cuihuan/awesome-ai-gateway
GitHub: cuihuan/awesome-ai-gateway
一个精选 AI 网关与 LLM 代理对比目录,通过成本、安全、合规等维度的可复现基准和决策树帮助开发者与企业选型。
Stars: 20 | Forks: 5
# Awesome AI Gateway [](https://awesome.re)
[](https://github.com/cuihuan/awesome-ai-gateway/stargazers)
[](BENCHMARKS.md)
[](.github/workflows/daily-update.yml)
_Built the hard way: **I burned $788 on AI coding in a single day** — one flagship model ate 78% of it, just because I'd defaulted everything to the priciest option. So I mapped the whole gateway landscape. → [the story](#why-this-exists)_
**Languages:** English · [简体中文](README.zh-CN.md)
## Which gateway should I use?
### ✅ Why trust this list
- **Independent — no vendor money, no affiliate links, CC0.** Unlike affiliate-driven relay "rankings," nobody pays to appear here.
- **Reproducible, not asserted.** Every cost cell is computed from [open pricing data](data/models.json) by a [unit-tested script](scripts/cost_calc.py); stars refresh daily via CI.
- **Honest about risk.** We disclose CVEs, label archived/stale projects, and [exclude gray-market relays](#how-to-choose-safely) — with the research to back it.
## How to choose safely
**Start by matching the gateway's trust level to your data's sensitivity** — this one call decides most of the rest:
| Your data | Route it to | Don't |
|---|---|---|
| 🔴 **Secrets / regulated** (PII, PHI, financial, source code, keys) | First-party **direct + ZDR** (Azure / Bedrock / Vertex) or a gateway **self-hosted in your VPC** | …send it through *any* third-party relay — full stop |
| 🟡 **Internal / business** | Compliant hosted (Cloudflare, Vercel, Portkey) **or** self-hosted (LiteLLM, Bifrost) | …use an unvetted relay; get ZDR in writing |
| 🟢 **Low-stakes / public / throwaway** (demos, scraped public text) | Cheapest wins — a gray relay can even be *economically* rational here | …skip the [canary test](#how-to-choose-safely): assume model-swap + data-harvest until you've proven otherwise |
Then, whatever tier you're in:
1. **Check the markup.** Marketplaces charge 0–6% — for high volume, self-hosting or 0%-markup gateways (Vercel, Helicone cloud) pay for themselves fast.
2. **Verify model fidelity (canary-diff test).** Some relays silently downgrade or quantize models. Send fixed "canary" prompts — a known-hard reasoning question plus a tokenizer/fingerprint probe — through the gateway *and* direct to the provider, then **diff the outputs** — [`scripts/canary_check.py`](scripts/canary_check.py) automates exactly this (relay vs. official → a verdict you can attach to a [watch-list report](https://github.com/cuihuan/awesome-ai-gateway/issues/new?template=report-relay.yml)). 2026 research found model-identity failures in ~46% of audited relays ([arXiv:2603.01919](https://arxiv.org/abs/2603.01919)). Community monitors [apiranking.com](https://apiranking.com) and [rate.linux.do](https://rate.linux.do) (browser-only) track relay authenticity/stability — usable as *signal* if you must vet one, but **listing there is not endorsement, and this list includes none of them.**
3. **Mind data flow.** Every gateway sees your prompts. For sensitive data: self-host, or require ZDR (zero data retention) in writing.
4. **License check before embedding.** new-api is AGPL-3.0; LiteLLM has an enterprise-licensed directory; "open core" ≠ everything free.
5. **Project health.** Star count ≠ maintenance. Check last release date — several once-popular gateways (BricksLLM, Glide, RouteLLM) are effectively unmaintained; this list labels them.
6. **Avoid gray-market relays** reselling reverse-engineered or stolen-quota access. Beyond account-ban risk, 2026 research caught relays serving poisoned models and exfiltrating planted secrets ([*Your Agent Is Mine*](https://arxiv.org/abs/2604.08407)) — and the most-visible relay "rankings" are often paid press releases or carry affiliate links. Account bans and data leaks are your risk, not theirs. **Caught one swapping models, harvesting data, or vanishing with your balance? [Report it — with evidence](https://github.com/cuihuan/awesome-ai-gateway/issues/new?template=report-relay.yml) — and we'll build the community watch list together.**
## FAQ
**What is an AI gateway (LLM gateway)?**
A proxy between your code and LLM providers: one OpenAI-compatible endpoint and key for many models, adding routing, failover, caching, rate limits, cost tracking and guardrails. See the [intro](#which-gateway-should-i-use).
**AI gateway vs LLM router — what's the difference?**
A *router* decides *which model* gets each request (e.g. cheap vs flagship); a *gateway* is the full proxy layer (auth, caching, observability, guardrails) that usually *includes* routing. See [smart routing](#-smart-routing--model-selection).
**What's the best open-source AI gateway?**
[LiteLLM](https://github.com/BerriAI/litellm) is the default for breadth (Python, 100+ providers). For raw performance pick [Bifrost](https://github.com/maximhq/bifrost) (Go); for enterprise K8s pick [Kong](https://github.com/Kong/kong) or [Higress](https://github.com/higress-group/higress). Full list under [self-hosted](#-self-hosted-open-source).
**LiteLLM vs OpenRouter — which should I use?**
OpenRouter is hosted (zero ops, ~5.5% fee, 400+ models); LiteLLM is self-hosted (your keys, your infra, $0 markup). Hosted to start, self-host when volume justifies it. Cost math in the [evaluation set](BENCHMARKS.md#part-3--real-world-token-cost-computed).
**What's the cheapest way to call many LLMs?**
For zero ops: [Vercel AI Gateway](https://vercel.com/ai-gateway) or [Cloudflare AI Gateway](https://developers.cloudflare.com/ai-gateway/) (0% markup). For lowest token cost, route bulk work to cheap models — a 100K-token report runs **$0.03 on DeepSeek vs $3.01 on GPT-5.5**. See [cost-first](#-cost-first-cheapest-multi-model-access).
**Are AI gateways safe? Who sees my prompts?**
Every gateway sees your prompts. For sensitive data self-host or require zero-data-retention in writing; check the [gateway scorecard](BENCHMARKS.md#part-4--gateway-scorecard-compliance--price--security--stability) for compliance/security ratings and known CVEs.
## 📚 Essential reading
*A short, vetted shelf — every link below was HTTP-checked live (2026-06-15). These are the concepts the comparison tables assume; read them before you commit to a gateway.*
**What an AI gateway actually is**
- [LLM Gateway: The One Decision That Removes 100 AI Engineering Decisions](https://www.latent.space/p/gateway) — Latent.Space (swyx), 2025-02 — why one gateway choice collapses routing, caching, observability and guardrails into a single control plane.
- [AI Gateway — overview](https://developers.cloudflare.com/ai-gateway/) — Cloudflare — first-party docs defining the pattern: one endpoint in front of many providers, with caching, rate limiting, analytics and cost tracking.
- [AI Gateway documentation](https://developer.konghq.com/index/ai-gateway/) — Kong — how gateway concerns (provider-agnostic routing, PII sanitization, token rate-limiting) map onto mature API-gateway infrastructure.
**Routing & fallback**
- [Routing & load balancing](https://docs.litellm.ai/docs/routing-load-balancing) — LiteLLM — cross-provider routing, weighted load balancing and tiered fallbacks from the most-deployed open-source gateway.
- [Router architecture (fallbacks & retries)](https://docs.litellm.ai/docs/router_architecture) — LiteLLM — how retries-within-group and cross-group fallbacks escalate on 429s and connection errors — the mechanics for judging reliability.
- [Load balancing](https://portkey.ai/docs/product/ai-gateway/load-balancing) — Portkey — weighted, sticky distribution across providers, models and keys so no single provider becomes a bottleneck.
- [FrugalGPT: Using LLMs While Reducing Cost and Improving Performance](https://arxiv.org/abs/2305.05176) — Chen, Zaharia & Zou (Stanford), 2023 — the foundational paper behind cost-aware routing: model cascades that try cheap-first and escalate only when needed.
**Semantic caching**
- [GPTCache documentation](https://gptcache.readthedocs.io/) — Zilliz — the de-facto open-source semantic cache: embedding + vector-similarity vs. exact-match.
- [GPTCache: An Open-Source Semantic Cache for LLM Applications](https://openreview.net/forum?id=ivwM8NwM4Z) — Fu Bang, EMNLP 2023 — the peer-reviewed case for similarity-matched caching to lift hit rates and cut cost/latency.
**Prompt caching (it's a prefix match)**
- [Prompt caching](https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching) — Anthropic — the authoritative spec: cache key from exact bytes up to a breakpoint, write/read pricing, and TTLs.
- [Prompt caching](https://platform.openai.com/docs/guides/prompt-caching) — OpenAI — cache hits require an exact prefix; put static instructions first and variable content last to maximize reuse.
**Reasoning-token cost**
- [Building with extended thinking](https://platform.claude.com/docs/en/docs/build-with-claude/extended-thinking) — Anthropic — reasoning/thinking tokens are billed and consume the output budget — the economics to grasp before enabling reasoning models behind a gateway.
**Security & guardrails**
- [OWASP Top 10 for LLM Applications](https://owasp.org/www-project-top-10-for-large-language-model-applications/) — OWASP, 2025 — the standard risk taxonomy; prompt injection is LLM01, the checklist any gateway's guardrails must answer to.
- [Design patterns for securing LLM agents against prompt injection](https://simonwillison.net/2025/Jun/13/prompt-injection-design-patterns/) — Simon Willison, 2025-06 — six concrete architectural defenses (Dual LLM, Plan-Then-Execute, Action-Selector, …).
- [LLM Prompt Injection Prevention Cheat Sheet](https://cheatsheetseries.owasp.org/cheatsheets/LLM_Prompt_Injection_Prevention_Cheat_Sheet.html) — OWASP — a defense-in-depth checklist for what a gateway's guardrail layer should implement.
**MCP & agent gateways**
- [Model Context Protocol — specification](https://modelcontextprotocol.io/specification/2025-03-26) — the open standard any MCP gateway must speak and govern.
- [Building effective agents](https://www.anthropic.com/engineering/building-effective-agents) — Anthropic, 2024 — when to use workflows vs. agents and the composable patterns (routing, orchestrator-workers) the traffic flowing through an agent gateway is made of.
- [LLM Powered Autonomous Agents](https://lilianweng.github.io/posts/2023-06-23-agent/) — Lilian Weng, 2023 — the canonical map of agent architecture (planning, memory, tool use) — what an MCP/agent gateway sits in front of and governs.
**Observability**
- [AI Gateway observability](https://developers.cloudflare.com/ai-gateway/observability/) — Cloudflare — per-request logs, token usage, cost estimation and OpenTelemetry export across all providers.
- [How to monitor your LLM API costs](https://www.helicone.ai/blog/monitor-and-optimize-llm-costs) — Helicone — practical cost-per-query tracking and spotting caching / model-downgrade opportunities.
- [Your AI Product Needs Evals](https://hamel.dev/blog/posts/evals/) — Hamel Husain, 2024 — why systematic evals (not vibes) are how you actually catch quality regressions in the request/response data your gateway logs.
**Self-hosting economics**
- [Automatic prefix caching](https://docs.vllm.ai/en/stable/design/prefix_caching/) — vLLM — KV-block prefix caching (and per-request cache isolation), the mechanism behind the savings when you self-host behind your own gateway.
## Guides & comparisons
In-depth, data-backed comparisons for the questions people actually search:
- [**LiteLLM vs OpenRouter vs Portkey (2026)**](compare/litellm-vs-openrouter-vs-portkey-2026.md) — which AI gateway should you use?
- [**LiteLLM alternatives (2026)**](compare/litellm-alternatives-2026.md) — 8 gateways compared by cost, security & self-hosting
- [**OpenRouter alternatives (2026)**](compare/openrouter-alternatives-2026.md) — 0%-markup, EU-residency & self-hosted options compared
- [**Cloudflare vs Vercel AI Gateway (2026)**](compare/cloudflare-vs-vercel-ai-gateway-2026.md) — which 0%-markup hosted gateway?
- [**Best self-hosted AI gateway in 2026**](compare/best-self-hosted-ai-gateway-2026.md) — LiteLLM vs Bifrost vs Portkey vs Kong
- [**one-api vs new-api vs LiteLLM**](compare/one-api-vs-new-api-vs-litellm.zh-CN.md) — 国内大模型 API 中转怎么选(中文)
*More comparisons coming. Suggest one via an [issue](https://github.com/cuihuan/awesome-ai-gateway/issues).*
## Why this exists
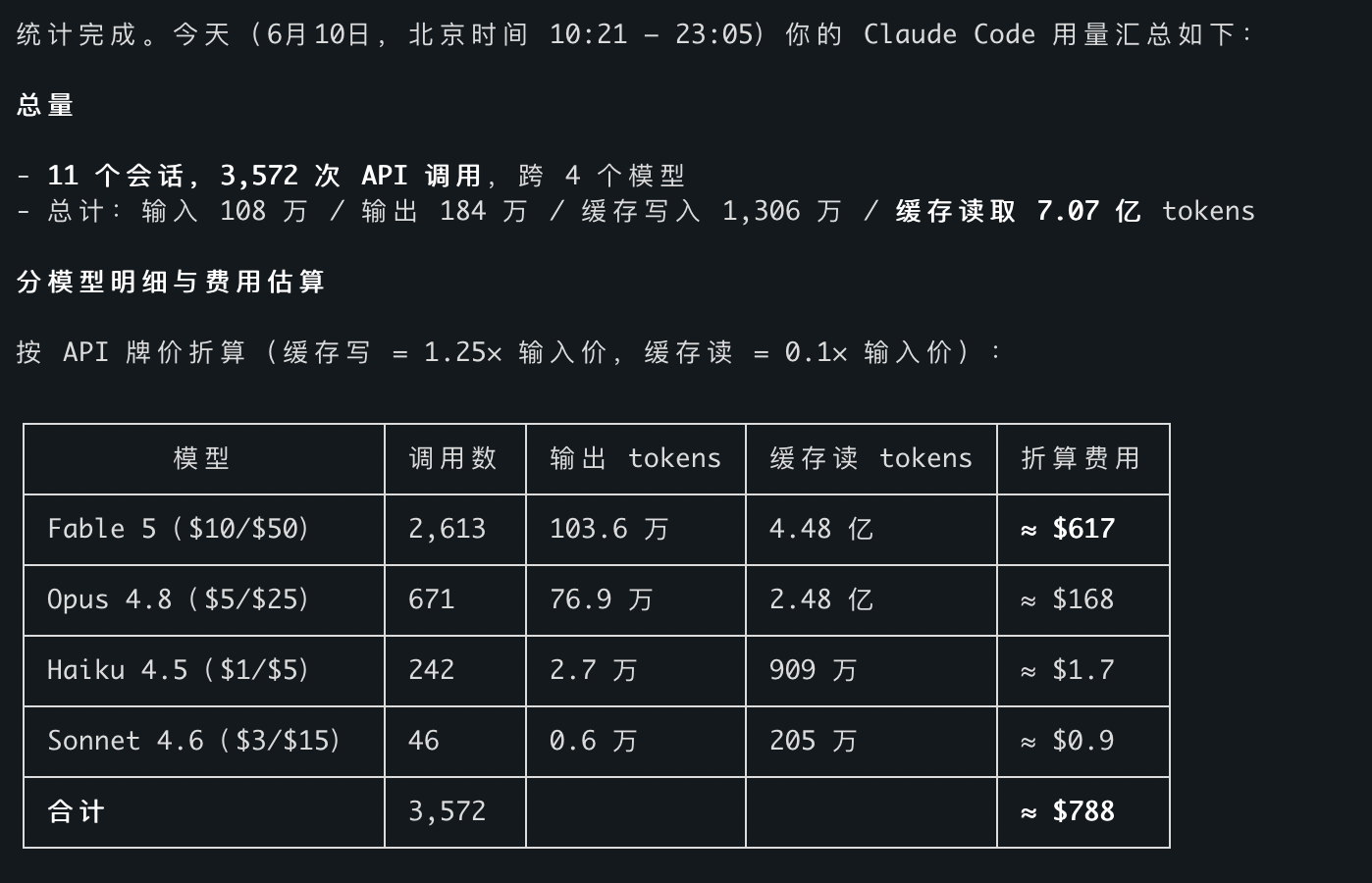
On **June 10 I ran Claude Code hard for ~13 hours, and the bill came to ≈ $788.** One look at the per-model breakdown told the whole story: the flagship (Fable 5) alone was **$617 — 78% of the bill** — while the cheap model (Haiku) did 242 real tasks for **$1.70**. I hadn't done anything clever to rack that up; I'd done the opposite — defaulted every request to the most capable (and most expensive) model because I couldn't be bothered to set up routing.
🧭 Pick a gateway 🚀 Live interactive site 📊 Cost & scorecard
📑 Full contents — pick fast · browse by need · reference
**Pick fast** · [Which gateway should I use?](#which-gateway-should-i-use) · [Quick comparison](#quick-comparison) **Browse by need** · [💰 Cost-first](#-cost-first-cheapest-multi-model-access) · [🔓 Self-hosted](#-self-hosted-open-source) · [🏢 Enterprise & compliance](#-enterprise--compliance) · [☁️ First-party clouds](#️-first-party-gateways-cloud--model-vendors) · [🇨🇳 China ecosystem](#-china-ecosystem) · [🤖 MCP & agent gateways](#-mcp--agent-gateways) **Reference** · [📊 Evaluation set](BENCHMARKS.md) · [How to choose safely](#how-to-choose-safely) · [FAQ](#faq) · [📚 Essential reading](#-essential-reading) · [📰 What's new](#-whats-new) · [Glossary](#glossary) · [Why this exists](#why-this-exists) · [Contributing](#contributing)
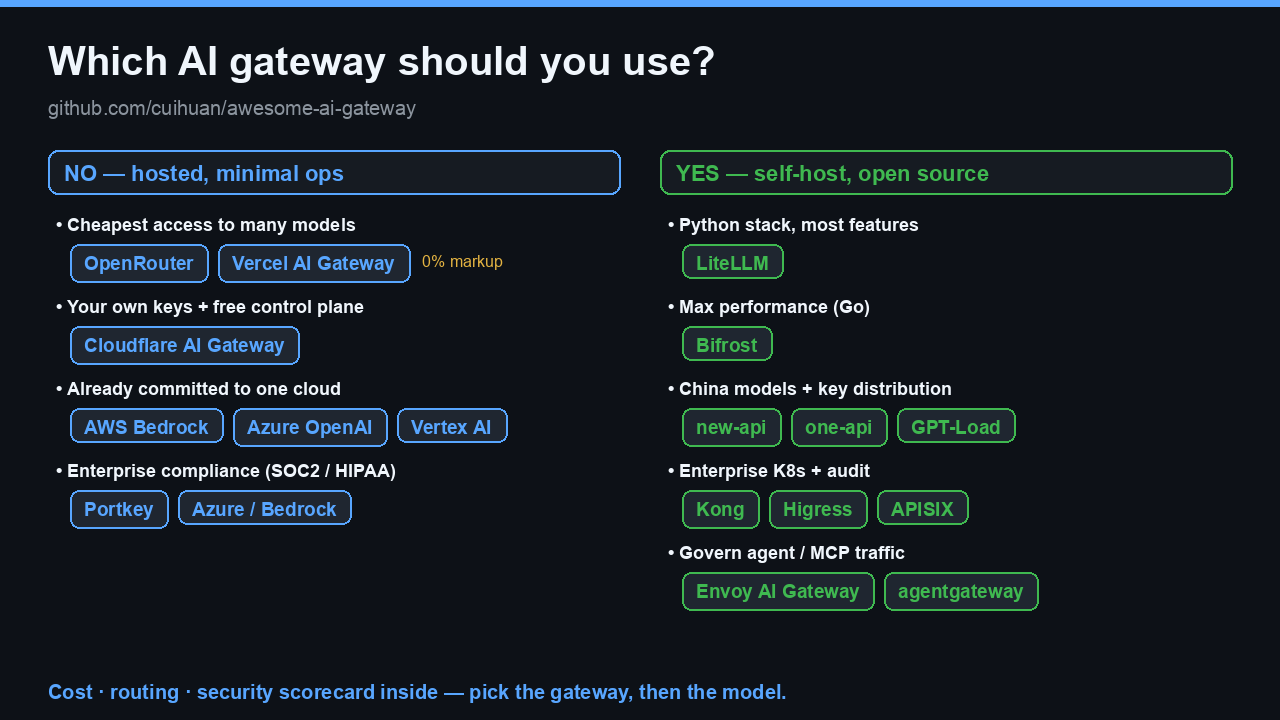
📋 The full decision tree — every branch, copy-pasteable
Do you want to self-host? │ ├─ NO — hosted, minimal ops │ ├─ Cheapest access to many models ──────────▶ OpenRouter · Vercel AI Gateway (0% markup) │ ├─ Free control plane over your own keys ───▶ Cloudflare AI Gateway │ ├─ EU data residency matters ───────────────▶ Requesty · Eden AI · nexos.ai │ └─ Already on one cloud ────────────────────▶ AWS Bedrock · Azure APIM · Vertex AI │ └─ YES — self-hosted / open source ├─ Python stack, broadest features ─────────▶ LiteLLM ├─ Raw performance (Go/Rust/TS) ────────────▶ Bifrost · Portkey Gateway ├─ Built-in evals + observability ──────────▶ Helicone · Portkey Gateway ├─ Key distribution / billing / CN models ──▶ new-api · one-api · GPT-Load ├─ Enterprise K8s, audit, guardrails ───────▶ Kong · Higress · APISIX · Envoy AI Gateway └─ Governing AI agents & MCP traffic ───────▶ agentgateway · Lunar.dev


Key terms used in the tables above (click to expand)
- **AI gateway / LLM gateway** — a proxy between your app and LLM providers; one endpoint and key for many models. - **LLM router** — the part that decides *which model* serves each request (cheap vs flagship, by cost or quality). - **Fallback** — automatically retry on another model/provider when the first fails or times out. - **Load balancing (LB)** — spread traffic across keys/providers to dodge rate limits and outages. - **Semantic caching** — return a cached answer when a *new* prompt is semantically similar to a past one (not just identical). - **Prompt / cached input** — providers bill reused prompt prefixes at a steep discount (≈0.1×); the gateway must not mangle the prefix or the cache misses. - **Guardrails** — input/output checks: prompt-injection detection, PII redaction, content filtering, schema enforcement. - **Virtual keys** — per-user/team keys the gateway issues in front of your real provider keys, with their own budgets and limits. - **ZDR (zero data retention)** — provider/gateway contractually does not store your prompts or completions. - **BYOK** — bring your own key: the gateway uses *your* provider accounts rather than reselling tokens. - **Markup** — the gateway's fee on top of provider token cost (0% to ~6%). - **MCP gateway** — governs agent ↔ tool traffic (Model Context Protocol), the agentic counterpart to an LLM gateway.
标签:AI网关, DLL 劫持, LLM代理, 大语言模型, 性能基准测试, 成本评估, 资源导航, 逆向工具