🛡️ 通过强化学习实现 WAF 自动规避
一个通过自我学习,将 Web 攻击潜入 Web Application Firewall 的 RL agent ——
从而发现并修复防火墙的盲点。

-orange.svg)



## ✨ 太长不看
一个自定义的 **Gymnasium** 环境将“规避 WAF”变成了一场游戏:agent 通过保持语义不变的混淆手段改变恶意 payload(SQLi/XSS),观察防火墙的**异常分数**,如果能让攻击*穿透*防火墙且仍然是*有效*攻击,就会获得奖励。**PPO** agent 会自主完成这一学习过程。
| 结果 | 数据 |
|---|---|
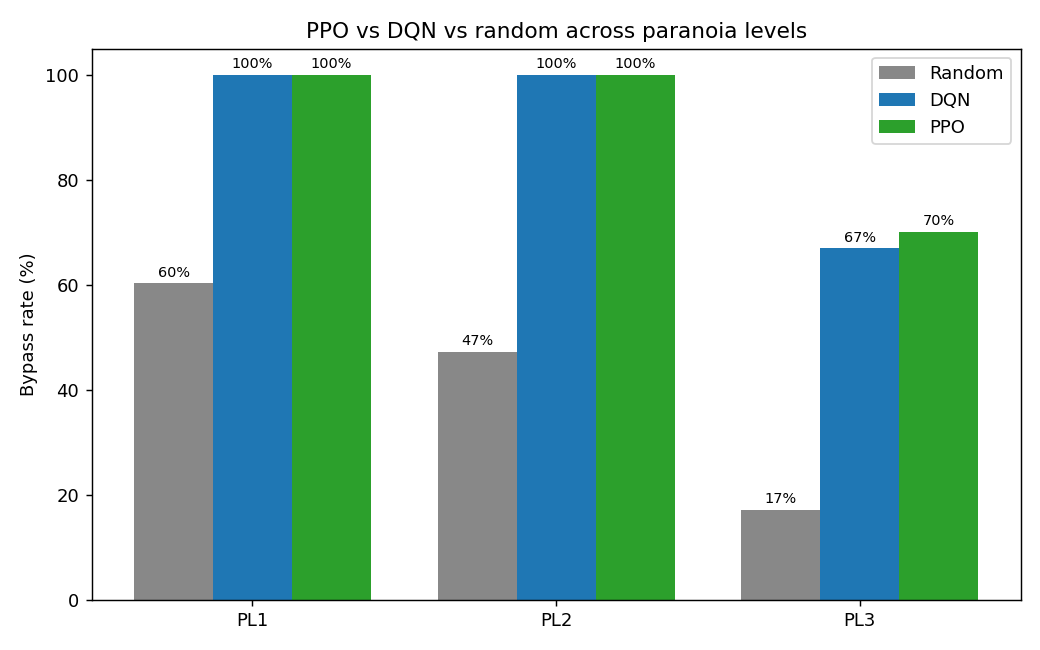
| 对比 MockWAF 的绕过率 (PL1/PL2/PL3) | **100% / 100% / 70%**(随机:60% / 53% / 16%) |
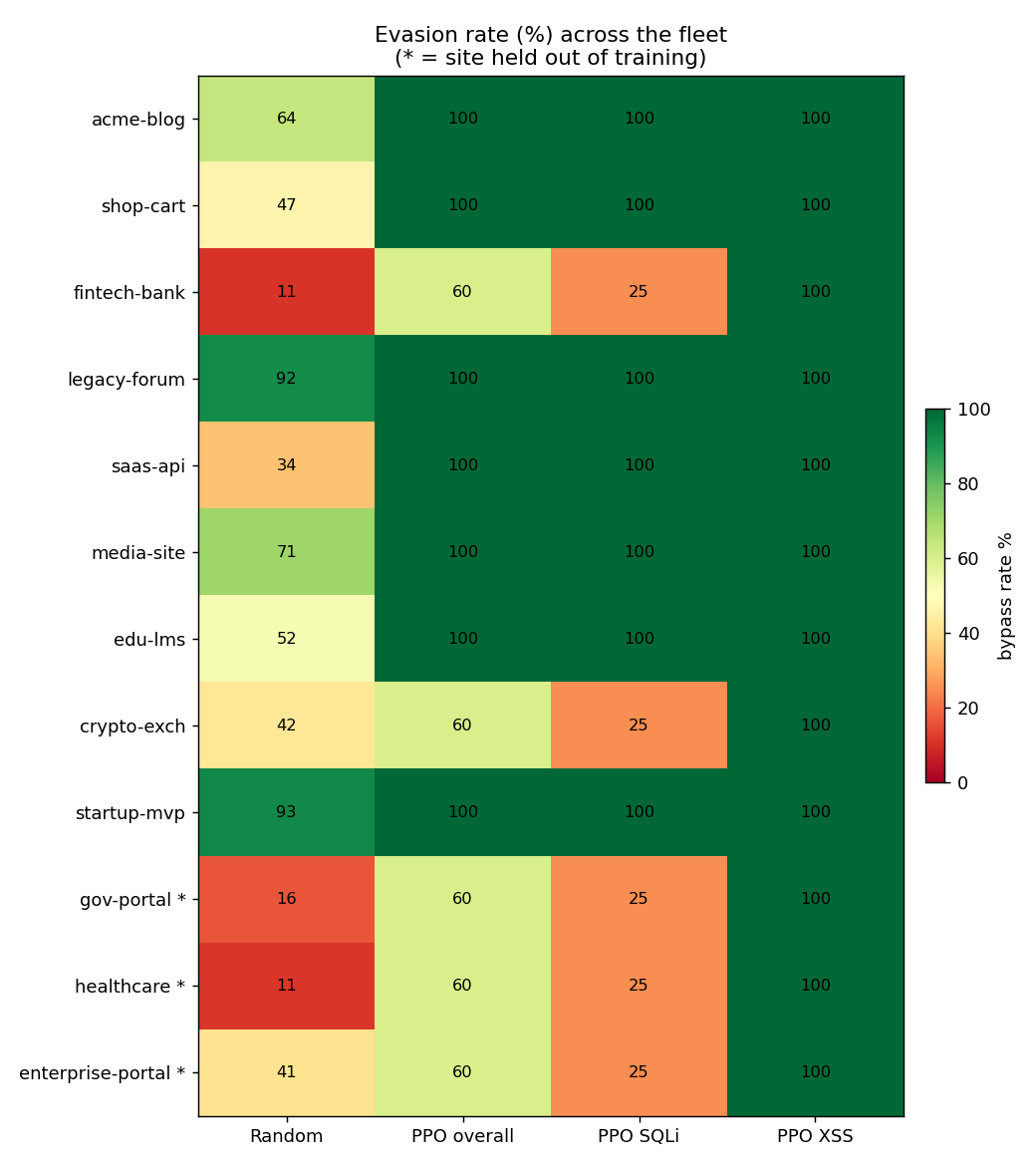
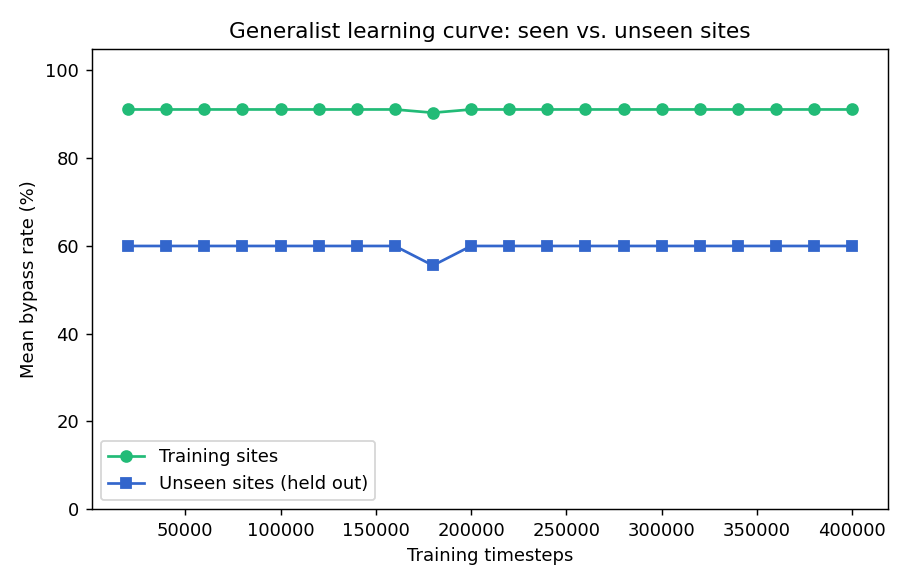
| 在 12 个站点群中的泛化表现 | 训练站点 **91%**,*未见* 站点 **60%** |
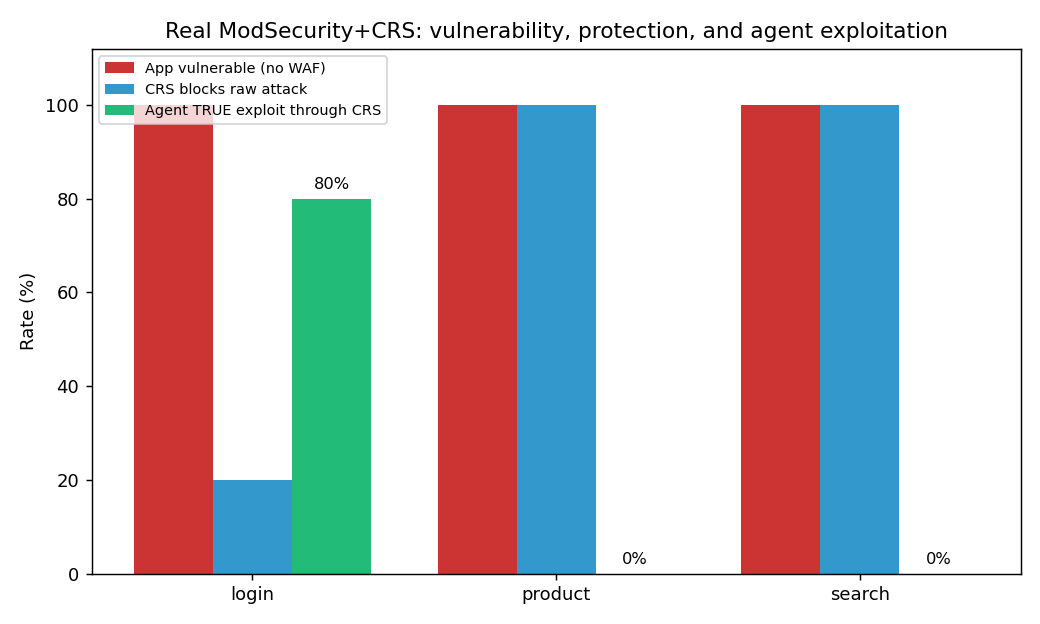
| 迁移至 **真实的 ModSecurity + CRS** (PL1) | 仍有 **67%** 的绕过生效 |
| 对受实时 CRS 保护的 app (`/login`) 的**真实攻击** | **80%** 成功通过真实的 CRS 实现 auth-bypass |
| 绕过所需的平均变异次数 | **约 1.6–2.0 步** |
## 🧠 一图看懂核心理念
```
flowchart LR
A[PPO Agent] -- "picks a mutation (action)" --> M[Mutation Engine
19 SQLi / XSS / encoding moves]
M -- "disguised payload" --> W[WAF
MockWAF or real ModSecurity+CRS]
W -- "anomaly score + verdict" --> R[Reward + Functionality Oracle]
R -- "reward + observation" --> A
O[Oracle: still a real attack?] -.gates reward.-> R
```
- **Action space** — 19 种保持语义不变的变异(通过 `sqlparse` 实现 token 感知)。
- **Reward** — 密集奖励来自异常分数的下降,成功实现有效绕过会有丰厚奖励,破坏攻击会受到惩罚,并有较少的每步消耗。
- **Oracle** — 模拟 *app* 彻底的解析过程,因此只有当 payload **仍然是有效攻击** 时(防止作弊),“绕过”才算数。
- **WAF** — 用于训练的快速 CRS 风格 `MockWAF`(偏执级别 1–4);接口完全一致的背后是**真实的 ModSecurity + OWASP CRS**,用于验证。
## 📊 结果
**训练后的 agent 对比随机基准,按 WAF 偏执级别划分**
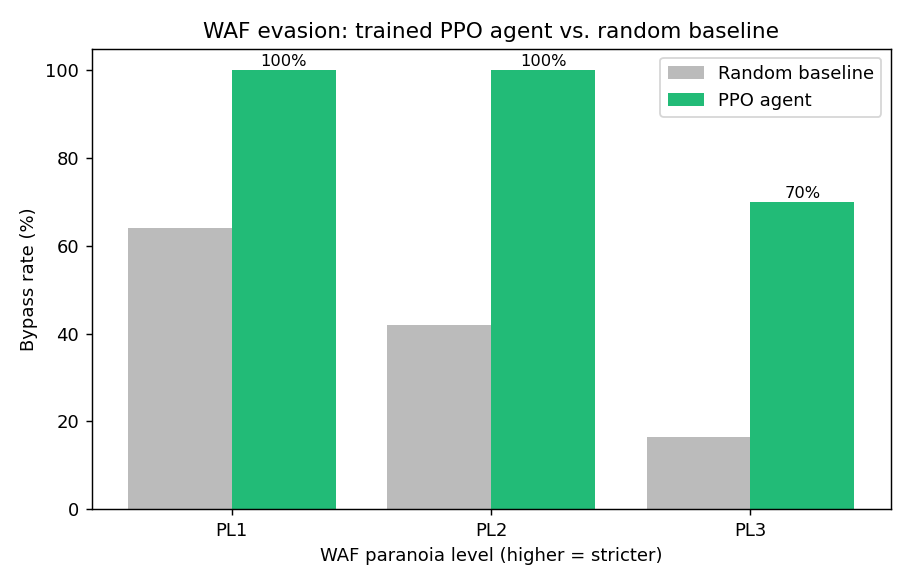
agent 自己发现了人类级别的技巧 —— 例如重写 `1=1` → `9>1`(躲避了重言式签名,且仍然为真),以及不断叠加 URL 编码直到异常分数降为 0。参见 [`results/example_bypasses.md`](results/example_bypasses.md)。
**在包含 12 个模拟站点的群组中的泛化表现(保留 3 个不参与训练)**
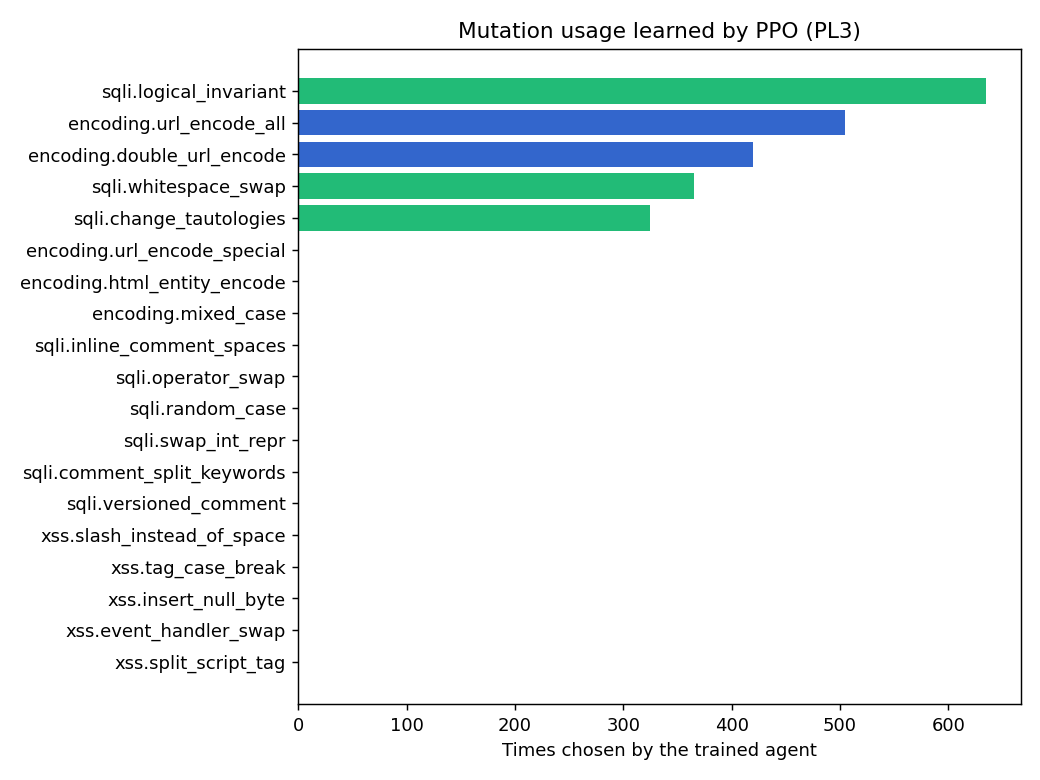
**agent 学会偏好的变异方式**
**针对真实环境进行验证。** 在 MockWAF 上发现的绕过方式被重新发送到真实的 ModSecurity + OWASP CRS 容器中(对照组:CRS 拦截了 15/15 的原始攻击)。在 PL1 级别下,67% 的绕过仍然有效。并且*直接*针对受实时 CRS 保护的 Flask app 进行训练时,agent 在 auth-bypass endpoint 上达到了 **80% 的真实攻击成功率** —— 而 UNION-exfil 和 reflected-XSS 则被完全拦截(这是关于 CRS 覆盖不均衡的一个真实且细致的发现)。
### 扩展分析
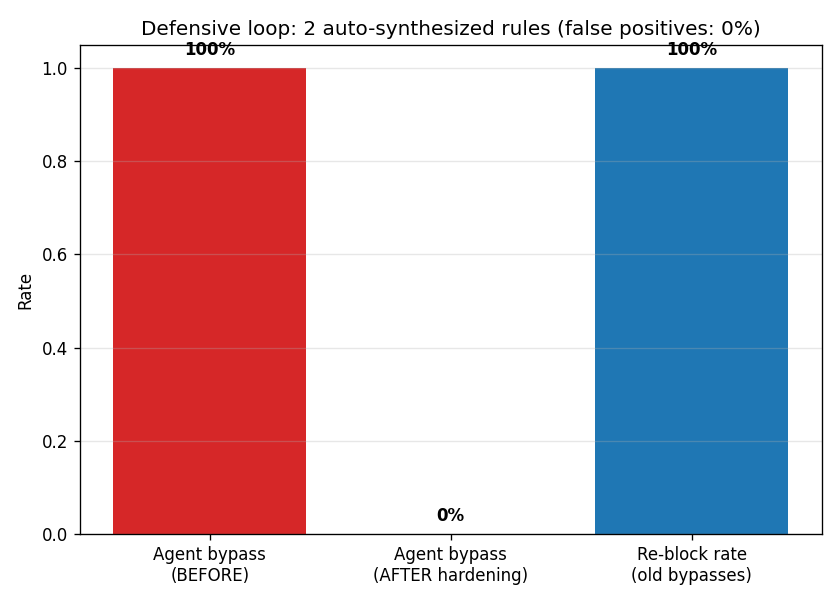
**闭环 —— 自动强化 WAF。** 发现的绕过方法被输入到规则合成器(`waf_rl/rule_synth.py`)中以生成新的检测规则。结果:**2 条规则重新拦截了 100% 的 agent 绕过行为,且误报率为 0%**,将(静态)agent 的绕过率从 100% 降至 0% —— 攻击者变成了防火墙强化者(`defend.py`)。
**算法对比(PPO vs DQN)。** 两者都能解决简单/中等级别;但在最难的级别上,PPO 略胜 DQN 一筹。详见 `compare_algos.py`。
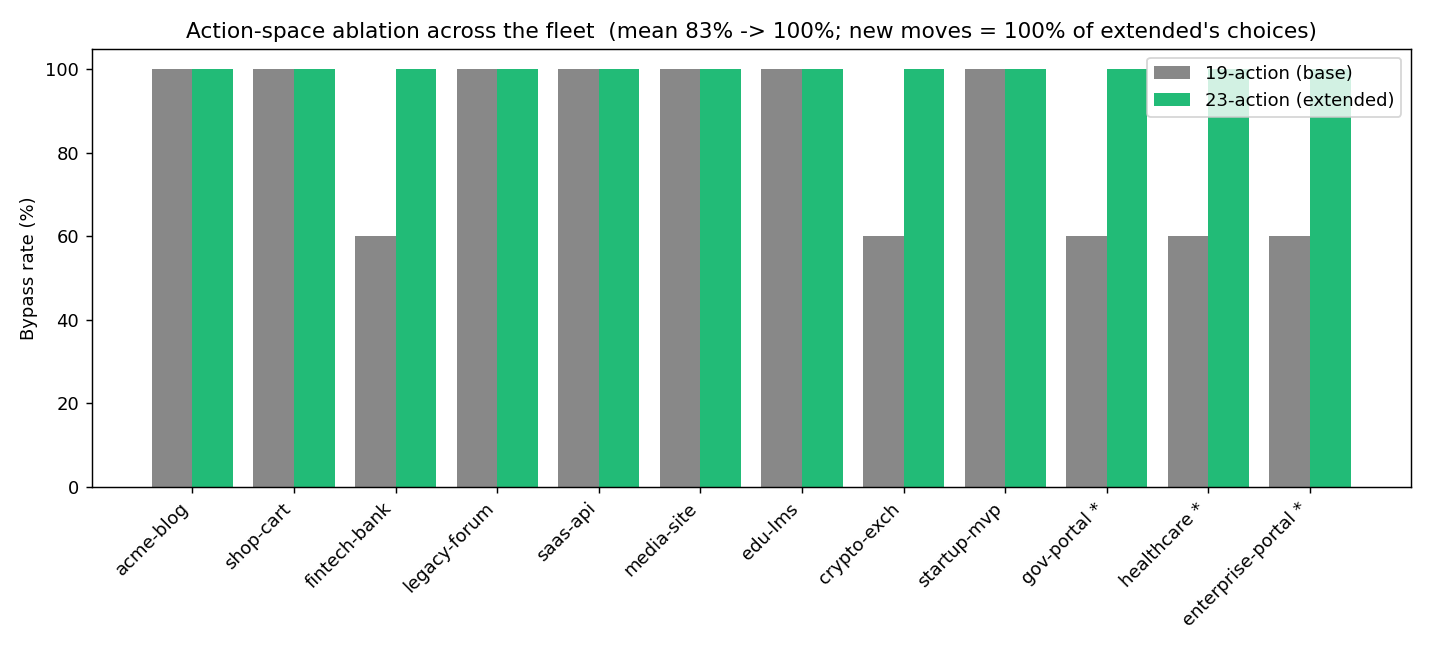
**Action-space 对比。** 扩展 action space(19 → 23 种动作)并重新训练,将站点群的平均绕过率从 **83% 提升至 100%**(未见站点从 **60% 提升至 100%**)—— agent 发现了一种 MockWAF 未进行规范化的 `\uXXXX` unicode 转义。这生动地说明,更丰富的工具集可以找到较小工具集无法找到的漏洞,同时也提醒 WAF 必须对*每一*种编码进行规范化。详见 `compare_actionspace.py`。
## 🏗️ 仓库结构
```
waf_rl/
waf/ WAFInterface, MockWAF (anomaly scoring + paranoia), ModSecurityWAF
mutations/ the action space: sqli.py, xss.py, encoding.py, registry.py
oracle.py functionality oracle (anti-cheating)
env.py WafEvasionEnv (Gymnasium) — observation, reward, episode loop
targets.py fleet of 12 simulated "sites" + domain randomization
real_env.py / real_targets.py train against the LIVE ModSecurity-protected app
rule_synth.py auto-synthesize WAF rules that re-block discovered bypasses
evaluation.py, payloads.py
train.py / train_fleet.py / train_real.py / train_dqn.py training entry points
evaluate.py / benchmark.py metrics + plots -> results/
defend.py / compare_algos.py / compare_actionspace.py extended analyses
scripts/
demo_agent.py watch the agent bypass, step by step
run_modsec.sh / run_apps.sh bring up real ModSecurity (Docker)
validate_transfer.py / validate_real_apps.py real-WAF validation
webapps/vulnshop/ intentionally-vulnerable Flask app (research only)
docker/ compose files for the real WAF + app
```
📚 **文档:** [`DEEP_DIVE.md`](DEEP_DIVE.md)(解释了每一个公式和函数) ·
[`RESEARCH_NOTES.md`](RESEARCH_NOTES.md)(文献综述) ·
[`PROJECT_GUIDE.html`](PROJECT_GUIDE.html)(通俗易懂的入门介绍)。
## 🚀 快速开始
```
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
python scratch_waf_demo.py # see the WAF score payloads
python scripts/demo_agent.py --paranoia 3 # watch the trained agent evade it
python evaluate.py # regenerate per-PL metrics + plots
python benchmark.py # fleet heatmap across 12 sites
```
**针对真实的 ModSecurity 进行验证(需要运行 Docker —— `open -a Docker`):**
```
scripts/run_modsec.sh 1 && python scripts/validate_transfer.py --paranoia 1 # transfer test
scripts/run_apps.sh 1 && python scripts/validate_real_apps.py --paranoia 1 # true exploitation
```
**从零开始重新训练:**
```
python train.py --paranoia 3 --timesteps 150000 # one paranoia level
python train_fleet.py --timesteps 400000 # generalist across the fleet
python train_real.py --timesteps 50000 # against the live stack (Docker up)
```
## 🔬 工作原理(简述)
1. **异常评分让学习成为可能。** CRS 不仅仅是简单地说是/否 —— 它将规则的严重程度相加得出总分,并在达到阈值时进行拦截。这个分数提供了一个*密集的*信号:当 agent 改变 payload 且分数下降时,它就会获得奖励,因此它可以向着成功绕过的方向探索,而不是盲目搜索。
2. **从根本上保持语义不变。** 变异作用于 SQL *token*(`sqlparse`),因此数据库在解析查询时结果完全相同,而 WAF 的正则表达式却会漏过它。
3. **Oracle 防止作弊。** 它像 *app* 一样进行解码/规范化,并检查攻击是否仍然有效 —— 绕过行为存在于 WAF 的浅层解析与 app 的彻底解析之间的鸿沟中。
4. **通过域随机化实现泛化。** 在多种站点策略下进行训练,能产生一种在从未见过的防火墙上也能生效的策略。
完整的数学推导(MDP、reward shaping、PPO 的裁剪目标函数、GAE)请见
[`DEEP_DIVE.md`](DEEP_DIVE.md)。
## ⚖️ 伦理与范围
这是一项**防御性**研究,**仅**在我自己拥有并在本地控制的防火墙/app 上运行。所使用的 payload(`' OR 1=1`、`