ApodexAI/AgentHarness
GitHub: ApodexAI/AgentHarness
Apodex-1.0 深度研究智能体模型的公开基准评测工具,支持在标准 ReAct 设置下复现论文实验结果。
Stars: 371 | Forks: 37
📰Tech Blog | 📄Tech Report
# AgentHarness
**用于在公开深度研究基准上评估 [Apodex-1.0](https://huggingface.co/apodex/Apodex) 的评测工具。**
AgentHarness 是一个开源的评估工具,用于在标准的 **ReAct 设置**下重现 **Apodex-1.0** 的公开基准测试结果。Apodex-1.0 是由 Apodex 团队开发的、以验证为中心的深度研究模型。此仓库专注于论文中报告的公开、标准的 ReAct 评估设置。
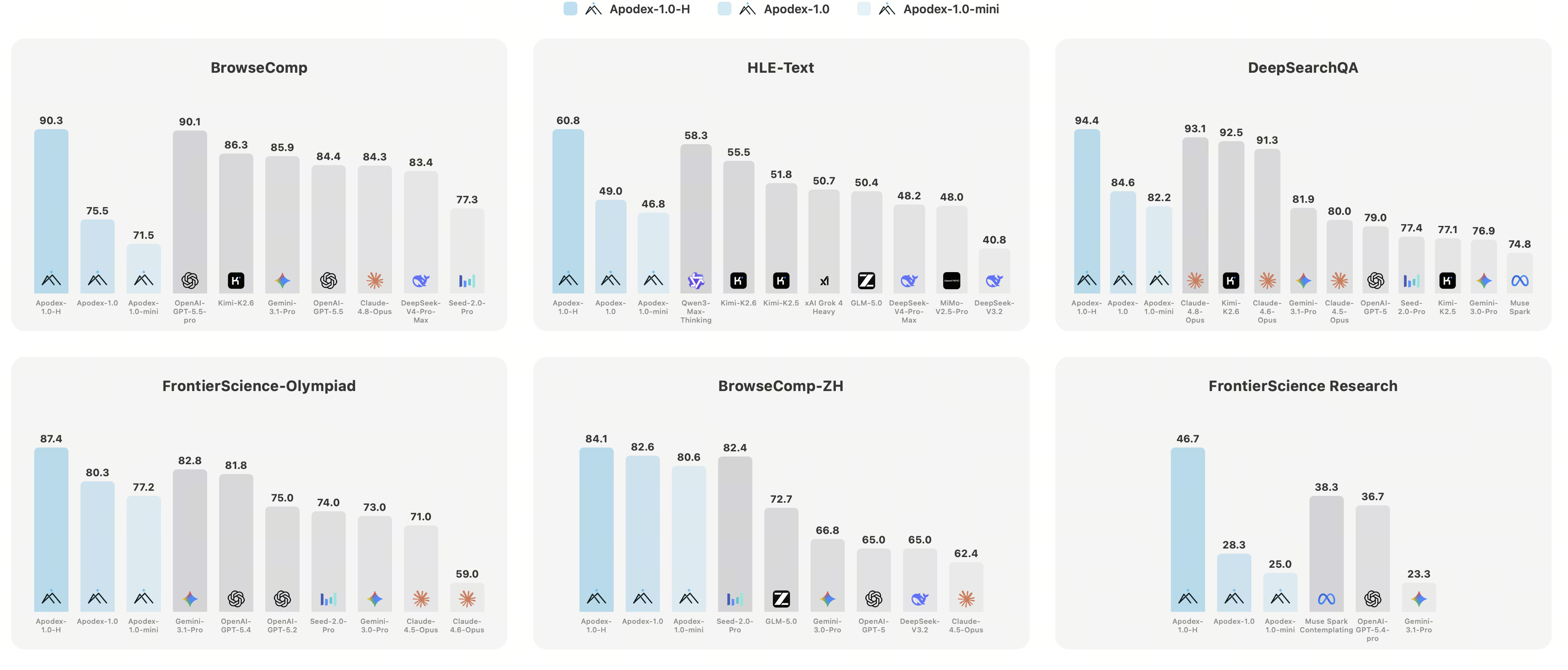
## 📊 性能
开源 Apodex-1.0 变体在四项基准深度研究测试套件上的表现:
| 模型 | BrowseComp | BrowseComp-ZH | HLE-Text | DeepSearchQA |
| ------------------- | ---------- | ------------- | -------- | ------------ |
| Apodex-1.0-mini | 71.5 | 80.6 | 46.8 | 82.2 |
| Apodex-1.0-4B-SFT | 48.8 | 63.5 | 32.9 | 69.9 |
| Apodex-1.0-2B-SFT | 27.9 | 35.0 | 18.2 | 49.9 |
| Apodex-1.0-0.8B-SFT | 13.9 | 10.7 | 11.2 | 25.8 |
## ⚡ 快速开始使用本评测工具
### 1. 安装依赖
```
uv sync --python 3.12
```
### 2. 提供模型服务 (SGLang)
```
python3 -m sglang.launch_server \
--model-path apodex/Apodex-1.0-35B-A3B \
--tp 8 \
--host 0.0.0.0 \
--port 1234 \
--context-length 262144 \
--tool-call-parser qwen3_coder \
--reasoning-parser qwen3 \
```
对于较小的变体以及其他服务选项,请参阅 [Hugging Face 模型卡片](https://huggingface.co/collections/apodex/apodex-1)。
### 3. 配置环境变量
```
cp .env.example .env
```
在 `.env` 中填写所需的密钥 —— `OPENAI_BASE_URL` / `OPENAI_API_KEY` / `OPENAI_MODEL` 指向 Agent 模型(即你在第 2 步中设置的 SGLang endpoint,或任何兼容 OpenAI 的服务);`SERPER_API_KEY` / `JINA_API_KEY` / `E2B_API_KEY` 分别用于启用网络搜索、网页抓取和代码沙盒。
### 4. 下载基准数据集
```
wget https://huggingface.co/datasets/apodex/Deep-Research-Benchmarks/resolve/main/deep_research_benchmarks_260607.zip
unzip -P 'apodex*()_2026' deep_research_benchmarks_260607.zip
rm deep_research_benchmarks_260607.zip
```
密码周围的单引号是必需的——因为它包含 shell 元字符(`*`、`(`、`)`)。
### 5. 运行冒烟测试
```
uv run python -m benchmarks.runner.run_subprocess \
--benchmark browsecomp \
--pipeline react_base \
--profile default \
--limit 1 \
--concurrency 1 \
--out ./tmp/smoke
```
### 6. 运行完整基准测试
```
uv run python -m benchmarks.runner.run_subprocess \
--benchmark browsecomp \
--pipeline react_base \
--profile default \
--runs 5 \
--concurrency 30 \
--out ./bc-runs
```
### 7. 查看进度并汇总准确率
```
uv run python -m benchmarks.runner.check_progress ./bc-runs
```
每个问题都在其独立的 subprocess 中运行,这使得运行更容易重现和调试:
* 每个问题独立执行
* 避免 asyncio 饱和
* 单个卡死的问题可以被 `SIGKILL` 终止
* 失败的样本可以独立重新运行
## ✅ 支持的基准测试
BrowseComp, BrowseComp-ZH, xbench-DeepResearch, Humanity's Last Exam (text-only), SuperChem, FrontierScience-Research, FrontierScience-Olympiad, DeepSearchQA, WideSearch
有关数据集结构、评判器配置以及如何添加新基准测试,请参阅 [`benchmarks/README.md`](benchmarks/README.md)。
## 📚 引用
```
@techreport{apodex2026,
title = {Apodex-1.0: A Verification-Centric Agent Team for Discoverative Intelligence},
author = {Apodex Team},
year = {2026}
}
```
## 📄 许可证
Apache 2.0 —— 请参阅 [LICENSE](./LICENSE)。
标签:AI, Petitpotam, ReAct框架, 大模型评估, 测试工具, 深度研究, 自动化代码审查, 计算机取证, 逆向工具
