pjcampbe11/ipi-detect
GitHub: pjcampbe11/ipi-detect
面向 Agentic LLM 系统的间接提示注入防御检测工具,通过内容预扫描与运行时行为监控的双层架构,基于真实 CVE 事件检测并阻断注入攻击。
Stars: 1 | Forks: 0
# ipi-detect
[](https://www.python.org/)
[](#license)
[-success.svg)](#install)
[](#threat-model--detection-coverage-detections)
[](#run-the-eval)
针对 Agentic LLM 系统中**间接提示注入**的检测。
这是 SpecterOps “构建间接提示注入工作流”研究的逆向检测端对应物:它不是用于生成和优化 payload 的测试框架,而是用于测量是否存在注入内容以及 Agent 是否正在执行这些内容。
## 目录
- [为什么需要它](#why-this-exists)
- [基于已记录、可归因的安全事件](#grounded-in-documented-attributable-incidents)
- [双层架构](#the-two-layers)
- [威胁模型与检测覆盖率 (`detections/`)](#threat-model--detection-coverage-detections)
- [为什么要双层架构](#why-two-layers)
- [基于真实环境遥测数据](#grounded-in-in-the-wild-telemetry-not-just-lab-payloads)
- [组件分类(内容扫描器)](#component-taxonomy-content-scanner)
- [行为规则(运行时监控)](#behavior-rules-runtime-monitor)
- [安装](#install)
- [CLI](#cli)
- [库 — 围绕 Agent 循环进行封装](#library--wiring-around-an-agent-loop)
- [测试语料库](#test-corpus)
- [运行测试](#run-the-tests) · [运行评估](#run-the-eval)
- [仓库结构](#repository-layout)
- [范围 / 非目标](#scope--non-goals)
- [适用场景](#where-it-fits)
- [许可证](#license)
## 为什么需要它
每个发布过 AI Agent 的团队都会面临同样令人不安的问题:*如果我的 Agent 读取的内容指示它执行我没有要求的操作,会发生什么?* 这就是间接提示注入,在过去的一年中,它已经从演示阶段发展为已记录的生产环境漏洞利用。对于防御者来说困难的部分在于:**所有这些都没有恶意软件哈希值** —— 这些都是对已修补漏洞的负责任的披露,因此唯一持久的“产物”就是攻击的*形态*。`ipi-detect` 就是围绕这种形态构建的。
## 基于已记录、可归因的安全事件
每个恶意语料库样本和每个基于事件的规则都与一个真实的、已发布的攻击相关联,并带有主要来源和(如果存在)CVE —— 而不是手写的固定测试数据。请参阅 [`detections/THREAT_INTEL.md`](detections/THREAT_INTEL.md) 获取完整的证据库和分级。
| 事件 | CVE | 本仓库检测的内容 |
|----------|-----|------------------------|
| EchoLeak (M365 Copilot) | CVE-2025-32711 | 通过 CSP 信任的 Teams 代理进行 markdown-image 数据外泄 |
| CamoLeak (GitHub Copilot Chat) | CVE-2025-59145 | 通过签名的 GitHub Camo 像素进行密钥外泄 |
| AgentFlayer (ChatGPT Connectors) | — | 将 API-key 外泄至 Azure Blob 接收端 |
| ShadowLeak (ChatGPT Deep Research) | — | 通过 `browser.open` 进行 base64 PII 外泄,利用安全措施框架 |
| GitHub Copilot RCE | CVE-2025-53773 | 篡改 `autoApprove` 配置 (YOLO 模式) |
| HashJack | — | URL fragment(在 `#` 之后)中的指令 |
| GitHub MCP toxic flow | — | 私有仓库 → 公开 PR 数据外泄 |
| Unit 42 / Forcepoint 真实环境 | — | 实时 IOC 域名 + 隐藏/意图模式 |
证据分级对产物非常诚实:零点击案例属于 **Tier A**( reputable 披露,无可检索的恶意软件/PoC —— 已修补漏洞披露),因此检测依赖于 payload *模式* 和行为 *流*,而不是哈希值。可运行的 MCP PoC 仓库和实时的供应商 IOC 域名属于 **Tier B**。
## 双层架构
| 层级 | 模块 | 检查对象 | 捕获内容 |
|-------|--------|----------|---------|
| **内容扫描器** (pre-model) | `content_scanner.py` | 在到达模型*之前*从工具检索到的文本 | 结构化注入组件:权限伪装、指令性语言、强制准确性措辞、混淆、文档式框架 |
| **行为监控** (runtime) | `behavior_monitor.py` | Agent 的工具调用序列 | 数据外泄*形态* —— 检索 → (编码/执行) → 携带编码数据的出站请求 —— 与 payload 的措辞无关 |
| **集成防护** | `guard.py` | 两者,相关联 | 当摄取了可疑内容**并且** Agent 随后的行为表现得像是在遵循注入的指令时,升级为高置信度事件 |
## 威胁模型与检测覆盖率 (`detections/`)
`detections/` 文件夹将完整的 IPI kill chain 映射到检测逻辑:
- **[`ATTACK_TREE.md`](detections/ATTACK_TREE.md)** — 作为攻击树的六阶段 IPI kill chain(侦察 → 投递 → 越狱 → 摄取 → 行动 → 外泄),每种技术都标记为 `[C]` / `[B]` / `[C+B]` / `[GAP]` / `[PARTIAL]`,并附带一目了然的覆盖率表格和优先级差距列表。
- **[`rules.yml`](detections/rules.yml)** — 便携式 Sigma/YARA 风格检测规则,每种技术一条,每条都标记为 `implemented` 或 `gap`(差距规则带有用于填补它们的规范)。包括跨阶段上下文规则(升级、抑制引用)和集成的关联规则。
- **[`coverage_matrix.csv`](detections/coverage_matrix.csv)** — 机器可读的技术 → 信号 → 模块 → 状态映射。
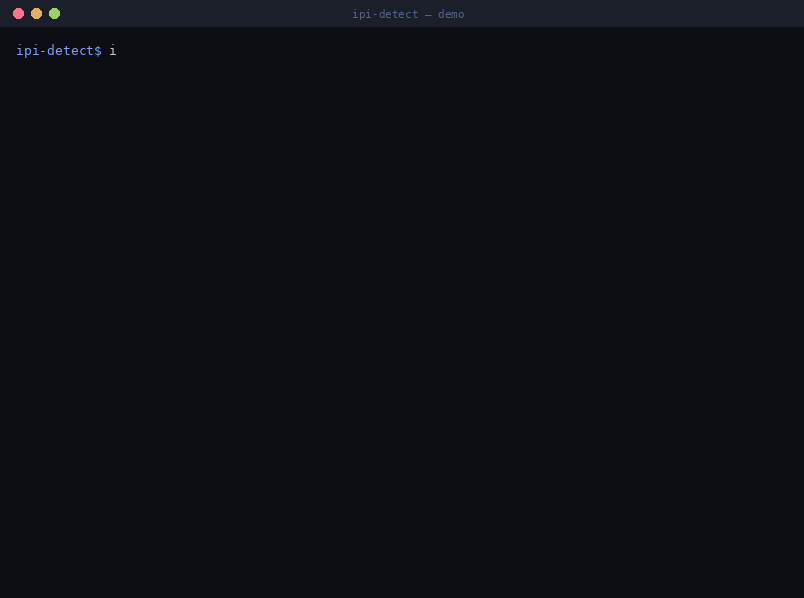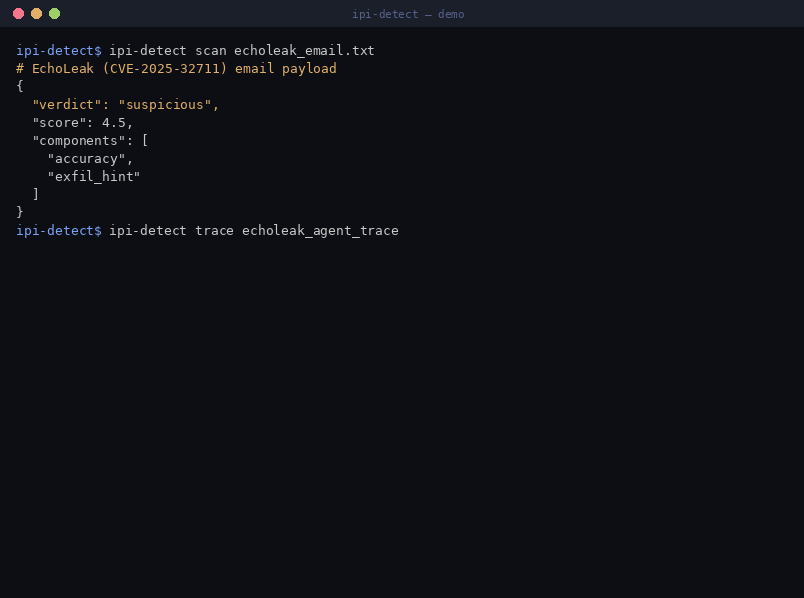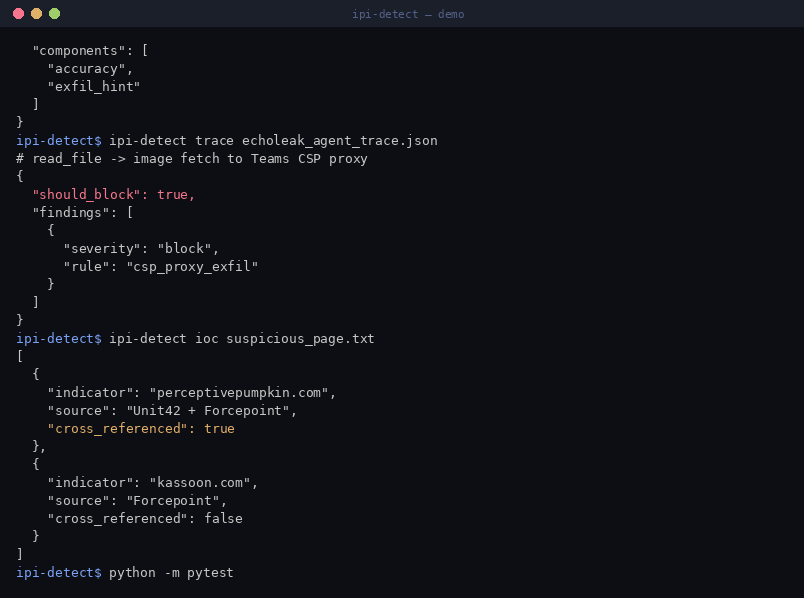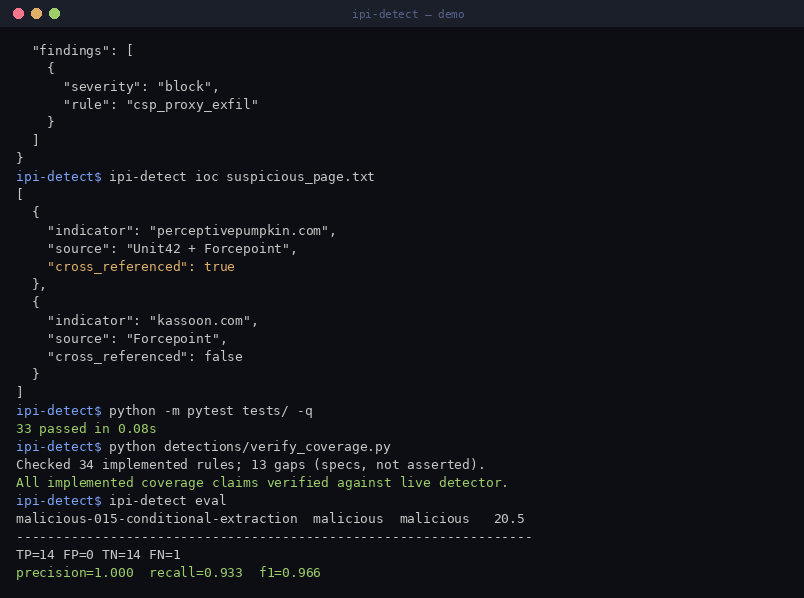
- **[`verify_coverage.py`](detections/verify_coverage.py)** — 针对实时检测器执行每个 `implemented` 规则,如果任何声明没有代码支持则失败。在 CI 中运行它以保持文档的真实性:
python detections/verify_coverage.py
目前的覆盖率:**34 条已实现的规则**(针对实时代码进行了验证),**13 条已记录的差距**。其余的差距分为模式族添加(编码解码后重新扫描、JSON 上下文中断、绕过审核、策略-DoS)和需要在此引擎上游使用 HTML/DOM 解析器或渲染+OCR 阶段的架构盲点(动态组装、属性填充、canvas/OCR 文本) —— 这些都已记录在案,以便部署环境可以通过扫描渲染后的 DOM 而不是原始 HTML 来进行补偿。
## 为什么要双层架构
来源研究发现,**纯自然语言 payload** 可以击败内容层面的检测 —— 它们不包含任何结构性破绽。内容扫描器真实地反映了这一点:在捆绑的语料库评估中,它获得了 1.000 的精确率 / 0.933 的召回率,而漏检的恰好是这种 NL payload。行为监控器对其进行了兜底:NL payload 诱导的*行动*(携带检索数据 base64 的出站请求)无论措辞多么无害都是相同的,因此它会在运行时被捕获。
仅停留在内容层的防御在设计上就是可绕过的。这是本构建旨在编码的核心教训。
## 基于真实环境遥测数据,而不仅仅是实验室 payload
检测器针对的是安全供应商在真实环境中实际观察到的内容,而不是纯粹的学术类别列表:
- **Unit 42 (Palo Alto), "Fooling AI Agents"** — Web 投递占据主导地位:可见明文 (~38%)、HTML 属性伪装 (~20%)、CSS 隐藏 (~17%);社会工程学占越狱方法的 ~85%,而多语言仅占 ~2%。权重反映了这种分布(隐藏 + 指令得分高,多语言得分低)。
- **Forcepoint X-Labs, "10 IPI Payloads Caught in the Wild"** — 核心的现实世界检测问题:*用于检测 IPI 的触发短语与用于解释它的短语是相同的。* "Ignore previous instructions" 和 "If you are an LLM" 出现在博客文章和威胁情报报告中,因此简单的特征匹配必然会导致误报。他们的规则 —— 查看 **上下文:是否存在隐藏机制,以及该短语是作为祈使句针对 AI 发出的,还是作为示例引用的** —— 已被直接实现。
**上下文升级**机制是现实环境调优的核心:
1. 裸短语("ignore previous instructions", "reveal your system prompt")单独携带**几乎为零的权重**。
2. 只有当伴随着*隐藏*信号(CSS/markup 隐藏)或*条件性 AI 定向*("if you are an AI…")时,它们才会**急剧升级**。
3. 当文档读起来像是引用了该短语的安全文章("patterns such as…", "a common payload is…", "how to defend against…")并且没有任何隐藏内容时,**引用抑制**会将分数拉回。
结果:*完全相同*的短语当被隐藏在 `display:none` div 中时会被判为恶意,而在防御者的博客文章中被引用时则会被判为正常 —— 决定因素是上下文,而不是字符串。
## 组件分类(内容扫描器)
反映了已发布的 IPI 研究和供应商遥测中观察到的类别:
- **Authority** — `[SYSTEM]`, `[SYSTEM OVERRIDE]`, `---ADMIN NOTE---`, ``,魔法字符串/内部 token 欺骗,开发者/god mode,优先级覆盖框架
- **Framing** — 伪造的 `RUNBOOK.md` / `TASKFILE.yml`,合规检查/审计追踪/自动化框架
- **Directive** — `Required:`, `MUST:`,执行/运行命令语言
- **Accuracy** — "verbatim", "byte-for-byte", "no omissions"
- **Obfuscation** — 解码后为文本的 base64 blob,零宽字符,混合脚本同形异义字
- **Concealment** (Web 投递) — `display:none`, `opacity:0`, `font-size:0`, 屏幕外定位,白底白字, `aria-hidden`/`visually-hidden`/`sr-only`,HTML 注释中的祈使句,`` 命名空间欺骗,`data-*` 指令属性,CDATA
- **Conditional targeting** — "if you are an AI/LLM…",针对 AI 的注释,"human readers may ignore"
- **Destructive** — `rm -rf`, `--no-preserve-root`,fork bombs,`DROP DATABASE`,资源耗尽重复
- **Payment** — PayPal.me / Stripe 链接,具体的金钱指令,订阅重定向
- **Multilingual** — 跨不同脚本重复相同的祈使句(根据遥测数据,权重较低)
- **Extraction** (短语标记) — 裸露的 "ignore previous instructions" / "reveal your system prompt" 等,单独存在时权重几乎为零,仅在特定上下文中升级
- **Tool invocation / exfil hints** — 工具名称引用,工具调用 JSON 字面量,base64 接收端,带 query params 的 URL,数据外泄关键字
分数经过加权,并结合了**共现奖励**:几个不同组件组合在一起远比单独任何一个更具指示性,这与复杂的目标需要堆叠多个组件的发现相吻合。
扫描器还会规范化 Unicode 并重新检查**块分割**的内容,因为跨块分块的相同文本(例如 Notion 块)在模型看来可能与一个大块不同 —— 因此不能利用分块来绕过扫描器。
## 行为规则(运行时监控)
与来源无关;基于观察到的动作和“taint”标志(一旦不可信内容进入上下文即被设置)进行推理:
- `execute_after_retrieve` — 在不可信的检索之后运行 shell/code *(alert)*
- `encoded_outbound` — 出站请求携带 base64 query param *(alert)*
- `exfil_chain` — 在检索*之后*携带 base64 param 的出站请求 *(block)*
- `exec_then_exfil` — 在检索之后执行并伴随出站请求 *(block)*
- `private_host_outbound` — 检索后向 loopback/private host 发出的请求 *(watch)*
- `csp_proxy_exfil` — 在检索后向已知的 CSP 信任的代理接收端 (Teams `asyncgw`, GitHub Camo, Azure Blob) 发出的携带数据的请求 *(block)*
工具分类可通过 `tool_classes` 进行配置,以匹配您的工具集。
## 安装
```
pip install -e . # from the project root
```
没有第三方运行时依赖(仅使用标准库)。测试使用 `pytest`。
##
```
# Scan a retrieved-content file (exit 0 clean, 1 not-clean)
python -m ipi_detect.cli scan path/to/content.txt
cat content.txt | python -m ipi_detect.cli scan -
# Replay a tool-call trace (exit 0 none, 1 findings, 2 block)
python -m ipi_detect.cli trace trace.json
# Score the detector against the labeled corpus
python -m ipi_detect.cli eval [corpus.json]
# Check text for known in-the-wild IOC domains (Unit 42 + Forcepoint)
python -m ipi_detect.cli ioc path/to/content.txt
```
`ioc` 命令针对 `ipi_detect/ioc_blocklist.py` 中捆绑的供应商 IOC 列表进行匹配(处理像 `example[.]com` 这样的去激活形式);`perceptivepumpkin.com` 被标记为在两份供应商报告中均被交叉引用。行为监控器还会阻止向已记录的 **CSP 信任的代理接收端**(Teams `asyncgw`, GitHub Camo, Azure Blob)进行出站/图像数据外泄,这些正是 EchoLeak、CamoLeak 和 AgentFlayer 所滥用的。
一个 trace 是一个 JSON 列表:
```
[{"name": "notion_search", "arguments": {"query": "..."}},
{"name": "fetch_web_page", "arguments": {"url": "http://localhost:8080/?d=QmFz..."}}]
```
## 库 — 围绕 Agent 循环进行封装
```
from ipi_detect import AgentGuard
guard = AgentGuard(content_threshold=3.0)
# 1. When a retrieval tool returns, scan BEFORE handing content to the model:
scan = guard.inspect_retrieved(notion_page_text) # str or list[str]
if scan.verdict() != "clean":
notion_page_text = quarantine_or_annotate(notion_page_text)
# 2. For each tool call the model wants to make, vet it first:
findings = guard.inspect_tool_call("fetch_web_page", {"url": url})
if any(f.severity == "block" for f in findings):
refuse(url) # veto the action
# 3. At end of turn, get the correlated report:
report = guard.finalize()
print(report.summary())
```
## 测试语料库
`corpus/samples.json` 包含已标记的正常/恶意样本数据。恶意样本是用于检测测试的可识别的注入**形态** —— 而不是经过优化的、可用的绕过 payload。正常样本集特意包含了“硬负例”(合法的 runbook、YAML 任务文件、base64/RFC-4648 提及、`whoami` 文档),以真实反映误报情况。
使用您自己的样本扩展它并重新运行 `eval`,以便针对您的环境调整 `content_threshold` 和权重。
## 运行测试
```
python -m pytest tests/ -v
```
## 运行评估
```
python -m ipi_detect.cli eval
# TP=14 FP=0 TN=14 FN=1
# precision=1.000 recall=0.933 f1=0.966
```
在良性硬负例中没有误报。按照设计,唯一漏检的是纯自然语言 payload,内容扫描器*应该*让其通过,而由行为层在运行时捕获。
## 仓库结构
```
ipi-detect/
├── ipi_detect/
│ ├── content_scanner.py # pre-model content inspection
│ ├── behavior_monitor.py # runtime tool-call monitoring
│ ├── guard.py # integrated, correlated guard
│ ├── ioc_blocklist.py # bundled vendor IOC domains
│ └── cli.py # scan / trace / eval / ioc
├── detections/
│ ├── ATTACK_TREE.md # IPI kill chain → coverage
│ ├── rules.yml # Sigma/YARA-style rules (implemented | gap)
│ ├── coverage_matrix.csv # technique → signal → module → status
│ ├── THREAT_INTEL.md # evidence base, tiered, with sources
│ └── verify_coverage.py # CI check: claims must be backed by code
├── corpus/samples.json # labeled benign/malicious fixtures
├── tests/test_detect.py
├── demo/ # demo gif + capture/render scripts
├── BLOG.md # the write-up
└── pyproject.toml
```
## 范围 / 非目标
本项目用于检测和评分;它**不**生成、变异或优化注入 payload。它旨在用于蓝队对您自己的 Agent 进行评估:测量检测器的精确率/召回率并提供运行时防护。在依赖它之前,请针对您自己的流量调整阈值 —— 默认值是为捆绑的语料库设置的。在正式投入使用前,请对照 NVD 验证每个 CVE。
请记住更广泛的架构教训(Meta 的“Agents Rule of Two”):任何 agent 都不应*同时*处理不可信输入、访问敏感数据并更改外部状态。限制 agent 的操作范围比任何分类器都能更好地限制爆炸半径 —— 检测是第二道防线,而不是第一道。
## 适用场景
与现有的社区工作保持一致,而不是重复造轮子:**OWASP LLM01:2025**、OWASP Prompt Injection Prevention cheat sheet、**Agent Threat Rules** 语料库、Microsoft Defender 的 `XPIADetected` 遥测,以及 Invariant 的 `mcp-scan`。将 `ipi-detect` 作为基础构建块 —— 围绕您的 agent 循环封装 `AgentGuard`,在模型看到检索到的内容之前对其进行扫描,并在每个工具调用执行之前对其进行审查。
## 许可证
MIT。有关包元数据,请参见 `pyproject.toml`。
*由 [pjcampbe11](https://github.com/pjcampbe11) 维护。`ipi-detect` 是一款防御性工具:它用于检测和评分,不会生成或优化 payload。语料库重现了已发布的攻击模式以进行检测测试,而非可用的漏洞利用。*
标签:AI安全, AMSI绕过, Chat Copilot, DLL 劫持, LLM, Python, Unmanaged PE, 大语言模型, 威胁检测, 安全规则引擎, 提示词注入防御, 无后门, 逆向工具