
Unlimited OCR Works
欢迎来到一次性长程解析的时代。
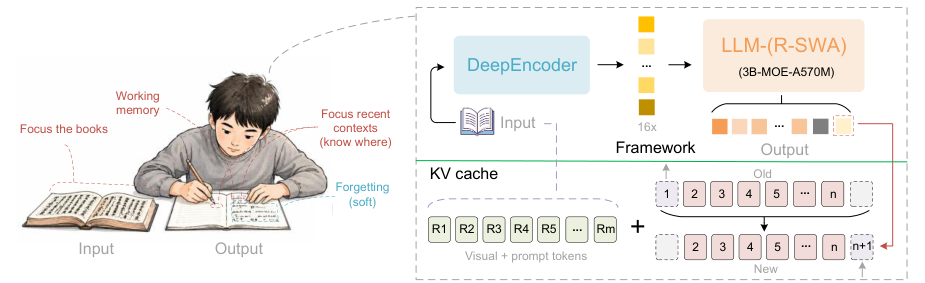
## 发布
- [2026/06/22] 🚀 我们推出了 [Unlimited-OCR](https://github.com/baidu/Unlimited-OCR),旨在将 [Deepseek-OCR](https://https://github.com/deepseek-ai/DeepSeek-OCR) 推向新的高度。
## 推理
### Transformers
在 NVIDIA GPU 上使用 Huggingface transformers 进行推理。已在 python 3.12.3 + CUDA12.9 环境下测试要求:
```
torch==2.10.0
torchvision==0.25.0
transformers==4.57.1
Pillow==12.1.1
matplotlib==3.10.8
einops==0.8.2
addict==2.4.0
easydict==1.13
pymupdf==1.27.2.2
psutil==7.2.2
```
```
import os
import torch
from transformers import AutoModel, AutoTokenizer
model_name = 'baidu/Unlimited-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
use_safetensors=True,
torch_dtype=torch.bfloat16,
)
model = model.eval().cuda()
# ── 单张图片支持两种配置:gundam 或 base ──
# gundam: base_size=1024, image_size=640, crop_mode=True
# base: base_size=1024, image_size=1024, crop_mode=False
model.infer(
tokenizer,
prompt='
document parsing.',
image_file='your_image.jpg',
output_path='your/output/dir',
base_size=1024, image_size=640, crop_mode=True,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=128,
save_results=True,
)
# ── 多页 / PDF 仅使用 base (image_size=1024) ──
model.infer_multi(
tokenizer,
prompt='Multi page parsing.',
image_files=['page1.png', 'page2.png', 'page3.png'],
output_path='your/output/dir',
image_size=1024,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=1024,
save_results=True,
)
# ── PDF (将页面转换为图片,然后进行多页解析) ──
import tempfile, fitz # PyMuPDF
def pdf_to_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
tmp_dir = tempfile.mkdtemp(prefix='pdf_ocr_')
mat = fitz.Matrix(dpi / 72, dpi / 72)
paths = []
for i, page in enumerate(doc):
out = os.path.join(tmp_dir, f'page_{i+1:04d}.png')
page.get_pixmap(matrix=mat).save(out)
paths.append(out)
doc.close()
return paths
model.infer_multi(
tokenizer,
prompt='Multi page parsing.',
image_files=pdf_to_images('your_doc.pdf', dpi=300),
output_path='your/output/dir',
image_size=1024,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=1024,
save_results=True,
)
```
### SGLang
配置环境(由 uv 管理的虚拟环境)。首先安装本地 SGLang wheel,
然后固定 `kernels==0.9.0` 并安装 PyMuPDF 以进行 PDF 转图像操作:
```
uv venv --python 3.12
source .venv/bin/activate
uv pip install wheel/sglang-0.0.0.dev11416+g92e8bb79e-py3-none-any.whl
uv pip install kernels==0.11.7
uv pip install pymupdf==1.27.2.2
```
启动 SGLang 服务器:
```
python -m sglang.launch_server \
--model baidu/Unlimited-OCR \
--served-model-name Unlimited-OCR \
--attention-backend fa3 \
--page-size 1 \
--mem-fraction-static 0.8 \
--context-length 32768 \
--enable-custom-logit-processor \
--disable-overlap-schedule \
--skip-server-warmup \
--host 0.0.0.0 \
--port 10000
```
向兼容 OpenAI 的 API 发送流式请求:
```
import base64
import json
import os
import tempfile
import fitz
import requests
from sglang.srt.sampling.custom_logit_processor import DeepseekOCRNoRepeatNGramLogitProcessor
server_url = "http://127.0.0.1:10000"
session = requests.Session()
session.trust_env = False
def pdf_to_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
tmp_dir = tempfile.mkdtemp(prefix="pdf_ocr_")
mat = fitz.Matrix(dpi / 72, dpi / 72)
image_paths = []
for i, page in enumerate(doc):
image_path = os.path.join(tmp_dir, f"page_{i + 1:04d}.png")
page.get_pixmap(matrix=mat).save(image_path)
image_paths.append(image_path)
doc.close()
return image_paths
def encode_image(image_path):
ext = os.path.splitext(image_path)[1].lower()
mime = "image/jpeg" if ext in (".jpg", ".jpeg") else f"image/{ext.lstrip('.')}"
with open(image_path, "rb") as f:
data = base64.b64encode(f.read()).decode("utf-8")
return {"type": "image_url", "image_url": {"url": f"data:{mime};base64,{data}"}}
def build_content(prompt, image_paths):
return [{"type": "text", "text": prompt}] + [encode_image(path) for path in image_paths]
def generate(prompt, image_paths, image_mode, ngram_window):
payload = {
"model": "Unlimited-OCR",
"messages": [{"role": "user", "content": build_content(prompt, image_paths)}],
"temperature": 0,
"skip_special_tokens": False,
"images_config": {"image_mode": image_mode},
"custom_logit_processor": DeepseekOCRNoRepeatNGramLogitProcessor.to_str(),
"custom_params": {
"ngram_size": 35,
"window_size": ngram_window,
},
"stream": True,
}
response = session.post(
f"{server_url}/v1/chat/completions",
headers={"Content-Type": "application/json"},
data=json.dumps(payload),
timeout=1200,
stream=True,
)
response.raise_for_status()
chunks = []
for line in response.iter_lines(chunk_size=1, decode_unicode=True):
if not line or not line.startswith("data: "):
continue
data = line[len("data: "):]
if data == "[DONE]":
break
event = json.loads(data)
delta = event["choices"][0].get("delta", {}).get("content", "")
if delta:
print(delta, end="", flush=True)
chunks.append(delta)
print()
return "".join(chunks)
# 单张图片支持两种配置:gundam 或 base。以下示例使用 gundam。
generate("document parsing.", ["your_image.jpg"], image_mode="gundam", ngram_window=128)
# 多张图片(仅限 base)
generate("Multi page parsing.", ["page1.png", "page2.png"], image_mode="base", ngram_window=1024)
# PDF(仅限 base)
generate("Multi page parsing.", pdf_to_images("your_doc.pdf", dpi=300), image_mode="base", ngram_window=1024)
```
对于批量推理,`infer.py` 会自动启动 SGLang 服务器,并针对图像目录或 PDF 发送并发请求:
```
# 图片目录
python infer.py \
--image_dir ./examples/images \
--output_dir ./outputs \
--concurrency 8 \
--image_mode gundam
# PDF 页面
python infer.py \
--pdf ./examples/document.pdf \
--output_dir ./outputs \
--concurrency 8 \
--image_mode gundam
```
实用选项:
```
--model_dir baidu/Unlimited-OCR # Local path or Hugging Face model ID
--gpu 0 # CUDA_VISIBLE_DEVICES value
--server_log ./log/sglang_server.log
```
## 可视化
 ## 鸣谢
我们要感谢 [Deepseek-OCR](https://https://github.com/deepseek-ai/DeepSeek-OCR)、[Deepseek-OCR-2](https://github.com/deepseek-ai/DeepSeek-OCR-2)、[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的宝贵模型与思路。
## 引用
即将推出!
## 鸣谢
我们要感谢 [Deepseek-OCR](https://https://github.com/deepseek-ai/DeepSeek-OCR)、[Deepseek-OCR-2](https://github.com/deepseek-ai/DeepSeek-OCR-2)、[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的宝贵模型与思路。
## 引用
即将推出!