Pradeep-G369/SOCweave
GitHub: Pradeep-G369/SOCweave
一个由五类 AI Agent 协同工作的安全告警自动化分诊系统,通过融合威胁情报、基础架构数据与组织上下文,为 SOC 分析师提供带置信度评分的告警判定。
Stars: 3 | Forks: 0
# 🛡️ SOCweave
### 将威胁情报、基础架构数据和人类背景信息交织在一起,每次都能得出明确的判定结果。
**专为 Microsoft Agents League 2026 — 推理智能体赛道打造**
[](LICENSE)







## 🎯 痛点问题
SOC 分析师每天要花费 **4 到 6 小时**调查那些最终被证明是误报的安全警报——这是导致分析师产生职业倦怠的主要原因。每一个孤立出来的警报看起来都令人恐惧,因为它们完全是根据技术信号来判断的,而完全不考虑发生该活动的*原因*或它真正会影响到*谁*。
**SOCweave 解决了这个问题**,它的推理方式就像一名高级分析师:在得出结论之前,综合交叉审查技术证据、基础架构影响以及人类/组织背景信息。
## 🧠 核心功能
SOCweave 是一个**多智能体推理系统**,包含 5 个不同的协同工作的 agent 角色:
| # | Agent | 职责 |
|---|---|---|
| 1 | **Triage Orchestrator** | 规划调查流程——在执行前生成可见的“推理轨迹” |
| 2 | **Foundry IQ Agent** | 将警报与 CVE、MITRE ATT&CK 和威胁情报进行比对——每一个论断均提供引用 |
| 3 | **Fabric IQ Agent** | 通过语义本体图映射基础架构的影响范围 |
| 4 | **Work IQ Agent** | 扫描 M365 邮件/工单以获取人类授权上下文 |
| 5 | **Verdict Synthesizer (Critic)** | 将所有信号整合为带有置信度分数的判定——如果置信度低于 70%,它将**重新自我查询** |
第六个组件是 **Analyst Co-Pilot**,它允许人类分析师使用离线语义 NLP 对任何判定提出后续问题。
## 🔍 工作原理 — 可视化演示(场景 A)
下图完整展示了一个真实的端到端示例:针对 `ASSET-07` 的一项 CRITICAL 警报被五个 agent 调查,并最终以 91% 的置信度被正确识别为已授权的维护操作。

## 🏗️ 架构
```
┌─────────────────────────┐
│ TRIAGE ORCHESTRATOR │
│ (Planner) │
└─────────┬─────────────────┘
┌──────────────┼──────────────┐
┌───────▼─────┐ ┌──────▼──────┐ ┌─────▼──────┐
│ Foundry IQ │ │ Fabric IQ │ │ Work IQ │
│ Agent │ │ Agent │ │ Agent │
│ CVE/MITRE │ │ Blast │ │ Email/ │
│ grounded RAG │ │ radius graph│ │ ticket scan│
└───────┬─────┘ └──────┬──────┘ └─────┬──────┘
└──────────────┼──────────────┘
┌─────────▼─────────────┐
│ VERDICT SYNTHESIZER │
│ (Critic/Verifier + │
│ confidence + severity)│
│ self-corrects if │
│ confidence < 70% │
└─────────┬─────────────┘
┌─────────▼─────────────┐
│ ANALYST CO-PILOT │
│ (semantic Q&A over │
│ verdict context) │
└────────────────────────┘
```
## 🎬 场景套件 — 三个演示,三种推理结果
SOCweave 用三个截然不同的案例证明了它是**结合上下文进行推理**,而不仅仅是模式匹配,这些案例涵盖了完整的决策空间:明确的误报、明确的真实威胁和真正的模糊地带。
### 🟢 场景 A — 误报
一个 **CRITICAL** 的“批量删除文件”警报最终被证明是已授权的维护操作——这得到了 IT 服务台工单和管理员邮件的确认。
### 🔴 场景 B — 真实威胁
一个 **HIGH** 的“异常出站传输”警报匹配到了已知的 C2 服务器和 CVE,且在整个组织内部**没有**找到任何授权记录。
### 🟡 场景 C — 模糊的内部人员活动(Critic 循环演示)
一名拥有合法数据库访问权限的员工在其正常会话结束 4 个多小时后登录——这虽然不能明确断定为恶意行为,但属于异常情况。
这是最重要的演示:置信度**低于 70% 的阈值**,**触发了 SOCweave 的 Critic agent** 模拟重新查询以获取扩展上下文,然后再作最终决定。SOCweave 不仅仅是给出答案——它知道自己何时*不确定*并会如实说明,而不是强行给出一个听起来自信但毫无根据的判定。
## 🎬 演示视频
[▶ 在 YouTube 上观看完整演示](https://youtu.be/jNmnG1klsSE)
## ⚡ 快速预览
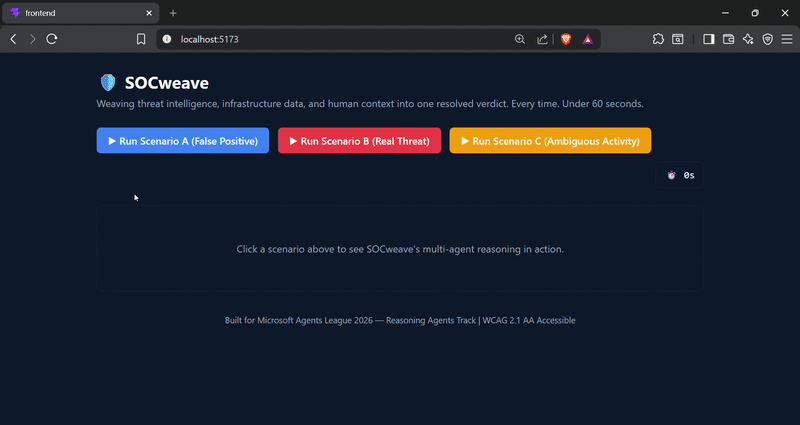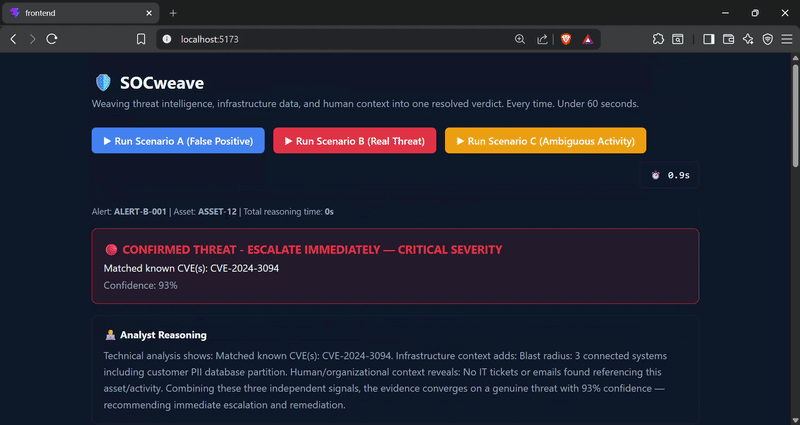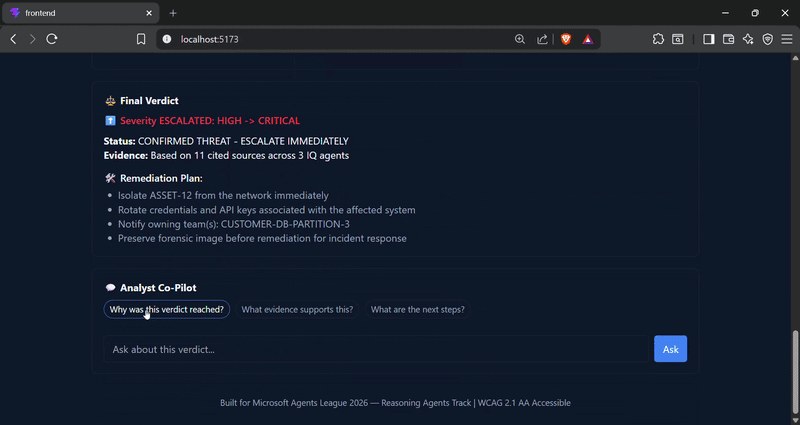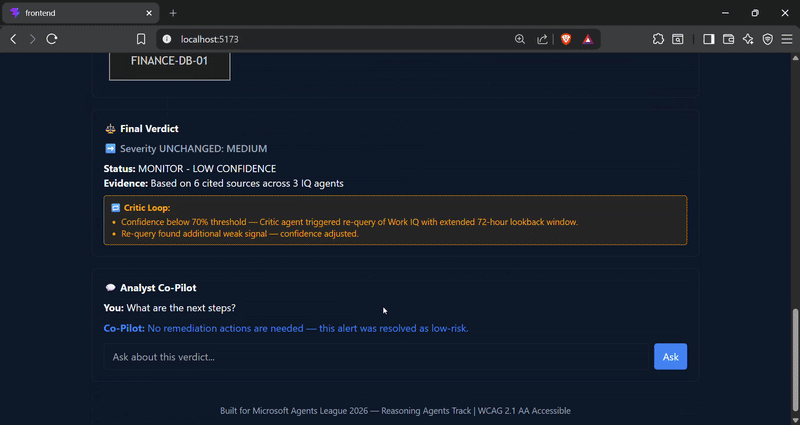
## 📸 截图
**场景 A — 授权的维护(误报,CRITICAL → LOW)**
**场景 B / C — 确认的威胁与模糊活动**

## 🚀 克隆并运行
### 1. 克隆本仓库
```
git clone https://github.com/Pradeep-G369/socweave.git
cd socweave
```
### 2. 一键演示(Git Bash)
```
bash run_demo.sh --scenario=a
bash run_demo.sh --scenario=b
bash run_demo.sh --scenario=c
```
### 3. 完整的交互式 UI
**终端 1 — 后端:**
```
python -m venv .venv
.venv\Scripts\activate # Windows
cd backend
pip install -r requirements.txt
uvicorn main:app --reload --port 8000
```
### 4. API 文档(自动生成)
在后端运行的情况下,访问:
`http://127.0.0.1:8000/docs` — 适用于所有端点的交互式 Swagger UI
**终端 2 — 前端:**
```
cd frontend
npm install
npm run dev
```
打开 **`http://localhost:5173`** 并点击三个场景按钮中的任意一个。
## 🧩 Microsoft IQ 集成
| IQ 层级 | 在 SOCweave 中的作用 |
|---|---|
| **Foundry IQ** | 检索相关的 CVE、MITRE ATT&CK 技术和威胁情报匹配——每一个论断均提供引用 |
| **Fabric IQ** | 对基础架构影响范围、相连系统和数据所有权进行语义本体映射 |
| **Work IQ** | 人类上下文层面——扫描 M365 邮件/工单,以区分授权操作和真实威胁 |
## 🏆 功能 → 评审标准映射
| 功能 | 评审标准 | 权重 |
|---|---|---|
| 带有引用的 Foundry IQ CVE/MITRE 基础支撑 | 准确性与相关性 | 20% |
| 5-agent 推理链 + Critic 自我纠正循环(场景 C) | 推理与多步思考 | 20% |
| 三场景套件(误报、真实威胁、模糊情况) | 创意与原创性 | 15% |
| 推理轨迹、置信度条、分析师推理、Co-Pilot | UX 与展示 | 15% |
| 输入过滤、速率限制、PII 清洗、评估套件 | 可靠性与安全性 | 20% |
| Discord 社区分享 | 社区投票 | 10% |
## ✅ 评估结果
# SOCweave 包含一个自动化评估测试工具,用于针对所有三个场景验证判定结果的准确性。
SOCweave 评估报告
✅ PASS — 场景 A
严重性匹配 : 通过
状态匹配 : 通过
置信度 : 预期 94%,实际 91%(差值:3)
✅ PASS — 场景 B
严重性匹配 : 通过
状态匹配 : 通过
置信度 : 预期 97%,实际 93%(差值:4)
✅ PASS — 场景 C
严重性匹配 : 通过
状态匹配 : 通过
# 置信度 : 预期 68%,实际 65%(差值:3)
结果:3/3 个场景通过
自行运行:
```
cd backend
python eval/run_eval.py
```
## 🧪 单元测试
各个 agent 模块均经过独立单元测试,以在不依赖端到端流水线的情况下验证评分逻辑。
eval/test_agents.py::test_foundry_iq_detects_cve_match PASSED
eval/test_agents.py::test_foundry_iq_no_match_low_signal PASSED
eval/test_agents.py::test_fabric_iq_blast_radius_scoring PASSED
eval/test_agents.py::test_work_iq_approved_ticket_raises_authorization PASSED
eval/test_agents.py::test_work_iq_no_evidence_zero_authorization PASSED
5 passed
自行运行:
```
cd backend
python -m pytest eval/test_agents.py -v
```
## 🔒 数据安全与隐私
所有使用的数据均为 **100% 合成数据**——专为演示目的而捏造,不包含任何真实的 PII、凭证或客户数据。`backend/safety/clean_data.py` 使用 **Microsoft Presidio** 在任何 agent 处理之前,自动从人类上下文数据中清除姓名、电子邮件、电话号码和 IP 地址。
## 🛡️ 输入安全
`backend/safety/sanitize.py` 根据严格的 schema(必填字段、有效的严重性枚举)验证每一个传入的警报,并在开始任何处理之前应用内存速率限制(10 个请求/分钟)。
## ♿ 无障碍访问
SOCweave 符合 **WCAG 2.1 AA** 标准:所有交互元素均具有 ARIA 标签,严重性通过图标 + 文本传达(而非仅通过颜色),置信度更新会通过屏幕阅读器播报,且每个组件都支持键盘导航。
## 🌍 社会影响
通过消除误报引起的调查疲劳,SOCweave 直接解决了分析师的职业倦怠问题——这是在持续处于高警报量环境下的 SOC 团队中普遍存在的一种心理健康隐患。
## 🛠️ 使用的技术
- **Microsoft Foundry IQ, Fabric IQ, Work IQ** — 通过代表真实智能体检索响应的结构化数据进行模拟
- **Python FastAPI** — 多 agent 编排后端
- **React + Vite + Tailwind CSS** — 深色企业级 UI
- **Mermaid.js** — 影响范围图表
- **Microsoft Presidio** — PII 检测与清洗
- **spaCy NLP (语义相似度)** — 为 Analyst Co-Pilot 的问题理解提供支持,完全离线运行
- 使用 **GitHub Copilot** 在 VS Code 中进行 AI 辅助开发
## 🔭 未来工作
- 用实时的 Microsoft Foundry IQ、Fabric 和 Graph API 连接器替换模拟 IQ 数据——请参阅 [INTEGRATION.md](INTEGRATION.md) 获取分步指南
- 将警报历史和分析师反馈持久化存储在数据库中,以便进行持续评估
- 使用 `asyncio.gather()` 并行处理三个 IQ agent 调用以提高吞吐量
- 作为 Hosted Agent 部署在 Foundry Agent Service 中以实现生产级规模
## 🔧 故障排除
| 问题 | 解决方案 |
|---|---|
| `Could not import module "main"` | 首先运行 `cd backend`,然后运行 `uvicorn main:app` |
| `ModuleNotFoundError: No module named 'agent'` | 确保已激活 `.venv`:`.venv\Scripts\activate` |
| `npm error ENOENT package.json` | 首先运行 `cd frontend`,然后运行 `npm run dev` |
| Tailwind 类未生效 | 检查 `tailwind.config.js` 内容路径是否包含 `./src/**/*.{js,jsx}` |
| Mermaid 图表未渲染 | 刷新页面——Mermaid 有时需要二次加载 |
| Presidio 返回 False | 在 `.venv` 中运行 `python -m spacy download en_core_web_lg` |
| 端口 8000 已被占用 | 运行 `netstat -ano \| findstr :8000`,然后运行 `taskkill /PID 标签:AI推理, AV绕过, FastAPI, React, Syscalls, 告警分诊, 多智能体, 威胁情报, 开发者工具, 逆向工具