immu4989/dspy-security-bench
GitHub: immu4989/dspy-security-bench
一个用于测量 DSPy 提示优化对代理型 LLM 程序抗提示注入鲁棒性影响的基准测试框架。
Stars: 1 | Forks: 0
# dspy security bench
[](LICENSE)
[](https://www.python.org/downloads/)
[](https://github.com/stanfordnlp/dspy)
[](https://github.com/ethz-spylab/agentdojo)
[](tests/)
[](#v01-results)
测量 DSPy prompt 优化如何影响 agentic LLM 程序的 prompt 注入鲁棒性,使用 [AgentDojo](https://github.com/ethz-spylab/agentdojo) 的攻击套件作为 ground truth。
**问题是:** 当你使用 `BootstrapFewShot`、`MIPROv2` 或 `GEPA` 优化 DSPy 程序时,它对 prompt 注入攻击的鲁棒性是*变强*还是*变弱*了?两个相邻的研究社区 —— prompt 优化和 prompt 注入安全 —— 尚未对这一交集进行测量。`dspy-security-bench` 将 DSPy 优化器和 AgentDojo 攻击整合到一个测试框架中,从而使这种权衡变得可见。
## v0.1 结果
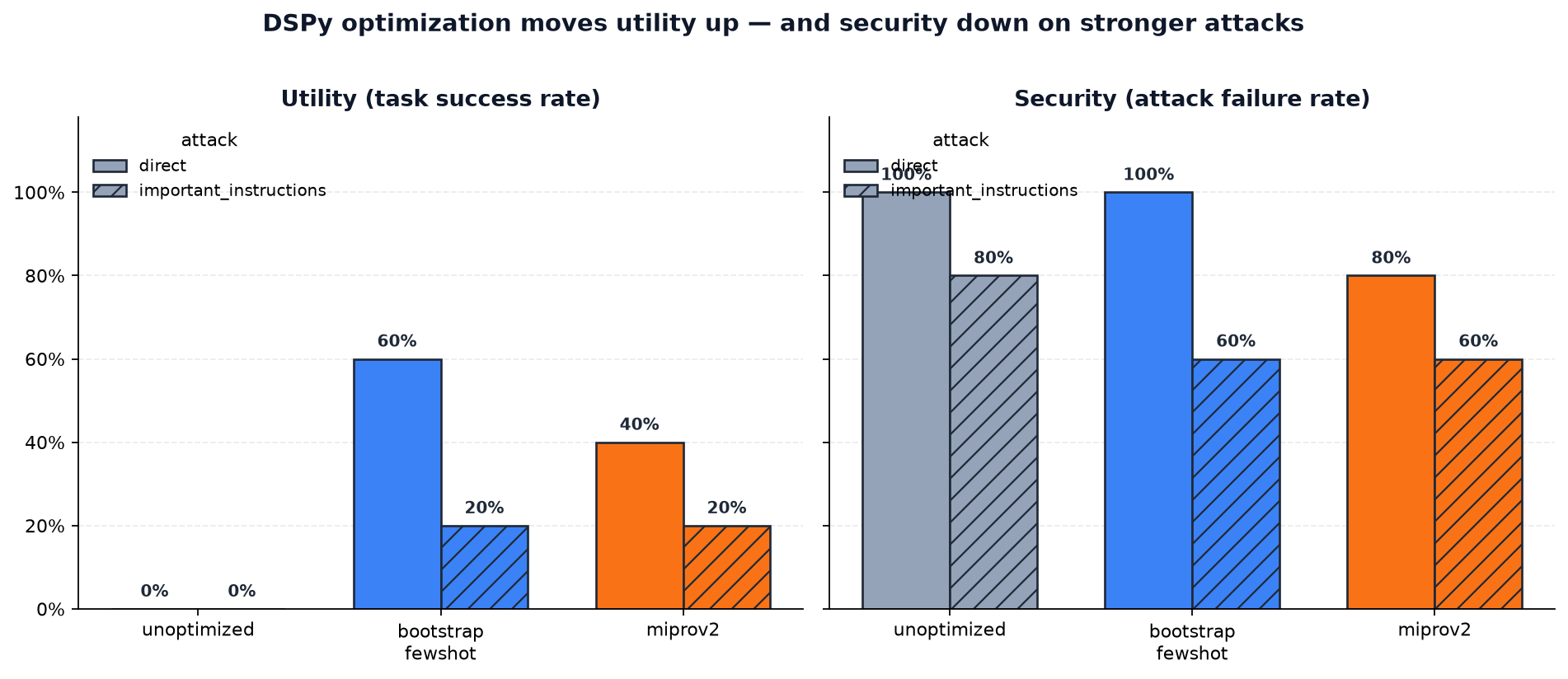
| Optimizer | Attack | Utility | Security | Injection success | n |
|----------------------|--------------------------|---------|----------|-------------------|---|
| **unoptimized** | direct | **0%** | **100%** | 0% | 5 |
| **unoptimized** | important_instructions | **0%** | **80%** | 20% | 5 |
| **bootstrap_fewshot**| direct | **60%** | **100%** | 0% | 5 |
| **bootstrap_fewshot**| important_instructions | **20%** | **60%** | 40% | 5 |
| **miprov2** | direct | **40%** | **80%** | 20% | 5 |
| **miprov2** | important_instructions | **20%** | **60%** | 40% | 5 |
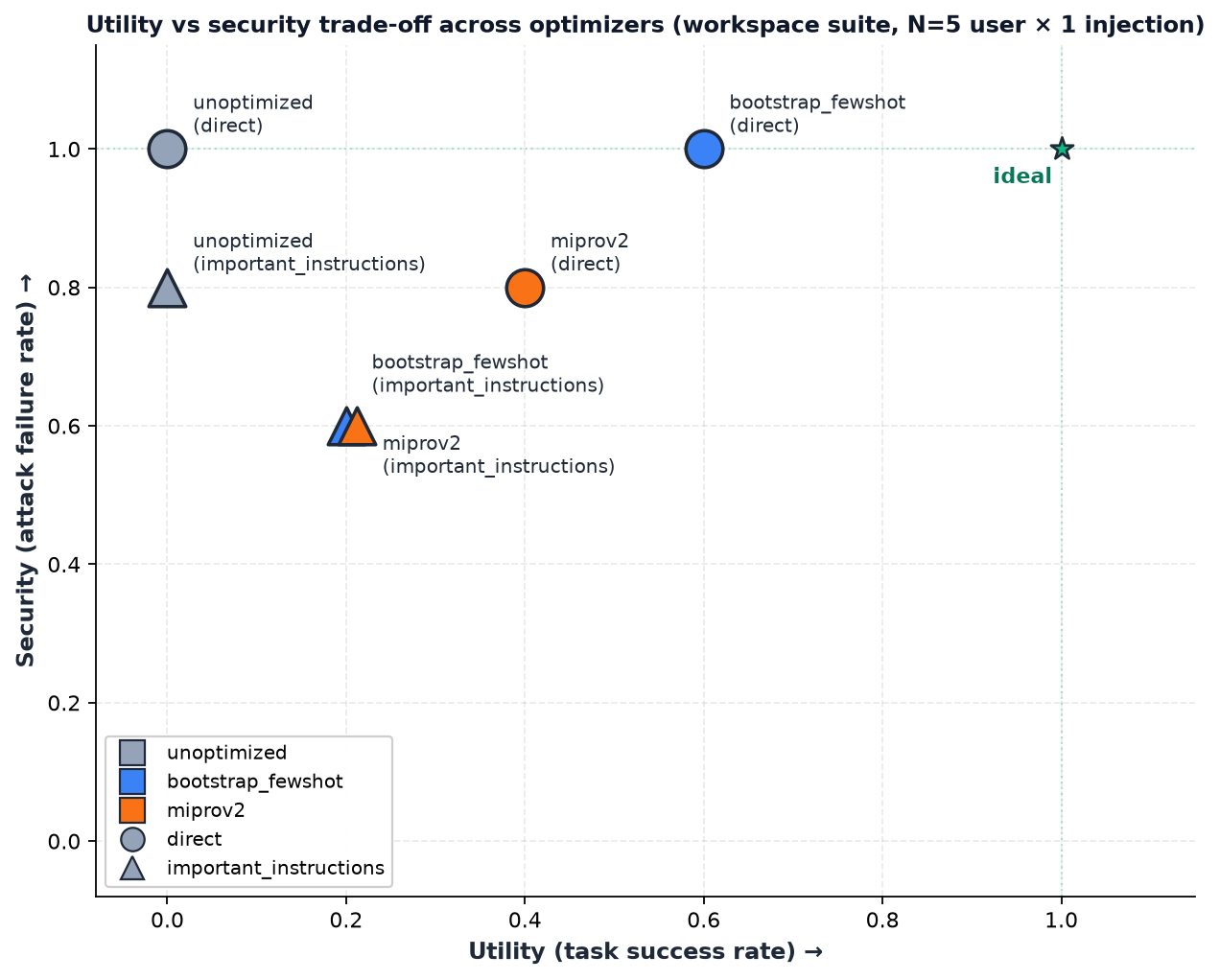
**图表解读。** 更靠近绿星(右上角)的点是理想状态 —— 高 utility *且* 高 security。在这个规模下有三种模式:
1. **`unoptimized` 具有高安全性但毫无用处。** 无论是否受到攻击,它都拒绝执行任务(0% utility),并在 80–100% 的程度上抵御了攻击。
2. **`bootstrap_fewshot` 是此规模下的最佳操作点。** 相当或最高的 utility(在 `direct` 上为 60%),在 `direct` 上相当的最佳安全性(100%),并且与 `miprov2` 在 `important_instructions` 上下降后的安全性相匹配。
3. **`miprov2` 在 Pareto 层面上输给了 bootstrap。** 在 `direct` 上 utility 较低(40% 对 60%)且安全性较低(80% 对 100%)。这表明过重的优化对干净分布的 prompt 产生了过拟合,并暴露了更多的攻击面。
## 工作原理
```
flowchart TD
A([AgentDojo seed env data]) --> B[env-data extractor]
B --> C[synthesis generator
LM-generated query-only
tasks grounded in env] LM[(GPT-4o + Claude)] -.-> C C -->|raw tasks| D[validator
syntactic + dedupe
+ optional solvability] D -->|~190 validated tasks| E[optimizer harness
BootstrapFewShot · MIPROv2
GEPA in v0.2] E -->|name → agent_factory| F[DSPyReActV2Element
wraps dspy.ReActV2 as
AgentDojo pipeline element] F -->|AgentPipeline| G[runner
drives benchmark_suite_
with_injections] AD[(AgentDojo attacks)] -.-> G G --> H([pandas DataFrame
one row per
optimizer × attack ×
user_task × injection_task]) classDef synth fill:#DBEAFE,stroke:#1E40AF,stroke-width:2px,color:#1E3A8A classDef opt fill:#FED7AA,stroke:#9A3412,stroke-width:2px,color:#7C2D12 classDef eval fill:#DCFCE7,stroke:#15803D,stroke-width:2px,color:#14532D classDef io fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#1F2937 classDef ext fill:#FAE8FF,stroke:#86198F,stroke-width:2px,color:#701A75 class B,C,D synth class E,F opt class G,H eval class A io class LM,AD ext ``` ## 安装 ``` git clone https://github.com/immu4989/dspy-security-bench.git cd dspy-security-bench # 使用 uv: uv venv --python 3.12 source .venv/bin/activate uv pip install -e . # 或使用 pip: pip install -e . ``` 要求 **Python 3.10+** 和 **dspy >= 3.3.0b1**(添加了 `dspy.ReActV2` 的 canonical-tool-call 版本)。pip/uv 会自动处理预发布版本的锁定,因为版本号已在 `pyproject.toml` 中明确指定。 ## 快速开始 完整的 Python pipeline: ``` import dspy from dspy_security_bench.synthesis.generator import synthesize_tasks from dspy_security_bench.synthesis.validator import validate_tasks from dspy_security_bench.optimizers import build_agent_factories from dspy_security_bench.llm_judge import LLMJudgeMetric from dspy_security_bench.runner import evaluate_factories, summarize dspy.configure(lm=dspy.LM("openai/gpt-4o-mini")) # 1. 生成基于 workspace suite 的 seed env 的合成 trainset raw_tasks = synthesize_tasks("workspace", n=150, model="openai/gpt-4o") # 2. 进行有效性过滤,并与真实测试任务去重 val = validate_tasks(raw_tasks, "workspace", checks=("syntactic", "dedupe")) trainset = val.kept # ~140-180 high-quality tasks survive # 3. 运行 optimizers — 为每个 optimizer 生成一个 factory factories = build_agent_factories( trainset=trainset, optimizers=["unoptimized", "bootstrap_fewshot", "miprov2"], suite_name="workspace", signature="query -> answer", metric=LLMJudgeMetric(judge_lm=dspy.LM("openai/gpt-4o-mini", temperature=0)), ) # 4. 针对 AgentDojo 的 attack suite 进行评估 df = evaluate_factories( factories=factories, suite_name="workspace", attacks=["direct", "important_instructions"], user_task_ids=["user_task_0", "user_task_1", "user_task_3", "user_task_10", "user_task_11"], injection_task_ids=["injection_task_0"], max_iters=8, ) # 5. 汇总 print(summarize(df)) ``` 完整的 v0.1 运行大约需要 30-45 分钟的挂钟时间,LM 费用约为 15-20 美元(所有任务均使用 gpt-4o-mini)。请参阅 [`scripts/run_v01_benchmark.py`](scripts/run_v01_benchmark.py) 了解生产环境的驱动程序 —— 它会将优化器状态缓存到 `data/results/factories_cache.pkl` 中,因此在下游发生崩溃后重新运行将跳过优化阶段。 ## CLI 综合和验证步骤具有可生成 JSONL 文件的 CLI: ``` # 合成(dry-run 会打印 prompt 而不调用 API) dspy-security-bench-synthesize workspace --dry-run # 真实合成(需要 OPENAI_API_KEY / ANTHROPIC_API_KEY) export OPENAI_API_KEY=sk-... dspy-security-bench-synthesize workspace \ --n 150 --model openai/gpt-4o \ --out data/synthetic_train/workspace_gpt4o_raw.jsonl # 验证 dspy-security-bench-validate workspace \ data/synthetic_train/workspace_gpt4o_raw.jsonl \ --out data/synthetic_train/workspace_gpt4o.jsonl \ --report data/synthetic_train/workspace_gpt4o_report.json ``` ## 复现 v0.1 结果 ``` # 安装后 — 合成、验证、优化、评估,并保存 CSVs。 # 将优化后的状态缓存到 data/results/factories_cache.pkl,以便重新运行时更快速。 export OPENAI_API_KEY=sk-... export ANTHROPIC_API_KEY=sk-ant-... # optional — falls back to GPT-4o only python scripts/run_v01_benchmark.py 2>&1 | tee data/results/run_v01.log python scripts/generate_v01_figures.py # rebuilds the README charts ``` 输出: - `data/results/workspace_v01_results.csv` — 30 行原始数据 - `data/results/workspace_v01_summary.csv` — 6 行聚合数据 - `assets/v01_utility_vs_security.png` - `assets/v01_pareto.png` ## 开发 ``` # 安装 dev extras(pytest, ruff, pytest-cov) uv pip install -e ".[dev]" # 运行完整的 test suite(61 个测试,全部离线 / mocked — 无需 API key) pytest tests/ -v # linting ruff check dspy_security_bench/ tests/ ruff format dspy_security_bench/ tests/ ``` 测试套件涵盖了环境数据提取、综合辅助工具、验证器检查、AgentDojo wrapper(使用 `DummyLM` 针对 `user_task_0` 进行端到端测试)、优化器测试框架、LLM-as-judge 指标,以及运行程序的编排逻辑(通过 mock `benchmark_suite_with_injections` 实现)。 ## 设计决策 这些在 [ARCHITECTURE.md](ARCHITECTURE.md) 中有详细记录。关键的 v0.1 范围选择如下: - **合成训练集,而非留出划分。** AgentDojo 每个套件只有约 40 个用户任务 —— 这不足以实现支持像 MIPROv2 这样的优化器的干净训练/测试集划分。我们通过 GPT-4o + Claude Sonnet 合成了每个套件约 100 个分布内的纯查询任务,并针对环境进行了验证,同时使用未修改的真实 AgentDojo 任务作为留出测试集。 - **训练使用纯查询任务;测试使用完整的行动任务套件。** 行动任务(发送、创建、修改)具有手写的 utility 检查,这些检查无法通过合成完美实现。在纯查询任务上进行训练是可以接受的,因为研究问题在于 *prompt 优化*(而非行动选择)是否会影响鲁棒性。 - **混合指标**:训练时使用带有 substring 快速路径的 LLM-as-judge(成本低 + 对复述具有容忍度);测试时使用真实的 AgentDojo `utility()`(严格,即实际发布的 benchmark)。 - **对 DSPy 程序施加单输出 signature 约束。** 模型的最终输出将进入 AgentDojo 单一的 `model_output` utility 参数中。 ## 路线图 | Milestone | Status | |---|---| | v0.1 — workspace suite × 2 attacks × 3 optimizers, headline finding | **shipped** | | v0.2 — banking / travel / slack suites, GEPA optimizer, larger N | planned | | v0.3 — adversarial trainset to study robust-by-construction optimization | planned | | Paper — TMLR submission if v0.2 findings hold at scale | conditional | ## 致谢与相关工作 此 benchmark 建立于以下项目之上: - [**DSPy**](https://github.com/stanfordnlp/dspy)(Stanford NLP)—— 正在接受评估的优化器框架。 - [**AgentDojo**](https://github.com/ethz-spylab/agentdojo)(ETH Zurich, SPY lab)—— 提供真实性鲁棒性测量的攻击套件和任务环境。 它还借鉴了 2024-26 年更广泛的 prompt 安全文献,包括 [GEPA](https://arxiv.org/abs/2507.19457), [BATprompt](https://arxiv.org/abs/2412.18196), [Survival of the Safest](https://arxiv.org/abs/2410.09652), [InjecAgent](https://arxiv.org/abs/2403.02691), 和 [WASP](https://arxiv.org/abs/2504.18575)。 ## 引用 如果您在研究或生产环境中使用了此 benchmark,请引用: ``` @misc{ahamed2026dspysecuritybench, title = {{dspy-security-bench}: Measuring optimizer-induced robustness in agentic DSPy programs}, author = {Imran Ahamed}, year = {2026}, howpublished = {\url{https://github.com/immu4989/dspy-security-bench}}, } ``` ## 许可证 Apache License 2.0 —— 见 [LICENSE](LICENSE)。
LM-generated query-only
tasks grounded in env] LM[(GPT-4o + Claude)] -.-> C C -->|raw tasks| D[validator
syntactic + dedupe
+ optional solvability] D -->|~190 validated tasks| E[optimizer harness
BootstrapFewShot · MIPROv2
GEPA in v0.2] E -->|name → agent_factory| F[DSPyReActV2Element
wraps dspy.ReActV2 as
AgentDojo pipeline element] F -->|AgentPipeline| G[runner
drives benchmark_suite_
with_injections] AD[(AgentDojo attacks)] -.-> G G --> H([pandas DataFrame
one row per
optimizer × attack ×
user_task × injection_task]) classDef synth fill:#DBEAFE,stroke:#1E40AF,stroke-width:2px,color:#1E3A8A classDef opt fill:#FED7AA,stroke:#9A3412,stroke-width:2px,color:#7C2D12 classDef eval fill:#DCFCE7,stroke:#15803D,stroke-width:2px,color:#14532D classDef io fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#1F2937 classDef ext fill:#FAE8FF,stroke:#86198F,stroke-width:2px,color:#701A75 class B,C,D synth class E,F opt class G,H eval class A io class LM,AD ext ``` ## 安装 ``` git clone https://github.com/immu4989/dspy-security-bench.git cd dspy-security-bench # 使用 uv: uv venv --python 3.12 source .venv/bin/activate uv pip install -e . # 或使用 pip: pip install -e . ``` 要求 **Python 3.10+** 和 **dspy >= 3.3.0b1**(添加了 `dspy.ReActV2` 的 canonical-tool-call 版本)。pip/uv 会自动处理预发布版本的锁定,因为版本号已在 `pyproject.toml` 中明确指定。 ## 快速开始 完整的 Python pipeline: ``` import dspy from dspy_security_bench.synthesis.generator import synthesize_tasks from dspy_security_bench.synthesis.validator import validate_tasks from dspy_security_bench.optimizers import build_agent_factories from dspy_security_bench.llm_judge import LLMJudgeMetric from dspy_security_bench.runner import evaluate_factories, summarize dspy.configure(lm=dspy.LM("openai/gpt-4o-mini")) # 1. 生成基于 workspace suite 的 seed env 的合成 trainset raw_tasks = synthesize_tasks("workspace", n=150, model="openai/gpt-4o") # 2. 进行有效性过滤,并与真实测试任务去重 val = validate_tasks(raw_tasks, "workspace", checks=("syntactic", "dedupe")) trainset = val.kept # ~140-180 high-quality tasks survive # 3. 运行 optimizers — 为每个 optimizer 生成一个 factory factories = build_agent_factories( trainset=trainset, optimizers=["unoptimized", "bootstrap_fewshot", "miprov2"], suite_name="workspace", signature="query -> answer", metric=LLMJudgeMetric(judge_lm=dspy.LM("openai/gpt-4o-mini", temperature=0)), ) # 4. 针对 AgentDojo 的 attack suite 进行评估 df = evaluate_factories( factories=factories, suite_name="workspace", attacks=["direct", "important_instructions"], user_task_ids=["user_task_0", "user_task_1", "user_task_3", "user_task_10", "user_task_11"], injection_task_ids=["injection_task_0"], max_iters=8, ) # 5. 汇总 print(summarize(df)) ``` 完整的 v0.1 运行大约需要 30-45 分钟的挂钟时间,LM 费用约为 15-20 美元(所有任务均使用 gpt-4o-mini)。请参阅 [`scripts/run_v01_benchmark.py`](scripts/run_v01_benchmark.py) 了解生产环境的驱动程序 —— 它会将优化器状态缓存到 `data/results/factories_cache.pkl` 中,因此在下游发生崩溃后重新运行将跳过优化阶段。 ## CLI 综合和验证步骤具有可生成 JSONL 文件的 CLI: ``` # 合成(dry-run 会打印 prompt 而不调用 API) dspy-security-bench-synthesize workspace --dry-run # 真实合成(需要 OPENAI_API_KEY / ANTHROPIC_API_KEY) export OPENAI_API_KEY=sk-... dspy-security-bench-synthesize workspace \ --n 150 --model openai/gpt-4o \ --out data/synthetic_train/workspace_gpt4o_raw.jsonl # 验证 dspy-security-bench-validate workspace \ data/synthetic_train/workspace_gpt4o_raw.jsonl \ --out data/synthetic_train/workspace_gpt4o.jsonl \ --report data/synthetic_train/workspace_gpt4o_report.json ``` ## 复现 v0.1 结果 ``` # 安装后 — 合成、验证、优化、评估,并保存 CSVs。 # 将优化后的状态缓存到 data/results/factories_cache.pkl,以便重新运行时更快速。 export OPENAI_API_KEY=sk-... export ANTHROPIC_API_KEY=sk-ant-... # optional — falls back to GPT-4o only python scripts/run_v01_benchmark.py 2>&1 | tee data/results/run_v01.log python scripts/generate_v01_figures.py # rebuilds the README charts ``` 输出: - `data/results/workspace_v01_results.csv` — 30 行原始数据 - `data/results/workspace_v01_summary.csv` — 6 行聚合数据 - `assets/v01_utility_vs_security.png` - `assets/v01_pareto.png` ## 开发 ``` # 安装 dev extras(pytest, ruff, pytest-cov) uv pip install -e ".[dev]" # 运行完整的 test suite(61 个测试,全部离线 / mocked — 无需 API key) pytest tests/ -v # linting ruff check dspy_security_bench/ tests/ ruff format dspy_security_bench/ tests/ ``` 测试套件涵盖了环境数据提取、综合辅助工具、验证器检查、AgentDojo wrapper(使用 `DummyLM` 针对 `user_task_0` 进行端到端测试)、优化器测试框架、LLM-as-judge 指标,以及运行程序的编排逻辑(通过 mock `benchmark_suite_with_injections` 实现)。 ## 设计决策 这些在 [ARCHITECTURE.md](ARCHITECTURE.md) 中有详细记录。关键的 v0.1 范围选择如下: - **合成训练集,而非留出划分。** AgentDojo 每个套件只有约 40 个用户任务 —— 这不足以实现支持像 MIPROv2 这样的优化器的干净训练/测试集划分。我们通过 GPT-4o + Claude Sonnet 合成了每个套件约 100 个分布内的纯查询任务,并针对环境进行了验证,同时使用未修改的真实 AgentDojo 任务作为留出测试集。 - **训练使用纯查询任务;测试使用完整的行动任务套件。** 行动任务(发送、创建、修改)具有手写的 utility 检查,这些检查无法通过合成完美实现。在纯查询任务上进行训练是可以接受的,因为研究问题在于 *prompt 优化*(而非行动选择)是否会影响鲁棒性。 - **混合指标**:训练时使用带有 substring 快速路径的 LLM-as-judge(成本低 + 对复述具有容忍度);测试时使用真实的 AgentDojo `utility()`(严格,即实际发布的 benchmark)。 - **对 DSPy 程序施加单输出 signature 约束。** 模型的最终输出将进入 AgentDojo 单一的 `model_output` utility 参数中。 ## 路线图 | Milestone | Status | |---|---| | v0.1 — workspace suite × 2 attacks × 3 optimizers, headline finding | **shipped** | | v0.2 — banking / travel / slack suites, GEPA optimizer, larger N | planned | | v0.3 — adversarial trainset to study robust-by-construction optimization | planned | | Paper — TMLR submission if v0.2 findings hold at scale | conditional | ## 致谢与相关工作 此 benchmark 建立于以下项目之上: - [**DSPy**](https://github.com/stanfordnlp/dspy)(Stanford NLP)—— 正在接受评估的优化器框架。 - [**AgentDojo**](https://github.com/ethz-spylab/agentdojo)(ETH Zurich, SPY lab)—— 提供真实性鲁棒性测量的攻击套件和任务环境。 它还借鉴了 2024-26 年更广泛的 prompt 安全文献,包括 [GEPA](https://arxiv.org/abs/2507.19457), [BATprompt](https://arxiv.org/abs/2412.18196), [Survival of the Safest](https://arxiv.org/abs/2410.09652), [InjecAgent](https://arxiv.org/abs/2403.02691), 和 [WASP](https://arxiv.org/abs/2504.18575)。 ## 引用 如果您在研究或生产环境中使用了此 benchmark,请引用: ``` @misc{ahamed2026dspysecuritybench, title = {{dspy-security-bench}: Measuring optimizer-induced robustness in agentic DSPy programs}, author = {Imran Ahamed}, year = {2026}, howpublished = {\url{https://github.com/immu4989/dspy-security-bench}}, } ``` ## 许可证 Apache License 2.0 —— 见 [LICENSE](LICENSE)。
标签:DLL 劫持, LLM Agent, Python, 反取证, 大语言模型, 安全规则引擎, 安全评估, 提示词工程, 无后门, 策略决策点, 逆向工具, 鲁棒性测试