FathimaNafra/finance-databricks-data-engineering-project
GitHub: FathimaNafra/finance-databricks-data-engineering-project
基于 Databricks 的端到端金融数据工程项目,采用 Medallion Architecture 实现数据处理全流程并支持欺诈检测与可视化分析。
Stars: 0 | Forks: 0
# 使用 Databricks 的金融数据工程项目
## 概述
本项目展示了基于 Databricks 构建的端到端 Data Engineering pipeline,采用了 Medallion Architecture(Bronze、Silver 和 Gold 层)。该 pipeline 会生成合成的金融交易数据,经过多个转换阶段进行处理,并生成可用于业务报告的分析就绪数据集。
本项目展示了关键的 Data Engineering 概念,包括数据摄取、数据转换、数据质量管理和分析型数据建模。
## 项目亮点
- 使用 Databricks 构建了端到端的 Data Engineering pipeline
- 实现了 Bronze、Silver 和 Gold Medallion Architecture
- 生成并处理了超过 10 万笔金融交易
- 构建了交互式 SQL dashboard 用于业务报告
- 执行了欺诈检测和风险分析
- 利用 Delta Lake 实现可扩展的数据存储
- 将 GitHub 版本控制与 Databricks 集成
## 架构
```
Raw Data Generation
│
▼
Bronze Layer
(Raw Ingestion)
│
▼
Silver Layer
(Data Cleaning &
Transformation)
│
▼
Gold Layer
(Business Metrics &
Analytics Tables)
```
## 项目结构
```
Finance_DE_Project
│
├── 01_Data_Generation
│ └── Generate_Finance_Data.ipynb
│
├── 02_Bronze
│ └── Bronze_Layer.ipynb
│
├── 03_Silver
│ └── Silver_Layer.ipynb
│
├── 04_Gold
│ └── Gold_Layer.ipynb
│
└── workflow_design.md
```
## 使用的技术
- Databricks
- Apache Spark
- PySpark
- Python
- Delta Lake
- Pandas
- Faker
- GitHub
## Medallion Architecture
### Bronze 层
**目的**
- 摄取原始金融数据
- 保留原始记录
- 存储未经转换的数据
**操作**
- 数据加载
- Schema 验证
- 原始数据存储
### Silver 层
**目的**
- 清洗和标准化数据
- 处理缺失值
- 提高数据质量
**操作**
- 数据清洗
- 数据验证
- 类型转换
- 应用业务规则
### Gold 层
**目的**
- 创建分析就绪的数据集
- 生成业务指标
- 支持报告和 dashboard
**操作**
- 聚合
- KPI 计算
- 财务汇总
- 报告数据集
## 数据集
使用 Faker 库生成合成的金融数据。
### 示例字段
| 列名 | 描述 |
|----------|------------|
| customer_id | 唯一客户标识符 |
| name | 客户姓名 |
| email | 客户电子邮件 |
| city | 客户位置 |
| transaction_id | 交易标识符 |
| amount | 交易金额 |
| transaction_date | 交易日期 |
| payment_method | 支付类型 |
## Pipeline 工作流
### 第一步 – 数据生成
使用 Python 和 Faker 生成真实的合成金融数据。
**输出**
```
Raw Finance Dataset
```
### 第二步 – Bronze 层
将生成的数据加载到 Bronze 层。
**输出**
```
Raw Delta Tables
```
### 第三步 – Silver 层
清洗、验证并标准化数据。
**输出**
```
Processed Delta Tables
```
### 第四步 – Gold 层
创建分析数据集和业务 KPI。
**输出**
```
Reporting Tables
```
## 核心功能
- 端到端 Data Pipeline
- Medallion Architecture 实现
- Delta Lake 存储
- 合成数据生成
- 数据质量验证
- 可扩展的 Spark 处理
- 分析就绪的 Gold 层
- Git 与 Databricks 集成
## 业务洞察示例
Gold 层可用于分析:
- 总收入
- 客户消费模式
- 交易趋势
- 区域业绩
- 支付方式分布
- 月度财务 KPI
## 如何运行
### 克隆仓库
```
git clone https://github.com/FathimaNafra/finance-databricks-data-engineering-project.git
```
### 在 Databricks 中打开
1. 将仓库导入 Databricks。
2. 附加一个 cluster 或使用 Serverless Compute。
3. 按以下顺序执行 notebook:
```
01_Data_Generation
↓
02_Bronze
↓
03_Silver
↓
04_Gold
```
## 学习成果
本项目展示了:
- Data Engineering 基础
- Apache Spark 处理
- Delta Lake 实现
- ETL/ELT Pipeline 开发
- Data Lakehouse 架构
- Databricks Workflow 开发
- Git 版本控制集成
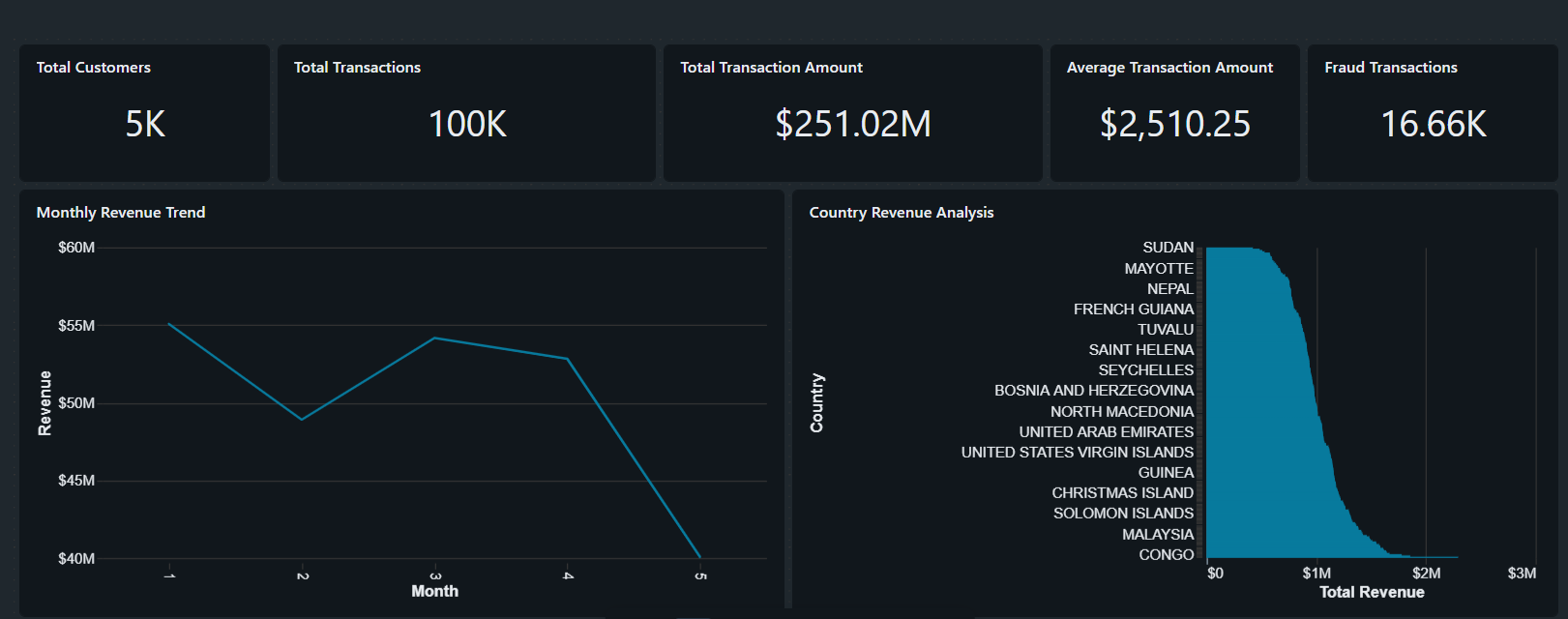
### 关键指标
| 指标 | 数值 |
|----------|----------|
| 客户总数 | 5,000 |
| 交易总数 | 100,000 |
| 交易总金额 | $251.02M |
| 平均交易金额 | $2,510.25 |
| 欺诈交易 | 16.66K |
### Dashboard 功能
#### 收入分析
- 月度收入趋势
- 国家收入分析
- 收入业绩监控
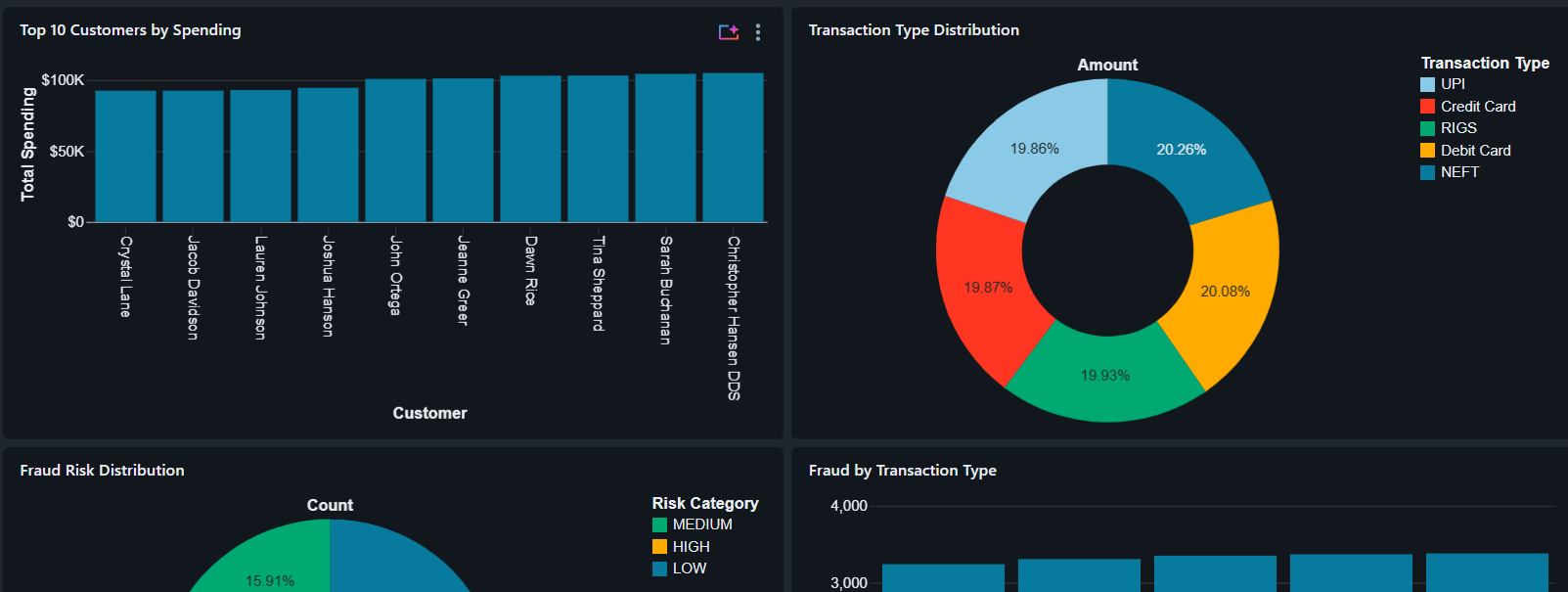
#### 客户分析
- 消费额排名前 10 的客户
- 客户交易分析
- 消费模式识别
#### 交易分析
- 交易类型分布
- 支付方式分析
- 交易量监控
#### 欺诈分析
- 欺诈风险分布
- 按交易类型划分的欺诈
- 风险类别分类
- 欺诈检测洞察
### Dashboard 洞察
- 处理了超过 100,000 笔金融交易
- 从超过 $251M 的交易量中生成了收入分析
- 识别了超过 16,000 笔潜在欺诈交易
- 将欺诈风险划分为低、中、高三类
- 分析了跨多个交易渠道的客户消费行为
-
## Dashboard 预览
### 使用的技术
- Databricks SQL Dashboard
- Apache Spark
- Delta Lake
- PySpark
- SQL Analytics
- Databricks Lakehouse Platform
## 作者
**Fathima Nafra**
GitHub: https://github.com/FathimaNafra
标签:Databricks, Delta Lake, PySpark, 代码示例, 多线程, 数据分析, 数据工程, 逆向工具, 金融数据