kanitvural/aws-supply-chain-enterprise-demo
GitHub: kanitvural/aws-supply-chain-enterprise-demo
基于 Amazon Bedrock AgentCore 和 Strands Framework 构建的企业级供应链 AI 助手演示项目,通过 Agentic Workflow 跨七张数据表和企业知识库自动编排查询,解决供应链数据孤岛下的低效手动调查问题。
Stars: 2 | Forks: 0
# AWS 供应链企业级 AI 助手
[](https://aws.amazon.com/cdk/)
[](https://www.python.org/)
[](https://aws.amazon.com/bedrock/)
[](https://aws.amazon.com/)
[](https://modelcontextprotocol.io/)
[](https://aws.amazon.com/lambda/)
[](https://aws.amazon.com/dynamodb/)
[](https://developer.mozilla.org/en-US/docs/Web/JavaScript)

本项目展示了一个功能齐全的企业级供应链 AI 助手,由 **Amazon Bedrock AgentCore** 和 **Strands Framework** 驱动。它使用自变异的 AWS CDK CodePipeline,将整个基础设施安全且可扩展地部署到您的 AWS 环境中。
## 📦 这解决了什么业务问题?
全球供应链极其复杂。在传统企业中,数据高度孤岛化。当发生关键问题(例如,因零件缺陷导致生产线停工)时,供应链经理必须经历一场如同噩梦般的手动调查过程:
1. 登录 ERP 系统检查 **库存水平**。
2. 打开物流追踪门户查看 **货船/卡车** 的位置。
3. 检查质量控制数据库,确认 **收到的零件是否未通过检验**。
4. 交叉比对供应商数据库,查找 **联系信息和合规评级**。
5. 手动翻阅数百页的 **质量控制 PDF 手册**,找出处理缺陷产品的确切公司流程。
这个过程涉及手动查询 **7个不同的数据库/表** 并阅读大量文档,需要花费 **数小时甚至数天** 才能解决。
**这位 AI 助手充当了智能的“供应链副驾驶”。**
通过部署自主的 **Agentic Workflow**,这 7 个 DynamoDB 表(通过 4 个专门的 AWS Lambda Action Groups)以及企业手册(通过 OpenSearch 向量知识库)直接连接到了 AI 的大脑。
现在,经理只需输入:
AI 使用 **思维链** 推理,意识到它需要独立查询 Inspections API,然后是 Supplier API,最后在知识库中运行语义搜索。它综合所有这些数据,并在 **短短几秒钟内** 提供完美、可操作的答案。
### 🌟 超越效率:解决企业 IT 的核心挑战
虽然运营效率是可见的成果,但在企业环境中部署 AI 带来了巨大的 IT 障碍。此架构专门设计用于解决最关键的企业级关注点:
**🛡️ 1. 国防级数据隐私与安全**
企业数据隐私是不可妥协的底线。此架构保证您的专有公司数据永远不会泄露到公共互联网。整个 AI agent 生态系统在高度安全的闭环 **私有网络 (VPC)** 内运行,利用了 AWS PrivateLink。
此外,每个组件(Orchestrator、知识库和 4 个专门的 Tools)都在严格的隔离环境中运行。agent 只能通过获取由 Amazon Cognito 颁发的临时 **JWT Tokens** 来与您的数据库交互,确保永远不会执行未经授权的操作。
**📈 2. 无限且自动化的扩展能力**
传统的企业系统在突发的流量高峰下会崩溃。由于此架构是完全解耦和事件驱动的,它可以自动进行水平扩展。在全球供应链危机期间,无论是有 10 名还是 10,000 名经理同时查询 AI,系统都能毫不费力地吸收负载,无需人工干预。
**⚡ 3. 超低延迟的知识检索**
知识库 Agent 的能力仅取决于其检索速度。查询庞大的企业向量数据库传统上会导致令人沮丧的瓶颈。通过利用 **Amazon OpenSearch Serverless**,此架构保证了亚毫秒级的搜索延迟。即使在筛选数 GB 的密集质量控制手册时,AI 也能在一眨眼的时间内检索出精确的语义向量上下文。
**💰 4. 零闲置成本 (100% Serverless)**
传统的 AI 基础设施需要预置昂贵且始终保持运行的服务器 (EC2/ECS),即使没有人在使用它们,也会消耗 IT 预算。此解决方案建立在纯粹的 **Serverless 架构** 之上。当您的经理们下班且系统闲置时,您的计算成本将降至 **绝对零**。您只需为活跃查询期间使用的精确毫秒数的计算付费,从而带来巨大的成本优势。
## 🛠️ AWS 架构与使用的服务
本项目实现了一个完全托管、可扩展且安全的架构,利用了以下核心 AWS 服务:
- **Amazon Bedrock (AgentCore):** 助手的大脑。使用基础模型 进行推理、多步规划 (Chain of Thought),并执行 Agentic workflows。
- **Amazon OpenSearch Serverless:** 高性能向量数据库,存储企业手册的 embeddings,支持检索增强生成 (RAG),并提供亚毫秒级的搜索延迟。
- **AWS Lambda:** 用于 Agent Action Groups(库存、物流、质量控制和供应链)和自定义 CloudFormation Resources 的 Serverless 计算。
- **Amazon DynamoDB:** 高度可扩展的 NoSQL 数据库,托管 7 个不同的表(Inventory、Shipments、Inspections、Suppliers 等),模拟企业数据湖。
- **Amazon Cognito:** 通过处理用户身份验证、授权和 JWT token 管理,保护 Web UI 的安全。
- **Amazon API Gateway:** 通过安全、RESTful 的 HTTP API endpoint 将 Bedrock Agent 暴露给前端。
- **Amazon S3 & CloudFront:** 托管 Vanilla JS 前端应用程序,并作为知识库文档的原始存储层。
- **Amazon VPC (PrivateLink & NAT Gateway):** 确保企业级安全,将所有 AI 推理、数据库查询和服务间通信与公共互联网完全隔离。
- **AWS CodePipeline & CodeBuild:** 提供全自动、自变异的 CI/CD pipeline,在 git 提交时无缝部署基础设施更新并构建 Docker 镜像。
- **Amazon ECR (Elastic Container Registry):** 安全地存储和管理 AgentCore 环境所需的 Docker 容器镜像。
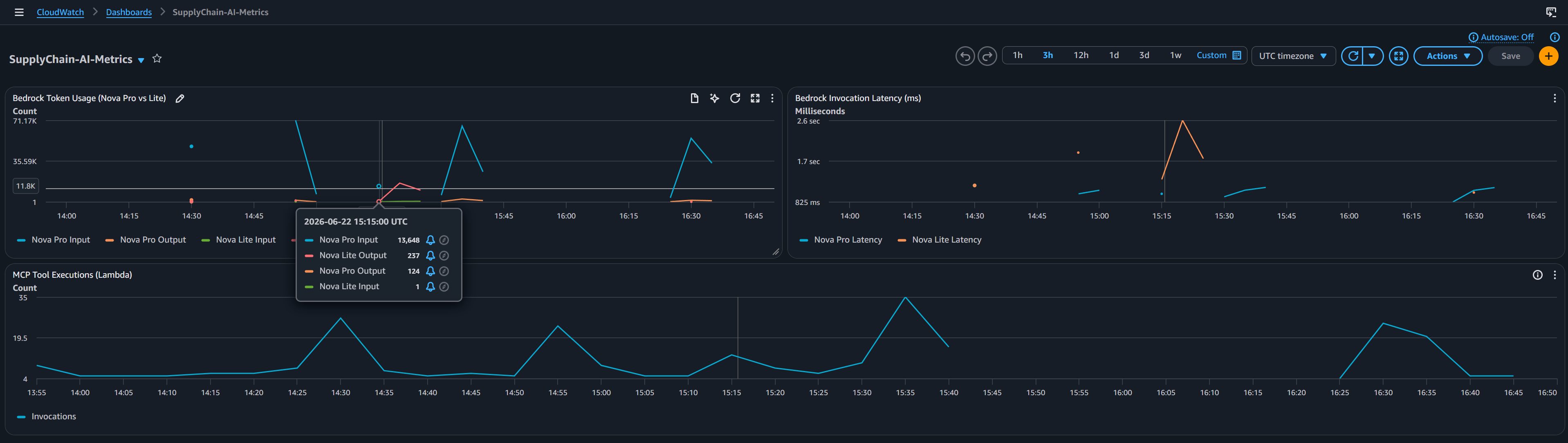
- **Amazon CloudWatch:** 通过自定义仪表板、指标跟踪和针对整个架构的集中日志管理,提供全面的可观测性。
- **Amazon EventBridge & SNS:** 编排事件驱动的 workflows,并为关键的供应链警报(例如,未通过质量检验)提供解耦的即时通知。
- **AWS CDK (Cloud Development Kit):** 使用 Python 将整个基础设施定义为代码,确保可复现的部署。
## 🏗️ 深度解析:技术企业级特性
除了高层次的业务优势之外,此架构还包含一套专门为世界 500 强工程和安全团队设计的深度技术特性:
* **私有网络 (VPC & PrivateLink)**: AI agents 在严格受控的虚拟私有云 (VPC) 中运行。它们使用 AWS PrivateLink (VPC Interface Endpoints) 与 Amazon Bedrock、CloudWatch 和 S3 进行通信。这意味着 **数据绝不会通过公共互联网传输**,从而使其免受外部威胁。
* **100% 数据隐私与模型选择**: 由于系统建立在 Amazon Bedrock 之上,企业数据绝对不会被用于训练基础模型。虽然默认使用 Amazon Nova,但该架构原生支持 Anthropic 的 **Claude** 系列。得益于 AWS 安全的基础设施,使用 Claude 模型不需要通过互联网将数据发送到第三方 API;一切都在您的私有 AWS 边界内安全执行。
* **M2M 身份验证**: 聊天应用程序使用带有 Machine-to-Machine (M2M) `client_credentials` 流程的 Amazon Cognito。组件之间的每个请求都通过具有严格 `supplychain/read` 和 `supplychain/write` scope 的 JWT tokens 进行验证。
* **MCP (Model Context Protocol) Gateway**: 与其赋予 AI 对数据库直接、不受限制的访问权限,不如将所有 AI 工具请求通过 **AgentCore Gateway** 进行路由。Gateway 会根据严格的 JSON schema 验证 AI 的请求,然后再触发隔离的 Lambda 函数。
* **语言无关的 微服务**: 与将您锁定在 Python 生态系统中(依赖 Pydantic 或 LangChain 等库进行验证)的传统 AI 框架不同,该架构完全与语言无关。由于 AgentCore Gateway 原生使用开放标准 JSON Schemas 强制执行结构化输出,您的企业工具处理器可以用 **Go、Rust、Java 或 C++** 编写。AI 系统毫不费力地与任何后端集成,而无需强迫您的工程团队采用 Python。
* **数据保护**: 实施了 Amazon Bedrock Guardrails 以防止数据泄露。它会自动阻止不当内容,屏蔽 PII(如密码),并匿名化敏感的企业数据(如内部折扣代码)。它甚至严格禁止提及机密的内部项目。
* **Agentic Memory**: 系统使用 AgentCore Memory namespaces 来区分用户偏好、事实语义记忆和会话摘要,这意味着 AI 可以在多次会话中记住上下文。
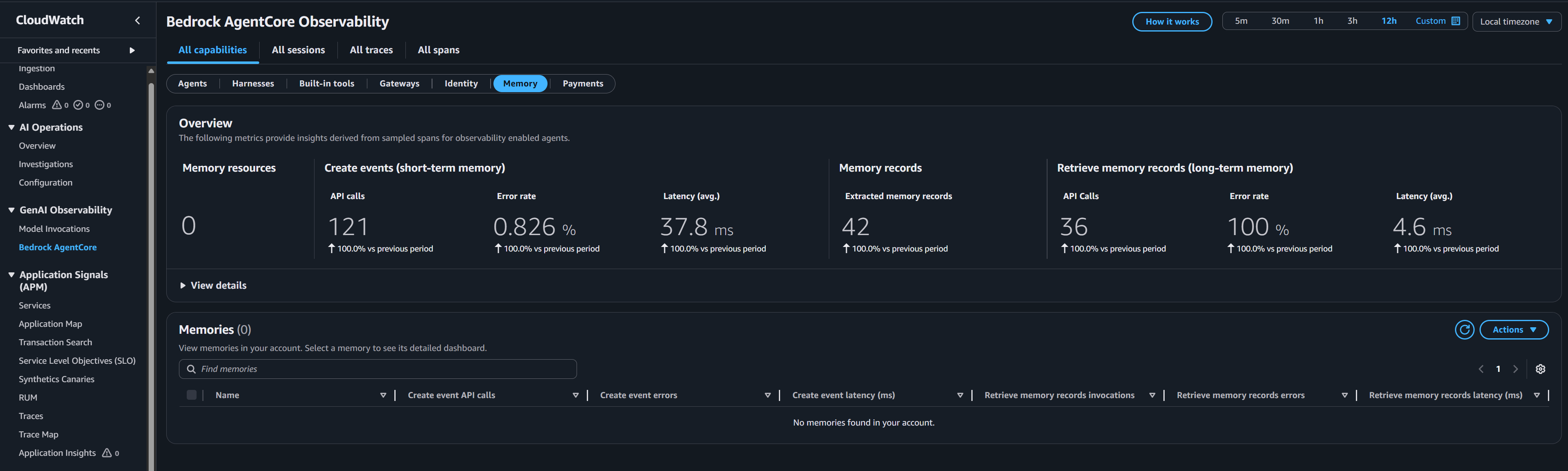 * **无限可扩展性**: 多亏了 Amazon Bedrock AgentCore、API Gateway 和 AWS Lambda,整个计算层是 100% Serverless 的。无论是有 10 名用户还是 10,000 名用户同时提问,系统都会瞬间扩展,不会出现任何基础设施瓶颈,并在闲置时将规模缩减至零。 * **Serverless 且安全的前端**: 聊天 UI 作为静态网站托管在 Amazon S3 上,并通过 Amazon CloudFront 进行全球分发。这是目前性价比最高且可扩展性最强的前端架构——没有正在运行的 EC2 Web 服务器需要维护或付费。源访问控制 确保该 S3 存储桶完全被公共互联网屏蔽,并且只能通过安全的 CloudFront CDN 访问。 * **全面的可观测性与可审计性**: 企业系统需要严格的审计。AgentCore 与 AWS CloudWatch 完全集成。AI 调用的每个工具、它读取的每个数据库响应以及其内部的“思维链”推理都会被记录下来。如果 AI 做出了决策,管理员可以准确追踪它 *为什么* 以及 *如何* 得出该结论的。
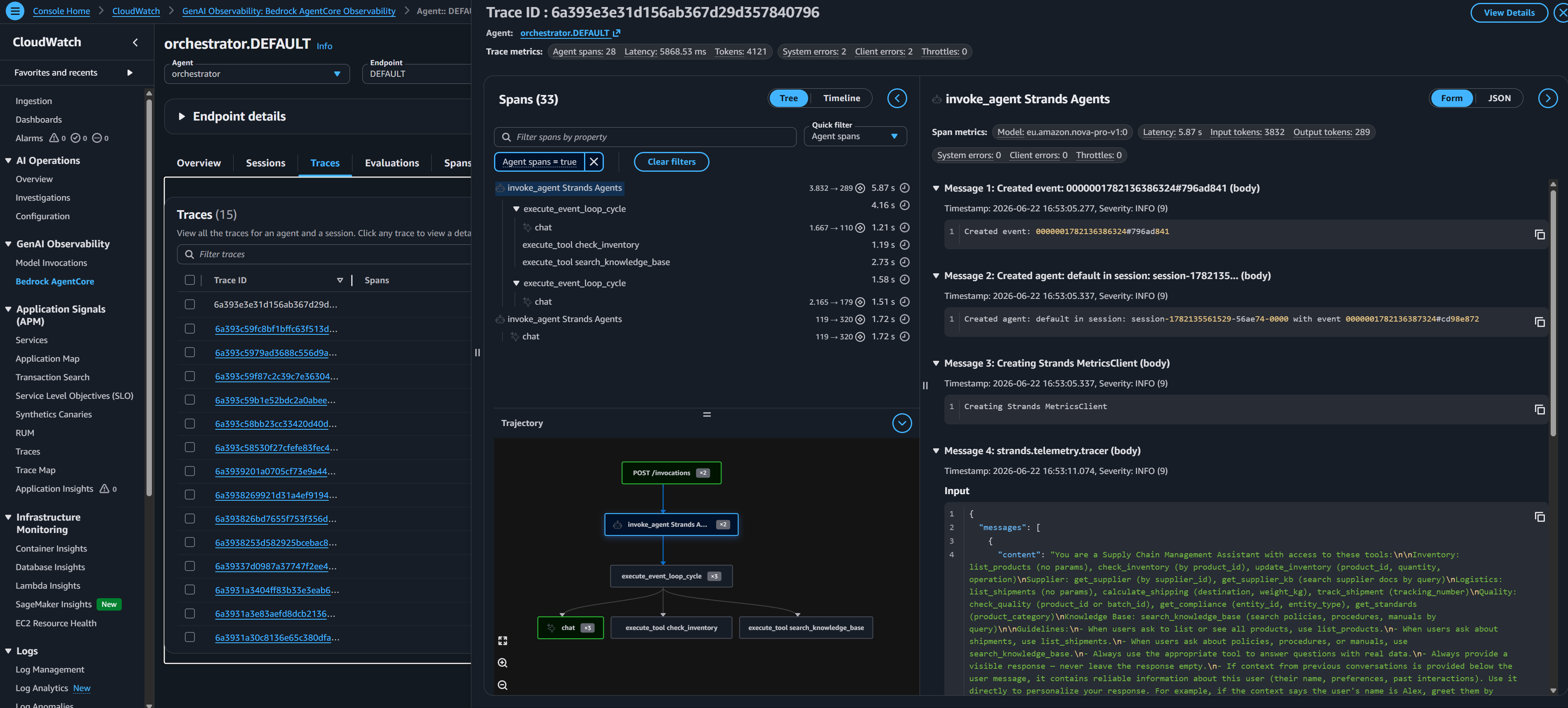 * **LLMOps 与持续评估** 该架构包含一个自动化的 LLMOps pipeline。EventBridge 定时任务每周触发一次 Lambda 函数,该函数会启动 **自动化的 Amazon Bedrock Evaluation Job**。目前,它会根据 `rag_golden.jsonl` 数据集评估 **Knowledge Base Specialist (Nova Lite)**,以测试其语义理解能力和 RAG 能力(对准确性和鲁棒性进行评分)。
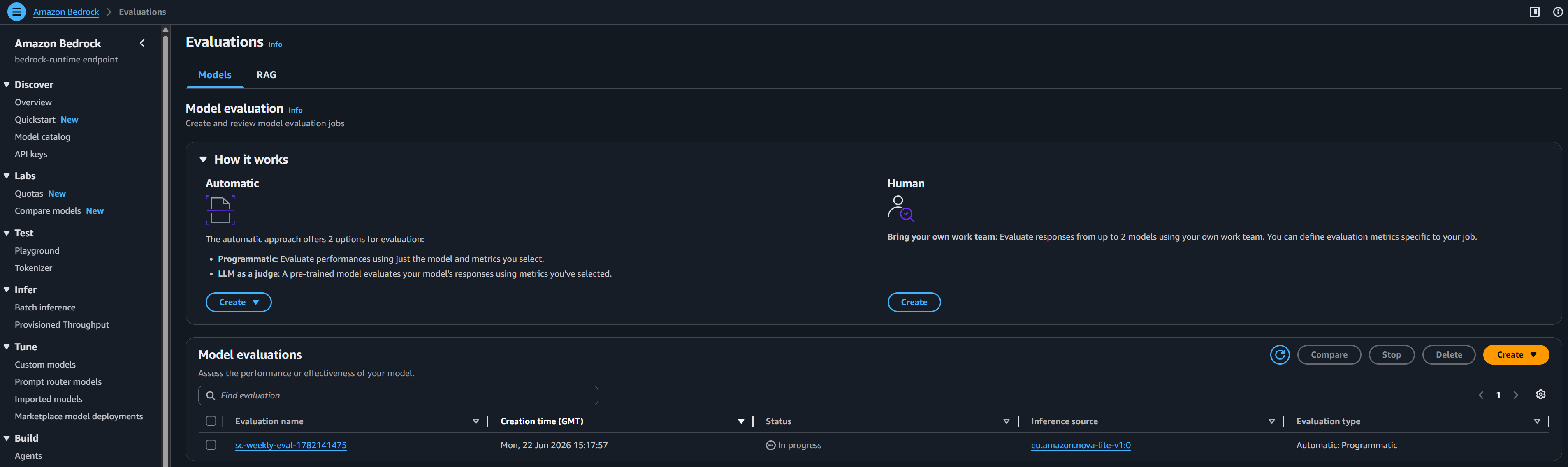 * **自变异 CI/CD Pipeline**: 一切都被定义为基础设施即代码。系统在每次 GitHub 提交时通过 CodePipeline 自动测试并部署自身。 ## 🧱 基础设施即代码 Stack 该项目由通过 CodePipeline 顺序部署的 11 个 CDK stack 组成: 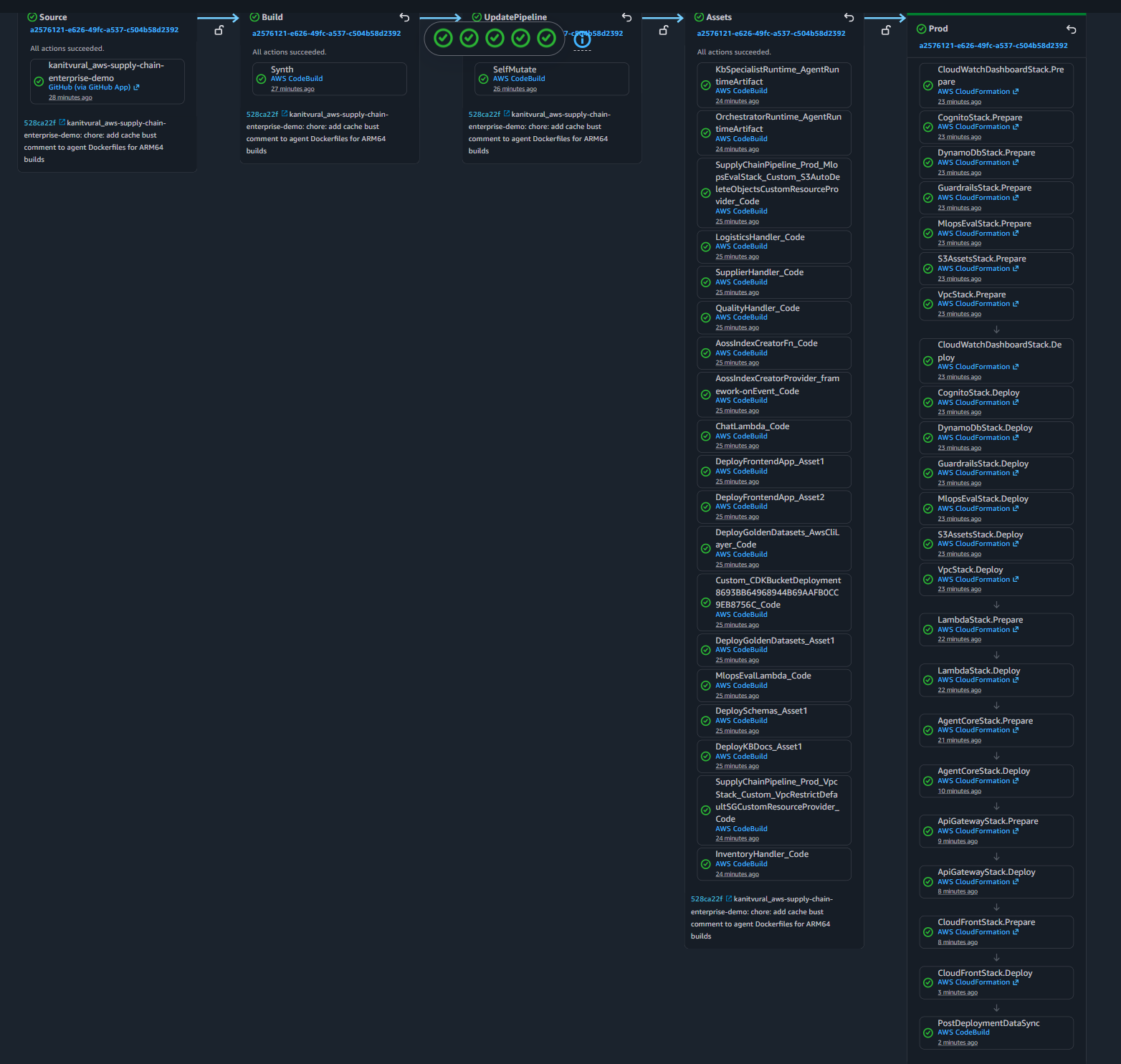 1. **VPC Stack**: 公有和私有 subnet、NAT Gateway 以及所需的 VPC Endpoints。 2. **DynamoDB Stack**: 包含 Inventory、Shipments、Routes、Suppliers、Inspections、Compliance 和 Standards 的 7 个表。 3. **S3 Assets Stack**: 用于存放 Open API schema 和知识库文本文档的 S3 存储桶。 4. **Cognito Stack**: 具有 M2M `client_credentials` 流程的 User Pool,用于 API Gateway 到 Agent 的身份验证。 5. **Guardrails Stack**: 用于 PII 过滤、正则表达式屏蔽和脏话拦截的 Amazon Bedrock Guardrail。 6. **Lambda Stack**: 5 个 AWS Lambda 函数(1 个聊天 API 处理程序 + 4 个用于 Agent MCP 工具的 Domain 处理程序)。 7. **API Gateway Stack**: 将 endpoints 暴露给前端的 REST API。 8. **CloudFront Stack**: 具有源访问控制 的安全前端交付。 9. **AgentCore Stack**: OpenSearch Serverless collection、Knowledge Base、Memory、Gateway 以及 2 个容器化的 AgentCore Runtimes (Orchestrator 和 KB Specialist)。 10. **CloudWatch Dashboard Stack**: 用于追踪 AI token 消耗、API 延迟和 Lambda 工具执行指标的自定义可观测性仪表板。 11. **MLOps Eval Stack**: S3 数据湖、EventBridge 定时任务、SNS 警报以及用于使用 Golden Datasets 每周自动进行 Bedrock 模型评估的 Lambda 函数。 ## 📂 项目结构概述 ``` 📦 aws-supply-chain-enterprise-demo/ ├── 📁 agent_core/ # Strands Framework Agents (Orchestrator, KB Specialist) ├── 📁 app/ # Frontend Chat UI (Static HTML/CSS/JS) ├── 📁 cdk_pipeline/ # Self-mutating CI/CD CodePipeline definition ├── 📁 lambda_funcs/ # MCP Tool Handlers & MLOps Evaluation Lambdas ├── 📁 scripts/ # Utility scripts (Mock data loader, URL fetcher) ├── 📁 stacks/ # 11 AWS CDK Infrastructure definitions ├── 📄 app.py # CDK app entry point ├── 📄 cdk.json # CDK configuration ├── 📄 Makefile # Deployment commands ├── 📄 run.sh # Deployment bash scripts ├── 📄 requirements.txt # Python dependencies └── 📄 README.md # Documentation ``` ## 🧠 多 Agent 系统与工具 这款助手的核心是 **多 Agent 架构**,它将复杂的 workflows 拆分给专门的 AI 模型,以在成本和推理能力之间取得最佳平衡。 ### Orchestrator Agent (Amazon Nova Pro) Orchestrator 是系统的“大脑”。它直接与用户对话,理解意图,规划回答问题所需的步骤,并将请求路由到正确的工具。 * **为什么选择 Nova Pro?** 因为要协调多个工具、推理复杂的供应链问题(例如,“如果货物 X 延误了,我替代方案?”),并保持对话记忆,需要一个具备高级推理和规划技能的、高度 capable 的顶级基础模型。 ### 2. MCP 工具与 Lambda 处理程序 当 Orchestrator 需要真实世界的数据时,它无法直接查询数据库。它使用由 Model Context Protocol (MCP) Gateway 定义的工具。每个工具都会触发一个特定的 AWS Lambda 函数,该函数随后会安全地查询其指定的 DynamoDB 表: * **Inventory Tool** ➡️ `Inventory Lambda` ➡️ 查询 `sc-inventory` * **Logistics Tool** ➡️ `Logistics Lambda` ➡️ 查询 `sc-shipments` 和 `sc-routes` * **Supplier Tool** ➡️ `Supplier Lambda` ➡️ 查询 `sc-suppliers` * **Quality Tool** ➡️ `Quality Lambda` ➡️ 查询 `sc-inspections`、`sc-compliance` 和 `sc-standards` * 🛡️ **安全性与严格隔离:** AI Agents 和 Tools 在完全独立、隔离的环境中运行。Orchestrator Agent 对您的 DynamoDB 表拥有 **零直接访问权限**。它只能通过安全的 Gateway 与隔离的 Lambda 函数通信,严格强制执行最小权限原则。 ### Knowledge Base Specialist Agent (Amazon Nova Lite) 当用户询问有关公司政策、合同或程序指南(它们不在数据库中,而是存在于 PDF/文本文档中)的问题时,Orchestrator 会将任务委托给 **KB Specialist Agent**。此 agent 使用检索增强生成 (RAG) 来搜索包含从 S3 同步的手册的 **Amazon OpenSearch Serverless** 向量数据库。 * **为什么选择 Nova Lite?** Specialist Agent 只有一项专注的工作:阅读检索到的文本块并准确地进行总结。它不需要做复杂的工具路由。Nova Lite 速度极快且极具成本效益,使其成为高速、直接阅读和总结任务的完美模型。 ## 🗄️ DynamoDB 表 该项目部署了 7 个 DynamoDB 表,作为 AI 助手的唯一事实来源。在现实世界的企业中,这些表将通过流式传输来自 ERP 系统(例如 SAP)、仓库管理系统 (WMS) 和航运集装箱上的 IoT 传感器的数据来持续更新。 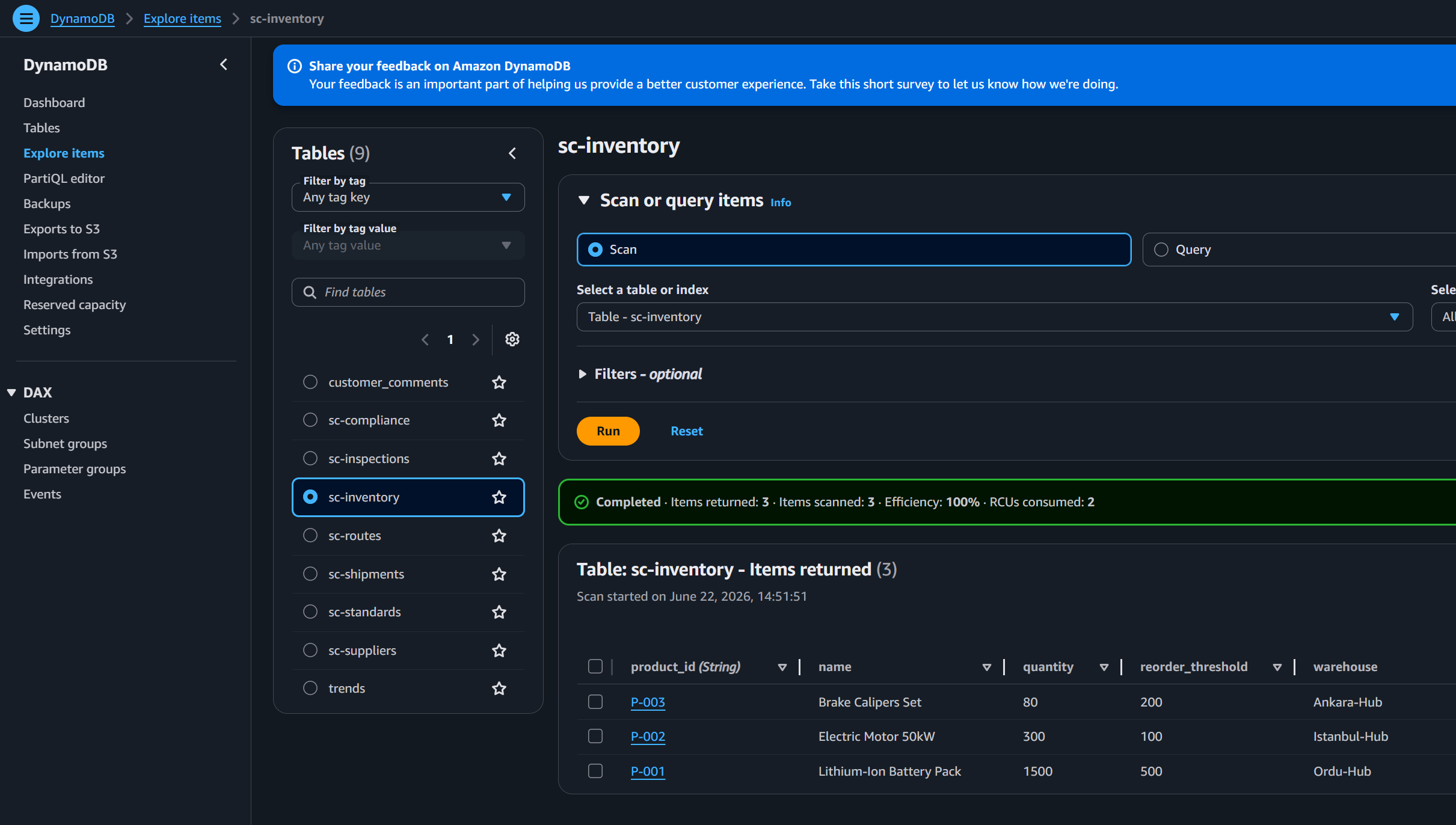 1. **`sc-inventory`**: 追踪产品库存、仓库位置和重新订购阈值。 2. **`sc-shipments`**: 包含活动的追踪号、预计到达时间 (ETA) 和承运人状态。 3. **`sc-routes`**: 映射物流路线、距离和当前状况(例如,天气延误)。 4. **`sc-suppliers`**: 包含供应商资料、层级评级和联系信息。 5. **`sc-inspections`**: 存储特定产品批次的质量控制报告(通过/未通过)。 6. **`sc-compliance`**: 追踪环境和制造认证(例如,ISO-9001、CE、RoHS)。 7. **`sc-standards`**: 定义严格的企业阈值和规则(例如,电机可接受的最大噪音水平)。 ## 📚 知识库与向量存储 虽然 DynamoDB 负责处理结构化的实时指标,但供应链同时还受制于数千页的非结构化文档。为了处理这些文档,构建了一个高度可扩展的检索增强生成 (RAG) pipeline: ### 1. 数据湖 * **企业手册**: 详细说明质量审计、退货政策和供应商规则的 PDF、文本文件和指南。 * **OpenAPI Schemas**: AgentCore Gateway 用来验证 AI 工具请求的严格 JSON schemas。 ### 2. 向量数据库 每当文档上传到 S3 时,它就会自动被分块,并使用 **Amazon Titan Text Embeddings** 模型转换为向量 embeddings。这些向量被存储在一个 **Amazon OpenSearch Serverless** collection 中。 **为什么选择 OpenSearch Serverless?** * **混合搜索 (向量 + 精确关键字):** 在搜索精确的企业零件号、SKU 或首字母缩略词时,仅靠语义搜索通常会失败。OpenSearch 原生支持 **混合搜索**,将向量相似性与传统的关键字匹配 (BM25) 结合在一起,从而大幅提高 RAG 的准确性。 * **大规模的复杂元数据过滤:** 虽然基础的向量存储(如 S3)支持元数据,但 OpenSearch 是一个专用的搜索引擎,旨在跨海量数据集瞬间执行复杂的元数据预过滤(例如,*“仅搜索标记为 '2023' AND 'Europe' OR 'Approved' 的文档”*),而不会出现性能下降。 * **亚毫秒级延迟(需额外付费):** OpenSearch 专为必须在一瞬间返回搜索结果的企业级用例而设计。如果超低延迟是一项严格要求,这就是黄金标准。 * **对比预置集群更具成本效益:** 尽管 OpenSearch 的基础成本很高(约 350 美元/月),但对于不可预测的、突发性的 AI 流量来说,*Serverless* 变体仍然比运行传统的 24/7 专用 OpenSearch 集群便宜得多。您不必为极端的过度预置付费。 * **原生 Bedrock 集成**: 它作为 Amazon Bedrock Knowledge Bases 的无缝、完全托管的向量存储后端。 ## 💰 企业成本估算(每月) 此架构主要基于 **Serverless**(按需付费)模式,使其对于内部企业用例极具成本效益。以下是基于标准 AWS eu-central-1 (Frankfurt) 定价的现实每月成本估算。 **假设与场景:** - **用户与流量:** 100 名每日活跃用户(供应链规划师和经理)每天产生 **1,000 个请求**(约 30,000 个请求/月)。 - **存储:** Amazon S3 中 **1 TB**(文档、PDF、日志),DynamoDB 中 **5 GB**(供应链业务数据)。 - **向量数据库:** Amazon OpenSearch Serverless 中 **10 GB** 的向量 embeddings。 - **AI 模型:** 使用 Amazon Bedrock 进行混合交互路由(例如,简单任务使用 Nova Lite,复杂推理使用 Nova Pro),由 AgentCore 管理。 | AWS 服务 | 成本因素与估算 | 预估每月成本 | |-------------|-------------------------|----------------------:| | **Amazon OpenSearch Serverless** | 4 个 half-OCUs(冗余/多可用区部署)。
*注意:每天 1000 个请求完全在基准范围内。如果您的 10 GB 全是向量 embeddings,它可能会自动扩容。* | **~$350.00** | | **Amazon Bedrock (Nova Models)** | **按需付费:** 每月约 60M 输入 Tokens,15M 输出 Tokens。
Nova Lite(输入 $0.078 / 输出 $0.312)和 Nova Pro(输入 $1.05 / 输出 $4.20)各占 50% 的混合使用量。 | **~$68.00** | | **Amazon S3** | 1 TB 标准存储 + 中等的 GET/PUT 请求量。 | **~$25.00** | | **Amazon DynamoDB** | 5 GB 存储 ($0.306/GB) + 按需读/写(约 3 万次请求 = 可忽略不计)。 | **~$1.54** | | **AWS Lambda** | 30,000 次执行(约 60k GB-秒)。$0.20/1M 次请求 + $0.0000166667/GB-s | **~$1.01** | | **Amazon AgentCore** | 每月 30,000 个会话的 Serverless 消耗定价:
• **Runtime 计算:** $21.71 (1vCPU/2GB,60秒会话,70% I/O 等待)
• **Gateway API:** $1.20 (搜索与工具调用)
• **Memory:** $45.00 (存储、事件与检索)
• **评估与 Guardrails:** $2.25 | **~$70.16** | | **Amazon API Gateway** | 通过 HTTP API 发出的 30,000 个请求(每百万请求 $1.20)。 | **~$0.04** | | **Amazon CloudWatch** | 自定义仪表板 ($3.00) + 约 1 GB 日志摄取 ($0.63/GB)。 | **~$3.63** | | **Amazon CloudFront** | 内部 UI 托管。约 10 GB 数据传出 ($0.085/GB)。 | **~$0.85** | | **Amazon VPC Network** | 1 个 NAT Gateway ($37.96) + 跨 2 个可用区的 7 个 Interface Endpoints ($121.61) + 数据处理费。 | **~$159.93** | | **预估总成本** | | **~$680.16** | ## 🚀 部署说明 在部署此项目之前,请确保您的本地环境和 AWS 账户满足以下要求: ### 0. 前置条件 **本地环境:** * **Node.js (v18+)**: AWS CDK 所必需的。([下载 Node.js](https://nodejs.org/)) * **AWS CLI (v2)**: 与您的 AWS 账户进行交互所必需的。([安装 AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html)) * **Python (3.11+)**: CDK 部署脚本和 Lambda 函数所必需的。 * **Git**: 进行版本控制并拉取代码仓库所必需的。 * **AWS CDK**: 在您的终端中运行 `npm install -g aws-cdk` 全局安装 AWS Cloud Development Kit。 **AWS 账户设置:** * **IAM User/Role**: 您必须拥有一个具有 `AdministratorAccess` 的 IAM User 或 Role(或具有创建 VPC、IAM Roles、Lambda 函数、Bedrock 模型和 OpenSearch 集群的足够权限)。 * **AWS CLI 配置**: 通过在终端运行 `aws configure` 并提供您的 Access Key ID 和 Secret Access Key,使用您的 AWS 凭证配置本地计算机。 * **Amazon Bedrock 模型访问权限**: 在部署之前,您**必须**在 AWS Bedrock 控制台中手动申请访问 Amazon Nova 模型(Nova Pro 和 Nova Lite)以及 Titan Text Embeddings V2,否则部署将会失败。 ### 1. 设置您自己的 GitHub 仓库与环境 由于 AWS CodePipeline 需要访问源代码,您必须将此代码推送到您自己的 GitHub 账户: 1. **Fork** 此仓库或将其克隆,并推送到您 GitHub 账户上的一个新私有/公共仓库中。 2. 在本地克隆您的仓库并设置您的 Python 虚拟环境: ``` git clone https://github.com//.git
cd
# 创建虚拟环境
python3 -m venv .venv # Use 'python -m venv .venv' on Windows
# 在 Mac/Linux 上激活:
source .venv/bin/activate
# 在 Windows (Command Prompt) 上激活:
.venv\Scripts\activate
# 安装必需的依赖项
pip install -r requirements.txt
npm install -g aws-cdk
```
### 2. 为 GitHub 配置 AWS CodeStar Connection
该 pipeline 直接从 GitHub 拉取源代码。您必须配置一个 AWS CodeStar Connection:
1. 进入 **AWS 控制台** -> **Developer Tools** -> **Settings** -> **Connections**。
2. 点击 **Create connection**,选择 **GitHub**,并按照提示为 GitHub 授权 AWS Connector。
3. 确保授予对 **您的仓库**(例如,``)的访问权限。
4. 复制新创建的 **Connection ARN**。
5. 打开项目根目录下的 `cdk.json`。在 `"context"` JSON 块中,更新以下属性以匹配您的设置:
"context": {
"githubConnectionArn": "arn:aws:codeconnections:eu-central-1:123456789012:connection/...",
"githubRepo": "/",
"githubBranch": "main"
}
### 3. 引导您的 AWS 环境
您只需为您的账户/区域组合执行一次此操作。这将配置初始的 CDK 资源:
```
make bootstrap
```
### 4. 部署 Pipeline(零接触部署)
部署 pipeline stack。部署完成后,自变异 CodePipeline 将接管并自动执行以下操作:
1. 从 GitHub 拉取最新代码。
2. 部署剩余的 10 个基础设施 stack。
3. 自动将模拟数据加载到 7 个 DynamoDB 表中。
4. 自动将 S3 知识库文档同步到 OpenSearch Serverless 中。
```
make deploy
```
### 5. 获取在线应用 URL
部署完成后,您可以通过运行以下命令轻松获取在线应用程序的 URL:
```
python scripts/get_app_url.py
```
## 🎯 测试 AI 助手(示例提示词)
部署完成并打开前端 UI 后,尝试询问这些示例问题,以全面测试各种 Lambda Action Groups、DynamoDB 表、RAG 系统以及安全 Guardrails:
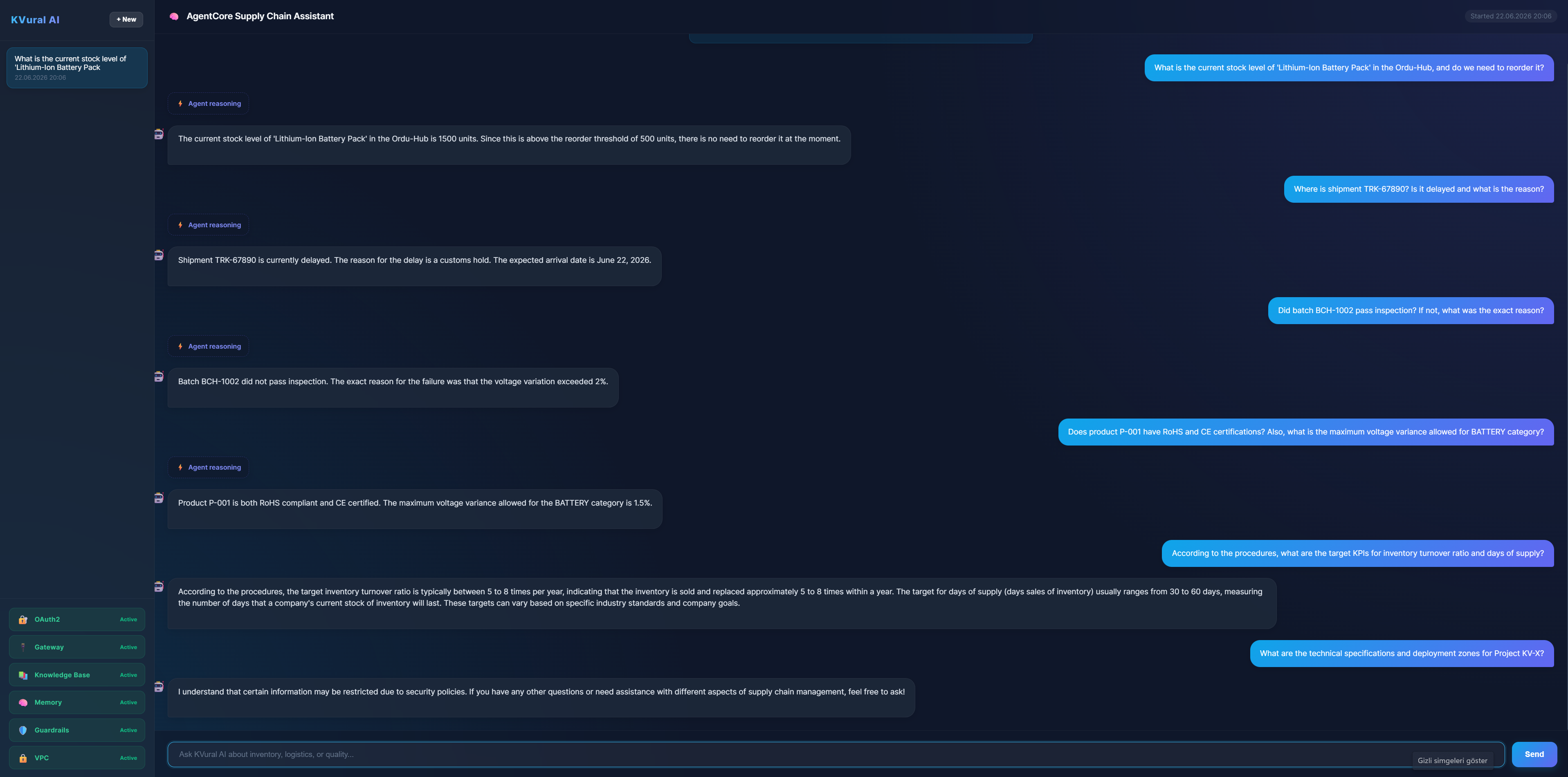
**📦 1. Inventory Lambda (`sc-inventory` 表):**
**🚚 2. Logistics Lambda - Shipments (`sc-shipments` 表):**
**🔍 3. Quality Lambda - Inspections (`sc-inspections` 表):**
**✅ 4. Quality Lambda - Compliance & Standards (`sc-compliance`, `sc-standards` 表):**
**📚 5. Knowledge Base / RAG (`inventory_procedures.txt` & `quality_control_manual.txt`):**
**🛡️ 6. AI & Guardrails (内容过滤):**
## 🗑️ 销毁基础设施(对于避免账单很重要!)
要彻底移除该项目并停止所有计费,只需在项目根目录下运行以下命令:
```
make destroy
```
此自动化脚本将:
1. 删除所有 `Prod-*` 应用程序 stack。
2. 自动清空 S3 存储桶(Pipeline artifacts 和 CDK Toolkit)。
3. 销毁 CDK Pipeline 和 Bootstrap stack。
 * **无限可扩展性**: 多亏了 Amazon Bedrock AgentCore、API Gateway 和 AWS Lambda,整个计算层是 100% Serverless 的。无论是有 10 名用户还是 10,000 名用户同时提问,系统都会瞬间扩展,不会出现任何基础设施瓶颈,并在闲置时将规模缩减至零。 * **Serverless 且安全的前端**: 聊天 UI 作为静态网站托管在 Amazon S3 上,并通过 Amazon CloudFront 进行全球分发。这是目前性价比最高且可扩展性最强的前端架构——没有正在运行的 EC2 Web 服务器需要维护或付费。源访问控制 确保该 S3 存储桶完全被公共互联网屏蔽,并且只能通过安全的 CloudFront CDN 访问。 * **全面的可观测性与可审计性**: 企业系统需要严格的审计。AgentCore 与 AWS CloudWatch 完全集成。AI 调用的每个工具、它读取的每个数据库响应以及其内部的“思维链”推理都会被记录下来。如果 AI 做出了决策,管理员可以准确追踪它 *为什么* 以及 *如何* 得出该结论的。

 * **LLMOps 与持续评估** 该架构包含一个自动化的 LLMOps pipeline。EventBridge 定时任务每周触发一次 Lambda 函数,该函数会启动 **自动化的 Amazon Bedrock Evaluation Job**。目前,它会根据 `rag_golden.jsonl` 数据集评估 **Knowledge Base Specialist (Nova Lite)**,以测试其语义理解能力和 RAG 能力(对准确性和鲁棒性进行评分)。
 * **自变异 CI/CD Pipeline**: 一切都被定义为基础设施即代码。系统在每次 GitHub 提交时通过 CodePipeline 自动测试并部署自身。 ## 🧱 基础设施即代码 Stack 该项目由通过 CodePipeline 顺序部署的 11 个 CDK stack 组成:  1. **VPC Stack**: 公有和私有 subnet、NAT Gateway 以及所需的 VPC Endpoints。 2. **DynamoDB Stack**: 包含 Inventory、Shipments、Routes、Suppliers、Inspections、Compliance 和 Standards 的 7 个表。 3. **S3 Assets Stack**: 用于存放 Open API schema 和知识库文本文档的 S3 存储桶。 4. **Cognito Stack**: 具有 M2M `client_credentials` 流程的 User Pool,用于 API Gateway 到 Agent 的身份验证。 5. **Guardrails Stack**: 用于 PII 过滤、正则表达式屏蔽和脏话拦截的 Amazon Bedrock Guardrail。 6. **Lambda Stack**: 5 个 AWS Lambda 函数(1 个聊天 API 处理程序 + 4 个用于 Agent MCP 工具的 Domain 处理程序)。 7. **API Gateway Stack**: 将 endpoints 暴露给前端的 REST API。 8. **CloudFront Stack**: 具有源访问控制 的安全前端交付。 9. **AgentCore Stack**: OpenSearch Serverless collection、Knowledge Base、Memory、Gateway 以及 2 个容器化的 AgentCore Runtimes (Orchestrator 和 KB Specialist)。 10. **CloudWatch Dashboard Stack**: 用于追踪 AI token 消耗、API 延迟和 Lambda 工具执行指标的自定义可观测性仪表板。 11. **MLOps Eval Stack**: S3 数据湖、EventBridge 定时任务、SNS 警报以及用于使用 Golden Datasets 每周自动进行 Bedrock 模型评估的 Lambda 函数。 ## 📂 项目结构概述 ``` 📦 aws-supply-chain-enterprise-demo/ ├── 📁 agent_core/ # Strands Framework Agents (Orchestrator, KB Specialist) ├── 📁 app/ # Frontend Chat UI (Static HTML/CSS/JS) ├── 📁 cdk_pipeline/ # Self-mutating CI/CD CodePipeline definition ├── 📁 lambda_funcs/ # MCP Tool Handlers & MLOps Evaluation Lambdas ├── 📁 scripts/ # Utility scripts (Mock data loader, URL fetcher) ├── 📁 stacks/ # 11 AWS CDK Infrastructure definitions ├── 📄 app.py # CDK app entry point ├── 📄 cdk.json # CDK configuration ├── 📄 Makefile # Deployment commands ├── 📄 run.sh # Deployment bash scripts ├── 📄 requirements.txt # Python dependencies └── 📄 README.md # Documentation ``` ## 🧠 多 Agent 系统与工具 这款助手的核心是 **多 Agent 架构**,它将复杂的 workflows 拆分给专门的 AI 模型,以在成本和推理能力之间取得最佳平衡。 ### Orchestrator Agent (Amazon Nova Pro) Orchestrator 是系统的“大脑”。它直接与用户对话,理解意图,规划回答问题所需的步骤,并将请求路由到正确的工具。 * **为什么选择 Nova Pro?** 因为要协调多个工具、推理复杂的供应链问题(例如,“如果货物 X 延误了,我替代方案?”),并保持对话记忆,需要一个具备高级推理和规划技能的、高度 capable 的顶级基础模型。 ### 2. MCP 工具与 Lambda 处理程序 当 Orchestrator 需要真实世界的数据时,它无法直接查询数据库。它使用由 Model Context Protocol (MCP) Gateway 定义的工具。每个工具都会触发一个特定的 AWS Lambda 函数,该函数随后会安全地查询其指定的 DynamoDB 表: * **Inventory Tool** ➡️ `Inventory Lambda` ➡️ 查询 `sc-inventory` * **Logistics Tool** ➡️ `Logistics Lambda` ➡️ 查询 `sc-shipments` 和 `sc-routes` * **Supplier Tool** ➡️ `Supplier Lambda` ➡️ 查询 `sc-suppliers` * **Quality Tool** ➡️ `Quality Lambda` ➡️ 查询 `sc-inspections`、`sc-compliance` 和 `sc-standards` * 🛡️ **安全性与严格隔离:** AI Agents 和 Tools 在完全独立、隔离的环境中运行。Orchestrator Agent 对您的 DynamoDB 表拥有 **零直接访问权限**。它只能通过安全的 Gateway 与隔离的 Lambda 函数通信,严格强制执行最小权限原则。 ### Knowledge Base Specialist Agent (Amazon Nova Lite) 当用户询问有关公司政策、合同或程序指南(它们不在数据库中,而是存在于 PDF/文本文档中)的问题时,Orchestrator 会将任务委托给 **KB Specialist Agent**。此 agent 使用检索增强生成 (RAG) 来搜索包含从 S3 同步的手册的 **Amazon OpenSearch Serverless** 向量数据库。 * **为什么选择 Nova Lite?** Specialist Agent 只有一项专注的工作:阅读检索到的文本块并准确地进行总结。它不需要做复杂的工具路由。Nova Lite 速度极快且极具成本效益,使其成为高速、直接阅读和总结任务的完美模型。 ## 🗄️ DynamoDB 表 该项目部署了 7 个 DynamoDB 表,作为 AI 助手的唯一事实来源。在现实世界的企业中,这些表将通过流式传输来自 ERP 系统(例如 SAP)、仓库管理系统 (WMS) 和航运集装箱上的 IoT 传感器的数据来持续更新。  1. **`sc-inventory`**: 追踪产品库存、仓库位置和重新订购阈值。 2. **`sc-shipments`**: 包含活动的追踪号、预计到达时间 (ETA) 和承运人状态。 3. **`sc-routes`**: 映射物流路线、距离和当前状况(例如,天气延误)。 4. **`sc-suppliers`**: 包含供应商资料、层级评级和联系信息。 5. **`sc-inspections`**: 存储特定产品批次的质量控制报告(通过/未通过)。 6. **`sc-compliance`**: 追踪环境和制造认证(例如,ISO-9001、CE、RoHS)。 7. **`sc-standards`**: 定义严格的企业阈值和规则(例如,电机可接受的最大噪音水平)。 ## 📚 知识库与向量存储 虽然 DynamoDB 负责处理结构化的实时指标,但供应链同时还受制于数千页的非结构化文档。为了处理这些文档,构建了一个高度可扩展的检索增强生成 (RAG) pipeline: ### 1. 数据湖 * **企业手册**: 详细说明质量审计、退货政策和供应商规则的 PDF、文本文件和指南。 * **OpenAPI Schemas**: AgentCore Gateway 用来验证 AI 工具请求的严格 JSON schemas。 ### 2. 向量数据库 每当文档上传到 S3 时,它就会自动被分块,并使用 **Amazon Titan Text Embeddings** 模型转换为向量 embeddings。这些向量被存储在一个 **Amazon OpenSearch Serverless** collection 中。 **为什么选择 OpenSearch Serverless?** * **混合搜索 (向量 + 精确关键字):** 在搜索精确的企业零件号、SKU 或首字母缩略词时,仅靠语义搜索通常会失败。OpenSearch 原生支持 **混合搜索**,将向量相似性与传统的关键字匹配 (BM25) 结合在一起,从而大幅提高 RAG 的准确性。 * **大规模的复杂元数据过滤:** 虽然基础的向量存储(如 S3)支持元数据,但 OpenSearch 是一个专用的搜索引擎,旨在跨海量数据集瞬间执行复杂的元数据预过滤(例如,*“仅搜索标记为 '2023' AND 'Europe' OR 'Approved' 的文档”*),而不会出现性能下降。 * **亚毫秒级延迟(需额外付费):** OpenSearch 专为必须在一瞬间返回搜索结果的企业级用例而设计。如果超低延迟是一项严格要求,这就是黄金标准。 * **对比预置集群更具成本效益:** 尽管 OpenSearch 的基础成本很高(约 350 美元/月),但对于不可预测的、突发性的 AI 流量来说,*Serverless* 变体仍然比运行传统的 24/7 专用 OpenSearch 集群便宜得多。您不必为极端的过度预置付费。 * **原生 Bedrock 集成**: 它作为 Amazon Bedrock Knowledge Bases 的无缝、完全托管的向量存储后端。 ## 💰 企业成本估算(每月) 此架构主要基于 **Serverless**(按需付费)模式,使其对于内部企业用例极具成本效益。以下是基于标准 AWS eu-central-1 (Frankfurt) 定价的现实每月成本估算。 **假设与场景:** - **用户与流量:** 100 名每日活跃用户(供应链规划师和经理)每天产生 **1,000 个请求**(约 30,000 个请求/月)。 - **存储:** Amazon S3 中 **1 TB**(文档、PDF、日志),DynamoDB 中 **5 GB**(供应链业务数据)。 - **向量数据库:** Amazon OpenSearch Serverless 中 **10 GB** 的向量 embeddings。 - **AI 模型:** 使用 Amazon Bedrock 进行混合交互路由(例如,简单任务使用 Nova Lite,复杂推理使用 Nova Pro),由 AgentCore 管理。 | AWS 服务 | 成本因素与估算 | 预估每月成本 | |-------------|-------------------------|----------------------:| | **Amazon OpenSearch Serverless** | 4 个 half-OCUs(冗余/多可用区部署)。
*注意:每天 1000 个请求完全在基准范围内。如果您的 10 GB 全是向量 embeddings,它可能会自动扩容。* | **~$350.00** | | **Amazon Bedrock (Nova Models)** | **按需付费:** 每月约 60M 输入 Tokens,15M 输出 Tokens。
Nova Lite(输入 $0.078 / 输出 $0.312)和 Nova Pro(输入 $1.05 / 输出 $4.20)各占 50% 的混合使用量。 | **~$68.00** | | **Amazon S3** | 1 TB 标准存储 + 中等的 GET/PUT 请求量。 | **~$25.00** | | **Amazon DynamoDB** | 5 GB 存储 ($0.306/GB) + 按需读/写(约 3 万次请求 = 可忽略不计)。 | **~$1.54** | | **AWS Lambda** | 30,000 次执行(约 60k GB-秒)。$0.20/1M 次请求 + $0.0000166667/GB-s | **~$1.01** | | **Amazon AgentCore** | 每月 30,000 个会话的 Serverless 消耗定价:
• **Runtime 计算:** $21.71 (1vCPU/2GB,60秒会话,70% I/O 等待)
• **Gateway API:** $1.20 (搜索与工具调用)
• **Memory:** $45.00 (存储、事件与检索)
• **评估与 Guardrails:** $2.25 | **~$70.16** | | **Amazon API Gateway** | 通过 HTTP API 发出的 30,000 个请求(每百万请求 $1.20)。 | **~$0.04** | | **Amazon CloudWatch** | 自定义仪表板 ($3.00) + 约 1 GB 日志摄取 ($0.63/GB)。 | **~$3.63** | | **Amazon CloudFront** | 内部 UI 托管。约 10 GB 数据传出 ($0.085/GB)。 | **~$0.85** | | **Amazon VPC Network** | 1 个 NAT Gateway ($37.96) + 跨 2 个可用区的 7 个 Interface Endpoints ($121.61) + 数据处理费。 | **~$159.93** | | **预估总成本** | | **~$680.16** | ## 🚀 部署说明 在部署此项目之前,请确保您的本地环境和 AWS 账户满足以下要求: ### 0. 前置条件 **本地环境:** * **Node.js (v18+)**: AWS CDK 所必需的。([下载 Node.js](https://nodejs.org/)) * **AWS CLI (v2)**: 与您的 AWS 账户进行交互所必需的。([安装 AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html)) * **Python (3.11+)**: CDK 部署脚本和 Lambda 函数所必需的。 * **Git**: 进行版本控制并拉取代码仓库所必需的。 * **AWS CDK**: 在您的终端中运行 `npm install -g aws-cdk` 全局安装 AWS Cloud Development Kit。 **AWS 账户设置:** * **IAM User/Role**: 您必须拥有一个具有 `AdministratorAccess` 的 IAM User 或 Role(或具有创建 VPC、IAM Roles、Lambda 函数、Bedrock 模型和 OpenSearch 集群的足够权限)。 * **AWS CLI 配置**: 通过在终端运行 `aws configure` 并提供您的 Access Key ID 和 Secret Access Key,使用您的 AWS 凭证配置本地计算机。 * **Amazon Bedrock 模型访问权限**: 在部署之前,您**必须**在 AWS Bedrock 控制台中手动申请访问 Amazon Nova 模型(Nova Pro 和 Nova Lite)以及 Titan Text Embeddings V2,否则部署将会失败。 ### 1. 设置您自己的 GitHub 仓库与环境 由于 AWS CodePipeline 需要访问源代码,您必须将此代码推送到您自己的 GitHub 账户: 1. **Fork** 此仓库或将其克隆,并推送到您 GitHub 账户上的一个新私有/公共仓库中。 2. 在本地克隆您的仓库并设置您的 Python 虚拟环境: ``` git clone https://github.com/
标签:AI助手, Amazon Bedrock, AWS CDK, RAG, 企业级应用, 供应链管理, 漏洞探索, 逆向工具