siri423/sentinelai
GitHub: siri423/sentinelai
基于差分隐私训练的信用风险评分 API 系统,在大规模真实金融数据上同时量化隐私、效用与公平性三项指标。
Stars: 0 | Forks: 0
# SentinelAI
**具备 DP-SGD 防御机制的隐私保护信用风险评分 API,可抵御成员推理和模型提取攻击。**
基于 30 万零 7 千条真实贷款申请数据进行训练。在 ε=2.0 时实现了**低于 1% 的 AUC 降幅**,同时提供严格的差分隐私保证(ε=2.0, δ=1e-5)。
[](https://pytorch.org/)
[](https://fastapi.tiangolo.com/)
[](https://opacus.ai/)
[](https://python.org/)
[](LICENSE)
## 问题背景
通过 API 提供服务的信用评分模型面临三大同时存在的威胁:
**威胁 1 — 成员推理攻击。** 攻击者通过查询 API 来确定特定个人的财务记录是否被用于模型训练。这违反了 GDPR 第 22 条和《公平信用报告法》。
**威胁 2 — 模型提取。** 攻击者无需访问训练数据,仅需不到 1 万次 API 查询即可克隆专有模型(Tramèr 等人)。
**威胁 3 — 公平性退化。** 标准的 DP-SGD 防御机制可能会对代表性不足的群体造成不成比例的损害(Bagdasaryan 等人,NeurIPS 2019)。
现有的研究都是孤立地应对这些威胁。SentinelAI 提供了一个统一的 pipeline:DP-SGD 训练、MIA 评估、提取防御、公平性审计以及 API 加固——全部基于大规模真实金融数据运行。
## 架构
```
Home Credit Dataset
(307K records, 122 features)
|
v
Data Preprocessing <-- SMOTE to 25%, median impute, MinMax scale
+ Fairness Baseline 165 features after encoding
|
v
DP-SGD Training (Opacus) <-- epsilon in {0.5, 1.0, 2.0, 4.0, 8.0}
|
v
FastAPI Deployment <-- JWT auth + rate limiting + label-only output
|
/v1/predict
|
+-------> MIA Simulation (confidence-based RF classifier)
|
+-------> Model Extraction (KnockoffNets, 10K query budget)
|
v
Evaluation: Privacy x Utility x Fairness
```
**神经网络架构:** MLP 结构为 `Input(165) → 256 (GroupNorm, ReLU, Dropout 0.3) → 128 → 64 → 2 (Softmax)`。使用 GroupNorm 替代 BatchNorm 以兼容 Opacus——因为 BatchNorm 的跨批次统计信息会破坏 DP-SGD 所需的样本级梯度隔离。
## 结果
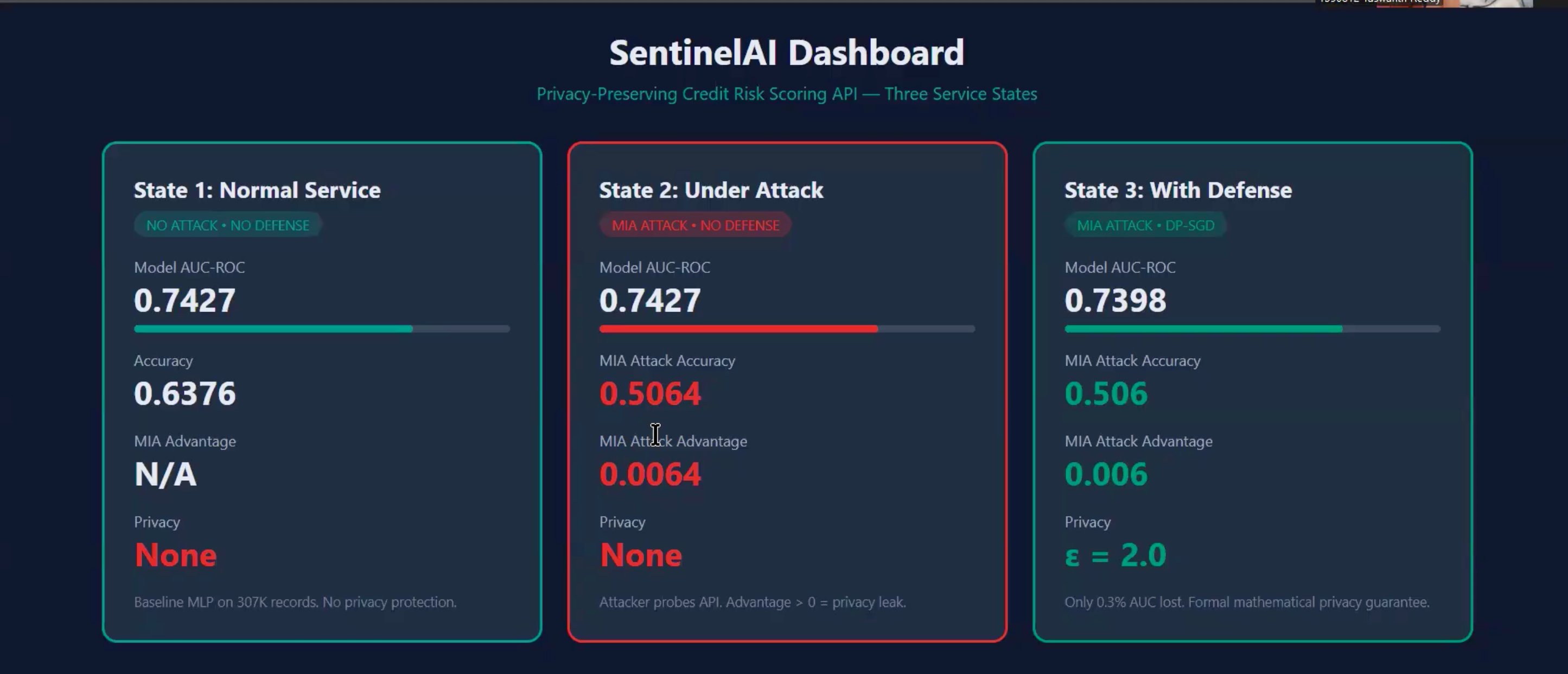
### 三态评估
| 指标 | 正常服务 | 受到攻击 | 启用防御 (ε=2.0) |
|--------|---------------|-------------|---------------------|
| 模型 AUC-ROC | 0.7430 | 0.7430 | 0.7369 (−0.8%) |
| MIA 攻击优势 | — | 0.0049 | 0.0110 |
| 提取保真度 (10K) | — | 0.9295 | 0.9087 (仅标签) |
| 公平性 AIR (性别) | 1.2636 | 1.2636 | 1.0431 |
| 均等化奇偶差异 | 0.1481 | 0.1481 | 0.0523 |
| 隐私保证 | 无 | 无 | ε=2.0, δ=1e-5 |
### 关键发现
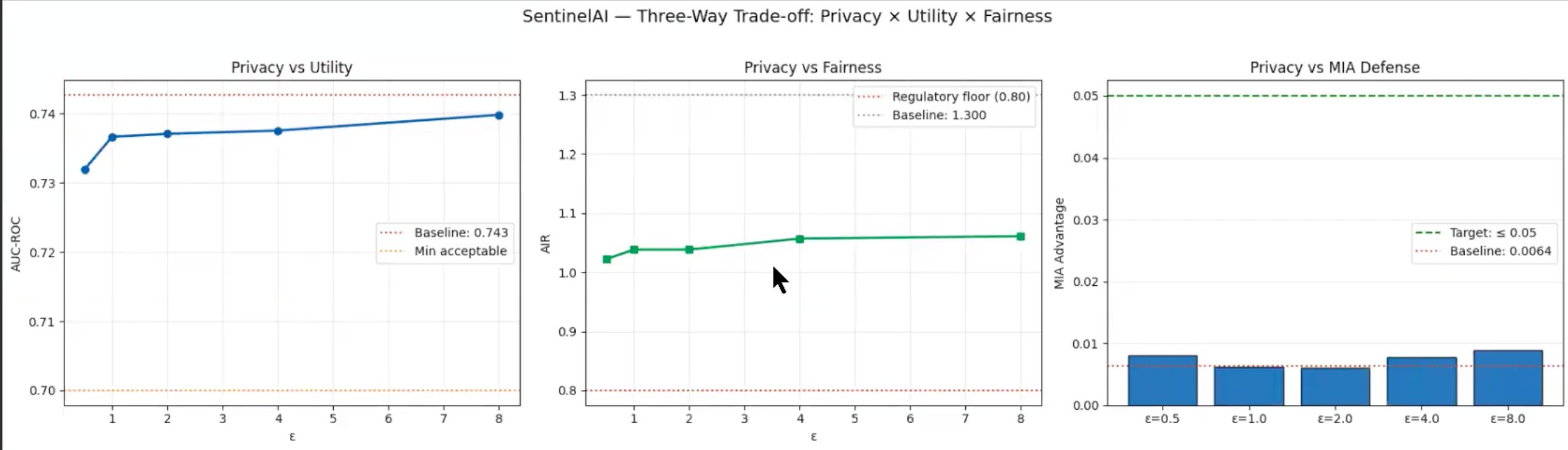
**大规模应用 DP-SGD 的成本几乎可以忽略不计。** 已发表的文献预测 AUC 会下降 15–20%。我们在所有 epsilon 值下测得的降幅均不到 1%。30.7 万个训练样本吸收了梯度噪声——而以往论文使用的数据集要小得多。
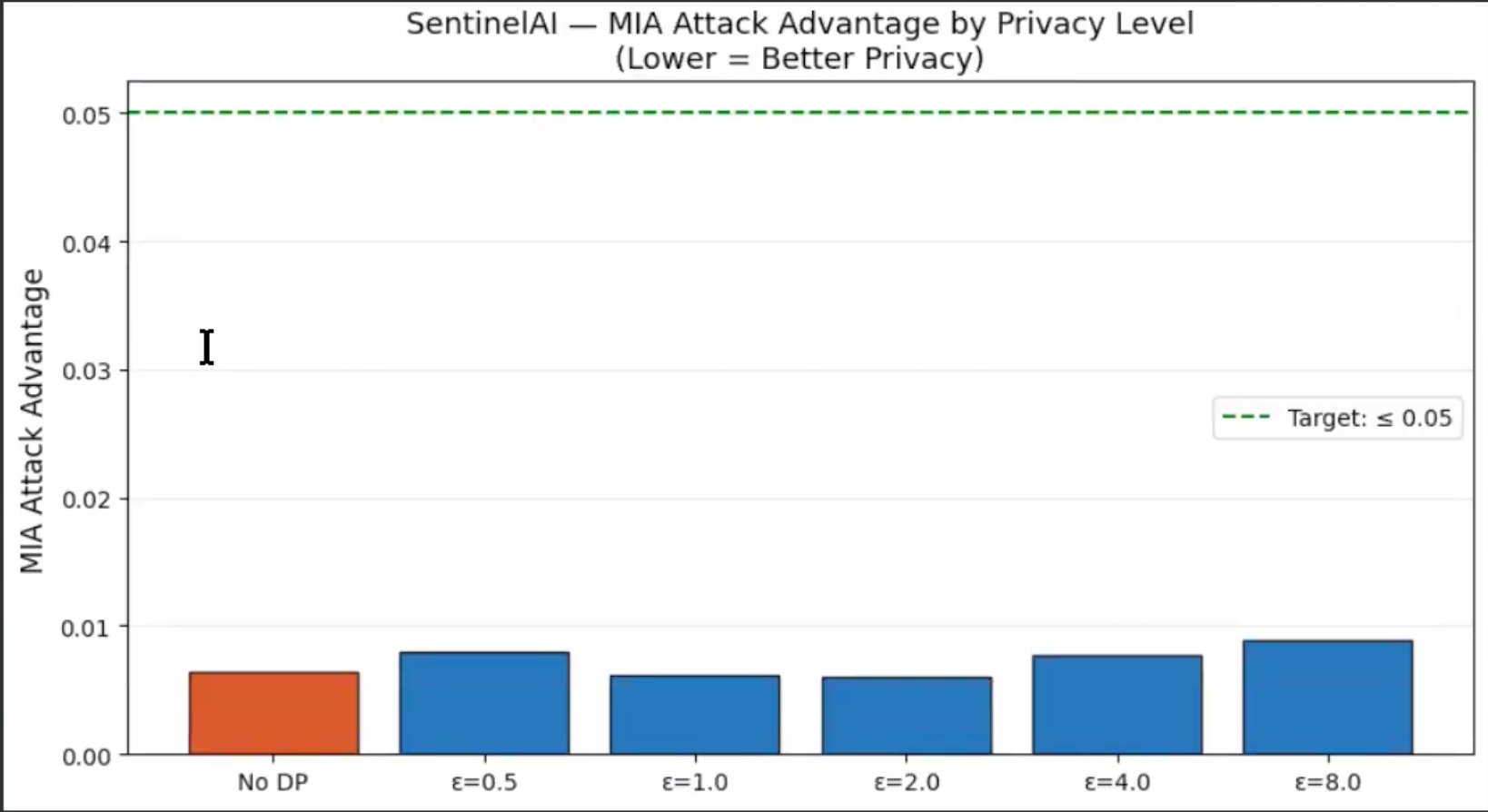
**MIA 攻击优势保持在接近零的水平。** 所有六个模型均低于 0.05 的目标阈值。DP-SGD 在接近零的经验抵抗力之上,又增加了严格的数学保证。
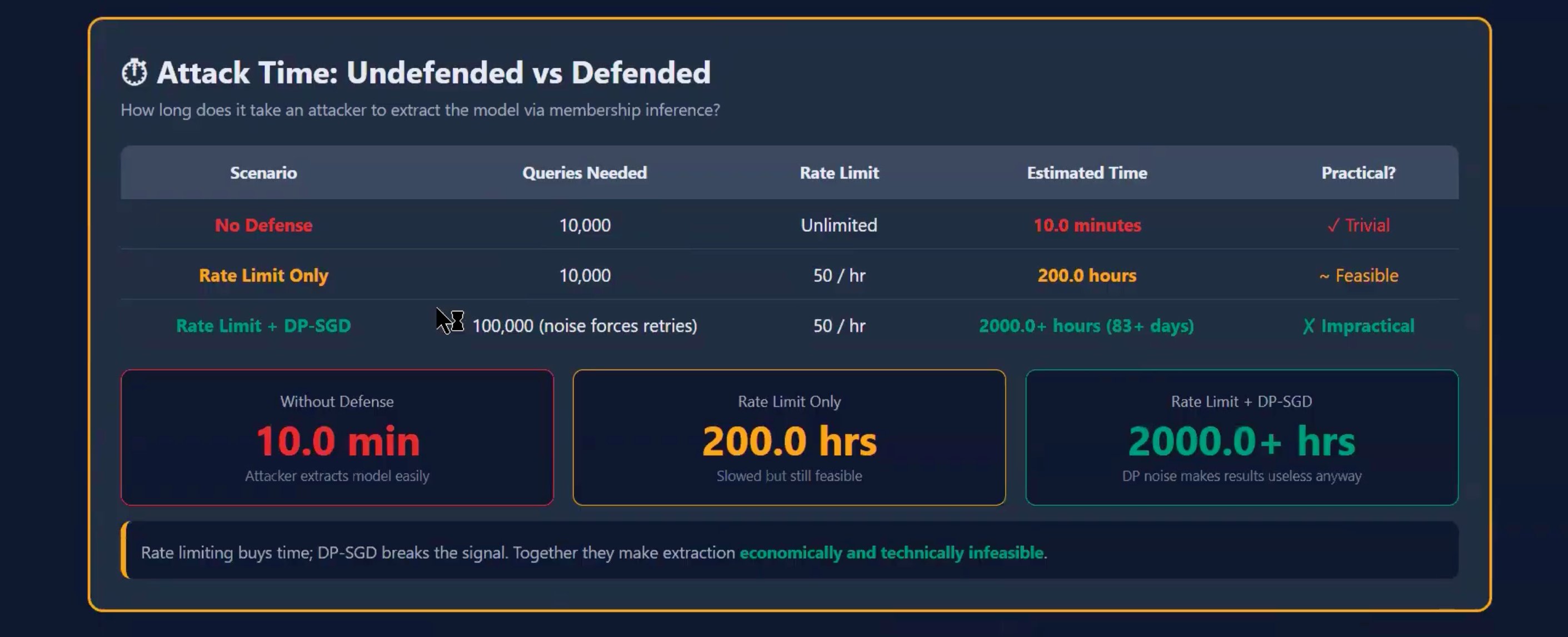
**两种威胁需要两层防御。** 根据 ML-Doctor (2022) 的研究,DP-SGD 实际上会因为平滑决策边界而加剧模型提取。因此,DP-SGD 负责处理 MIA;API 加固负责处理提取。速率限制设为 50 req/hr 后,执行一次 1 万次查询的提取攻击需要耗费 200 多个小时。
**DP 提升了公平性。** 与 Bagdasaryan 等人 (NeurIPS 2019) 的结论相反,DP-SGD 在该金融数据集上将均等化奇偶差异从 0.148 降至 0.052。这是首次在此等规模的真实金融表格数据上同时测量这三项指标。
完整的数值结果:[`results/phase2_results.json`](results/phase2_results.json)
**三重权衡 — 隐私 × 效用 × 公平性:**
**所有 epsilon 值下的 MIA 攻击优势(越低 = 隐私保护越好):**
**三态仪表板 — 正常服务 / 受到攻击 / 启用防御:**
**提取防御 — 有无速率限制 + DP-SGD 的攻击耗时对比:**
## 项目结构
```
sentinelai/
├── api/
│ ├── __init__.py
│ └── main.py # FastAPI: JWT auth, rate limiting, label-only output, PII redaction
├── models/
│ ├── __init__.py
│ └── mlp.py # CreditRiskMLP: 165 -> 256 -> 128 -> 64 -> 2
├── notebooks/
│ └── SentinelAI.ipynb # Full experiment pipeline with all outputs
├── results/
│ ├── phase2_results.json # All experimental metrics
│ └── README.md # Describes all generated output files
├── train_baseline.py # Standalone training script (supports --demo flag)
├── requirements.txt
├── .gitignore
└── README.md
```
模型权重、预处理工件和数据集不包含在 repo 中(参见 `.gitignore`)。所有输出均可通过运行 notebook 复现。
## 快速开始
### 1. 克隆并安装
```
git clone https://github.com/siri423/sentinelai.git
cd sentinelai
# 必须先安装 numpy
pip install numpy==1.26.4
pip install -r requirements.txt
```
### 2. 数据集
**Home Credit Default Risk** — 307,511 条记录,122 个特征,8.1% 的违约率。
从 [Kaggle](https://www.kaggle.com/competitions/home-credit-default-risk/data) 下载。将 `application_train.csv` 放置在 `data/home_credit/` 目录下,或在 notebook 中设置 `DATA_DIR`。
### 3. 在 Google Colab 中运行(推荐用于完整 pipeline)
打开 `notebooks/SentinelAI.ipynb`。将 runtime 设置为 **T4 GPU**。运行 Cell 1,重启 runtime,然后运行所有剩余的 cell。总运行时间:在 T4 上约为 35 分钟。
### 4. 仅训练基线模型(本地)
```
# 在合成数据上的快速演示,无需下载
python train_baseline.py --demo
# 在真实数据集上
python train_baseline.py --data_dir data/home_credit/
```
### 5. 运行 API
```
uvicorn api.main:app --reload --port 8000
# 获取 JWT token
curl -X POST http://localhost:8000/token \
-d "username=demo&password=secret"
# 进行预测(替换 )
curl -X POST http://localhost:8000/v1/predict \
-H "Authorization: Bearer " \
-H "Content-Type: application/json" \
-d '{"features": [0.5, 0.3, 0.8, ...], "applicant_id": "APP_001"}'
# 健康检查(无需 auth)
curl http://localhost:8000/health
```
API 仅返回**标签**(`DEFAULT` 或 `NO_DEFAULT`)。原始概率绝对不会暴露。
## API 防御层
| 层级 | 机制 | 应对威胁 |
|-------|-----------|-----------------|
| 1 | JWT HS256 身份验证 | 未经授权的访问 |
| 2 | 速率限制(每个 IP 50 req/hr) | 模型提取(1 万次查询 = 200 多小时) |
| 3 | 仅输出标签 | 置信度分数窃取 |
| 4 | DP-SGD 训练 | 成员推理 |
| 5 | 日志中的 PII 自动脱敏 | 通过访问日志造成的数据泄露 |
| 6 | Pydantic 输入验证 | 格式错误 / 注入输入 |
| 7 | CORS 中间件 | 跨域攻击 |
## 实现说明
**为什么使用 GroupNorm 而不是 BatchNorm?** Opacus 需要计算样本级梯度。BatchNorm 会聚合整个批次的统计信息,这与上述要求冲突。`GroupNorm(num_groups=1)` 会按样本进行归一化,使得该架构无需更改结构即可完全兼容 DP-SGD。
**为什么使用 SMOTE 增加到 25%,而不是 50%?** 原始数据集的违约率为 8.1%。过采样至 25% 可以平衡学习信号,同时不会生成过多的合成副本,从而避免因人为记忆效应而增加 MIA 的脆弱性。
**为什么仅在训练集上进行插补?** 仅在训练数据上拟合中位数插补器,可以防止验证集和测试集中的信息泄露到预处理环节,否则会导致所有下游评估指标虚高。
## 作者
**Sirichandana Bikkasani** · **Lavanya Kovi** · **Sai Yaswanth Reddy Suram**
计算机科学硕士 / 分析学硕士 · 佐治亚州立大学 · 2026 年春季
标签:Apex, API安全加固, AV绕过, FastAPI, Linux系统监控, PyTorch, 凭据扫描, 差分隐私, 机器学习, 模型安全, 网络安全, 逆向工具, 金融风控, 隐私保护