jordann6/aws-incident-responder
GitHub: jordann6/aws-incident-responder
基于 n8n 工作流引擎的 AWS 自动化事件响应流水线,通过 CloudWatch 警报触发自动修复并通过 Claude 与 Slack 实现智能通知与升级。
Stars: 0 | Forks: 0
# AWS 事件响应器
这是一个自动化的事件响应流水线,其中操作手册是一个 n8n 工作流,而不是粘合代码。目标 EC2 实例上的 CloudWatch 警报会触发至 SNS topic,后者通过 HTTPS 将其交付至运行在 ECS Fargate 上的 n8n。该工作流会自动确认其自身的 SNS 订阅,请求 Claude Haiku 生成通俗易懂的事件摘要,将事件卡片发布到 Slack,重启实例,然后等待并重新检查警报,以决定将事件标记为已解决还是进行升级处理。
## 架构
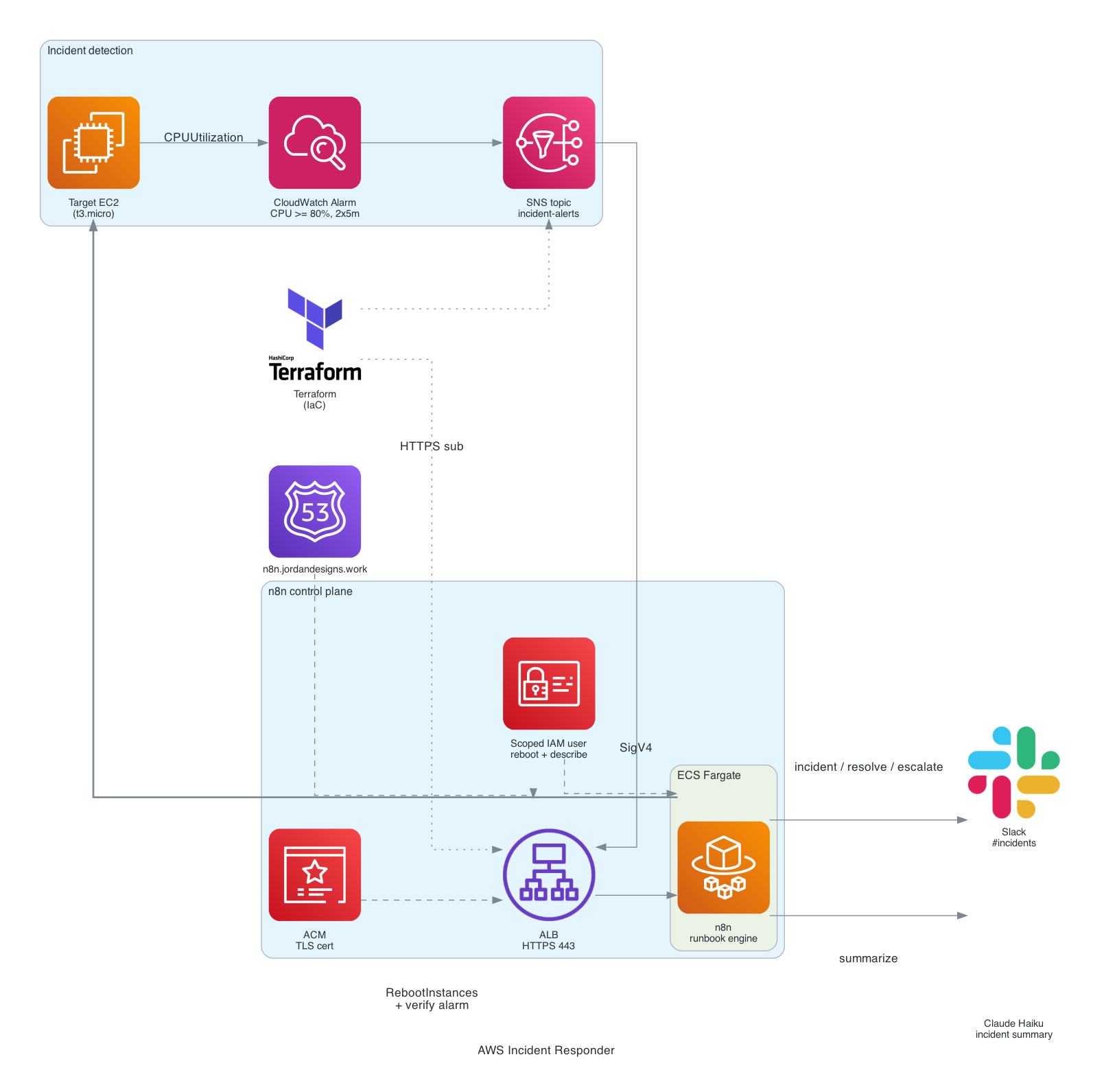
## 工作原理
```
Target EC2 CPUUtilization >= 80% (2 x 5 min)
-> CloudWatch Alarm
-> SNS topic (incident-alerts)
-> HTTPS subscription
-> ALB (ACM TLS, n8n.jordandesigns.io)
-> n8n on ECS Fargate
n8n runbook:
confirm SNS subscription
-> parse alarm
-> Claude Haiku incident summary
-> Slack incident card
-> EC2 RebootInstances (SigV4)
-> wait 60s
-> DescribeAlarms
-> resolved -> Slack resolved
not yet -> Slack escalate
```
## 为什么使用 n8n 而不是 Lambda
这是与同类 [event-driven-aws-remediation](https://github.com/jordann6/event-driven-aws-remediation) 项目刻意形成的对比,后者使用 Python Lambda 作为警报与操作之间的粘合剂。在这里,同一类事件由一个可视化的、可审计的、作为真正 AWS 服务运行的操作手册来处理。该操作手册以 JSON 格式进行版本控制,可以在不阅读代码的情况下检查修复步骤,并且添加一个步骤(丰富化、审批关卡、二次修复)只需添加一个节点,而无需重新部署。Claude Haiku 提供了人类可读的摘要,因此 Slack 卡片读起来就像是一份值班笔记,而不是原始的警报 payload。
## 组件
| 层级 | 资源 | 角色 |
|---|---|---|
| 检测 | **EC2 目标** (t3.micro, AL2023) | 演示工作负载;内置了一个自包含的 CPU 压力单元和一个 SSM 实例角色,以便可以通过 Session Manager 访问它 |
| 检测 | **CloudWatch 警报** | `CPUUtilization >= 80%`,2 个评估周期,每个 5 分钟 |
| 路由 | **SNS topic** | 将警报状态变更分发到 n8n 的 HTTPS endpoint |
| 控制平面 | **ALB + ACM** | 提供受公开信任的 TLS,以便 SNS 接受 HTTPS 订阅 |
| 控制平面 | **ECS Fargate** | 运行 `n8nio/n8n`,即操作手册引擎;任务仅接受来自 ALB 的流量(受安全组限制) |
| 操作手册 | **Claude Haiku** | 生成事件摘要和建议的下一步操作 |
| 操作手册 | **Slack** | 向 `#incidents` 发送事件、已解决和升级消息 |
| 修复 | **受限 IAM 用户** | 仅对目标拥有 `ec2:RebootInstances` 权限,外加只读的丰富化权限 |
| IaC | **Terraform** | VPC, ALB, ECS, 警报, SNS, IAM, DNS;S3 远程状态 |
## 前置条件
- Terraform >= 1.6,为账户 `692859913278` 配置的 AWS CLI
- S3 状态后端存储桶 `tf-backend-jord-projs`
- 用于 `jordandesigns.io` 的公共 Route 53 托管区域(由注册商委托的区域)
- Anthropic API key 以及一个具有 `chat:write` 权限的 Slack bot token
## 部署
密钥不会被保存在 Terraform 状态中。请先创建 n8n SSM 参数:
```
aws ssm put-parameter --name /incident-responder/n8n-basic-auth-password \
--type SecureString --value "$(openssl rand -base64 18)"
aws ssm put-parameter --name /incident-responder/n8n-encryption-key \
--type SecureString --value "$(openssl rand -hex 24)"
```
然后配置基础设施:
```
cd terraform
terraform init
terraform apply
```
请注意输出内容(`n8n_url`、`n8n_webhook_endpoint`、`target_instance_id`、`alarm_name`、`n8n_iam_user`)。
### 配置 n8n
1. 打开 `n8n_url`,使用 basic auth 用户(`admin`)和 SSM 密码登录。
2. 导入 `workflows/incident-responder.json`。
3. 为受限的 IAM 用户创建访问密钥,并将其添加为工作流的 AWS 凭证:
aws iam create-access-key --user-name incident-responder-n8n
4. 将 Anthropic 凭证添加为 HTTP Header Auth:标头为 `x-api-key`,值为你的 API key。
5. 添加 Slack 凭证(bot token)并确认 bot 已在 `#incidents` 频道中。
6. 激活工作流。
### 将 SNS 连接到实时工作流
SNS 订阅受 `enable_sns_subscription`(默认为 `false`)控制,因为 SNS 在订阅时会拒绝无法访问的 endpoint,这会导致在 n8n 提供 webhook 服务之前的首次 apply 失败。一旦工作流被导入并激活,请启用它,以便 SNS 将确认信息交付给由 n8n 自动确认的实时 endpoint:
```
terraform apply -var="enable_sns_subscription=true"
```
确认其已移出 `PendingConfirmation` 状态:
```
aws sns list-subscriptions-by-topic --topic-arn "$(terraform output -raw sns_topic_arn)" \
--query 'Subscriptions[].SubscriptionArn'
```
## 验证
在目标上拉高 CPU 以触发警报(目标具有 SSM 角色,因此无需任何入站访问即可使用 Session Manager;要求本地安装了 `session-manager-plugin`):
```
aws ssm start-session --target "$(terraform output -raw target_instance_id)"
sudo systemctl start incident-stress # burns every vCPU for 10 minutes
```
在两个评估周期内,警报将进入 ALARM 状态,操作手册将端到端运行。确认以下事项:
- Slack 的 `#incidents` 显示了包含 Haiku 摘要的事件卡片,随后是一条已解决或升级的消息。
- n8n 执行日志显示了完整路径,包括重启和 DescribeAlarms 步骤。
- 目标实例的系统日志中显示了最近的重启记录。
## 销毁
```
cd terraform
terraform destroy
aws ssm delete-parameter --name /incident-responder/n8n-basic-auth-password
aws ssm delete-parameter --name /incident-responder/n8n-encryption-key
```
销毁过程是干净的。ALB 及其 ENI 可能需要一分钟来注销,因此偶尔重试销毁可以清除残留的 ENI 依赖。之后请确认 SNS 订阅和 IAM 访问密钥已被彻底删除。
## 成本
运行期间约为 `$0.05/hour`(ALB,一个 0.25 vCPU 的 Fargate 任务,一个 t3.micro),大约 `$1/day`。其设计旨在同一天内部署、演示并销毁,总花费远低于一美元。ACM 和现有的托管区域不会产生额外费用。
## 加固说明
- 在生产环境中,ECS 任务角色将直接拥有修复权限,因此不需要 IAM 用户的访问密钥;此处的受限用户是为了简化演示用的 n8n 凭证设置。
- n8n 在临时的 Fargate 存储上运行 SQLite。为了在任务重启后保持持久化,请挂载 EFS 或将 n8n 指向 RDS Postgres。
- 警报触发的影响仅限于单次重启;生产环境中的操作手册应在执行破坏性操作之前增加审批关卡,并在升级前设置最大重试预算。
标签:AWS, DPI, ECS, n8n, Terraform, 大模型, 漏洞利用检测, 自动化运维