gaasher/Agent-Loop-Skills
GitHub: gaasher/Agent-Loop-Skills
将通用智能体迭代循环(如自动研究、数据分析、代码优化)封装为开放标准的Agent Skills,支持跨宿主可移植部署。
Stars: 1 | Forks: 1
# agent-loop-skills
### 循环直到更好 —— 开箱即用的智能体**循环**,封装为开放标准的 **Agent Skills**。
自动研究 · 科学写作 · 数据分析 · 代码/SQL/prompt 优化 · 红队测试 ——
每一个都是一个*通用的、可复用的循环*,你可以在调用时将其绑定到**你自己的任务**上,并基于
**真实信号**不断迭代,直到工作成果真正变得更好。
[](https://agentskills.io/specification)
[](#compatibility)

[](CONTRIBUTING.md)
[](LICENSE)
[](https://github.com/gaasher/agent-loop-skills)
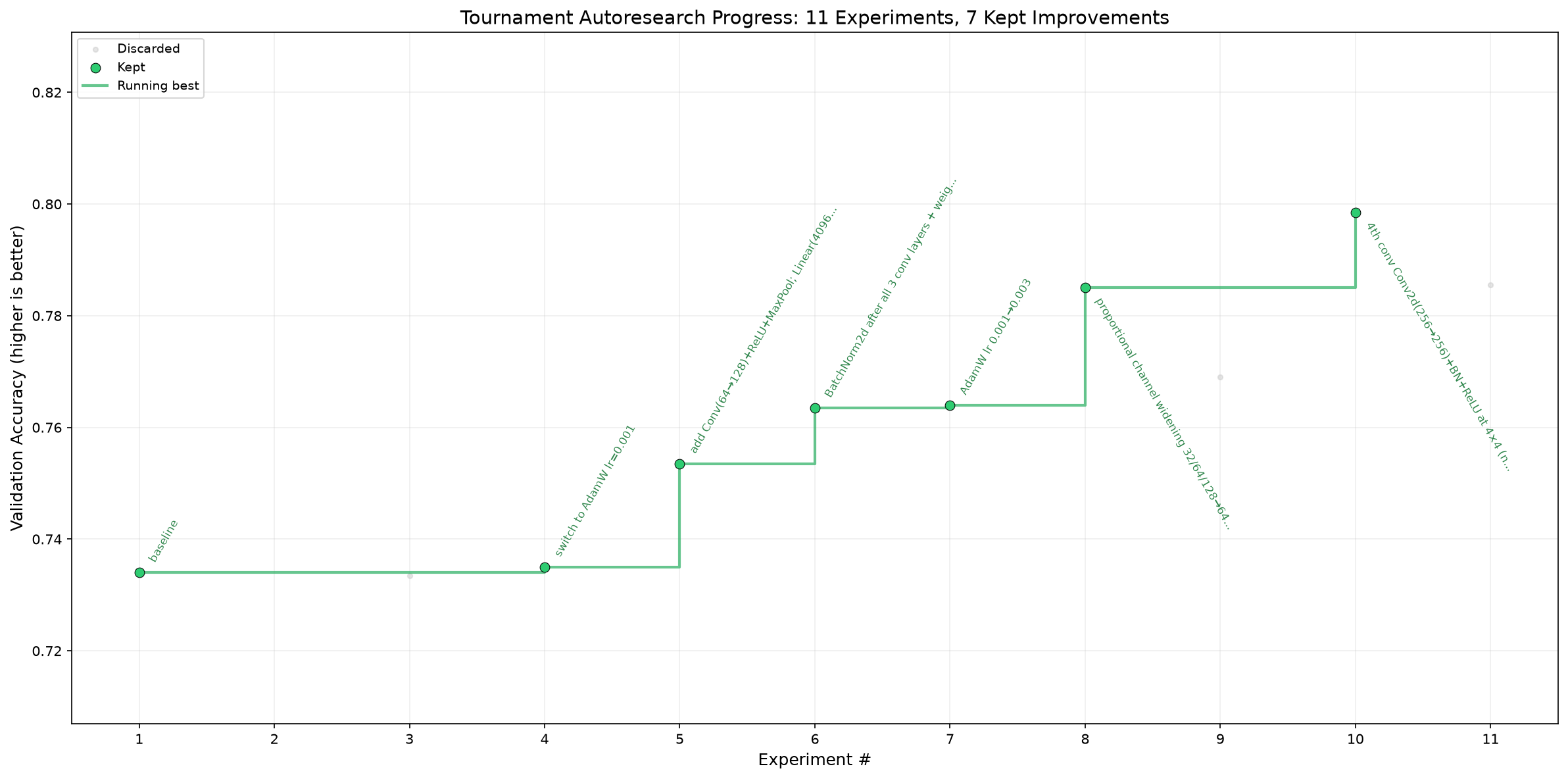 一次真实的运行。 在固定的 5 个 epoch 预算下,针对 CIFAR-10 模型运行的
一次真实的运行。 在固定的 5 个 epoch 预算下,针对 CIFAR-10 模型运行的
按照设计,这远未达到 SOTA —— 这是在笔记本电脑 GPU(Apple MPS)上训练 5 个 epoch 的一个小型 CNN。演示的重点是循环的决策过程,而不是绝对的准确率。
## 为什么选择“循环即技能”
两个想法在 2025 年末发生了碰撞,而这个仓库正位于它们的交集:
- **技能成为了可移植的单元。** 一个 [Agent Skill](https://agentskills.io/specification) 就是一点 Markdown 加上一点 YAML,智能体只会在*相关时*加载它 —— “可能比 MCP 更重要……
扔进去一些文本,然后让模型自己弄明白”
([Simon Willison](https://simonwillison.net/2025/Oct/16/claude-skills/))。现在,单个 `SKILL.md` 就可以跨
~30 个宿主运行(Claude Code、Codex、Cursor 等)。
- **循环成为了程序本身。** Karpathy 通过一个 Markdown
prompt 在 2 天内运行了 [~700 次自动研究实验](https://www.nextbigfuture.com/2026/03/andrej-karpathy-on-code-agents-autoresearch-and-the-self-improvement-loopy-era-of-ai.html);
Geoffrey Huntley 的 [Ralph](https://ghuntley.com/ralph/) 就“以其最纯粹的形式而言,是一个 Bash 循环。” 智能体的
大部分能力并非来自一个巧妙的 prompt,而是来自于**根据反馈进行迭代**。
**这个仓库让循环*成为*技能本身。** 每个条目都不是针对特定任务的技能,而是一个通用的循环 ——
*程序 · 产物 · 反馈信号 · 运行账本 · 终止条件* —— 你可以在调用时将其绑定到你的任务上。
粘贴你的目标;循环会提出修改,在**你的**环境中运行它,基于一个**真实的**
信号(测试、延迟、指标、校准过的评估器)对其打分,仅在结果更好时予以保留,记录下来,然后重复。
## 循环的工作原理
```
flowchart LR
T["bind your task
一次真实的运行。 在固定的 5 个 epoch 预算下,针对 CIFAR-10 模型运行的 tournament-autoresearch 循环 ——
竞争的智能体在每一步提出修改,一个自校准的评估器保留获胜者(绿色)并丢弃退化的方案(灰色):
0.734 → 0.798 val_acc,无需人工干预,保留了 11 个方案中的 7 个。完整账本:showcase/tournament-autoresearch。按照设计,这远未达到 SOTA —— 这是在笔记本电脑 GPU(Apple MPS)上训练 5 个 epoch 的一个小型 CNN。演示的重点是循环的决策过程,而不是绝对的准确率。
(artifact + signal + budget)"] --> P["propose
one change"] P --> R["run it in
your env"] R --> S{"score
tests · metric · judge"} S -->|better| K["keep + log"] S -->|worse| X["revert"] K --> G{stop?} X --> G G -->|"plateau · budget · threshold"| B(["best artifact"]) G -->|no| P ``` 每个循环都分解为相同的五个要素 —— **程序**(`SKILL.md`)、**产物槽位** (被改进的对象)、**反馈信号**(驱动下一步的依据)、**运行账本**(仅追加的日志)以及 **终止条件**(何时停止)。这些技能**不携带任何重型依赖**:你的代码(torch trainer、SQL 数据库、数据集)通过绑定的运行命令在*你的*环境中运行;技能通过 shell 调用并读取 结果。多角色循环使用 **spawn-or-degrade** 机制 —— 在 Claude Code 上生成真实的、隔离的 subagent,在其他宿主上则以内联方式运行相同的角色。 ## 安装 以下任何一种方式都可以安装所有循环: **Claude Code —— 插件市场**(添加一次,然后安装): ``` /plugin marketplace add gaasher/agent-loop-skills /plugin install agent-loops@agent-loop-skills ``` 循环在安装时会以 `agent-loops:
更多真实运行 —— optimize-loop、research-proposal、red-team、power-analysis……
| 循环 | 运行结果 | |---|---| | [`optimize-loop`](showcase/optimize-loop) | 以正确性为门控的加速:一个 SQLite 查询从 **1,131.75 ms 降至 1.055 ms (~1,073×)**,在**每次保留的迭代中**结果集哈希均与基线匹配;在 *code* 模式下,**13/13 个测试全绿**,并将圈复杂度从 **23 降至 15**(嵌套从 7 降至 3)。 | | [`research-proposal`](showcase/research-proposal) | ScholarEval 根据文献对提案进行评分;Judge + Reviser 在 5 轮内将其**评分从 45 提升至 84**(soundness 2→4,contribution 1→4)。 | | [`red-team`](showcase/red-team) | 针对一个简单的 content filter,暴露了**所有 5 个植入的弱点**(大小写绕过、leetspeak、空格、同义词、过度拦截)—— 39 次绕过 + 6 次过度拦截 —— 并为每个弱点提供了单行根本原因修复。 | | [`power-analysis`](showcase/power-analysis) | 通过 Monte-Carlo 计算出 **n = 100/组以达到 80% 的统计功效**,修复了所有 6 个有效性缺陷,并生成了完整的预注册报告。 | | [`research-question`](loops/research-question) | 将 5 个模糊的草稿提炼为 3 个强有力的问题(≥75),通过真实的网络查新检验,将已有答案的问题转向尚未解决的子问题。 |自动研究 —— 基于指标迭代 ML 产物
| 循环 | 何时使用它 | |---|---| | [`karpathy`](loops/karpathy) | 最简基线 —— 提出、训练、保留更好的结果、循环。是对 Karpathy 自动研究的忠实致敬。 | | [`ml-autoresearch`](loops/ml-autoresearch) † | 分析优先:诊断每次运行,并基于证据为下一次修改寻找依据。`literature` 刻度盘可增加基于论文的修改。 | | [`exploratory-autoresearch`](loops/exploratory-autoresearch) | 通过 temperature/swing 调度器强制进行广泛探索 —— 避免永远只在同一个想法上爬山。 | | [`tournament-autoresearch`](loops/tournament-autoresearch) † | 每一步由自校准评估器评判的竞争性修改。 | | [`dueling-autoresearch`](loops/dueling-autoresearch) † | 两种方法并行比拼同一指标,并跨赛道借鉴想法。 | | [`alpha-evolve`](loops/alpha-evolve) † | 基于种群的进化(MAP-Elites + islands,diff-mutate,cascade-eval)。 |文献与写作 · 数据 · 代码与优化 · 其他(点击展开)
**文献与写作** | 循环 | 何时使用它 | |---|---| | [`literature-search`](loops/literature-search) | 共享工具链(非循环):通过 Semantic Scholar + arXiv 进行论文发现、摘要、引用图谱及全文检索。 | | [`literature-survey`](loops/literature-survey) | 构建一个由来源 × 主张组成的饱和证据/矛盾矩阵。 | | [`research-question`](loops/research-question) | 将模糊的主题提炼为强有力、新颖、可行的研究问题。 | | [`hypothesis-gen`](loops/hypothesis-gen) † | 生成并利用文献审查一批研究假设。 | | [`research-proposal`](loops/research-proposal) † | 根据文献对提案进行评分(ScholarEval),并不断修改直到通过。 | | [`scientific-writer`](loops/scientific-writer) † | 专家评估器 + 独立的同行评审对草稿进行点评;作者不断修改直到分数达到标准。 | **数据** | 循环 | 何时使用它 | |---|---| | [`data-analysis`](loops/data-analysis) | 假设 → 验证发现;每个发现都有可复现的数字和显著的效应大小作为支撑。 | | [`anomaly-investigation`](loops/anomaly-investigation) | 通过形成、测试和排除候选者来诊断已知异常的原因。 | | [`claim-verify`](loops/claim-verify) | 以对抗方式根据底层数据验证结果草稿中的主张。 | | [`tabular-cleanup`](loops/tabular-cleanup) | 通过确定性检查,将混乱的表格清理为符合推断数据契约的格式。 | **代码与优化** | 循环 | 何时使用它 | |---|---| | [`optimize-loop`](loops/optimize-loop) | 带有可插拔正确性门控 + 最小化指标的 Evaluator-optimizer —— 重构代码(测试全绿 + 复杂度↓)或加速 SQL(结果相同 + 延迟↓)。 | | [`prompt-optimize`](
### ⭐ 如果“循环直到更好”正是你喜欢的那种乐趣,请给它点个 star 并[发送一个循环](CONTRIBUTING.md)。

标签:AI智能体, AI辅助研究, RESTful API, 代码优化, 代码示例, 工作流自动化, 应用安全, 提示词优化, 数据分析, 自动化循环, 防御加固