b1nd03/cybersynth-ids
GitHub: b1nd03/cybersynth-ids
一款基于 LightGBM 和 FastAPI 的入侵检测研究平台,提供网络流数据预处理、模型训练、合成数据生成、预测解释与漂移监控的一站式 Web 仪表板。
Stars: 2 | Forks: 0
# CyberSynth IDS
CyberSynth IDS 是一款用于网络安全数据集实验的本地 Web 工具。它可以准备网络流数据集、训练基线入侵检测模型、生成经过筛选的合成数据行、验证上传的 CSV 文件,并通过 FastAPI 仪表板展示模型结果。
## 屏幕截图
| 概览 | 预测 |
|---|---|
| 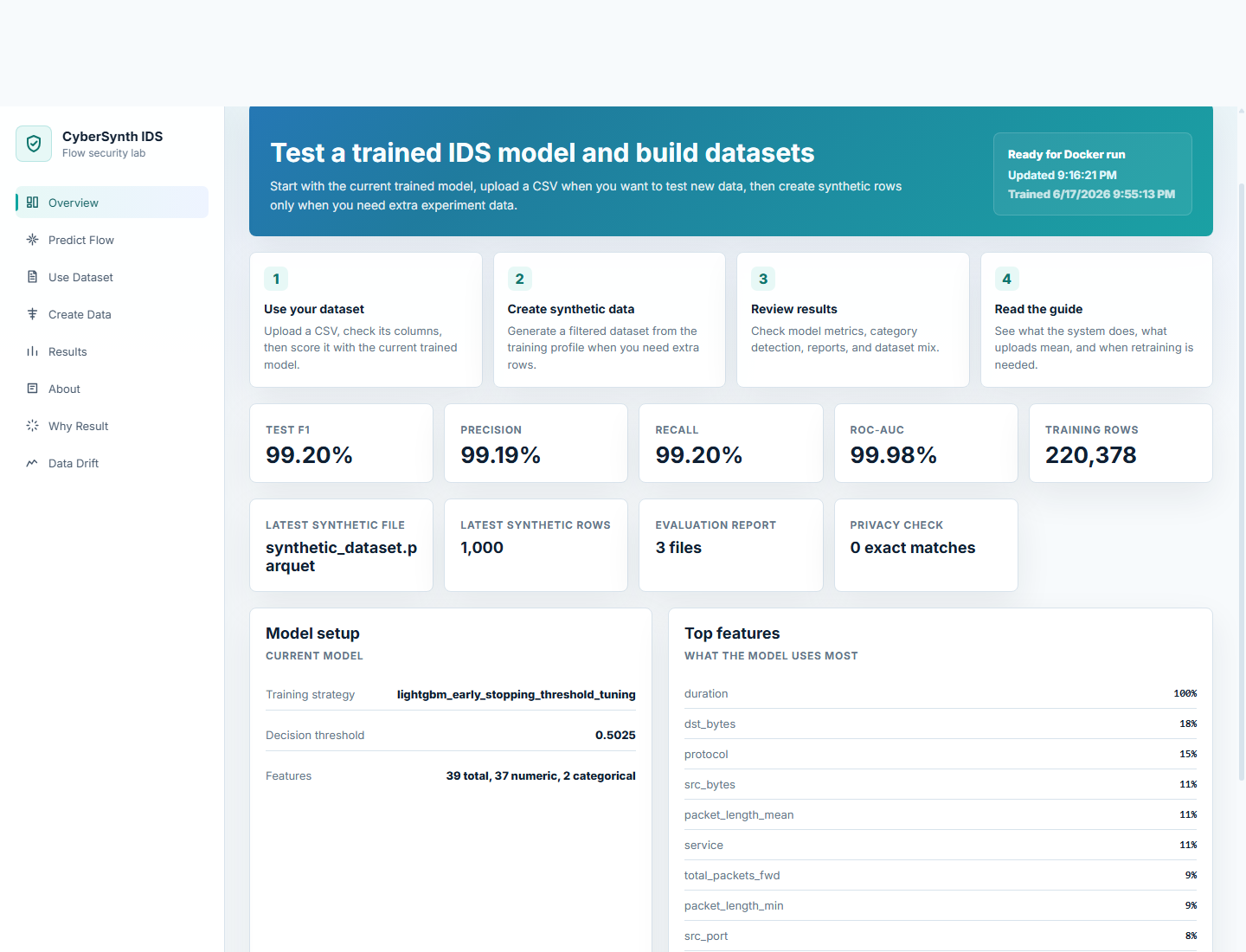 | 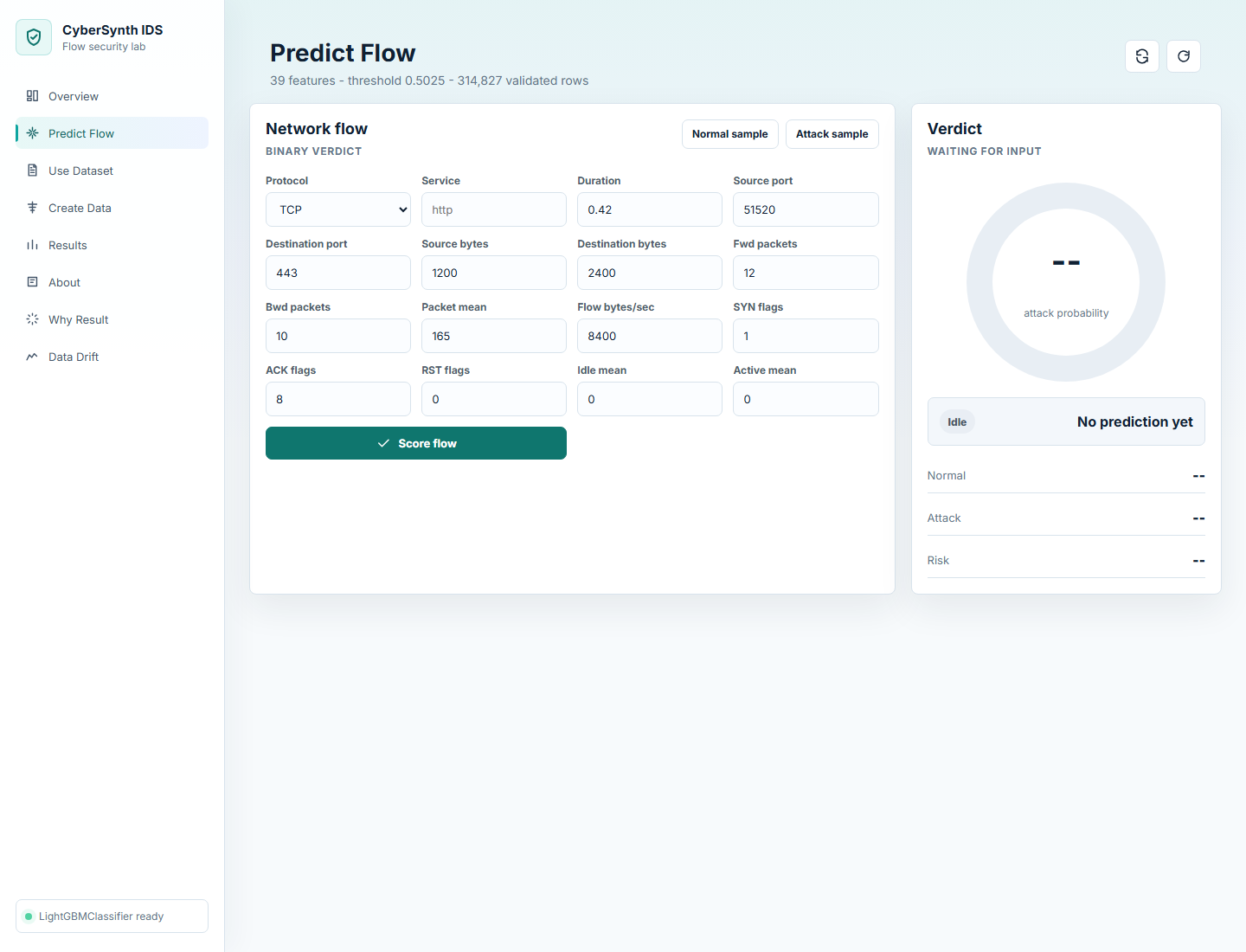 |
| 上传 CSV | 结果 |
|---|---|
| 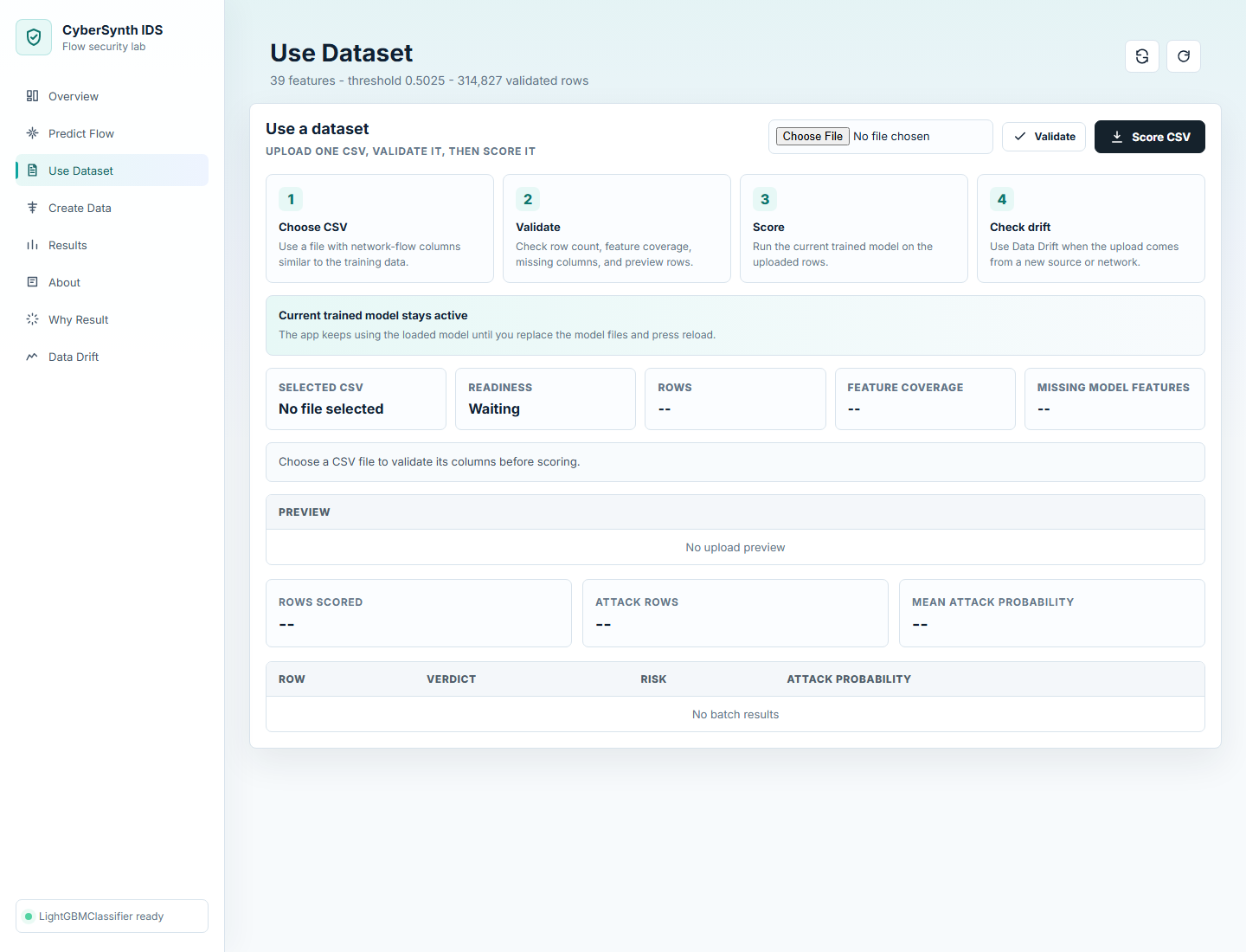 | 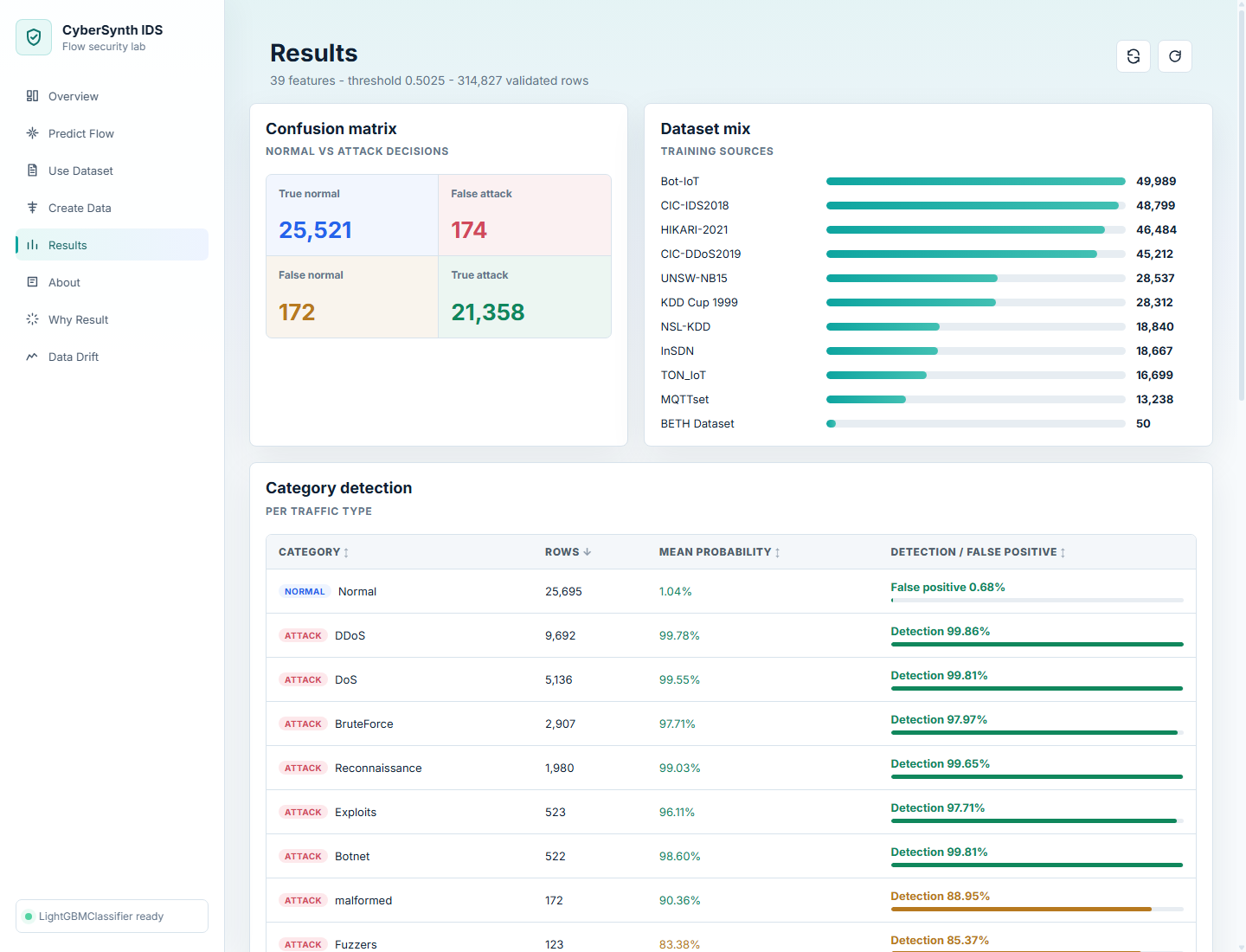 |
| 可解释性 | 漂移 |
|---|---|
|  |  |
## 核心亮点
- FastAPI 仪表板支持 IDS 预测、CSV 上传、合成数据集创建、结果查看、可解释性分析以及漂移检查。
- LightGBM 基线模型支持保存指标、特征重要性、阈值调优以及各类别报告。
- 数据集生成器支持按标签、攻击家族、源数据集、环境和子类别进行筛选。
- 上传验证支持检查行数、特征覆盖率、缺失列,并在评分前预览数据行。
- 支持 Docker 的本地发行版,提供可选的 API key 认证、管理员重载 token、速率限制、审计日志、CORS 白名单、模型哈希校验以及安全响应头。
## 工作原理
CyberSynth IDS 将支持的网络流数据集标准化为统一的共享 schema,基于流量特征训练模型,并保留元数据用于报告、筛选和数据集生成。
上传的 CSV 文件在评分前会根据训练好的特征集进行验证。可以通过预处理、分割、重新训练和漂移检查来添加新的数据集。
合成数据生成器使用训练配置信息来创建经过筛选的实验数据,同时减少与真实数据行的完全匹配。
## 系统架构
```
flowchart LR
Raw[Raw IDS datasets] --> Prep[Preprocessing and schema mapping]
Prep --> Split[Train and test splits]
Split --> Model[LightGBM IDS model]
Split --> Gen[Synthetic data generator]
Model --> API[FastAPI backend]
Gen --> API
API --> UI[Web dashboard]
UI --> Predict[Flow prediction]
UI --> Upload[CSV validation and scoring]
UI --> Explain[SHAP explanation]
UI --> Drift[PSI drift monitoring]
```
## 项目结构
```
configs/ Dataset and experiment configuration
docs/ Project notes for model behavior
docs/screenshots/ Dashboard screenshots for the README
src/ingestion/ Preprocessing and train/test split scripts
src/evaluation/ Model training and synthetic-data evaluation scripts
src/generation/ Synthetic dataset generator
src/web/ FastAPI application
web/ Dashboard HTML, CSS, and JavaScript
models/ Trained model artifact for the Docker demo
outputs/ Metrics and report outputs
```
原始下载文件、生成的合成数据集、日志、notebooks、缓存文件夹和私人笔记会被 Git 忽略。公开仓库仅保留 Docker 演示所需的小型 runtime artifacts:训练好的模型、专用于演示的微型合成训练/测试分割、数据集质量报告、指标和评估报告。
## 快速开始
安装 Web runtime 依赖:
```
pip install -r requirements.txt
```
运行仪表板:
```
python -m uvicorn src.web.app:app --host 127.0.0.1 --port 8000
```
打开:
```
http://127.0.0.1:8000
```
执行完整的预处理、训练、生成和评估工作:
```
pip install -r requirements-pipeline.txt
```
代码库中提交的 `data/processed/train.parquet` 和 `data/processed/test.parquet` 文件是微型的合成演示分割数据,以便仪表板在克隆代码后能直接运行。在训练或报告新结果之前,请根据您自己下载的数据集重新生成本地的完整分割数据。
用于测试和代码检查工具:
```
pip install -r requirements-dev.txt
```
## 主要命令
预处理数据集:
```
python src\ingestion\preprocessor.py --config configs\active_datasets.yaml
python src\ingestion\validate_and_split.py
```
训练基线模型:
```
python src\evaluation\train_baseline.py
```
创建合成数据集:
```
python src\generation\generate_synthetic.py --rows 500000 --mode label_balanced --output data\synthetic\synthetic_dataset_v1.0.parquet --summary-output data\synthetic\synthetic_dataset_v1.0_summary.json
```
评估合成数据集:
```
python src\evaluation\evaluate_synthetic.py --synthetic data\synthetic\synthetic_dataset_v1.0.parquet --output-dir outputs\reports
```
运行测试:
```
pytest -q
```
## 网站工作流
1. 打开 **概览** 检查模型状态、最新的数据集输出、报告以及所需文件。
2. 打开 **预测** 测试单个网络流。
3. 打开 **使用数据集** 在评分前验证 CSV 文件。
4. 打开 **创建数据** 选择筛选条件并创建合成数据集。
5. 当需要进一步深入检查时,打开 **结果**、**结果归因** 或 **数据漂移**。
## 结果概览
- 基线 LightGBM F1 分数:`0.9916`
- 真实与合成数据结合的 F1 分数:`0.9920`
- 生成数据中与真实数据行完全匹配的数量:`0`
## 部署
由于该应用会提供本地的模型、指标和数据集 artifacts,公共版本请使用 Docker 进行部署。有关 Docker 和 GitHub 的检查清单,请参阅 `DEPLOYMENT.md`。
## 文档说明
- `MODEL_CARD.md` 描述了基线 IDS 模型。
- `dataset_card.md` 描述了生成的数据集 artifact。
- `DEPLOYMENT.md` 描述了 Docker 发布工作流。
## 许可证
MIT License。
如需配置部署设置,请将 `.env.example` 复制为 `.env`,并根据需要设置 API key、管理员 token、CORS 源、模型哈希、上传大小、速率限制和 runtime 限制。
标签:Apex, AV绕过, FastAPI, LightGBM, 机器学习, 网络安全, 请求拦截, 逆向工具, 隐私保护