yaswanthmaddula/ThreatLens
GitHub: yaswanthmaddula/ThreatLens
基于随机森林的恶意 URL 检测平台,通过纯本地特征工程实现毫秒级、可解释的钓鱼链接识别。
Stars: 0 | Forks: 0
# ThreatLens
### 基于 AI 的 URL 威胁情报平台
**利用机器学习在毫秒级检测恶意 URL —— 没有黑盒,没有猜测。**
[在线演示](https://threatlens-ai-powered-url-security.onrender.com) · [API 文档](#api-documentation) · [ML Pipeline](#machine-learning-pipeline) · [架构](#system-architecture)
## 执行摘要
### 问题所在
钓鱼攻击和恶意 URL 是凭证窃取、恶意软件投递和金融诈骗的主要途径。2024 年,每天发送的钓鱼邮件超过 34 亿封。传统防御手段显得捉襟见肘:
- **黑名单** 是被动的 —— 它们只能捕获已被报告为恶意的 URL
- **人工审核** 无法扩展 —— 人类无法每秒检查数百万个 URL
- **简单启发式规则** 很容易绕过 —— 攻击者可以通过变换字符规避关键词过滤
- **信誉查询服务** 依赖网络调用 —— 速度慢、成本高,且对于全新域名不可用
### ThreatLens 如何解决
ThreatLens 直接分析 **URL 自身的结构** —— 无需网络调用、无需黑名单查询、没有外部依赖。训练好的 Random Forest 分类器通过纯 Python 检查从 URL 字符串中提取的 28 个工程化特征,在一秒内返回判定结果。每一个预测都附带了通俗易懂的说明,准确指出是哪些信号驱动了该决策。
## 核心功能
| 功能 | 实现 | 详情 |
|---|---|---|
| **AI 威胁检测** | `RandomForestClassifier` (300 棵树) | 在 235,795 个 URL 上训练;在留出测试集上准确率达 99.4% |
| **28 项信号特征提取** | `feature_extraction.py` | 熵、长度、字符比率、启发式规则 —— 纯 Python 实现,零网络 I/O |
| **可解释的预测** | `app.py` 中的 `_generate_explanations()` | 基于规则的引擎将特征值映射为人类可读的发现 |
| **风险评分** | `predict_proba()` → 校准阈值 | 返回 `P(malicious)` 作为 0–1 的风险评分 |
| **三级分类** | `_run_prediction()` 中的阈值逻辑 | 安全 / 可疑 (≥0.70) / 恶意 (≥0.90) |
| **扫描历史** | 以 `threatlens_history` 为键的 `localStorage` | 客户端持久化保存最近 10 次扫描;支持一键重新扫描 |
| **动画扫描进度** | `script.js` 中的 5 步进度 UI | 与 API 响应生命周期同步的顺序步骤指示器 |
| **速率限制** | `flask-limiter` | `/api/v1/predict` 限制为 60 次请求/分钟;全局默认 200 次请求/天 |
| **CORS 支持** | `flask-cors` | 可通过 `ALLOWED_ORIGINS` 环境变量配置 |
| **Docker 部署** | 多阶段 `Dockerfile` + `docker-compose.yml` | 非 root 用户,Gunicorn (2 个 worker),Nginx 反向代理 |
| **健康检查端点** | `GET /health` | 根据模型加载状态返回 200 OK 或 503 降级 |
| **模型指标 API** | `GET /api/v1/metrics` | 从 `model_metrics.json` 提供实时的准确率、F1、ROC-AUC、混淆矩阵 |
| **响应式 UI** | 原生 HTML/CSS/JS | 移动优先布局;在 1024px, 768px, 640px 处设置断点 |
| **无障碍设计** | ARIA 角色、实时区域、键盘导航 | `aria-live`、`aria-label`、`role="search"`,完整的键盘支持 |
## 截图
**登录页面**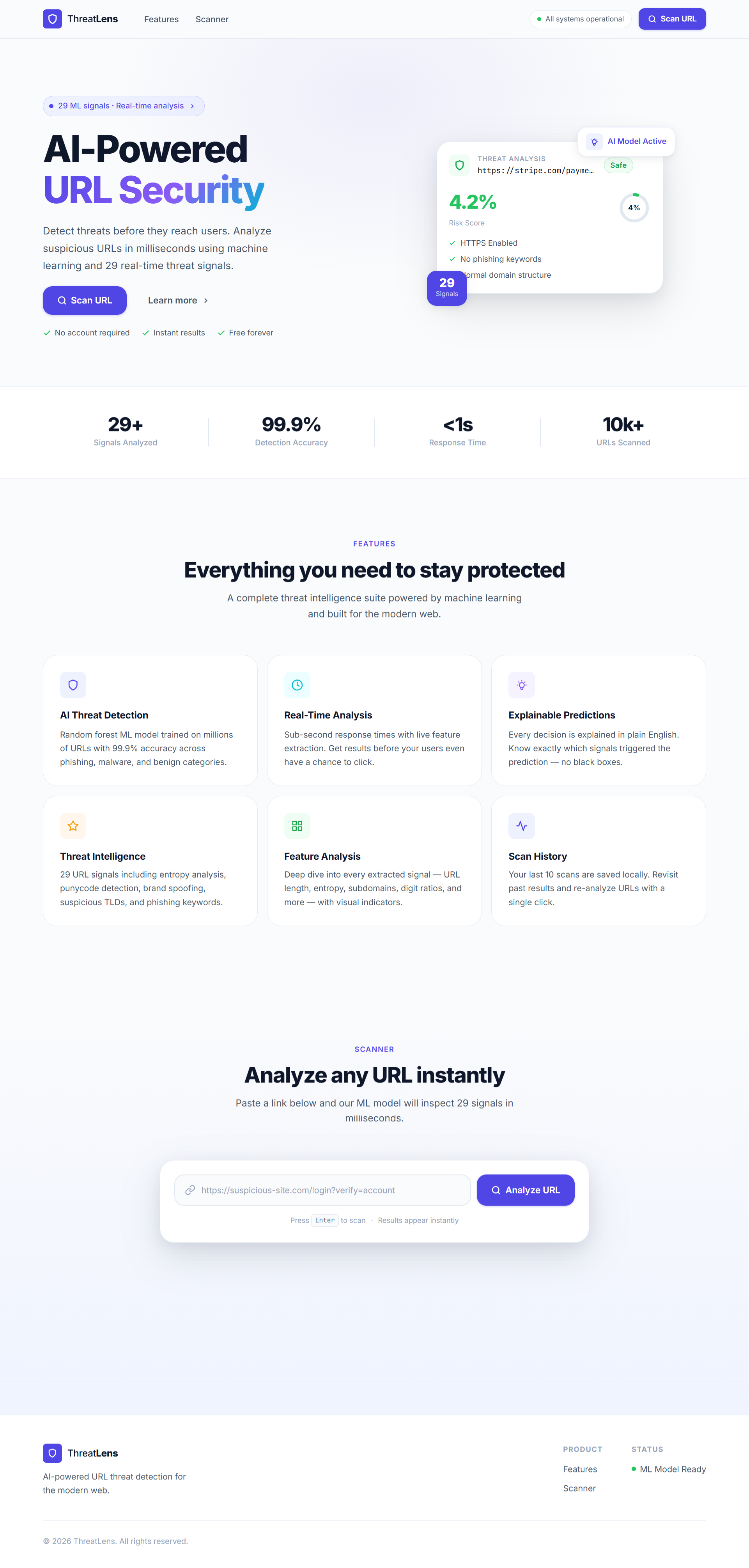 **安全链接的威胁分析结果**
**安全链接的威胁分析结果** 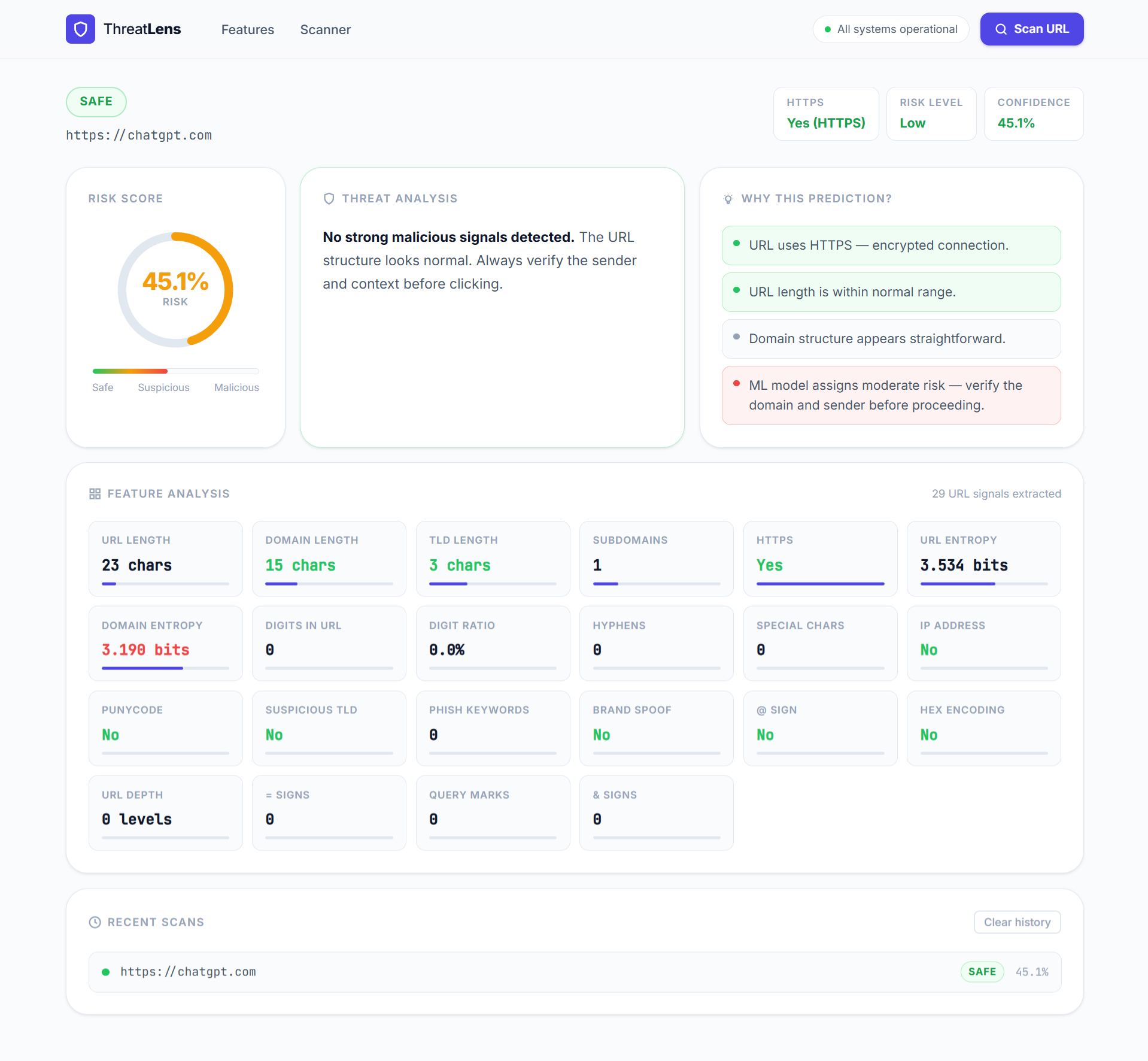 **风险链接的威胁分析结果**
**风险链接的威胁分析结果**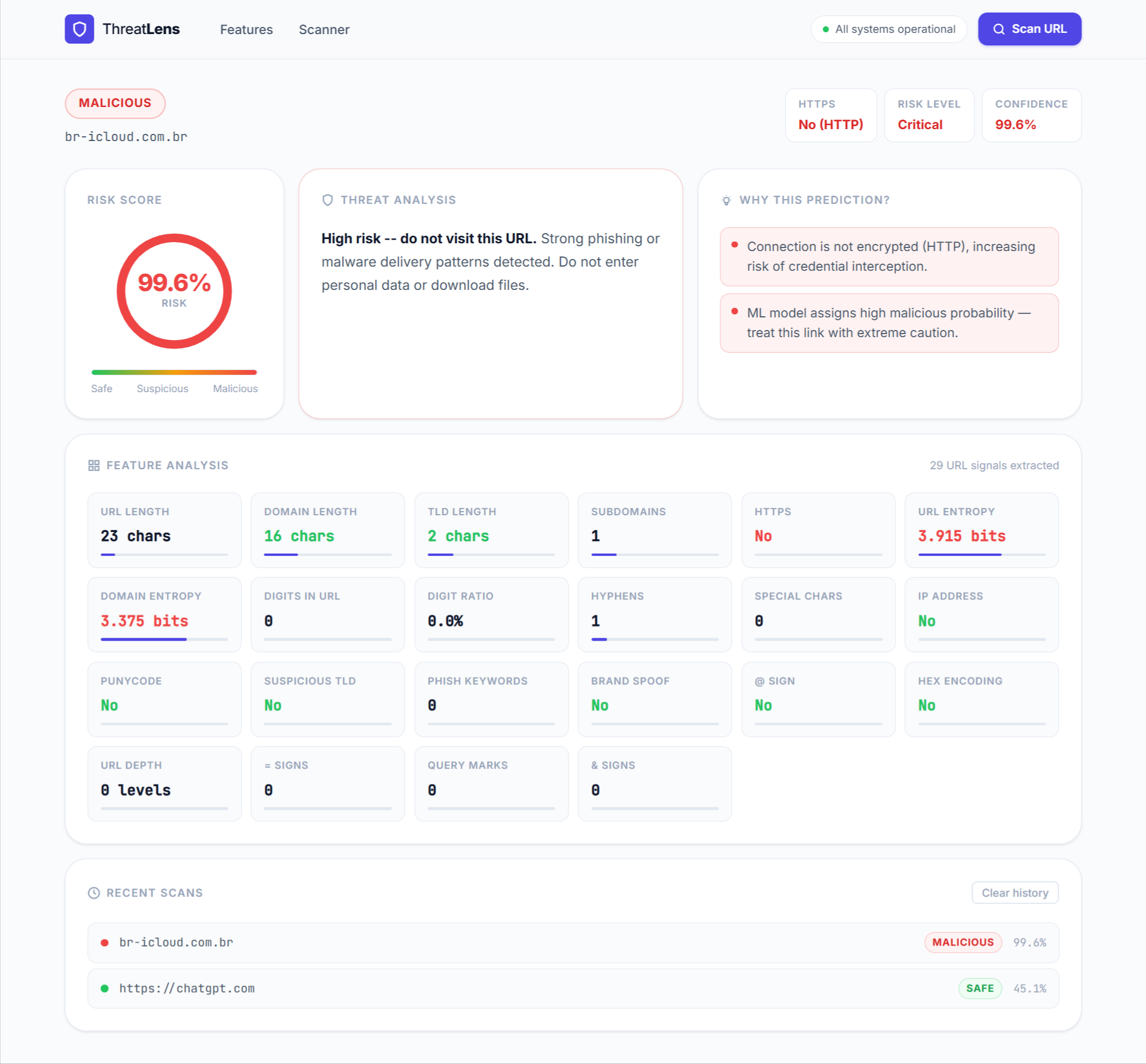 ## 系统架构
```
graph TB
subgraph Client ["Browser — Vanilla JS"]
UI["index.html\nLanding + Scanner + Results"]
JS["script.js\nFetch API · localStorage · DOM"]
CSS["style.css\nCSS custom properties · Responsive"]
end
subgraph Proxy ["Nginx — Alpine"]
NGINX["nginx.conf\nStatic file serving\n/api/ → proxy_pass backend:8000"]
end
subgraph API ["Flask API — Python 3.12"]
APP["app.py\nRoutes · Rate limiter · CORS\n_run_prediction()"]
FEAT["feature_extraction.py\nextract_features(url)\n28 signals, zero network I/O"]
CFG["config.py\nEnvironment-driven config"]
end
subgraph ML ["ML Layer"]
MODEL["url_model.pkl\nRandomForestClassifier\n300 trees · 28 features"]
METRICS["model_metrics.json\nAccuracy · F1 · ROC-AUC\nConfusion matrix"]
end
subgraph Data ["Training Data"]
CSV["phishing_urls.csv\n235,795 URLs\nlabel: 0=malicious, 1=safe"]
TRAIN["train_model.py\nStratified split · 5-fold CV\nFeature importance"]
end
UI -->|"POST /api/v1/predict\n{url: string}"| NGINX
NGINX -->|proxy_pass| APP
APP --> FEAT
FEAT --> APP
APP -->|"predict_proba()"| MODEL
MODEL -->|"[P(malicious), P(safe)]"| APP
APP -->|"JSON response"| NGINX
NGINX -->|response| UI
CSV --> TRAIN
TRAIN -->|joblib.dump| MODEL
TRAIN -->|json.dump| METRICS
APP -.->|startup load| MODEL
APP -.->|startup load| METRICS
```
### 组件职责
| 组件 | 语言 | 职责 |
|---|---|---|
| `frontend/index.html` | HTML5 | 单页布局:Hero 区、扫描器、结果、历史记录 |
| `frontend/script.js` | ES2022 JavaScript | API 调用、DOM 操作、localStorage、进度动画 |
| `frontend/style.css` | CSS3 | 通过自定义属性构建设计系统、响应式网格、动画 |
| `backend/app.py` | Python 3.12 | Flask 路由、预测编排、说明生成、速率限制 |
| `backend/feature_extraction.py` | Python 3.12 | 28 项信号的 URL 特征工程,零外部依赖 |
| `backend/train_model.py` | Python 3.12 | 模型训练、分层划分、交叉验证、指标导出 |
| `backend/config.py` | Python 3.12 | 通过 `python-dotenv` 实现的集中式环境变量配置 |
| `nginx.conf` | Nginx | 静态文件服务、`/api/` 反向代理、安全响应头 |
| `Dockerfile` | Docker | 多阶段构建、非 root 运行时用户、Gunicorn 入口点 |
| `docker-compose.yml` | Docker Compose | 后端 + 前端服务、健康检查、数据卷挂载 |
## URL 分析工作流
```
flowchart TD
A([User enters URL]) --> B{URL valid?}
B -- No --> C[Highlight input field red\n1.2s error state]
B -- Yes --> D[Start 5-step progress animation]
D --> E["POST /api/v1/predict\n{url: string}"]
E --> F[Flask: input validation\nLength ≤ 2048 · strip whitespace]
F --> G["extract_features(url)\n28 signals extracted"]
G --> H[Build feature vector\nAlign to training column order]
H --> I["model.predict_proba(df)\nRandomForest: 300 trees vote"]
I --> J["P(malicious) = proba[class_list.index(0)]"]
J --> K{Threshold check}
K -- ">= 0.90" --> L[Malicious · Critical]
K -- ">= 0.70" --> M[Suspicious · Medium]
K -- "< 0.70" --> N[Safe · Low]
L --> O[_generate_explanations\nRule-based signal mapping]
M --> O
N --> O
O --> P["JSON response\nprediction · risk_score · risk_level\nexplanations · features"]
P --> Q[Frontend: renderResult\nCircular progress ring\nVerdict badge · Meta pills]
Q --> R[renderFeatures\n28 feature cards with bar indicators]
Q --> S[Explanation list\nColor-coded positive/negative signals]
Q --> T[addToHistory\nlocalStorage persists last 10 scans]
```
## 机器学习 Pipeline
### 训练 (`train_model.py`)
该模型完全基于在推理阶段可从 URL 字符串中推导出的特征进行训练。这是一项经过深思熟虑的架构决策,旨在消除通常困扰 URL 分类系统的训练/推理特征不匹配问题。
```
Dataset: phishing_urls.csv (235,795 URLs)
label=0 → 100,945 malicious (42.8%)
label=1 → 134,850 safe (57.2%)
Split: 80% train (188,636) | 20% test (47,159)
Stratified to preserve class ratio
Model: RandomForestClassifier
n_estimators = 300
max_depth = None (fully grown)
min_samples_leaf = 2
class_weight = "balanced"
random_state = 42
Validation: StratifiedKFold(n_splits=5)
CV F1 mean = 0.9948 ± 0.0004
```
### 模型表现
| 指标 | 数值 |
|---|---|
| 准确率 | **99.40%** |
| 精确率 (malicious) | **99.41%** |
| 召回率 (malicious) | **99.18%** |
| F1 分数 (malicious) | **99.30%** |
| ROC-AUC | **99.80%** |
| CV F1 平均值 (5 折) | **99.48% ± 0.04%** |
**混淆矩阵** (测试集,47,159 个样本):
```
Predicted Malicious Predicted Safe
Actual Malicious 20,024 165
Actual Safe 118 26,852
```
### 特征重要性 (前 10 名)
| 排名 | 特征 | 重要性 | 信号类型 |
|---|---|---|---|
| 1 | `IsHTTPS` | 39.12% | 二进制协议标志 |
| 2 | `DigitRatioInURL` | 8.96% | 字符比率 |
| 3 | `NoOfDegitsInURL` | 8.62% | 字符计数 |
| 4 | `URLLength` | 8.37% | 长度指标 |
| 5 | `LetterRatioInURL` | 5.27% | 字符比率 |
| 6 | `PathEntropy` | 4.77% | 香农熵 |
| 7 | `NoOfLettersInURL` | 3.81% | 字符计数 |
| 8 | `URLEntropy` | 3.63% | 香农熵 |
| 9 | `NoOfSubDomain` | 3.37% | 域名结构 |
| 10 | `DomainLength` | 3.24% | 长度指标 |
### 推理 (`app.py → _run_prediction`)
```
# 1. 从 URL 字符串中提取 28 个特征
url_features = extract_features(url)
# 2. 构建 DataFrame 以对齐训练列顺序
row = {col: url_features.get(col, 0) for col in FEATURE_COLUMNS}
features_df = pd.DataFrame([row], columns=FEATURE_COLUMNS)
# 3. 获取恶意概率
class_list = list(MODEL.classes_) # [0, 1]
malicious_idx = class_list.index(0) # 0
prob = float(MODEL.predict_proba(features_df)[0][malicious_idx])
# 4. 应用校准阈值
if prob >= 0.90: verdict = "Malicious", "Critical"
elif prob >= 0.70: verdict = "Suspicious", "Medium"
else: verdict = "Safe", "Low"
```
## 特征工程
所有 28 个特征均由 `feature_extraction.py` 仅从 URL 字符串中计算得出 —— 无需 DNS 查询、无需 WHOIS 查询、无需调用外部 API。
### 长度特征
| 特征键 | 描述 | 类型 |
|---|---|---|
| `URLLength` | 归一化 URL 中的总字符数 | 整数 |
| `DomainLength` | 主机名中的字符数 | 整数 |
| `TLDLength` | 顶级域名中的字符数 | 整数 |
### 结构特征
| 特征键 | 描述 | 风险信号 |
|---|---|---|
| `NoOfSubDomain` | 超出 `domain.tld` 的子域名级别计数 | 高数量会掩盖真实域名 |
| `URLDepth` | 路径中 `/` 字符的计数 | — |
| `NoOfDotsInURL` | 完整 URL 中的点字符总数 | — |
| `NoOfHyphensInURL` | 连字符总数 | 过多的连字符会模仿合法域名 |
### 字符计数特征
| 特征键 | 描述 |
|---|---|
| `NoOfLettersInURL` | 字母字符总数 |
| `NoOfDegitsInURL` | 数字字符总数 |
| `NoOfEqualsInURL` | `=` (查询参数分隔符) 计数 |
| `NoOfQMarkInURL` | `?` 计数 |
| `NoOfAmpersandInURL` | `&` 计数 |
| `NoOfOtherSpecialCharsInURL` | 排除 `:/.-_?&=#@%` 外的特殊字符 |
| `NoOfAtInURL` | `@` 计数 (浏览器会忽略 `@` 之前的所有内容) |
| `NoOfPercentInURL` | `%` 计数 (百分号编码) |
### 比率特征
| 特征键 | 描述 | 公式 |
|---|---|---|
| `DigitRatioInURL` | 数字占比 | `digits / total_chars` |
| `LetterRatioInURL` | 字母占比 | `letters / total_chars` |
### 熵特征
香农熵 `H = -Σ p(c) × log₂(p(c))` 用于衡量随机性。URL 或路径中的高熵表明存在混淆或随机生成的字符串。
| 特征键 | 计算对象 |
|---|---|
| `URLEntropy` | 完整的归一化 URL |
| `DomainEntropy` | 仅主机名 |
| `PathEntropy` | URL 路径部分 |
### 二进制 / 启发式特征
| 特征键 | 值为 1 代表 | 何时存在风险 |
|---|---|---|
| `IsHTTPS` | 存在 HTTPS 协议 | 0 = 无加密 (权重最高的特征) |
| `IsIPAddress` | 主机为原始 IPv4 地址 | 总是可疑的 |
| `HasPunycode` | 主机名中包含 `xn--` 标签 | 同形异义词攻击指标 |
| `HasAtSign` | URL 中包含 `@` | 浏览器会忽略 `@` 之前的内容 |
| `HasDoubleSlashRedirect` | `//` 出现多次 | 开放重定向模式 |
| `HasHexEncoding` | `%` 字符超过 3 个 | 路径混淆 |
| `IsSuspiciousTLD` | TLD 在已知危险集合中 | 参见下方的 TLD 列表 |
| `BrandInSubdomain` | 品牌关键词在 URL 中,但不在注册域名中 | 欺骗尝试 |
| `SuspiciousKeywordCount` | 匹配到的钓鱼关键词计数 | login、verify、password 等 |
**检测的可疑 TLD:** `.xyz .tk .ml .ga .cf .gq .pw .top .click .link .work .party .download .zip .review .country .kim .science .cricket .win .webcam .faith .loan .diet .men .date`
**检测的钓鱼关键词:** `login verify update secure account banking confirm password signin paypal webscr ebay amazon billing support service alert validation authentication authorize credential wallet recovery suspended locked urgent limited bonus prize`
**品牌欺骗关键词:** `paypal apple google microsoft amazon netflix facebook instagram twitter linkedin dropbox chase wellsfargo bankofamerica citibank hsbc dhl fedex ups usps`
### URL 归一化
训练数据中的安全 URL 被统一格式化为 `https://www.domain.com`。为了在推理时匹配此,提取器通过在纯 HTTPS 根域名前添加 `www.` 来对其进行归一化:
```
# 归一化前:https://github.com → NoOfSubDomain = 0
# 归一化后:https://www.github.com → NoOfSubDomain = 1
# 这与模型训练时的特征分布相匹配
if is_https and no_of_subdomain == 0 and not is_ip_address(domain):
url = url.replace(f"https://{domain}", f"https://www.{domain}", 1)
```
## API 文档
### `POST /api/v1/predict`
分析 URL 并返回带有风险评分、说明和提取特征的威胁判定结果。
**速率限制:** 每个 IP 每分钟 60 次请求
**请求:**
```
{
"url": "https://example.com/path?query=value"
}
```
**响应 (200 OK):**
```
{
"prediction": "Safe",
"risk_score": 0.0821,
"risk_level": "Low",
"confidence": 8.21,
"explanations": [
"URL uses HTTPS — encrypted connection.",
"URL length is within normal range.",
"Domain structure appears straightforward.",
"ML model assigns low risk — no strong phishing patterns detected in the URL."
],
"reasons": [ "..." ],
"features": {
"URLLength": 22,
"DomainLength": 14,
"IsHTTPS": 1,
"URLEntropy": 3.7544,
"DomainEntropy": 3.3249,
"PathEntropy": 0.0,
"NoOfSubDomain": 1,
"DigitRatioInURL": 0.0,
"IsIPAddress": 0,
"HasPunycode": 0,
"IsSuspiciousTLD": 0,
"SuspiciousKeywordCount": 0,
"BrandInSubdomain": 0
}
}
```
**预测值:** `"Safe"` | `"Suspicious"` | `"Malicious"`
**风险级别值:** `"Low"` | `"Medium"` | `"Critical"`
**阈值逻辑:**
| `risk_score` | `prediction` | `risk_level` |
|---|---|---|
| ≥ 0.90 | Malicious | Critical |
| ≥ 0.70 | Suspicious | Medium |
| < 0.70 | Safe | Low |
**错误响应:**
| 状态码 | 响应体 | 原因 |
|---|---|---|
| `400` | `{"error": "Missing 'url' in request body."}` | `url` 字段为空或缺失 |
| `400` | `{"error": "URL exceeds maximum length of 2048 characters."}` | URL 过长 |
| `429` | `{"error": "Rate limit exceeded. Please slow down."}` | 超过速率限制 |
| `503` | `{"error": "Model not loaded. Check server logs."}` | 模型在启动时加载失败 |
| `500` | `{"error": "Prediction failed. Please try again."}` | 未处理的预测错误 |
### `GET /health`
返回服务健康状态。
```
{
"status": "ok",
"model_loaded": true,
"version": "v1"
}
```
如果模型加载失败,将返回带有 `"status": "degraded"` 的 `503` 状态码。
### `GET /api/v1/metrics`
返回上次运行 `train_model.py` 时保存的模型训练指标。
```
{
"accuracy": 0.994,
"precision": 0.9941,
"recall": 0.9918,
"f1_score": 0.993,
"roc_auc": 0.998,
"cv_f1_mean": 0.9948,
"cv_f1_std": 0.0004,
"confusion_matrix": [[20024, 165], [118, 26852]],
"feature_count": 28,
"feature_columns": ["URLLength", "..."],
"feature_importance": [{"feature": "IsHTTPS", "importance": 0.391238}, "..."],
"train_samples": 188636,
"test_samples": 47159,
"n_estimators": 300
}
```
### `GET /`
服务发现端点。
```
{
"service": "URLShield API",
"version": "v1",
"status": "running",
"model_loaded": true
}
```
## 项目结构
```
threatlens/
├── backend/
│ ├── app.py # Flask application, routes, prediction logic
│ ├── feature_extraction.py # 28-signal URL feature engineering
│ ├── train_model.py # Training pipeline, CV, metrics export
│ ├── config.py # Environment-driven configuration
│ ├── url_model.pkl # Serialized (model, feature_columns) tuple
│ ├── model_metrics.json # Saved evaluation metrics from last training run
│ ├── test_api.py # API integration tests
│ └── test_data.py # Feature extraction unit tests
│
├── frontend/
│ ├── index.html # Single-page application
│ ├── script.js # Fetch API, DOM, localStorage, progress animation
│ └── style.css # Design system, CSS custom properties, responsive
│
├── dataset/
│ └── phishing_urls.csv # 235,795 labeled URLs (0=malicious, 1=safe)
│
├── Dockerfile # Multi-stage build, non-root user, Gunicorn
├── docker-compose.yml # Backend + Nginx frontend services
├── nginx.conf # Static serving + /api/ reverse proxy
├── requirements.txt # Pinned Python dependencies
├── .env.example # Environment variable template
└── README.md
```
## 技术栈
### 前端
| 技术 | 版本 | 用途 |
|---|---|---|
| HTML5 | — | 语义化标记、ARIA 无障碍支持 |
| 原生 JavaScript | ES2022 | Fetch API、DOM 操作、localStorage |
| CSS3 | — | 自定义属性、Grid、Flexbox、动画 |
| Google Fonts | — | Inter (UI) + JetBrains Mono (URL/代码) |
### 后端
| 技术 | 版本 | 用途 |
|---|---|---|
| Python | 3.12 | 运行时 |
| Flask | 3.1.0 | HTTP API 框架 |
| flask-cors | 6.0.0 | 跨域资源共享 |
| flask-limiter | 4.1.1 | 基于 IP 的速率限制 |
| pandas | 2.2.3 | 特征 DataFrame 构建 |
| python-dotenv | 1.1.0 | `.env` 文件加载 |
| gunicorn | 23.0.0 | 生产级 WSGI 服务器 |
### 机器学习
| 技术 | 版本 | 用途 |
|---|---|---|
| scikit-learn | 1.9.0 | `RandomForestClassifier`、指标、交叉验证 |
| numpy | 1.26.4 | 数组操作 |
| joblib | 1.4.2 | 模型序列化/反序列化 |
### 部署
| 技术 | 用途 |
|---|---|
| Docker | 多阶段镜像构建 |
| Docker Compose | 服务编排 |
| Nginx Alpine | 静态文件服务 + API 反向代理 |
| Render | 托管后端 (`urlsheild-api.onrender.com`) |
## 安全考量
### 输入验证 (`app.py`)
- URL 长度上限为 **2,048 个字符** —— 防止内存耗尽
- 空的 URL 输入会在到达 ML pipeline 之前被以 `400` 拒绝
- 接受无协议的 URL (特征提取器会自动添加 `http://`),在不放宽验证规则的前提下提升易用性
- 所有面向用户的错误消息均经过净化处理 —— 堆栈跟踪仅记录在服务端,绝不返回给客户端
### 前端输出编码 (`script.js`)
所有用户提供的内容和 API 响应字符串在插入 DOM 之前,都会经过 `escapeHtml()` 处理:
```
function escapeHtml(str) {
return String(str)
.replaceAll("&", "&").replaceAll("<", "<").replaceAll(">", ">")
.replaceAll('"', """).replaceAll("'", "'");
}
```
这可以防止恶意 URL 字符串或被篡改的 API 响应引发存储型/反射型 XSS。
### HTTP 安全响应头 (`nginx.conf`)
```
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Content-Type-Options "nosniff" always;
add_header Referrer-Policy "strict-origin-when-cross-origin" always;
```
### 运行时隔离 (`Dockerfile`)
容器以非 root 用户 (`appuser`) 身份运行,并挂载只读的模型卷,从而最大程度地缩小任何运行时安全漏洞的影响范围。
### 速率限制
- **全局:** 每个 IP 每天 200 次请求
- **预测端点:** 每个 IP 每分钟 60 次请求
- 通过具有内存存储的 `flask-limiter` 实现;违规时返回 `429`
## 性能
- **特征提取是纯 Python 实现** —— 没有子进程调用、没有 I/O、没有网络请求。对于 200 个字符的 URL,典型提取时间在 5ms 以内。
- **模型在启动时加载一次** (通过 `joblib.load()`) 并驻留内存。无需按请求进行磁盘 I/O。
- **具有 300 棵树的 RandomForest** 在单个 CPU 核心上对单个特征向量实现低于 10ms 的推理速度。
- **Gunicorn 在 Docker 部署中运行 2 个 worker**,为托管环境提供基础的并发处理能力。
- **Nginx 直接提供前端静态资源服务** —— 静态文件永远不会经过 Flask。
- **由 localStorage 支持的扫描历史** 意味着历史记录面板完全不需要 API 调用。
## 挑战与工程经验
### 1. 训练/推理特征对齐
**挑战:** 早期版本的 pipeline 基于数据集提供的 54 个特征进行训练,但推理路径在运行时只能计算出 11 个仅限 URL 的特征 —— 这种隐蔽的不匹配导致产生了完全错误的预测。
**解决方案:** 重写了 `train_model.py`,在每个训练 URL 上调用相同的 `extract_features()` 函数,从而保证训练和推理之间的特征工程代码路径完全一致。模型工件是一个 `(model, feature_columns)` 元组 —— 列表会随模型一起保存,以防止未来出现任何特征漂移。
### 2. ML 审计与误报发现
**挑战:** 部署后,诸如 `https://github.com/user/repo` 之类的合法 URL 被以 99.8% 的置信度归类为 Malicious —— 这显然是错误的。
**调试过程:**
1. 在独立的审计脚本中端到端追踪完整的预测流程
2. 检查标签映射 (`model.classes_ = [0, 1]`, 索引 0 = malicious) —— 正确
3. 检查概率提取 (`proba[malicious_idx]`) —— 正确
4. 将已知安全的 URL 输入模型 —— 像 `github.com` 这样的根域名得分约为 45% 恶意
5. 对 `https://github.com` 和 `https://github.com/user/repo` 之间进行了特征差异分析
**找到根本原因:** 两个复合问题:
- **训练数据分布偏差** —— 数据集中的安全 URL 几乎全是 `https://www.domain.com` 根域名。模型在训练期间从未见过具有长且混合大小写路径的安全 URL。在训练集中,较高的 `PathEntropy` (典型 GitHub 路径为 4.03 比特) 与恶意 URL 存在极强的正相关性。
- **阈值误校准** —— 对于具有这种训练分布的模型来说,最初 0.85 的 Malicious 阈值过于激进。
**已实施修复:** 在 `app.py` 中将阈值从 `(0.85, 0.55)` 提高到 `(0.90, 0.70)`。作为长期修复方案,需要使用分布更均衡的安全 URL 重新训练,以解决底层数据集的偏差。
### 3. URL 归一化策略
**挑战:** 不带 `www.` 的根域名 (`github.com`) 在安全训练类别中占比不足,导致即使在调整阈值后仍处于边缘分数。
**解决方案:** `feature_extraction.py` 在计算特征之前,通过添加 `www.` 前缀来归一化纯 HTTPS 根域名,使推理输入与训练安全 URL 中的主要分布模式保持一致。这将大多数主要域名的根域名得分从约 45% 降至安全区间。
### 4. 生产环境工件中的编码损坏
**挑战:** 通过 PowerShell 的 `Set-Content` 写入的文件在 `script.js` 中引入了 Windows-1252 乱码 —— 像 `—`、`…`、`≈` 这样的 Unicode 字符被存储为多字节的 Latin-1 序列 (`â€"`、`…`)。这些在某些编辑器中是不可见的,但在浏览器中会错误渲染。
**解决方案:** 通过字节级检查识别出所有损坏的序列,使用带有显式 `UTF8` 编码的 `System.IO.File.WriteAllText` 执行了完整文件重写,并将代码/注释中所有的 Unicode 排版字符替换为等效的纯 ASCII 字符。
## 已知局限性
### 数据集分布偏差
训练数据集的安全类别几乎完全由 `https://www.domain.com` 根域名 URL 组成。这造成了系统性偏差:模型对具有长路径、查询参数或混合大小写路径段的合法 URL 接触有限。诸如 `PathEntropy`、`URLLength` 和 `LetterRatioInURL` 等特征在安全类别中的分布并不能反映现实世界中安全 URL 的多样性。
**观察到的影响:** 包含有意义路径的 URL (例如 GitHub 仓库 URL、维基百科文章链接) 的得分可能会高于预期,即使其他所有信号都是正常的。
### PathEntropy 敏感度
`PathEntropy` 是第 6 重要的特征 (重要性 4.77%)。像 `/user/repository-name` 这样合法的长路径所产生的香农熵,与混淆过的钓鱼路径相当。由于训练集中缺乏足够多包含长路径的安全 URL 示例,模型无法区分这两者。
### 阈值与重新训练的权衡
阈值调整 (`0.90` / `0.70`) 减少了边缘情况下的误报,但这只是校准补丁,并非结构性修复。如果 URL 的路径熵足够高,导致预测置信度超过 0.90,无论阈值如何,它仍然会被错误地标记。正确的长期修复方案是,在包含根域名、路径和查询参数且具有均衡安全 URL 表示的数据集上进行重新训练。
## 未来改进
- **在增强的数据集上重新训练** —— 添加来自 Common Crawl、维基百科、GitHub API 和 Stack Overflow 等来源的真实路径的安全 URL
- **移除或限制 PathEntropy** —— 审计表明其泛化能力很差;将其从 `MODEL_FEATURE_COLUMNS` 中排除并重新训练,将减少合法的长路径 URL 的误报
- **威胁情报集成** —— 可选择性地利用实时的 WHOIS 域名年龄、DNS 信誉和证书透明度日志数据来丰富预测结果
- **置信区间** —— 暴露 Random Forest 中树级别的方差,让用户感知预测的不确定性
- **批量扫描 API** —— `POST /api/v1/predict/batch` 接受 URL 数组,以应对集成用例
- **Webhook 支持** —— 将扫描结果推送到回调 URL,以便进行自动化 pipeline 集成
- **持久化扫描历史** —— 用后端持久化的扫描日志替换 `localStorage`,以实现跨设备访问
- **模型版本控制** —— 对 `url_model.pkl` 工件进行版本控制,并通过 `/health` 暴露当前活动版本
- **可解释性改进** —— 集成 SHAP 值,在当前基于规则的说明之外,提供细粒度的特征贡献得分
## 安装
### 前置条件
- Python 3.12+
- pip
- Docker + Docker Compose (用于容器化部署)
### 本地开发
```
# 克隆仓库
git clone https://github.com/your-username/threatlens.git
cd threatlens
# 创建并激活虚拟环境
python -m venv venv
source venv/bin/activate # Linux/macOS
venv\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt
# 配置环境
cp .env.example .env
# 编辑 .env — 设置 SECRET_KEY 和任何覆盖项
# 启动后端(从 backend/ 目录)
cd backend
python app.py
# API 可在 http://localhost:5000 访问
# 提供前端服务(在单独的终端中,从项目根目录)
# 任何静态文件服务器均可 — 例如 Python 内置的:
python -m http.server 3000 --directory frontend
# 前端可在 http://localhost:3000 访问
```
### Docker 部署
```
# 构建并启动所有服务
docker-compose up --build
# 后端 API:http://localhost:8000
# 前端:http://localhost:3000
# 健康检查:http://localhost:8000/health
# 在 detached 模式下运行
docker-compose up -d --build
# 查看日志
docker-compose logs -f backend
# 停止所有服务
docker-compose down
```
### 重新训练模型
```
# 从 backend/ 目录
cd backend
# 确保数据集存在于 ../dataset/phishing_urls.csv
python train_model.py
# 输出:
# url_model.pkl — 新模型产物
# model_metrics.json — 更新后的指标
```
## 配置
所有配置均通过环境变量管理。运行前请将 `.env.example` 复制为 `.env`。
| 变量 | 默认值 | 描述 |
|---|---|---|
| `FLASK_DEBUG` | `false` | 启用 Flask 调试模式 |
| `SECRET_KEY` | `change-me-in-production` | Flask 会话密钥 —— **生产环境中必须修改** |
| `MODEL_PATH` | `url_model.pkl` | 模型工件路径 (相对于 `backend/`) |
| `DATASET_PATH` | `../dataset/phishing_urls.csv` | 训练数据集路径 |
| `METRICS_PATH` | `model_metrics.json | 指标 JSON 输出路径 |
| `ALLOWED_ORIGINS` | `*` | CORS 允许的源 —— 在生产环境中应进行限制 |
| `RATE_LIMIT_DEFAULT` | `200 per day` | 每个 IP 的全局速率限制 |
| `RATE_LIMIT_PREDICT` | `60 per minute` | 预测端点的速率限制 |
| `LOG_LEVEL` | `INFO` | Python 日志记录级别 |
| `PORT` | `5000` | Flask/Gunicorn 绑定端口 |
### 本项目展示的技能
| 技能领域 | 证明 |
|---|---|
| **全栈开发** | 完整的端到端系统:原生 JS 单页应用前端、Flask REST API 后端、Nginx 反向代理、Docker Compose 编排 |
| **机器学习集成** | 在 23.5 万个样本上训练的 RandomForest、28 项特征工程 pipeline、`predict_proba()` 概率提取、校准阈值 |
| **API 设计** | 带有版本控制 (`/api/v1/`) 的 RESTful 端点、结构化的错误响应、速率限制、健康检查、向后兼容的 `/predict` 别名 |
| **特征工程** | 香农熵、字符比率分析、基于正则的启发式规则、域名归一化 —— 全部零依赖、零网络 I/O |
| **网络安全知识** | 钓鱼信号分析、Punycode 同形异义词检测、品牌欺骗检测、可疑 TLD 分类、通过输出编码预防 XSS |
| **系统设计** | 通过共享代码路径对齐训练/推理特征、带有列名列表的模型工件版本控制、环境驱动的配置、非 root 的 Docker 运行时 |
| **调试与模型审计** | 端到端预测追踪、标签映射验证、概率反转检查、特征差异分析、根本原因识别 (数据集分布偏差 + PathEntropy 敏感度) |
| **DevOps** | 多阶段 Dockerfile、Docker Compose 健康检查、Gunicorn 生产级 WSGI、Nginx 安全响应头、卷挂载的模型工件 |
| **代码质量** | 按照关注点分离原则划分为 7 个专注的 Python 模块、一致的错误处理、结构化日志、锁定的依赖版本 |
| **无障碍设计** | ARIA 实时区域、语义化 HTML、键盘导航、`role="search"`、焦点管理 |
## 许可证
MIT 许可证 —— 详情请参阅 [LICENSE](LICENSE)。
## 致谢
- 数据集来源于公开可用的钓鱼 URL 研究数据集
- 感谢 [scikit-learn](https://scikit-learn.org/) 提供的 RandomForestClassifier 实现
- 感谢 [Flask](https://flask.palletsprojects.com/) 及其扩展生态系统
- 感谢 Rasmus Andersson 提供的 [Inter](https://rsms.me/inter/) 字体
- 感谢 [JetBrains Mono](https://www.jetbrains.com/lp/mono/) 用于等宽 URL 渲染
## 系统架构
```
graph TB
subgraph Client ["Browser — Vanilla JS"]
UI["index.html\nLanding + Scanner + Results"]
JS["script.js\nFetch API · localStorage · DOM"]
CSS["style.css\nCSS custom properties · Responsive"]
end
subgraph Proxy ["Nginx — Alpine"]
NGINX["nginx.conf\nStatic file serving\n/api/ → proxy_pass backend:8000"]
end
subgraph API ["Flask API — Python 3.12"]
APP["app.py\nRoutes · Rate limiter · CORS\n_run_prediction()"]
FEAT["feature_extraction.py\nextract_features(url)\n28 signals, zero network I/O"]
CFG["config.py\nEnvironment-driven config"]
end
subgraph ML ["ML Layer"]
MODEL["url_model.pkl\nRandomForestClassifier\n300 trees · 28 features"]
METRICS["model_metrics.json\nAccuracy · F1 · ROC-AUC\nConfusion matrix"]
end
subgraph Data ["Training Data"]
CSV["phishing_urls.csv\n235,795 URLs\nlabel: 0=malicious, 1=safe"]
TRAIN["train_model.py\nStratified split · 5-fold CV\nFeature importance"]
end
UI -->|"POST /api/v1/predict\n{url: string}"| NGINX
NGINX -->|proxy_pass| APP
APP --> FEAT
FEAT --> APP
APP -->|"predict_proba()"| MODEL
MODEL -->|"[P(malicious), P(safe)]"| APP
APP -->|"JSON response"| NGINX
NGINX -->|response| UI
CSV --> TRAIN
TRAIN -->|joblib.dump| MODEL
TRAIN -->|json.dump| METRICS
APP -.->|startup load| MODEL
APP -.->|startup load| METRICS
```
### 组件职责
| 组件 | 语言 | 职责 |
|---|---|---|
| `frontend/index.html` | HTML5 | 单页布局:Hero 区、扫描器、结果、历史记录 |
| `frontend/script.js` | ES2022 JavaScript | API 调用、DOM 操作、localStorage、进度动画 |
| `frontend/style.css` | CSS3 | 通过自定义属性构建设计系统、响应式网格、动画 |
| `backend/app.py` | Python 3.12 | Flask 路由、预测编排、说明生成、速率限制 |
| `backend/feature_extraction.py` | Python 3.12 | 28 项信号的 URL 特征工程,零外部依赖 |
| `backend/train_model.py` | Python 3.12 | 模型训练、分层划分、交叉验证、指标导出 |
| `backend/config.py` | Python 3.12 | 通过 `python-dotenv` 实现的集中式环境变量配置 |
| `nginx.conf` | Nginx | 静态文件服务、`/api/` 反向代理、安全响应头 |
| `Dockerfile` | Docker | 多阶段构建、非 root 运行时用户、Gunicorn 入口点 |
| `docker-compose.yml` | Docker Compose | 后端 + 前端服务、健康检查、数据卷挂载 |
## URL 分析工作流
```
flowchart TD
A([User enters URL]) --> B{URL valid?}
B -- No --> C[Highlight input field red\n1.2s error state]
B -- Yes --> D[Start 5-step progress animation]
D --> E["POST /api/v1/predict\n{url: string}"]
E --> F[Flask: input validation\nLength ≤ 2048 · strip whitespace]
F --> G["extract_features(url)\n28 signals extracted"]
G --> H[Build feature vector\nAlign to training column order]
H --> I["model.predict_proba(df)\nRandomForest: 300 trees vote"]
I --> J["P(malicious) = proba[class_list.index(0)]"]
J --> K{Threshold check}
K -- ">= 0.90" --> L[Malicious · Critical]
K -- ">= 0.70" --> M[Suspicious · Medium]
K -- "< 0.70" --> N[Safe · Low]
L --> O[_generate_explanations\nRule-based signal mapping]
M --> O
N --> O
O --> P["JSON response\nprediction · risk_score · risk_level\nexplanations · features"]
P --> Q[Frontend: renderResult\nCircular progress ring\nVerdict badge · Meta pills]
Q --> R[renderFeatures\n28 feature cards with bar indicators]
Q --> S[Explanation list\nColor-coded positive/negative signals]
Q --> T[addToHistory\nlocalStorage persists last 10 scans]
```
## 机器学习 Pipeline
### 训练 (`train_model.py`)
该模型完全基于在推理阶段可从 URL 字符串中推导出的特征进行训练。这是一项经过深思熟虑的架构决策,旨在消除通常困扰 URL 分类系统的训练/推理特征不匹配问题。
```
Dataset: phishing_urls.csv (235,795 URLs)
label=0 → 100,945 malicious (42.8%)
label=1 → 134,850 safe (57.2%)
Split: 80% train (188,636) | 20% test (47,159)
Stratified to preserve class ratio
Model: RandomForestClassifier
n_estimators = 300
max_depth = None (fully grown)
min_samples_leaf = 2
class_weight = "balanced"
random_state = 42
Validation: StratifiedKFold(n_splits=5)
CV F1 mean = 0.9948 ± 0.0004
```
### 模型表现
| 指标 | 数值 |
|---|---|
| 准确率 | **99.40%** |
| 精确率 (malicious) | **99.41%** |
| 召回率 (malicious) | **99.18%** |
| F1 分数 (malicious) | **99.30%** |
| ROC-AUC | **99.80%** |
| CV F1 平均值 (5 折) | **99.48% ± 0.04%** |
**混淆矩阵** (测试集,47,159 个样本):
```
Predicted Malicious Predicted Safe
Actual Malicious 20,024 165
Actual Safe 118 26,852
```
### 特征重要性 (前 10 名)
| 排名 | 特征 | 重要性 | 信号类型 |
|---|---|---|---|
| 1 | `IsHTTPS` | 39.12% | 二进制协议标志 |
| 2 | `DigitRatioInURL` | 8.96% | 字符比率 |
| 3 | `NoOfDegitsInURL` | 8.62% | 字符计数 |
| 4 | `URLLength` | 8.37% | 长度指标 |
| 5 | `LetterRatioInURL` | 5.27% | 字符比率 |
| 6 | `PathEntropy` | 4.77% | 香农熵 |
| 7 | `NoOfLettersInURL` | 3.81% | 字符计数 |
| 8 | `URLEntropy` | 3.63% | 香农熵 |
| 9 | `NoOfSubDomain` | 3.37% | 域名结构 |
| 10 | `DomainLength` | 3.24% | 长度指标 |
### 推理 (`app.py → _run_prediction`)
```
# 1. 从 URL 字符串中提取 28 个特征
url_features = extract_features(url)
# 2. 构建 DataFrame 以对齐训练列顺序
row = {col: url_features.get(col, 0) for col in FEATURE_COLUMNS}
features_df = pd.DataFrame([row], columns=FEATURE_COLUMNS)
# 3. 获取恶意概率
class_list = list(MODEL.classes_) # [0, 1]
malicious_idx = class_list.index(0) # 0
prob = float(MODEL.predict_proba(features_df)[0][malicious_idx])
# 4. 应用校准阈值
if prob >= 0.90: verdict = "Malicious", "Critical"
elif prob >= 0.70: verdict = "Suspicious", "Medium"
else: verdict = "Safe", "Low"
```
## 特征工程
所有 28 个特征均由 `feature_extraction.py` 仅从 URL 字符串中计算得出 —— 无需 DNS 查询、无需 WHOIS 查询、无需调用外部 API。
### 长度特征
| 特征键 | 描述 | 类型 |
|---|---|---|
| `URLLength` | 归一化 URL 中的总字符数 | 整数 |
| `DomainLength` | 主机名中的字符数 | 整数 |
| `TLDLength` | 顶级域名中的字符数 | 整数 |
### 结构特征
| 特征键 | 描述 | 风险信号 |
|---|---|---|
| `NoOfSubDomain` | 超出 `domain.tld` 的子域名级别计数 | 高数量会掩盖真实域名 |
| `URLDepth` | 路径中 `/` 字符的计数 | — |
| `NoOfDotsInURL` | 完整 URL 中的点字符总数 | — |
| `NoOfHyphensInURL` | 连字符总数 | 过多的连字符会模仿合法域名 |
### 字符计数特征
| 特征键 | 描述 |
|---|---|
| `NoOfLettersInURL` | 字母字符总数 |
| `NoOfDegitsInURL` | 数字字符总数 |
| `NoOfEqualsInURL` | `=` (查询参数分隔符) 计数 |
| `NoOfQMarkInURL` | `?` 计数 |
| `NoOfAmpersandInURL` | `&` 计数 |
| `NoOfOtherSpecialCharsInURL` | 排除 `:/.-_?&=#@%` 外的特殊字符 |
| `NoOfAtInURL` | `@` 计数 (浏览器会忽略 `@` 之前的所有内容) |
| `NoOfPercentInURL` | `%` 计数 (百分号编码) |
### 比率特征
| 特征键 | 描述 | 公式 |
|---|---|---|
| `DigitRatioInURL` | 数字占比 | `digits / total_chars` |
| `LetterRatioInURL` | 字母占比 | `letters / total_chars` |
### 熵特征
香农熵 `H = -Σ p(c) × log₂(p(c))` 用于衡量随机性。URL 或路径中的高熵表明存在混淆或随机生成的字符串。
| 特征键 | 计算对象 |
|---|---|
| `URLEntropy` | 完整的归一化 URL |
| `DomainEntropy` | 仅主机名 |
| `PathEntropy` | URL 路径部分 |
### 二进制 / 启发式特征
| 特征键 | 值为 1 代表 | 何时存在风险 |
|---|---|---|
| `IsHTTPS` | 存在 HTTPS 协议 | 0 = 无加密 (权重最高的特征) |
| `IsIPAddress` | 主机为原始 IPv4 地址 | 总是可疑的 |
| `HasPunycode` | 主机名中包含 `xn--` 标签 | 同形异义词攻击指标 |
| `HasAtSign` | URL 中包含 `@` | 浏览器会忽略 `@` 之前的内容 |
| `HasDoubleSlashRedirect` | `//` 出现多次 | 开放重定向模式 |
| `HasHexEncoding` | `%` 字符超过 3 个 | 路径混淆 |
| `IsSuspiciousTLD` | TLD 在已知危险集合中 | 参见下方的 TLD 列表 |
| `BrandInSubdomain` | 品牌关键词在 URL 中,但不在注册域名中 | 欺骗尝试 |
| `SuspiciousKeywordCount` | 匹配到的钓鱼关键词计数 | login、verify、password 等 |
**检测的可疑 TLD:** `.xyz .tk .ml .ga .cf .gq .pw .top .click .link .work .party .download .zip .review .country .kim .science .cricket .win .webcam .faith .loan .diet .men .date`
**检测的钓鱼关键词:** `login verify update secure account banking confirm password signin paypal webscr ebay amazon billing support service alert validation authentication authorize credential wallet recovery suspended locked urgent limited bonus prize`
**品牌欺骗关键词:** `paypal apple google microsoft amazon netflix facebook instagram twitter linkedin dropbox chase wellsfargo bankofamerica citibank hsbc dhl fedex ups usps`
### URL 归一化
训练数据中的安全 URL 被统一格式化为 `https://www.domain.com`。为了在推理时匹配此,提取器通过在纯 HTTPS 根域名前添加 `www.` 来对其进行归一化:
```
# 归一化前:https://github.com → NoOfSubDomain = 0
# 归一化后:https://www.github.com → NoOfSubDomain = 1
# 这与模型训练时的特征分布相匹配
if is_https and no_of_subdomain == 0 and not is_ip_address(domain):
url = url.replace(f"https://{domain}", f"https://www.{domain}", 1)
```
## API 文档
### `POST /api/v1/predict`
分析 URL 并返回带有风险评分、说明和提取特征的威胁判定结果。
**速率限制:** 每个 IP 每分钟 60 次请求
**请求:**
```
{
"url": "https://example.com/path?query=value"
}
```
**响应 (200 OK):**
```
{
"prediction": "Safe",
"risk_score": 0.0821,
"risk_level": "Low",
"confidence": 8.21,
"explanations": [
"URL uses HTTPS — encrypted connection.",
"URL length is within normal range.",
"Domain structure appears straightforward.",
"ML model assigns low risk — no strong phishing patterns detected in the URL."
],
"reasons": [ "..." ],
"features": {
"URLLength": 22,
"DomainLength": 14,
"IsHTTPS": 1,
"URLEntropy": 3.7544,
"DomainEntropy": 3.3249,
"PathEntropy": 0.0,
"NoOfSubDomain": 1,
"DigitRatioInURL": 0.0,
"IsIPAddress": 0,
"HasPunycode": 0,
"IsSuspiciousTLD": 0,
"SuspiciousKeywordCount": 0,
"BrandInSubdomain": 0
}
}
```
**预测值:** `"Safe"` | `"Suspicious"` | `"Malicious"`
**风险级别值:** `"Low"` | `"Medium"` | `"Critical"`
**阈值逻辑:**
| `risk_score` | `prediction` | `risk_level` |
|---|---|---|
| ≥ 0.90 | Malicious | Critical |
| ≥ 0.70 | Suspicious | Medium |
| < 0.70 | Safe | Low |
**错误响应:**
| 状态码 | 响应体 | 原因 |
|---|---|---|
| `400` | `{"error": "Missing 'url' in request body."}` | `url` 字段为空或缺失 |
| `400` | `{"error": "URL exceeds maximum length of 2048 characters."}` | URL 过长 |
| `429` | `{"error": "Rate limit exceeded. Please slow down."}` | 超过速率限制 |
| `503` | `{"error": "Model not loaded. Check server logs."}` | 模型在启动时加载失败 |
| `500` | `{"error": "Prediction failed. Please try again."}` | 未处理的预测错误 |
### `GET /health`
返回服务健康状态。
```
{
"status": "ok",
"model_loaded": true,
"version": "v1"
}
```
如果模型加载失败,将返回带有 `"status": "degraded"` 的 `503` 状态码。
### `GET /api/v1/metrics`
返回上次运行 `train_model.py` 时保存的模型训练指标。
```
{
"accuracy": 0.994,
"precision": 0.9941,
"recall": 0.9918,
"f1_score": 0.993,
"roc_auc": 0.998,
"cv_f1_mean": 0.9948,
"cv_f1_std": 0.0004,
"confusion_matrix": [[20024, 165], [118, 26852]],
"feature_count": 28,
"feature_columns": ["URLLength", "..."],
"feature_importance": [{"feature": "IsHTTPS", "importance": 0.391238}, "..."],
"train_samples": 188636,
"test_samples": 47159,
"n_estimators": 300
}
```
### `GET /`
服务发现端点。
```
{
"service": "URLShield API",
"version": "v1",
"status": "running",
"model_loaded": true
}
```
## 项目结构
```
threatlens/
├── backend/
│ ├── app.py # Flask application, routes, prediction logic
│ ├── feature_extraction.py # 28-signal URL feature engineering
│ ├── train_model.py # Training pipeline, CV, metrics export
│ ├── config.py # Environment-driven configuration
│ ├── url_model.pkl # Serialized (model, feature_columns) tuple
│ ├── model_metrics.json # Saved evaluation metrics from last training run
│ ├── test_api.py # API integration tests
│ └── test_data.py # Feature extraction unit tests
│
├── frontend/
│ ├── index.html # Single-page application
│ ├── script.js # Fetch API, DOM, localStorage, progress animation
│ └── style.css # Design system, CSS custom properties, responsive
│
├── dataset/
│ └── phishing_urls.csv # 235,795 labeled URLs (0=malicious, 1=safe)
│
├── Dockerfile # Multi-stage build, non-root user, Gunicorn
├── docker-compose.yml # Backend + Nginx frontend services
├── nginx.conf # Static serving + /api/ reverse proxy
├── requirements.txt # Pinned Python dependencies
├── .env.example # Environment variable template
└── README.md
```
## 技术栈
### 前端
| 技术 | 版本 | 用途 |
|---|---|---|
| HTML5 | — | 语义化标记、ARIA 无障碍支持 |
| 原生 JavaScript | ES2022 | Fetch API、DOM 操作、localStorage |
| CSS3 | — | 自定义属性、Grid、Flexbox、动画 |
| Google Fonts | — | Inter (UI) + JetBrains Mono (URL/代码) |
### 后端
| 技术 | 版本 | 用途 |
|---|---|---|
| Python | 3.12 | 运行时 |
| Flask | 3.1.0 | HTTP API 框架 |
| flask-cors | 6.0.0 | 跨域资源共享 |
| flask-limiter | 4.1.1 | 基于 IP 的速率限制 |
| pandas | 2.2.3 | 特征 DataFrame 构建 |
| python-dotenv | 1.1.0 | `.env` 文件加载 |
| gunicorn | 23.0.0 | 生产级 WSGI 服务器 |
### 机器学习
| 技术 | 版本 | 用途 |
|---|---|---|
| scikit-learn | 1.9.0 | `RandomForestClassifier`、指标、交叉验证 |
| numpy | 1.26.4 | 数组操作 |
| joblib | 1.4.2 | 模型序列化/反序列化 |
### 部署
| 技术 | 用途 |
|---|---|
| Docker | 多阶段镜像构建 |
| Docker Compose | 服务编排 |
| Nginx Alpine | 静态文件服务 + API 反向代理 |
| Render | 托管后端 (`urlsheild-api.onrender.com`) |
## 安全考量
### 输入验证 (`app.py`)
- URL 长度上限为 **2,048 个字符** —— 防止内存耗尽
- 空的 URL 输入会在到达 ML pipeline 之前被以 `400` 拒绝
- 接受无协议的 URL (特征提取器会自动添加 `http://`),在不放宽验证规则的前提下提升易用性
- 所有面向用户的错误消息均经过净化处理 —— 堆栈跟踪仅记录在服务端,绝不返回给客户端
### 前端输出编码 (`script.js`)
所有用户提供的内容和 API 响应字符串在插入 DOM 之前,都会经过 `escapeHtml()` 处理:
```
function escapeHtml(str) {
return String(str)
.replaceAll("&", "&").replaceAll("<", "<").replaceAll(">", ">")
.replaceAll('"', """).replaceAll("'", "'");
}
```
这可以防止恶意 URL 字符串或被篡改的 API 响应引发存储型/反射型 XSS。
### HTTP 安全响应头 (`nginx.conf`)
```
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Content-Type-Options "nosniff" always;
add_header Referrer-Policy "strict-origin-when-cross-origin" always;
```
### 运行时隔离 (`Dockerfile`)
容器以非 root 用户 (`appuser`) 身份运行,并挂载只读的模型卷,从而最大程度地缩小任何运行时安全漏洞的影响范围。
### 速率限制
- **全局:** 每个 IP 每天 200 次请求
- **预测端点:** 每个 IP 每分钟 60 次请求
- 通过具有内存存储的 `flask-limiter` 实现;违规时返回 `429`
## 性能
- **特征提取是纯 Python 实现** —— 没有子进程调用、没有 I/O、没有网络请求。对于 200 个字符的 URL,典型提取时间在 5ms 以内。
- **模型在启动时加载一次** (通过 `joblib.load()`) 并驻留内存。无需按请求进行磁盘 I/O。
- **具有 300 棵树的 RandomForest** 在单个 CPU 核心上对单个特征向量实现低于 10ms 的推理速度。
- **Gunicorn 在 Docker 部署中运行 2 个 worker**,为托管环境提供基础的并发处理能力。
- **Nginx 直接提供前端静态资源服务** —— 静态文件永远不会经过 Flask。
- **由 localStorage 支持的扫描历史** 意味着历史记录面板完全不需要 API 调用。
## 挑战与工程经验
### 1. 训练/推理特征对齐
**挑战:** 早期版本的 pipeline 基于数据集提供的 54 个特征进行训练,但推理路径在运行时只能计算出 11 个仅限 URL 的特征 —— 这种隐蔽的不匹配导致产生了完全错误的预测。
**解决方案:** 重写了 `train_model.py`,在每个训练 URL 上调用相同的 `extract_features()` 函数,从而保证训练和推理之间的特征工程代码路径完全一致。模型工件是一个 `(model, feature_columns)` 元组 —— 列表会随模型一起保存,以防止未来出现任何特征漂移。
### 2. ML 审计与误报发现
**挑战:** 部署后,诸如 `https://github.com/user/repo` 之类的合法 URL 被以 99.8% 的置信度归类为 Malicious —— 这显然是错误的。
**调试过程:**
1. 在独立的审计脚本中端到端追踪完整的预测流程
2. 检查标签映射 (`model.classes_ = [0, 1]`, 索引 0 = malicious) —— 正确
3. 检查概率提取 (`proba[malicious_idx]`) —— 正确
4. 将已知安全的 URL 输入模型 —— 像 `github.com` 这样的根域名得分约为 45% 恶意
5. 对 `https://github.com` 和 `https://github.com/user/repo` 之间进行了特征差异分析
**找到根本原因:** 两个复合问题:
- **训练数据分布偏差** —— 数据集中的安全 URL 几乎全是 `https://www.domain.com` 根域名。模型在训练期间从未见过具有长且混合大小写路径的安全 URL。在训练集中,较高的 `PathEntropy` (典型 GitHub 路径为 4.03 比特) 与恶意 URL 存在极强的正相关性。
- **阈值误校准** —— 对于具有这种训练分布的模型来说,最初 0.85 的 Malicious 阈值过于激进。
**已实施修复:** 在 `app.py` 中将阈值从 `(0.85, 0.55)` 提高到 `(0.90, 0.70)`。作为长期修复方案,需要使用分布更均衡的安全 URL 重新训练,以解决底层数据集的偏差。
### 3. URL 归一化策略
**挑战:** 不带 `www.` 的根域名 (`github.com`) 在安全训练类别中占比不足,导致即使在调整阈值后仍处于边缘分数。
**解决方案:** `feature_extraction.py` 在计算特征之前,通过添加 `www.` 前缀来归一化纯 HTTPS 根域名,使推理输入与训练安全 URL 中的主要分布模式保持一致。这将大多数主要域名的根域名得分从约 45% 降至安全区间。
### 4. 生产环境工件中的编码损坏
**挑战:** 通过 PowerShell 的 `Set-Content` 写入的文件在 `script.js` 中引入了 Windows-1252 乱码 —— 像 `—`、`…`、`≈` 这样的 Unicode 字符被存储为多字节的 Latin-1 序列 (`â€"`、`…`)。这些在某些编辑器中是不可见的,但在浏览器中会错误渲染。
**解决方案:** 通过字节级检查识别出所有损坏的序列,使用带有显式 `UTF8` 编码的 `System.IO.File.WriteAllText` 执行了完整文件重写,并将代码/注释中所有的 Unicode 排版字符替换为等效的纯 ASCII 字符。
## 已知局限性
### 数据集分布偏差
训练数据集的安全类别几乎完全由 `https://www.domain.com` 根域名 URL 组成。这造成了系统性偏差:模型对具有长路径、查询参数或混合大小写路径段的合法 URL 接触有限。诸如 `PathEntropy`、`URLLength` 和 `LetterRatioInURL` 等特征在安全类别中的分布并不能反映现实世界中安全 URL 的多样性。
**观察到的影响:** 包含有意义路径的 URL (例如 GitHub 仓库 URL、维基百科文章链接) 的得分可能会高于预期,即使其他所有信号都是正常的。
### PathEntropy 敏感度
`PathEntropy` 是第 6 重要的特征 (重要性 4.77%)。像 `/user/repository-name` 这样合法的长路径所产生的香农熵,与混淆过的钓鱼路径相当。由于训练集中缺乏足够多包含长路径的安全 URL 示例,模型无法区分这两者。
### 阈值与重新训练的权衡
阈值调整 (`0.90` / `0.70`) 减少了边缘情况下的误报,但这只是校准补丁,并非结构性修复。如果 URL 的路径熵足够高,导致预测置信度超过 0.90,无论阈值如何,它仍然会被错误地标记。正确的长期修复方案是,在包含根域名、路径和查询参数且具有均衡安全 URL 表示的数据集上进行重新训练。
## 未来改进
- **在增强的数据集上重新训练** —— 添加来自 Common Crawl、维基百科、GitHub API 和 Stack Overflow 等来源的真实路径的安全 URL
- **移除或限制 PathEntropy** —— 审计表明其泛化能力很差;将其从 `MODEL_FEATURE_COLUMNS` 中排除并重新训练,将减少合法的长路径 URL 的误报
- **威胁情报集成** —— 可选择性地利用实时的 WHOIS 域名年龄、DNS 信誉和证书透明度日志数据来丰富预测结果
- **置信区间** —— 暴露 Random Forest 中树级别的方差,让用户感知预测的不确定性
- **批量扫描 API** —— `POST /api/v1/predict/batch` 接受 URL 数组,以应对集成用例
- **Webhook 支持** —— 将扫描结果推送到回调 URL,以便进行自动化 pipeline 集成
- **持久化扫描历史** —— 用后端持久化的扫描日志替换 `localStorage`,以实现跨设备访问
- **模型版本控制** —— 对 `url_model.pkl` 工件进行版本控制,并通过 `/health` 暴露当前活动版本
- **可解释性改进** —— 集成 SHAP 值,在当前基于规则的说明之外,提供细粒度的特征贡献得分
## 安装
### 前置条件
- Python 3.12+
- pip
- Docker + Docker Compose (用于容器化部署)
### 本地开发
```
# 克隆仓库
git clone https://github.com/your-username/threatlens.git
cd threatlens
# 创建并激活虚拟环境
python -m venv venv
source venv/bin/activate # Linux/macOS
venv\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt
# 配置环境
cp .env.example .env
# 编辑 .env — 设置 SECRET_KEY 和任何覆盖项
# 启动后端(从 backend/ 目录)
cd backend
python app.py
# API 可在 http://localhost:5000 访问
# 提供前端服务(在单独的终端中,从项目根目录)
# 任何静态文件服务器均可 — 例如 Python 内置的:
python -m http.server 3000 --directory frontend
# 前端可在 http://localhost:3000 访问
```
### Docker 部署
```
# 构建并启动所有服务
docker-compose up --build
# 后端 API:http://localhost:8000
# 前端:http://localhost:3000
# 健康检查:http://localhost:8000/health
# 在 detached 模式下运行
docker-compose up -d --build
# 查看日志
docker-compose logs -f backend
# 停止所有服务
docker-compose down
```
### 重新训练模型
```
# 从 backend/ 目录
cd backend
# 确保数据集存在于 ../dataset/phishing_urls.csv
python train_model.py
# 输出:
# url_model.pkl — 新模型产物
# model_metrics.json — 更新后的指标
```
## 配置
所有配置均通过环境变量管理。运行前请将 `.env.example` 复制为 `.env`。
| 变量 | 默认值 | 描述 |
|---|---|---|
| `FLASK_DEBUG` | `false` | 启用 Flask 调试模式 |
| `SECRET_KEY` | `change-me-in-production` | Flask 会话密钥 —— **生产环境中必须修改** |
| `MODEL_PATH` | `url_model.pkl` | 模型工件路径 (相对于 `backend/`) |
| `DATASET_PATH` | `../dataset/phishing_urls.csv` | 训练数据集路径 |
| `METRICS_PATH` | `model_metrics.json | 指标 JSON 输出路径 |
| `ALLOWED_ORIGINS` | `*` | CORS 允许的源 —— 在生产环境中应进行限制 |
| `RATE_LIMIT_DEFAULT` | `200 per day` | 每个 IP 的全局速率限制 |
| `RATE_LIMIT_PREDICT` | `60 per minute` | 预测端点的速率限制 |
| `LOG_LEVEL` | `INFO` | Python 日志记录级别 |
| `PORT` | `5000` | Flask/Gunicorn 绑定端口 |
### 本项目展示的技能
| 技能领域 | 证明 |
|---|---|
| **全栈开发** | 完整的端到端系统:原生 JS 单页应用前端、Flask REST API 后端、Nginx 反向代理、Docker Compose 编排 |
| **机器学习集成** | 在 23.5 万个样本上训练的 RandomForest、28 项特征工程 pipeline、`predict_proba()` 概率提取、校准阈值 |
| **API 设计** | 带有版本控制 (`/api/v1/`) 的 RESTful 端点、结构化的错误响应、速率限制、健康检查、向后兼容的 `/predict` 别名 |
| **特征工程** | 香农熵、字符比率分析、基于正则的启发式规则、域名归一化 —— 全部零依赖、零网络 I/O |
| **网络安全知识** | 钓鱼信号分析、Punycode 同形异义词检测、品牌欺骗检测、可疑 TLD 分类、通过输出编码预防 XSS |
| **系统设计** | 通过共享代码路径对齐训练/推理特征、带有列名列表的模型工件版本控制、环境驱动的配置、非 root 的 Docker 运行时 |
| **调试与模型审计** | 端到端预测追踪、标签映射验证、概率反转检查、特征差异分析、根本原因识别 (数据集分布偏差 + PathEntropy 敏感度) |
| **DevOps** | 多阶段 Dockerfile、Docker Compose 健康检查、Gunicorn 生产级 WSGI、Nginx 安全响应头、卷挂载的模型工件 |
| **代码质量** | 按照关注点分离原则划分为 7 个专注的 Python 模块、一致的错误处理、结构化日志、锁定的依赖版本 |
| **无障碍设计** | ARIA 实时区域、语义化 HTML、键盘导航、`role="search"`、焦点管理 |
## 许可证
MIT 许可证 —— 详情请参阅 [LICENSE](LICENSE)。
## 致谢
- 数据集来源于公开可用的钓鱼 URL 研究数据集
- 感谢 [scikit-learn](https://scikit-learn.org/) 提供的 RandomForestClassifier 实现
- 感谢 [Flask](https://flask.palletsprojects.com/) 及其扩展生态系统
- 感谢 Rasmus Andersson 提供的 [Inter](https://rsms.me/inter/) 字体
- 感谢 [JetBrains Mono](https://www.jetbrains.com/lp/mono/) 用于等宽 URL 渲染标签:Apex, URL检测, Web安全, 威胁情报, 开发者工具, 机器学习, 版权保护, 蓝队分析, 请求拦截, 逆向工具, 钓鱼检测