BryanStats/fraud-detection
GitHub: BryanStats/fraud-detection
基于 IEEE-CIS 数据集的成本感知交易欺诈检测模型,以 PR-AUC 和最小化预期业务成本为核心,通过 SHAP 提供可解释的欺诈预警。
Stars: 0 | Forks: 0
# 基于成本感知阈值化的交易欺诈检测
基于 [IEEE-CIS 数据集](https://www.kaggle.com/competitions/ieee-fraud-detection) 构建的梯度提升欺诈检测模型
(包含 590,540 笔交易,欺诈率为 3.5%),其评估方式与生产环境中的交易
监控系统一致:不看重准确率,而是关注在固定预警处理能力下,分析师团队实际能抓住多少真正的欺诈行为。
作为 Wells Fargo 的高级柜员,我花了约 1.7 年时间处理这类业务的运营工作——包括核实身份、监控交易,以及在《银行保密法/反洗钱》(BSA/AML) 规定下上报可疑活动。本项目重构了其中的*检测*环节:即决定哪些交易会进入分析师处理队列的模型。
## 设计决策
**基于时间的验证集划分(非随机划分)。**
随机划分可能会将未来的交易放入训练集,而将更早的交易放入测试集,这相当于模型有效地利用了“未来”进行训练,并在“过去”上进行评分。由于欺诈模式会随时间发生漂移,测试分数会被虚高,模型预测正确的原因在实际部署中根本无法实现。基于时间的划分仅使用晚于所有训练数据时间的交易进行测试,这完全契合生产环境:你总是使用昨天的数据来预测明天的欺诈。因此,你得到的分数能真实反映模型的泛化能力。
**使用类别权重(`scale_pos_weight`)而非 SMOTE。**
类别不平衡表现为 3.5% 的欺诈率,因此模型需要帮助来学习少数类。我使用了 `scale_pos_weight` 对损失函数进行重新加权,使得每个欺诈样本的权重约为 27 倍——这正是在 3.5% 基准率下正常交易与欺诈交易的比例——而不是使用 SMOTE 来生成合成的欺诈数据行。SMOTE 会通过推高表观欺诈率来扭曲预测概率,而我的操作阈值是通过一个假设这些概率已校准的成本模型来选择的。因此,损坏的概率会导致阈值选择失效。类别权重在不触及概率校准的情况下处理了不平衡问题。
**将 PR-AUC 作为核心指标(而非准确率或 ROC-AUC)。**
准确率在这里毫无用处:在 3.5% 的欺诈率下,一个将所有交易预测为“非欺诈”的模型能获得 96.5% 的准确率,但却抓不到任何欺诈。ROC-AUC 稍好,但在不平衡数据上仍然具有粉饰作用,因为它 rewarding 了正确对大量容易识别的合法交易的排序,因此即使模型在寻找欺诈方面表现平庸,它的读数依然可能高达 0.90+。PR-AUC 由精确率和召回率构建,仅衡量在正类上的表现;它们不会因为容易识别的负类而给模型加分。因此,PR-AUC 不会因数据不平衡而虚高;它直接衡量了模型发现并确认真实欺诈的能力。这就是我报告该指标的原因。我的 0.617 看起来比 ROC-AUC 要低,但这是一个真实的数字——在 3.5% 的基准率下,它比随机猜测好了约 18 倍。
**基于成本的操作阈值(而非默认的 0.5)。**
只有当两类错误的代价相同时,0.5 的阈值才是最优的。在欺诈检测中,它们的代价极度不对称:漏报欺诈的代价是全额的交易损失(数百到数千美元),而误报的成本仅仅是分析师的审查时间(可能只有 25 美元)。因此,我不追求准确率或 F1 分数;我选择能最小化预期成本的阈值。因为漏报的代价要高昂得多,该阈值会远低于 0.5——在我的运行中大约是 0.02——这意味着要进行激进的上报,并容忍误报,以避免漏掉代价高昂的欺诈。这是在经济上正确的权衡,且与默认的 0.5 相去甚远。
## 结果
基于时间划分的训练集进行训练:472,432 笔交易用于训练,118,108 笔较新的交易用于验证。
| 指标 | 数值 |
|---|---|
| PR-AUC(基于时间划分的验证集) | 0.617 |
| Precision@1000(每日 1000 次预警的精确率) | 0.929 |
| Recall@1000(每日 1000 次预警的召回率) | 0.229 |
| 成本最优阈值 | 0.022 |
| — 该阈值下标记的预警数 | 5,325 |
| — 此处的精确率 / 召回率 | 0.485 / 0.636 |
**从业务运营角度解读:** 在固定的 1,000 条预警队列中,93% 被标记的交易是真正的欺诈(这是一个纯净的队列——审查人员的假阳性负担很低),但该队列仅捕获了所有欺诈行为的 23%。当由成本模型来设定阈值时,它会标记约 5,300 笔交易以将召回率推高至 64%,同时接受较低的精确率,因为漏掉一起代价高昂的欺诈比触发一次误报的损失更大。
作为背景参考:在 0.035 的基准率下取得 0.617 的 PR-AUC,意味着其在精确率/召回率的权衡上比随机猜测好了约 18 倍。(此时 ROC-AUC 的读数会高得多,而这正说明了为什么在此场景下它是错误的评估指标。)
### 模型解释 (SHAP)
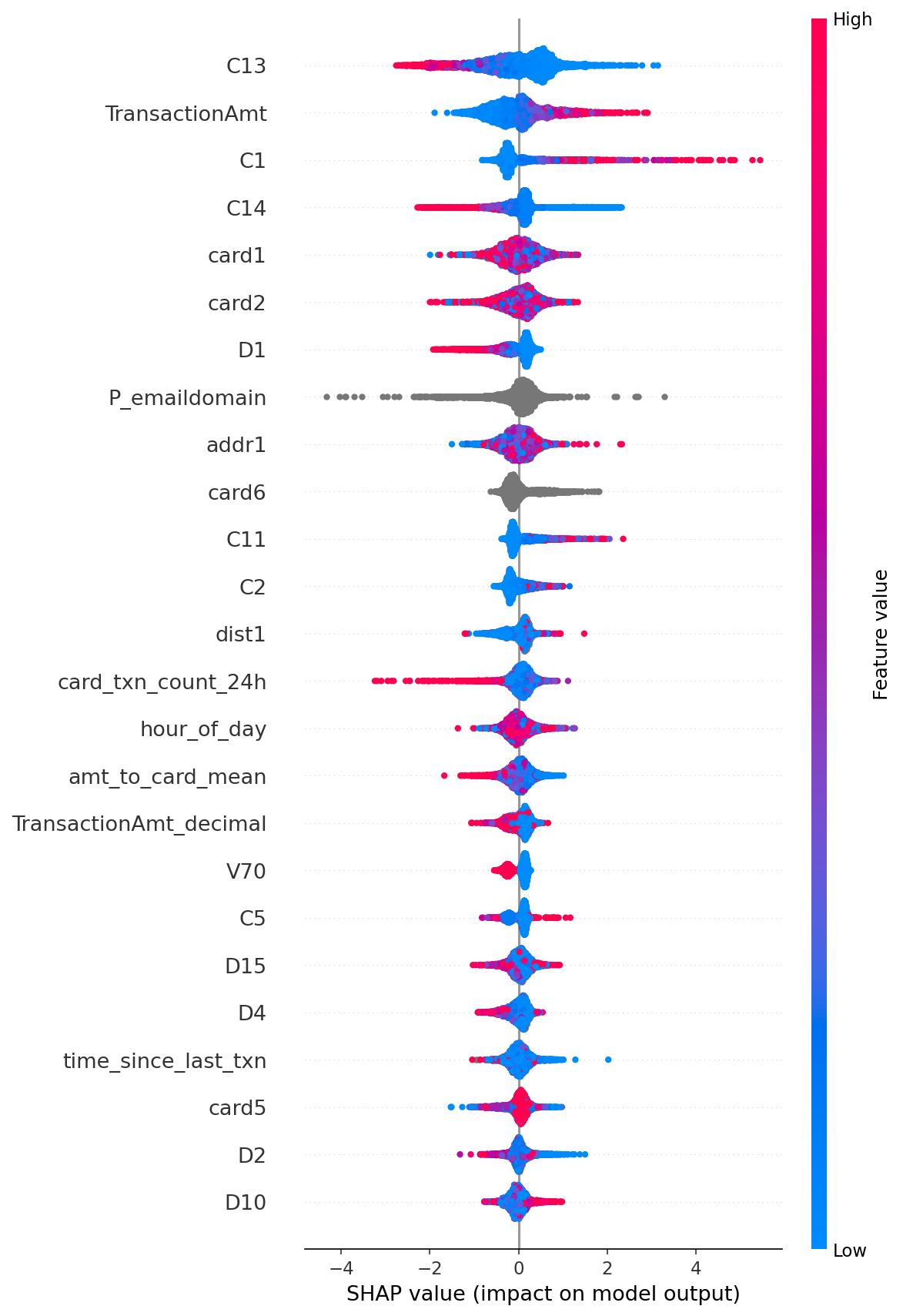
每一个上报的案例都需要一个理由——单凭一个分数对分析师来说不具备可操作性,在监管机构面前也无法辩护。SHAP 提供了全局视角(模型总体上关注什么)和单笔交易的解释(为什么这笔交易被标记)——这相当于模型生成的案件叙述。
## 未生效的尝试(以及为何值得记录它)
**假设:** 测试信用卡欺诈会连续发起许多小额交易,以寻找可用的失窃卡。没有任何单笔交易看起来可疑——可疑的是节奏——而基于单笔交易的特征无法捕捉节奏,因为它们一次只能查看一笔交易。我的修复方案是添加每张卡的频次特征:距离该卡上一笔交易的时间,以及过去 24 小时内的交易次数,期望它们能提高此类欺诈的召回率。
**结果:** PR-AUC 基本保持平稳(0.62 → 0.62),且 recall@1000 也未偏离 ~23%。
**诊断:** SHAP 解释了原因——频次特征在重要性图中排名接近垫底,而数据集中匿名的 C 系列计数特征占据了主导地位。最可能的原因是那些 C 列已经编码了基于卡的交易计数,因此我的频次特征只是在重复推导模型已经拥有的信号。(另一个我没有完全测试的可能性是:24 小时的窗口可能太宽,无法有效隔离通常在几分钟内爆发式发生的测试卡行为。)
我将这些频次特征保留在了代码库中:它们是正确的、无数据泄露风险的,并且经过了单元测试,而且这个负面结果也是项目经历的一部分。
**第二个发现:** 在早期版本中,原始的 `TransactionDT` 是排名首位的 SHAP 特征。我将其从模型中移除了,因为依赖绝对时间戳在基于时间的划分下无法向未来泛化——该模型当时是在拟合交易发生在数据集时间线中的*具体时刻*,而不是一种可迁移的欺诈信号。移除它后各项指标均无明显波动,这证实了该信号与派生出的时间特征是冗余的。
## SQL 特征工程(`db.py`)
每张卡的特征也通过针对 SQLite 的分析型 SQL 实现了,并通过单元测试与 pandas 的实现进行了交叉验证。
- **窗口函数**在不折叠行的情况下重新派生基于卡的特征:
使用 `AVG(...) OVER (PARTITION BY card1)`、`LAG(...) OVER (... ORDER BY ...)`,以及用于计算 24 小时计数的 `RANGE BETWEEN 86400 PRECEDING AND CURRENT ROW` 窗口框。
- **带有收缩的风险排名:** 按原始欺诈率对卡进行排名会暴露小样本噪声(一张 5/5 欺诈率的卡会显示为 100%)。取而代之的是,我使用 Beta-二项式收缩率进行排名——以总体欺诈率添加伪计数,这样单薄的数据样本就会按照其背后缺乏数据的程度被按比例拉向平均值。一张仅有 5 笔交易的卡其欺诈率会向基准率靠拢;而一张拥有 200 笔交易的卡几乎不会受到影响。这使得那些具有高频次且证据充分的欺诈卡得以浮出水面,而不会像原始排名那样被掩盖。
## 仓库结构
```
src/fraud_detection/
config.py # paths, hyperparameters, cost assumptions
data.py # load, merge transaction + identity, time-based split
features.py # memory reduction, engineered + velocity features, encoding
train.py # LightGBM training with early stopping
evaluate.py # PR-AUC, precision@k, cost-based threshold selection
explain.py # SHAP global + per-transaction explanations
db.py # SQLite store + analytical-SQL feature engineering
cli.py # command-line entry points
tests/ # unit tests for feature, metric, and SQL logic
```
## 环境配置
```
pip install -e ".[dev]"
# 数据未包含在内(~1.2GB)。要复现,你需要一个 Kaggle 账户、一个 API
# token,并且需要接受比赛规则:
kaggle competitions download -c ieee-fraud-detection -p data/raw
unzip data/raw/ieee-fraud-detection.zip -d data/raw
# 运行:
fraud-detect train
fraud-detect evaluate --alerts-per-day 1000
fraud-detect explain --row-index 0
fraud-detect sql --nrows 100000
# 测试:
pytest
```
本项目使用 Python、LightGBM、scikit-learn、SHAP、pandas 和 SQLite 构建。
标签:Apex, SHAP, XGBoost, 反洗钱, 成本敏感学习, 机器学习, 欺诈检测, 逆向工具, 金融风控