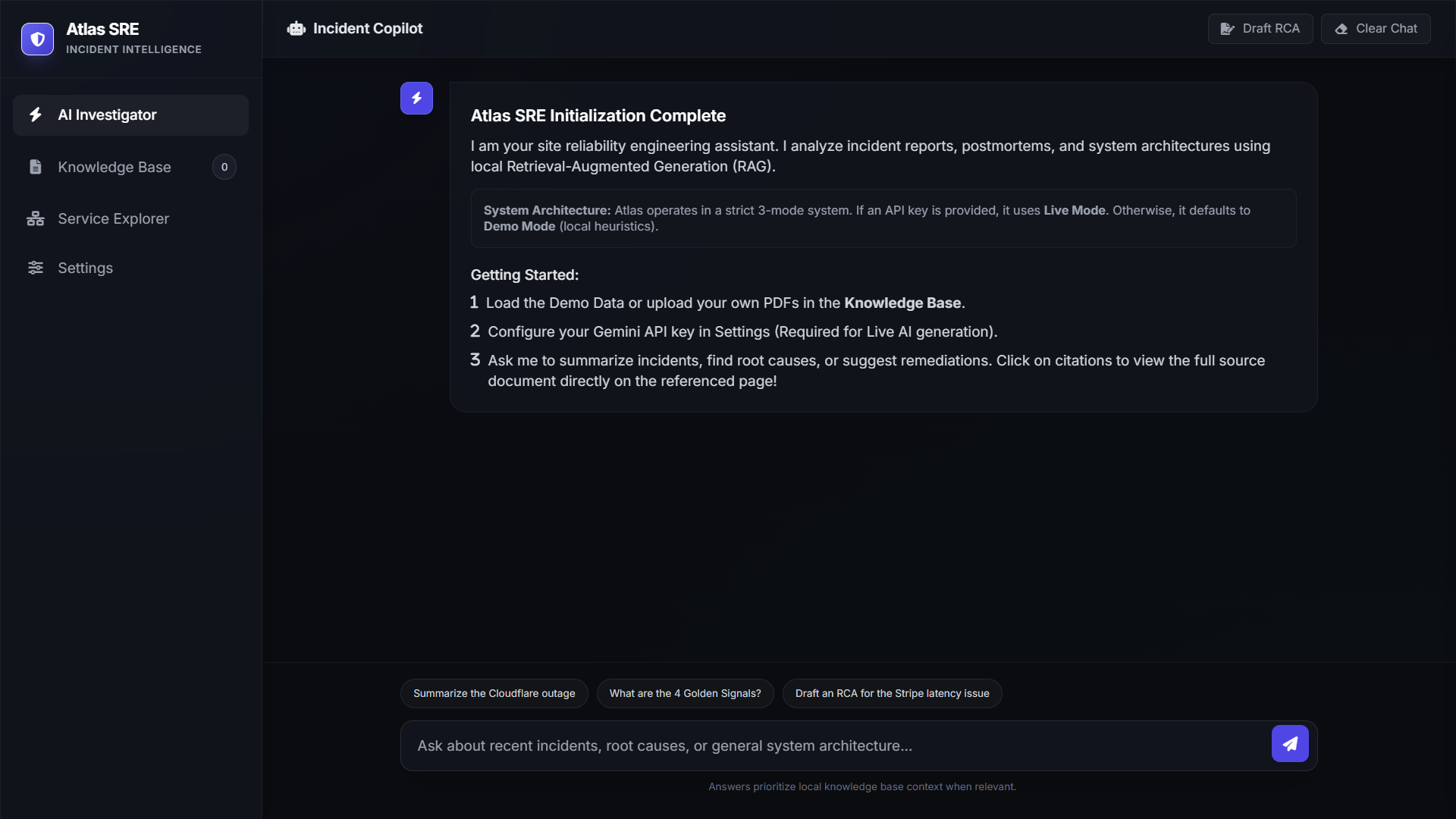
## 🚀 快速开始
我们设计 Atlas SRE 的初衷是让项目评审人员和工程师能够立即进行评估。您无需启动任何数据库,无需安装 Node 模块,也无需构建 Docker 容器。
### 前置条件
- 一款现代 Web 浏览器(Chrome、Edge、Firefox、Safari)。
- 一个免费的 [Google Gemini API Key](https://aistudio.google.com/app/apikey)。
### 1. 本地安装与启动
首先,将仓库克隆到您的本地计算机:
```
git clone https://github.com/yourusername/atlas-sre.git
cd atlas-sre
```
由于 `PDF.js` 使用 Web Workers 进行解析,您必须通过本地 Web 服务器提供文件,以绕过 CORS 限制。请选择以下方法之一:
- **Python:** 运行 `python -m http.server 8000`
- **Node.js:** 运行 `npx serve`
- **VS Code:** 右键点击 `index.html` 并选择 **Open with Live Server**。
在浏览器中访问 `http://localhost:8000` 即可启动应用程序。
### 2. 进入工作区并加载演示数据
1. 在落地页上,点击 **Enter Workspace**。
2. 注意屏幕顶部的全局 **Demo Mode** 横幅。
3. 点击 **Load Demo Knowledge Base**,即刻吸收包含 18 份 SRE 文档(SLO、过往中断记录、操作手册)的预打包数据集。
### 3. 配置 AI 引擎
1. 导航到左下角侧边栏的 **Settings**。
2. 粘贴您的 **Gemini API Key**。
3. 选择 **Gemini 3.5 Flash** 或 **Gemini 3.5 Pro**。
4. 如果需要,调整 Retrieval Top-K 和 Temperature,然后点击 **Save Configuration**。
### 4. 发出查询
打开 **AI Investigator** 聊天界面。尝试使用内置宏或提出复杂查询:
- *“基于最近的上下文,为缓存雪崩起草一份结构化的 SRE 无责任复盘报告。”*
- *“根据架构文档,支付网关的依赖链是什么?”*
观察 **RAG Transparency Log**,点击生成的 **Citation Chips**,即可在聊天旁边即时渲染相应的 PDF 页面。
## 🗺️ 路线图
- [ ] **IndexedDB 支持:** 将文档存储从易失性内存迁移到持久的浏览器存储中,以在不同会话之间保留 PDF。
- [ ] **语义 WebGL Embeddings:** 使用轻量级、基于浏览器的 embedding 模型(如 Transformers.js)在本地从词汇搜索升级为语义搜索。
- [ ] **自动化服务图谱生成:** 增强 Service Explorer,使用 D3.js 从文本上下文中动态绘制基于节点的架构图。
- [ ] **可导出工作区:** 允许团队将处理后的知识库作为单个加密的 JSON payload 下载,以便在实时事件期间安全地共享。
## 📄 许可证
基于 MIT 许可证分发。查看 `LICENSE` 了解更多信息。

由 codedByBurhan 用 🩦 构建
标签:AI助手, RAG, SRE, 偏差过滤, 前端计算, 后端开发, 数据可视化, 智能问答