NeuralWatch
具备本地 AI 分析能力的自动化网络威胁情报平台






## 为什么开发这个项目
在学习网络安全的过程中,我一直问自己一个问题:*如果威胁情报对每个 SOC 都如此关键,为什么仍然依赖于分析师手动浏览 RSS 订阅源,并将 IOC 复制粘贴到电子表格中?*
像 Recorded Future 和 Mandiant Advantage 这样的商业平台解决了这个问题——但需要花费 1.5 万到 10 万美元/年。MISP 和 OpenCTI 是开源替代方案,但它们需要庞大的基础设施,并且仍然将“阅读和总结报告”这部分工作留给人类。
随着本地 LLM 真正具备执行结构化提取任务的能力,我意识到我可以构建一个自动化整个 CTI 生命周期的系统——收集、提取、丰富、AI 驱动的分析和分发——并且完全在一台笔记本电脑上运行,无需云成本,也不会有敏感数据离开网络。这就是 NeuralWatch。
## 实际功能
NeuralWatch 全天候监控 **12 个威胁情报源**——从 AlienVault OTX 和 CISA 的已知漏洞利用 (KEV) 目录,到 Unit 42、Talos 和 Securelist 等供应商的研究博客。每 30 分钟,它会拉取新数据,从原始报告中提取 IOC(IP、域名、哈希、CVE),使用 AbuseIPDB 和 VirusTotal 的信誉评分对其进行丰富,然后通过 Ollama 将报告文本提供给**本地运行的 Phi-3-Mini 模型**进行处理。
LLM 不仅仅是进行总结——它还能生成结构化的 JSON 输出,包含威胁行为者归属、MITRE ATT&CK 战术和技术映射、目标行业、恶意软件家族、严重性评级以及建议的检测规则。所有这些都将在后台自主运行。最终输出是什么?每日高管简报、适配 SIEM 的 IOC 导出文件,以及 STIX 2.1 数据包——全程无需人工干预。
## 仪表板
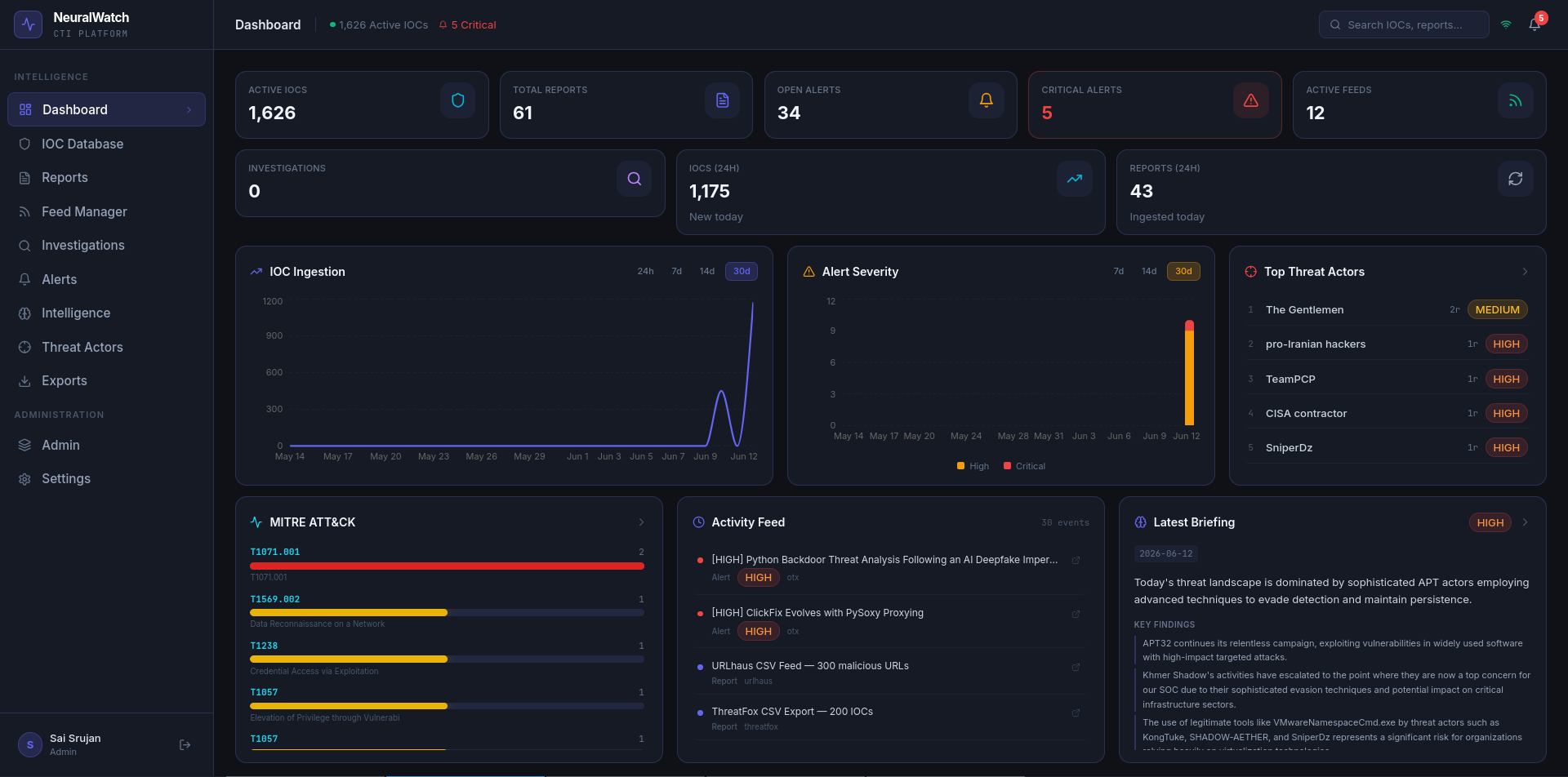
SOC 主管所需的一切都集中在一个屏幕上:实时 IOC 计数、摄取趋势(支持 24 小时/7 天/14 天/30 天时间范围)、警报严重程度分布、活跃度最高的威胁行为者、MITRE ATT&CK 技术观测、实时活动流以及最新的 AI 生成的简报。无需滚动页面。
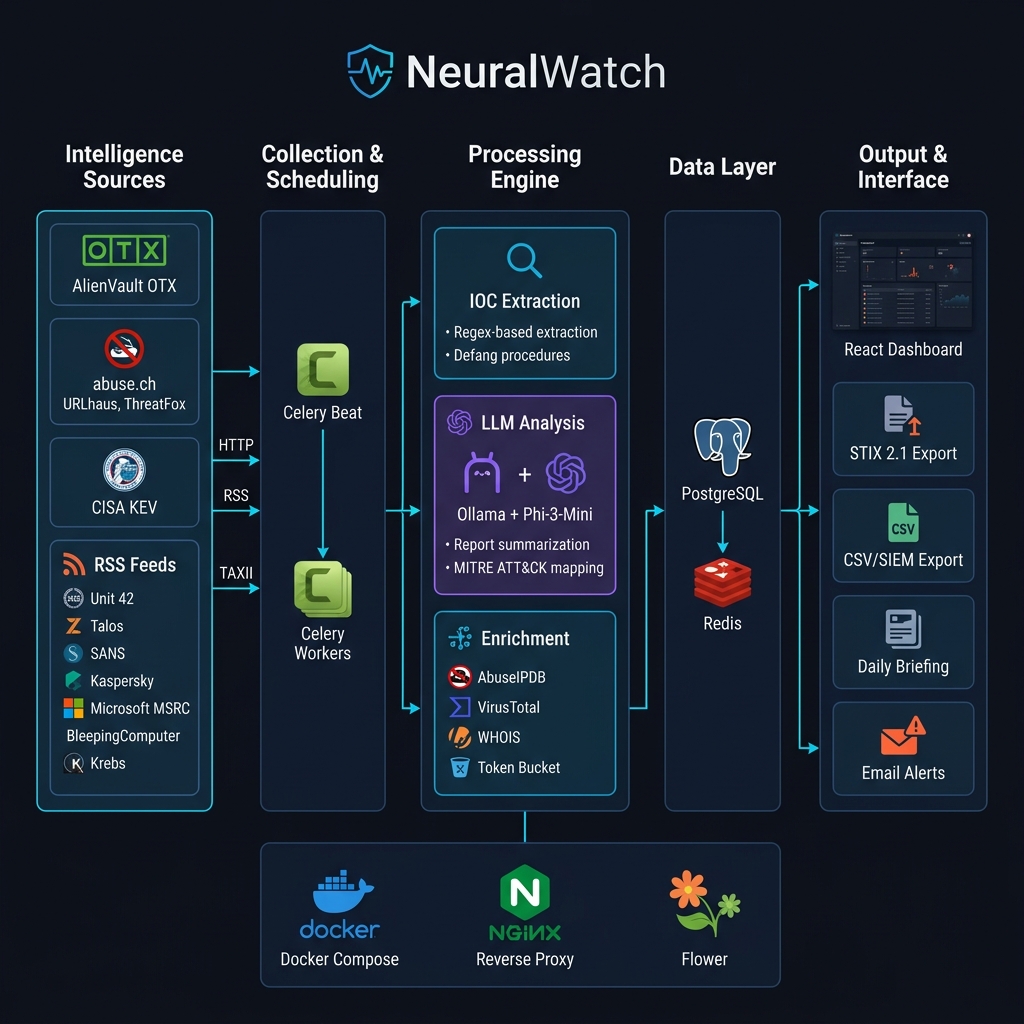
## 数据流水线 —— 数据流向
这并不是一个只运行一次的脚本。它是一个基于 Celery 构建的用于分布式任务处理的连续、多阶段流水线:
**1. 收集 →** Celery Beat 根据可配置的时间表触发收集任务。每种源类型——JSON API、RSS/Atom、TAXII 2.1——都有自己独立的收集器类。数据源在 YAML 注册表中定义,因此添加新数据源只需修改配置,而无需编写代码。单个源的失败永远不会阻塞其他源。
**2. IOC 提取 →** 每份报告都会经过基于 `iocextract` 构建的提取引擎和自定义验证器的处理。它会提取 IPv4/v6、域名、URL、文件哈希 (MD5/SHA1/SHA256)、CVE 和电子邮件地址。至关重要的是,它能处理**消除威胁的指示器**——当研究人员为了避免读者误点击而写成 `hxxp[://]evil[.]com` 或 `1[.]2[.]3[.]4` 时——系统会自动将其还原以进行存储。系统会过滤掉 RFC 1918 私有网段,以避免报告内嵌的网络拓扑图引发误报。
**3. LLM 分析 →** 这正是 AI 层发挥关键作用的地方。报告会排队,通过运行 Phi-3-Mini Q4_K_M(占用约 2.5 GB 内存)的 Ollama 进行本地推理。我是经过深思熟虑后才选择这个模型的——它足够小,可以在 CPU 上运行而不会拖垮 16 GB 内存的机器,而且在适当约束任务的情况下,它完全有能力执行结构化提取。
这里的关键工程决策如下:
- **温度参数设为 0.1** —— 我需要的是确定性的、符合 schema 的 JSON,而不是创意写作。低温使模型的输出具有可预测性。
- **带重叠的分块处理** —— 超过约 1,500 个 token 的报告会在句子边界处被切分,并带有 200 个 token 的重叠。每个分块独立总结,然后通过最终的合成调用将它们合并。这本质上是应用于 LLM 处理的 map-reduce 模式。
- **三层 JSON 解析** —— 小模型会产生混乱的输出。流水线会剥离 Markdown 代码块标记,使用基于边界的提取方法(`从第一个 { 到最后一个 }`),修复尾随逗号和未闭合的大括号,作为最后手段,还会回退到正则表达式字段提取。如果所有这些尝试都失败,该报告将被排入重试队列——绝不会导致流水线崩溃。
- **Jinja2 提示词模板** —— 提示词以 `.j2` 模板的形式存储,而不是硬编码的字符串。这让我能够在不改动 Python 代码的情况下,对提示词工程进行迭代优化。
**4. 丰富 →** IOC 会通过 AbuseIPDB 置信度分数、VirusTotal 检出率和 WHOIS 注册数据进行丰富。API 配额由 **令牌桶限流器** 管理——而不是简单粗暴的 `sleep()`——这允许在配额允许时进行突发处理,同时严格遵守每日限制(AbuseIPDB 为每天 1,000 次,VirusTotal 为每分钟 4 次)。所有结果都缓存在数据库中,TTL(生存时间)为 7 天,以防止重复查询。
**5. 置信度评分 →** 每个 IOC 都会获得一个计算出的置信度分数 (0.0–1.0),计算基于:有多少独立来源报告了它、时效性如何、丰富 API 返回了什么结果,以及来源数据源的质量权重。只有高于可配置阈值(默认:0.6)的 IOC 才会进入 SIEM 导出文件。这就是一个有用的情报源与一个误报生成器之间的区别。
**6. 输出 →** 以 Markdown 格式呈现的每日 AI 合成高管简报、兼容 Wazuh 的活动 IOC CSV 导出文件、用于与 MISP/OpenCTI 互操作的 STIX 2.1 数据包、XLSX 报告,以及针对关键发现的可配置电子邮件警报。
## AI 驱动的报告分析
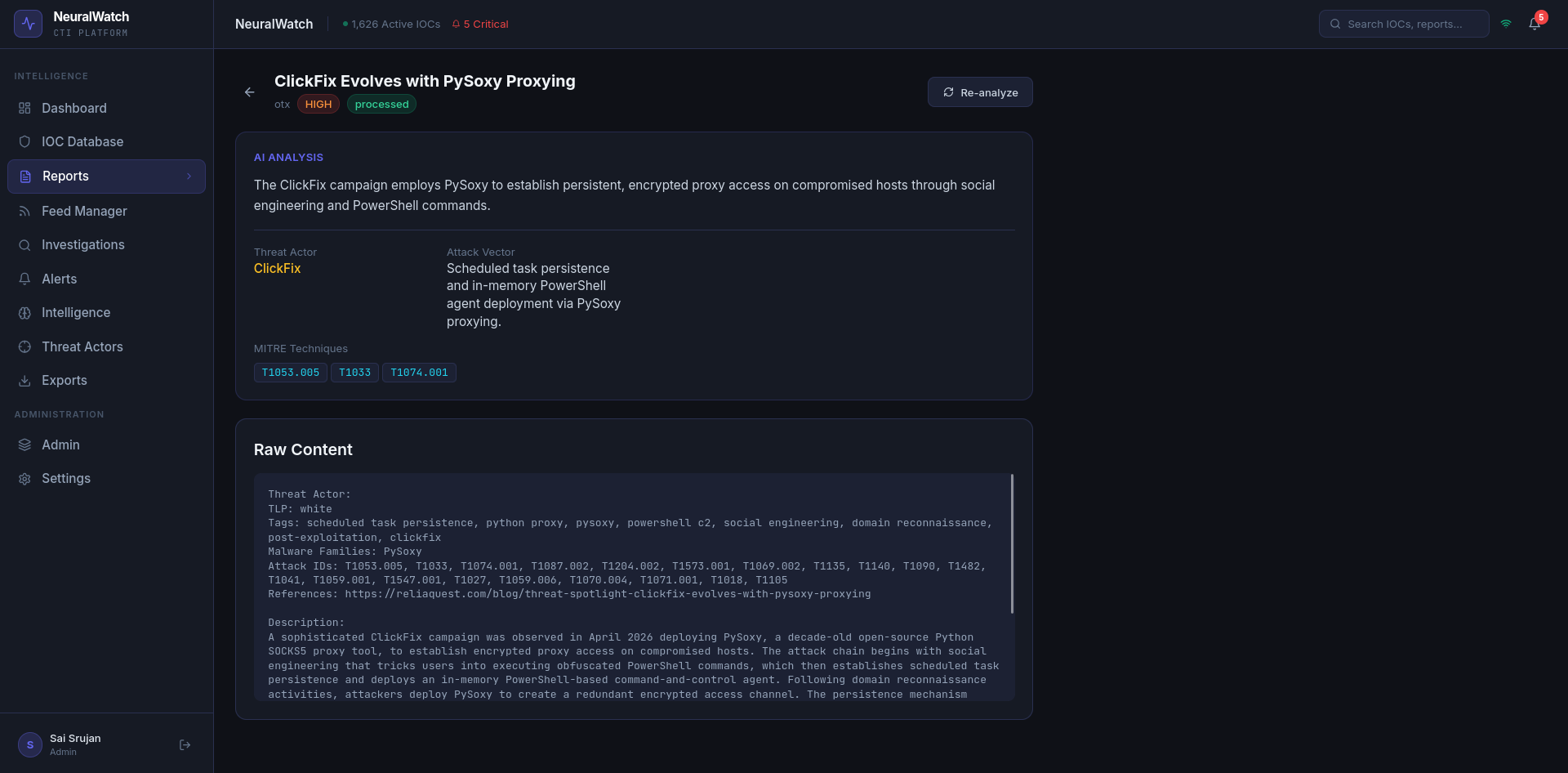
每份摄取的报告都会被自动分析。LLM 会识别威胁行为者,将技术映射到 MITRE ATT&CK(精确到如 T1053.005 或 T1059.001 等子技术级别),提取恶意软件家族,并撰写简明扼要的高管摘要。分析师处理一份报告需要 15-20 分钟,而该系统在 90 秒内即可自主完成。
系统提示词被设计为扮演一名 CTI 分析师的角色——而不是聊天机器人。它被限制为仅输出符合严格 schema 的 JSON,包含严重性评级、置信度分数和建议的检测规则。当模型返回乱码时(小模型有时会这样),流水线会捕获它、记录日志并重试——无需人工干预。
## 情报来源
所有订阅源均通过 `feeds/registry.yaml` 配置——添加新源无需修改任何代码:
| 来源 | 类型 | 间隔 | 提供内容 |
|------|------|----------|-----------------|
| **AlienVault OTX** | JSON API | 30 分钟 | 包含结构化 IOC 的社区威胁脉冲 |
| **CISA KEV** | JSON API | 6 小时 | 已知被利用漏洞 —— US-CERT 权威数据 |
| **URLhaus** (abuse.ch) | JSON API | 30 分钟 | 实时恶意 URL 订阅源 |
| **ThreatFox** (abuse.ch) | JSON API | 1 小时 | 社区 IOC 共享 —— IP、域名、哈希 |
| **Palo Alto Unit 42** | RSS | 4 小时 | 企业级 APT 研究及详细 IOC |
| **Cisco Talos** | RSS | 4 小时 | 威胁情报与漏洞分析 |
| **Kaspersky Securelist** | RSS | 4 小时 | 深入的 APT 及恶意软件活动研究 |
| **SANS ISC** | RSS | 2 小时 | 包含技术分析的每日安全日记 |
| **Microsoft MSRC** | RSS | 6 小时 | 微软安全公告和补丁 |
| **BleepingComputer** | RSS | 1 小时 | 安全新闻、CVE 跟踪、恶意软件家族 |
| **Krebs on Security** | RSS | 6 小时 | 调查性安全新闻 |
| **MalwareBazaar** (abuse.ch) | JSON API | *已禁用* | 恶意软件哈希库 *(需要付费 API 密钥)* |
每个源都有一个 `confidence_weight` (0.0–2.0),反映了其可靠程度。CISA KEV 获得权重 1.8(权威政府来源),而 BleepingComputer 获得权重 0.8(新闻类——有助于了解背景,但不是主要的 IOC 来源)。这些权重直接影响从该源提取出的每个 IOC 的置信度评分。
## 技术栈
| 层级 | 技术 | 选择原因 |
|-------|-----------|----------------|
| **后端** | Python 3.10+, FastAPI, SQLAlchemy 2.0 (异步) | 通过 Pydantic 实现类型安全的异步优先 API |
| **任务队列** | Celery + Redis | 用于并发收集/丰富/分析的分布式 worker |
| **调度器** | Celery Beat | 在容器重启期间持久的基于 cron 的调度 |
| **数据库** | PostgreSQL 16 | 具备完全 ACID 合规性的生产级关系型存储 |
| **缓存 / Broker** | Redis 7 | 集任务 broker、结果后端和会话缓存于一项服务中 |
| **AI 引擎** | Ollama + Phi-3-Mini (Q4_K_M) | 本地 CPU 推理 —— 占用约 2.5 GB 内存,零云成本,数据保留在本地 |
| **前端** | React 18, TypeScript, Vite, TailwindCSS | 具有实时数据可视化功能的响应式暗色模式仪表板 |
| **IOC 提取** | `iocextract` + 自定义验证器 | 处理其他库遗漏的已消除威胁 (Defanged) 的指示器 |
| **丰富** | AbuseIPDB, VirusTotal, WHOIS | IP 信誉、哈希判定、域名注册情报 |
| **标准** | STIX 2.1 / TAXII 2.1 | ISAC 和政府数据源使用的 NATO 标准威胁共享格式 |
| **导出** | CSV, STIX JSON, Markdown, XLSX | 用于 Wazuh、MISP、OpenCTI 和高管报告的多格式输出 |
| **基础设施** | Docker Compose (8 个服务), Nginx, Flower | 一键部署并内置任务监控 |
## 快速开始
**前置条件:** Docker、Docker Compose,以及来自 [AlienVault OTX](https://otx.alienvault.com/)、[AbuseIPDB](https://www.abuseipdb.com/) 和 [VirusTotal](https://www.virustotal.com/) 的免费 API 密钥。
```
# 1. Clone 仓库
git clone https://github.com/Shiva-destroyer/NeuralWatch.git
cd NeuralWatch
# 2. 配置环境
cp .env.example .env
# Edit .env — 添加你的 API 密钥并设置强密码
# 3. 启动全部 8 个服务
docker compose up -d --build
# 4. 验证
docker compose ps # All services should show 'running'
# 5. 访问 dashboard
# → http://localhost
```
首次启动时,Ollama 将自动拉取 Phi-3-Mini 模型(下载量约 2.3 GB)。使用 `docker compose logs -f ollama` 监控进度。完整的详细步骤请参阅 [SETUP.md](SETUP.md)。
## 示例输出
[`sample_outputs/`](sample_outputs/) 目录包含了平台生成的真实示例:
| 输出 | 格式 | 描述 |
|--------|--------|-------------|
| [每日简报](sample_outputs/daily_briefing_sample.md) | Markdown | AI 合成的高管摘要,包含关键警报和建议操作 |
| [IOC 导出](sample_outputs/iocs_export_sample.csv) | CSV | 带有置信度评分的活动指示器 —— 可直接导入 Wazuh 或任何 SIEM |
| [STIX 包](sample_outputs/stix_bundle_sample.json) | JSON | 用于 MISP / OpenCTI 集成的行业标准 STIX 2.1 输出 |
| [MITRE 数据](sample_outputs/mitre_heatmap_sample.csv) | CSV | 技术频率 —— 可导入 [ATT&CK Navigator](https://mitre-attack.github.io/attack-navigator/) |
## 项目结构
```
NeuralWatch/
├── backend/
│ ├── app/
│ │ ├── api/v1/ # 14 REST endpoints (auth, dashboard, IOCs, reports, feeds, alerts, exports...)
│ │ ├── core/ # Config, security middleware, async DB session management
│ │ ├── intelligence/
│ │ │ ├── collectors/ # Feed-specific collection (OTX, RSS, abuse.ch, CISA)
│ │ │ ├── enricher.py # AbuseIPDB + VirusTotal + WHOIS with token bucket rate limiter
│ │ │ ├── ioc_extractor.py # Regex extraction, defang handling, RFC 1918 filtering
│ │ │ └── llm_analyzer.py # Multi-provider LLM engine (Ollama/Anthropic/OpenAI)
│ │ ├── models/ # SQLAlchemy ORM (IOCs, reports, threat actors, users, enrichment cache)
│ │ ├── schemas/ # Pydantic v2 request/response validation
│ │ ├── services/ # Business logic (IOC lifecycle, exports, AI orchestration)
│ │ └── workers/tasks/ # Celery tasks — collection, enrichment, analysis, briefing queues
│ ├── feeds/registry.yaml # YAML feed config — add sources without touching code
│ ├── prompts/ # Jinja2 prompt templates (summarization.j2, briefing.j2)
│ └── tests/ # pytest suite covering auth, collectors, enrichment, IOC extraction
├── frontend/src/
│ ├── pages/ # Dashboard, IOC Database, Reports, Feed Manager, Alerts, Settings...
│ ├── components/ # Layout, Header, Sidebar — reusable UI components
│ ├── services/ # Typed API client layer
│ └── store/ # Zustand auth state management
├── nginx/ # Reverse proxy config (dev + prod)
├── docker-compose.yml # 8 services: DB, Redis, Ollama, Backend, Worker, Beat, Flower, Frontend, Nginx
├── docker-compose.prod.yml # Production-hardened configuration
└── sample_outputs/ # Working examples of all intelligence outputs
```
## 关键设计决策
**为什么选择 Phi-3-Mini 而不是更大的模型?**
我测试了多个模型。像 Llama 3 8B 这样的大模型生成的文本更好,但需要约 6 GB 内存,对于结构化提取来说性能过剩。Phi-3-Mini 在 Q4_K_M 量化下仅使用约 2.5 GB 内存,在 CPU 上生成速度为 10-15 tokens/秒,并且当您对其进行适当约束时——低温(0.1)、在系统提示词中明确 schema 以及严格要求“仅输出”——它在遵循 JSON schema 方面表现出人意料的好。对于一个处理速度并不批处理流水线来说,在 16 GB 笔记本电脑上,这种内存与质量的权衡使其成为正确的选择。
**为什么使用提示词模板而不是硬编码字符串?**
提示词工程是一个不断迭代的过程。我发现自己经常在微调系统提示词——调整字段描述、更改 few-shot 示例、尝试不同的指令措辞。将提示词存储为 Jinja2 的 `.j2` 模板意味着我可以修改、版本控制和对提示词进行 A/B 测试,而无需改动哪怕一行 Python 代码。这些模板还会注入运行时上下文(报告标题、来源、发布日期),这有助于模型产生更准确的归因。
**为什么需要三层 JSON 解析?**
小型量化模型会产生不完美的输出。Q4 量化下的 Phi-3-Mini 偶尔会将 JSON 包裹在 Markdown 标记中,添加对话式的开场白(如“以下是分析结果:”),产生尾随逗号,或者在对象输出到一半时被截断。解析器并没有将这些情况视为失败,而是分阶段处理它们:剥离 Markdown → 基于边界的提取 → 大括号修复和逗号清理 → 作为最后手段的正则字段提取。这意味着即使是略有格式错误的响应也能产生可用的情报,而不是被直接丢弃。
**为什么使用令牌桶而不是 sleep() 来进行限流?**
在调用 VirusTotal 之间简单地使用 `sleep(0.25)` 会在您积累了配额时浪费时间,并且无法处理突发请求。令牌桶会持续补充,并允许瞬时消耗突发量——如果已经积累了 4 个令牌,4 个 IOC 就会被立即丰富。它还是线程安全的,这对于在 Celery worker 上并发运行丰富任务和收集任务来说至关重要。
**为什么置信度评分对 SIEM 导出很重要。**
将每个提取的 IOC 导出到 Wazuh 会导致检测层充斥着误报。每个 IOC 的置信度是根据以下因素计算的:独立来源的数量、新鲜度(越新 = 分数越高)、丰富 API 的评分以及原始数据源的质量权重。只有高于阈值(默认:0.6)的 IOC 才会被导出。这正是商业 TIP(威胁情报平台)所实现的功能——也是区分有用的威胁情报源和无效信息噪音的关键。
## 经验教训
**用于结构化提取的提示词工程与对话式提示是截然不同的领域。** 当我刚开始使用 LLM 时,我编写提示词的方式就像和 ChatGPT 聊天一样——对话式、开放式。输出结果不一致,而且很难通过程序进行解析。对于提取任务真正有效的方法是:在系统提示词中使用明确的 JSON schema,将 `"Respond with ONLY a valid JSON object"` 作为硬性约束,温度设为 0.1,以及使用包含确切字段名称的零样本指令。模型不需要创作自由——它需要严格的约束。
**Defanged IOC 比我预期的更常见。** 安全研究人员经常修改指示器以防止误点击——`hxxp[://]evil[.]com`,`1[.]2[.]3[.]4`。由于这个原因,早期版本的提取引擎漏掉了研究博客中大约 30% 的指示器。添加全面的 defang 模式匹配并在存储前自动进行恢复,是整个流水线中准确性提升最显著的改进之一。
**缓存是区分可运行的原型与破损原型的关键。** 如果没有本地丰富缓存,那些被广泛报告的 C2 IP 地址在每篇提到它们的报告中都会被重复查询。短短几小时内,免费的 AbuseIPDB 配额就会被耗尽。一个简单的具有 7 天 TTL 的缓存大幅减少了冗余的 API 调用,这意味着流水线实际上可以在没有人工干预的情况下持续运行。
**为失败而构建比成功更重要。** 流水线需要处理具有不同格式的数据源、有速率限制的 API,以及偶尔产生乱码的 LLM。每个组件都被设计为优雅降级——糟糕的 API 响应会进入重试队列,格式错误的 LLM 输出会记录失败并继续往下执行,一个数据源超时不会阻塞其他 11 个数据源。正是这些设计让它成为一个真正的自动化系统,而不是一个需要人盯着的脚本。
## 路线图
- [ ] IOC 关系图谱 —— 映射基础设施连接(IP → 域名 → 注册人 → 电子邮件),用于攻击活动归因
- [ ] 利用 LLM 从恶意软件分析文章中自动生成 YARA 规则
- [ ] 集成 Discord/Slack webhook 以实现实时严重警报
- [ ] 包含历史 TTP 演进时间线的威胁行为者画像页面
- [ ] 直接从仪表板 UI 导出 MITRE ATT&CK Navigator 热力图
## 许可证
MIT 许可证 —— 详情请参阅 [LICENSE](LICENSE)。
由 Sai Srujan Murthy 构建
saisrujanmurthy@gmail.com