PushpenderIndia/SIFT-Sentinel
GitHub: PushpenderIndia/SIFT-Sentinel
一款基于 MCP 架构的自主取证分流代理,通过只读工具集和结构化解析让 Claude Code 在不破坏证据完整性的前提下完成 Windows 数字取证分析。
Stars: 0 | Forks: 0
# SIFT-Sentinel
一个专为 SANS SIFT Workstation 设计的自主、保证证据安全的应急响应分析工具。为 Find Evil! 黑客松而构建。
其目标是让 Protocol SIFT 作为一个完全自主的分流(triage)代理发挥实用价值,同时解决其目前存在的两个问题:产生幻觉的发现,以及代理修改原始证据的风险。SIFT-Sentinel 通过自定义的 MCP server 将 SIFT 工具集暴露给 Claude Code 来实现这一点,该 server 仅提供有类型的、只读的函数,并在模型看到原始工具输出之前,将其解析为紧凑的 JSON。
架构:自定义 MCP Server(信任边界)加上作为推理代理的 Claude Code。包含十八个只读取证工具、结构化解析器、artifact 缓存,以及无需真实 SIFT 工具和 API key 即可运行的测试套件。
## 演示
真实分流运行的视频录制 —— 包含解说的终端执行过程,以及一段自我纠正序列。
[](https://youtu.be/G-Joj5jwE7Y)
YouTube 链接:https://youtu.be/G-Joj5jwE7Y
本仓库中的原始视频文件:[`docs/demo_video.mp4`](docs/demo_video.mp4)
## 灵感
AI 驱动的攻击者可以在不到八分钟的时间内从初始访问实现到域控。而防守者通常还在准备他们的工具包。Protocol SIFT 表明,通过 MCP 将代理连接到 SIFT Workstation 是可行的,但它产生的幻觉超出了证据工作所能接受的范围。我们想看看其中有多少问题可以通过结构化方式解决,而不是仅仅依赖于 prompt 调优,以及证据完整性是否可以作为架构保证,而不是要求模型遵守的规则。
## 功能与作用
将其指向一个挂载的 Windows 磁盘镜像和 RAM 捕获文件,然后要求其进行分流。Claude Code 遵循 `CLAUDE.md` 中的分析师指令,驱动一组固定的只读工具来执行以下操作:
- 从宏观到微观:首先检查执行证据和文件系统时间线,然后转向内存、登录和持久化机制。
- 跨来源验证。只有当至少有两个独立的 artifact 一致时(例如 Prefetch、Amcache 和 MFT),发现才会被标记为 CONFIRMED。
- 揭示矛盾。当磁盘和内存结果不一致时,它会报告一个 CONTRADICTION,而不是默默地选择其中一个。
- 自我纠正。如果仍有遗漏,它会更缩小范围重新运行,例如使用更严格的 `path_filter` 或特定的事件 ID。
- 引用其工作。每项声明都会引用生成该声明的工具执行的 `call_id`,并记录在只追加的审计日志中。
没有 `execute_shell` 工具。代理无法运行破坏性命令,因为在其动作空间中不存在这样的函数。
## 特性
证据安全:
- 有类型的、只读的 MCP 动作空间。没有 `execute_shell`,没有通用命令函数。破坏性动作是无法表达的。
- 仅限允许列表的子进程运行器。参数以列表形式传递,绝不是作为 shell 字符串,且从不使用 `shell=True`。任何不在显式允许列表中的二进制文件都会被拒绝。
- 路径遍历防护。每个由工具提供的路径在使用前都会被解析并检查是否位于允许的证据根目录内。支持多个根目录(例如,一个磁盘根目录加上一个单独挂载的 RAM 捕获),而不会放宽到整个文件系统。
- 每个由文件支持的证据 artifact 的 SHA-256 哈希值在工具调用前后都会被记录。如果调用后哈希值发生改变,将作为完整性错误返回并记录在审计记录中。
准确性与输出处理:
- 原始工具输出在到达模型之前,会被解析为紧凑的、有类型的 JSON 记录。模型永远不会看到数兆字节的 CSV。
- 解析后的 artifact 缓存以证据 SHA-256 为键。当使用不同的过滤器再次查询同一证据时,昂贵的 MFT、EVTX、Amcache、ShimCache 和 SRUM 解析将被安全地重用。
- 字节预算限制每个响应的序列化记录负载(`SIFT_MAX_BYTES`,默认 60 KB),此外还有记录数限制(`SIFT_MAX_RECORDS`),因此没有任何单次调用可以超出传输限制。
- MFT 摘要模式将完整的时间线(可能包含 20 万条以上记录)浓缩为总计数、删除计数、按月创建的直方图,以及一组值得关注的精选记录:用户可写路径中的可执行文件和脚本、伪装的双扩展名、NTFS 备用数据流和已删除的可执行文件。
- 缩小范围参数(`path_filter`、`event_id`)允许代理在自我纠正期间重新运行聚焦查询,而不是重新转储所有内容。
- 事件日志解析从 EVTX 负载中提取行为者字段:目标账户、主体账户、源 IP、工作站、登录类型、服务名称、映像路径和 PowerShell 脚本块文本。
- CSV 解析器能够容忍底层工具产生的参差不齐的行,而不会因此崩溃。
推理规范:
- 包含四个明确级别的置信度模型:CONFIRMED、INFERRED、UNCERTAIN、CONTRADICTION。CONFIRMED 需要至少两个支持的 `call_id`,由数据模型强制执行。
- 跨磁盘和内存的多源关联(例如,将 netscan C2 连接关联到其二进制文件被 MFT 显示为几秒钟前投放的 PID)。
- 超级时间线将 MFT、Amcache、ShimCache、EVTX 和 Prefetch 记录合并到一个按时间排序的视图中,用于事件窗口关联。
- `CLAUDE.md` 中的高级分析师指令和 `/triage` 工作流设定了排序、印证和引用规则。
可审计性与输出:
- 只追加的 JSONL 审计日志,每次工具调用对应一条记录,包含时间戳、参数、输入哈希、执行的二进制文件、持续时间、输出摘要和每次调用的 token 计数。任何发现都可以追溯到 `call_id`。
- `tokens` 字段是该次调用返回到代理上下文中的响应负载的估算大小(以 token 为单位)。只读的 MCP server 永远无法看到模型自身的 prompt/completion 使用量,因此我们不捏造该数字,而是记录在信任边界处我们可以诚实衡量的那项 token 成本 —— 在代理接收到的确切负载(在应用字节预算和 MFT 摘要之后)上确定且离线地估算(`sift_sentinel/tokens.py`)。这是操作员用来推理上下文预算的单次调用成本。
- 报告生成会检查缺失或重复的 `call_id` 引用,从而确保引用的明确性。
- 离线报告生成(`sift-sentinel-report`)在调查之后,根据叙述和审计日志渲染出调查结果文档。
- 基准测试工具(`benchmark/score.py`)根据真实情况和 Protocol SIFT 基线对发现结果进行评分。
运维操作:
- 可在标准的 SIFT Workstation 上运行。Prefetch 使用 `sccainfo` (libscca),注册表使用 `rip.pl` (RegRipper),因此不需要 Windows 运行环境。
- 为常见的 Zimmerman 和 Volatility 输出添加了 Linux 友好的包装器:AppCompatCacheParser、SrumECmd、EvtxECmd、AmcacheParser、MFTECmd、YARA 和 Volatility 3。
- 优雅降级。例如,域控制器上的空 Prefetch 目录或缺失的 YARA 规则文件将返回明确的提示信息,而不是错误堆栈。
- 独立的广泛扫描调用可以通过线程池助手并发运行,同时保留只追加的审计记录。
- 一步到位的 `install.sh` 可设置 virtualenv、安装依赖项和 `yara`,并在 Claude Code 中注册 MCP server。
- 测试无需真实的 SIFT 工具和 API key 即可运行,使用的是捕获的测试固件和注入的模拟运行器。
## 暴露给 Claude Code 的 18 个工具
下表为概览;每个工具的签名、参数、返回结构以及每次调用所共享的保证详见 [`docs/tools.md`](docs/tools.md)。
| 工具 | 底层二进制文件 | 取证问题 |
|---|---|---|
| `extract_mft_timeline` | MFTECmd | 文件是何时创建或修改的? |
| `get_amcache` | AmcacheParser | 执行过或存在哪些程序?可选择抑制已知正常的哈希值。 |
| `analyze_prefetch` | libscca (`sccainfo`) | 执行计数和最后运行时间 |
| `shimcache` | AppCompatCacheParser | 当 Prefetch 缺失时的二进制文件存在/执行证据 |
| `srum` | SrumECmd | 每个应用的资源使用情况、网络字节和泄露迹象 |
| `parse_event_logs` | EvtxECmd | 安全、服务安装和 PowerShell 事件(已提取行为者字段) |
| `logon_summary` | EvtxECmd | 按账户、源 IP 和登录类型分组的 4624/4625 登录事件 |
| `powershell_logs` | EvtxECmd | PowerShell 4103/4104 命令和脚本块活动 |
| `registry_autoruns` | RegRipper (`rip.pl`) | 持久化和自启动项 |
| `yara_scan` | YARA | 证据上匹配的已知恶意签名 |
| `read_artifact` | 内部只读读取器 | 文本 artifact(如 PowerShell 记录),已进行哈希处理和审计 |
| `mem_pslist` | Volatility 3 | RAM 捕获时正在运行的进程 |
| `mem_pstree` | Volatility 3 | 父/子进程关系 |
| `mem_cmdline` | Volatility 3 | 每个进程的命令行 |
| `mem_netscan` | Volatility 3 | 网络连接 / C2 信号 |
| `mem_malfind` | Volatility 3 | 注入或无后端可执行内存区域 |
| `mem_svcscan` | Volatility 3 | 驻留在内存中的服务及其二进制文件 |
| `super_timeline` | 内部关联 | 跨磁盘、执行和事件 artifact 的时间排序视图 |
添加工具对信任边界来说是一个很小的改变:实现包装器,在 `mcp_server.py` 中注册有类型的 MCP 函数,将其添加到 `tools/registry.py` 中供非 MCP 调用者/测试使用,如果它会派生外部二进制文件,则在 `runner.ALLOWED_BINARIES` 中添加一个允许列表条目。诸如 `read_artifact` 和 `super_timeline` 之类的内部工具即使不派生外部二进制文件,也仍然会通过路径、哈希和审计控制。
## 架构
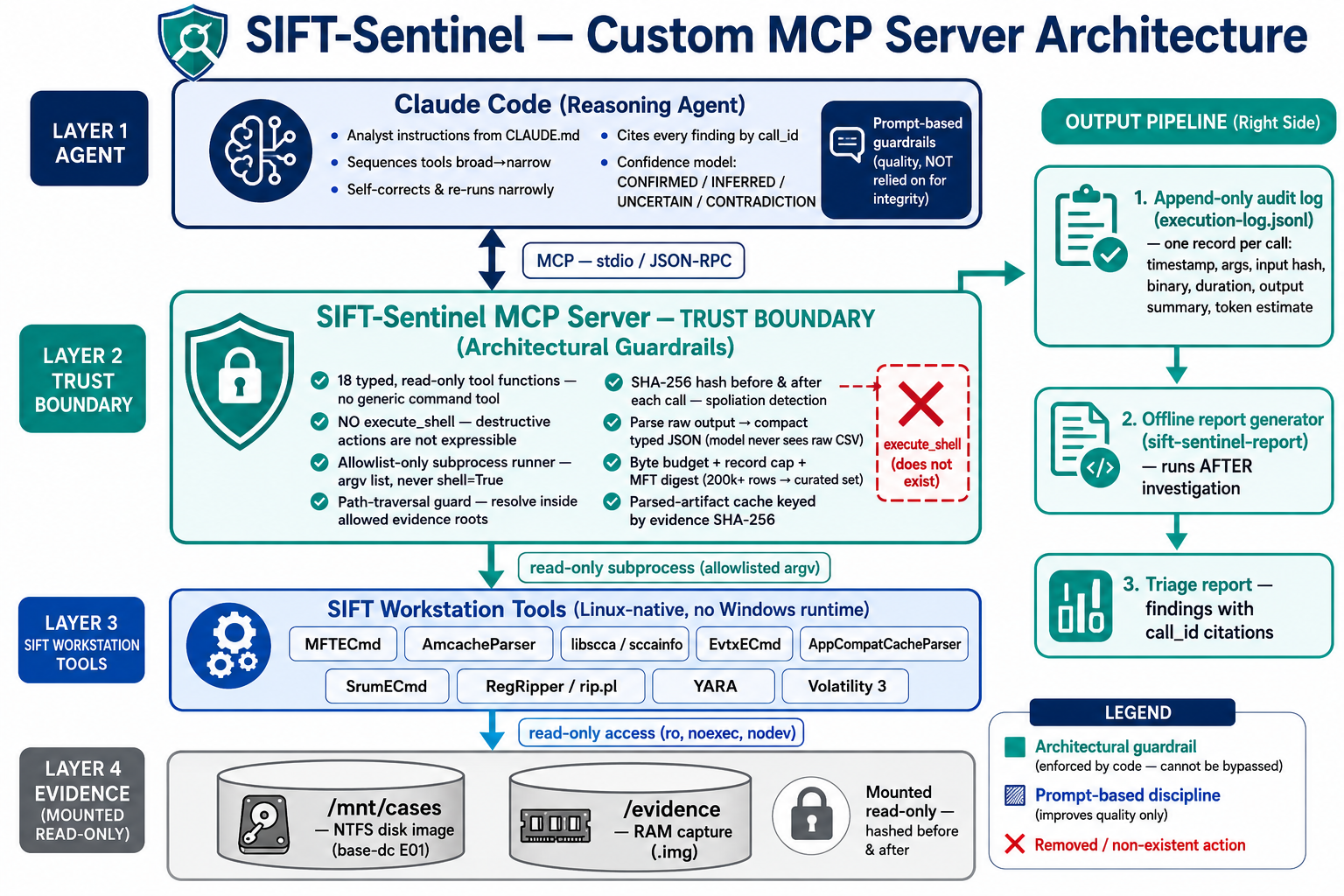
完整的书面指南 —— 包括组件、单次工具调用的数据流、信任边界以及两个护栏层 —— 详见 [`docs/architecture.md`](docs/architecture.md)。
有两个独立的护栏层,我们刻意将它们区分开来:
- 架构层面:MCP 动作空间、只读挂载、哈希验证和允许列表运行器。代理无法绕过这些,因为它们是现有代码的固有属性。
- 基于 prompt 的层面:`CLAUDE.md` 中的分析师准则(置信度标记、排序)。这能提高质量,但永远不作为保证证据完整性的依赖。
## 架构决策及其原因
选择自定义 MCP Server 而不是直接代理扩展或替代 IDE。黑客松允许采用四种方法。我们选择 MCP server,因为它是唯一通过架构而不是通过模型遵循指令来强制执行证据完整性的方法。对于暴露了 shell 的代理,“不要修改证据”是一个模型可以忽略的请求。在这里,破坏性动作并不存在于动作空间中,所以根本没有什么可以忽略的。
选择有类型的函数而不是通用的命令工具。暴露 `extract_mft_timeline(...)` 而不是 `run("mftecmd ...")` 意味着由服务器(而不是模型)决定运行哪些二进制文件以及使用哪些参数。这也让服务器控制输出处理,这正是准确性工作发挥作用的地方。
单一且仅限允许列表的无 shell 运行器。每次外部执行都通过同一个函数进行,该函数接受参数列表,拒绝任何不在允许列表中的二进制文件,并且从不调用 shell。这使得破坏性命令和命令注入的攻击面变成了一个单一、微小且可审计的瓶颈,而不是分散在每个工具中。
在模型看到任何内容之前进行解析。一个完整的 `$MFT` 大约有 23.6 万条记录,大约 60 MB 的 CSV。将其喂给模型会浪费上下文,并且是产生被截断或乱码文本幻觉的已知来源。首先解析为小型的有类型记录可以保持上下文干净,并使模型的工作变成推理任务,而不是文本提取任务。
字节预算和摘要,而不仅仅是行数限制。我们最初通过记录数来限制响应。这仍然超出了传输限制,因为决定问题的是记录的宽度,而不是数量:1,000 行较宽的 MFT 记录大约是 257 KB而且它们大部分是毫无意义的文件系统元数据。字节预算保证负载无论多宽都能容纳得下,而摘要则返回真正重要的记录,以便代理基于信号而不是数据量进行推理。
将置信度作为数据模型,而不是约定。要求模型标记其置信度是不可靠的。相反,CONFIRMED 要求数据结构中至少有两个支持的 `call_id`,因此不支持的自信声明是无法表示的。这是对幻觉问题的直接结构性回答。
带有 call-id 引用的只追加审计日志。每次工具调用都会写入一条不可变记录,并且每个发现都会引用生成它的 `call_id`。这免费提供了可追溯性,也是执行日志的交付物。我们选择 JSON Lines 是因为它本质上是只追加的,并且永远不需要重写。
将报告生成保持在带外。调查结果报告必须写在某个地方,这是一种写操作。为了不削弱只读的动作空间,报告生成是一个单独的离线命令,在调查之后针对已经存在的数据(叙述和审计日志)运行。
Claude Code 作为代理,没有单独的运行器或 API key。这些工具由 Claude Code 通过 MCP 直接调用,因此没有额外的服务需要运行,也没有密钥需要管理。评委可以直接安装、挂载证据并进行分流,而无需建立额外的基础设施。
Linux 原生的底层工具。Prefetch 使用 `sccainfo`,注册表使用 `rip.pl` 意味着整个流水线可以在标准的 SIFT Workstation 上运行,而无需 Windows 运行环境,这使得试用过程变得简单。
结合只读挂载和哈希校验以防范证据篡改。镜像以 `ro,noexec,nodev` 方式挂载,每个证据文件在运行前后都会进行哈希处理。在整个文件支持的调用过程和整个调查的 `EvidenceSet` 检查中,相同的哈希值证明了没有任何内容被修改,这正是准确性报告需要展示的内容。
## 处理超大输出
最有效的可靠性修复来自于让代理针对真实的域控制器镜像运行并观察其失败过程。`extract_mft_timeline` 返回了 236,778 条记录,由于超出了传输限制(即使应用了旧的行数限制后),响应被转储到了临时文件中。我们通过上述的字节预算和 MFT 摘要修复了这个问题,因此完整且未过滤的时间线现在会返回一个可用的摘要以及精选的有趣记录集,并且代理会在需要时使用 `path_filter` 来完整枚举特定目录。
## 挑战
- 行数限制看起来很安全,但仍然超出了传输限制,因为决定问题的是记录的宽度,而不是记录数。我们只有在针对真实证据运行时才发现这个问题。
- 我们将 `sccainfo` (libscca) 用于 Prefetch,将 `rip.pl` 用于注册表,因此整个流水线可以在没有 Windows 运行环境的标准 SIFT Workstation 上运行。
- 保持只读边界完整意味着我们必须拒绝一些方便的捷径,比如让代理编写自己的报告。
## 学到了什么
最大的准确性提升来自于架构。在应用任何 prompt 工作之前,结构化解析和对庞大结果的摘要消化消除了整类幻觉问题,并让我们能够真正捍卫“破坏性工具根本不存在”这一主张。
## 数据集
完整的证据数据集文档 —— 包括来源、读取的 artifact 和发现 —— 详见 [`docs/dataset.md`](docs/dataset.md)。
SIFT-Sentinel 是针对 **SANS Find Evil! "SRL-2018 Compromised Enterprise Network"** 数据集(由 SANS 为黑客松提供)开发和测试的。它已针对**该数据集中的两个主机镜像**进行过端到端运行 —— 每个都是独立的运行,带有自己的审计日志、分流报告和演示:
| 运行 | 主机 | 磁盘 + 内存 | 分流报告 | 审计日志 |
|---|---|---|---|---|
| **`base-dc`** | `base-dc.shieldbase.lan` — Windows Server 2016 **域控制器** | `base-dc-cdrive.E01` + `base-dc-memory.7z` → `/mnt/cases`, `/evidence/base-dc-memory.img` | [`triage-report-base-dc-2026-06-14.md`](audit/triage-report-base-dc-2026-06-14.md) | [`execution-log-base-dc.jsonl`](audit/execution-log-base-dc.jsonl) |
| **`base-file`** | `base-file.shieldbase.lan` — Windows Server **文件服务器** | `base-file-cdrive.E01` + `base-file-memory.7z` → `/mnt/file-case`, `/evidence/base-file-memory.img` | [`triage-report-base-file.md`](audit/triage-report-base-file.md) | [`execution-log-base-file.jsonl`](audit/execution-log-base-file.jsonl) |
两个主机属于同一个 `shieldbase.lan` 域,因此这些运行结果可以相互印证(在两者中都出现了相同的 `BASE-HUNT` 源和相同的 F-Response / `Mnemosyne.sys` IR 工具)。
**代理发现的线索 — `base-dc`**(完整报告:[`audit/triage-report-base-dc-2026-06-14.md`](audit/triage-report-base-dc-2026-06-14.md)):
- **CONFIRMED** — F-Response 远程取证代理(`subject_srv.exe`)和 `mnemosyne` 内核驱动程序(`Mnemosyne.sys`)于 2018-09-06/07 被存放在 `C:\Windows` 中,每一项都得到了 MFT 外加 7045 服务安装事件的印证,并归因于 IR/获取工具,而不是攻击者。
- **INFERRED** — 在约 27 小时内,来自 `BASE-HUNT$`(`172.16.5.25`)针对该 DC 的持续 163 次失败登录(事件 4625)。
- **CONTRADICTION** — 内存工具在未报错的情况下返回了零个进程,被标记为隐蔽的工具故障(盲点),而不是主机干净的证据。
**代理发现的线索 — `base-file`**(完整报告:[`audit/triage-report-base-file.md`](audit/triage-report-base-file.md);演示:[`docs/sans-2018-base-file-demo.mp4`](docs/sans-2018-base-file-demo.mp4)):
- **CONFIRMED** — 伪装的“Microsoft Advanced API 32/64”服务(由 `msadvapi2_*.exe` 提供支持,通过 `install_wormhole` 分阶段部署)和 WinPcap `npf.sys` 驱动程序,得到 MFT 外加 7045 服务安装事件的印证,并同时投放了恶意 CA 证书;在 `base-dc` 上也看到了相同的 F-Response / `Mnemosyne.sys` IR 工具。
- **INFERRED** — `rsydow-a` 的 2 分钟信标循环(来自 `172.16.4.4` 的 160 多次类型 3 登录)以及来自 `10.10.x.x` 的网外 `cbarton` 登录。
- **CONTRADICTION** — 内存工具在有效的、经过哈希验证的镜像上再次返回了零条记录(相同的 Volatility 配置文件不匹配),被标记为盲点。
## 试用
完整的分步安装、挂载和故障排除说明详见 [`docs/installation.md`](docs/installation.md)。
需要 SANS SIFT Workstation(基于 Ubuntu,预装了 IR 工具)。
### 1. 安装
```
git clone https://github.com/PushpenderIndia/SIFT-Sentinel
cd SIFT-Sentinel
./install.sh
```
`install.sh` 会创建一个 virtualenv(如果检测到 vboxsf 共享文件夹,则在本地磁盘上创建),安装包和开发依赖,如果缺失则通过 apt 安装 `yara`,并在 Claude Code 的 MCP 配置中注册 `sift-sentinel` MCP server。使用 `./install.sh --evidence-root /mnt/cases` 传递自定义根目录。
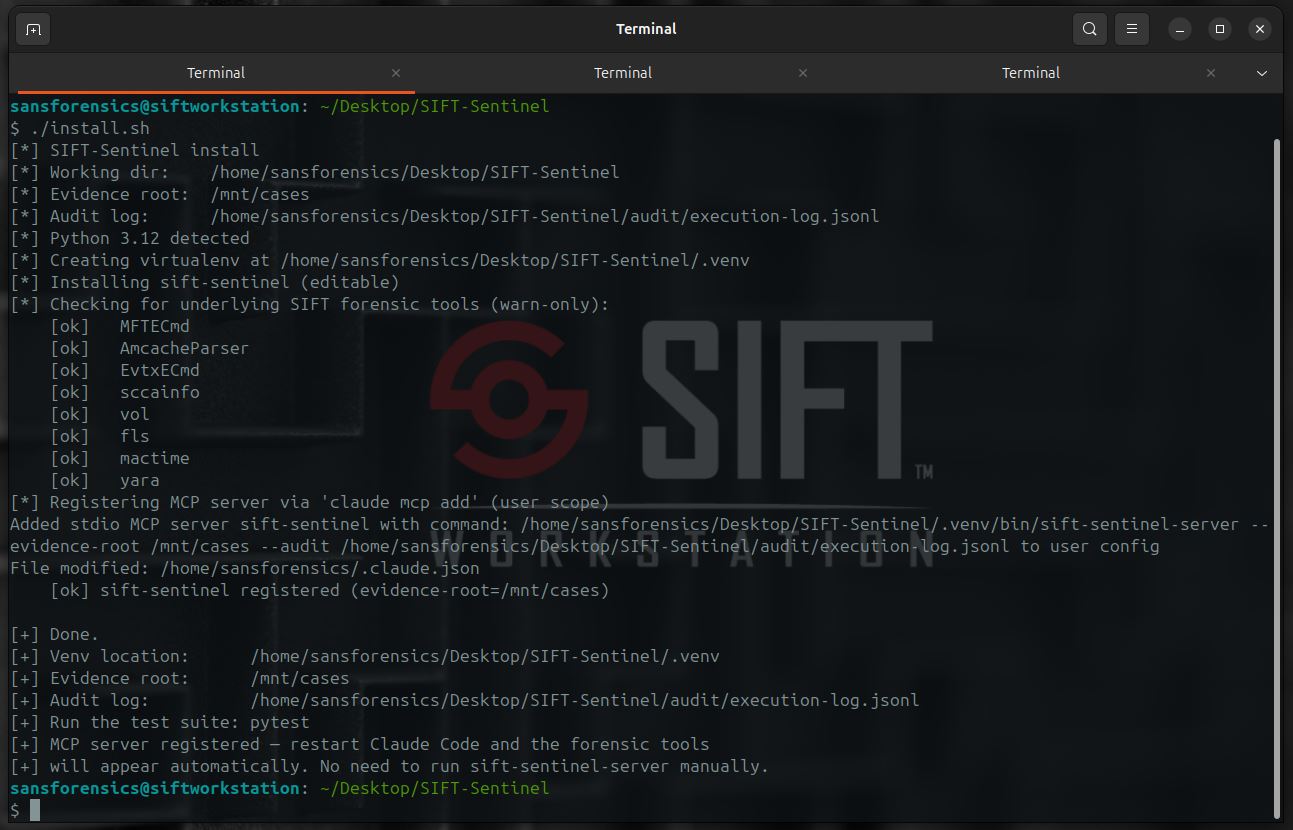
### 2. 重启 Claude Code 之前以只读方式挂载证据
```
# 磁盘镜像 (E01 -> raw -> NTFS 挂载, 只读)
sudo mkdir -p /mnt/ewf /mnt/cases
sudo ewfmount /path/to/base-dc-cdrive.E01 /mnt/ewf
sudo mount -t ntfs-3g -o ro,noexec,nodev /mnt/ewf/ewf1 /mnt/cases
# 内存捕获
sudo mkdir -p /evidence
sudo 7z x /path/to/base-dc-memory.7z -o/evidence/
```
Artifact 随后将位于 `/mnt/cases/$MFT`、`/mnt/cases/Windows/appcompat/Programs/Amcache.hve`、`/mnt/cases/Windows/Prefetch/`、`/mnt/cases/Windows/System32/config/SYSTEM`、`/mnt/cases/Windows/System32/config/SOFTWARE`、`/mnt/cases/Windows/System32/sru/SRUDB.dat`、`/mnt/cases/Windows/System32/winevt/Logs/` 和 `/evidence/.img`。
### 3. 分流
重启 Claude Code 以便 MCP server 启动并显示工具,然后运行 `/triage` 或直接询问:
```
Triage the domain controller evidence at /mnt/cases with memory at
/evidence/base-dc-memory.img. Start with execution evidence and the MFT
timeline, then check memory, logons, and persistence. Cross-reference across
sources and flag anything CONFIRMED. Cite the call_id for every finding.
```
### 4. 测试
```
source .venv/bin/activate
pytest # no forensic tools or API key required
```
## 三条声明的追踪(供评委查看)
官方规则保证代理报告中的任何发现都可以追溯到生成它的特定工具执行过程。以下是主要评分运行(DFIR Madness Case 001)中三个具有代表性的声明,每项均已对应到 [`audit/execution-log-szechuan.jsonl`](audit/execution-log-szechuan.jsonl) 中的审计日志条目。
| 声明(来自分流报告) | call\_id | 工具 | 日志条目关键字段 |
|---|---|---|---|
| "确认 `coreupdater.exe` (PID 3644) 在内存捕获时正在运行" | `call-000005` | `mem_pslist` | `"binary":"vol"`, `"tool":"mem_pslist"`, output\_summary 列出了 `coreupdater.exe` |
| "从 PID 3644 发起 `ESTABLISHED` 状态的 C2 TCP 连接到 `203.78.103.109:443`" | `call-000006` | `mem_netscan` | `"binary":"vol"`, `"tool":"mem_netscan"`, output\_summary 第一项:`203.78.103.109:443` |
| "312 次失败 + 1 次成功登录,`Administrator@194.61.24.102`,type=10 (RemoteInteractive)" | `call-000012` | `logon_summary` | `"binary":"cache:evtx"`, `"tool":"logon_summary"`, output\_summary 第一项:`Administrator@194.61.24.102 type=10 ok=1 fail=312` |
验证方式:`grep "call-000005\|call-000006\|call-000012" audit/execution-log-szechuan.jsonl | python3 -m json.tool`
完整的监管链检查(所有引用的 `call_id` 与记录的日志对比)也可以离线运行:
```
python -m sift_sentinel.report \
--audit audit/execution-log-szechuan.jsonl \
-f audit/triage-report-citadel-dc01-2026-06-15.md \
--case "DFIR Madness Case 001" \
-o /tmp/szechuan-report.pdf
# 输出:"PASS: all N cited call_id(s) resolve to a logged tool invocation"
```
## 要求的交付物
| # | 交付物 | 位置 |
|---|---|---|
| 1 | 代码仓库(公开,MIT) | 本仓库 |
| 2 | 包含自我纠正序列的演示视频 | [YouTube](https://youtu.be/G-Joj5jwE7Y) · 原始文件 [`docs/demo_video.mp4`](docs/demo_video.mp4)(也位于 Devpost 提交中)。额外的演示录制 — `base-file` SANS 运行:[`docs/sans-2018-base-file-demo.mp4`](docs/sans-2018-base-file-demo.mp4) |
| 3 | 架构图和信任边界 | 本 README 的“架构”部分 |
| 4 | 书面项目描述 | 本 README |
| 5 | 数据集文档 | 针对 **两台 SANS Find Evil! "SRL-2018" 主机** 运行 — `base-dc` (`base-dc-cdrive.E01` + `base-dc-memory.7z`) 和 `base-file` (`base-file-cdrive.E01` + `base-file-memory.7z`) — **外加 DFIR Madness Case 001 "Stolen Szechuan Sauce"** (`CITADEL-DC01` + `DESKTOP-SDN1RPT`);详见 [`docs/dataset.md`](docs/dataset.md) |
| 6 | 包含防篡改证明的准确性报告 | `src/sift_sentinel/benchmark/score.py` + 哈希不变性检查;评分运行详见 [`docs/accuracy_report.md`](docs/accuracy_report.md)(DFIR Madness Case 001 — F1=0.818,0% 幻觉率) |
| 7 | 试用说明 | 本 README 和 `install.sh` |
| 8 | 代理执行日志 | 每次调用对应一条记录 — `audit/execution-log-base-dc.jsonl`, `audit/execution-log-base-file.jsonl` (SANS SRL-2018) 和 `audit/execution-log-szechuan.jsonl` (Szechuan Sauce) |
## 许可证
MIT,详见 [`LICENSE`](LICENSE)。
标签:DLL 劫持, MCP, 大语言模型, 子域名变形, 安全运营, 扫描框架, 数字取证, 自动化应急响应, 自动化脚本, 逆向工具