aayushcodebook/agentscan
GitHub: aayushcodebook/agentscan
面向自托管 AI agent 的跨框架本地安全态势扫描器,通过 19 项检查并映射行业标准框架给出 A–F 评分,帮助开发者和安全团队快速发现配置缺陷、已知漏洞及恶意插件。
Stars: 0 | Forks: 0
# agentscan
**适用于自托管 AI agent 的跨 agent 安全态势扫描器。**
 https://github.com/user-attachments/assets/422a90a9-3ce1-4071-8ce9-38c10cf77238
大多数 agent 安全工具只能在您安装之前扫描单个 agent 的单一 skill。
agentscan 可审计您的**整个运行中安装**——并且支持跨 **OpenClaw,
Hermes 等**通过单一工具完成。一条命令即可执行基于框架映射的
态势评估——**19 项检查加上复合风险关联**——涵盖
网络暴露、网关认证、CVE、密钥、SSRF、沙盒,*以及*恶意
skills/plugins(包含污点分析 + prompt injection 检测)。它将每个
发现映射到 CWE / OWASP LLM Top 10 / MITRE ATLAS,为您的设置评分 **A–F**,并
为 CI 输出 **SARIF**。一切都在您的本地机器上运行——绝不上传
任何数据,且**零依赖**,因此您可以在信任它之前查阅每一行代码。
已针对 **OpenClaw 和 Hermes 两者的**真实默认安装进行了验证——
每项均获得 **B** 评级,并提供具体、可操作的发现,**零误报**(包含
超过 300 个真实的内置 skills)。
```
npx @aayushcodebook/agentscan
```
```
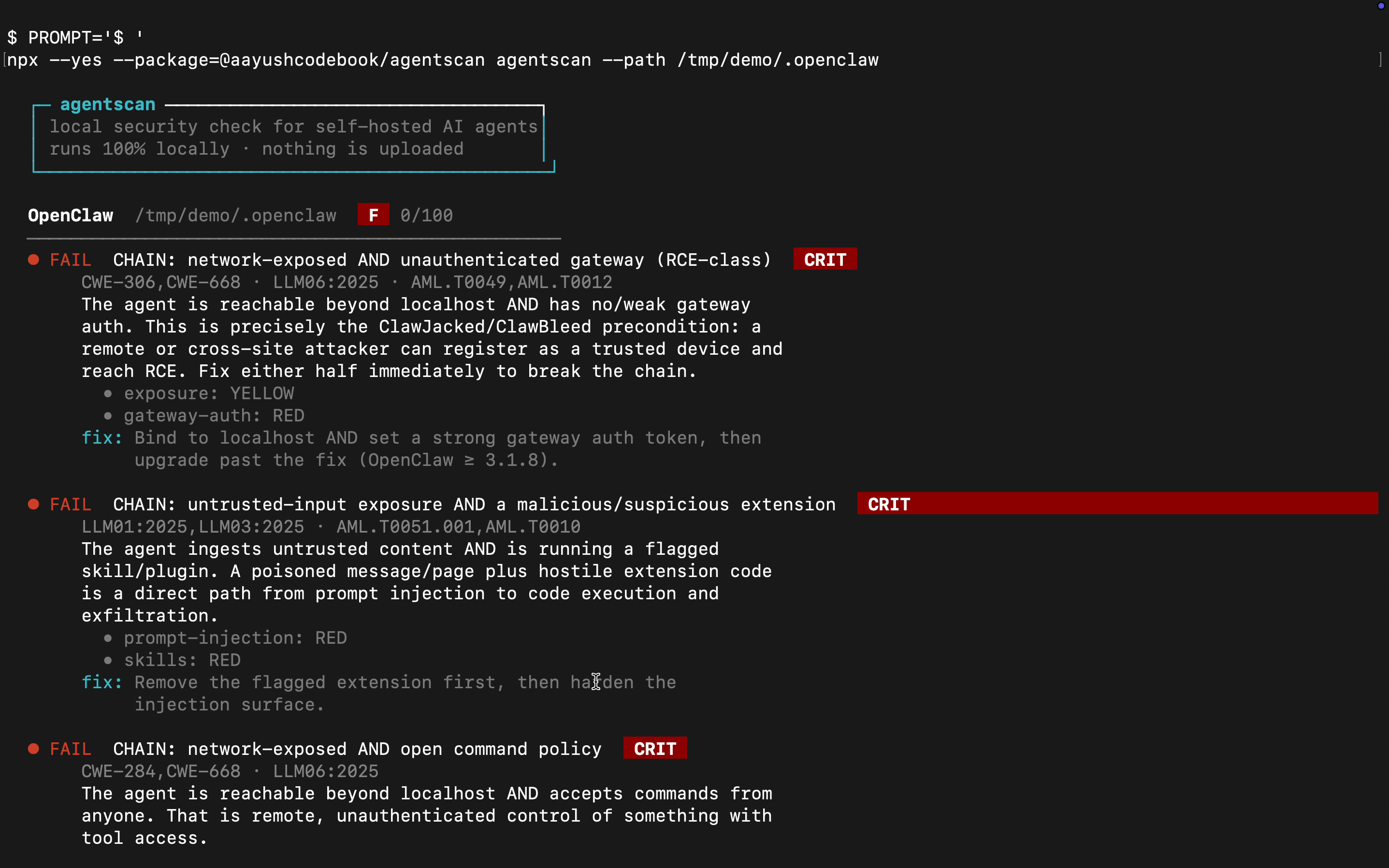
OpenClaw ~/.openclaw F 0/100
──────────────────────────────────────────────────
● FAIL CHAIN: network-exposed AND unauthenticated gateway (RCE-class) CRIT
CWE-306,CWE-668 · LLM06:2025 · AML.T0049,AML.T0012
● FAIL Agent version vs. known security advisories (CVEs) CRIT
CWE-1395 · LLM03:2025
Installed version 3.0.0 is affected by CVE-2026-25253 (CVSS 8.8)…
● FAIL Malicious or suspicious skills & plugins CRIT
● FAIL Gateway authentication (is the local API/WebSocket protected?) CRIT
…
posture grade F 0/100
coverage: 13/15 checks ran
```
## 检查内容
每个发现都会标记其 **CWE**、**OWASP LLM Top 10 (2025)**,以及(如果适用)
**MITRE ATLAS** 技术,并带有用于评分的固有严重性。
| 检查项 | 映射到 | 为什么重要 |
|-------|---------|----------------|
| **网络暴露** | CWE-668 · ATLAS T0049 | 端口在 localhost 之外是否可访问?(63% 的公开实例是可访问的。) |
| **隧道暴露** | CWE-668 · LLM06 | 通过 Tailscale Funnel / ngrok / cloudflared 代理的 localhost 绑定 agent 实际上仍暴露在公网上——这是绑定地址的视觉盲区。 |
| **网关认证** | CWE-306/307 · LLM06 | 开放端口 + 无/弱认证 = ClawJacked/ClawBleed (CVE-2026-25253) 的前置条件。 |
| **访问策略** | CWE-284 · LLM06 | `dmPolicy: open` / `allowFrom: ["*"]` 允许频道上的任何陌生人指挥 agent。 |
| **CORS** | CWE-942 | 通配符 origin 允许您访问的任何网站调用 agent 的 API。 |
| **明文凭据** | CWE-312 · LLM02 | API 密钥/密码以明文形式存储在 config 中。 |
| **密钥脱敏** | CWE-532 · LLM02 | 如果关闭脱敏,工具输出中的密钥会泄漏到 transcripts 和磁盘上的 logs 中。 |
| **密钥文件权限** | CWE-732 | `.env` 中的密钥只有在文件对全局不可读时才是安全的。 |
| **Git 中的密钥** | CWE-540 · LLM02 | Agent 主目录是一个 repo 且密钥未被 `.gitignore` 忽略 → 被提交/推送。 |
| **版本与 CVE** | CWE-1395 · LLM03 | 运行带有已发布安全公告的构建(feed 可更新;内置 2026 年 OpenClaw CVE)。 |
| **恶意 skills & plugins** | CWE-506 · LLM01/LLM03 · ATLAS T0010 | 通过签名发现(`SKILL.md`/`openclaw.plugin.json`),与 ClawHavoc 黑名单匹配,进行**污点分析**(密钥是否真的*流入*了网络/exec sink?),在 SKILL.md *文本*中进行 **prompt injection 扫描**(隐形/双向 unicode、隐藏注释指令、角色劫持/覆盖、数据外泄 prompt),并进行**完整性验证**(“第一方” skill 只有在其字节哈希与原始匹配时才被信任;冒名顶替者将被捕获)。如果未发现任何内容则跳过(从不通过)。 |
| **MCP 供应链** | CWE-829 · LLM03 | 远程 MCP 工具服务器是位于 agent 信任边界内的第三方代码。 |
| **SSRF / 私有 URL** | CWE-918 · LLM06 | 如果开启了私有 URL 访问,中毒的链接可能会触达内部主机或 cloud-metadata endpoint (169.254.169.254)。 |
| **命令内容扫描器** | CWE-693 · LLM06 | Hermes 预先检查 shell 命令 (Tirith);标记其是否已禁用或 fail-open。 |
| **沙盒 / agency** | CWE-250 · LLM06 | 未沙盒化的工具(或以 root 身份运行)会将一条错误指令转化为完整的机器访问权限。 |
| **命令/exec 策略** | CWE-250 · LLM06 | 不受限制的 shell(`tools.exec.security="full"`,命令允许列表为空)是从 prompt injection 到 RCE 的路径。 |
| **审批 (HITL)** | CWE-250 · LLM06 | 自动批准的高影响操作移除了对抗被劫持 agent 的最后一道人工关卡。 |
| **Prompt injection 暴露** | CWE-77 · LLM01 · ATLAS T0051 | 态势:不受信任的输入 × 能力 × 弱关卡。诚实地说明静态扫描无法*证明* injection 路径。 |
| **审计日志** | CWE-778 | 没有 agent 操作记录 = 没有事件响应,不符合 SOC2/HIPAA/GDPR。 |
**复合风险关联。** 单独为黄色的发现可能构成严重的
链条。agentscan 会指出它们——例如 *暴露 + 未认证*(RCE 级别,
CVE-2026-25253)、*暴露 + 开放命令策略*、*不受信任的输入 + 实时
恶意扩展*。
**态势评分与评级。** 从 100 分开始,减去基于严重程度的扣分
(fail = 全扣,warn = 扣半,**skipped = 扣 ¼**,因此不确定性仍会产生代价),最低为 0,划分为 A–F。覆盖率会单独报告,因此低覆盖率下的高分无法伪装成安全。
## 持续监控(免费)
扫描是点状时间点操作,但风险时刻是在设置*之后*——当您安装
新 skill 或更改 config 时。按计划重新运行,仅在您的态势
变**糟**时收到警报。无需额外工具——只需 `agentscan`、调度程序和 diff。
一个 cron 单行命令可每日重新扫描,并在出现任何新发现(评级下降或
新 fail)时发出通知,并与上次运行结果进行比对:
```
# crontab -e → 每天早上 8 点进行 scan;仅在 grade/score 下降时发出 alert
0 8 * * * cur=$(npx @aayushcodebook/agentscan@latest --quiet 2>/dev/null); prev=$(cat ~/.agentscan/last 2>/dev/null); \
echo "$cur" > ~/.agentscan/last; [ "$cur" != "$prev" ] && \
printf '%s\n' "$cur" | grep -qE 'AT RISK|fail' && \
osascript -e "display notification \"$cur\" with title \"agentscan\"" 2>/dev/null || true
```
在 Linux 上,将 `osascript` 行替换为 `notify-send "agentscan" "$cur"`(或通过管道发送至
Slack/email)。在 CI 中,`examples/agentscan-scan.yml` 中的 GitHub Action 会执行相同的
定时操作并上传 SARIF。
内置的 `agentscan --watch`(文件监控 agent 的 config + skills 目录,在
发生更改时立即扫描)已列入路线图——如果您会使用它,请提交 issue。
实时行为监控(在数据外泄或 injection *发生时*进行捕获)是
一项独立且更庞大的工作,不属于此 CLI 的一部分。
### 它与原生工具的关系
agentscan 是 agent 自带审计工具的**补充**,而非替代品。
OpenClaw 内置的 `openclaw security audit --deep` 在
OpenClaw 专属的 config 加固(文件系统 ACL、hooks、Docker 沙盒
内部原理)方面要深入得多,并且可以自动修复——请运行它。agentscan 独特的价值在于**跨 agent
覆盖**(OpenClaw *和* Hermes)、**精心整理的恶意 skill 黑名单**和
**CVE 公告 feed**(内置 `doctor` 无法维护的威胁情报),以及面向安全团队和 CI 的
**框架映射、SARIF 输出**。建议两者配合使用。
干净的结果意味着未发现*这些*已知问题。这并不能
保证整体安全——值得注意的是,prompt injection 是作为
*态势*进行评估的,并未证明其不存在,而原生的 `--deep` 审计会发现
agentscan 无法检测到的 config 加固细节。
## 用法
```
npx @aayushcodebook/agentscan # scan auto-detected installs
npx @aayushcodebook/agentscan --path ~/my-agent # also scan a custom location (repeatable)
npx @aayushcodebook/agentscan --json # full findings + score + framework tags (JSON)
npx @aayushcodebook/agentscan --sarif # SARIF 2.1.0 for GitHub code scanning / CI
npx @aayushcodebook/agentscan --quiet # one-line graded verdict
npx @aayushcodebook/agentscan --update-feed # refresh blocklist + CVE advisory feeds
npx @aayushcodebook/agentscan --help
```
### 退出码
| 代码 | 含义 |
|------|---------|
| `0` | 全部正常(或未发现 agent) |
| `1` | 仅有警告 —— 建议审查 |
| `2` | 严重问题 —— 立即修复 |
| `3` | 扫描器错误 |
在 CI 中很有用:`npx @aayushcodebook/agentscan --quiet || echo "agent needs attention"`。
## 隐私
agentscan 会读取本地文件并列出本地 socket 以生成报告。它
**不发起网络调用**,也不上传任何内容。恶意 skill 黑名单
在包内离线提供。您可以通过阅读
`src/` 来确认所有这些内容——它是几百行没有任何第三方包的纯 Node 代码。
## 支持的 agent
`src/data/targets.js` 中的布局取自每个项目的官方文档:
| Agent | Config | 默认端口 | 绑定设置 | Extensions |
|-------|--------|--------------|--------------|------------|
| **OpenClaw** | `~/.openclaw/openclaw.json` (JSON5), `~/.openclaw/.env`; 旧版 `~/.clawdbot/` | `18789` | `gateway.bind`: `loopback` (安全) / `lan` / `tailnet` / `custom` | skills (`SKILL.md`) + plugins (`openclaw.plugin.json`) |
| **Hermes Agent** | `~/.hermes/config.yaml`, `~/.hermes/.env` | `8642` API, `9119` dashboard | `API_SERVER_HOST` 环境变量 (`127.0.0.1` 安全, `0.0.0.0` 暴露) | skills (`SKILL.md`, 按类别嵌套) |
添加另一个 agent 只需要在 `src/data/targets.js` 中添加一个条目(其 config 路径、
默认端口、绑定模型和 skill 目录)。
## 更新威胁 feed
内置的恶意 skill 黑名单 + CVE 公告是一个*保底基准*。无需
升级包即可刷新它们:
```
agentscan --update-feed
agentscan --update-feed --feed-url https://your-mirror/blocklist.json
```
信任保证(见 `src/feed.js`):
- **扫描器零网络调用**——它会读取内置列表或您之前
明确获取的 feed,以较新者为准。`--update-feed` 是唯一
接触网络的命令。
- 内置版本是**降级底线**:拒绝使用过期或被篡改(例如
清空)的缓存,因此检测能力不会被悄无声息地削弱。
- 获取失败会**回退到内置版本**并以非零状态退出。
## 贡献
欢迎提交 issue 和 PR——尤其是新的 agent 定义(`src/data/targets.js`)、
黑名单/CVE 条目以及误报报告。整个工具是无依赖的,
旨在方便从头到尾阅读;运行 `node test/run.js` 即可执行测试套件。
## 许可证
MIT。
https://github.com/user-attachments/assets/422a90a9-3ce1-4071-8ce9-38c10cf77238
大多数 agent 安全工具只能在您安装之前扫描单个 agent 的单一 skill。
agentscan 可审计您的**整个运行中安装**——并且支持跨 **OpenClaw,
Hermes 等**通过单一工具完成。一条命令即可执行基于框架映射的
态势评估——**19 项检查加上复合风险关联**——涵盖
网络暴露、网关认证、CVE、密钥、SSRF、沙盒,*以及*恶意
skills/plugins(包含污点分析 + prompt injection 检测)。它将每个
发现映射到 CWE / OWASP LLM Top 10 / MITRE ATLAS,为您的设置评分 **A–F**,并
为 CI 输出 **SARIF**。一切都在您的本地机器上运行——绝不上传
任何数据,且**零依赖**,因此您可以在信任它之前查阅每一行代码。
已针对 **OpenClaw 和 Hermes 两者的**真实默认安装进行了验证——
每项均获得 **B** 评级,并提供具体、可操作的发现,**零误报**(包含
超过 300 个真实的内置 skills)。
```
npx @aayushcodebook/agentscan
```
```
OpenClaw ~/.openclaw F 0/100
──────────────────────────────────────────────────
● FAIL CHAIN: network-exposed AND unauthenticated gateway (RCE-class) CRIT
CWE-306,CWE-668 · LLM06:2025 · AML.T0049,AML.T0012
● FAIL Agent version vs. known security advisories (CVEs) CRIT
CWE-1395 · LLM03:2025
Installed version 3.0.0 is affected by CVE-2026-25253 (CVSS 8.8)…
● FAIL Malicious or suspicious skills & plugins CRIT
● FAIL Gateway authentication (is the local API/WebSocket protected?) CRIT
…
posture grade F 0/100
coverage: 13/15 checks ran
```
## 检查内容
每个发现都会标记其 **CWE**、**OWASP LLM Top 10 (2025)**,以及(如果适用)
**MITRE ATLAS** 技术,并带有用于评分的固有严重性。
| 检查项 | 映射到 | 为什么重要 |
|-------|---------|----------------|
| **网络暴露** | CWE-668 · ATLAS T0049 | 端口在 localhost 之外是否可访问?(63% 的公开实例是可访问的。) |
| **隧道暴露** | CWE-668 · LLM06 | 通过 Tailscale Funnel / ngrok / cloudflared 代理的 localhost 绑定 agent 实际上仍暴露在公网上——这是绑定地址的视觉盲区。 |
| **网关认证** | CWE-306/307 · LLM06 | 开放端口 + 无/弱认证 = ClawJacked/ClawBleed (CVE-2026-25253) 的前置条件。 |
| **访问策略** | CWE-284 · LLM06 | `dmPolicy: open` / `allowFrom: ["*"]` 允许频道上的任何陌生人指挥 agent。 |
| **CORS** | CWE-942 | 通配符 origin 允许您访问的任何网站调用 agent 的 API。 |
| **明文凭据** | CWE-312 · LLM02 | API 密钥/密码以明文形式存储在 config 中。 |
| **密钥脱敏** | CWE-532 · LLM02 | 如果关闭脱敏,工具输出中的密钥会泄漏到 transcripts 和磁盘上的 logs 中。 |
| **密钥文件权限** | CWE-732 | `.env` 中的密钥只有在文件对全局不可读时才是安全的。 |
| **Git 中的密钥** | CWE-540 · LLM02 | Agent 主目录是一个 repo 且密钥未被 `.gitignore` 忽略 → 被提交/推送。 |
| **版本与 CVE** | CWE-1395 · LLM03 | 运行带有已发布安全公告的构建(feed 可更新;内置 2026 年 OpenClaw CVE)。 |
| **恶意 skills & plugins** | CWE-506 · LLM01/LLM03 · ATLAS T0010 | 通过签名发现(`SKILL.md`/`openclaw.plugin.json`),与 ClawHavoc 黑名单匹配,进行**污点分析**(密钥是否真的*流入*了网络/exec sink?),在 SKILL.md *文本*中进行 **prompt injection 扫描**(隐形/双向 unicode、隐藏注释指令、角色劫持/覆盖、数据外泄 prompt),并进行**完整性验证**(“第一方” skill 只有在其字节哈希与原始匹配时才被信任;冒名顶替者将被捕获)。如果未发现任何内容则跳过(从不通过)。 |
| **MCP 供应链** | CWE-829 · LLM03 | 远程 MCP 工具服务器是位于 agent 信任边界内的第三方代码。 |
| **SSRF / 私有 URL** | CWE-918 · LLM06 | 如果开启了私有 URL 访问,中毒的链接可能会触达内部主机或 cloud-metadata endpoint (169.254.169.254)。 |
| **命令内容扫描器** | CWE-693 · LLM06 | Hermes 预先检查 shell 命令 (Tirith);标记其是否已禁用或 fail-open。 |
| **沙盒 / agency** | CWE-250 · LLM06 | 未沙盒化的工具(或以 root 身份运行)会将一条错误指令转化为完整的机器访问权限。 |
| **命令/exec 策略** | CWE-250 · LLM06 | 不受限制的 shell(`tools.exec.security="full"`,命令允许列表为空)是从 prompt injection 到 RCE 的路径。 |
| **审批 (HITL)** | CWE-250 · LLM06 | 自动批准的高影响操作移除了对抗被劫持 agent 的最后一道人工关卡。 |
| **Prompt injection 暴露** | CWE-77 · LLM01 · ATLAS T0051 | 态势:不受信任的输入 × 能力 × 弱关卡。诚实地说明静态扫描无法*证明* injection 路径。 |
| **审计日志** | CWE-778 | 没有 agent 操作记录 = 没有事件响应,不符合 SOC2/HIPAA/GDPR。 |
**复合风险关联。** 单独为黄色的发现可能构成严重的
链条。agentscan 会指出它们——例如 *暴露 + 未认证*(RCE 级别,
CVE-2026-25253)、*暴露 + 开放命令策略*、*不受信任的输入 + 实时
恶意扩展*。
**态势评分与评级。** 从 100 分开始,减去基于严重程度的扣分
(fail = 全扣,warn = 扣半,**skipped = 扣 ¼**,因此不确定性仍会产生代价),最低为 0,划分为 A–F。覆盖率会单独报告,因此低覆盖率下的高分无法伪装成安全。
## 持续监控(免费)
扫描是点状时间点操作,但风险时刻是在设置*之后*——当您安装
新 skill 或更改 config 时。按计划重新运行,仅在您的态势
变**糟**时收到警报。无需额外工具——只需 `agentscan`、调度程序和 diff。
一个 cron 单行命令可每日重新扫描,并在出现任何新发现(评级下降或
新 fail)时发出通知,并与上次运行结果进行比对:
```
# crontab -e → 每天早上 8 点进行 scan;仅在 grade/score 下降时发出 alert
0 8 * * * cur=$(npx @aayushcodebook/agentscan@latest --quiet 2>/dev/null); prev=$(cat ~/.agentscan/last 2>/dev/null); \
echo "$cur" > ~/.agentscan/last; [ "$cur" != "$prev" ] && \
printf '%s\n' "$cur" | grep -qE 'AT RISK|fail' && \
osascript -e "display notification \"$cur\" with title \"agentscan\"" 2>/dev/null || true
```
在 Linux 上,将 `osascript` 行替换为 `notify-send "agentscan" "$cur"`(或通过管道发送至
Slack/email)。在 CI 中,`examples/agentscan-scan.yml` 中的 GitHub Action 会执行相同的
定时操作并上传 SARIF。
内置的 `agentscan --watch`(文件监控 agent 的 config + skills 目录,在
发生更改时立即扫描)已列入路线图——如果您会使用它,请提交 issue。
实时行为监控(在数据外泄或 injection *发生时*进行捕获)是
一项独立且更庞大的工作,不属于此 CLI 的一部分。
### 它与原生工具的关系
agentscan 是 agent 自带审计工具的**补充**,而非替代品。
OpenClaw 内置的 `openclaw security audit --deep` 在
OpenClaw 专属的 config 加固(文件系统 ACL、hooks、Docker 沙盒
内部原理)方面要深入得多,并且可以自动修复——请运行它。agentscan 独特的价值在于**跨 agent
覆盖**(OpenClaw *和* Hermes)、**精心整理的恶意 skill 黑名单**和
**CVE 公告 feed**(内置 `doctor` 无法维护的威胁情报),以及面向安全团队和 CI 的
**框架映射、SARIF 输出**。建议两者配合使用。
干净的结果意味着未发现*这些*已知问题。这并不能
保证整体安全——值得注意的是,prompt injection 是作为
*态势*进行评估的,并未证明其不存在,而原生的 `--deep` 审计会发现
agentscan 无法检测到的 config 加固细节。
## 用法
```
npx @aayushcodebook/agentscan # scan auto-detected installs
npx @aayushcodebook/agentscan --path ~/my-agent # also scan a custom location (repeatable)
npx @aayushcodebook/agentscan --json # full findings + score + framework tags (JSON)
npx @aayushcodebook/agentscan --sarif # SARIF 2.1.0 for GitHub code scanning / CI
npx @aayushcodebook/agentscan --quiet # one-line graded verdict
npx @aayushcodebook/agentscan --update-feed # refresh blocklist + CVE advisory feeds
npx @aayushcodebook/agentscan --help
```
### 退出码
| 代码 | 含义 |
|------|---------|
| `0` | 全部正常(或未发现 agent) |
| `1` | 仅有警告 —— 建议审查 |
| `2` | 严重问题 —— 立即修复 |
| `3` | 扫描器错误 |
在 CI 中很有用:`npx @aayushcodebook/agentscan --quiet || echo "agent needs attention"`。
## 隐私
agentscan 会读取本地文件并列出本地 socket 以生成报告。它
**不发起网络调用**,也不上传任何内容。恶意 skill 黑名单
在包内离线提供。您可以通过阅读
`src/` 来确认所有这些内容——它是几百行没有任何第三方包的纯 Node 代码。
## 支持的 agent
`src/data/targets.js` 中的布局取自每个项目的官方文档:
| Agent | Config | 默认端口 | 绑定设置 | Extensions |
|-------|--------|--------------|--------------|------------|
| **OpenClaw** | `~/.openclaw/openclaw.json` (JSON5), `~/.openclaw/.env`; 旧版 `~/.clawdbot/` | `18789` | `gateway.bind`: `loopback` (安全) / `lan` / `tailnet` / `custom` | skills (`SKILL.md`) + plugins (`openclaw.plugin.json`) |
| **Hermes Agent** | `~/.hermes/config.yaml`, `~/.hermes/.env` | `8642` API, `9119` dashboard | `API_SERVER_HOST` 环境变量 (`127.0.0.1` 安全, `0.0.0.0` 暴露) | skills (`SKILL.md`, 按类别嵌套) |
添加另一个 agent 只需要在 `src/data/targets.js` 中添加一个条目(其 config 路径、
默认端口、绑定模型和 skill 目录)。
## 更新威胁 feed
内置的恶意 skill 黑名单 + CVE 公告是一个*保底基准*。无需
升级包即可刷新它们:
```
agentscan --update-feed
agentscan --update-feed --feed-url https://your-mirror/blocklist.json
```
信任保证(见 `src/feed.js`):
- **扫描器零网络调用**——它会读取内置列表或您之前
明确获取的 feed,以较新者为准。`--update-feed` 是唯一
接触网络的命令。
- 内置版本是**降级底线**:拒绝使用过期或被篡改(例如
清空)的缓存,因此检测能力不会被悄无声息地削弱。
- 获取失败会**回退到内置版本**并以非零状态退出。
## 贡献
欢迎提交 issue 和 PR——尤其是新的 agent 定义(`src/data/targets.js`)、
黑名单/CVE 条目以及误报报告。整个工具是无依赖的,
旨在方便从头到尾阅读;运行 `node test/run.js` 即可执行测试套件。
## 许可证
MIT。
https://github.com/user-attachments/assets/422a90a9-3ce1-4071-8ce9-38c10cf77238
大多数 agent 安全工具只能在您安装之前扫描单个 agent 的单一 skill。
agentscan 可审计您的**整个运行中安装**——并且支持跨 **OpenClaw,
Hermes 等**通过单一工具完成。一条命令即可执行基于框架映射的
态势评估——**19 项检查加上复合风险关联**——涵盖
网络暴露、网关认证、CVE、密钥、SSRF、沙盒,*以及*恶意
skills/plugins(包含污点分析 + prompt injection 检测)。它将每个
发现映射到 CWE / OWASP LLM Top 10 / MITRE ATLAS,为您的设置评分 **A–F**,并
为 CI 输出 **SARIF**。一切都在您的本地机器上运行——绝不上传
任何数据,且**零依赖**,因此您可以在信任它之前查阅每一行代码。
已针对 **OpenClaw 和 Hermes 两者的**真实默认安装进行了验证——
每项均获得 **B** 评级,并提供具体、可操作的发现,**零误报**(包含
超过 300 个真实的内置 skills)。
```
npx @aayushcodebook/agentscan
```
```
OpenClaw ~/.openclaw F 0/100
──────────────────────────────────────────────────
● FAIL CHAIN: network-exposed AND unauthenticated gateway (RCE-class) CRIT
CWE-306,CWE-668 · LLM06:2025 · AML.T0049,AML.T0012
● FAIL Agent version vs. known security advisories (CVEs) CRIT
CWE-1395 · LLM03:2025
Installed version 3.0.0 is affected by CVE-2026-25253 (CVSS 8.8)…
● FAIL Malicious or suspicious skills & plugins CRIT
● FAIL Gateway authentication (is the local API/WebSocket protected?) CRIT
…
posture grade F 0/100
coverage: 13/15 checks ran
```
## 检查内容
每个发现都会标记其 **CWE**、**OWASP LLM Top 10 (2025)**,以及(如果适用)
**MITRE ATLAS** 技术,并带有用于评分的固有严重性。
| 检查项 | 映射到 | 为什么重要 |
|-------|---------|----------------|
| **网络暴露** | CWE-668 · ATLAS T0049 | 端口在 localhost 之外是否可访问?(63% 的公开实例是可访问的。) |
| **隧道暴露** | CWE-668 · LLM06 | 通过 Tailscale Funnel / ngrok / cloudflared 代理的 localhost 绑定 agent 实际上仍暴露在公网上——这是绑定地址的视觉盲区。 |
| **网关认证** | CWE-306/307 · LLM06 | 开放端口 + 无/弱认证 = ClawJacked/ClawBleed (CVE-2026-25253) 的前置条件。 |
| **访问策略** | CWE-284 · LLM06 | `dmPolicy: open` / `allowFrom: ["*"]` 允许频道上的任何陌生人指挥 agent。 |
| **CORS** | CWE-942 | 通配符 origin 允许您访问的任何网站调用 agent 的 API。 |
| **明文凭据** | CWE-312 · LLM02 | API 密钥/密码以明文形式存储在 config 中。 |
| **密钥脱敏** | CWE-532 · LLM02 | 如果关闭脱敏,工具输出中的密钥会泄漏到 transcripts 和磁盘上的 logs 中。 |
| **密钥文件权限** | CWE-732 | `.env` 中的密钥只有在文件对全局不可读时才是安全的。 |
| **Git 中的密钥** | CWE-540 · LLM02 | Agent 主目录是一个 repo 且密钥未被 `.gitignore` 忽略 → 被提交/推送。 |
| **版本与 CVE** | CWE-1395 · LLM03 | 运行带有已发布安全公告的构建(feed 可更新;内置 2026 年 OpenClaw CVE)。 |
| **恶意 skills & plugins** | CWE-506 · LLM01/LLM03 · ATLAS T0010 | 通过签名发现(`SKILL.md`/`openclaw.plugin.json`),与 ClawHavoc 黑名单匹配,进行**污点分析**(密钥是否真的*流入*了网络/exec sink?),在 SKILL.md *文本*中进行 **prompt injection 扫描**(隐形/双向 unicode、隐藏注释指令、角色劫持/覆盖、数据外泄 prompt),并进行**完整性验证**(“第一方” skill 只有在其字节哈希与原始匹配时才被信任;冒名顶替者将被捕获)。如果未发现任何内容则跳过(从不通过)。 |
| **MCP 供应链** | CWE-829 · LLM03 | 远程 MCP 工具服务器是位于 agent 信任边界内的第三方代码。 |
| **SSRF / 私有 URL** | CWE-918 · LLM06 | 如果开启了私有 URL 访问,中毒的链接可能会触达内部主机或 cloud-metadata endpoint (169.254.169.254)。 |
| **命令内容扫描器** | CWE-693 · LLM06 | Hermes 预先检查 shell 命令 (Tirith);标记其是否已禁用或 fail-open。 |
| **沙盒 / agency** | CWE-250 · LLM06 | 未沙盒化的工具(或以 root 身份运行)会将一条错误指令转化为完整的机器访问权限。 |
| **命令/exec 策略** | CWE-250 · LLM06 | 不受限制的 shell(`tools.exec.security="full"`,命令允许列表为空)是从 prompt injection 到 RCE 的路径。 |
| **审批 (HITL)** | CWE-250 · LLM06 | 自动批准的高影响操作移除了对抗被劫持 agent 的最后一道人工关卡。 |
| **Prompt injection 暴露** | CWE-77 · LLM01 · ATLAS T0051 | 态势:不受信任的输入 × 能力 × 弱关卡。诚实地说明静态扫描无法*证明* injection 路径。 |
| **审计日志** | CWE-778 | 没有 agent 操作记录 = 没有事件响应,不符合 SOC2/HIPAA/GDPR。 |
**复合风险关联。** 单独为黄色的发现可能构成严重的
链条。agentscan 会指出它们——例如 *暴露 + 未认证*(RCE 级别,
CVE-2026-25253)、*暴露 + 开放命令策略*、*不受信任的输入 + 实时
恶意扩展*。
**态势评分与评级。** 从 100 分开始,减去基于严重程度的扣分
(fail = 全扣,warn = 扣半,**skipped = 扣 ¼**,因此不确定性仍会产生代价),最低为 0,划分为 A–F。覆盖率会单独报告,因此低覆盖率下的高分无法伪装成安全。
## 持续监控(免费)
扫描是点状时间点操作,但风险时刻是在设置*之后*——当您安装
新 skill 或更改 config 时。按计划重新运行,仅在您的态势
变**糟**时收到警报。无需额外工具——只需 `agentscan`、调度程序和 diff。
一个 cron 单行命令可每日重新扫描,并在出现任何新发现(评级下降或
新 fail)时发出通知,并与上次运行结果进行比对:
```
# crontab -e → 每天早上 8 点进行 scan;仅在 grade/score 下降时发出 alert
0 8 * * * cur=$(npx @aayushcodebook/agentscan@latest --quiet 2>/dev/null); prev=$(cat ~/.agentscan/last 2>/dev/null); \
echo "$cur" > ~/.agentscan/last; [ "$cur" != "$prev" ] && \
printf '%s\n' "$cur" | grep -qE 'AT RISK|fail' && \
osascript -e "display notification \"$cur\" with title \"agentscan\"" 2>/dev/null || true
```
在 Linux 上,将 `osascript` 行替换为 `notify-send "agentscan" "$cur"`(或通过管道发送至
Slack/email)。在 CI 中,`examples/agentscan-scan.yml` 中的 GitHub Action 会执行相同的
定时操作并上传 SARIF。
内置的 `agentscan --watch`(文件监控 agent 的 config + skills 目录,在
发生更改时立即扫描)已列入路线图——如果您会使用它,请提交 issue。
实时行为监控(在数据外泄或 injection *发生时*进行捕获)是
一项独立且更庞大的工作,不属于此 CLI 的一部分。
### 它与原生工具的关系
agentscan 是 agent 自带审计工具的**补充**,而非替代品。
OpenClaw 内置的 `openclaw security audit --deep` 在
OpenClaw 专属的 config 加固(文件系统 ACL、hooks、Docker 沙盒
内部原理)方面要深入得多,并且可以自动修复——请运行它。agentscan 独特的价值在于**跨 agent
覆盖**(OpenClaw *和* Hermes)、**精心整理的恶意 skill 黑名单**和
**CVE 公告 feed**(内置 `doctor` 无法维护的威胁情报),以及面向安全团队和 CI 的
**框架映射、SARIF 输出**。建议两者配合使用。
干净的结果意味着未发现*这些*已知问题。这并不能
保证整体安全——值得注意的是,prompt injection 是作为
*态势*进行评估的,并未证明其不存在,而原生的 `--deep` 审计会发现
agentscan 无法检测到的 config 加固细节。
## 用法
```
npx @aayushcodebook/agentscan # scan auto-detected installs
npx @aayushcodebook/agentscan --path ~/my-agent # also scan a custom location (repeatable)
npx @aayushcodebook/agentscan --json # full findings + score + framework tags (JSON)
npx @aayushcodebook/agentscan --sarif # SARIF 2.1.0 for GitHub code scanning / CI
npx @aayushcodebook/agentscan --quiet # one-line graded verdict
npx @aayushcodebook/agentscan --update-feed # refresh blocklist + CVE advisory feeds
npx @aayushcodebook/agentscan --help
```
### 退出码
| 代码 | 含义 |
|------|---------|
| `0` | 全部正常(或未发现 agent) |
| `1` | 仅有警告 —— 建议审查 |
| `2` | 严重问题 —— 立即修复 |
| `3` | 扫描器错误 |
在 CI 中很有用:`npx @aayushcodebook/agentscan --quiet || echo "agent needs attention"`。
## 隐私
agentscan 会读取本地文件并列出本地 socket 以生成报告。它
**不发起网络调用**,也不上传任何内容。恶意 skill 黑名单
在包内离线提供。您可以通过阅读
`src/` 来确认所有这些内容——它是几百行没有任何第三方包的纯 Node 代码。
## 支持的 agent
`src/data/targets.js` 中的布局取自每个项目的官方文档:
| Agent | Config | 默认端口 | 绑定设置 | Extensions |
|-------|--------|--------------|--------------|------------|
| **OpenClaw** | `~/.openclaw/openclaw.json` (JSON5), `~/.openclaw/.env`; 旧版 `~/.clawdbot/` | `18789` | `gateway.bind`: `loopback` (安全) / `lan` / `tailnet` / `custom` | skills (`SKILL.md`) + plugins (`openclaw.plugin.json`) |
| **Hermes Agent** | `~/.hermes/config.yaml`, `~/.hermes/.env` | `8642` API, `9119` dashboard | `API_SERVER_HOST` 环境变量 (`127.0.0.1` 安全, `0.0.0.0` 暴露) | skills (`SKILL.md`, 按类别嵌套) |
添加另一个 agent 只需要在 `src/data/targets.js` 中添加一个条目(其 config 路径、
默认端口、绑定模型和 skill 目录)。
## 更新威胁 feed
内置的恶意 skill 黑名单 + CVE 公告是一个*保底基准*。无需
升级包即可刷新它们:
```
agentscan --update-feed
agentscan --update-feed --feed-url https://your-mirror/blocklist.json
```
信任保证(见 `src/feed.js`):
- **扫描器零网络调用**——它会读取内置列表或您之前
明确获取的 feed,以较新者为准。`--update-feed` 是唯一
接触网络的命令。
- 内置版本是**降级底线**:拒绝使用过期或被篡改(例如
清空)的缓存,因此检测能力不会被悄无声息地削弱。
- 获取失败会**回退到内置版本**并以非零状态退出。
## 贡献
欢迎提交 issue 和 PR——尤其是新的 agent 定义(`src/data/targets.js`)、
黑名单/CVE 条目以及误报报告。整个工具是无依赖的,
旨在方便从头到尾阅读;运行 `node test/run.js` 即可执行测试套件。
## 许可证
MIT。标签:AI安全, Chat Copilot, MITM代理, OWASP LLM Top 10, StruQ, Web报告查看器, XXE攻击, 安全态势评估, 插件系统, 文档结构分析, 自定义脚本