rvong65/threat-intelligence-assistant
GitHub: rvong65/threat-intelligence-assistant
基于 RAG 架构的威胁情报问答助手,通过强制引用和置信度评分帮助安全分析师有依据地探索 MITRE ATT&CK 和 CISA KEV 数据。
Stars: 1 | Forks: 0
# 威胁情报助手
一个**检索增强生成 (RAG)** 聊天应用程序,可帮助安全分析师以**有依据、有引用、可解释**的答案探索 **MITRE ATT&CK** 和 **CISA 已知被利用漏洞 (KEV)** —— 而非开放网络的推测。
## 🎯 问题与动机
威胁分析师经常需要在 MITRE 技术页面、组织档案、软件条目和 CISA KEV 公告之间来回切换。通用 LLM 在**幻觉出技术 ID、CVE 或归属**时听起来可能很自信 —— 这在安全工作流中是严重的失败模式。
本项目旨在探讨:*一个小型、透明的 RAG pipeline 能否提供快速、对分析师友好且始终关联权威来源的答案?*
**目标:**
- 每一个答案都基于检索到的 MITRE / KEV 上下文
- 要求内联引用并在 UI 中展示来源链接
- 明确评分置信度,并在证据薄弱时选择不作答
- 在浪费检索和 LLM 调用之前拦截离题或模糊的提示
## 🛠️ 技术栈






| 层级 | 本地开发 | 云端部署 |
|-------|-------------------|------------------|
| **UI** | Streamlit (`app.py`) | Streamlit Community Cloud |
| **编排** | LangChain | LangChain |
| **LLM** | Ollama `gemma3:4b` | Groq `llama-3.1-8b-instant` |
| **Embeddings** | Ollama `nomic-embed-text` | HuggingFace `nomic-ai/nomic-embed-text-v1` (固定版本) |
| **向量存储** | FAISS (已提交的索引) | FAISS (已提交的索引) |
| **配置** | Pydantic Settings + `.env` | Streamlit Secrets + 环境变量 |
| **测试** | pytest (49 个测试) | 通过 `validation_matrix.py` 运行相同的 pipeline |
## 📊 数据来源与归属说明
本项目索引了 **MITRE ATT&CK Enterprise** STIX 数据和 **CISA 已知被利用漏洞 (KEV)** 目录。已提交的 FAISS 索引仅基于这些来源构建。
**使用的数据集**(保存在 `data/raw/` 下):
| 文件 | 来源 | 提供的内容 |
|------|--------|------------------|
| `enterprise-attack.json` | [MITRE ATT&CK STIX data](https://github.com/mitre-attack/attack-stix-data) | 技术、子技术、战术、组织 (`G####`)、软件 (`S####`) |
| `known_exploited_vulnerabilities.csv` | [CISA KEV catalog](https://www.cisa.gov/known-exploited-vulnerabilities-catalog) | 正在被利用的 CVE、供应商、产品、修复截止日期 |
**已索引的语料库 (v1.0.0):** 3,306 份文档 → 3,312 个 chunk —— 包含 697 项技术、174 个组织、821 个软件、1,614 条 KEV 条目。
**数据时效性:** 提交的 FAISS 索引是一个**时间点快照** —— 请参阅 [`indices/faiss_index/manifest.json`](indices/faiss_index/manifest.json) 中的 `built_at`(目前为 **2026-06-10**)。MITRE 和 CISA 会定期发布更新。要刷新语料库,请运行 `python scripts/ingest.py --build-index` 并重新提交 `indices/faiss_index/`。
**许可证合规性**
| 数据 | 许可证 / 条款 |
|------|-----------------|
| MITRE ATT&CK | © [The MITRE Corporation](https://attack.mitre.org/)。非排他性、免版税许可证,用于研究、开发和商业用途 —— 参见 [attack-stix-data LICENSE](https://github.com/mitre-attack/attack-stix-data?tab=License-1-ov-file#readme) 和 [ATT&CK Terms of Use](https://attack.mitre.org/resources/terms-of-use/)。在任何副本中均须保留 MITRE 的版权声明。 |
| CISA KEV | [CC0 1.0 Universal](https://www.cisa.gov/sites/default/files/licenses/kev/license.txt) —— 公共领域声明。不授权使用 CISA 标志或 DHS 印章。 |
**运行时使用的模型**(未在本仓库中分发):
| 模型 | 角色 | 许可证 / 致谢 |
|-------|------|--------------------------|
| [nomic-ai/nomic-embed-text-v1](https://huggingface.co/nomic-ai/nomic-embed-text-v1) | 云端查询 embeddings (Streamlit) | [Apache 2.0](https://huggingface.co/nomic-ai/nomic-embed-text-v1) —— 参见 [Nomic Embed technical report (arXiv:2402.01613)](https://arxiv.org/abs/2402.01613) |
| `nomic-embed-text` (Ollama) | 本地索引构建 + 本地开发 embeddings | 与上述属于同一模型家族 |
| `gemma3:4b` (Ollama) | 本地开发 LLM | [Gemma Terms of Use](https://ai.google.dev/gemma/terms) |
| `llama-3.1-8b-instant` (Groq) | 云端演示 LLM | Meta Llama 通过 Groq API 提供 —— [Groq Terms](https://groq.com/terms/) |
本项目与 MITRE、CISA、DHS、Nomic AI 或 Groq 没有任何隶属关系。威胁情报数据仅用于教育和研究目的。请务必根据一手来源验证关键发现。
**原始文件未提交。** 本仓库在 `indices/faiss_index/` 下提供了一个预构建的索引,因此克隆时无需原始数据即可运行。要从头构建,请将文件放置在 `data/raw/` 中:
| 保存为 | 下载 |
|---------|----------|
| `data/raw/enterprise-attack.json` | [enterprise-attack.json](https://raw.githubusercontent.com/mitre-attack/attack-stix-data/master/enterprise-attack/enterprise-attack.json) |
| `data/raw/known_exploited_vulnerabilities.csv` | [known_exploited_vulnerabilities.csv](https://www.cisa.gov/sites/default/files/csv/known_exploited_vulnerabilities.csv) |
或者运行 `python scripts/ingest.py --build-index` —— 当文件缺失时,它会自动下载 `config/settings.py` 中配置的相应 MITRE/CISA URL。
**可选:NVD 丰富(默认索引中不包含)**
代码库支持通过 [NIST NVD API](https://nvd.nist.gov/) 进行*可选的* CVE 详情丰富(`python scripts/ingest.py --build-index --enrich-nvd`)。这**默认关闭**;已提交的索引和实时演示**不**包含 `nvd_cve` 文档。KEV 条目链接到 NVD 页面仅用于提供引用 URL。
## 🏗️ 架构与设计选择
高层请求流 —— 表示层、RAG 编排、检索和模型提供商:
```
flowchart TB
subgraph Client["Client Layer"]
U[Analyst / Demo user]
UI[Streamlit UI
app.py] end subgraph App["Application Layer — src/rag/"] QG[Query guard
scope & intent] MEM[Conversation memory
last N turns] RW[Follow-up rewrite
optional LLM/heuristic] RET[Hybrid retriever
FAISS + entity ID boost] ABS[Abstention gate
pre/post generation] GEN[Grounded generation
mandatory citations] VAL[Citation validation
+ confidence score] end subgraph Data["Data Layer"] FAISS[(FAISS index
indices/faiss_index)] MITRE[MITRE ATT&CK STIX/JSON] KEV[CISA KEV CSV] end subgraph Models["Model Layer"] EMB[Embedding model
Ollama or HuggingFace] LLM[Chat model
Ollama or Groq] end U --> UI UI --> QG QG -->|in scope| MEM MEM --> RW RW --> RET RET --> EMB EMB --> FAISS FAISS --> RET RET --> ABS ABS -->|pass| GEN GEN --> LLM LLM --> VAL VAL --> UI QG -->|out of scope| UI ABS -->|abstain| UI MITRE -. ingest .-> FAISS KEV -. ingest .-> FAISS ``` **关键设计决策:** | 决策 | 理由 | |----------|-----------| | **在仓库中使用预构建的 FAISS 索引** | Streamlit Cloud 不包含 Ollama;在本地构建向量,运行时使用 HF embeddings 查询 | | **实体 ID docstore 查找** | 仅靠语义搜索会遗漏显式 ID(例如 `T1059`);直接查找 + 权重提升可解决分析师风格的查询 | | **硬弃权** | 当检索置信度较低时,宁可不给出答案,也不提供看似合理的幻觉 | | **LLM 生成后进行引用验证** | 标记模型引用但未出现在检索 chunk 中的 ID(在长组织列表中可见的 G0007 限制) | | **双部署配置** | `DEPLOYMENT_PROFILE=local\|cloud` 无需更改代码即可切换 LLM/embedding 提供商 | | **固定 HF embed 版本** | 避免每次冷启动时不知不觉地执行新的远程建模代码 | ### 开发历程 ``` flowchart LR A[Ingestion pipeline
MITRE + KEV + groups/software] --> B[FAISS index
3,312 chunks] B --> C[RAG core
retrieve → generate → cite] C --> D[Streamlit UI
chat + sidebar sources] D --> E[Responsible AI
guard · abstention · confidence] E --> F[Retrieval tuning
ID boost · KEV rerank] F --> G[Cloud profile
Groq + HuggingFace] G --> H[Validation matrix
11 PASS / 1 WARN / 0 FAIL] H --> I[GitHub + Streamlit deploy
MVP] ``` ## 🚀 在线演示 **[▶ 在 Streamlit Cloud 中打开实时应用](https://threat-intelligence-rag-assistant.streamlit.app/)** **截图** 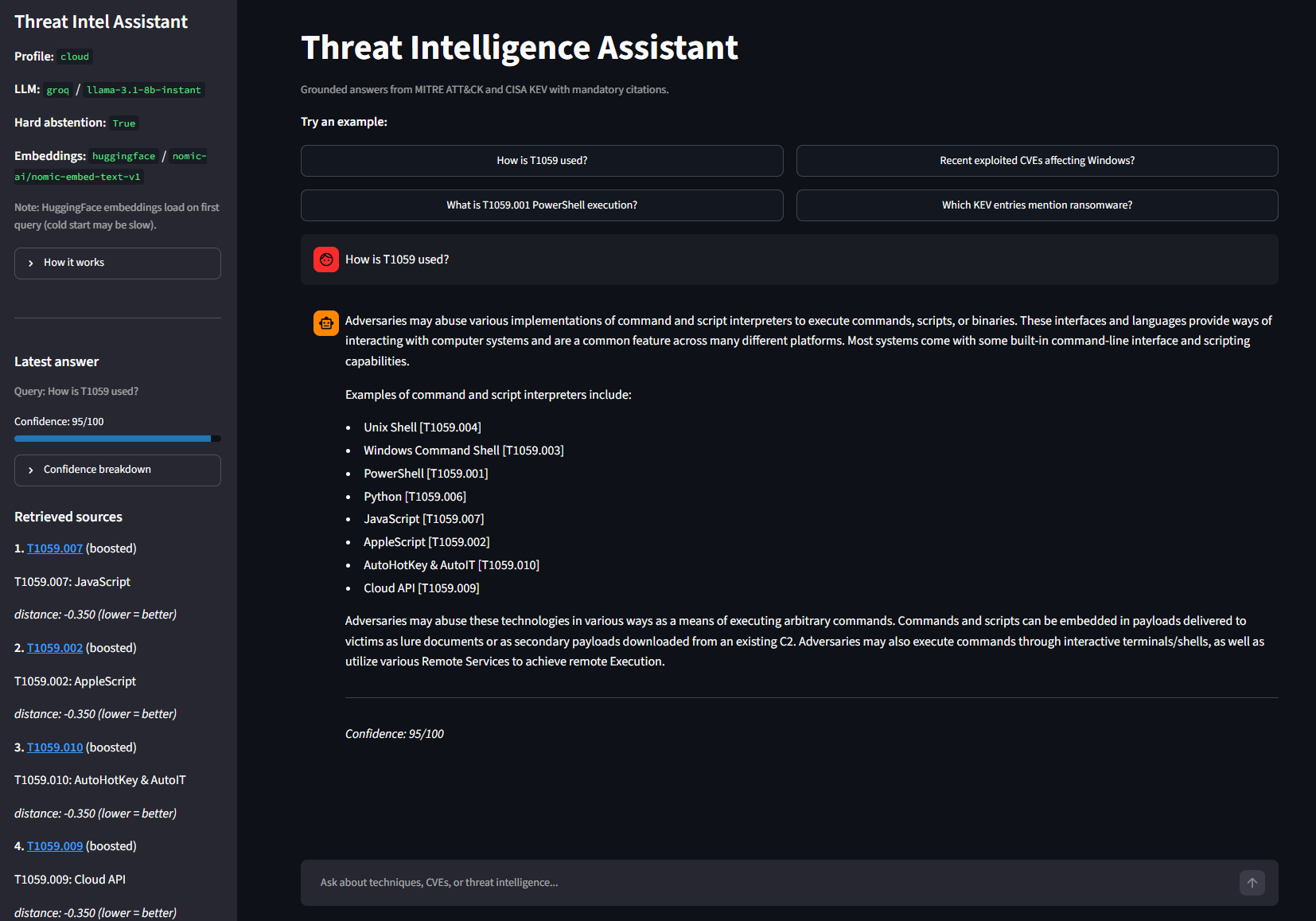 *说明性示例 —— 答案基于检索到的 MITRE/KEV chunk;措辞和结果可能有所不同。引用和侧边栏来源反映了检索 pipeline 的情况。* 或者在本地运行: ``` streamlit run app.py ``` ## 快速开始 ### 前置条件 - Python 3.11+ - **默认(云端):** 环境变量或 Streamlit Secrets 中的 `GROQ_API_KEY` —— 与 `.env.example` 一致 - **本地 Ollama 路径:** 按照 `.env.example` 底部的本地配置块编辑 `.env`(包含 `nomic-embed-text` 和 `gemma3:4b` 的 [Ollama](https://ollama.com/),需约 8 GiB RAM) ### 安装设置 ``` git clone https://github.com/rvong65/threat-intelligence-assistant.git cd threat-intelligence-assistant python -m venv .venv .\.venv\Scripts\activate pip install -r requirements.txt copy .env.example .env # 云端:在您的环境(或在部署时的 Streamlit Secrets)中设置 GROQ_API_KEY。 # 本地:将 .env 切换为 .env.example 底部注释块中的 Ollama 值。 ``` **首次构建索引**(如果不使用已提交的索引): ``` python scripts/ingest.py --build-index ``` **运行应用:** ``` streamlit run app.py ``` **运行测试:** ``` pytest -v python scripts/smoke_test.py python scripts/validation_matrix.py ``` ### Streamlit Cloud(供维护者参考) 主文件:**`app.py`**。在 **Settings → Secrets** 中,镜像 `.env.example`(云端配置)。最低要求: ``` GROQ_API_KEY = "your-groq-api-key" ``` 所有其他 key 均已与仓库默认值匹配(`DEPLOYMENT_PROFILE=cloud`,Groq LLM,HuggingFace embeddings)。仅在覆盖默认值时才需要添加显式密钥。 最终用户无需提供 API key;凭证仅由维护者配置。 ## ✨ 功能 - **有依据的聊天** —— 答案仅从检索到的 MITRE ATT&CK + CISA KEV chunk 中生成 - **强制引用** —— 内联的 `[T1059]`、`[G0007]`、`[CVE-…]` 以及侧边栏来源链接 - **置信度评分 (0–100)** —— 透明的明细(检索、覆盖率、引用匹配度) - **查询守卫** —— 拦截问候、天气和模糊的离题提示 - **硬弃权** —— 当证据低于阈值时不给出推测性答案 - **引用验证** —— 标记模型输出中未经验证的 ID - **元数据感知检索** —— 实体 ID 提升、KEV 重排序、关键词提升(如 `Windows` 等) - **多轮记忆** —— 简短的追问(例如 *PowerShell 呢?*) - **管理员数据摄入面板** —— 仅限本地的语料库验证和索引重建 - **Groq 错误用户体验** —— 友好的限流 / 身份验证消息(聊天中不显示堆栈跟踪) **验证基准 (Groq 云端):** 12 个检查风格的测试用例中包含 11 个 PASS · 1 个 WARN · 0 个 FAIL。 **已知 WARN:** 类似 `G0007` 的组织查询可能会列出许多技术,而 top-k 检索只能验证其中一部分 —— 答案仍然有用;出现引用警告是预期行为。 | | 本地 `gemma3:4b` | 云端 Groq `llama-3.1-8b-instant` | |--|-------------------|-----------------------------------| | 测试矩阵 | ~5 PASS / ~7 WARN | **11 PASS / 1 WARN** | | 延迟 | 在 CPU 上较慢 | 快速(托管 API) | | 最适用途 | 开发 / 低内存 | 演示 / 生产级 UI | ## 🛡️ 安全考量 这是一个**决策支持**工具,而不是自主的威胁狩猎或事件响应自动化。 | 原则 | 实现 | |-----------|----------------| | **依据** | LLM 提示词被限制在检索到的上下文中 | | **来源** | 每一个声明都应引用检索结果中的 `source_id` | | **谦逊** | 低置信度 → 免责声明或硬弃权 | | **范围控制** | 查询守卫拒绝非威胁情报的提示 | | **透明度** | 侧边栏显示检索到的 chunk、距离和置信度公式 | | **隐私(云端)** | 问题 + 检索到的上下文将发送至 Groq 进行推理;不使用用户的 API key | | **已知差距** | 长的组织技术列表与 top-k chunk 的对比 → 引用警告(已记录,v1.1 目标) | 请务必根据主要的一手 MITRE / NVD / 供应商来源验证关键发现。 ## 📈 项目状态与构建日志 | 步骤 | 重点 | |------|-------| | **1** | 数据摄入 —— MITRE ATT&CK、CISA KEV、组织和软件加载器 | | **2** | RAG pipeline —— FAISS 索引、检索、引用、置信度评分 | | **3** | Streamlit UI —— 聊天、侧边栏来源、对话记忆 | | **4** | 负责任的 AI —— 查询守卫、硬弃权、引用验证 | | **5** | 检索调优 —— 实体 ID 提升、KEV 检测、元数据重排序 | | **6** | 云端集成 —— Groq LLM、HuggingFace embeddings、错误用户体验 | | **7** | 验证与部署 —— 矩阵基准、GitHub 仓库、Streamlit Cloud | **当前状态:** ✅ MVP 完成 —— 可随时进行公开演示部署 ## 📁 仓库结构 ``` threat-intelligence-assistant/ ├── app.py # Streamlit entry point ├── config/ # Pydantic settings, deployment profiles ├── src/ │ ├── embeddings/ # Ollama / HuggingFace embedding factory │ ├── ingestion/ # Chunking, normalization │ ├── llm/ # Ollama / Groq LLM factory, error mapping │ ├── loaders/ # MITRE, KEV, groups/software (optional NVD at ingest) │ ├── models/ # Document schema │ ├── rag/ # Chain, retriever, guard, citations, confidence │ └── vectorstore/ # FAISS load/build ├── scripts/ │ ├── ingest.py # Download, validate, build index │ ├── smoke_test.py # Pipeline smoke test │ └── validation_matrix.py ├── indices/faiss_index/ # Committed FAISS index (index.faiss, index.pkl, manifest.json) ├── tests/ # pytest suite (49 tests) ├── data/raw/ # Gitignored — downloaded at ingest ├── data/processed/ # Gitignored — regenerated at ingest ├── requirements.txt ├── .env.example └── LICENSE # MIT ``` ## 📄 许可证 **MIT License** —— 参见 [LICENSE](LICENSE)。 MITRE ATT&CK([许可证](https://github.com/mitre-attack/attack-stix-data?tab=License-1-ov-file#readme))和 CISA KEV([CC0 1.0](https://www.cisa.gov/sites/default/files/licenses/kev/license.txt))仍受其各自条款的约束。本项目与 MITRE、CISA、DHS 或 Groq 没有任何隶属关系。 ## 🤝 联系方式 / 后续计划 欢迎提供反馈、建议以及使命一致的合作。 **未来可能的探索方向** *(不承诺时间线)*: - 针对完整的组织/软件文档文本进行引用验证(修复 G0007 风格的警告) - 在数据摄入时提供可选的 NVD 丰富(默认索引中不包含) - 用于解放双手分析师查询的语音输入 / TTS - 扩展的验证矩阵以及在 push 时触发的 CI 工作流
app.py] end subgraph App["Application Layer — src/rag/"] QG[Query guard
scope & intent] MEM[Conversation memory
last N turns] RW[Follow-up rewrite
optional LLM/heuristic] RET[Hybrid retriever
FAISS + entity ID boost] ABS[Abstention gate
pre/post generation] GEN[Grounded generation
mandatory citations] VAL[Citation validation
+ confidence score] end subgraph Data["Data Layer"] FAISS[(FAISS index
indices/faiss_index)] MITRE[MITRE ATT&CK STIX/JSON] KEV[CISA KEV CSV] end subgraph Models["Model Layer"] EMB[Embedding model
Ollama or HuggingFace] LLM[Chat model
Ollama or Groq] end U --> UI UI --> QG QG -->|in scope| MEM MEM --> RW RW --> RET RET --> EMB EMB --> FAISS FAISS --> RET RET --> ABS ABS -->|pass| GEN GEN --> LLM LLM --> VAL VAL --> UI QG -->|out of scope| UI ABS -->|abstain| UI MITRE -. ingest .-> FAISS KEV -. ingest .-> FAISS ``` **关键设计决策:** | 决策 | 理由 | |----------|-----------| | **在仓库中使用预构建的 FAISS 索引** | Streamlit Cloud 不包含 Ollama;在本地构建向量,运行时使用 HF embeddings 查询 | | **实体 ID docstore 查找** | 仅靠语义搜索会遗漏显式 ID(例如 `T1059`);直接查找 + 权重提升可解决分析师风格的查询 | | **硬弃权** | 当检索置信度较低时,宁可不给出答案,也不提供看似合理的幻觉 | | **LLM 生成后进行引用验证** | 标记模型引用但未出现在检索 chunk 中的 ID(在长组织列表中可见的 G0007 限制) | | **双部署配置** | `DEPLOYMENT_PROFILE=local\|cloud` 无需更改代码即可切换 LLM/embedding 提供商 | | **固定 HF embed 版本** | 避免每次冷启动时不知不觉地执行新的远程建模代码 | ### 开发历程 ``` flowchart LR A[Ingestion pipeline
MITRE + KEV + groups/software] --> B[FAISS index
3,312 chunks] B --> C[RAG core
retrieve → generate → cite] C --> D[Streamlit UI
chat + sidebar sources] D --> E[Responsible AI
guard · abstention · confidence] E --> F[Retrieval tuning
ID boost · KEV rerank] F --> G[Cloud profile
Groq + HuggingFace] G --> H[Validation matrix
11 PASS / 1 WARN / 0 FAIL] H --> I[GitHub + Streamlit deploy
MVP] ``` ## 🚀 在线演示 **[▶ 在 Streamlit Cloud 中打开实时应用](https://threat-intelligence-rag-assistant.streamlit.app/)** **截图**  *说明性示例 —— 答案基于检索到的 MITRE/KEV chunk;措辞和结果可能有所不同。引用和侧边栏来源反映了检索 pipeline 的情况。* 或者在本地运行: ``` streamlit run app.py ``` ## 快速开始 ### 前置条件 - Python 3.11+ - **默认(云端):** 环境变量或 Streamlit Secrets 中的 `GROQ_API_KEY` —— 与 `.env.example` 一致 - **本地 Ollama 路径:** 按照 `.env.example` 底部的本地配置块编辑 `.env`(包含 `nomic-embed-text` 和 `gemma3:4b` 的 [Ollama](https://ollama.com/),需约 8 GiB RAM) ### 安装设置 ``` git clone https://github.com/rvong65/threat-intelligence-assistant.git cd threat-intelligence-assistant python -m venv .venv .\.venv\Scripts\activate pip install -r requirements.txt copy .env.example .env # 云端:在您的环境(或在部署时的 Streamlit Secrets)中设置 GROQ_API_KEY。 # 本地:将 .env 切换为 .env.example 底部注释块中的 Ollama 值。 ``` **首次构建索引**(如果不使用已提交的索引): ``` python scripts/ingest.py --build-index ``` **运行应用:** ``` streamlit run app.py ``` **运行测试:** ``` pytest -v python scripts/smoke_test.py python scripts/validation_matrix.py ``` ### Streamlit Cloud(供维护者参考) 主文件:**`app.py`**。在 **Settings → Secrets** 中,镜像 `.env.example`(云端配置)。最低要求: ``` GROQ_API_KEY = "your-groq-api-key" ``` 所有其他 key 均已与仓库默认值匹配(`DEPLOYMENT_PROFILE=cloud`,Groq LLM,HuggingFace embeddings)。仅在覆盖默认值时才需要添加显式密钥。 最终用户无需提供 API key;凭证仅由维护者配置。 ## ✨ 功能 - **有依据的聊天** —— 答案仅从检索到的 MITRE ATT&CK + CISA KEV chunk 中生成 - **强制引用** —— 内联的 `[T1059]`、`[G0007]`、`[CVE-…]` 以及侧边栏来源链接 - **置信度评分 (0–100)** —— 透明的明细(检索、覆盖率、引用匹配度) - **查询守卫** —— 拦截问候、天气和模糊的离题提示 - **硬弃权** —— 当证据低于阈值时不给出推测性答案 - **引用验证** —— 标记模型输出中未经验证的 ID - **元数据感知检索** —— 实体 ID 提升、KEV 重排序、关键词提升(如 `Windows` 等) - **多轮记忆** —— 简短的追问(例如 *PowerShell 呢?*) - **管理员数据摄入面板** —— 仅限本地的语料库验证和索引重建 - **Groq 错误用户体验** —— 友好的限流 / 身份验证消息(聊天中不显示堆栈跟踪) **验证基准 (Groq 云端):** 12 个检查风格的测试用例中包含 11 个 PASS · 1 个 WARN · 0 个 FAIL。 **已知 WARN:** 类似 `G0007` 的组织查询可能会列出许多技术,而 top-k 检索只能验证其中一部分 —— 答案仍然有用;出现引用警告是预期行为。 | | 本地 `gemma3:4b` | 云端 Groq `llama-3.1-8b-instant` | |--|-------------------|-----------------------------------| | 测试矩阵 | ~5 PASS / ~7 WARN | **11 PASS / 1 WARN** | | 延迟 | 在 CPU 上较慢 | 快速(托管 API) | | 最适用途 | 开发 / 低内存 | 演示 / 生产级 UI | ## 🛡️ 安全考量 这是一个**决策支持**工具,而不是自主的威胁狩猎或事件响应自动化。 | 原则 | 实现 | |-----------|----------------| | **依据** | LLM 提示词被限制在检索到的上下文中 | | **来源** | 每一个声明都应引用检索结果中的 `source_id` | | **谦逊** | 低置信度 → 免责声明或硬弃权 | | **范围控制** | 查询守卫拒绝非威胁情报的提示 | | **透明度** | 侧边栏显示检索到的 chunk、距离和置信度公式 | | **隐私(云端)** | 问题 + 检索到的上下文将发送至 Groq 进行推理;不使用用户的 API key | | **已知差距** | 长的组织技术列表与 top-k chunk 的对比 → 引用警告(已记录,v1.1 目标) | 请务必根据主要的一手 MITRE / NVD / 供应商来源验证关键发现。 ## 📈 项目状态与构建日志 | 步骤 | 重点 | |------|-------| | **1** | 数据摄入 —— MITRE ATT&CK、CISA KEV、组织和软件加载器 | | **2** | RAG pipeline —— FAISS 索引、检索、引用、置信度评分 | | **3** | Streamlit UI —— 聊天、侧边栏来源、对话记忆 | | **4** | 负责任的 AI —— 查询守卫、硬弃权、引用验证 | | **5** | 检索调优 —— 实体 ID 提升、KEV 检测、元数据重排序 | | **6** | 云端集成 —— Groq LLM、HuggingFace embeddings、错误用户体验 | | **7** | 验证与部署 —— 矩阵基准、GitHub 仓库、Streamlit Cloud | **当前状态:** ✅ MVP 完成 —— 可随时进行公开演示部署 ## 📁 仓库结构 ``` threat-intelligence-assistant/ ├── app.py # Streamlit entry point ├── config/ # Pydantic settings, deployment profiles ├── src/ │ ├── embeddings/ # Ollama / HuggingFace embedding factory │ ├── ingestion/ # Chunking, normalization │ ├── llm/ # Ollama / Groq LLM factory, error mapping │ ├── loaders/ # MITRE, KEV, groups/software (optional NVD at ingest) │ ├── models/ # Document schema │ ├── rag/ # Chain, retriever, guard, citations, confidence │ └── vectorstore/ # FAISS load/build ├── scripts/ │ ├── ingest.py # Download, validate, build index │ ├── smoke_test.py # Pipeline smoke test │ └── validation_matrix.py ├── indices/faiss_index/ # Committed FAISS index (index.faiss, index.pkl, manifest.json) ├── tests/ # pytest suite (49 tests) ├── data/raw/ # Gitignored — downloaded at ingest ├── data/processed/ # Gitignored — regenerated at ingest ├── requirements.txt ├── .env.example └── LICENSE # MIT ``` ## 📄 许可证 **MIT License** —— 参见 [LICENSE](LICENSE)。 MITRE ATT&CK([许可证](https://github.com/mitre-attack/attack-stix-data?tab=License-1-ov-file#readme))和 CISA KEV([CC0 1.0](https://www.cisa.gov/sites/default/files/licenses/kev/license.txt))仍受其各自条款的约束。本项目与 MITRE、CISA、DHS 或 Groq 没有任何隶属关系。 ## 🤝 联系方式 / 后续计划 欢迎提供反馈、建议以及使命一致的合作。 **未来可能的探索方向** *(不承诺时间线)*: - 针对完整的组织/软件文档文本进行引用验证(修复 G0007 风格的警告) - 在数据摄入时提供可选的 NVD 丰富(默认索引中不包含) - 用于解放双手分析师查询的语音输入 / TTS - 扩展的验证矩阵以及在 push 时触发的 CI 工作流
标签:AI风险缓解, FAISS, Kubernetes, LangChain, RAG, Streamlit, 人工智能, 威胁情报, 开发者工具, 用户模式Hook绕过, 访问控制, 轻量级, 逆向工具