[](#-status)
[](../../releases/tag/v5.26.0)
[](#-tests)
[](#-tests)
[](LICENSE)
[](https://www.python.org/)
**A desktop app that runs an autonomous external penetration test against a
scope you're authorized to hit — and hands back a markdown report of what it
found and proved. One AI agent, all its memory as plain markdown files, every
tool inside a hardened, network-filtered Kali sandbox.**
## 📖 Table of contents
- [What it is](#-what-it-is) · [Status](#-status)
- [Quick start](#-quick-start) · [The UI](#-the-ui) · [scope.yaml](#-scopeyaml-example)
- [Toolkit](#-toolkit) · [Engine-steps](#-engine-steps) · [OWASP playbooks](#-owasp-playbooks) · [Stealth profiles](#-stealth-profiles)
- [Architecture](#-architecture) · [Safety](#-safety) · [Tech stack](#-tech-stack) · [Tests](#-tests)
- [Roadmap](#-roadmap) · [Notable runs](#-notable-runs) · [Origins](#-origins) · [Philosophy](#-philosophy) · [License](#-license)
## 🎯 What it is
BULWARK is a **desktop app** (native on Windows, with Linux bundles too)
that a professional pentester points at an authorized scope (a domain or
IP range) and walks away from. It comes
back with a clean markdown report covering the full external surface —
services, tech stack, vulnerabilities, confirmed exploits — without ever
leaking the operator's real IP, drifting out of scope, or burning the
engagement budget.
It is **not** a CTF solver, a multi-agent framework, a SaaS, or a
research toy. It is one local app that does one job well, and
progressively more of it over time.
Install the app, point it at a scope, and hit **Start** — no flags, no
scripts, no terminal. The whole engagement plays out across its eight
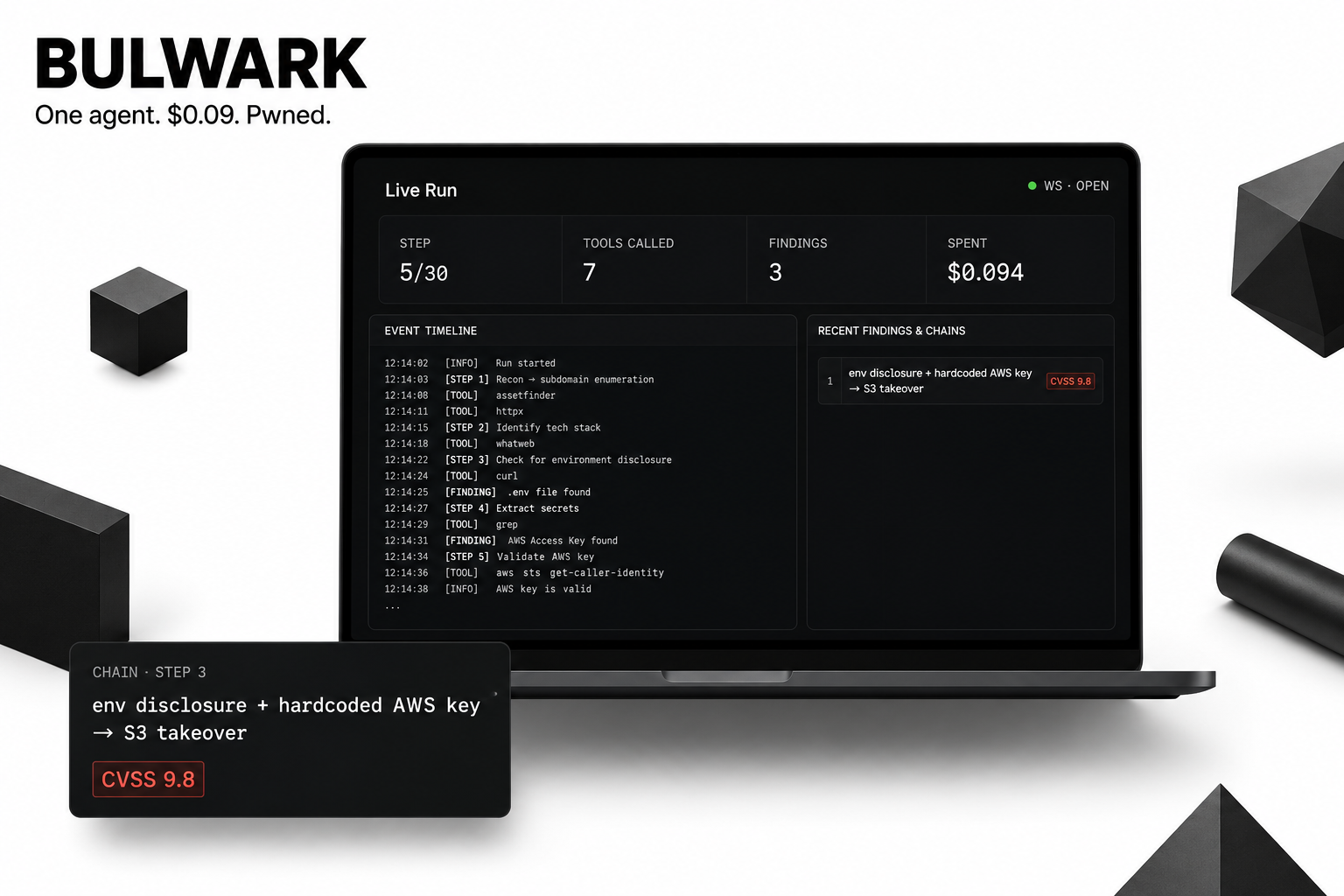
pages: set everything up on **Config**, follow the live timeline on
**Run**, watch the attack surface build on **Graph**, read findings in the
**Vault**, and export the exploit chain from the **Board**. See
[The UI](#-the-ui) for the full tour.
## 🏷 Status
**v5.26.0 — first public release** (current). The product is a Tauri desktop app
(plus a native Windows runtime/installer) + FastAPI sidecar wrapping the
same hand-written ReAct loop the project has shipped since v0. The web UI
received a full refonte from v5.0 onward — workspace tabs · dockable
Inspector · whiteboard at `/board` · then an **institutional black-&-white
restyle**, a **radial agent-activity Flow**, a new **`/graph`
attack-surface route**, an **encrypted Settings page**, and **external
recon intel** (Shodan / Censys / SecurityTrails / VirusTotal). The agent
operates at a **junior-pentester capability with cross-run learning**:
profile-aware recon, multi-signal evidence, HTTP session management with
IDOR detection, sqlmap/ffuf/hydra wrappers, **12 OWASP + CVE-chain playbooks**,
CWE-aware reports with auto-remediation, an offline CVE catalog (103 CVEs
across 30 components), **39 in-code cascade engine-steps**, and a JSONL
lessons store that auto-injects past attack chains on first Host write of
every new engagement.
timeline
title BULWARK · release line (v0 → v5.26.0)
section Engine foundation
v0 core agent : ReAct loop · markdown vault · Scope/Cost/Egress guards · Kali sandbox
v1 LLM power : multi-provider (Claude/Kimi/DeepSeek/GLM) · adaptive thinking
v3 TUI + recon : Textual TUI · 5 OWASP playbooks · recon/http/sqlmap/hydra wrappers
v3.7 engine-steps : cascades introduced (11) · LLMStep + EngineStep playbook union
v3.8 memory : cross-engagement lessons · Jaccard matcher · HTB medium pwn'd
section Web app (TUI retired)
v4.0 FastAPI + React : web UI replaces the Textual TUI
v4.6 → v4.10 : themes · perf sweep · design reset · ⌘K palette · slim sidebar
section UI refonte
v5.0 → v5.2 : escutcheon mark · workspace tabs · dockable Inspector (⌘I)
v5.3 → v5.4 : whiteboard /board · auto chain edges · severity · live · MD export
section Capability + platform
cascades 11 → 39 : SSRF/SSTI/XXE · JWT/OAuth/SAML · Kerberoast/ACL · recon/nuclei · external-intel
intel + settings : Shodan/Censys/SecurityTrails/VirusTotal · encrypted Settings page
graph + flow : /graph attack-surface route · Flow as a radial agent-activity graph
B&W + Windows : institutional black-and-white restyle · native Windows runtime + installer
evidence + plugins : validate_finding gate · vault body contracts · open-core plugin spec
section Now
v5.26.0-public-ready : current · first public release on bulwark-sec
next : CVE catalog expansion · Playwright browser · Nuclei depth
**What works today:**
- 🦴 **One ReAct agent loop** (`for` over `max_steps`, 31 static tools —
70 LLM-facing once the 39 engine-steps are appended). No framework.
- 🌐 **Desktop app + web UI** — the app serves the React UI at
`127.0.0.1:7331`; the native Windows installer and the Linux Tauri
bundle wrap the same sidecar in a native window, behind a `BootGate`
splash that waits on `/health`.
- 🧭 **Workspace tabs** above the TopBar — pinned routes + closeable
vault-file tabs · drag-reorder · localStorage-persisted.
- 🔍 **Dockable Inspector** (⌘I) — right-side panel that follows
`focusedItem`: event JSON on `/run`, frontmatter + body preview on
`/vault`, full chain detail on `/board`.
- 🎨 **Institutional black & white** — white is the single accent
(CTA / active nav / focus); color appears only on CVSS severity bands
and status. Light + dark themes via `data-theme`, persisted across
reloads. No purple, no dot-grid, no glass.
- 🌐 **Radial agent-activity Flow** (`/flow`) — a central AGENT hub with
one node per `tool.call` event, clustered by tool category, built live
from the events store — not a rigid Sankey.
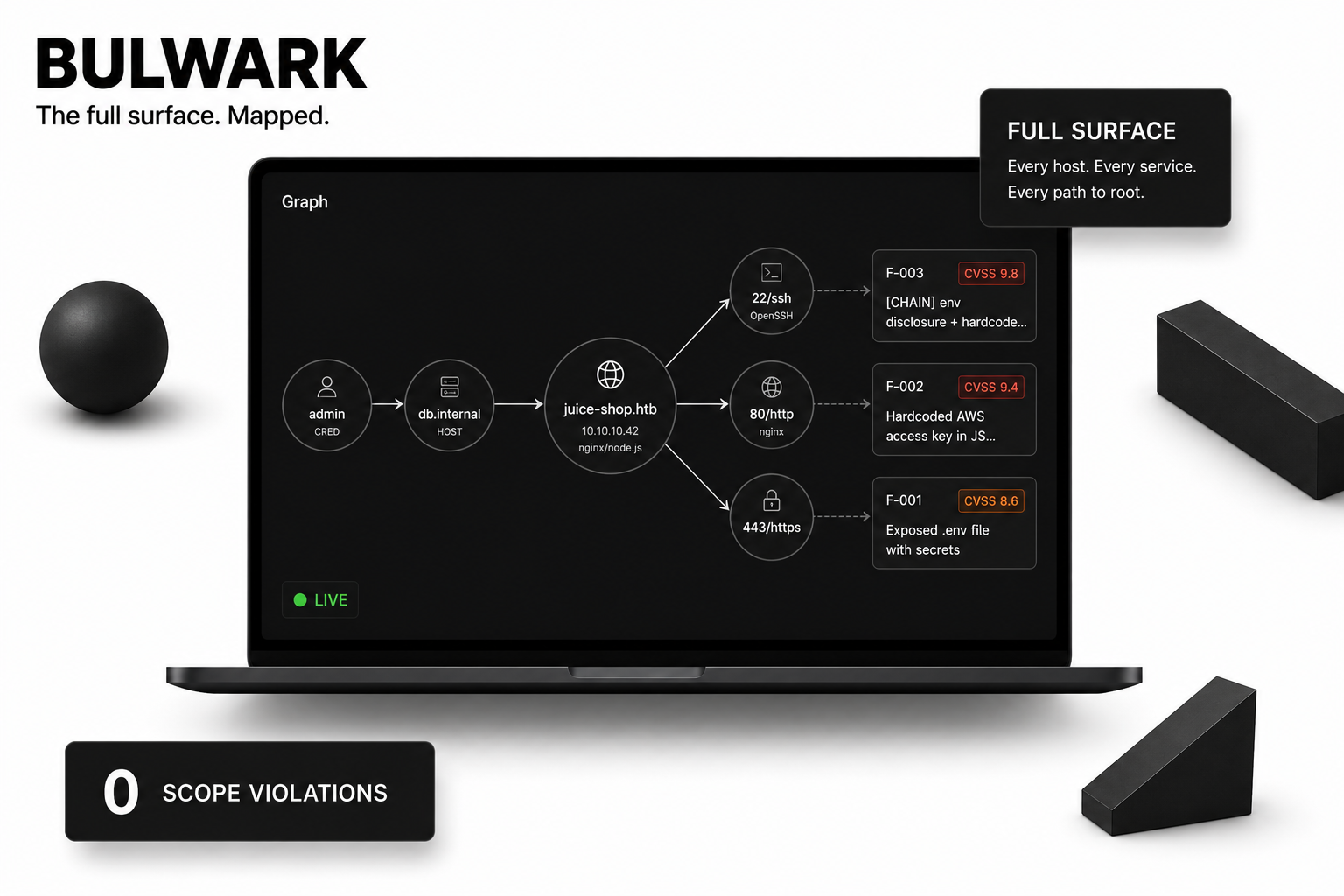
- 🕸️ **Attack-surface Graph** (`/graph`) — a dagre-laid-out graph of
hosts/services/findings/creds + authored overlay, with focus-mode
dimming and animated attack-paths.
- 🪞 **Whiteboard at `/board`** — Figma-style canvas with auto chain
edges from `[CHAIN]` findings, CVSS-band severity strips, status
dots, live pulse on new findings, drag-to-link, Markdown export.
- 🔑 **Encrypted Settings page** (`/settings`) — API keys for the LLM
provider and the recon/OSINT intel sources, stored encrypted, grouped
Recon / OSINT / LLM. Env vars remain an alternative.
- 🛰️ **External recon intel** — Shodan / Censys / SecurityTrails /
VirusTotal lookups, surfaced as engine-step cascades.
- 🛡️ **Layered guards** — Scope (path-aware extraction, profile-aware
blacklist, sandbox-bridge-IP allowlist for OOB callbacks), Cost
(per-model pricing + pre-call gate), Egress (host + container-side),
Audit (hash-chained JSONL + AES-GCM), Sandbox (read-only Kali,
cap_drop ALL).
- 📓 **Markdown vault as memory** — `vault_summary()`, `recall(query,
kind)`, structured Evidence schema with `http_request` / `command` /
`observation` discriminated kinds, plus body-structure contracts (soft
lint surfaced to the agent, INDEX, and viewer).
- 🧾 **Evidence discipline** — engine-step cascades capture REAL
reproducible proof (no fabricated status) and route through
`validate_finding()` before a finding lands.
- ⚡ **39 cascade engine-steps** — SSRF/SSTI/XXE web cascades, JWT /
OAuth / SAML auth cascades, Kerberoast / ASREPRoast / ACL-abuse AD
cascades, recon-sweep / crawl / dns-deep orchestration, nuclei /
exploit-search, and the four external-intel lookups, on top of the
original cmd-injection / LFI / IDOR / mass-assignment / GraphQL set.
- 🌐 **Profile-aware recon** — `loud` runs `nmap -T4` and `subfinder
-all -recursive`; `paranoid` does `-T0` + passive subfinder only.
- 🔓 **Authenticated testing** — `login()`/`logout()` cookie-jar,
`http(use_session=true)`, `auth_state_compare()` IDOR detector.
- 🎯 **OWASP + CVE-chain playbooks** — `web_app_unauth`, `web_app_authed`,
`api_rest_audit`, `graphql_audit`, `low_hanging_files`,
`lfi_exploit`, `target_enum`, `creds_harvest`,
`confirm_command_injection`, `ad_compromise`,
`nextjs_middleware_bypass` (CVE-2025-29927), `ml_pickle_rce`. Each
playbook mixes LLM-steps and engine-steps.
- 📊 **CWE-aware reports** — 20-entry library auto-renders remediation.
CVSS vector field. Auto exec_summary built from vault.
- 🌍 **CVE lookup** — `cve_lookup(component, version)` against a
bundled offline catalog of **103 CVEs across 30 components**
(frameworks, servers, databases, and the Log4Shell / Confluence /
Struts class). Severity-ranked, alias-aware, version-filtered.
- 🐺 **Validated** — HTB easy `10.129.51.155` pwn'd autonomously in 88
steps for $0.93 (both flags retrieved); HTB medium pwn'd autonomously
(JWT alg=none → SSH CA → root).
## 🚀 Quick start
### Desktop app (recommended)
Download the latest bundle for your platform from the
[Releases](https://github.com/bulwark-sec/bulwark/releases) page and launch
it — no Python / Node / build step on your side:
- **Windows** — the native installer / runtime (`BULWARK-Setup.exe`).
- **Linux** — `.AppImage` / `.deb` / `.rpm`.
On first engagement it pulls the ~2.2 GB sandbox image (progress shows
on `/run`).
### From source (dev)
# 1. Clone + install (needs Python 3.12, uv, and Node 22 for the UI build)
git clone https://github.com/bulwark-sec/bulwark.git
cd bulwark
uv python install 3.12
uv sync
bash scripts/build_frontend.sh # build the web UI (editable installs don't)
# 2. Set ONE LLM provider's API key (or enter keys in the encrypted /settings page)
export ANTHROPIC_API_KEY=sk-ant-... # Claude (default model: claude-sonnet-4-6)
export DEEPSEEK_API_KEY=sk-... # DeepSeek (default: deepseek-v4-pro)
export KIMI_API_KEY=sk-kimi-... # Kimi (kimi-k2.6) / Kimi for Coding (kimi-for-coding)
export GLM_API_KEY=... # GLM (default: glm-5.1)
# 3. Launch the app — serves the UI at 127.0.0.1:7331 and opens your browser
uv run bulwark run
# …or build the native desktop bundle instead:
bash scripts/build_desktop.sh
./src-tauri/target/release/bundle/appimage/BULWARK_amd64.AppImage
📖 **Full step-by-step — demo, real run, sandbox image, troubleshooting:
[INSTALL.md](INSTALL.md).**
The first engagement auto-pulls the bundled Kali sandbox image — no
manual `docker build`. The UI handles target / provider / API key /
budget / profile / auth.pdf in a form on `/config`. Hit Start → sandbox
spins up → engagement runs → live timeline on `/run`, attack-surface on
`/graph`, findings on `/vault`, keys on `/settings`, board on `/board`.
Engagements are configured in the web UI (`/config`). For unattended batch
benchmarking against a list of boxes there's a separate non-interactive path:
uv run bulwark bench run path/to/boxes.yaml --sprint-tag my-run
## 🖥 The UI
The web app ships at `127.0.0.1:7331` (the Tauri desktop bundle and the
Windows runtime serve the same React bundle from the FastAPI sidecar). **Eight top-level pages**, all reachable from the slim 60px
sidebar OR via ⌘K:
| Page | Path | What it does |
|------------|-------------|-----------------------------------------------------------------|
| Config | `/config` | Engagement setup form + Advanced ▸ (max_steps, thinking, etc.) |
| Run | `/run` | Live event stream · stat cards · filter chips · click → ⌘I inspector |
| Flow | `/flow` | Radial agent-activity graph — central AGENT hub, one node per `tool.call`, clustered by tool category, built live from the events store |
| Graph | `/graph` | Attack-surface graph (hosts/services/findings/creds + authored overlay, focus-mode dimming, animated attack-paths) |
| **Board** | `/board` | **Whiteboard canvas — auto chain edges, severity strips, live pulse, MD export** |
| Vault | `/vault` | Browse the engagement's markdown tree, with frontmatter cards (labelled **Findings** in the nav) |
| Bench | `/bench` | Benchmark dashboard — HTB pwn-rate aggregates across runs |
| Settings | `/settings` | Encrypted API keys (Recon / OSINT / LLM groups) |
*(`/` redirects to `/config`.)*
**Cross-page primitives** (above the routes):
- **Workspace tabs** — strip between the sidebar and the TopBar. Pinned
for routes (Config / Run / Flow / Graph / Board / Vault / Bench /
Settings), closeable for vault files. Drag-reorder. Persisted across
reloads.
- **TopBar** — ⌘K palette button · active engagement id · status pill
(`running` / `done` / `failed`) · Inspector toggle · theme toggle.
- **Inspector dock** (⌘I) — right-side panel that follows the focused
item. Resizable 280-720px. Persisted open/closed + width.
- **Command palette** (⌘K) — fuzzy command launcher.
Categories: Navigate · Engagement · Theme · Help.
- **BootGate** — splash that blocks the App from mounting until
`/health` returns 200, so a cold start never lands you on an
empty page with broken queries.
## 📄 scope.yaml example
engagement:
client: acme
date: 2026-05-10
authorization:
hash: sha256:0123456789abcdef... # SHA-256 of the signed authorization PDF
signed_pdf: ./auth-acme.pdf
scope:
domains:
- acme.com
- "*.acme.com" # wildcard subdomains allowed
ips:
- 203.0.113.0/24 # CIDR ranges (IPv4 and IPv6)
excluded:
- admin.acme.com # explicitly excluded — blocked even if matched by wildcard
egress:
provider: mullvad
expected_ip: 185.213.155.74 # your VPN exit IP (ipify-verified)
budget_usd: 10.0 # hard kill-switch (kills before this is exceeded)
stealth_profile: stealth # loud | normal | stealth | paranoid
## 🛠 Toolkit
The agent has **31 static tools** (70 LLM-facing once the 39 engine-steps
are appended). Categorized by purpose:
| Category | Tools |
|---|---|
| **Vault as memory** | `vault_summary` · `recall` · `read_note` · `write_note` · `update_note` · `list_notes` · `search_vault` · `recall_past_attacks` |
| **Recon (profile-aware)** | `recon(intent, target)` — wraps `subfinder` / `nmap` / `httpx` / `nuclei` with profile-aware flags · `register_vhost` (virtual-host pinning) |
| **Attack-surface graph** | `graph_summary` · `graph_add` — feed/query the typed nodes/edges behind `/graph` |
| **External knowledge** | `cve_lookup(component, version)` — offline catalog (103 CVEs across 30 components: express, nginx, apache, php, openssh, django, spring, log4j, struts, …) |
| **External recon intel** | Shodan / Censys / SecurityTrails / VirusTotal lookups (engine-step cascades, keyed from `/settings`) |
| **HTTP probing** | `http(method, url, headers?, body?, use_session?, follow_redirects?)` — structured response |
| **Headless browser** | `browser(op)` — headless Chromium for JS-heavy / SPA targets (navigate · screenshot · evaluate · intercept_xhr · fill_login · dom_xss_probe) |
| **Authenticated testing** | `login(url, body, headers)` (cookie-jar) · `logout()` · `auth_state_compare(url)` IDOR detector |
| **Vulnerability confirmation** | `sqlmap_run` · `dir_brute` · `hydra_brute` · `jwt_inspect` · `jwt_forge` · `crack_hash` |
| **OWASP playbooks** | `run_playbook(name, target)` returns checklist for the 12 bundled playbooks |
| **Post-exploitation** | `target_shell` (stateful PTY) · `reverse_listener` · `payload_gen` · `pivot` (SOCKS5 forward) · `upload_file` |
| **Engine-steps (cascade in code)** | 39 in-code cascades — see [Engine-steps](#-engine-steps) below |
| **Escape hatch** | `execute(cmd)` — raw shell when wrappers don't fit |
Each tool is dispatched via the tool-dispatch layer after `ScopeGuard.check()`. Output is captured to the audit log. Findings get written through the same vault tools and routed through `validate_finding()`.
## ⚡ Engine-steps
Engine-steps are the v3.7 evolution of vulnerability confirmation,
grown to a **39-cascade surface** at v5.25.0: cascades that grind
through 5-10 variants **in code** without paying LLM cost per variant.
The agent calls one engine-step tool, the engine runs the cascade
internally, captures REAL reproducible proof, routes it through
`validate_finding()`, writes a Finding directly when any method
confirms, and returns a structured
`StepResult(passed, finding_id, evidence, message, next_hint)` to the LLM.
The 39 engine-steps currently shipped, by category:
| Category | Engine-steps |
|---|---|
| **Command injection / files** | `confirm_cmd_injection` (5 methods: OOB · PCAP-size delta · output reflection · error injection · time-delay) · `scan_low_hanging_files` (~30 paths) · `lfi_payload_cascade` (traversal · php://filter · log-poisoning RCE · nullbyte) |
| **Web logic** | `idor_cascade` · `mass_assignment_cascade` · `rest_verb_tampering` · `rest_header_injection` · `param_mining_cascade` · `api_schema_discover` |
| **Injection (SSRF/SSTI/XXE)** | `ssrf_probe_cascade` · `ssti_engine_id_cascade` · `xxe_oob_cascade` |
| **GraphQL** | `graphql_introspection_probe` · `graphql_batching_probe` |
| **Auth / tokens** | `jwt_audit_cascade` · `jwt_replay_cascade` · `oauth_audit_cascade` · `saml_xsw_cascade` |
| **Active Directory** | `ad_anonymous_enum_cascade` · `kerberoast_cascade` · `asreproast_cascade` · `acl_abuse_cascade` · `esc8_relay_chain` |
| **Credentials** | `default_creds_cascade` (~30 combos) · `creds_extract_pcap` (tshark) |
| **Recon / orchestration** | `recon_sweep` · `crawl` · `dns_deep` · `nuclei_run` · `exploit_search` · `cloud_bucket_hunt` · `jar_decompile_extract` |
| **External intel** | `shodan_lookup` · `censys_lookup` · `securitytrails_lookup` · `virustotal_lookup` |
| **OSINT / evasion** | `osint_leak_hunt` · `js_recon_extract` · `waf_bypass_cascade` |
Each engine-step:
- Goes through `ScopeGuard.check()` + audit log on every probe (`ctx.http()` / `ctx.exec()` helpers do this transparently).
- Captures REAL reproducible evidence and routes through `validate_finding()` — no fabricated status.
- Writes the Finding directly when its cascade hits a positive signal (no extra LLM round-trip).
- Returns `StepResult(passed=True, finding_id="F-NNN", evidence=[...], next_hint="...")` so the LLM knows what to do next.
- Has unit tests for every cascade branch (3-12 tests per step) and is `@pytest.mark.integration` for end-to-end.
## 🎯 OWASP playbooks
The agent doesn't grope around. When asked to probe a target, it pulls a playbook. Each playbook is a mix of `[LLM]` steps (manual probes the agent decides on) and `[ENGINE]` steps (cascades that run in code). The `_PLAYBOOKS` registry ships **12 playbooks** (the `run_playbook` enum is derived from the registry, so it can never drift out of sync):
| Playbook | When to run | Engine-steps it composes |
|---|---|---|
| **`low_hanging_files`** | **Always run first** | `scan_low_hanging_files` (the 30-path cascade) |
| `web_app_unauth` | First on a fresh web target | `scan_low_hanging_files` + manual nuclei/dir_brute steps |
| `web_app_authed` | After login | `idor_cascade` + `mass_assignment_cascade` + manual probes |
| `api_rest_audit` | Target exposes /api/* | `rest_verb_tampering` + `rest_header_injection` + JWT cascades |
| `graphql_audit` | /graphql or /graphiql reachable | `graphql_introspection_probe` + `graphql_batching_probe` |
| `lfi_exploit` | LFI signal surfaced | `lfi_payload_cascade` + manual log-read confirmation |
| `creds_harvest` | Services exposed + PCAPs available | `creds_extract_pcap` + `default_creds_cascade` |
| `target_enum` | Always second | All-LLM (recon orchestration) |
| `confirm_command_injection` | Cmd-injection candidate found | `confirm_cmd_injection` (the flagship 5-method cascade) |
| **`ad_compromise`** | AD domain controller reachable | `ad_anonymous_enum_cascade` + `kerberoast_cascade` + `asreproast_cascade` + `acl_abuse_cascade` + `esc8_relay_chain` |
| `nextjs_middleware_bypass` | Next.js app with a middleware-gated route | All-LLM CVE-2025-29927 chain: `x-middleware-subrequest` bypass → loot protected APIs → foothold |
| `ml_pickle_rce` | App loads an uploaded/registered ML model (MLflow, sklearn/joblib) | All-LLM chain: forge a `__reduce__` pickle → trigger load → RCE → reverse shell |
Each playbook renders as a markdown checklist with `[LLM]` or `[ENGINE]` labels and explicit `Call: (args)` hints so the agent knows when to grind cascades in code vs decide manually. See the `agent/playbooks.py` module.
## 🥷 Stealth profiles
Pentest engagements aren't all the same. BULWARK ships four profiles:
| Profile | Use case | Time cost | Detection probability |
|---|---|---|---|
| **loud** | Lab, CTF, "scan-as-loud-as-you-want" | 1× | 100% — you don't care |
| **normal** *(default)* | Standard engagement | 2-3× | ~80% on scan |
| **stealth** | Client wants to measure their detection | 5-10× | ~30% passive, ~60% active |
| **paranoid** | Long-duration red team simulation | 20-50× | <10% on recon |
The profile drives `recon()` flags, `ScopeGuard`'s blacklist tier, AND the post-exploitation tools' availability:
- **loud** → `nmap -T4`, `subfinder -all -recursive`, nuclei rate 150 req/s. Aggressive nmap timing patterns lifted from the blacklist. All post-ex tools available.
- **normal** → defaults across the board. `target_shell`, `reverse_listener`, `payload_gen`, `pivot` available.
- **stealth** → no `nmap -T4/-T5`, no aggressive brute, post-ex tools blocked at dispatch.
- **paranoid** → `nmap -T0`, `subfinder` passive sources only, nuclei rate 1 req/s, jitter ±80%, post-ex blocked.
ALWAYS-blocked patterns (regardless of profile): `rm -rf /`, `mkfs`, fork bomb, `dd if=/dev/zero`, `eval $(...)`, `nc -e`, `curl ... | sh`, `bash <(curl)`.
## 🏗 Architecture
flowchart TB
classDef host fill:#0A0A0A,stroke:#FFFFFF,color:#FFFFFF;
classDef panel fill:#111111,stroke:#FFFFFF,color:#FFFFFF;
classDef store fill:#0A0A0A,stroke:#888888,color:#FFFFFF;
classDef guard fill:#111111,stroke:#FFFFFF,color:#FFFFFF,stroke-width:2px;
classDef ok fill:#0A0A0A,stroke:#22C55E,color:#FFFFFF,stroke-width:2px;
classDef danger fill:#1A1A1A,stroke:#CC0000,color:#FFFFFF,stroke-width:2px;
subgraph HOST["HOST · operator laptop"]
direction TB
UI["UI layer React SPA + FastAPI sidecar · BootGate · 8 routes"]:::panel
subgraph BRAIN["Agent core"]
direction TB
AGENT["Agent loop ReAct · no framework"]:::host
ENGINE["Engine-steps registry 39 cascades"]:::panel
VALIDATE(["validate_finding evidence gate"]):::ok
end
subgraph INTEL["Recon + projection"]
direction TB
RECON["Recon intel Shodan/Censys/STrails/VT"]:::store
GRAPHPKG["Attack-surface graph builder + overlay"]:::store
WATCH["Watch baseline · scanner · notifier"]:::store
end
VAULT[("Vault markdown · Evidence · contracts")]:::store
AUDIT[("Audit log hash-chained · AES-GCM")]:::store
REPORT["Report engine CWE · auto exec_summary"]:::panel
subgraph GUARDS["Guards · every probe"]
direction LR
SCOPE["Scope"]:::guard
COST["Cost"]:::guard
EGRESS["Egress"]:::guard
end
end
subgraph SANDBOX["DOCKER · hardened sandbox"]
KALI["Kali container read-only · cap_drop ALL · non-root"]:::host
end
subgraph NET["NETWORK"]
direction TB
VPN(["VPN / proxy verified host + container"]):::ok
TARGET["Authorized target scope IPs only"]:::danger
end
UI --> AGENT
UI --> RECON
AGENT --> ENGINE
AGENT --> VAULT
ENGINE --> VALIDATE --> VAULT
RECON --> VAULT
VAULT --> GRAPHPKG --> UI
WATCH --> VAULT
VAULT --> REPORT
AGENT -. probes .-> GUARDS
ENGINE -. probes .-> GUARDS
AGENT --> AUDIT
ENGINE --> AUDIT
GUARDS ==>|"docker exec · host socket NOT mounted"| KALI
KALI ==>|"ops-net + iptables egress filter"| VPN
VPN ==> TARGET
The host process runs the agent; the React SPA + FastAPI sidecar (served
by the desktop app and the Windows runtime) is the entry layer. Three
backend packages support the recon/graph surface: `recon/` (external
intel), `graph/` (attack-surface builder + overlay behind `/graph`), and
`watch/` (baseline / scanner / notifier). The web API now
exposes seven route modules: `engagements`, `uploads`, `vault`, `bench`,
`util`, plus `graph` (backs `/graph`) and `settings` (backs the encrypted
`/settings` keys).
**Key invariants:**
1. **Agent process runs on host**, not in the container. `docker.sock` is used by the agent, never mounted into the sandbox.
2. **Engine-steps run on host too** — they orchestrate cascade probes that go through the same `ScopeGuard` + audit + sandbox-execute path as the agent's classic tool calls, and route confirmed proof through `validate_finding()`.
3. **Egress is checked from inside the container** — the host can have VPN green while the container leaks; we check both.
4. **Every shell command** the LLM emits goes through `ScopeGuard.check()` first (target extraction, profile-aware blacklist, sandbox-bridge-IP allowlist for OOB callbacks), THEN through the iptables egress filter at the network layer.
5. **The vault is the source of truth.** The LLM context is jetable — at any point we can crash, restart, and resume from the vault via `vault_summary()` + `recall()`. The `/graph` view is a derived, in-memory projection of the vault + authored overlay, NOT a persistent graph database.
## 🛡 Safety
This is a **defensive-first** offensive tool. The threat model includes a misbehaving LLM (jailbreak, hallucination, going rogue). Defenses are layered:
| Layer | What it does | Where it lives |
|---|---|---|
| 1 | **ScopeGuard.check(cmd)** — extracts targets (IPv4/IPv6/URLs/hostnames) excluding body/header/cookie/UA values, file-extension paths, and Python module args. Profile-aware blacklist tier. Sandbox-bridge-IP auto-allowlisted for OOB callbacks. | Python, before every `execute()` and engine-step probe |
| 2 | **iptables egress filter** — DROP by default, ALLOW only resolved scope IPs + LLM provider hosts | Host network, on `ops-net` bridge |
| 3 | **Container hardening** — read-only rootfs, cap_drop ALL, no-new-privileges, non-root user, disposable `--rm`, /tmp tmpfs only | Docker runtime |
| 4 | **Hash-chained audit log** — every tool call + engine-step result + guard decision, SHA-256 chained, optionally AES-GCM at rest | Filesystem (per engagement dir) |
| 5 | **CostGuard.will_exceed()** — pre-call gate prevents one-call-too-many overage on hard budgets | Python, before each LLM call |
| 6 | **EgressGuard** — verifies VPN host-side AND container-side; freezes everything if exit IP drifts mid-session | Python + Sandbox.execute() |
## ⚙ Tech stack
**Backend (engine + sidecar)**
- **Python 3.12** — modern syntax, PEP 695 generics
- **uv** — package & venv manager
- **pydantic 2.x** — every config + Evidence schema validated, discriminated unions
- **FastAPI + uvicorn** — local web backend (`/api/*`, WS `/ws/events`)
- **Anthropic SDK** — primary LLM client (`ClaudeClient`); default model `claude-sonnet-4-6`, with prompt caching + adaptive thinking
- **OpenAI-compatible SDK** — `OpenAICompatibleClient` fronts DeepSeek (`deepseek-v4-pro`), Kimi (`kimi-k2.6`), Kimi for Coding (`kimi-for-coding`), GLM (`glm-5.1`). Six selectable `--provider` names (claude, claude-code, deepseek, kimi, kimi-code, glm) across four vendors via two client classes.
- **docker SDK** — sandbox isolation (mocked in tests)
- **Jinja2** — report rendering
- **cryptography** — AES-GCM for audit log; encrypted at-rest key storage for `/settings`
- **scapy** (dev) — PCAP fixture generation for `creds_extract_pcap` tests
- **mypy strict** + **ruff** + **pytest** — clean across the entire codebase
**Frontend (web UI)**
- **React 19** + **Vite 8** + **TypeScript** — built into a static
bundle, served by FastAPI from the wheel
- **Tailwind v4** (CSS-first, no `tailwind.config.js`) with custom
properties for the institutional black & white palette — monochrome
surfaces, white as the single accent, color only on security data
(severity bands / status)
- **TanStack Query 5** — server-state cache for engagements, vault
tree, findings-summary
- **Zustand 5** — UI store: theme · engagementId · events · paletteOpen ·
tabs · activeTabId · inspectorOpen · inspectorWidth · focusedItem
- **React Router 7** — routes are tab-aware via the sync hook
- **dagre** — attack-surface graph layout for `/graph`
- **framer-motion** — `Reorder` for workspace tabs, intro animations
- **lucide-react** — icon set
**Desktop shell**
- **Tauri 2.11** (Rust) — bundles the FastAPI sidecar + the static React
build into an AppImage / .deb / .rpm on Linux.
- **Native Windows runtime + installer** — a Windows packaging path
(v5.23-windows-installer / v5.23.1-windows-portability /
v5.23.2-windows-runtime) ships the same sidecar + UI as a Windows app.
- **PyInstaller** — freezes the FastAPI server + dependencies into a
single-file binary that the desktop shells ship as the sidecar.
**Explicitly not used** (and never will be): LangGraph, LangChain,
CrewAI, AutoGen, LiteLLM, **Neo4j, vector DB**. The agent loop is a
hand-written `for`, and memory is the markdown vault — not a graph or
vector database. The new `/graph` attack-surface route (`Graph.tsx` +
`web/api/routes/graph.py`) is a *derived, in-memory* typed-node/edge
projection of the vault + authored overlay, NOT a persistent graph DB.
## 🧪 Tests
uv run pytest # all unit tests
uv run pytest -m "not integration" # unit only (default)
uv run pytest -m integration # requires Docker + image
uv run pytest --cov=src # coverage report
cd web/ui && npm test # frontend vitest suite
The suite is **1900+ test functions across 176 files** (mypy strict +
ruff clean, all green before tag):
| Test surface | Notes |
|---|---|
| Agent loop · tools · prompts · playbooks | ReAct loop, dispatch, system prompt sections, 12 OWASP + CVE-chain playbooks |
| Engine-steps (39 modules + framework) | Per-cascade-method positive + negative + orchestrator. Framework: StepResult / StepContext / register_step / dispatch · `validate_finding()` |
| Audit · CLI · config | Hash chain, AES-GCM, --scope routing, env-var provider inference |
| CWE library · CVE catalog | Coverage, alias resolution, version filtering (103 CVEs / 30 components) |
| Guards (Scope · Cost · Egress) | IPv6, wildcard, file-extension filter, body/header strip, profile-aware blacklist, internal_ips bridge-IP allowlist |
| LLM clients (Claude / Kimi / DeepSeek / GLM) | Provider clients, retry, headers |
| Report engine · stealth | Auto exec_summary, CWE remediation lookup, profile presets |
| Sandbox · post-ex (sessions / listeners / payload-gen / pivot) | Container lifecycle, bridge_ip, ShellSession + RelayShellSession, FIFO listener handoff |
| Recon intel · graph · watch | Shodan/Censys/SecurityTrails/VirusTotal lookups, attack-surface builder + overlay, baseline/scanner/notifier |
| Web API routes (engagements / uploads / vault / bench / util / graph / settings) | FastAPI TestClient · validation · path-traversal guards |
| Vault (store + schema) | Evidence discriminated union, CWE pattern, frontmatter + body-structure contracts |
| Frontend (vitest) | Zustand store: tabs, inspector, focusedItem · URL → tab id helpers · WS subscription |
| **Goal** | mypy strict + ruff clean · all green before tag |
## 🗺 Roadmap
**Shipped (each tagged on the `master` branch):**
- ✅ **v0** — 10-phase foundation: ReAct loop, vault, guards, sandbox, LLM clients, report engine, CLI
- ✅ **v0.5-stabilization** — audit hardening, V0.5 feedback suffix, frontmatter completeness rejection
- ✅ **v1-llm-power** — multi-provider (Claude/Kimi/DeepSeek/GLM), adaptive thinking, ReasoningBlock round-trip
- ✅ **v2-tui-live** — opt-in Textual fullscreen TUI alongside V1 streaming
- ✅ **v2.1-wizard** — questionary CLI wizard for scope.yaml
- ✅ **v3-tui** — single-command Textual app (ConfigScreen → RunScreen → chat REPL); wizard removed
- ✅ **v3.1-agent-leveling** — recon/sqlmap/dir_brute/hydra wrappers · 5 OWASP playbooks · HTTP session management · Evidence multi-signal · ScopeGuard hardening
- ✅ **v3.2-report-quality** — CWE library + auto-remediation · CVSS vector field · auto exec_summary
- ✅ **v3.3-cve-lookup** — offline CVE catalog (started at 5 components × ~5 CVEs; since grown to **103 CVEs across 30 components**) · http() follow_redirects · session jar persistence · profile-aware caps
- ✅ **v3.5.1-sandbox-tooling** — new Kali tools (smbclient, crackmapexec, evil-winrm, impacket-*, nuclei, kerbrute, …)
- ✅ **v3.6-post-foothold** — `target_shell`, `reverse_listener`, `payload_gen`, `pivot` (SOCKS5) · ShellSession + ReverseListener
- ✅ **v3.6.4-rce-chain** — bridge-IP allowlist for OOB callbacks · RelayShellSession FIFO handoff · validated by HTB easy box pwn'd autonomously in 88 steps for $0.93
- ✅ **v3.7-engine-steps** — engine-steps introduced (11 cascades at the tag; **39 today**) · LLMStep | EngineStep playbook union · system.md addendum
- ✅ **v3.8-cross-engagement-memory** — JSONL lessons store · Jaccard matcher with version-stripping · `recall_past_attacks` tool · `bulwark commit-lessons` operator review gate · validated HTB medium pwn'd autonomously (JWT alg=none → SSH CA → root)
- ✅ **v4 (web app)** — FastAPI + React replaces the Textual TUI · ⌘K command palette · light/dark themes
- ✅ **v5.0 → v5.4 (web + UI refonte)** — real BULWARK escutcheon mark · workspace tabs · dockable Inspector (⌘I) · whiteboard at `/board` (auto chains · severity · live · MD export)
- ✅ **v5.5 → v5.25 (capability + platform)** — engine-step surface grown to **39 cascades** (SSRF/SSTI/XXE, JWT/OAuth/SAML, Kerberoast/ASREPRoast/ACL, recon/crawl/nuclei, external-intel); **external recon intel** (Shodan/Censys/SecurityTrails/VirusTotal); **encrypted Settings page**; new **`/graph` attack-surface route**; **Flow rebuilt** as a radial agent-activity graph; **institutional black-&-white restyle**; **native Windows runtime + installer**; **vault body-structure contracts**; the **evidence-discipline pass** (validate_finding gate)
- ✅ **v5.26.0-public-ready** — current; first release on bulwark-sec/bulwark under the AGPL-3.0 license
**Next sprints:**
- 🔮 **Open-core + paid capability plugins** — designed/spec'd in
[docs/plugin-architecture-spec.md](docs/plugin-architecture-spec.md):
a safety-critical open-core trunk vs paid capability plugins (auth,
web, AD, post-ex, …) with per-plugin entitlement, so the trunk stays
minimal and auditable while the surface grows.
- 🔮 **Offensive depth** — see
[docs/offensive-capability-roadmap.md](docs/offensive-capability-roadmap.md):
CVE catalog expansion (NVD feed), Playwright-driven browser, deeper
Nuclei orchestration, further SSRF/SSTI/XXE coverage.
## 🔥 Notable runs
**Run on 2026-05-09 (v3.6.4)** — kimi-code, profile=loud, budget=$5, max_steps=180:
| Metric | Value |
|---|---|
| Target | HTB easy `10.129.51.155` (fresh box, no operator hand-holding) |
| Outcome | **Both flags retrieved autonomously** (`user.txt` + `root.txt`) |
| Cost | **$0.93** total |
| Steps used | **88 / 180** (ended naturally on `end_turn`) |
| Findings | 3 confirmed (cmd-injection candidate marked `not_exploitable` honestly, PCAP cred leak confirmed, capability privesc confirmed) + 1 credential captured |
| Scope violations | **0** (BUG-006 sandbox-bridge-IP fix held up) |
| Notable | Agent self-pivoted from a brittle cmd-injection path to PCAP-cred-leak → SSH login → `getcap -r /` → `/usr/bin/python3.8 cap_setuid` → root.txt. Honest path adaptation, not blind retry. |
This was the first time BULWARK retrieved an HTB flag autonomously without any operator nudge. The validation that mattered: the agent honestly marked an unconfirmed cmd-injection as `not_exploitable` instead of fake-confirming, then found a different exploitation path on its own.
**Run (v3.8) — HTB medium, autonomous:** JWT `alg=none` forge → SSH CA
signing abuse → root. Validated the cross-engagement memory line: the
lessons store auto-injected the prior chain on the first Host write.
Subsequent work (through v5.26.0) added the recon-intel
layer, the attack-surface graph, the encrypted Settings flow, the
institutional B&W restyle, and the native Windows runtime — the engine
underneath these runs is unchanged.
## 🐺 Origins
**BULWARK** is a defender's framing for what is still an offensive
tool — a wall the client raises against real adversaries by paying a
friendly one to test it first. The brand mark in the desktop window's
sidebar is an inline SVG escutcheon-in-block rendered in `currentColor`
(`App.tsx` `BulwarkMark`): monochrome, theme-flipping, no glow — in
keeping with the institutional black & white identity.
The name points at one posture: authorized recon, patient
enumeration, inevitable foothold. The tool returns with proof, not
theatrics.
## 🦴 Philosophy
Six constraints we self-impose. Removing any of them turns BULWARK
into another LangGraph zoo:
1. **One ReAct agent.** Not seventeen, not five, not "a planner + an
executor". One. The hand-written `for` loop is the agent.
2. **Markdown vault.** Not Neo4j, not Pinecone, not RAG. Files on
disk that the LLM reads with its tools and that an operator can
`vim` at any moment. Queryable via `recall()`, summarised via
`vault_summary()`. (The `/graph` view is a derived projection of
the vault, not a graph database.)
3. **No agentic framework.** No LangGraph, no LangChain, no CrewAI,
no AutoGen, no LiteLLM. Two hand-written client
classes (`ClaudeClient` + `OpenAICompatibleClient`) front six
selectable providers across four vendors.
4. **Stealth-first defaults.** XBOW optimizes for "fast and loud,
you're authorized". BULWARK optimizes for "the client should
learn whether their detection works".
5. **Threat actor in posture, sober in claim.** Silent, patient,
inevitable. We don't oversell what we deliver, we show the work:
real audit-logged engagements, honest dead-ends documented, flags
captured or not — with evidence routed through `validate_finding()`.
6. **One surface.** Everything happens in the app — set up, run, read,
export. No flag soup, no intermediate scripts, no terminal.
## 🔒 Security
See [SECURITY.md](./SECURITY.md). **Authorized use only.** BULWARK is
built for engagements where the operator has explicit written
authorization. Running it against systems you don't own or have
written permission to test is illegal in most jurisdictions.
## 🎨 Media kit
Brand reference — institutional palette · typography
**Palette (institutional black & white, web UI v5.x)** — the active
brand. Defined as CSS custom properties keyed off `data-theme`. White is
the single accent; color appears ONLY on security data (severity bands
and status), never as ornament.
| Token | Dark | Light | Used for |
|--------------------|----------------------------|----------------------------|-------------------------------------------|
| `--color-bg` | `#0A0A0A` | `#FFFFFF` | app background |
| `--color-fg` | `#FFFFFF` | `#0A0A0A` | primary text |
| `--color-muted` | `rgba(255,255,255,.55)` | `rgba(0,0,0,.55)` | secondary text |
| `--color-panel` | `#111111` | `#FFFFFF` | cards, panels, sidebars |
| `--color-panel-2` | `#1A1A1A` | `#F4F4F4` | elevated / hover surface |
| `--color-border` | `rgba(255,255,255,.10)` | `rgba(0,0,0,.12)` | hairline borders |
| `--color-accent` | **`#FFFFFF`** | **`#0A0A0A`** | the single accent · CTA · active nav · focus |
| `--color-success` | `#22C55E` | `#1A7A3A` | live / ok status |
| `--color-warning` | `#E85D00` | `#B8480A` | candidate status |
| `--color-danger` | `#CC0000` | `#B00000` | failed status |
**Severity bands (CVSS — DATA ONLY, never decoration):**
| Token | Dark | Range |
|-----------------------|-----------|-------------|
| `--severity-critical` | `#CC0000` | 9.0 – 10.0 |
| `--severity-high` | `#E85D00` | 7.0 – 8.9 |
| `--severity-medium` | `#C89B00` | 4.0 – 6.9 |
| `--severity-low` | `#4A7A4A` | 0.1 – 3.9 |
| `--severity-info` | `#4A6A8A` | informational |
The institutional palette keeps the whole UI monochrome; white (dark
theme) / black (light theme) marks the single focal point of any screen
(active nav, focused card, primary CTA). No purple, no dot-grid, no
glass, no colored glow.
**Typography** — body in Geist (self-hosted via Fontsource) / system-ui ·
code in Geist Mono / JetBrains Mono · tabular-nums for stat cards.
## 📜 License
Licensed under [Apache License 2.0](LICENSE). The license includes an explicit patent grant — relevant for an offensive-security tool that may implement publicly-known exploitation techniques.
The open-core / paid-plugin split is **designed**, not hypothetical:
[docs/plugin-architecture-spec.md](docs/plugin-architecture-spec.md)
defines the boundary between a safety-critical open-core trunk
(Apache-2.0) and paid capability plugins gated by per-plugin
entitlement. If a hosted BULWARK-Cloud ever ships on top of that split,
a dual-license arrangement may apply: Apache-2.0 on the open-source core,
commercial license on the cloud-only and paid-plugin layers. Pattern:
HashiCorp pre-BSL.
END · OF · BRIEFING · BULWARK/v5.26.0 · github.com/bulwark-sec/bulwark
**BULWARK** · Silent. Patient. Inevitable.
*Built by reading what existing tools got wrong and doing the opposite.*