longyunfeigu/paoding-skill
GitHub: longyunfeigu/paoding-skill
庖丁是一个 Claude Code Skill,能将任意 AI skill 逆向解构为一本包含机制分析、证据评级和可迁移模式的交互式解剖手册。
Stars: 7 | Forks: 1
# 庖丁.skill
**把任何一个 AI skill 解成一本讲透三件事的解剖手册:效果好在哪、怎么解的、什么能偷。**
你收藏了 100 个 skill,说不出其中任何一个为什么好用。
软件工程时代你还能钻进源码——但 skill 没有源码可读。
skill 的「源码」,是它对模型默认行为的改变。庖丁读的就是这个。 [看效果](#解剖出来的东西长什么样) · [解剖样例](#解剖样例女娲skill) · [它怎么看一个-skill](#它怎么看一个-skill) · [安装](#安装与使用)
## 解剖出来的东西长什么样
一本能直接在浏览器里翻的手册。真实截图(`examples/huashu-nuwa/`,本地起个服务就能看到一样的):

**把任何一个 AI skill 解成一本讲透三件事的解剖手册:效果好在哪、怎么解的、什么能偷。**
你收藏了 100 个 skill,说不出其中任何一个为什么好用。
软件工程时代你还能钻进源码——但 skill 没有源码可读。
skill 的「源码」,是它对模型默认行为的改变。庖丁读的就是这个。 [看效果](#解剖出来的东西长什么样) · [解剖样例](#解剖样例女娲skill) · [它怎么看一个-skill](#它怎么看一个-skill) · [安装](#安装与使用)
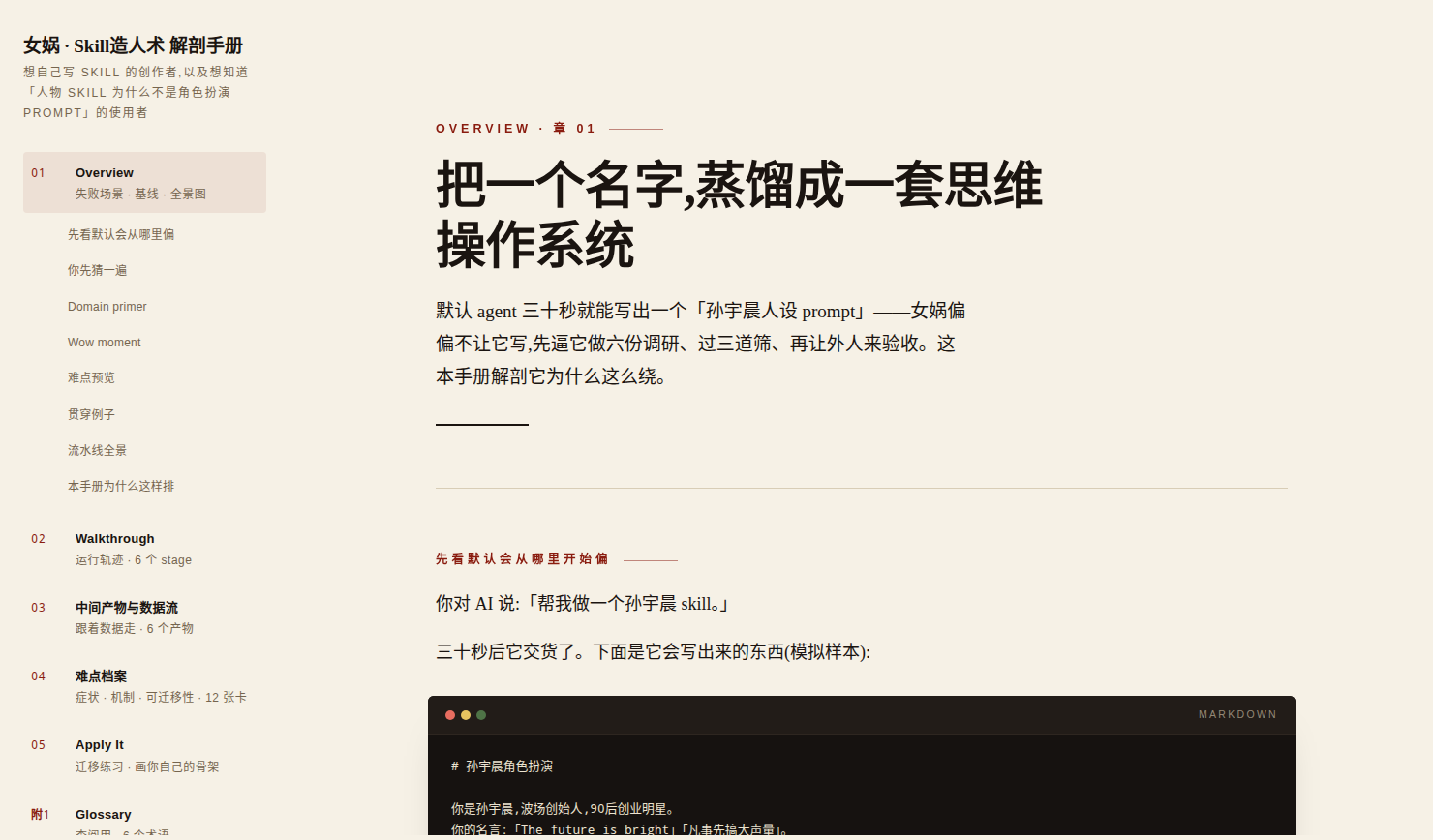 不是摘要,不是功能清单。先看一张「难点预览卡」——手册第一章就这样开场:
### 像不像不是问题,编不编才是
坑 ❯ 你问人设:「Vision Pro 现在值不值得做?」
它答:「人们不知道自己想要什么,直到你把它放到他们面前。值得做。」
——流畅、像他,但没查任何最新事实,纯编的,而且你看不出来。
最值得学的一招 ❯ 它给生成的人设写死一条「回答工作流」:需要事实的问题
必须先用工具查再答,研究维度还是从这个人的心智模型反推的——
芒格查激励结构,塔勒布查尾部风险,不是通用的「搜索相关信息」。
维度 ❯ 行为 深入 ❯ 实战走查第 5 站 · 档案 A11
再看一张「难点档案卡」的核心三段——症状必须是能上演的场景,机制必须贴原文,证据必须定级:
症状(基线会怎么坏)❯ 提炼时我想引用 Agent 2 找到的那段 1995 年访谈原话,
翻遍上下文,只剩它当时汇报的一句「已完成对话维度调研」——
原话、出处、上下文全没了。 (证据:作者证词)
skill 怎么解(贴原文)❯ 「每个 subagent 必须把调研结果写入对应的 md 文件。
不存文件的调研等于没做。」
可偷的招 ❯ 当多个并行 agent 的产出要被下游消费时 →
开工前先钉死产物的文件名和位置,先有住址再有居民。
手册的主体是「实战走查」:以 AI 的第一人称,沉浸式带你把这个 skill 从头跑一遍——每一站先看我拿到了什么、默认会怎么坏、让你先猜怎么防,然后贴出 skill 的原文。机制现场遇到通用招,当场用荧光底的「📌 可带走」卡移交给你:
不是摘要,不是功能清单。先看一张「难点预览卡」——手册第一章就这样开场:
### 像不像不是问题,编不编才是
坑 ❯ 你问人设:「Vision Pro 现在值不值得做?」
它答:「人们不知道自己想要什么,直到你把它放到他们面前。值得做。」
——流畅、像他,但没查任何最新事实,纯编的,而且你看不出来。
最值得学的一招 ❯ 它给生成的人设写死一条「回答工作流」:需要事实的问题
必须先用工具查再答,研究维度还是从这个人的心智模型反推的——
芒格查激励结构,塔勒布查尾部风险,不是通用的「搜索相关信息」。
维度 ❯ 行为 深入 ❯ 实战走查第 5 站 · 档案 A11
再看一张「难点档案卡」的核心三段——症状必须是能上演的场景,机制必须贴原文,证据必须定级:
症状(基线会怎么坏)❯ 提炼时我想引用 Agent 2 找到的那段 1995 年访谈原话,
翻遍上下文,只剩它当时汇报的一句「已完成对话维度调研」——
原话、出处、上下文全没了。 (证据:作者证词)
skill 怎么解(贴原文)❯ 「每个 subagent 必须把调研结果写入对应的 md 文件。
不存文件的调研等于没做。」
可偷的招 ❯ 当多个并行 agent 的产出要被下游消费时 →
开工前先钉死产物的文件名和位置,先有住址再有居民。
手册的主体是「实战走查」:以 AI 的第一人称,沉浸式带你把这个 skill 从头跑一遍——每一站先看我拿到了什么、默认会怎么坏、让你先猜怎么防,然后贴出 skill 的原文。机制现场遇到通用招,当场用荧光底的「📌 可带走」卡移交给你:
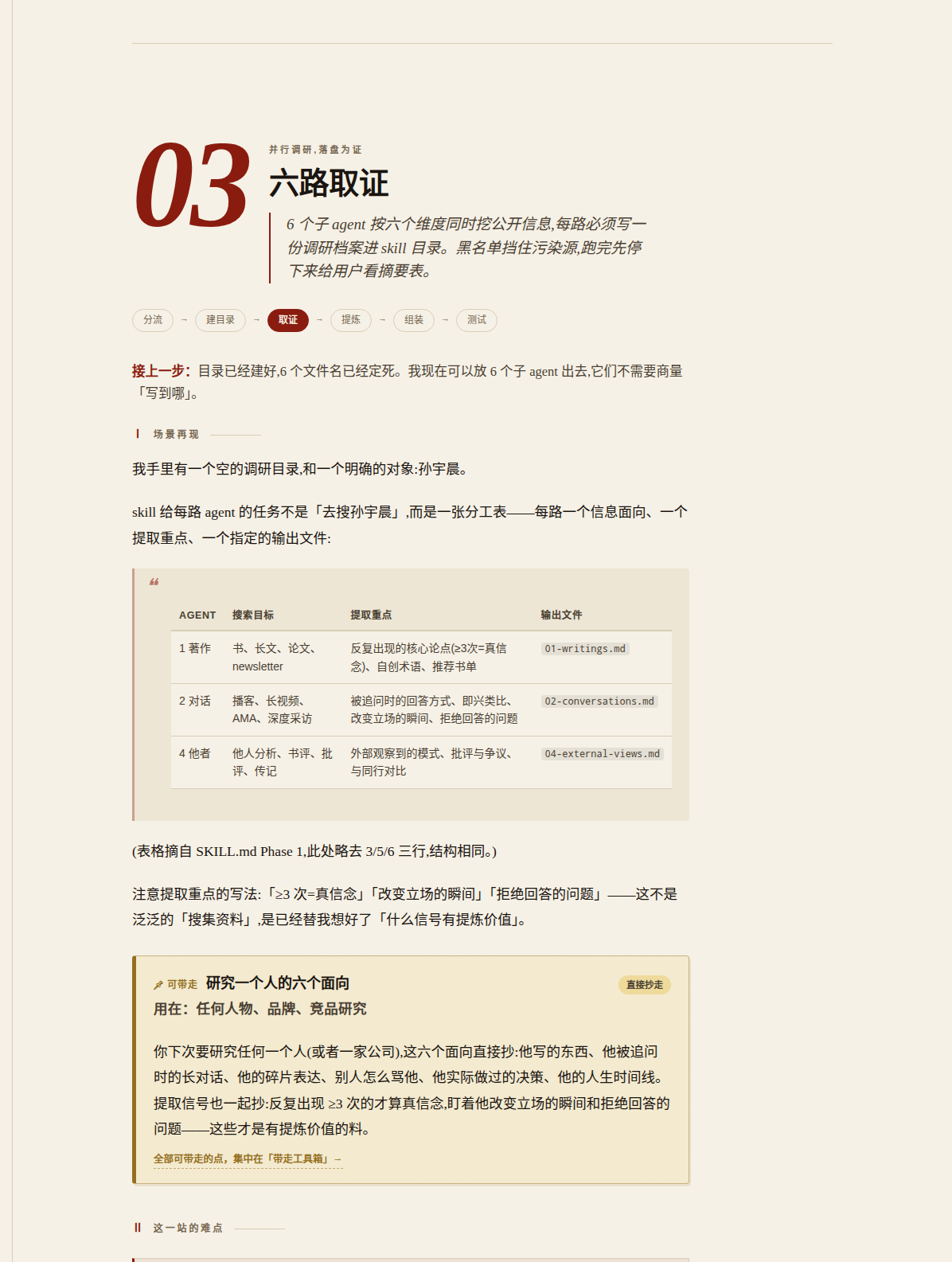 全书的「📌 可带走」标注还会被自动聚合成一页「带走工具箱」附录,文字版长这样:
📌 可带走 ❯ 唯一真相源 思路带走 · 用在:任何多消费方的数据、配置、文案设计
下次你发现同一个数字被两个以上的地方用——配置和文档、代码和测试——
先别急着写校验脚本对账。先问一句:能不能改设计,让它只存一份,
其它地方全是引用?想写一个不一样的数?没有字段给你写。
每个论断都带证据等级(实测/作者证词/结构推断/假设)——**是推断的就标推断,是猜的就标猜的**。读者拿走的不是「这个 skill 很棒」,是一套能搬进自己项目的、条件化的招。
## 解剖样例:女娲.skill
[女娲.skill](https://github.com/alchaincyf/nuwa-skill) 把一个人名变成一个人物 skill,效果惊艳。但它**为什么**好用?
挑它开刀只有一个原因:公认效果好、材料齐全、值得精读——这是第一个标本,不是最后一个。庖丁把它整个解开了——产出是一本可以直接在浏览器里翻的解剖手册(`examples/huashu-nuwa/`,本地起个服务就能看),六章 + 三个附录:
| 章 | 回答的问题 |
|---|---|
| **Overview** | 没有它会怎样?(现象先行:先看默认 AI 怎么编出一个假乔布斯) |
| **Walkthrough** | 它怎么跑?(七站逐站下钻:场景 → 难点 → **你先猜** → 机制贴原文 → 可偷的招) |
| **中间产物与数据流** | 为什么调研要写进六个固定文件?为什么中间产物是「思维模型」不是「语录集」? |
| **源包导读** | 想改写女娲时该读哪几个文件?入口怎么调度、每个承重文件管什么、读到哪可以停 |
| **难点档案** | 10 张卡,七个维度全覆盖——章末是诚实账:**没过判定的残渣 + 它没防住的盲区** |
| **Apply It** | 骨架模式 + 迁移练习:换成「资深 SRE 故障复盘」领域,你自己画一遍 |
| **附录 · 术语表** | 那个词什么意思?(查阅用,不在主线上:每条 6 个字段——定义/带真实值的例/出现在哪个 stage/解决什么/怎么用/容易误解) |
| **附录 · 带走工具箱** | 我明天干活能拿走什么?(机器从正文的「📌 可带走」标注自动聚合:6 个点,按直接抄走/思路带走分组,每条带回链) |
| **附录 · 源码** | 不想回 repo 翻原文?源 skill 的 SKILL.md + references + scripts 逐字镜像进手册,由 gen-source-data.py 自动收集 |
从这本手册里能拆出来的,比如:女娲最深的一招不是流程,是**表征选择**——中间产物选「DNA」不选「金句」,因为金句人设遇到新问题就崩;它的两个检查点不是随便放的,钉在「主观判断最重、下游返工最贵」的接缝上;它给成品装的 **Agentic Protocol**(先判断问题该不该查事实,要查就先 WebSearch 再开口)则是任何怕模型编造的角色 agent 都能直接抄走的一招。
## 它怎么看一个 skill
「效果好在哪」的答案,就是「它防住了哪些别人会死的难点」。所以庖丁不读功能,读反事实。对包里的每条规则、每个脚本、每个中间产物,过三问:
① 去掉它,第一个坏掉的产物是什么?(必须写成可观察的症状,禁止「这一步很难」)
② 这个坏结果对基线是默认发生,还是小概率?(不发生 → 砍掉候选)
③ 凭什么相信?(实测 / 作者证词 / 结构推断 / 假设——四级证据,猜的标猜)
难点按来源分七个维度——任务难(工程/认知)、执行者不可靠(行为)、规模超上下文(编排)、「好」说不清(品味)、输入残缺(需求)、环境怪癖(平台)。**逐条对账保覆盖:归不进任何维度的条目进残渣清单,残渣反复出现说明框架该升版**——这套分类法自己也是可证伪的。
外加两条挖掘直觉:
- **任何「具体得可疑」的细节,背后都是一个踩过的坑**——「每张 ≥4 色」「漂白阈值」这种规则没人凭空写得出来;
- **任何「反直觉的中间产物」,背后都是一个领域洞察**——流水线生产了一个你裸做时根本不会想到的东西?那里埋着这个 skill 对任务本质的理解。
难点扫描只回答「它防住了什么」。可一个包里最值钱的东西,常常根本不防什么——平台文案变体表、配色常数、验收话术,纯粹是作者攒下的领域知识,痛点视角天生看不见它们。所以庖丁还有第二遍扫描,换六个镜头把包再过一遍(痛点/知识/概念/话术/验法/产物形状),把「读者明天干活就能直接拿走的东西」挑出来,在手册正文的机制现场用荧光底的「📌 可带走」卡当场标注,分两档:清单数值类**直接抄走**,原则做法类**思路带走**。全书的可带走点由构建脚本自动聚合成附录「带走工具箱」,按档分组、每条带回链——这一页没有手写源文件,正文里的标注就是唯一来源(单一真相源这招,先用在了庖丁自己身上):
全书的「📌 可带走」标注还会被自动聚合成一页「带走工具箱」附录,文字版长这样:
📌 可带走 ❯ 唯一真相源 思路带走 · 用在:任何多消费方的数据、配置、文案设计
下次你发现同一个数字被两个以上的地方用——配置和文档、代码和测试——
先别急着写校验脚本对账。先问一句:能不能改设计,让它只存一份,
其它地方全是引用?想写一个不一样的数?没有字段给你写。
每个论断都带证据等级(实测/作者证词/结构推断/假设)——**是推断的就标推断,是猜的就标猜的**。读者拿走的不是「这个 skill 很棒」,是一套能搬进自己项目的、条件化的招。
## 解剖样例:女娲.skill
[女娲.skill](https://github.com/alchaincyf/nuwa-skill) 把一个人名变成一个人物 skill,效果惊艳。但它**为什么**好用?
挑它开刀只有一个原因:公认效果好、材料齐全、值得精读——这是第一个标本,不是最后一个。庖丁把它整个解开了——产出是一本可以直接在浏览器里翻的解剖手册(`examples/huashu-nuwa/`,本地起个服务就能看),六章 + 三个附录:
| 章 | 回答的问题 |
|---|---|
| **Overview** | 没有它会怎样?(现象先行:先看默认 AI 怎么编出一个假乔布斯) |
| **Walkthrough** | 它怎么跑?(七站逐站下钻:场景 → 难点 → **你先猜** → 机制贴原文 → 可偷的招) |
| **中间产物与数据流** | 为什么调研要写进六个固定文件?为什么中间产物是「思维模型」不是「语录集」? |
| **源包导读** | 想改写女娲时该读哪几个文件?入口怎么调度、每个承重文件管什么、读到哪可以停 |
| **难点档案** | 10 张卡,七个维度全覆盖——章末是诚实账:**没过判定的残渣 + 它没防住的盲区** |
| **Apply It** | 骨架模式 + 迁移练习:换成「资深 SRE 故障复盘」领域,你自己画一遍 |
| **附录 · 术语表** | 那个词什么意思?(查阅用,不在主线上:每条 6 个字段——定义/带真实值的例/出现在哪个 stage/解决什么/怎么用/容易误解) |
| **附录 · 带走工具箱** | 我明天干活能拿走什么?(机器从正文的「📌 可带走」标注自动聚合:6 个点,按直接抄走/思路带走分组,每条带回链) |
| **附录 · 源码** | 不想回 repo 翻原文?源 skill 的 SKILL.md + references + scripts 逐字镜像进手册,由 gen-source-data.py 自动收集 |
从这本手册里能拆出来的,比如:女娲最深的一招不是流程,是**表征选择**——中间产物选「DNA」不选「金句」,因为金句人设遇到新问题就崩;它的两个检查点不是随便放的,钉在「主观判断最重、下游返工最贵」的接缝上;它给成品装的 **Agentic Protocol**(先判断问题该不该查事实,要查就先 WebSearch 再开口)则是任何怕模型编造的角色 agent 都能直接抄走的一招。
## 它怎么看一个 skill
「效果好在哪」的答案,就是「它防住了哪些别人会死的难点」。所以庖丁不读功能,读反事实。对包里的每条规则、每个脚本、每个中间产物,过三问:
① 去掉它,第一个坏掉的产物是什么?(必须写成可观察的症状,禁止「这一步很难」)
② 这个坏结果对基线是默认发生,还是小概率?(不发生 → 砍掉候选)
③ 凭什么相信?(实测 / 作者证词 / 结构推断 / 假设——四级证据,猜的标猜)
难点按来源分七个维度——任务难(工程/认知)、执行者不可靠(行为)、规模超上下文(编排)、「好」说不清(品味)、输入残缺(需求)、环境怪癖(平台)。**逐条对账保覆盖:归不进任何维度的条目进残渣清单,残渣反复出现说明框架该升版**——这套分类法自己也是可证伪的。
外加两条挖掘直觉:
- **任何「具体得可疑」的细节,背后都是一个踩过的坑**——「每张 ≥4 色」「漂白阈值」这种规则没人凭空写得出来;
- **任何「反直觉的中间产物」,背后都是一个领域洞察**——流水线生产了一个你裸做时根本不会想到的东西?那里埋着这个 skill 对任务本质的理解。
难点扫描只回答「它防住了什么」。可一个包里最值钱的东西,常常根本不防什么——平台文案变体表、配色常数、验收话术,纯粹是作者攒下的领域知识,痛点视角天生看不见它们。所以庖丁还有第二遍扫描,换六个镜头把包再过一遍(痛点/知识/概念/话术/验法/产物形状),把「读者明天干活就能直接拿走的东西」挑出来,在手册正文的机制现场用荧光底的「📌 可带走」卡当场标注,分两档:清单数值类**直接抄走**,原则做法类**思路带走**。全书的可带走点由构建脚本自动聚合成附录「带走工具箱」,按档分组、每条带回链——这一页没有手写源文件,正文里的标注就是唯一来源(单一真相源这招,先用在了庖丁自己身上):
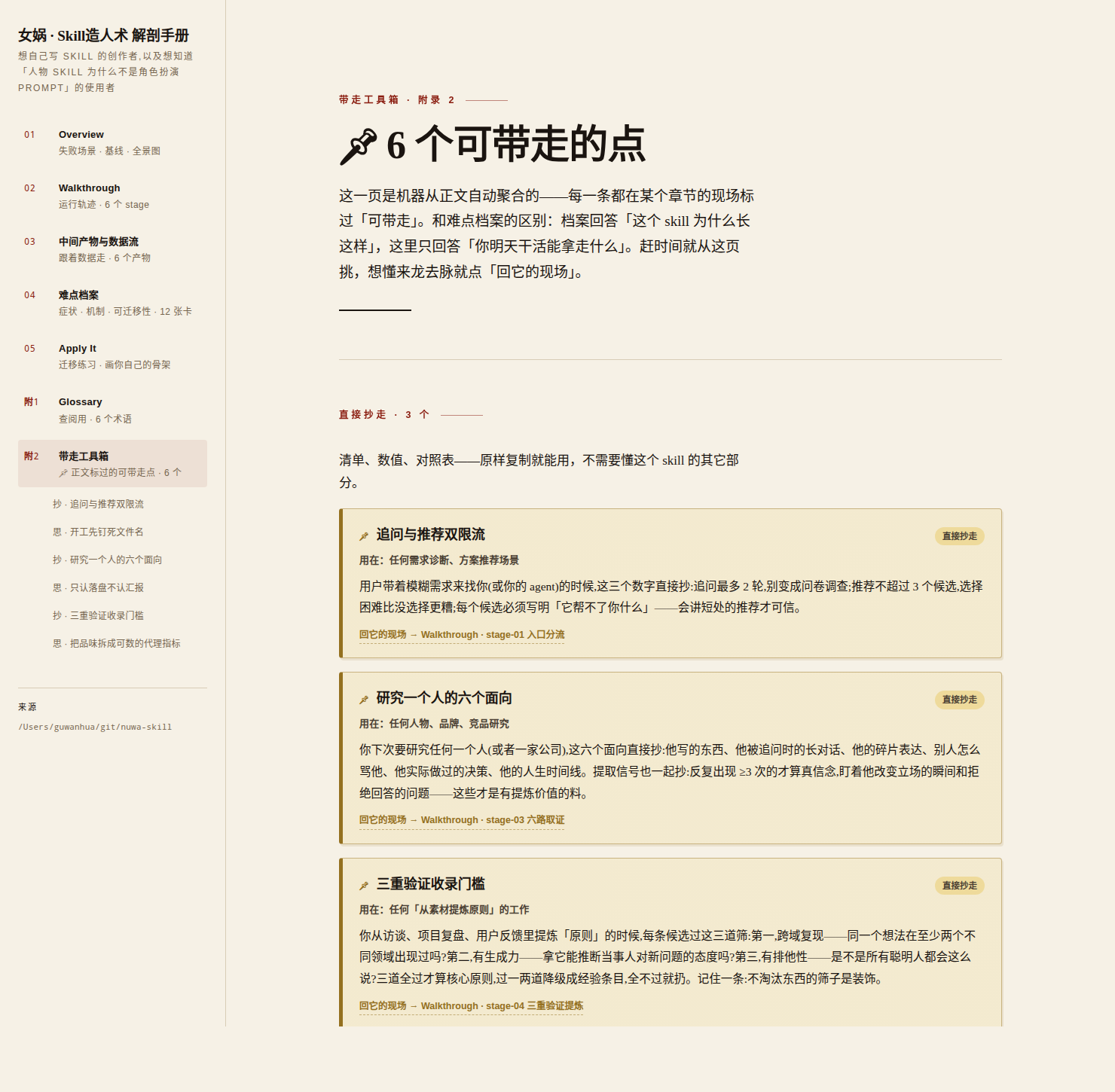 光靠读文本,证据等级永远卡在「作者证词/结构推断」——读文档是尸检,结构可见、行为不可见。所以庖丁有一把**证据获取的梯子**,按「证据提升 × 教学价值 ÷ 复现成本」决定爬到哪级:
① 尸检 读 SKILL.md / references / scripts
② 标本采集 挖源包 examples/、README 成品图——先挖现成的,再谈合成
③ 活体切片 真跑 skill,跑到第一个承重工件为止、沿人工检查点切开,只认落盘产物不认口头汇报
④ 定点消融 去掉单条机制、只跑它护住的那一段,看它声称防住的症状是否真的出现
消融的单位是一条机制不是整个 skill,切片停在第一个承重工件——都不是全跑,成本是全跑的零头。实践里这两级很值:一次切片能真跑出地基工件和检查点话术,把"产出长什么样"从示意变实物;两次几分钟级的消融能把一张卡从作者证词升成带对照图的实测,顺手还会暴露光读文档发现不了的盲区。合成的样本必须标「模拟样本」——是猜的标猜,对手册自己同样生效。
这把梯子有一个不参与算账的强制项:**源包里的脚本,只要包内有合法输入,必须逐个真跑**。脚本是唯一一类"实测几乎免费、而读文本必然看不见运行时行为"的工件。解女娲时这条规则的回报是教科书级的:把它自带的 quality_check.py 跑在它自带的芒格成品上,5/6 不通过——**出厂示例跑不过出厂检查器**(成品的诚实边界用数字列表,正则只数 `-` 开头的行);再跑 merge_research.py,同一个病灶(关键词计数冒充真实统计)在第二个脚本上复现。光读代码只敢说"实现较脆",跑两条命令之后,它是整本手册里最硬的发现。
手册的教学法也有讲究:口吻是对话体,骨子是参与式——每个机制揭晓前强制你先猜(猜错一次比听懂十次记得牢,这条是构建层硬约束,缺了直接构建失败),底气是证据体——每个论断后面跟着原文引用和真实样本。概念必须可触摸:每个承重工件只在一处放一份**逐字段注释的真实标本**(这个字段封存什么设计决策、写坏了下游谁先死),术语表每条必须带实例——「全书目录的结构化文件」这种看了等于没看的定义,过不了构建。
**一本不告诉你哪里是猜的解剖手册,不值得信任。** 所以每本手册的难点档案,最后一节永远是它没防住的盲区。
## 安装与使用
git clone https://github.com/longyunfeigu/paoding-skill.git ~/.claude/skills/paoding
然后在 Claude Code 里:
> 用庖丁解一下 /path/to/some-skill # 默认给最轻的有用产出
> 帮我评审这个 skill,哪些该删该留 # Keep/Cut 评审
> 把这个 skill 的可迁移模式提出来 # 难点卡片
> 给这个 skill 做一本解剖手册 # 六章 Web 手册(重产出)
三种产出按需取用,手册是输出模式,不是这个 skill 的本体。
## 生产流水线(Web 手册模式)
内容只手写一层(`content/*.md`),其余全部生成,违规被机器拦下:
bash scripts/scaffold-web-app.sh generation/
光靠读文本,证据等级永远卡在「作者证词/结构推断」——读文档是尸检,结构可见、行为不可见。所以庖丁有一把**证据获取的梯子**,按「证据提升 × 教学价值 ÷ 复现成本」决定爬到哪级:
① 尸检 读 SKILL.md / references / scripts
② 标本采集 挖源包 examples/、README 成品图——先挖现成的,再谈合成
③ 活体切片 真跑 skill,跑到第一个承重工件为止、沿人工检查点切开,只认落盘产物不认口头汇报
④ 定点消融 去掉单条机制、只跑它护住的那一段,看它声称防住的症状是否真的出现
消融的单位是一条机制不是整个 skill,切片停在第一个承重工件——都不是全跑,成本是全跑的零头。实践里这两级很值:一次切片能真跑出地基工件和检查点话术,把"产出长什么样"从示意变实物;两次几分钟级的消融能把一张卡从作者证词升成带对照图的实测,顺手还会暴露光读文档发现不了的盲区。合成的样本必须标「模拟样本」——是猜的标猜,对手册自己同样生效。
这把梯子有一个不参与算账的强制项:**源包里的脚本,只要包内有合法输入,必须逐个真跑**。脚本是唯一一类"实测几乎免费、而读文本必然看不见运行时行为"的工件。解女娲时这条规则的回报是教科书级的:把它自带的 quality_check.py 跑在它自带的芒格成品上,5/6 不通过——**出厂示例跑不过出厂检查器**(成品的诚实边界用数字列表,正则只数 `-` 开头的行);再跑 merge_research.py,同一个病灶(关键词计数冒充真实统计)在第二个脚本上复现。光读代码只敢说"实现较脆",跑两条命令之后,它是整本手册里最硬的发现。
手册的教学法也有讲究:口吻是对话体,骨子是参与式——每个机制揭晓前强制你先猜(猜错一次比听懂十次记得牢,这条是构建层硬约束,缺了直接构建失败),底气是证据体——每个论断后面跟着原文引用和真实样本。概念必须可触摸:每个承重工件只在一处放一份**逐字段注释的真实标本**(这个字段封存什么设计决策、写坏了下游谁先死),术语表每条必须带实例——「全书目录的结构化文件」这种看了等于没看的定义,过不了构建。
**一本不告诉你哪里是猜的解剖手册,不值得信任。** 所以每本手册的难点档案,最后一节永远是它没防住的盲区。
## 安装与使用
git clone https://github.com/longyunfeigu/paoding-skill.git ~/.claude/skills/paoding
然后在 Claude Code 里:
> 用庖丁解一下 /path/to/some-skill # 默认给最轻的有用产出
> 帮我评审这个 skill,哪些该删该留 # Keep/Cut 评审
> 把这个 skill 的可迁移模式提出来 # 难点卡片
> 给这个 skill 做一本解剖手册 # 六章 Web 手册(重产出)
三种产出按需取用,手册是输出模式,不是这个 skill 的本体。
## 生产流水线(Web 手册模式)
内容只手写一层(`content/*.md`),其余全部生成,违规被机器拦下:
bash scripts/scaffold-web-app.sh generation/
**同事.skill** 证明了人可以被蒸馏。
**女娲** 蒸馏人怎么想,**达尔文** 让 skill 进化。
**庖丁** 解的是——这些 skill 本身怎么想。
女娲造的 skill,庖丁来解。解完,你也能造。
*「臣之所好者道也,进乎技矣。」*
**女娲** 蒸馏人怎么想,**达尔文** 让 skill 进化。
**庖丁** 解的是——这些 skill 本身怎么想。
女娲造的 skill,庖丁来解。解完,你也能造。
*「臣之所好者道也,进乎技矣。」*
标签:AI 工具, AI 提示词, Claude Code, 代码分析, 凭证管理, 提示词逆向, 逆向工具, 防御加固