Sam-sid1402/Real-Time-Fraud-Detection
GitHub: Sam-sid1402/Real-Time-Fraud-Detection
该项目是一个基于自动化机器学习的实时信用卡欺诈检测系统,涵盖从特征工程、模型选择到 API 部署的完整 pipeline。
Stars: 0 | Forks: 0
# 实时欺诈检测 API
这是一个用于检测潜在欺诈性信用卡交易的端到端自动化机器学习项目。该项目包括数据预处理、特征工程、自动化模型选择、模型评估、SHAP 可解释性、业务决策引擎,以及用于批量欺诈预测的 FastAPI 应用程序。
在训练期间,会使用交叉验证指标和 Optuna 自动训练、评估和比较多个机器学习模型。然后选择表现最佳的模型,并将其部署为生产环境的欺诈检测 pipeline。
该 API 接收原始交易记录,应用与训练时相同的特征工程逻辑,使用选定的模型生成欺诈概率,并为每笔交易返回业务决策。
## 项目概述
欺诈检测是一个高度不平衡的分类问题,其中欺诈交易仅占所有支付活动的一小部分。本项目展示了一个完整的自动化机器学习工作流,可以作为实时欺诈检测系统的后端。
主要功能包括:
- 自动化模型比较和选择
- 从原始交易数据中进行特征工程
- 欺诈概率预测
- 基于 SHAP 的模型可解释性
- 业务决策引擎
- FastAPI 部署
- Docker 容器化
最终的 API 返回:
- 欺诈概率
- 二元欺诈预测
- 风险评分
- 风险等级
- 建议措施
决策引擎使用自定义阈值 `0.65`,使系统在标记高风险交易时更加保守,有助于在保持强大欺诈检测性能的同时减少误报。
## 项目结构
```
FRAUD_DETECTION_PROJECT/
│
├── app/
│ ├── main.py # FastAPI application
│ └── test_api_from_csv.py # Local API test script using CSV data
│
├── data/
│ ├── raw/
│ │ ├── fraudTrain.csv # Raw training data
│ │ └── fraudTest.csv # Raw test data
│ │
│ └── processed/
│ ├── X_test.csv # Processed test features
│ └── y_test.csv # Test labels
│
├── model/
│ └── best_fraud_pipeline.pkl # Trained ML pipeline
│
├── notebooks/
│ ├── data.ipynb # Data cleaning, EDA, feature engineering, training
│ ├── live_inference_sim.ipynb # Inference simulation
│ └── SHAP_EVAL.ipynb # SHAP model interpretation
│
├── src/
│ ├── cleaning_data.py # Cleaning helper functions
│ ├── decision_engine.py # Risk scoring and business action logic
│ └── feature_engineering.py # Feature engineering pipeline
│
├── requirements.txt
├── Dockerfile
├── .dockerignore
└── README.md
```
## 主要功能
### 机器学习 Pipeline
本项目使用训练好的 ML pipeline,保存为:
```
model/best_fraud_pipeline.pkl
```
该模型在启动时由 FastAPI 应用程序加载。
### 特征工程
特征工程模块创建交易级别和客户级别的特征,包括:
- 交易金额
- 客户平均历史交易金额
- 相对客户历史记录的金额比较
- 交易小时
- 夜间交易标志
- 首次交易标志
- 客户年龄
- 商家频率
- 职业频率
- 性别编码
- 距离上次交易的时间
- 类别
- 使用经纬度计算的客户与商家之间的距离
### 决策引擎
决策引擎将原始的模型概率转换为实际的欺诈决策。
| 欺诈概率 | 风险等级 | 操作 |
|---:|---|---|
| `< 0.30` | 低 | `approve` |
| `0.30 - 0.65` | 中 | `manual_review` |
| `>= 0.65` | 高 | `block_or_review` |
当前阈值为:
```
THRESHOLD = 0.65
```
## API Endpoints
### 根 Endpoint
```
GET /
```
返回基本的 API 状态。
示例响应:
```
{
"message": "Fraud Detection API is running.",
"model_loaded": true,
"threshold": 0.65
}
```
### 健康检查
```
GET /health
```
返回模型加载状态和模型路径。
示例响应:
```
{
"status": "ok",
"model_loaded": true,
"model_path": "/app/model/best_fraud_pipeline.pkl"
}
```
### 批量预测
```
POST /predict_batch
```
接收原始交易列表并返回带有风险决策的预测。
必需的输入列:
```
trans_date_trans_time
cc_num
merchant
category
amt
gender
lat
long
job
dob
merch_lat
merch_long
```
如果存在 `first`、`last`、`city`、`street`、`city_pop` 和 `Unnamed: 0` 等可选列,系统会自动将其删除。
示例请求:
```
{
"transactions": [
{
"trans_num": "example_transaction_001",
"trans_date_trans_time": "2020-06-21 12:14:25",
"cc_num": 2291163933867244,
"merchant": "fraud_Kirlin and Sons",
"category": "personal_care",
"amt": 2.86,
"gender": "M",
"lat": 33.9659,
"long": -80.9355,
"job": "Mechanical engineer",
"dob": "1968-03-19",
"merch_lat": 33.986391,
"merch_long": -81.200714
}
]
}
```
示例响应:
```
{
"total_transactions": 1,
"threshold": 0.65,
"predictions": [
{
"trans_num": "example_transaction_001",
"trans_date_trans_time": "2020-06-21 12:14:25",
"cc_num": 2291163933867244,
"merchant": "fraud_Kirlin and Sons",
"category": "personal_care",
"amt": 2.86,
"fraud_probability": 0.00003,
"prediction": 0,
"risk_score": 0,
"risk_level": "low",
"action": "approve"
}
]
}
```
## 在本地运行
### 1. 克隆仓库
```
git clone
cd FRAUD_DETECTION_PROJECT
```
### 2. 创建虚拟环境
```
python -m venv venv
source venv/bin/activate
```
### 3. 安装依赖项
```
pip install --upgrade pip
pip install -r requirements.txt
```
### 4. 启动 API
```
uvicorn app.main:app --reload
```
API 将在以下地址提供:
```
http://127.0.0.1:8000
```
交互式 API 文档:
```
http://127.0.0.1:8000/docs
```
## 从 CSV 测试 API
在本地启动 API 后,运行:
```
python app/test_api_from_csv.py
```
此脚本从以下位置读取示例交易数据:
```
data/raw/fraudTest.csv
```
然后它将前 100 行发送到:
```
http://127.0.0.1:8000/predict_batch
```
## Docker 用法
### 1. 构建 Docker 镜像
```
docker build -t fraud-detection-api .
```
### 2. 运行容器
```
docker run -p 8000:8000 fraud-detection-api
```
### 3. 打开 API 文档
```
http://localhost:8000/docs
```
### 4. 检查 API 健康状况
```
curl http://localhost:8000/health
```
## Docker 重要提示
Docker 镜像要求训练好的模型文件存在于:
```
model/best_fraud_pipeline.pkl
```
如果缺少此文件,API 仍会启动,但预测请求将返回错误,因为无法加载模型。
默认情况下,大型原始数据集会通过 `.dockerignore` 被排除在 Docker 之外。这使得镜像体积更小。Docker 镜像旨在用于提供已训练模型的预测服务,而不是用于重新训练模型。
## 模型解释
### SHAP 摘要图
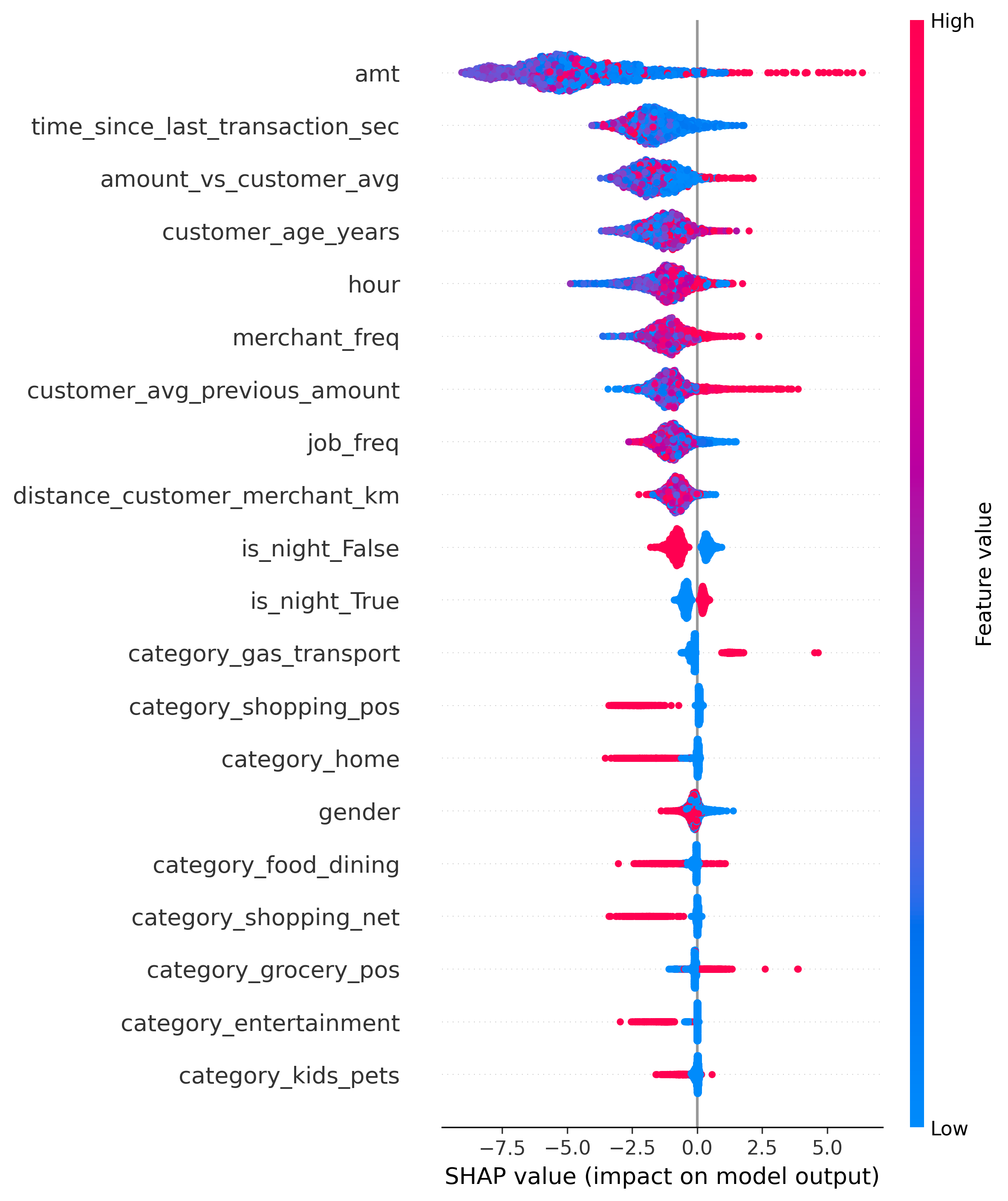
该模型主要依赖于:
- 交易金额
- amount_vs_customer_avg
- customer_avg_previous_amount
- 商家频率
- 交易时间特征
### SHAP 特征重要性
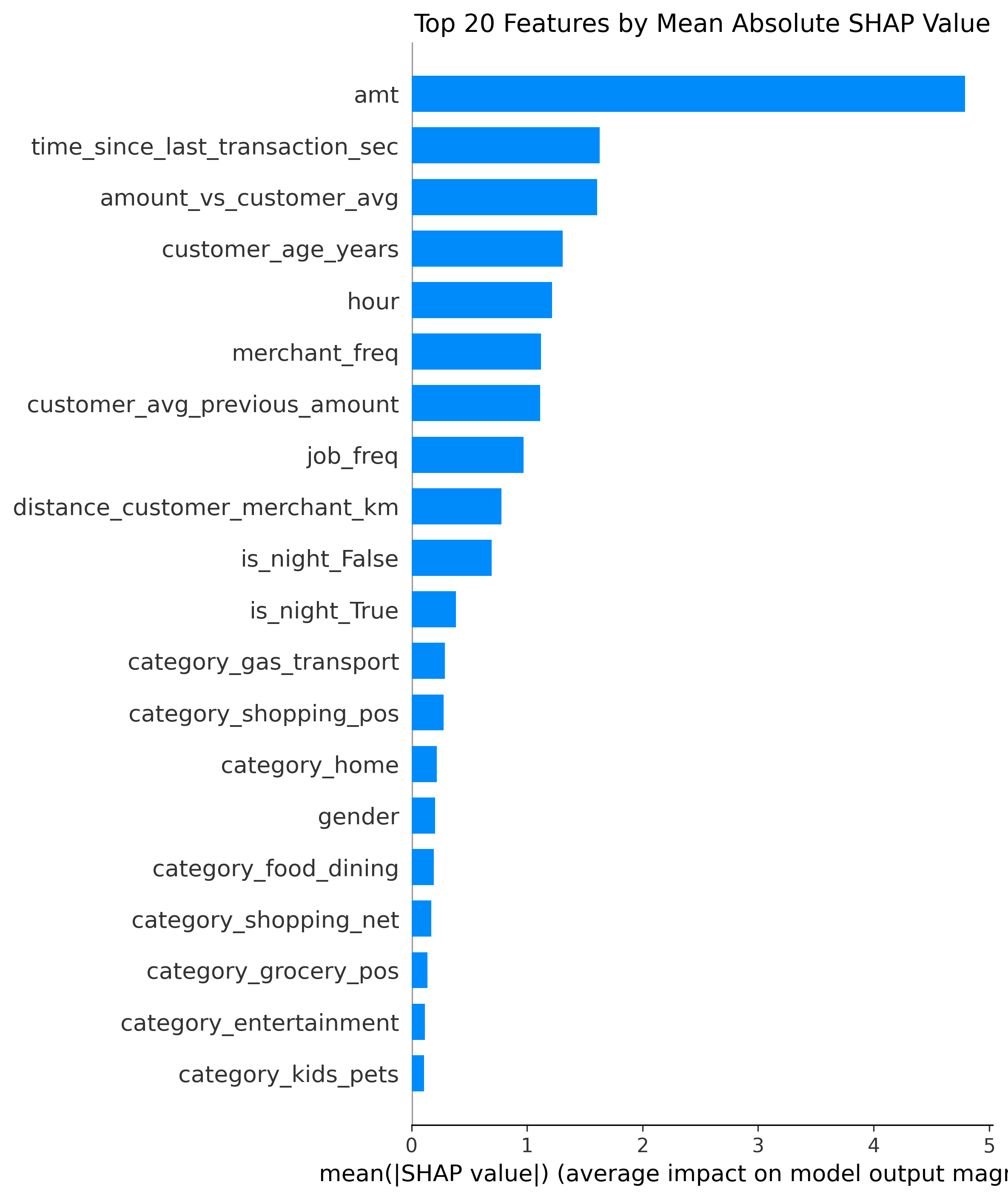
交易金额和客户消费行为是最强的欺诈指标。
更多的 SHAP 分析包含在:
```
notebooks/SHAP_EVAL.ipynb
```
此 notebook 用于了解哪些工程化特征对欺诈预测的影响最大。
SHAP 未包含在生产环境的 `requirements.txt` 中,因为它用于模型分析,而不是用于通过 API 提供预测服务。
## 使用的技术
- Python
- pandas
- NumPy
- scikit-learn
- XGBoost
- FastAPI
- Pydantic
- Uvicorn
- Joblib
- Docker
## 作者
Semyon Sidorov
标签:Apex, AutoML, AV绕过, Docker, FastAPI, 安全防御评估, 机器学习, 模型可解释性, 欺诈检测, 请求拦截, 逆向工具