k3rnel-pan1c-ksd/automated-keystroke-acoustic-attack
GitHub: k3rnel-pan1c-ksd/automated-keystroke-acoustic-attack
该项目通过视频-音频联合分析实现键盘输入的自动化声学侧信道攻击,利用 OCR 自动标注流水线与 CNN 分类器高精度还原击键内容。
Stars: 0 | Forks: 0
# 通过视频-音频联合分析对键盘输入的自动化声学侧信道攻击
[](https://colab.research.google.com/github/k3rnel-pan1c-ksd/automated-keystroke-acoustic-attack/blob/main/ZnanstveniRad_final.ipynb)
Dario Vranješ, Ivo Stančić, Toni Perković, Marin Bugarić
克罗地亚斯普利特大学电气工程、机械工程与造船学院 (FESB)
本仓库发布了针对键盘输入的声学侧信道攻击 (ASCA) 的代码、训练模型和带标签数据集。其核心贡献是一条**自动化 OCR 对齐标注流水线**:通过光学字符识别 (OCR) 处理视频帧来恢复输入的真实字符序列,将音轨分割成以检测到的击键声为中心的片段,并将这两个流进行对齐。随后,使用在 mel 频谱图特征上训练的卷积神经网络 (CNN) 对击键进行分类,而**迁移学习**仅需少量样本即可使预训练模型适应新的用户/会话。
在预留的测试集上,基础 CNN 在真实编程课程中记录的 50 个唯一 QWERTZ 按键上实现了 **98.1% 的 top-1 准确率、99.4% 的 top-2 准确率和 100% 的 top-3 准确率**。即使每个按键仅有 **13 个样本**,迁移学习依然保持了出色的性能。
## README
以下文本描述了流程的每个阶段。其中大部分内容也用于随附的科学论文中。
### 威胁模型
攻击者在打字会话期间同时观察 (i) 目标机器的屏幕和 (ii) 相应的音频——这正是在线课程、屏幕共享会议或公开直播教程的确切条件。无需物理接近、隐藏麦克风或在受害者设备上安装软件;音频通过普通的笔记本电脑麦克风捕获,并且可能会经过会议软件的压缩/降噪处理。OCR 流**仅**用于生成训练声学分类器的真实标签——而不是作为主要的推理信号——这正是本工作与纯基于视频的击键推断的区别所在。
需要修饰键组合(例如 Shift+字母)的按键在训练字母表中没有单独列出;大写/符号处理留待未来的工作解决。
### 输入
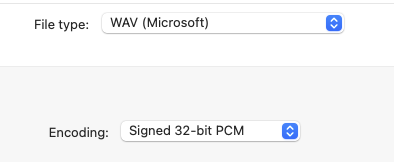
音频使用 Audacity 以 **44.1 kHz** 录制,并导出为 **32-bit PCM** 的 `.wav` 文件。对于每次课程,都捕获了同步的屏幕录像和音频文件。
### 按键检测与分离
每个信号首先被归一化为**单位 RMS** 振幅,以减少音量差异。借鉴 *Don't Skype & Type!*,我们在 **10 ms** 的窗口上计算 STFT,并对其幅度谱求和以获得能量包络。每当能量超过阈值时,即检测到一个按下事件,并提取随后的 **100 ms** 音频作为击键波形(当击键密集排列时,为了避免重叠,会将其缩短)。每个裁剪出的击键都作为单个文件存储。
预期检测/输出形式:

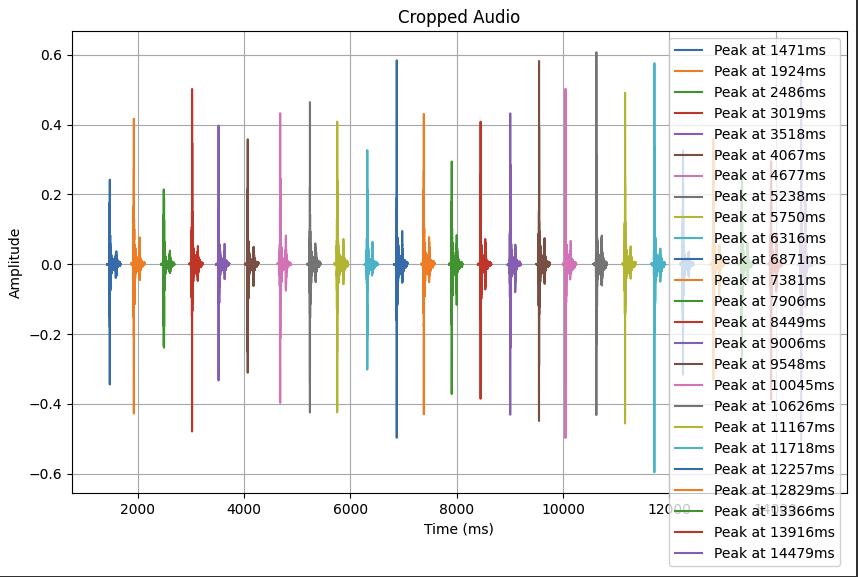
这将生成**两个数据集**:
| 数据集 | 每键样本数 | 用途 | 仓库路径 |
| --- | --- | --- | --- |
| 基础 (泛化) | 125 | 预训练基础模型 | `cropped_base/` |
| 目标 (用户/会话) | 25 | 迁移学习 + 网格搜索 | 重新生成至 `input_sounds_cropped/` |
### 自动标注 (OCR 对齐)
通过对录制的视频帧运行 OCR 来恢复输入的字符序列,并将其与音频中检测到的点击事件进行对齐,从而以最少的人工工作量生成大规模带标签的击键数据集。这消除了限制以往 ASCA 可扩展性和可重复性的手工标注瓶颈。
### 实际演示 —— 浏览器中的自动标注
🔗 **在线体验:[auto-key-practical.vercel.app](https://auto-key-practical.vercel.app/)**
传统上,构建击键声学数据集意味着**手动将每个击键声音与其对应的按键配对**——听录音并逐一手动标记每次点击。这不仅速度慢、容易出错,也是以往攻击无法规模化的主要原因。
我们用一个**自动标注流程**取代了这一手动步骤:该工具检测音频中的每次点击,通过 OCR 从视频中恢复输入的字符,并对齐这两个流,使得每个孤立的击键声音都能自动标记上其真实的按键——无需人工标注。网络演示允许您端到端地运行此过程,并观察击键是如何被自动检测、分割和标注的,这展示了为本仓库中 CNN 训练提供数据的数据采集流水线。
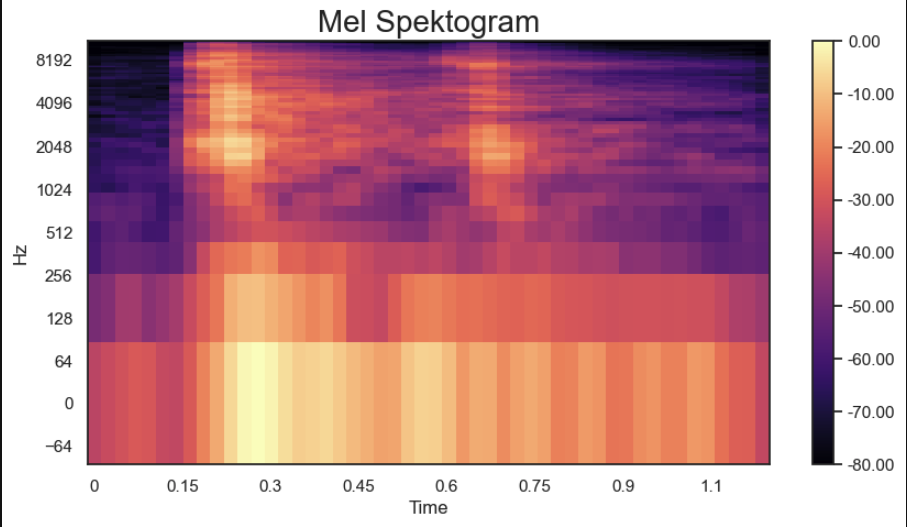
### 特征提取
每个裁剪出的击键都被转换为 **log-mel 频谱图**。由于丢弃频率可能会丢失相关的非语音信息,MFCC 被拒绝使用;相反,我们保留了原始的 mel 频谱图。
| 参数 | 值 |
| --- | --- |
| Mel 频带 | 64 |
| FFT 窗口大小 | 1024 |
| Hop length | 225 |
```
def extract_features(file_name):
audio_signal, sample_rate = librosa.load(file_name, sr=None)
mel_spec = librosa.feature.melspectrogram(
y=audio_signal, sr=sample_rate,
n_fft=1024, hop_length=225, n_mels=64)
return librosa.power_to_db(mel_spec, ref=np.max)
```
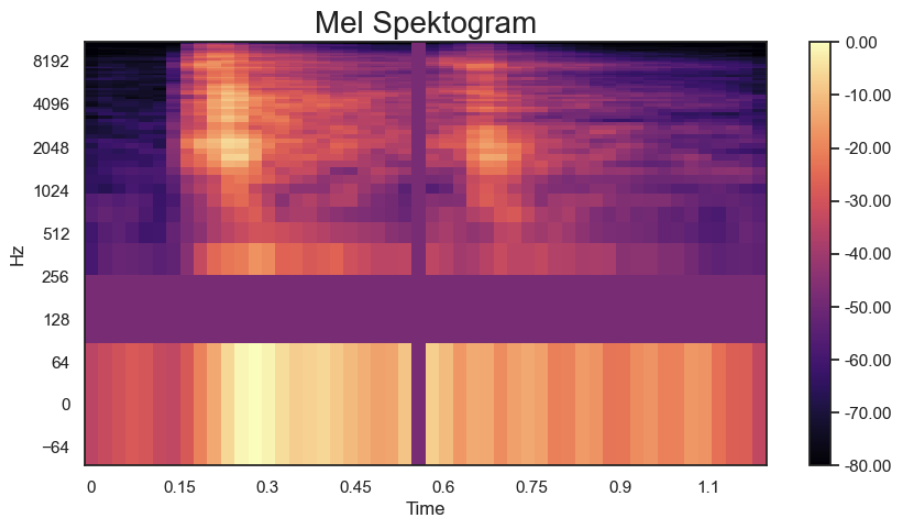
**SpecAugment** 被用作数据增强:时间轴上的随机频带和频率轴上的随机频带被设置为频谱图的平均值(“遮挡”图像的一部分),从而鼓励模型进行泛化。
```
def spec_augment(mel_spectrogram):
num_freqs, num_frames = mel_spectrogram.shape
mean_value = mel_spectrogram.mean()
f0 = np.random.randint(0, num_freqs) # frequency mask
mel_spectrogram[f0:f0 + 1, :] = mean_value
t0 = np.random.randint(0, num_frames) # time mask
mel_spectrogram[:, t0:t0 + 1] = mean_value
return mel_spectrogram
```
### CNN 架构
该网络采用**因式分解卷积**设计直接在 mel 频谱图上运行。每个模块首先应用 `3 × 3` 卷积来捕获局部的时间-频率模式,随后通过 `3 × 1` 和 `1 × 3` 卷积将时间与频谱特征学习解耦。所有卷积层均使用 ReLU 和 `same` 填充;初始层省略了偏置项。`(2 × 1)` 最大池化降低了时间分辨率,同时保留了频率分辨率。第二个模块增加了滤波器以捕获更多抽象特征。卷积阶段之后依次是:dropout (0.2) → flatten → dense (ReLU) → batch normalisation → dropout (0.4) → softmax。优化使用 **Adam** 和分类交叉熵。
### 超参数搜索与模型选择
网格搜索(54 种配置)探索了:
| 参数 | 值 |
| --- | --- |
| 滤波器 (f1, f2) | (32,64), (64,64), (64,128) |
| Dense units | 128, 256 |
| Dropout (卷积) | 0.2 (固定) |
| Dropout (全连接) | 0.2, 0.3, 0.4 |
| Learning rate | 1e-3, 3e-4, 1e-4 |
配置按**验证集 macro-F1** 排名。在平衡验证集性能和测试集泛化能力后,论文在所有后续实验中采用**配置 13** —— 滤波器 `(32,64)`,256 个 dense units,dense dropout `0.4`,learning rate `1e-3` ——(这是相对于 F1 略高但体积更大的网格搜索获胜者的一种刻意选择)。
### 模型训练
数据被划分为 **80% 训练 / 10% 验证 / 10% 测试**,其中测试集在开发期间完全不可见。标签先进行 label-encoded,然后进行 one-hot 编码。
在合并的训练+验证数据上运行**分层五折交叉验证**(50 个 epoch,batch size 为 32,Adam lr 1e-3;每折模型中验证损失最低的模型被保留)。固定的随机种子 (42) 用于打乱、分割和权重初始化。最后,在完整的训练+验证集上训练最终模型,并在预留的测试集上进行一次评估。
软件栈:Python 3.10, TensorFlow 2.15, NumPy 1.26, librosa 0.10, scikit-learn 1.3。
训练在 MacBook Pro(Apple M2,8 GB RAM,无 GPU)上运行;一次完整的 50 个 epoch 运行耗时不到 2 分钟,包含五折交叉验证和最终重训练约需 8 分钟。
### 评估
性能使用 **top-k 准确率 (k = 1–5)**、**宏平均 F1** 和**基于熵的指标**(相对于类别上均匀先验的熵减少量,用于量化分类器对单个按键的判定有多尖锐)进行报告。
基础模型(125 个样本/按键)是一个**理想化的上界参考** —— 一个大型的、同质的单会话数据集 —— 并且在设计上实现了非常高的准确率:
| 指标 | Top-1 | Top-2 | Top-3 |
| --- | --- | --- | --- |
| 基础模型 (预留测试集) | 98.1% | 99.4% | 100% |
### 迁移学习
对于现实的、数据受限的攻击,预训练的卷积特征提取器被**冻结**,仅在目标数据集上重新训练一个紧凑的分类头。适配后的模型拥有约 663 万个参数,其中仅有约 22,575 个(<1%)可训练,这极大地减少了过拟合。重训练(50 个 epoch,Adam)在不到一分钟内即可收敛。
每个按键仅有 **13 个样本**时,适配后的模型在预留测试集上就已经达到了约 85% 的 top-1、约 95% 的 top-3 和约 99% 的 top-5 准确率,随后会出现提前饱和。
### 在未见数据上的测试
该流水线在未见过的击键序列 `diplomski123@` 上进行了端到端的演示。未见过的片段使用**迁移模型**(其 47 个按键的字母表与输入文本匹配)进行分类,而不是基础模型。
## 仓库内容 / 运行方式
完整的分析以单个 notebook 提供:**`ZnanstveniRad_final.ipynb`**。
请从上到下运行各部分:
0. **设置** —— 克隆数据集仓库,安装依赖项,导入(种子 42)。
1. **数据收集与标注** —— 点击检测 + 裁剪 → `input_sounds_cropped/`。
2. **特征提取** —— log-mel 频谱图 + SpecAugment。
3. **CNN 架构** + 超参数网格搜索(表 2–3)。
4. **基础模型** —— 5 折交叉验证,top-k 准确率,熵减少 → `keystroke_cnn_model.keras`。
5. **迁移学习** → `keystroke_transfer_model.keras`。
6. **在未见数据上测试** —— `diplomski123@` 演示。
在运行之前,请将第 0 节中的克隆 URL 指向您自己的数据集仓库副本,并将 125 个样本/按键的基础数据集作为 `cropped_base/` 上传(克隆后它会在 `input-sounds/cropped_base/` 中暴露)。
包含所有代码、训练模型、超参数网格搜索 CSV 和随机种子,以支持完全可复现的研究。
标签:Apex, 侧信道攻击, 声学分析, 机器学习, 计算机视觉, 逆向工具, 音频处理