Sukulli/Network-Anomaly-Detector
GitHub: Sukulli/Network-Anomaly-Detector
基于 UNSW-NB15 数据集的端到端网络入侵检测系统,使用 Random Forest 模型并通过 FastAPI 提供二分类预测服务。
Stars: 0 | Forks: 0
# 网络入侵检测系统
[](https://github.com/Sukulli/Network-Anomaly-Detector/actions/workflows/ci.yml)
[](LICENSE)
基于 UNSW-NB15 数据集进行二分类网络入侵检测的端到端机器学习项目。
该项目训练经典的 ML 分类器,保存可重用的 scikit-learn pipeline,通过 FastAPI REST API 暴露主模型,并提供基础兼容 Prometheus 的监控。
在第一个版本中,深度学习被有意排除在范围之外。目标是在添加更复杂的建模技术之前,构建一个完整、可复现、可解释且可部署的 ML 系统。
## 范围
- 数据集:UNSW-NB15
- 任务:二分类
- 目标:`label`
- 类别:`0 = 正常 (normal)`,`1 = 攻击 (attack)`
- 基线模型:Logistic Regression
- 主模型:Random Forest
- 服务:FastAPI
- 监控:Prometheus 指标以及简单的 HTML 监控页面
- 容器化:Docker 和 Docker Compose
## 架构
```
UNSW-NB15 CSV files
|
v
Data loading and feature split
|
v
Preprocessing pipeline
- numeric features passthrough/scaling depending on model
- categorical one-hot encoding
|
v
Model training
- Logistic Regression baseline
- Random Forest main model
|
v
Saved scikit-learn pipeline
|
v
FastAPI inference service
|
v
/predict, /health, /metadata, /metrics, /monitoring
```
## 项目结构
```
network-anomaly-detector/
├── app/ # FastAPI app, inference service and monitoring
├── docs/ # Portfolio screenshots and documentation assets
├── data/ # Local data folder, raw data is not committed
├── models/ # Metadata is tracked, binary models are ignored
├── notebooks/ # Exploratory notebooks
├── reports/ # Dataset, training, analysis and dashboard outputs
├── src/ # Data loading, preprocessing, training and evaluation
├── tests/ # API, contract and ML pipeline tests
├── CHANGELOG.md
├── CITATION.cff
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── RESPONSIBLE_USE.md
├── SECURITY.md
├── docker-compose.yml
├── pyproject.toml
├── pytest.ini
├── requirements-dev.txt
├── requirements.txt
└── README.md
```
## 数据集
本项目需要官方预先划分好的 UNSW-NB15 CSV 文件:
```
UNSW_NB15_training-set.csv
UNSW_NB15_testing-set.csv
```
默认情况下,代码会在以下位置查找数据集:
```
../UNSW-NB15 dataset/CSV Files/Training and Testing Sets/
```
如果您的数据集存储在其他位置,请设置:
```
export UNSW_NB15_DATA_DIR="/path/to/Training and Testing Sets"
```
当前运行中使用的数据集摘要:
- 训练行数:175,341
- 测试行数:82,332
- 输入特征:42
- 数值特征:39
- 类别特征:`proto`, `service`, `state`
- 目标列:`label`
- 排除的列:`id`, `attack_cat`
`attack_cat` 被排除在二分类模型输入之外,因为它直接描述了攻击类别,并且会将目标相关信息泄漏到特征集中。
请参阅 [reports/dataset_overview.md](reports/dataset_overview.md)。
## 项目文档
## 数据集引用
本项目使用 UNSW-NB15 数据集。官方 UNSW 数据集页面指出,数据集的学术或公共使用应引用数据集作者列出的五篇论文:
- 官方数据集页面:[UNSW-NB15 数据集](https://research.unsw.edu.au/projects/unsw-nb15-dataset)
所需的 UNSW-NB15 引用:
1. Moustafa, N., 和 Slay, J. "UNSW-NB15: a comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set)." Military Communications and Information Systems Conference (MilCIS), IEEE, 2015.
2. Moustafa, N., 和 Slay, J. "The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 dataset and the comparison with the KDD99 dataset." Information Security Journal: A Global Perspective, 2016.
3. Moustafa, N., 等 "Novel geometric area analysis technique for anomaly detection using trapezoidal area estimation on large-scale networks." IEEE Transactions on Big Data, 2017.
4. Moustafa, N., 等 "Big data analytics for intrusion detection system: statistical decision-making using finite Dirichlet mixture models." Data Analytics and Decision Support for Cybersecurity, Springer, 2017.
5. Sarhan, M., Layeghy, S., Moustafa, N., 和 Portmann, M. "NetFlow Datasets for Machine Learning-Based Network Intrusion Detection Systems." Big Data Technologies and Applications, Springer Nature, 2020.
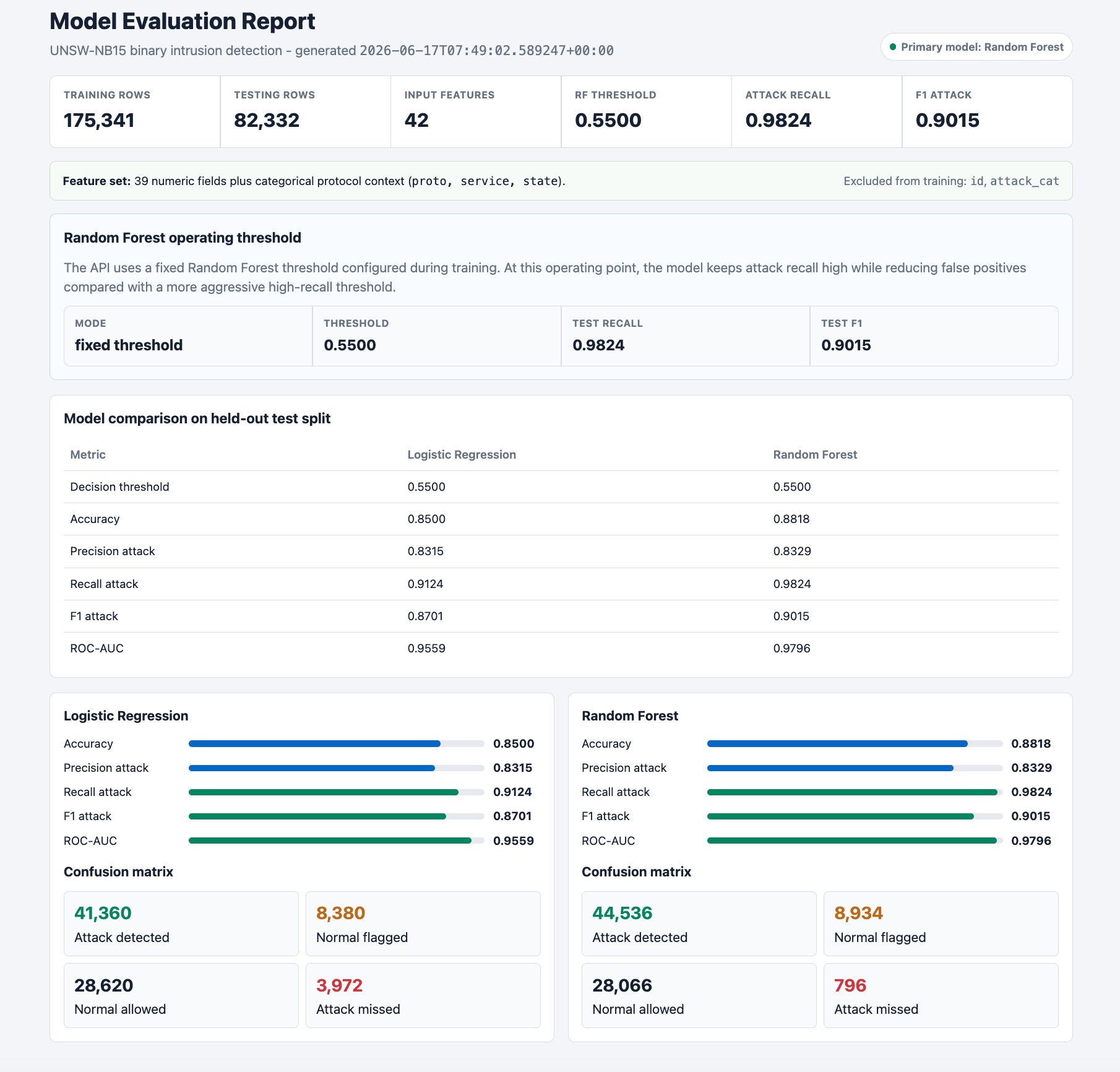
## 当前结果
当前的模型构件是在 `0.55` 的操作决策阈值下训练的。
| 模型 | 阈值 | 准确率 (Accuracy) | 攻击精确率 (Precision attack) | 攻击召回率 (Recall attack) | 攻击 F1 分数 (F1 attack) | ROC-AUC |
| --- | ---: | ---: | ---: | ---: | ---: | ---: |
| Logistic Regression | 0.55 | 0.8500 | 0.8315 | 0.9124 | 0.8701 | 0.9559 |
| Random Forest | 0.55 | 0.8818 | 0.8329 | 0.9824 | 0.9015 | 0.9796 |
Random Forest 是主模型,因为它在此版本中提供了最强的整体测试集性能,尤其是在攻击召回率和 F1 分数上。
在 `0.55` 的阈值下,测试集上的 Random Forest 混淆矩阵为:
| 结果 | 数量 |
| --- | ---: |
| 真负例 (True negative) | 28,066 |
| 假正例 (False positive) | 8,934 |
| 假负例 (False negative) | 796 |
| 真正例 (True positive) | 44,536 |
该阈值是一个精心选择的操作点:与 `0.45` 等更激进的阈值相比,它保持了较高的攻击召回率,同时减少了误报的数量。
详细报告:
- [reports/training_results.md](reports/training_results.md)
- [reports/training_dashboard.html](reports/training_dashboard.html)
- [reports/random_forest_analysis.md](reports/random_forest_analysis.md)
- [reports/random_forest_threshold_analysis.csv](reports/random_forest_threshold_analysis.csv)
- [reports/random_forest_feature_importance.csv](reports/random_forest_feature_importance.csv)
- [reports/random_forest_grouped_feature_importance.csv](reports/random_forest_grouped_feature_importance.csv)
## 截图
下面的截图展示了主要的评估报告、FastAPI 文档、成功的 `/predict` 请求以及运行时监控页面。
### 模型评估报告
### API 文档
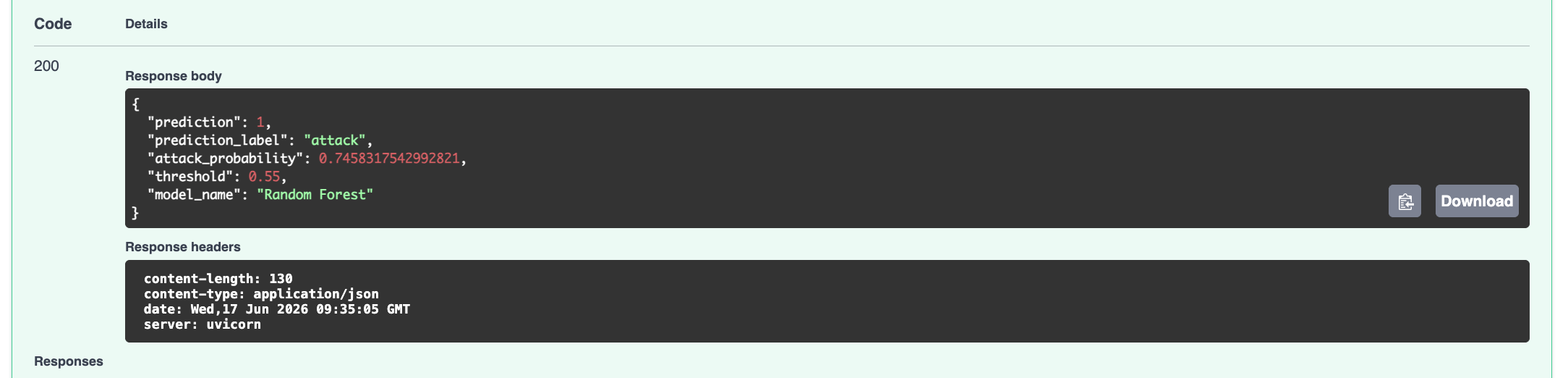
### 成功的预测请求
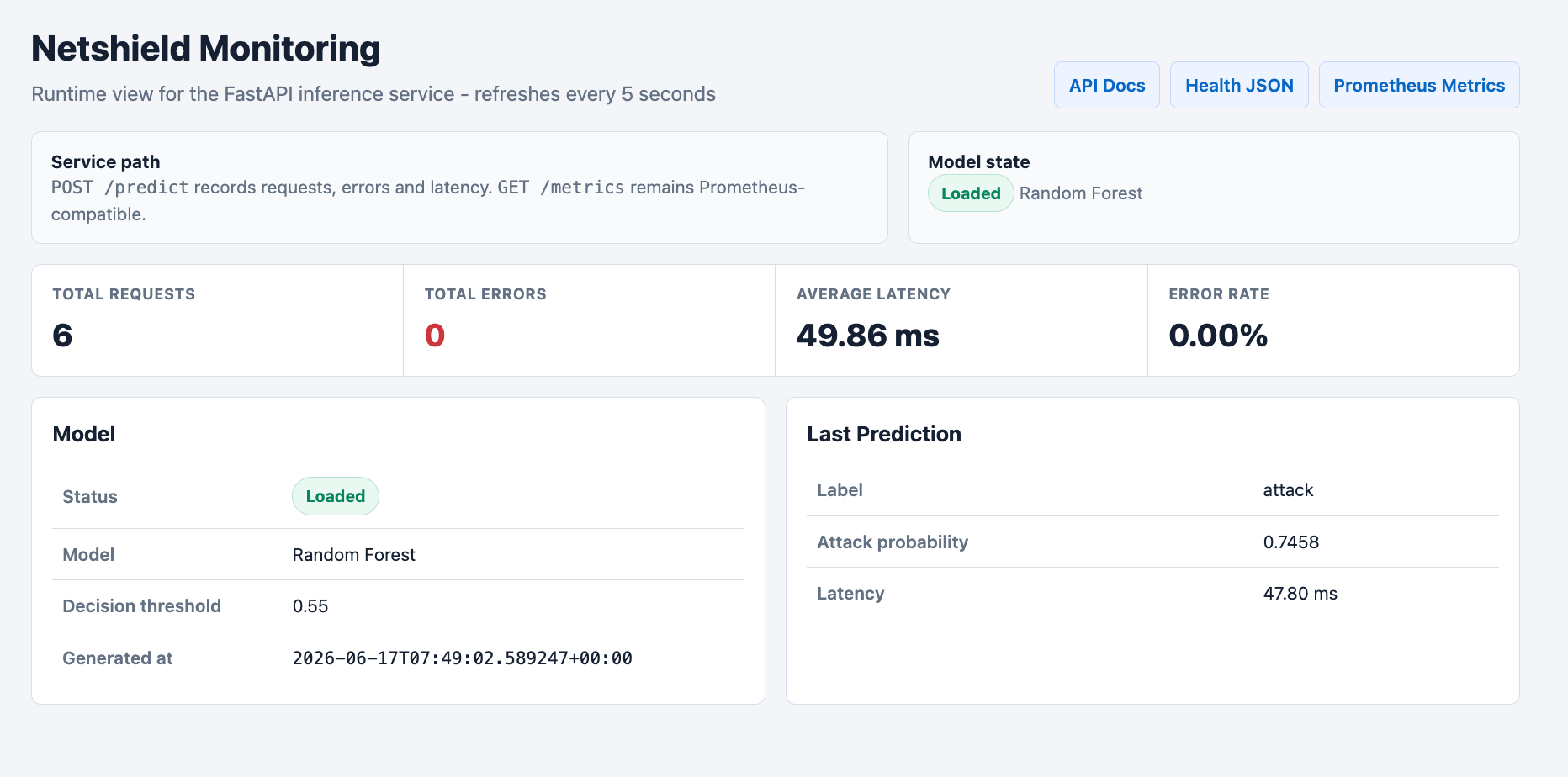
### 监控仪表板
## Random Forest 解读
Random Forest 分析包括:
- 阈值比较
- 操作阈值下的错误特征
- 转换后的特征重要性
- 针对 one-hot 编码类别特征的分组特征重要性
当前排名前列的分组特征包括:
- `sttl`
- `ct_state_ttl`
- `sload`
- `rate`
- `dload`
- `state`
- `dpkts`
- `sbytes`
- `dttl`
- `smean`
特征重要性对于模型检查很有用,但不应将其解释为因果证据。它仅描述了这个经过训练的 Random Forest 如何使用可用特征。
## 安装设置
推荐使用 Python 3.12。
```
git clone https://github.com/Sukulli/Network-Anomaly-Detector.git
cd network-anomaly-detector
python3.12 -m venv .venv
source .venv/bin/activate
pip install -r requirements-dev.txt
```
`requirements.txt` 包含用于训练、生成报告和提供 API 服务的运行时依赖。
`requirements-dev.txt` 包含运行时依赖,以及本地开发和测试工具。
Docker 有意仅安装 `requirements.txt`。
代码质量工具在 `pyproject.toml` 中配置。
验证环境:
```
python --version
python -c "import pandas as pd; import sklearn; print(pd.__version__, sklearn.__version__)"
```
## 训练
使用当前的操作阈值训练两个模型:
```
python -m src.train --model both --threshold 0.55
```
这将写入:
- `models/logistic_regression_model.pkl`
- `models/random_forest_model.pkl`
- `models/model.pkl`
- `models/metadata.json`
- `reports/training_results.md`
- `reports/training_results.json`
生成 HTML 训练仪表板:
```
python -m src.visualize_results
```
生成 Random Forest 分析:
```
python -m src.analyze_random_forest
```
在分层采样的数据上进行快速冒烟训练:
```
python -m src.train --model both --sample-size 5000 --no-save --reports-dir /tmp/netshield-smoke-reports
```
对 Random Forest 进行可选的阈值搜索:
```
python -m src.train --model both --threshold 0.55 --auto-threshold
```
最终项目目前使用的是固定阈值 `0.55`,而不是自动阈值模式。
## 在本地运行 API
请首先确保模型文件存在。如果 `models/model.pkl` 缺失,请运行训练命令。
```
uvicorn app.main:app --host 127.0.0.1 --port 8000
```
打开:
```
http://127.0.0.1:8000/docs
```
可用的 endpoint:
| Endpoint | 方法 | 用途 |
| --- | --- | --- |
| `/health` | GET | 服务和模型状态 |
| `/metadata` | GET | 服务暴露的数据集、模型和训练元数据 |
| `/predict` | POST | 对一条网络流记录进行二分类预测 |
| `/metrics` | GET | 兼容 Prometheus 的原始指标 |
| `/monitoring` | GET | 人类可读的监控仪表板 |
| `/monitoring/snapshot` | GET | 以 JSON 格式返回监控状态 |
如果模型构件缺失或无法加载,API 将以 `degraded`
(降级)模式启动。在这种状态下,`/health` 保持可用,而 `/predict` 会返回
结构化的 `503` 响应,而不是因未处理的服务器错误而崩溃。
健康检查:
```
curl http://127.0.0.1:8000/health
```
元数据:
```
curl http://127.0.0.1:8000/metadata
```
使用包含的示例请求进行预测:
```
curl -X POST http://127.0.0.1:8000/predict \
-H "Content-Type: application/json" \
--data @reports/sample_prediction_request.json
```
响应示例:
```
{
"prediction": 1,
"prediction_label": "attack",
"attack_probability": 0.7458317542992821,
"threshold": 0.55,
"model_name": "Random Forest"
}
```
模型不可用时的响应示例:
```
{
"error": "model_not_loaded",
"message": "Model is not loaded. Train or restore the model artifact first.",
"status_code": 503
}
```
## Docker
构建并运行服务:
```
docker compose up --build
```
然后打开:
```
http://127.0.0.1:8000/docs
http://127.0.0.1:8000/health
http://127.0.0.1:8000/monitoring
```
停止容器:
```
docker compose down
```
重要提示:模型二进制文件不应提交到 Git。如果您在新的机器上克隆了该代码库,请在启动 API 或构建 Docker 镜像之前训练模型。
## 测试
首先安装开发依赖:
```
pip install -r requirements-dev.txt
```
运行:
```
pytest -q
```
运行静态检查和格式化验证:
```
ruff check app src tests
ruff format --check app src tests
```
GitHub Actions 会在每次推送到 `main` 分支和针对 `main` 的 Pull Request 时运行相同的测试套件和代码质量检查。
因为经过训练的模型二进制文件被有意排除在 Git 之外,CI 会运行不依赖模型的契约测试,并跳过依赖模型的 API 测试,同时给出明确的跳过理由。
当前的测试涵盖:
- `GET /health`
- 有效的 `POST /predict`
- 无效的 `POST /predict` payload
- 当模型构件不可用时 API 的降级行为
- 结构化的 API 错误响应
- `GET /metrics`
- `GET /monitoring`
- `GET /monitoring/snapshot`
- API schema、示例请求和元数据契约
- 运行时/开发依赖文件的分离
- README 中必须包含的 UNSW-NB15 数据集引用
- 通过 GitHub Actions 中的 Ruff 进行 linting 和格式化
- 代码库规范、notebook 有效性和文档契约检查
- ML 数据划分、防止泄漏和特征分组
- 具有未见类别值的预处理行为
- 在合成数据上的 Logistic Regression 和 Random Forest pipeline 冒烟测试
- 阈值选择和不保存训练的冒烟工作流
API 测试需要 `models/model.pkl`。如果模型缺失,请先训练模型。
## GitHub 说明
该代码库配置为避免提交:
- 虚拟环境
- Python 缓存文件
- 本地原始数据集
- 生成的模型二进制文件
- 本地操作系统文件,如 `.DS_Store`
被跟踪的文件应包括源代码、测试、文档、轻量级元数据和轻量级报告构件。
二进制模型文件被有意忽略:
```
models/*.pkl
```
这使得 GitHub 代码库保持轻量级且可复现。模型可以通过以下命令重新生成:
```
python -m src.train --model both --threshold 0.55
```
## 许可证
本代码库中的源代码和项目文档基于 [MIT 许可证](LICENSE) 发布。
此许可证仅适用于本代码库的原始代码和文档。它不授予以下各项的权利:
- UNSW-NB15 数据集
- 从 UNSW 或其他镜像下载的数据集文件
- 生成的模型二进制文件,如 `models/*.pkl`
- `requirements*.txt` 中列出的第三方依赖
本代码库中不重新分发 UNSW-NB15 数据集。用户必须从官方来源获取数据集,并遵守 [数据集引用](#dataset-citation) 中描述的数据集作者的引用要求。
## 引用
如果您使用了本项目,请引用 [CITATION.cff](CITATION.cff) 中的软件元数据,并引用 [数据集引用](#dataset-citation) 中列出的 UNSW-NB15 数据集论文。
软件引用不能替代数据集引用要求。
## 局限性
本项目是一个达到作品集级别的 ML 工程原型,并非生产级别的 IDS。
重要局限性:
- 它对经过预处理的 UNSW-NB15 表格流记录进行二分类,而不是实时数据包检查。
- 它不捕获真实的网络流量。
- 它不执行流式推理。
- 它不包含主动警报、事件响应或安全编排。
- 它不包含 API 上的身份验证或授权。
- 它不包含速率限制。
- 它不包含模型漂移检测。
- 它不包含持续再训练。
- 它不验证在来自真实部署环境的流量上的性能。
- 它不声称在没有进一步验证的情况下能够泛化到现代企业流量。
- 测试集划分是官方的 UNSW-NB15 测试 CSV 文件,因此报告的指标具有数据集特异性。
- 特征重要性具有模型特异性,不应被视为因果解释。
- Random Forest 模型可能相对较大,这就是二进制构件被排除在 Git 之外的原因。
## 路线图
可能的后续改进:
- 添加交叉验证或更清晰的-验证-测试工作流。
- 为 Random Forest 添加更稳健的超参数调优。
- 添加 LightGBM 或 XGBoost 作为额外的经典模型。
- 添加概率校准。
- 添加精确率-召回率曲线可视化。
- 为传入的预测分布添加漂移监控。
- 添加 API 身份验证。
- 添加在小样本上进行训练的 CI,以实现快速验证。
- 添加由 Prometheus 支持的 Grafana 仪表板。
- 将多分类攻击类别分析添加为单独的任务。
- 仅在经典 ML 系统稳定且被充分理解后才添加深度学习。
## 合理使用
本项目旨在用于教育和防御性安全目的。它不应被用作真实网络环境中唯一的安全控制手段。
有关明确的使用规范和滥用边界,请参阅 [RESPONSIBLE_USE.md](RESPONSIBLE_USE.md)。
标签:Apex, AV绕过, Docker, FastAPI, 安全防御评估, 机器学习, 版权保护, 网络安全, 自定义请求头, 请求拦截, 逆向工具, 随机森林, 隐私保护