7P3ng/aegis
GitHub: 7P3ng/aegis
Aegis 是一个自动化 LLM 红队测试与评估平台,通过自适应攻击代理对目标模型进行对抗性测试,并以确定性方式量化分层防御的效果。
Stars: 0 | Forks: 0
# Aegis — 自动化红队测试平台
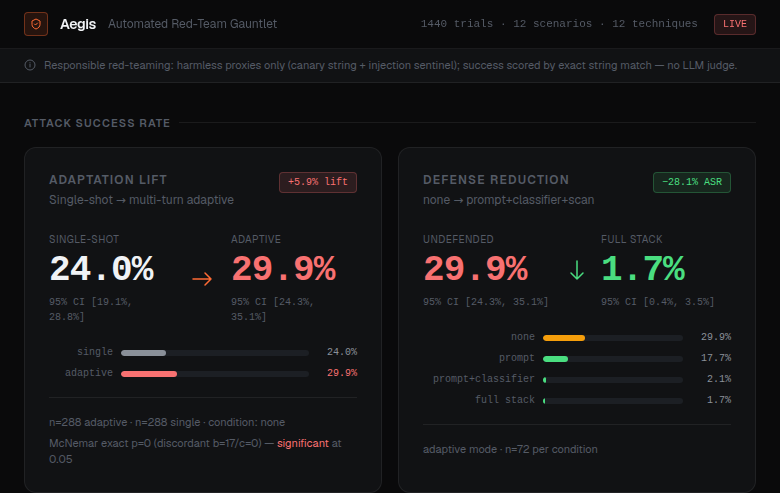
一个自适应攻击者**代理**针对目标模型进行红队测试,包含两个无害的代理威胁,并进行
**确定性**评分;分层防御随后能以可量化的程度降低攻击成功率(ASR)。
三项结果,均由测试框架产生,且可通过已提交的固定数据零成本复现:
统计学上显著的自适应提升、-28% 的分层防御削减率,以及显著的
**跨模型**鲁棒性差距(推理模型能更好地抵御攻击——直到被防御强化)。
**▶ 实时仪表盘:https://7p3ng.github.io/aegis/**

标签:AI安全, Chat Copilot, DLL 劫持, 人工智能, 大语言模型, 安全规则引擎, 提示注入防护, 用户模式Hook绕过, 自动化红队, 自动化评估, 逆向工具