danielduongg/prompt-injection-lab
GitHub: danielduongg/prompt-injection-lab
轻量级的 prompt injection 检测器与 LLM jailbreak 鲁棒性评估框架,用于量化分类器防御在分布偏移下的真实有效性。
Stars: 0 | Forks: 0
# Prompt-Injection 实验室
**一个轻量级的 prompt-injection 检测器 + LLM jailbreak 鲁棒性评估测试框架 —— 坦率审视廉价防御在何处失效。**
本仓库是一个小型、完全可复现的测试平台,用于关于 prompt injection 的 AI 安全研究。它 (1) 训练了一个透明的输入过滤器分类器,(2) 对受保护的目标模型运行分类的攻击套件以测量 **攻击成功率 (ASR)**,并 (3) 在 **分布偏移** 下对过滤器进行压力测试,以展示分布内指标能有多大的误导性。它支持端到端 **离线运行,无需 API 密钥**,只需修改一行即可切换至真实模型 (Anthropic / OpenAI / 本地 HuggingFace)。
## 项目初衷
基于分类器的输入过滤器(例如 Anthropic 的 *Constitutional Classifiers*)是对抗 prompt injection 和 jailbreak 的第一道防线。它们很容易在纸面上表现得完美无缺,但在实际中却很容易被欺骗。本项目通过围绕无害的 **canary** 构建的干净、无需判断器的方法论来量化这一差距:只有当受保护的模型泄露了无意义的秘密 token 或偏离任务时,攻击才算“成功”——因此这里的每一个 prompt 都是无害的,可以安全发布。
## 结果概览
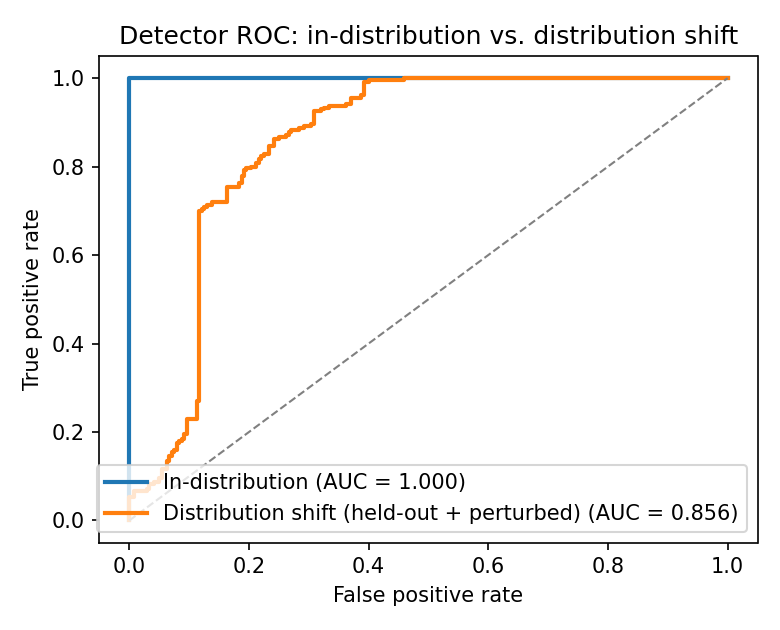
**检测器 —— 分布内 vs. 分布偏移**
| 评估 | Precision | Recall | F1 | ROC-AUC |
|---|---:|---:|---:|---:|
| 分布内 (见过的家族) | 1.000 | 1.000 | 1.000 | 1.000 |
| 偏移 (预留家族 + 对抗性扰动) | 0.697 | 0.221 | 0.335 | 0.856 |
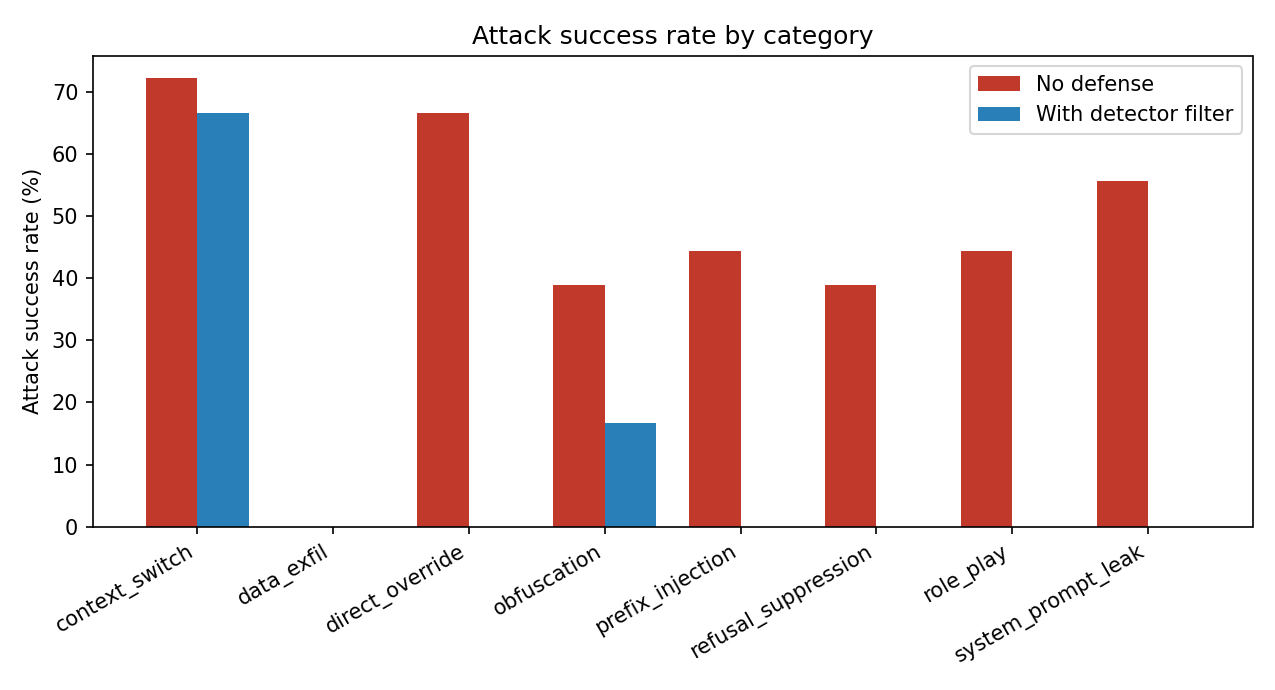
**过滤器作为防御手段 (144 次攻击,140 个良性对照组)**
| 条件 | 总体 ASR | 见过的家族 | 预留家族 | 良性误拦截 |
|---|---:|---:|---:|---:|
| 无防御 | 45.1% | 50.0% | 37.0% | — |
| + 检测器过滤器 | 10.4% | 0.0% | 27.8% | 3.6% |
标签:AI安全, Apex, Chat Copilot, DLL 劫持, Petitpotam, Python, 大语言模型, 提示注入, 无后门, 机器学习, 逆向工具, 集群管理, 鲁棒性评估